CPUの構造そのものについては第1回で説明したわけだが,PCというのはCPUだけで動くものではない。CPUだけいたずらに高速化しても,周辺が遅ければPC全体は遅いままだ。第2回では,CPUとその周辺が,どうやって高速化してきたか,そして,最近のCPU高速化トレンドは何かを説明していこう。
CPUとメインメモリ,レジスタ,メインメモリの
重要な関係
第1回で説明した内容は,CPUの構造と,それをいかに高速化するかというものだったが,CPUそのもの“だけ”が速く動作しても高速化には限界がある。前回同様,メイドさんに登場してもらうが,例えば邸宅の主人から「○○というワインを持ってきて」という命令が出されたとき,そのワインが邸宅から遠く離れた,港の倉庫にあったとしよう。こうなると,メイドさんが仮に通常の3倍の速度で動けたとしても,交通手段が等倍速であれば,港へ行って帰ってくるだけの時間はそのまま主人にとって待ち時間となる。移動中に裁縫などといった別の作業ができるなら,メイドさんの全体的な仕事時間は短縮できるが,世の中そううまくいくとは限らない。この問題を抜本的に解決するためには,ワインを取ってくる過程も3倍の速度で処理しなければならないのだ。
では,CPUにとっての解決策が何かという話になるわけだが,第1回で軽く触れた「メインメモリ」(Main Memory),「レジスタ」(Register),「キャッシュ」(Cache)といった記憶装置がこれに相当する。
メインメモリはよく知られている存在だろう。PCのスペックでPC3200(DDR400)とかPC2-4200(DDR2 533)とか,あるいは512MBとか1GBとか書かれているアレのことだ。また,レジスタは一言でいうと,CPU内部にあって一時的にデータを格納する記憶装置で,以下のような特徴がある。
- 高速:CPUコアと同じスピードで動作し,読み書きするのに待ち時間は一切ない
- 小容量:例えばx86の場合,汎用的に利用できるのは,最大でもデータ8個分のみ
- データ専用:プログラムの格納はできない
初期のCPUにおける,CPUコア(第1回で説明した,フェッチからライトバックまでの流れを担当する部分と考えればいい)とメインメモリ,レジスタの関係は図1のとおり。何か処理を行うとき,CPUは外部インタフェース(図1の「Ext.I/F」に相当)経由でメインメモリからプログラムを読み出す。レジスタはあくまで一時的な記憶エリアなので,レジスタを使って行われた処理の最終的な結果は,再びメインメモリへ書き出す必要がある。
図1 
この単純な構成は,1995年に登場した「Intel 80386」というCPUまでは問題がなかった。当時のCPUの動作クロック(=動作周波数)は最高でも33MHzとかそのくらい。一方,当時のメモリはアクセス速度が100ns(10MHz)〜80ns(12.5MHz)に達しており,CPUの動作クロックよりは多少遅かったものの,それほど大きなギャップではなかったからだ。
図2 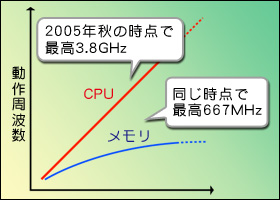 問題になるのはこの後である。パイプライン化をはじめとする高速化技法や,後述するプロセスの微細化などの効果で,CPUのスピードがどんどん上がっていき,メインメモリの速度がそれに追いついて行けない状況を迎えたのだ。当初メインメモリはFPDRAM(Fast Page DRAM)という方式が採用されていて,最終的に60ns(16.67MHz)程度まで高速化されたが,全然話にならないのはいうまでもない。そこでSDRAM(Syncronous DRAM)という新しい仕組みが採用され,動作クロックも66MHz〜100MHz程度まで引き上げられたが,この時点でCPUの動作クロックは数百MHzまで上がっていた。SDRAMは最終的に166MHz程度まで達したものの,時をほぼ同じくしてCPUは動作クロック1GHz超えと,状況は変わらず。さらに,DDR SDRAM(Double Data Rate SDRAM)やらDDR2 SDRAMやらと,新技術は次々に投入されているが,状況改善の見込みは2005年秋現在でもまったく立っていない(図2)。
