Text by 大原雄介
PCに詳しくなくても,4GamerでPCゲームの情報を仕入れているような人なら,知らぬ者はないと思われるのが「Pentium 4」というCPUだ。2006年4月時点で最も市場シェアが高く,かつ最も広範囲で利用されている一方,最近ではいろいろ無理が出てきてしまい,次第に敬遠されつつあるのが現状だったりするPentium 4。今回は,このPentium 4というCPUについて考えてみたい。
Pentium 4を読み解くうえで,重要なキーワードになるのが,「NetBurst(ネットバースト)マイクロアーキテクチャ」である。
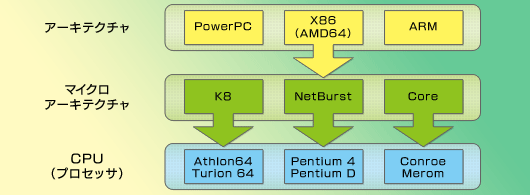
よくIT系のニュースで出てくる「マイクロアーキテクチャ」(Micro Architecture)。これは一言でいうと「設計思想」みたいなものだ。あるCPU(プロセッサ)を製造するに当たっては,より大きな設計思想「アーキテクチャ」があり,それに基づいてハードウェアを開発するためのマイクロアーキテクチャが作られる,といったイメージになる(図1)。
図1
IntelやAMDのCPUは「x86」というアーキテクチャに基づいて作られている。だからPentium 4でもAthlon 64でも同じWindows XPが動作するのだ
では,NetBurstというマイクロアーキテクチャにはどんな思想があるのかだが,答えは単純明快で,ズバリ「いかにして動作クロックを上げるか」である。
なぜ動作クロック偏重なのかというと,これには少し昔話が必要になる。20世紀も終わろうとしていた1998年〜2000年にかけて,IntelとAMDは激しいクロックアップ競争をしていた。そして,2000年3月6日,AMDが先にAthlonで動作クロック1GHzの“大台”突破を発表ベースで果たしたのだ。それから2日遅れてIntelもPentium III/1GHzを発表したが,実際の市場投入もAthlon/1GHzのほうが早く,Intelは1GHz到達競争で完全に敗北した格好になった。
もちろん,それが理由のすべてではないだろうが,負けるのが嫌いなIntelは,動作クロック競争で絶対に負けないため,5GHzあたりの動作クロックを実現するマイクロアーキテクチャを開発しようとしたのだろう。その結果として,NetBurstでは,通常なら1段でまかなえるようなところも4段に分割するなど,極端なスーパーパイプライン化を行った。Intelはこれを「ハイパー・パイプライン」と呼んでいるが,その結果生まれたのがPentium 4なのである。
Pentium IIIで10段だったパイプラインは,初期のPentium 4で20段。しかも,Pentium 4ではフェッチ(Fetch)とデコード(Decode)のパイプラインと,エグゼキュート(Execute)以降のパイプラインとが分離しており,エグゼキュートだけで20段だ。パイプラインの段数は単純計算でPentium IIIの倍以上になったといえる。
久しぶりにメイドさんにお出ましいただくと,「これまでメイドさん10人で作業していたが,仕事のスピードを10倍にするため,メイドさんの数を100人にしたいと考え,そのためにメイドさん100人を収容できる宿舎の建設構想を立てた。ただ,さすがにいきなり100人分の宿舎というのは土地面積的な問題などいろいろ難しかったので,建築技術などがいずれ向上することを期待しつつ,ひとまず20人分の宿舎を作って20人雇った」といったところだろうか。
そして,せっかく20人雇ったので,目玉焼き一つ作るのでも,これまではメイドさん一人で作っていたところを,「一人が冷蔵庫から取り出し,一人が卵を割ってフライパンに落とし,一人が焼き,一人が皿に盛りつけ,一人が配膳する」といったような分業制を敷くことで,メイドさん1人当たりの作業量を減らして高速化を図った,といった感じである。
