 Text by 大原雄介
ここまで2回にわたって,メイドさんの助けを借りながら(?)CPUやCPUの周辺がどうなっているのかを解説してきた。そこで今回は,あえてメイドさんにお出まし願わず,4Gamerの読者にとって「CPUが高速である」とはどういうことなのかをまとめてみよう。
さて,すでに第1回と第2回をお読みいただいたことを前提として振り返ってみると,要するにCPUの仕事というのは,データの加工と処理である。以下の(1)〜(3)ができるCPUなら「高速である」といえるわけだ。
- (1)データを高速に読み込む
- (2)読み込んだデータを高速で処理する
- (3)処理が終ったデータを高速で書き戻す
加えていえば,CPUが処理を行うためには,ゲームやWebブラウザなど,CPUが何を処理するかが書かれた「プログラム」が必要になる。よって,以下の2点を高速に処理できるかどうかも,CPUには求められている。
- (4)プログラムを高速で読み込む
- (5)読み込んだプログラム(=命令)を高速で解釈する
このうち,(1)(3)(4)は,第2回で解説したように,CPUそのものというよりは,外的な環境(=CPU周辺の環境)によって決まる部分である。「いかにメモリと高速にデータのやりとりをするか」が重要だ。このため,CPUはバス速度を上げる方向で常に進化してきた。表1は主要なCPUのバスについてまとめたものだが,Pentium II時代に66MHz程度の動作クロックだったバスは,2005年現在,10倍以上高速になっており,データを1秒間にどれくらい転送できるかを示す「帯域幅」も,やはり10倍になっていることが分かる。
表1 主要なCPUのバス 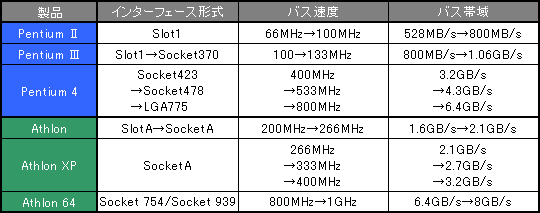
そういうわけで,純粋にCPU“だけ”が高速かどうかを語る場合,注目すべきは(2)と(5)になる。そこでまずは,(5)の「読み込んだプログラム(=命令)を高速で解釈する」について,もう少し掘り下げてみよう。
CPUの命令処理性能は,一般に以下の式で求められる。
命令処理性能 = 1サイクルの間に処理できる命令数×動作クロック
Performance = IPC(Instructions Per Cycle) × Frequency
これはメイドさん……ではなく,自動車のエンジンで想像すると分かりやすいかもしれない。自動車には,トラックのように「重い荷物を運ぶタイプ」とレーシングカーのように「スピードを出すタイプ」がある。それに応じてエンジンにも,最高速度は大したことないが重い荷物を載せてもある程度の速度を維持できるタイプ(トルク型)と,重い荷物を載せると性能がガタ落ちになるもののスピードを出しやすいタイプ(高回転型)があり,乗用車はこの中間に位置する。乗用車というのは,言ってみればスピードが“そこそこ”に出せて,かつ荷物も“そこそこ”積めるという,バランスを重視した車種なのである。
ところが性能競争が激しくなってくると,従来と同じ発想で性能を全体的に引き上げていくのが難しくなるし,おまけに「ちょっと」の向上ではあまりアドバンテージにならなくなってくる。例えば,荷物を積むのはきっぱりあきらめる代わりに「ものすごくスピードが出ます」とか,逆にスピードは放棄する代わりに「ものすごくいっぱい荷物が積めます」とか,メリハリを持ったエンジンが,かえって尊ばれることもあり得るわけだ。
現在のCPUは,まさにそうした状況にある。「何でもそこそこできます」というCPUでは性能が頭打ちになってきており,1サイクル当たりで処理できる命令数(以下IPC)を上げるか,動作クロックを上げるかという割り切りが必要になってきたのだ。
「では,どちらを取るか?」これが,次にやってくる問題である。
IPCを選択すると,とにかく同時に多数の命令を処理できるような仕組みが必要になる。ここで役に立つのは,まず第1回で説明したスーパースカラである。スーパースカラの場合,複数の命令を同時に実行させるというやり方で,IPCを向上させられる。