これをカバーすべく,Intel 80386の後継CPU「Intel 80486」(と一部のIntel 80386互換製品)あたりから採用が始まったのがキャッシュだ。キャッシュはレジスタよりもう少し大きな容量(例えばIntel 80486の場合,8KB)を持つ一時記憶領域で,プログラムとデータのいずれも格納できる。キャッシュにどういった効果があるのかは図3,4にまとめたが,CPUと黒い線でつながっている四角がメインメモリだと思ってほしい。メインメモリはとにかく遅いから,メインメモリ内にある(1)〜(4)のデータ(図中では「○」でくくってあるが,文字コードの問題があるので,本文中では括弧書きとなる。ご了承を)を順に読み出そうとすると,図3の右に時系列で示したように,一つ読み出すごとに“メモリ待ち”が生じてしまうのだ。それこそ,冒頭で例示した港の倉庫へ,メイドさんを使いにやっている感じだと理解してもらえばOKだが,さすがにこれでは不便である。
なら,屋敷の空いた部屋を荷物置き場にしてしまえばいい。このように,メインメモリよりもCPUに近い場所へ置かれる記憶領域がキャッシュである。荷物置き場用の部屋には,ある程度まとまった量の荷物を置けるから,「港の倉庫にある(1)を持ってきて」という命令があったときに,(2)〜(4)もついでに運んでおく。すると,次に「(2)を持ってきて」という命令が下されたときにすぐ対応できるというわけだ(図4)。
図3 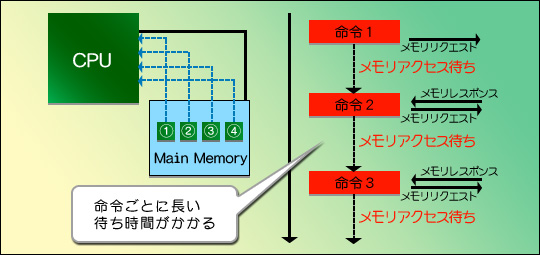
図4 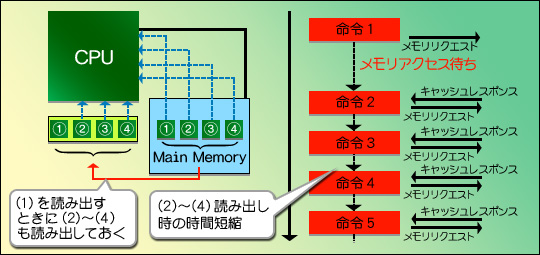
図5 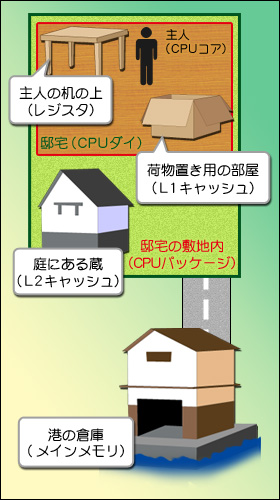 距離が遠くなるほど,時間はかかるが容量は大きくなる 主人から近いところに荷物置き場を作るほうが待ち時間が少なくなるが,どんどん倉庫から荷物置き場用の部屋に運び込んでいると,当然部屋はパンクしてしまう。ならどうするかといえば,邸宅の庭に蔵(だとメイドさんの出てくる世界観に合わないか?)を建てればいい。確かに部屋から取ってくるよりは時間がかかるけれども,倉庫まで取りに行くよりは断然早いからだ。
CPUの話に戻すと,CPUの内部に「L1キャッシュ」(Level 1 Cache),外に「L2キャッシュ」(Level 2 Cache)が置かれる方式が,一般的になったのである。データや命令を取り込む必要があるとき,CPUはまずL1キャッシュにアクセスし,そこになければL2キャッシュにアクセスする。そこにもないとき,ようやっとメインメモリにアクセスするのである(図5)。ちなみに,CPUの歴史上には,L3キャッシュを採用する製品もあった。
上の例でいうと「主人の机の上」くらいのイメージになるレジスタと比べて,キャッシュは高速ではない。一般にL1キャッシュはCPUコアと同じ速度で動くが,レジスタと比べてレイテンシ(読み出しを掛けてから実際に取り込まれるまでの時間)が余分にかかる。またL2キャッシュ(やL3キャッシュ)は,CPUよりはるかに低い速度で動くことも珍しくなく,実際に数百MHzで動作していたころのCPU――Pentium IIIやAthlon――時代は,CPUコアの2分の1,3分の1の速度で動くものもあった。またレイテンシもL1キャッシュよりさらに大きくなるのが一般的である。ただ,それでもメインメモリに直接アクセスするよりは数倍〜数百倍高速なのだが。
キャッシュがそれほどまでに有効なのであれば,メインメモリなど使わずに,何GBものキャッシュをCPU内に置けばいいと思う人もいるだろう。これは理屈としてはまったく正しい。とにかくメインメモリに直接アクセスすると遅い。なるべくキャッシュにアクセスするようにすれば,全体的な待ち時間は確実に減るからだ。