ただこのとき,まだ焼き作業が終わっていないのに,次の卵をフライパンの上に落とすわけにはいかない。このように,メイドさんの作業(=パイプライン1段)には,1クロックという一定の時間がかかるのだ。
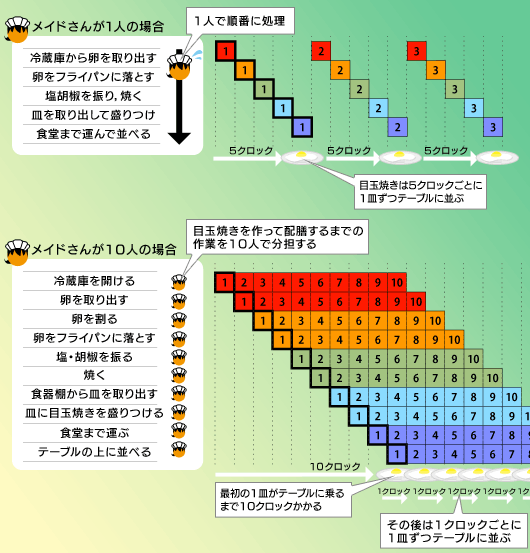
メイドさん1人で目玉焼きを1個作るのに,5クロックかかったとしよう。この状態でメイドさんを10人に増やす(パイプラインを10段にする)と,10人それぞれが作業に1クロック要するので,作業時間は10クロックになってしまう。
一方,1度に100個の目玉焼きを作る場合,1人で作業する場合は5×100で500クロックかかるのに対し,10人がかりだと,最初の1個が出てくるまでには10クロックかかるものの,それ以降は1クロックごとに目玉焼きがテーブルに並ぶから,109クロックで作業は完了することになる。これが,パイプラインを増やすメリットだ。
ただし,途中でメニューがスクランブルエッグに変わってしまうと,また,最初の10クロック待たねばならない。これがパイプラインを増やすことのデメリット(「ペナルティ」)である。
このあたりは第1回の復習になるが,重要なので改めて図2に示してみた。パイプライン段数を増やしたPentium 4には,こういうメリットとデメリットがあることを理解しておきたい。
図2
パイプラインが増えると,一度に同じ命令が繰り返されるようなとき,最大の効果を発揮できる。ただし,途中で命令が変更されると,結果が出るまで,また改めて一定クロック待つ必要が生じてしまう
先ほど「フェッチとデコードがエグゼキュート用のパイプラインと分離された」と書いたが,この部分について,もう少し詳しく説明しよう。先にフェッチとデコードについて説明したのはだいぶ前になってしまったので,忘れている人は第1回を読み直してほしい。
さて,フェッチによってメモリから読み出される命令は,Pentium 4(や,本誌読者が利用するCPU)では「x86命令」と呼ばれる。先ほどの図1に出てきたアーキテクチャの「x86」だ。
このx86命令はCPUが実行しやすい方法にデコードされるわけだが,このときデコードされたものを「μOp」(Micro Operation,マイクロオペレーション)という。そして,多くのCPUはx86命令をそのまま実行するのではなく,μOpをエグゼキュート(実行)するようになっている。
μOpの実行に当たって,極端なスーパーパイプライン化がなされているPentium 4では,どうしても(これまた第1回で説明した)分岐ミスがつきまとう。そこで,分岐ミスによってパイプラインハザードが発生し,パイプラインの流れが停止(これを「パイプラインストール」という)したときに,すぐまたパイプラインを流すため,Pentium 4では「トレースキャッシュ」(Trace Cache,「実行トレースキャッシュ」ともいう)という仕組みを,L1キャッシュの中に,一般的なデータキャッシュとは別に用意している。
トレースキャッシュのサイズは12KμOps。そう,トレースキャッシュは,μOpを保存するためのメモリ領域なのである。
トレースキャッシュにμOpを置いてあれば,同じ命令を毎度毎度フェッチしてデコードする必要がなくなるため,CPUの処理効率は上がる。デコードというのはけっこう負荷の高い処理なので,デコード済みのμOpsをトレースキャッシュから持ってこられるというのは,それなりの意味があるのだ。
トレースキャッシュを採用したことにより,エグゼキュート用パイプラインの中で「μOpをフェッチする」段が設けられているのも,NetBurstマイクロアーキテクチャの特徴だ。分岐予測を行って命令をフェッチする機構を,最初とエグゼキュート用パイプラインの中の2か所に用意することで,分岐予測精度の向上を図っているわけである。ちなみにこの機構は,「BTB」(Branch Target Buffer,分岐予測バッファ)という,分岐予測の情報を格納しておくスペースと,分岐予測アルゴリズムによって成り立っている。