図1で見てみよう。単純な実行ユニットが一つだけのパイプライン(1クロック間に実行できる命令は一つなので,IPC=1)を,実行ユニットを三つ持つスーパースカラに変更すると,IPCは最大3になる。さらに,よく使われる整数演算やロードストアを一つずつ強化してスーパースカラ化すると,IPCは最大5まで引き上げられることになる。
図1 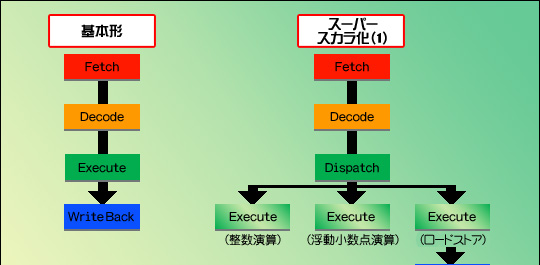 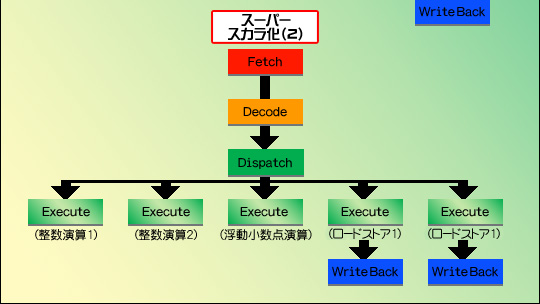
さて,ここで「最大3」とか「最大5」といったように,「最大」としているのにはワケがある。この最大値はあくまで理想的に事が運んだ場合の値であって,実際にはなかなかそこまで上がらないのだ。
例えば図1右上の構成で,IPCが3になるためには,プログラムも図2のように,きれいに並んでいる必要がある。
図2 
しかし,実際には(あくまで例だが)図3のようなイメージになっているのが普通だ。
図3 
要するに「すべての実行ユニットが常に利用できる状態にある」とは限らないのである。
IPC重視で進化している代表的なCPUは,AMDのAthlonやAthlon XP/64で,とくにAthlon 64ではIPCが3にかなり近いところまで引き上げられているといわれるが,これですらピーク値での話。通常は1〜1.5,条件がよければ2程度といったところだ。
この方針を採るCPUにおいては,IPCをさらに引き上げるため,2005年秋時点では命令変換とアウトオブオーダーを併用するのが必須条件となっている。
図4はその一例。単にスケーラを搭載しただけでは,命令はユニットから次のユニットへと順番に流れていって実行されるだけなので,実行ユニットを分けてもあまり意味がない。ところが,実行順を任意に変えられるアウトオブオーダーを採用すると,図5のように,13サイクルかかっていたものが6サイクルで済むなど,効率的に処理できるというわけである。
図4 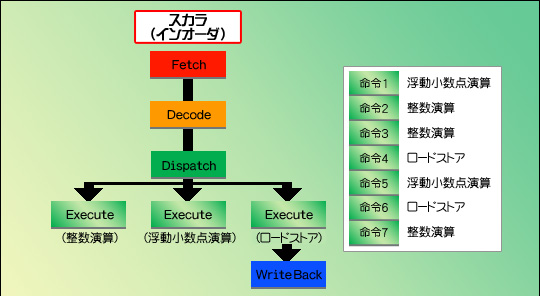 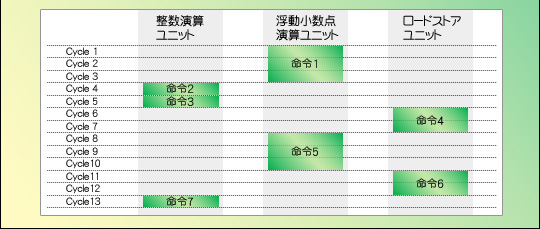 図5 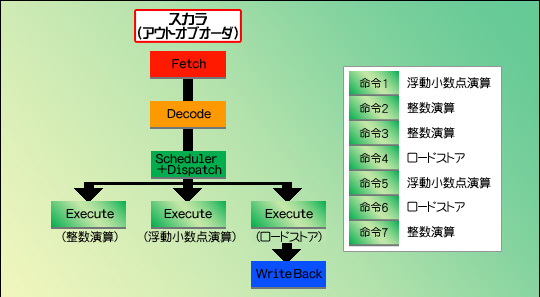 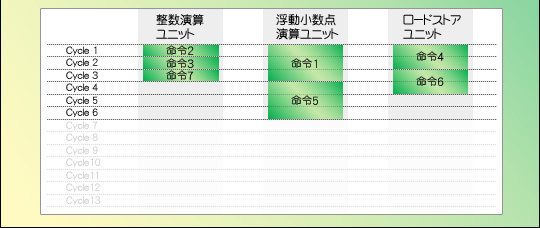
一方,動作クロックを上げるにはどうするか。これは第2回で述べたように,ひたすらパイプライン段数を増やすのが得策といえる。
この方向性の代表であるPentium 4だと,実際にパイプラインは31段というところまで膨れ上がっている。これは,設計段階で5GHzの実現を念頭に置いた結果だそうだ。ただ,ここまで段数が増えると,分岐ミスによるパイプラインハザードの影響が非常に大きくなるので,分岐予測をひたすら強化し,効率を落とさないようにするというアプローチが必要になってくる。
結局,どちらのアプローチがより好ましいかは一概にいえない。というのも,この問題は冒頭で述べた(2),すなわち,読み込んだデータを高速で処理することとも関連するからだ。
命令と違い,データのほうは条件分岐も何もないわけで,ひたすら読み込んで処理して出力ということになる。ちなみに,CPUのデータ処理能力は以下の式から計算可能だ。
データ処理性能 = 1サイクルの間に処理できる命令数×動作クロック
Performance = DPC(Data Per Cycle) × Frequency
命令処理性能と同じ形なので想像できると思うが,つまりは1回に扱えるデータの数を増やすか,動作クロックを上げるかすれば,データ処理性能は向上するわけである。