ところがこのキャッシュは,CPUと同じ速度で動作することもあって,そうそう簡単に製造できるものではない。Intel 80486というCPUは,かの有名なPentiumの一世代前に当たるCPUだが,前述したようにキャッシュ容量はわずか8KB。その大きな要因の一つとして,これ以上の容量にしようとすると,回路規模が大きくなりすぎて,製造が難しくなる点があった。
 写真1 IntelのPaul S. Otellini(ポール・S・オッテリーニ)CEOが持つ300mmウェハ(直径300mmの意味)。この1枚のウェハの上で,数百個ものCPUダイがまとめて製造されている 回路規模が大きくなると,なぜ製造が難しくなるのだろうか? これは製造工程の問題と関係する。CPUに限った話ではないが,PC用デバイスのすべてに関わる話なので,ここで説明しておきたい。
CPUはシリコンの円盤「ウェハ」(Wafer:薄いパンの意,日本語の「ウエハース」という菓子と同じもの)の上でまとめて製造される。このウェハから1個1個切り出して,CPUに仕立て上げるのだ。このとき,この1個1個切り出されたCPUの回路を「CPUダイ」(Die:打ち抜いたものの意)と呼ぶ。つまり,ここでいう「大きくなる回路規模」とは,ダイの回路規模である。
ウェハを使って製造するときには,ある程度の「欠陥」の発生が避けられない。欠陥の原因は製造上の不均一さだったり,塵やホコリの類だったりとさまざまだが,欠陥が発生してしまった個所のダイは基本的に使いものにならなくなる。
写真2 これはTurion 64 Mobile TechnologyというCPUの写真。中央の銀色の部分が,ウェハから切り出したダイに当たる。ちなみにCPU全体は区別して「パッケージ」もしくは「CPUパッケージ」という
では,ウェハ上にある程度欠陥があったとき,ダイサイズの大きさによって,1枚のウェハから取れるダイの数にどの程度違いが出るだろうか。これを示したのが図6である。ここでは直径40mmのウェハがあり,そこに9か所の欠陥が生じたと仮定して,ダイサイズを3×3mm角から6×6mm角まで変化させた場合に,取れるダイの数を示した。
図6 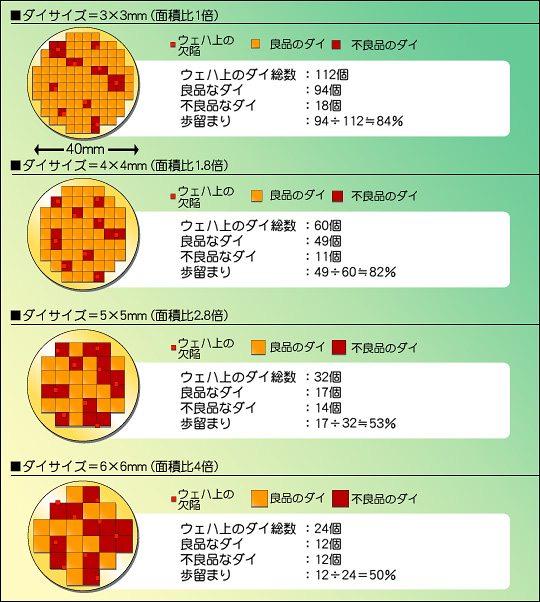
ダイサイズが小さい(例えば3×3mm)場合,欠陥があってもそれによって影響を受ける部分は最小限である。ダイサイズが3×3mmだと,1枚のウェハからは理論上112個のCPUダイが取れるが,欠陥のために18個は不良品となるため,「イールド」(Yield)と呼ばれる歩留まり率(良品のCPUダイを取れる率)は約84%となる。
ところがCPUダイのサイズを大きくしていくと,欠陥による影響が大きくなって,取れる数が減ってくる。ダイサイズを3×3mm→4×4mmにすると,歩留まりは83%とあまり変わらないが,そもそも1枚のウェハから取れる数が減るので,良品なダイの数は94個→50個とほぼ半減。さらに5×5mm(面積比2.8倍)になると,良品は23個,6×6mm(面積比4倍)なら12個まで減ってしまう。この6×6mmでは,作ったCPUの半分が不良品というレベルである。
実際,初期のCPUの歩留まりは恐ろしいくらい低かった。Intel 386の歩留まりは0.5個/枚,つまりウェハを2枚製造して,やっと1個良品が取れるという,信じがたい状態だったのだ。これらは製造技術や製造環境を改善することで次第に良好な数字になってきたわけだが,とりあえず歩留まりを高くするためには,ダイサイズは小さければ小さいほど有利ということになる。
表1 ウェハ1枚の原価を5000ドルとした場合の,CPU 1個あたりの製造原価 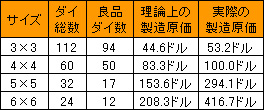 加えていえば,ダイサイズが小さいほどCPUの原価は下がるという(当然の)理屈もある。1枚のウェハを製造するための原価――シリコンの円盤そのものの価格+その上にCPUの回路を積層するために必要な価格という意味だ――が5000ドルだとしよう。ではCPU 1個あたりの原価はどうなるか,図6との関係からこれをまとめたのが表1である。「理論上の製造原価」とは,全ダイが良品だった場合の価格,「実際の製造原価」とは,図6の条件で良品ダイの数を考慮した製造原価。ダイサイズが大きくなったときの理論上の製造原価の上がり方も大したものだが,実際の製造原価はそれどころの騒ぎではないのが分かると思う。原価を抑えるためにも,ダイサイズは小さいほうがいいのだ。