もう少し具体的に説明しよう。図3は初期Pentium 4のパイプライン構造を示したものだ。Pentium 4では,トレースキャッシュからμOpをフェッチしてパイプラインに流す処理を行う。これを「μOpキューイング」(μOp Queuing)というが,見てのとおり,ここは4段で構成されている。
図3
初期Pentium 4のパイプライン構成を図示したもの。正確には,トレースキャッシュ〜μOpキューイングのところは「TC Next IP」×2,「TC Fetch」×2だが,簡略化している
ふーんそうなのか,と思うかもしれないが,現実問題として,L1キャッシュから次の命令を取り出すというのは,それほど難しい処理ではない。もっというと,ここに4段も割くマイクロアーキテクチャというのは,NetBurstのほかには聞いたことがない。段数が多すぎである。
逆にいえば,ここまでパイプラインの段数を増やしているから,例えば同じ0.13μプロセスで比較したとき,AMDのAthlon XPというCPUが2.2GHzまでだったところを,Pentium 4では3.40GHzまで動作クロックを上げられた,ともいえるのだが。
図3に戻ろう。「アロケート/リネーム」から「スケジューラ」までは,μOpをスーパースカラ処理するための前段階,くらいに理解してもらっていい。並行して実行できる処理を同時に行わせるのがスーパースカラであるというのは,第1回で説明したとおりだが,ここは,μOpの列を作り(キューイング),スーパースカラ処理のための待機列を維持し(スケジューラ),ディスパッチを行って実際にスーパースカラ処理を行う,といった流れになる。ポイントは,スケジューラのステージだけでパイプラインが5段もあることで,一般的にはちょっとありえない感じだ。
また,「レジスタファイル」は第2回で説明したレジスタのことで,ここはそんなに深く考えなくていいい。実際にμOpを実行する前段階で,一時的にデータを置いたりする,くらいに捉えておけばOKだ。ただ,ここにも2段用意されているのは,およそ考えられない仕様だったりする。
……と,こんな風にパイプラインの段数を増やしていった結果,Pentium 4の効率=IPCは,Pentium IIIと比べて最大30%落ちているといわれる。とはいえ,IPCがPentium IIIの70%であっても,倍のクロックで動作させれば70×2=140%という計算が成り立つので,動作クロックが上がれば自然と解消するレベルの問題だった。(少なくともNetBurstマイクロアーキテクチャが発表された時点では)Pentium 4のIPCの低さというのは,Intelからするとそれほど問題ではなかったのだ。
再び図3に戻ると,レジスタファイルの下に,ズラリと並んでいるのが,エグゼキュートの“本体”となる実行ユニットである。実行ユニットは「整数演算」「浮動小数点演算」の二つに大きく分かれているが,まずは整数演算の実行ユニットについて見てみることにしよう。
●プログラム(=ゲーム)の制御を行う整数演算ユニット
整数演算とは,文字どおり整数の演算をすることだ。それこそ「1+1」とか「2×3」とかの計算を行う。整数演算は主にプログラムの制御に用いられており,「モンスターが○体いる」とか「あと○発食らうと死ぬ」とか,「今○ターンめ」とかいったあたりが主な担当。要するに,整数演算はゲームの全体的なパフォーマンスにかかわるが,“全体的すぎる”ため,整数演算性能のよさ,みたいなものを体感するのはなかなか難しい。
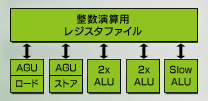