しかし,データの数をむやみやたらに増やすわけにはいかない。これはプログラムの互換性に関係してくるからだ。勝手に拡張すると,旧来のプログラムとの互換性がなくなってしまう。端的に言えば,今のx86プロセッサの唯一のアドバンテージは互換性なわけで,これを失ったら誰もついてこなくなる。プレイステーション → プレイステーション2 → プレイステーション3で同じゲームが動作するとか,Xbox360が何とかXboxとの互換性を保とうと努力するといった話は聞いたことがあると思うが,これはPCの世界でも同じことなのだ。
したがって,データ処理速度を上げるには,やはり動作クロックを上げるのが得策ということになる。
かくして,命令の処理速度とデータの処理速度の両方を勘案して,「どのアプローチが最適か」が決定されるわけである。2005年秋時点で主流となっているPentium 4,Pentium M,Athlon 64という3製品で比較すると,だいたい以下のような傾向になっている。詳細は第2章で解説するので,ここでは,大まかなイメージを掴んでもらえればOKだ。
Pentium 4:動作クロック最重視。そもそもデザインの段階で,命令の処理能力だけでなく,データの処理能力を高めることも重要視した形跡がある。発表当時,プレスリリースには「マルチメディア時代を迎え,PCに求められるデータ処理能力はさらに高くなるだろう」といった文言が躍っていた。つまりIntelは,命令処理能力とデータ処理能力の両方を引き上げるためには,動作クロックを上げるしかないと判断し,それに合わせてIPCの追求をほどほどにするとか,パイプラインハザードを最小限に抑えるといった個別の設計目標が打ち出されてきたようだ。
Pentium M:IPC最重視。とにかく「動作クロックを上げずに,いかに性能を上げるか」に注力された設計で,キャッシュミスを減らすとか分岐ミスを最小限にするとかいった,「IPCを引き上げる」というより,むしろ「IPCを落とさない」設計が特徴的である。
Athlon 64:IPC重視。Pentium Mほど特化した設計はなされていない。もちろん,Pentium Mと同様,IPCを落とさないための設計部分も見受けられるが,全体的には「IPCを引き上げる」方向のアプローチだ。また,Pentium 4ほどではないが,動作クロックも重視するなど,結果としてPentium 4とPentium Mの間に位置する設計になっている。
コラム:対応プログラムなら有効なCPU拡張命令
ここまで述べてきた原則にも例外はあって,それがMMX,SSE,SSE2,SSE3,3DNow!,Enhanced 3DNow!,3DNow! Professionalなどの拡張命令である。表2に,拡張機能それぞれの特徴をかいつまんでまとめたが,これらの命令を使えば,1回で複数のデータに対して同じ処理を適用できる。この方式をSIMD(Single Instruction, Multiple Data)と呼ぶが,これらはあくまでx86命令の拡張という扱いなので,すべてのx86命令を置き換えられるわけではない。また「あるCPUはこれをサポートしているが,別のCPUはサポートしていない」といったことも多いので,世の中にあるすべてのプログラムがこれらを活用しているわけではない。単純にCPUの性能とは見なしにくい要素である。
表2 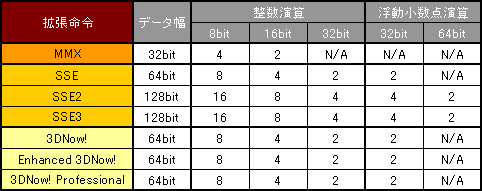
さて,ここまではCPUの性能をいかに引き上げるかという方法論の話に終始してきたので,このあたりでここ1年ほど深刻な課題となっている「CPUの高性能化を阻害する要因」について,少し書いておきたいと思う。表面的な問題を言えば,それは「発熱が多すぎる」ということだ。
まずは少々基礎知識を。最近のCPUはほとんどが「CMOS」と呼ばれるプロセスで製造されている。CMOSとは,MOS FETというトランジスタをペアにして利用するものであり,このFET(Field Emmition Transistor,電界効果トランジスタ)というのがCPUの構造の原点である。FETはG(Gate,ゲート),S(Source,ソース),D(Drain,ドレイン)という三つの端子を持ち,G-S間に電圧をかけると,それに応じてS-D間に電流が流れるという動きをする(図6左側)。