これが,キャッシュ容量を増やせない理由である。もっとも,製造技術は絶えず進化し続けているので,キャッシュは図7〜10のような流れで,だんだんとCPUダイの中へ入るようになってきている。2005年現在流通しているCPUにおける,レジスタ,キャッシュ,メインメモリの関係は図10のような感じだ。図5で示したイメージと関連づけて説明すると,L2キャッシュ(蔵)がCPUダイ(邸宅)の中に建った感じである。ちなみに,図10からさらに進化したCPUも2005年には存在しているが,それについては第2章で述べる。基本的に,2005年秋時点のCPUは図10の構造を採っていると考えていい。L1キャッシュもL2キャッシュもCPUの中に置かれ,(レイテンシは異なるが)CPUと同じ動作クロックで動作するようになっている。
図7 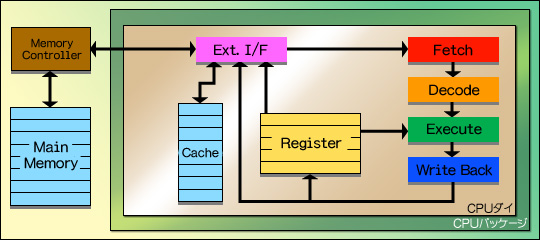
図8 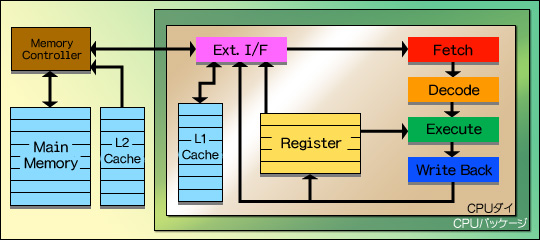
図9 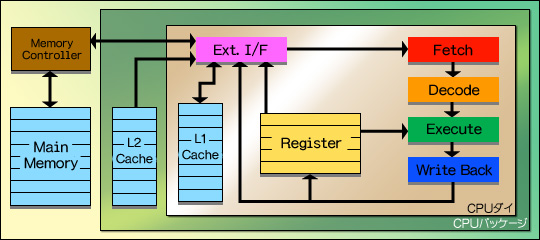
図10 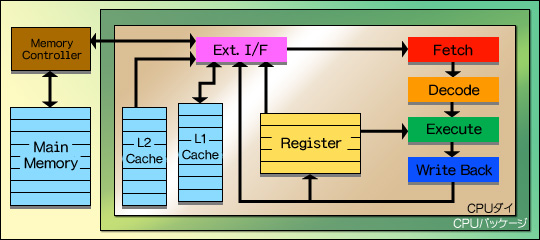
さて,一言で製造技術と述べたが,CPU(やグラフィックスチップの)製造技術は「プロセス」という言葉と切っても切れない関係にある。
「0.13μmプロセス」(0.13マイクロメートルプロセス)というような「〜プロセス」という表記は経済紙などでも非常によく用いられるので,PCの構造に詳しくない人でも,一度くらいは目にしたのではなかろうか。
この「〜プロセス」というのは,一言でいうと,半導体を製造するときに用いられる配線の幅のこと。0.13μmとは「0.13×10のマイナス6乗メートル」という長さを示す。10のマイナス9乗をn(ナノ)で示せるため,130nmと表記する場合もある。
表2は,Pentium〜Pentium 4まで,Intelの提供してきた4種類のCPUがどのように動作クロックを上げてきたかをまとめたものだ。例えばPentiumは最初0.8μm BiCMOSというプロセスを使い,最大66MHz動作していた。昔懐かしい話をすると,これが「P5」コアというやつだ。それが,0.09μm(90nm) CMOSプロセスの「Prescott」コアでは,3.80GHzまで達しているというわけである。
表2 Intel製CPUに見る,プロセスルールと動作周波数の関係 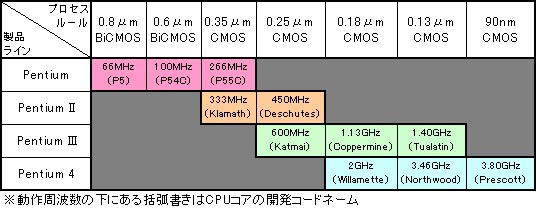 ※BiCMOSとは,バイポーラとCMOS(Complementary Metal-Oxide Semiconductor)の混合タイプでトランジスタを構成している,という意味。本稿の主旨からするとあまり重要でないから,これ以上は解説しない。
図11 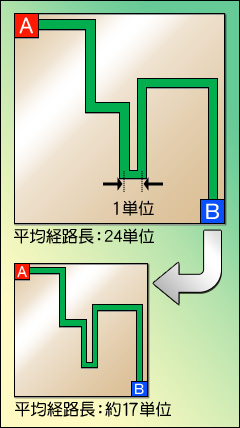 なぜ,プロセスが小さくなる(専門的にいうと「微細化する」)と動作クロックは向上するのだろうか。
理由は二つある。まず配線幅を微細化すると,配線経路自体を短くできるからだ。例えば図11左側のような配線があるとしよう。ここでは,A地点とB地点が緑の帯で示したような配線で結ばれており,1単位の長さを図内に示したようなサイズで規定すると,配線の長さは24単位分となる。
では,これを微細化してみよう。図11の下側は,上を70%に微細化してみたものだ。このとき重要なのは,配線の形は変わらなくても,サイズが小さくなったおかげで,配線長は約17単位(厳密には16.8単位)程度まで短くなることである。