整数演算ユニット(図4,図2より一部抜粋)のうち,「ALU」は「Alithmetic Logic Unit」の略で,日本語では「論理演算装置」。要するにALUはこの整数演算を行うユニットというわけである。
ちなみに,「AGU」(Address Generation Unit,アドレス生成装置)は,データのロード(Load)/ストア(Store,セーブの意)が正しく行えるよう面倒を見るもので,これもかなり重要なユニットといえる。
Pentium 4においては,単純命令(Simple Instruction)用の2倍速ALU(2x ALU)が2組,複雑な命令(Complex Instruction)用の等速ALU(Slow ALU)が1組。AGUはロードとセーブが各1組となっている。単純命令とか複雑な命令とかいろいろあるが,まあ,ここはALUがざっくり3組,AGUがロードとセーブ用で1組ずつあると理解してくれれば問題ない。
●ゲームのリアリティにかかわる浮動小数点演算ユニット
続いて,浮動小数点演算ユニット(「Floating point number Processing Unit」,FPUともいう)だが,まず浮動小数点演算について誤解を恐れずにいうと,「小数点が移動する小数の演算」のこと。123だったら1.23×10の2乗,4567だったら4.567×10の3乗として表現するのが浮動小数点だ。ここは説明するとかなり難解になるので,「こうしたほうがコンピュータから扱いやすいから」と理解しておいてほしい。
浮動小数点演算の特徴は,表現力にある。
例えば,明るさの表現について考えてみよう。100という明るさがあったとして,「100よりちょっとだけ明るい」を表現しようとしたとき,整数演算だとこれは101になるが,浮動小数点だと100.1(1.001×10の3乗)はおろか,100.01(1.0001×10の3乗)や,100.00000001(1.0000000001×10の3乗)だって表現できるのだ。明るさのグラデーションのようなものを表現したいと思ったとき,どちらがより滑らかに行えるかは,言うまでもないと思う。
そして,この表現力はゲームのリアリティにつながる。浮動小数点演算性能が上がると,ゲームの速度を維持したまま,画面のリアリティを向上させられるのだ。逆に,同じ画面のリアリティを維持するなら,ゲームのパフォーマンスを向上させられるようになる。
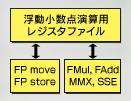
図5は図2の一部を抜粋したものだが,「FP move」はFloating Point number(浮動小数点数)の,小数点数の移動を行う部分。「FP store」はストア(セーブ)を行う。「FMul」「FAdd」がそれぞれ浮動小数点の加算,乗算を行うようになっている。
ただ,これら浮動小数点演算ユニットは,過去のx86アーキテクチャのCPUと互換性を持つ必要があるため,性能はそれほどでもない。一方Intelは,表現力の高さにつながる浮動小数点演算性能を,圧倒的に向上させたいと考えたのだ。そこで同社は,既存の浮動小数点演算ユニットは互換性維持のためそのままにしつつ,過去のCPUとの互換性をあえて切り捨てた高速な浮動小数点演算回路を導入した。これが「SSE」(Streaming SIMD Extentions)である。
SSEを日本語で書くと「インターネット・ストリーミングSIMD拡張命令」※。当然「SIMDって何?」という話になるが,これは「Single Instruction / Multiple Data」の略語で,一つの命令(Single Instruction)で複数のデータ(Multiple Data)を扱う方式のことを指す。
