










ニュース
2018年のGPUで使われる新メモリ「GDDR6」の特徴とは? 高速化と省電力の両立が鍵に
 |
そもそもGDDR6は,メモリ技術の標準化団体であるJEDEC Solid State Technology Association(以下,JEDEC)で,現在もまだ仕様を策定中の規格である。GDDR6の仕様は,JEDECの「JC-42」(Solid State Memories)という委員会内に設けられた「JC-42.3」(DRAM Memories),および「JC-42.3C」(DRAM Parametrics)という2つの分科会で,現在も策定作業が行われている状況だ。
そのため,仕様が固まった状況ではないことを断ったうえで,この新世代グラフィックスメモリの特徴について解説してみたい。
 |
 |
 |
なぜGDDR6が必要なのか?
冒頭でGDDR6のことを,メインストリーム(ミドルクラス)〜バリュー(エントリー)市場向けのGPUで使われるメモリと書いた。これを見て,「新世代のメモリ規格であれば,その世代のハイエンド市場向け製品から使われるのではないのか?」と疑問に思った人もいるかもしれない。
その理由は簡単で,ハイエンド市場向けGPUは,積層メモリ技術の「HBM2」を採用することが明らかだからだ。
 |
ただHBM2は,高性能だが高コストのソリューションでもあり,性能追求のハイエンド市場向けGPUはともかく,コストパフォーマンスが問題になるメインストリーム市場以下を狙ったGPUでは採用しにくい。
これもあってNVIDIAは,「GeForce GTX 1080」や「NVIDIA TITAN X」などで「GDDR5X SGRAM」(以下,GDDR5X)というメモリ規格を採用した。その詳細については,こちらの解説記事に詳しく述べている。本稿でもGDDR5Xの仕様との比較が出てきたりするので,未見の人は一読しておいていただきたい。
さて,このGDDR5Xは,2016年8月にJEDECの標準規格「JESD232A」になった。しかし,このGDDR5Xを生産するのは,今のところMicron Technology(以下,Micron)の1社だけ。製品に利用しているのもNVIDIAだけであり,広範に利用されているとは到底言いがたい状況だ。
その他のメモリメーカーであるSamsung Electronics(以下,Samsung)やSK Hynix,GPUメーカーであるAMDは,最初からGDDR5Xではなく,GDDR6を将来の製品で利用することを想定しており,ようやくそのサンプルがSK Hynixから出始めたというのが,現在の状況というわけである。
こうした事情もあり,今回SK Hynixがリリースしたものは,まだ仕様が固まる前のドラフト版に基づいた,エンジニアリングサンプルに近いものである。なぜそれを先行して出したのかといえば,AMDやNVIDIAがGDDR6を利用するGPUを開発中であり,その試作と評価のためには,まずメモリチップのエンジニアリングサンプルが必要ということからだ。
GDDR6は高速化と消費電力低減を両立
GDDR6登場に至る経緯は以上のとおりとなる。続いては,GDDR6の特徴について説明していこう。
冒頭でも触れたとおり,GDDR6は現在規格が策定中であり,JEDECによるドラフト版ドキュメントも,まだ公開されていない。そのため本稿では,2016年8月に行われた半導体関連イベント「Hot Chips 28」でSamsungが行った「The future of graphic and mobile memory for new applications」というセッションの内容とスライドを用いて,GDDR6の特徴を説明していく。