図6 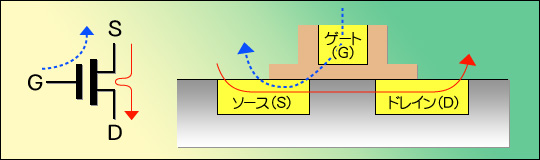
入力「電圧」で出力「電流」をコントロールできるというのが,ここでのポイントだ。論理回路では,0か1かという状態を保持する必要があるが,FETを使った場合,例えば0を0V,1を5Vと決めてしまえば,この時点で実際に電流を流す必要はない。FETを使って論理回路を構築するケースでは,電流が流れるのは状態が変わるとき(0→1,あるいは1→0)のみとなっている。
さてこのFETは,シリコンの上に図6右側のような構造で構築されている。G-S間に電圧をかけると先ほど書いたが,ここは絶縁構造なので非常に抵抗値が高い。オームの法則では以下のようになっているため,電圧(E)が一定で抵抗(R)がものすごく大きな値ならば,流れる電流は非常に少なくなるのである。
E = I × R → I = E ÷ R
(電圧 = 電流 × 抵抗 → 電流 = 電圧 ÷ 抵抗)
そして,消費電力は下に示すとおり電圧×電流で表されるから,電流が少なくなれば消費電力も小さくなるのだ。
W = E × I
(消費電力 = 電圧 × 電流)
ところで,半導体であるFETの性質上,S-D間は一度電流が流れ始めると,抵抗値は極めて小さくなる(それが「半」導体というものである)。なので,消費電力を求めるこの式に,先ほどのオームの法則を突っ込むと,以下のような式になる。
W = (I × R) × I = I2 × R
(消費電力= 電流2 × 抵抗)
要するに,抵抗(R)が限りなく0に近くなると,その場合も消費電力は0に近づくわけである。
ただ,どちらの状態にしても,「0に近い」≠「0である」というのが難しい部分だ。そもそも完全に0なら,トランジスタは動作するに当たって電気を食わないはずだが,実際にそれが可能なのは超伝導の世界だけで,通常は多少なりとも消費電力が発生する。
そして消費電力が何に変わるかというと,大半が熱になるわけだ。これは別に半導体に限った話ではない。モーターにせよ電球にせよ,とにかく電流が流れるところ熱は必ず発生する。常温超伝導体でも登場しない限り,今のところ発熱は避けようがなく,結果として発熱はトランジスタの動作(=CPUの動作)につきものの現象となっている。
これまでのCPUで発熱がそれほど大きな問題にならなかったのは,「電流が流れるのは状態変化時だけ」だからだ。そして,変化が生じる頻度はCPUの動作クロックに比例するので,結果として消費電力と発熱も動作クロックの上昇に比例して増えていく傾向にある。
とはいえ,第2回で書いたように,プロセスルール(CPU製造時の配線間隔)を縮小していくと,より低い電圧でトランジスタが動作するようになる。ある程度電流が流れても,電力は小さいままに保てるのだ。だから,これまで問題にならなかったのである。
ここでまた理科の時間。まず,繰り返しになるが,消費電力の計算式は以下のとおりだ。
W = E × I
(消費電力 = 電圧 × 電流)
これに,先ほどと同じようにオームの法則を当てはめると,電圧を下げることのメリットはぐっと分かりやすくなる。
W = E × (E ÷ R) = E2 ÷ R
(消費電力 = 電圧2 ÷ 抵抗)
つまり,電圧を下げれば,その下げ幅の二乗に比例して電力が下がる。結果として発熱も減らせるのだ。
この好循環は,0.18μmプロセスあたりまではほぼ問題なく成立してきた。消費電力をそれほど変えずに速度を上げられたのだ。第2回の表2で示したとおり,Pentium IIIはTDP(Thermal Design Power:熱設計電力,ここでは消費電力とほぼ同義)をほとんど変えずに動作クロックを上げてこられたわけだが,それはこの,プロセスルールの微細化によるところが大きい。