※最近のIntelの資料だと「インターネット」が外れて「ストリーミングSIMD拡張命令」になっている。20世紀ならまだしも,21世紀になってわざわざ頭に「インターネット」と書くのは,さすがに恥ずかしくなったのかもしれない。
一般的な演算では,これらは上から順番に処理されていくわけだが,これがSIMD演算だと,以下のようになる。

要するに,SIMD演算では「同じ命令(ここでは乗算)で処理できるものは,まとめて読み出して,まとめて処理する」ようにした。そして,SIMD演算を利用して高速化を図ったのがSSE,というわけである。
SSEはPentium IIIで採用された拡張命令だが,Pentium 4では新たに「SSE2」(ストリーミングSIMD拡張命令2)が追加されている。これは簡単にいうと,SIMD演算における「(1.11×10の2乗)×(2.22×10の2乗)」といった,演算一つ一つの高速化を図ったものだ。
浮動小数点演算は,整数演算と比べるとCPU負荷が高い(=データを読み出している時間と比べて,演算している時間が相対的に長い)ため,純粋にCPUの演算性能がパフォーマンスに影響しやすい。もっというと,同一のパイプラインなら,動作クロックの高いほうが性能はよくなる。そういう意味で,SSEやSSE2といった拡張命令は,NetBurstアーキテクチャと相性のいい命令といえるだろう。
しかし,SSEやSSE2には,一つ大きな弱点がある。それは,SSEやSSE2は過去のCPUと互換性がない新命令なので,プログラム側から利用できるように最適化されていなければ,利用できないという点だ。
ならゲームはどうなのかというと,SSE/SSE2に対応したタイトルはそれほど多くない。ゲームにおいて,Pentium 4は最高性能を発揮できない場合が多いのである。
これはなぜかというと,ゲームの場合,SSEやSSE2に最適化しようとすると,最適化すべきポイントが非常に多くなってしまうから。例えばMPEG-2などのビデオエンコードソフトは,(言ってしまえば)単機能のアプリケーションなので,最適化すべきポイントが限られている。よって,そこをSSEやSSE2に最適化すれば,処理を高速化できる。
対してゲームだと,戦場のシーンがあったとして,光の表現のような特定の1か所だけSSEやSSE2に最適化したとしよう。しかし,このとき爆発時の煙も同時に最適化されていなければ,シーン全体としてのパフォーマンス向上には寄与しない。つまり,単機能のアプリケーションと比べて,最適化のメリットが見えにくいのだ。もちろん,すべて最適化すれば効果はあるのだが,そんなことをしていたらいつまで経ってもゲームは発売されない。だから,あまり最適化が進んでいないのである。
ただこれには「ゲームエンジン」という例外があることを覚えておくべきだろう。ゲームエンジンは多くの場合「売り物」なので,SSEやSSE2に最適化されていることは,ゲームのデベロッパから付加価値として評価される。このため汎用的なゲームエンジンでは,少なくとも一般的なゲームタイトルと比べると,対応が進んでいる。
パイプラインの効率を「どうにかする」ための
Hyper-Threadingテクノロジ
整数,あるいは浮動小数点の実行ユニットはエグゼキュートのパイプラインに含まれているので,当然のことながらパイプラインストールの影響を受ける。ということは,これまた当然のごとくパイプラインの効率はあまりよくないわけだが,それを解決すべく導入されたのが「Hyper-Threadingテクノロジ」(以下HTテクノロジ)だ。
HTテクノロジについては第2回でも簡単に触れたが,まず簡単に定義のようなものを示すと,「実行ユニットの空いている部分を使って,流れているスレッドとは別のスレッドを流す技術」である。
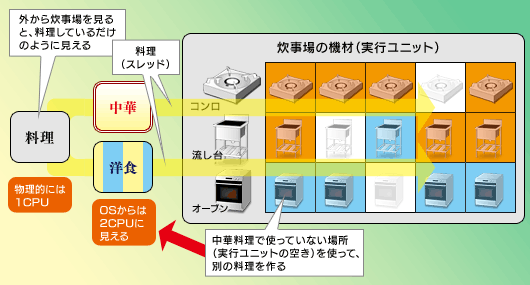