まずは,メモリ技術の大雑把なロードマップ(スライド1)を見てほしい。スライド左のグラフは,縦軸がピンあたりの信号速度(≒メモリバス帯域幅),横軸が年度である。GDDR5Xがないのはご愛嬌として,2018年あたりのGDDR6で,ピン当たり14Gbpsの信号速度を実現するのが目標であるわけだ。
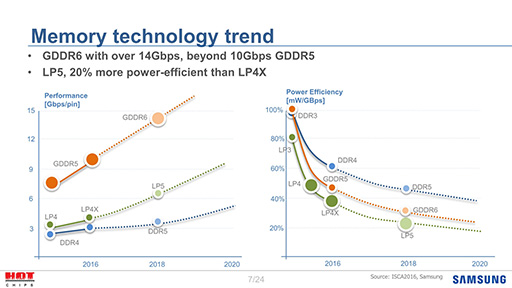 |
信号速度の進化よりも重要なのは右のグラフで,これは信号速度あたりの消費電力が下がる様子を示したものである。これを見ると,GDDR6はGDDR5と比べても,大幅に消費電力を削減できるという。つまりGDDR6はGDDR5と比べて,信号速度がおおむね倍になりながら,転送にかかる消費電力は同程度か下回る程度に抑えることを目標としているわけだ。
そもそも消費電力は,GDDR5Xの大きな弱点であった。GDDR5Xは,信号速度の向上にほぼ比例する形で消費電力が増えるので,GDDR5比で1.6倍近い電力を必要としてしまう。つまり,省電力化がGDDR6で実現するメリットの1つというわけだ。
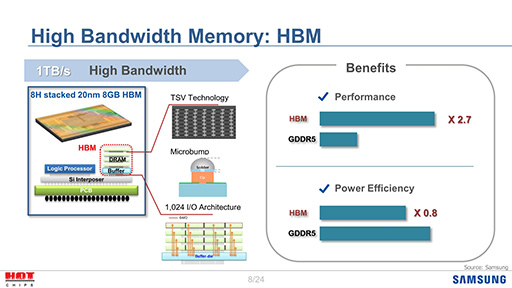
ちなみに,SamsungもHBMを手がけているので,GDDR5とHBMを比較したスライド(スライド2)を公表していたりする。HBMがGDDR5(やGDDR6)と比較して,性能と消費電力という観点で良好なのは当然だが,問題はコストが高いことであり,だからGDDR6を開発しようという話になっているわけだ。
 |
GDDR6における高速化実現の鍵は,クロストークの削減と信号波形の補正
GDDR6では,信号速度の高速化を実現するために,大きく2つの工夫がなされている。1つはエンコードを利用したクロストーク(※信号線同士の干渉)の削減で,もう1つはイコライザを利用した高速伝送時の信号波形補正である。
クロストークの削減から説明していこう。
基本的な考え方は,隣あった信号線のうち片方の電圧が上がると,もう片方も影響を受けて電圧がわずかに変動することだ。たとえば,隣接した3本の信号線に「111」という信号が流れた場合,3本の信号線は相互に隣接した信号線の電圧を上げるので,3本のうち,とくに中央の信号線では,両端の信号線で生じた電圧の変動に影響を受けて,信号の波形が乱れやすい。2本の信号線による「11」の場合も,「111」ほどではないが同様に相互に干渉が発生してしまう。電圧の掛からない「000」であれば,なにも問題はない。
クロストークの対策としてよくあるのが,信号線の間にGND(グランド,0Vの基準電位)の線を挟むことだ。ちょっと昔の話になるが,HDDの接続インタフェース規格が「Ultra 33」から「Ultra 66」になったとき,Ultra 33の信号線を挟み込むように,GNDに落とす信号線を挟み込むことでクロストークを減らす仕組みを採用して,これにより高速伝送が可能になったことを覚えている人もいるだろう。
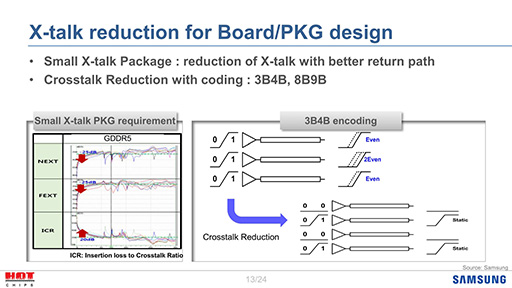
GDDR6においても,理屈はそれと近い。とはいえ,Ultra 66のような単純なやり方では,配線の数が倍になるので実装面積の観点で非常に不利となる。そこでGDDR6では,「3B4B」または「8B9B」というエンコード処理を挟むことで,この問題を解決しようとしているのだ(スライド3)。
ここでいう3B4Bとは,3bitのデータを送るときには4bit分の「シンボル」に変換(エンコード)して送る方式のことで,同様に8B9Bは,8bitのデータを送るときには9bit分のシンボルに変換する方式のことである。
 |
このエンコードを挟むと,なぜクロストークが減らせるのだろうか。