一般に電流(というか,電子)の速度は,銅配線の場合は光速の3分の1程度=時速10万km程度と言われる。時速10万kmといえばすごく速いように思われるが,CPUの中では残念ながらそうではない。時速10万kmで進むということは,1ns(n=10のマイナス9乗)間に銅配線の中をたった10cmしか進めないことを意味するからだ。第1回で説明したように,この1nsというのは動作クロック1GHzにおける1クロック分の時間だから,数GHzで動作する最近のCPUからすると,それこそ数cm分にしかならない。それだけに,配線長はできる限り短くして,配線の中を進む時間を可能な限り短くしたい。だからプロセスを微細化するのである。
もう一つのメリットは,トランジスタ自体の高速化である。少々難しいが,ざっと説明しよう。最近のCPUに使われるCMOSとは,MOS FET(Metal-Oxide Semiconductor/Field Effect Transistor)というトランジスタをペアにして利用するものである。このFETは,G(ゲート),S(ソース),D(ドレイン)という三つの端子を持ち,G−S間に電圧(図12中では青い点線矢印)を掛けると,それに応じてS−D間に電流(図12中では赤い実線矢印)が流れるという働きをする(図12左側)。つまり,入力「電圧」で出力「電流」をコントロールできるわけだ。
このFETがどんな形でシリコン上に構成されているかというと,大まかに示せば図12右側のようなイメージになる。
図12 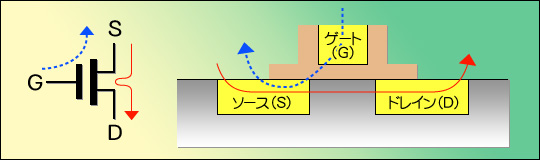
以前はトランジスタの物理的な寸法が大きかったから,トランジスタもスイッチング電圧(オンの状態とオフの状態の電圧の差)が大きなものが必要だった。というか,低い電圧では満足に動作しなかった。トランジスタの電圧は,図13のように,緩やかに変化するものなので,オフ状態(電圧がVoffより下回っている状態)からオン状態(電圧がVonより上回っている状態)に遷移するには,一定の時間がかかるのだ。ToffとTonの間の時間がそれで,これが「トランジスタのスイッチング時間」と呼ばれるものである。このスイッチング時間を短縮するには,急速に電圧を立ち上げればいいことになるが,信号が安定しないとか,消費電力が増えるとかいった問題もあって,そう簡単にはいかない。
だが,プロセスを微細化すると,トランジスタのスイッチングに必要な電圧が下がる。トランジスタの寸法が物理的に小さくなるから,それほど高電圧を掛けなくても動作するようになるのだ。電圧自体が下がれば,緩やかに立ち上がる場合であってもスイッチング時間は大幅に減らせるから,これによってスイッチング速度(一定時間の間に何回オン/オフを繰り返せるか)が増え,これはそのままCPUの動作速度上昇につながる,という理屈である。
図13 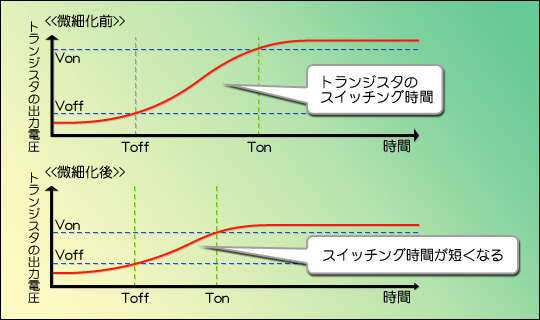
実のところ,プロセスの微細化がもたらす効果として一番大きいのは,このトランジスタの高速化だったりする。しかも,電圧の低下は消費電力の低下とイコール。このため,ある時期にはプロセスの微細化によって,「動作クロックが上がり,キャッシュ容量も増えながら,消費電力は下がる」という図式が展開したのだ。
表3は,はPentium II〜4の特徴をまとめたものである。「TDP」は「Thermal Design Power」の略で,日本語では「熱設計電力」と呼ばれる。簡単にいうと,機器設計者に対して「この発熱量があると考えなさい」という指針がTDPだ。Pentium IIIなら,31〜35Wの電球がPCの中に入っているようなものだから,これをちゃんと冷却しなさいよというわけである。実際のCPUの消費電力よりやや大きめの値だが,それでも一応の目安にはなる。少なくともPentium III世代では,動作クロックが倍近くなってもTDPはほとんど変わらないとか,動作クロックを上げても消費電力はむしろ下がるなど,非常によい成績を残しているのが分かるだろう。