例として,ご主人様の意向を受けた執事が「今日の夕食は中華」と決めた,という状況を仮定してみよう。料理担当のメイドさんが10人いて,中華料理が得意なのはそのうち3人とする。このとき,残る7人は何もすることがないから,惰眠をむさぼることになる。
ただ,中華鍋の置かれたコンロこそ使えない一方,オーブンは空いている。つまり,オーブンを使って,食後のデザート用にケーキを作ろうと思えば作れるのだ(図6)。
図6
炊事場(実行ユニット)に,中華料理というスレッドが流れているイメージ。あるスレッドが,実行ユニットのすべてを使うということはまずなく,実行ユニットには使われない部分が生じる。なお,ここでは実行ユニットを3種類に分け,さらにそれぞれを5分割しているが,これはあくまでイメージである
そこで,洋食担当のメイドさんを2人たたき起こして,ケーキを作らせることにする。もちろん,そう決定したところで和食担当の5人は寝ているわけだが,洋食担当まで寝ているよりは,炊事場を効率的に利用できるのもまた確か。HTテクノロジというのは,炊事場(=実行ユニット)を効率的に利用するため,寝ているメイドさんを叩き起こして働かせる(=実行ユニットの空きにスレッドを流す)技術なのである。
このとき,外から見ると炊事場でメイドさんが料理しているだけだが,実作業としては2種類の料理を同時に作っている。このようにHTテクノロジでは,CPUとしては1個でありながら,2個のCPUであるかのように,同時に複数のスレッドを処理させることができるのである(図7)。逆にいうと,ご主人様が「中華なら,デザートは杏仁豆腐だろう」とのたまった場合,洋食担当のメイドさんはすることがなくなる。マルチスレッドに対応した命令でなければ,HTテクノロジの効果は得られないので,この点は覚えておきたい。
図7
そしてこれがHTテクノロジの概念図。実行ユニットのうち,あるスレッドで使用していない部分に,別の命令を流すことで,パイプラインの効率化を図る。すると,OSからはあたかもCPUコアが2個あるように見えるというわけだ
パイプラインを31段にするなど
高クロック化へと突き進んだPentium 4
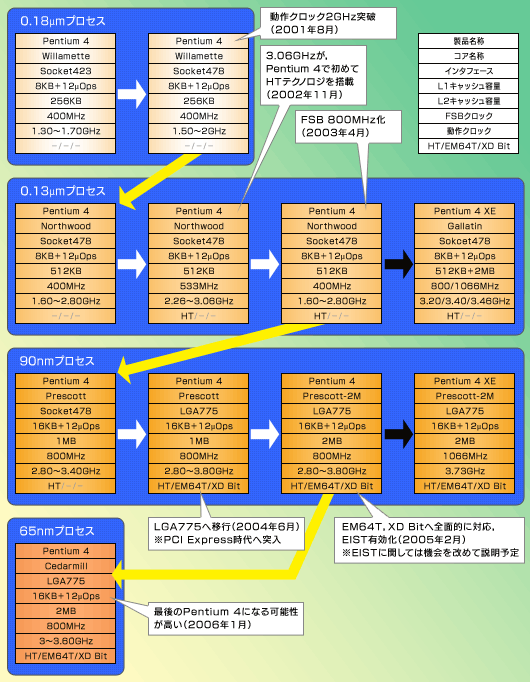
以上がPentium 4の基礎知識だが,Pentium 4は最初からHTテクノロジを採用していたわけではない。また,パイプライン段数にも変化がある。そこで,まずは系統図を図8のとおりまとめてみた。
黄色の矢印は,プロセスルールを含む大きな変革,白色の矢印はそこまでの変化ではない細かなアップデート,黒色の矢印は派生した限定モデルを示す。同じ背景色のモデルは,同じ「CPUコア世代」と考えてもらっていい。
図8
HTテクノロジ,EM64T,XD Bitについては,シリーズに属するモデルすべてで有効な場合は黒字で表記し,一部モデルで有効なものを灰色で表記した。また,無効なものは灰色のハイフン(―)で示している
最初のPentium 4は,0.18μmプロセスで製造された,開発コードネーム「Willamette」(ウィラミット)。「開発コードネーム=CPUコア」とする観点から「Willametteコア版Pentium 4」などとも呼ばれる。最初は1.40/1.50GHzのみだったが,後に1.70GHz,1.30GHzの順に追加され,これがPentium 4の基礎となった。
初期のCPUソケットは423ピンの「Socket423」だったが,すぐに「Socket478」と呼ばれる小型のソケットへ移行し,動作周波数は2GHzを突破する。
これに続く製品が,0.13μプロセスで製造された開発コードネーム「Northwood」(ノースウッド)である。Northwoodコアは1.60〜3.40GHzと幅広く展開され,展開の中で「FSB」(Front Side Bus)と呼ばれるシステムバス速度もどんどん高速化していった。Pentium 4において,FSBはCPUとチップセット(ノースブリッジ)を結ぶバスのことで,Willamette時代に400MHzだったFSBクロックは,533MHzを経て800MHzと,Northwoodコアで2倍になっている。