だが,0.18μmプロセスを超えたあたりから,この好循環が成立しなくなってきた。それは,「リーク電流」という新たな要因が出てきたからである。日本語で書けば「漏れ電流」であるが,要するにトランジスタが動いていないときでも,図7のようにあちこちから電流が漏れて,流れてしまう現象である。トランジスタが動作していない(スイッチがオフになっている)ときにも電流が流れてしまう。つまり,本来流れないはずのところへ電流が流れてしまうのだ。そして,電流が流れてしまうから,消費電力は(設計者が想定したよりも)はるかに大きくなるというわけである。
図7 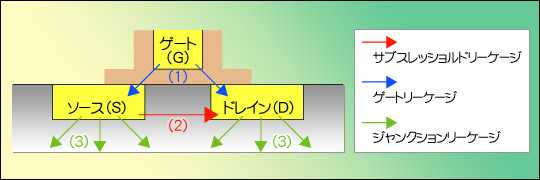
理由そのものは単純で,プロセスの縮小によって配線同士の距離が縮み,絶縁が十分でなくなってしまっているため。だからといって厚みを増したらトランジスタのスイッチング速度が落ち,今度は動作クロックを上げられなくなる。
身の周りにあるものにたとえて説明するなら,ちょうど水道のパッキングみたいなものだ。パッキングを厚くすれば水が漏れる心配はなくなるが,開け閉めに力がいるため,時間がかかる。では,とパッキングを薄くしていけば,次第に水が漏れ始め,限度を超えて薄くすると,パッキングが水圧に負けて水がダダ漏れになる。現在のプロセスルールでは,まさにこのダダ漏れ状態が発生してしまう場合があり,このリーク電流が,トランジスタの高速化に「待った」を掛けた形になってしまったのだ。
リーケージ(Leakage:リークすること=漏れること)には大別して3種類あり,それぞれ,以下のように呼ばれている。
- (1)ゲート絶縁膜からのリーク(Gate Leakage)
- (2)ソース→ドレインからのリーク(Subthreshold Leakage)
- (3)ソース/ドレイン自体からのリーク(Junction Leakage)
リーケージ自体は以前から知られていた話である。G(ゲート)に制御「電圧」をかけると,それに応じてS(ソース) → D(ドレイン)方向に電流が流れる……ここで重要なのは,G/Sの間には理論上電流が流れないことだ。もちろん実際には完全に0というわけにはいかないが,FETのG/S間の抵抗は非常に高いので,無視しうる程度の大きさに収まってきた。
現在問題になっているのは(2)のサブスレッショルドリーケージ(Subthreshold Leakage)であるが,この先さらにプロセスルールが微細化していくと,今度はGate Leakage(ゲートリーケージ)やJunction Leakage(ジャンクションリーケージ)のほうが問題になると予測されており,メーカー各社ともにこれを減らすためのさまざまな技術開発にいそしんでいる。
そんななか,「この問題にいつ対処しなければならないか」というタイミングを完全に見誤ったのがIntelである。Pentium 4の場合,0.13μmプロセスにおけるリーク電流は全体の10%程度に収まっていたため,それほど積極的な対処をする必要がなかった。それゆえIntelは「90nmプロセスにおいてもその延長で大丈夫」という見通しを立て,リーク電流に本格的な対処が必要なのは65nm世代からと考えていたのだ。
ところが,90nmプロセスではリーク電流の割合が30〜50%という値を示し,このまま動作クロックを上げていったら全然シャレにならないことが「作ってしまってから」判明してしまった。
CPUが消費する電力はマザーボードから供給されるので,その電力が大きければ,マザーボード側でそれに見合うだけの電力を供給しなければならない。加えて,消費した電力の大半は熱の形で放出されるから,この熱をきちんと受け止め,排熱/拡散してやらないとCPUの温度がどんどん上がって,最後にはCPU自体が破壊されてしまう。したがって,マザーボードの電力供給回路を強化するとともに,発熱対策を充実させないと,PCのコアパーツとしてまともに使えないわけだ。