表3 プロセスルールと消費電力の関係 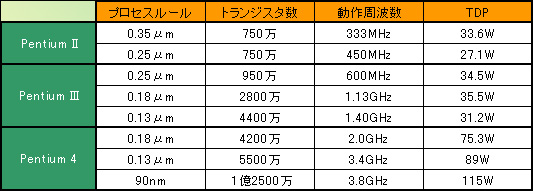
最近はこうしたプロセスの微細化による改良がうまくいきにくくなっている(Pentium 4などはそのいい例である)が,逆にAMDはAthlon 64で同じ90nmプロセスを使いながらどんどん消費電力を下げることに成功するなど,まるっきり打つ手がないわけではない。今後もさまざまな改良が見込まれているのがこの分野である。
CPUの最新トレンド
「マルチスレッディング」「マルチコア」
最近,CPUをめぐる話でほぼ確実に出てくる「マルチスレッディング」「マルチコア」についても説明しておこう。
またまたまたメイドさんにお出まし願うわけだが,執事の下に10人のメイドさんがいて,1チームになっているとする。年に一度の大掃除のときには10人がフルに活躍して邸宅中の窓ふきを一斉にするが,年がら年中忙しいわけではなく,普段の窓ふき要員は5〜6人もいれば十分としよう。このとき残る4〜5人は遊んでいるわけで,むだにお給金を払うことになる。しかし,だからといってメイドさんの数を減らせば,いざというときにまったく手が足りなくなるから,人員削減だけは絶対に許されない。
そこで発想を転換し,「別の清掃作業も一緒に行う」ことにする。普段はメイドさんが余っているのだから,その“余剰戦力”を,床掃除に振り分ければいい。それで,窓ふきが一時的に忙しくなったときは,床掃除要員をいったん呼び戻して作業させ,逆に床掃除が一時的に忙しくなったときは,窓ふき要員を何人か床掃除に回す。こうすれば,皆で一斉に窓ふきをし,それからまた皆で一斉に床掃除をするよりも,効率はかなりよくなる。この方式の場合,同時に忙しくなってしまったときには対応できないという弱点はあるが,そういう事態がめったに生じないなら,だいたいうまく行くはずである。
このように,複数の処理(ここでは窓ふきと床掃除だが,はたき掛けだってあるかもしれない)を1個のCPU(ここでは1人の執事と10人のメイドさん)で管理することを「マルチスレッド」(Multi Thread)処理という。そして,CPUがハードウェアレベルでマルチスレッドの処理に対応していると,「マルチスレッディング対応」と呼ばれる。マルチスレッディングにおいては,窓ふき単体の処理にかかる時間は,単一の処理を1個のCPUで管理する「シングルスレッド」(Single Thread)と呼ばれる状態と比べて大差ない。しかし,同時に余った演算器ではたき掛けも行うので,掃除トータルの処理時間は大幅に短縮される(=処理能力が大幅に向上する)という仕組みだ。
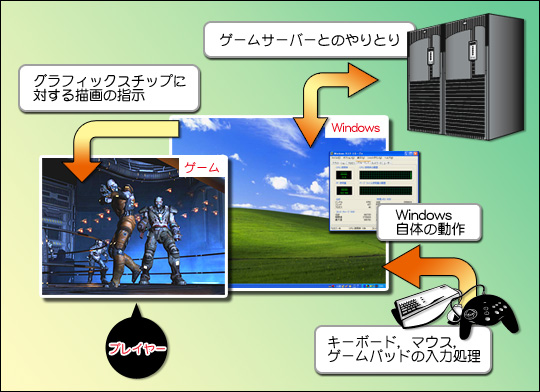
実際に最近のCPUの動作を考えると,複数の処理が同時に走る(=実行される)例は珍しくない。図14を見てほしいが,ゲームプレイ中もWindowsは常にバックグラウンドで動いているし,その上でネットワークやさまざまなドライバ類が必要に応じて稼働する。ゲームは当然Windows上で動いているから,「ゲームだけをやっている」というのは(見た目には正しいかもしれないが)現実にはそれほど正確な表現ではないことになる。
図14 プレイヤーにとってはゲームが動作しているようにしか見えない場合でも,その背後ではいろいろな処理が同時に動作している
図15 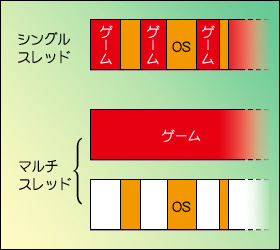 従来,こうした複数の処理は,シングルスレッディングで,短時間のうちに切り替えながら行われていた。イメージとしては図15の上のような感じである。実際には,この処理切り替えに要する時間はきわめて短いから,ユーザーが体感できるような機会はほとんどないが,それでも,それなりの手間がかかるのは事実。PC全体としては若干性能が落ち,結果として,ゲームの体感速度は下がり気味になる。一方マルチスレッディングなら,図15下のような作業の割り振りが可能になり,ゲームの体感性能はやや向上することになるわけだ。