もう少し細かく見てみよう。NorthwoodコアではFSBクロックを533MHzへ引き上げたときに,最上位となる3.06GHzで,先ほど説明したHTテクノロジが初めて有効化された。その後「AMDがAthlon 64を投入してくる」という話になってくると,とにかくAMDに負けたくないIntelは先制攻撃的にFSBクロックを800MHzへと引き上げ,HTテクノロジを全動作周波数で有効にするというアプローチを取りつつ,さらに動作クロックも3.40GHzまで引き上げた,といった流れになる。
さらに,AMDがAthlon 64の上位モデルとしてAthlon 64 FXという特別版を投入してくると,これに対抗。Northwoodコアをベースに,L3キャッシュを2MB内蔵した(本来はサーバー/ワークステーション用であるXeon MPというCPUの)「Gallatin」というコアを急いで流用して,“新製品”Pentium 4 Extreme Edition(Pentium 4 XE)を発売した。
その後,Intelは90nm(0.09μm)プロセスの「Prescott」(プレスコット)コアへと,製品ラインを置き換えていく。PrescottコアはまずSocket478で登場したが,その後「LGA775」という新しいCPUソケットへ移行し,同時に「プロセッサナンバー」と呼ばれる3桁数字の採用を始めた。「Pentium 4 5xx」とか「Pentium 4 6xx」(xxには数字が入る)といった表記には,見覚えがあると思う。なお,3桁数字の持つ意味については次回説明したい。
ちなみに,Prescottでは,パイプライン段数がNorthwoodまでの20段から,31段へと増えた。このほか,Willamette/Northwoodと比べたとき,L1のデータキャッシュ容量がそれまでの8KBから16KBに,L2キャッシュ容量が同じく512KBから1MBへとそれぞれ拡張されている。将来的に動作クロックが上がっていくと,メインメモリと速度の違いが大きくなって,メインメモリへデータを読みに行くことになったときのペナルティが大きくなる(=CPUから見たときの待ち時間が相対的に長くなる)わけだが,キャッシュ容量の増加は,この問題への配慮と見るべきだろう。もちろん,ここには技術的な進歩もある。
細かいところでは,前出のBTBが512エントリから2Kエントリへ増加したあたりも変更点だが,これらは要するに「20段でも多いところを31段へとさらにパイプラインを細分化して高速動作させるようにすると,パイプラインストールのペナルティが大きくなるから,分岐予測を強化した」といった感じである。
Prescottでは機能追加が行われ,
“最後”のCedarmillへ
さらにPrescottでは新たに,「SSE3」と呼ばれる命令群の追加,「EM64T」への対応,「XD Bit」の搭載が行われている。
SSE3は,SSE2をさらに拡張したもの,という理解で問題ない。EM64T(Extended Memory 64 Technology)だが,これは一言でいうと,x86命令の64bit拡張版「AMD64」の互換命令だ。AMD64に関しては,Athlon 64についての解説時に改めて説明したいと思う。今のところは,EM64Tが有効なPentium 4だと「Windows XP Professional 64-bit Edition」や,次期Windows「Windows Vista」の64bit対応上位モデルを動作させることができる,くらいの認識でいてくれればいい。