 PrescottコアのPentium 4では,負荷の低いときには動作クロックを下げて,消費電力と発熱を減らす「拡張版Intel SpeedStepテクノロジ」を途中から搭載したが,圧倒的な消費電力の大きさを前にして,効果はほとんどなかった
4GHz超えを目指したPrescottコアのPentium 4は,あまりにも消費電力が大きすぎ,しかもこれにまつわるさまざまなトラブルが噴出したため,動作クロックを3.8GHzで打ち止めとせざるを得なかった。しかも,このPrescottコアに続くPentium 4として開発していたTejasというコア(より高クロックで動作し,さらにHyper-Threadingテクノロジを強化した製品)をキャンセルせざるを得なくなったのである。
で,キャンセルしてみたら「次がない」という問題に直面し,急きょ登場させたのが“Pentium 4のコアを2個くっつけた”デュアルコアのPentium D,開発コードネームSmithfield(スミスフィールド)と呼ばれていた製品である。このPentium Dに続いて,さらに65nmプロセスルールに縮小したPreslerというCPUが,同じPentium 4(というか,Pentium D)の路線で登場するところまでは確定しているが,おそらくPentium 4の系譜を引く製品は,このPreslerで打ち止めになるだろうと見られている。
Intelが直面した“打ち止め”は要するに,動作クロック重視の考え方が行き詰まったことを示している。
ここで再びエンジンの例を持ち出すと,高回転型エンジンはレースなどでよく使われるものの,一般車にはほとんど使われていない。その大きな理由は,性能を引き出すのが難しいからだ。高回転型エンジンは常時高回転で廻さないとパワーが出ないが,都市部をのろのろ走っているときに「エンジンを高回転で廻せ」というのは非効率である。
また,エンジン各所の劣化が激しいのも欠点といえる。回転数が高いから機構的に壊れやすく,頻繁にオーバーホールを行わないといけないとか,エンジンオイルがすぐ劣化するとかいった欠点も持ち合わせている。さらに細かいことをいえば,発熱が多い,燃費が悪いという問題もあり,少なくとも日常用途にはろくなことがない。
やや強引だが,これはCPUにも当てはまる話だ。クロック重視のCPUは性能を引き出すのが難しい。キャッシュミスを最小限に抑え,メモリの帯域幅は十分に確保し,かつパイプラインストールなどが発生しないようにしないと,さっぱり性能が出ないのである。
動作クロックが高い関係で「性能は低いが長持ちする」部材は使えないし,高クロックゆえに発熱と消費電力は多くなる。結果として,AMDのAthlon 64やIntelのPentium Mなど,車とエンジンでいえば積載量勝負の高トルク型,つまりIPC重視型が,最近では注目されている,もっといえば生き残る結果につながったというわけだ。
また,ここまでの経緯には「Intelが思ったほどに,データの量は多くならなかった」という要因も絡んでいる。データの量が多い処理というのは,例えば動画のエンコードとかトランスコードとかいったものだ。こうした用途に限っていえば,相変わらずPentium 4シリーズは圧倒的に高速である。
ところがゲームや一般的なWindows操作だと,データの量はそれほど多くなく,むしろ処理の仕方が毎回変わるパターン,つまり単純なデータ処理では済まないパターンが多いのだ。
ゲームで考えてみよう。敵AIのキャラが数万体あって,これが独立して勝手に動いていれば,大量のAIというデータを処理するわけだから,明らかに「データ量が多い」といえるレベルである。が,そんな作りのゲームには今のところお目にかかったことがなく,多くて数十体程度。100体を超えるようなパターンはまれである。
ここで「MMORPGは?」と思った人はいるだろうが,あれはまた話が別。大人数PvPなどを謳うMMORPGだと,同時に100を超えるプレイヤーキャラクターが登場することも珍しくないが,この場合,プレイヤーキャラクターの処理は,ネットワークでつながったそれぞれ別のPCや,ゲームサーバー側で行われている。自分のPCで処理すべきAIの数はそれほどなく,結果としてデータ量は大して多くないのだ。