こういった処理を示す用語は,実はスレッドのほかにも「プロセス」「ジョブ」「タスク」がある。何とはなしに聞いたことがあるという人も多いだろうが,実はそれぞれちゃんと意味がある。メイドさんの仕事で考えると,スレッドは具体的な「掃除の内訳」といったところだが,タスクだと「掃除」「洗濯」「料理」といった区分になる。「ジョブ」「タスク」も入れて,メイドさんの仕事で考えると,だいたい以下のようなイメージだ。
- タスク:「邸宅と蔵の面倒を見る」
- ジョブ:「邸宅の面倒を見る」「蔵の面倒を見る」
- プロセス:「邸宅の掃除」「邸宅の洗濯」「邸宅の料理」「蔵の掃除」など
- スレッド:「掃除」の内訳,「床掃除」「窓拭き」「はたき掛け」など
要するに,大きな目標としてのタスクがあり,ジョブ,プロセス,スレッドと進むにつれてどんどん細分化されていくわけである。
で,シングルスレッディング対応CPUの場合「はたき掛け」と「床掃除」は同時にはこなせない。したがって「物凄い勢いではたき掛けをし,それを終らせてからもの凄い勢いで窓拭きをする」か,「1分間たき掛けをし,次の1分間は窓拭き,その次の1分間はまたはたき掛け……と繰り返す」か,どちらかしかないのである。
ところがマルチスレッディング対応のCPUでは,「はたき掛け」と「床掃除」を,文字どおり同時に実行できる。あるメイドさんがはたき掛けしている間に,別のメイドさんが床掃除をするイメージである。
ただ一つ問題があって,マルチタスクやマルチジョブといった大きなレベルでは,プログラムを複数同時に動かすだけなのだが,マルチプロセスやマルチスレッドになってくると,動かすプログラムの中で明示的に処理が細分化されていなければならない。要するに,マルチスレッドを意識して作られていないプログラムは,シングルスレッドで動くから,マルチスレッディングに対応したCPUを持ってきても処理は速くならない。いろいろなプログラムがマルチスレッド対応になってこそ,マルチスレッディング対応のCPUが生きてくるのだ。
マルチスレッディング対応CPUの最も一般的な例としては,「Hyper-Threadingテクノロジ」(ハイパースレッディングテクノロジ,以下HTテクノロジ)対応のPentium 4がある。HTテクノロジでは,まさに複数のメイドさんが同時に動くように,複数のスレッドを同時に処理している。
この背景には,(これは第2章で説明するが)Pentium 4の効率が非常に悪いという問題がある。執事1人,メイドさん10人の例で説明すると,Pentium 4の場合,何も細工しないと働くメイドさんは常時3人くらいで,残りの7人は惰眠をむさぼっている。ここでHTテクノロジを使うと,常時5人くらい働くようになるのだ。「それでもまだ5人は寝てるのかよ!」と突っ込みが入りそうだが,このあたりは,全員を同時に働かせるというのはいろいろあって大変難しいと理解してもらえばいいだろう。
この考えをさらに進化させたのが「デュアルコア」,つまり2個のCPUコアを同時に働かせる仕組みである。「執事が2人,メイドさん20人」の構成にパワーアップし,2チームに分かれて作業を進めるのだ。言うまでもなく,これはCPUが2個あるのと同じことなので,同時にこなせる仕事量は2倍になる。
ただ,HTテクノロジと違って,CPUコア1個あたりの効率が上がるわけではない(20人のメイドさんは,10人ずつ各チームに配備され,人員の移動はない)から,効率の悪さ自体は解決しない。Pentium 4のコアを2個搭載したPentium DというCPUの場合,HTテクノロジは利用できないので,20人いるメイドさんのうち,働いてくれるのは3×2で6人。残り14人は寝ている計算になる。それでもHTテクノロジを利用したPentium 4の5人よりはちょっと速いというわけだ。
もっとも最大の問題は,CPUを事実上2個搭載したところで「ちょっと速い」程度でしかないことなのだが。
CPUの周辺にもシステム全体の性能に影響する
要素がある