最後にXD Bit(eXecute Disable Bit)だが,これは理解するのに二つほど予備知識が必要になる。一つは「メモリには,プログラムを格納するところと,データを格納するところの2種類に分けられる。プログラム用は一度書き込んだら読み出し専用でかまわないのだが,データ用のところは読み書きが発生する」ということ。もう一つは「プログラムの誤動作を引き起こすダミーデータと,ユーザーのPCを乗っ取るプログラムをセットにしてダウンロードさせ,あるプログラムがこのデータを読み出そうとしたタイミングで,PC乗っ取りプログラムをこっそり実行してしまうという形の不正プログラムが現れてきた」ということだ。
XD Bitは,こういった「メモリ上にある,データ用のところにあるデータすべて」に対して,文字どおりエグゼキュート(実行)をDisable(不可)にする機能である。これにより,この手の不正プログラムは完全にブロックできる。
なお,XD BitはAMDのAthlon 64が搭載する「NX Bit」(No eXecution Bit)とまったく同じもの。いずれもWindows XP Service Pack 2の「DEP」(Data Execution Protection)機能と連動して動作する。
Windowsと連動して動くため,かなり安全な機能といえるXD Bitだが,ゲーマーからすると,一つだけ注意しておく点がある。それは,ゲームのコピーガードソフト(や暗号化ソフト)だ。コピーガードソフトなどは,プログラムの中身をのぞかれるといろいろ不都合があるので,メモリのデータ用のところで,“自分自身”を適宜書き換えながら実行するようになっており,XD Bit(というかDEP)を有効にしておくと,ゲームが起動しなくなってしまう場合がある。DEPは,例外指定が可能なので,ゲームがうまく起動しない場合は,設定を見直すといいだろう。
機能以外に目を向けると,Prescottコアでは,それまでのPentium 4から一転,CPU側に接続用のピンを持たない「LGA775」というCPUソケットへ移行したのもトピックだ。また,Prescottコアと仕様はほぼ同じながら,製造プロセスが65nmへと進化した「Cedarmill」(シーダーミル)というコアが,2006年1月に導入されている。
しかし――ここまであえて触れてこなかったが――CedahmillコアでPentium 4が4GHzや5GHzを超えるかといえば,そんなことはなかった。Northwoodで3.40GHzを達成したPentium 4だが,Prescottでは3.80GHzまでしか動作クロックを向上させられず,Cedarmillでもクロックは3.80GHzに据え置かれたままだ。そして,Cedarmillは,最後のPentium 4用コアになり,NetBurstマイクロアーキテクチャのCPUは,これにて打ち止めになると目されている。
- 1.Pentium 4は,とにかく動作クロックを高くすることに注力した「NetBurstマイクロアーキテクチャ」を採用している。
- 2.動作クロックを高くするため,パイプライン段数は初期で20段,後期で31段と,非常に長い。パイプライン段数が長くなると,分岐ミスによる効率の低下が問題となるが,分岐予測を2度行ったり,HTテクノロジを導入したりといった対策が行われている。
- 3.Pentium 4は,プロセス技術の進化によって,3GHz程度までは順調に動作クロックが上がってきたが,Prescottコア以降では動作クロック向上がIntelの思うように行っていない。
第3回を覚えている人は,Pentium 4の動作クロックが上がらなくなった理由が,消費電力&発熱にあると予測がつくと思う。そこで次回は,Intelが直面した問題とその対応を中心に,Pentium 4,そしてPentium D,Celeron DといったCPUについて,総括してみたい。
|