ゲームの将来という話をすれば,次第にデータ量が多くなる傾向にあるのは間違いない。例えば現在のFPSで,壁面や床にある細かな凹凸はテクスチャで実現されている。凹凸があるように見えても,そこには巨大な1枚のポリゴンに,凹凸を表現するテクスチャが貼られているだけだ。だから,壁の凹凸具合と衝突したときの勢いによって,ダメージが違ったりするようなことはない。
しかし,今後リアリティが追求されていくと,壁面の凹凸をきちんとデータで持ち,細かな衝突シミュレーションを行って,その結果に応じてダメージが決定される(でこぼこの床で転ぶと大きく擦りむける,とか)なんてことが起こりうる。そして,それに必要なデータの計算量たるや,現在とは比較にならないだろう。
  NVIDIAのデモ「Luna」より。奥の壁は立体的で凝った印象だが,実際にはテクスチャを貼り付けてあるだけの“1枚板”だ
 NVIDIAのデモ「Nalu」より。本物の髪と比べると,水の中における髪の動きが単純化されている あるいは最近,グラフィックスカードのデモに必ずといっていいほど出てくる,人の髪の表現で考えてみよう。今のところ髪1本1本の運動方程式は割とおおざっぱなため,動きはあまり自然でない。これは,髪の毛1本単位で空気抵抗まで考えて運動方程式を解いていたら,その処理が重すぎて,グラフィックスのデモにならないからだが,ゲームにさらなるリアルさが求められるようになれば,髪の毛の計算量一つ取っても大幅に増えるはずだ。
PCの能力が上がって用途が広がり続ける以上,“いつか”はデータ量の爆発が起きる。これはまず間違いないところだろう。しかし,それが向こう1〜2年の間に起こるわけではないように思える。
筆者個人としては,こうした爆発が起きるのは(=爆発させることで意味のある表現や用途が実現する見込みが出てくるのは),CPUの数がもっと飛躍的に多くなってからだろうと思う。つまり1個のCPUパッケージに複数のCPUコアが入り,しかもそうしたCPUがネットワーク経由で連携して動く,疎結合のクラスタが実用的になってからではないかと考えている。それまでのうちは,あまりデータ量の爆発を考える必要はない。したがって,とくに4Gamer的には,「高速なCPU」=「命令処理性能の高いCPU」と考えておいて間違いではないように筆者は思う。(※)
※例外が動画のエンコード,というのは上でも述べたとおりだ。
- 1.CPUの性能は,「1サイクルの間に処理できる命令数×動作クロック」で求められる。1サイクルの間に処理できる命令数のことは「IPC」という。
- 2.CPUの消費電力と発熱は,同じプロセスルールであれば,動作クロックが上がると比例して増えていく。一方,プロセスルールが微細化すると,より低い電圧で動作するようになるので,消費電力と発熱を小さいまま保てるようになる。
- 3.しかし,0.18μmよりもプロセスルールが微細化するころになると,リーク電流が大きくなり,それが原因で消費電力と発熱も増加。プロセスルールの微細化によるメリットがあまり受けられなくなってきた。
- 4.Intelは,動作クロック重視でPentium 4やPentium Dを開発したため,消費電力と発熱の問題をマトモに食らってしまった。このためIntelは2006年以降,IPC重視で開発されたPentium M(とその後継)を主力のCPUとする予定である。AMDのAthlon 64もIPC重視だ。
- 5.データ処理能力が必要となるのはまだ先。その意味で「ゲームで高速なCPUとは,命令処理性能の高いCPU」と理解しておくといい。
CPUという存在についての説明が一段落したので,次回からは,CPUのシリーズごとに,その具体的な特徴を見ていくことにしよう。
| 