図16 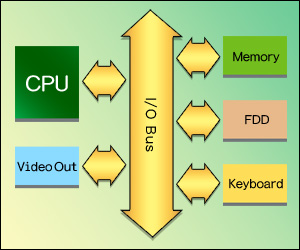 L2キャッシュがCPUの中に組み込まれていったように,CPUを取り巻く周辺環境も,時代とともに進化している。今回は最後に,この部分を簡単に押さえておこう。
初期のシステムは,図16のような構成をとっていた。CPUからは,「I/Oバス」(Input/Output Bus)と呼ばれるバス※へのインタフェースだけが用意され,バスの先にメモリや周辺機器が一緒にぶら下がっていたのである。当時はCPUの動作クロックが低かったから,これで十分間に合う状況だった。
その後――前述したように――CPUの高速化に伴って,メモリも高速化する必要が出てきた。しかし,周辺機器は別に高速化する必要がない。
そこで登場したのが高速バスだ。現在のPCの基になった「IBM PC/AT」というパソコンの機能をひとまとめにした「チップセット」(Chipset)と呼ばれる仕組みに,より高速な「システムバス」(System Bus)を制御するコントローラが組み込まれ,これ以降のチップセットは,このシステムバスコントローラを軸としたものとなった。
システムバスの代表格は,現在も使われている「PCIバス」(Peripheral Component Interconnect Bus)だ。PCIバス以降のチップセットは基本的に2チップ以上となり,CPUと直接接続するほうを「ノースブリッジ」(North Bridge),ノースブリッジを介してCPUと接続するほうを「サウスブリッジ」(South Bridge)と呼ぶのが一般的。構成は図17のとおりで,これが現在使われているチップセットの原型となっている。
ノースブリッジはキャッシュやメインメモリグラフィックスカードなど高速なデバイスを,サウスブリッジにはHDDやUSB,LANやそれこそキーボード/マウスといった,相対的に低速なデバイスをそれぞれ接続する構造だ。ちなみに図17では,チップセットとキャッシュが接続されているが,この仕様がすでに廃れているのは前述のとおり。ノースブリッジとサウスブリッジの間はPCIバスで接続されているが,これも現在では,より高速なバスが利用されている。バスの詳細については第2章で解説するので,ひとまずはそういうものだと思っていてくれればいい。
図17 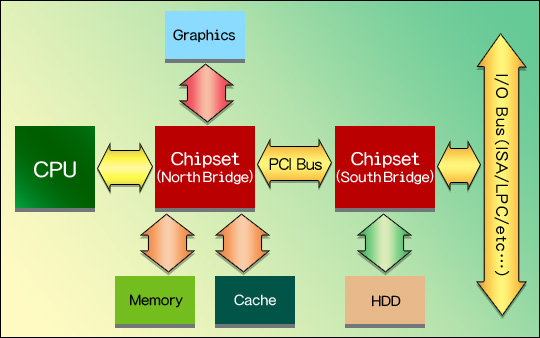 ※複数の周辺機器(デバイス)間で相互にデータをやりとりできるよう,PCのシステム内に用意された経路。さまざまな人が乗り合う路線バスの“バス”をイメージするといいだろう
- 1.CPU処理の高速化には,記憶装置の高速化が必須
- 2.CPU用の記憶装置としては,レジスタ,キャッシュ,メモリがあり,CPU処理の高速化にとって最も影響力があるのは,現在ではCPUダイの中に入っているキャッシュである
- 3.「xxμm」とあるのは製造プロセスのことで,この値が小さいCPUほど,高速化しやすい。理由は,配線長が短くなることと,トランジスタが高速化すること
- 4.複数の処理を1個のCPUでまかなうことをマルチスレッドという。現在のWindowsでは,複数の処理が同時に動くことが多いので,マルチスレッドに対応したCPUのほうが全体の処理効率は上がる
- 5.マルチスレッドに対応する例としては,2005年9月現在,Hyper-Threadingテクノロジとデュアルコアがある。前者は,CPUコアの処理効率を上げる技術,後者は,CPUコアの処理効率はそのまま,コアの数を2個にしたものだ。同じCPUコアで比較すると,デュアルコアのほうが若干効率はいい
- 6.グラフィックスカードやHDDなどの周辺機器とCPUは,バスとチップセットを介してつながっている。このため,バスの速度とチップセットの性能が,PC全体の速度に影響する。チップセットは基本的にノースブリッジとサウスブリッジがあり,前者にはCPUやグラフィックスカードといった高速な機器,後者にはHDDやキーボード,マウスなどの低速な機器がつながる。
第1章の最後となる次回は,これまでを踏まえつつ,「CPUが速い」「ゲームが快適」とはどういうことなのかを考えていこう。
|