実際にはもっと複雑な仕組みを採用するはずなので,あくまでイメージとしてとらえてほしいのだが,たとえば元のデータが「111」なら,それを隣り合う信号線が同時に「1」にならないよう,「0101」に変換する。要は,クロストークを減らすために,追加の信号線を使ってデータを「11」という並びが発生しないようなシンボルに変換するという点がポイントである。
一方,この方式のデメリットは,信号線が増えることだ。
3B4Bエンコードでは,3bitのデータを4bit分のシンボルに変換してから伝送するので,信号線も4本必要になる。データが16bit分なら22本,32bit分だと44本の信号線が必要になる計算だ。Ultra 66の例では信号線が40本から80本へと倍増していたから,それに比べればまだ少ないが,それでも配線数が増えるのはあまり好ましくない。
そこで,より信号線の数を減らせる8B9Bエンコードの採用が,3B4Bエンコードと並行して検討されているようだ。こちらだと16bitなら18本,32bitでは36本の信号線になるので,3B4Bエンコードの場合よりも,多少は信号線の数を減らせる計算になる。
3B4Bと8B9Bのどちらを採用するのか,2016年8月の時点ではまだ決まっていなかったが,SK Hynixがエンジニアリングサンプルを出荷する以上,現状ではどちらかに決まっているのだろう。
GDDR6では,タイミングやパラメータ調整を定期的に行う
2つめの工夫に出てくるイコライザとは,データ伝送の信号を補正して,伝送中に失われてしまう信号の要素を補う技術,あるいはそれを行う回路のことだ。
GDDR6では,GPUが内蔵するメモリコントローラ側にタイミング調整機能とイコライザを,メモリチップの側にはノイズ耐性の高い回路を入れて,信号補正を行う仕組みを導入するという。その仕組みを示した図がスライド4だ。
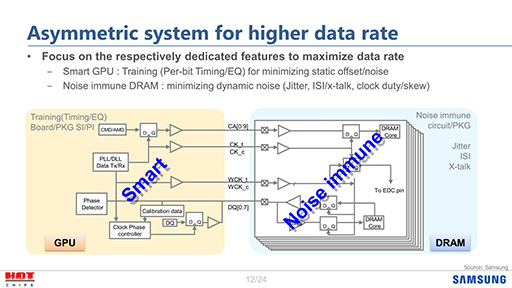 |
スライド4で何をしているのか,もう少し分かりやすく説明しよう。
まずGPU内のメモリコントローラでは,タイミングの調整とイコライザのパラメータ調整を行う「Training」を定期的に実施する。
ここでいうTrainingとは,何種類かの特定のパターンの信号を一定時間送って,その伝送タイミングや波形を精密に測定することで,タイミングのずれや波形の補正などを行う仕組みのことだ。
こうしたTrainingは,たとえばDDR4などでも行っているのだが,従来は電源投入時やリセット時に,1回実施するだけであった。配線の微妙な差とか,実装の状況による信号反射の影響を消すには,最初にTrainingを行っておけば十分という理屈だ。
それをGDDR6で定期的に行う仕組みにしたのは,おそらく温度上昇にともなう基板やパッケージの微細な歪み,あるいは温度変化による材質のパラメータ変化といった信号伝達特性の変化を連続的に補正するためであろう。逆に言えば,16Gbpsもの信号を通そうとすると,ここまで配慮しなくてはいけないとも言える。
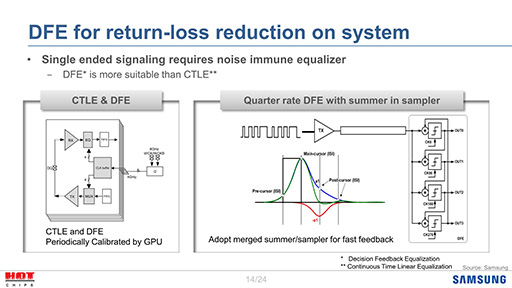 |
CTLEとは,時間軸に沿って信号の振幅を増減させるフィルタで,これで低周波成分を抑えて信号成分を増幅することで符号間干渉信号(Inter-Symbol Interference,ISI)を削減しようというものだ。一方のDFEは,補正した波形の出力を次の波形を補正するときの計算にも利用することで,符号間干渉信号を除去しようというものだった。
JEDECでは,4タップ(1/4波長づつ処理する)のDEFが,CTLEよりも有効であると考えているようだ。
データ転送用のクロック信号はメモリコントローラ側で4倍速を生成
GDDR6では,クロック信号の作り方にも変更がある。
GDDR5Xの解説記事でも触れたように,GDDR5やGDDR5Xでは,もとになるクロック信号(CK)と,これを倍速化したWClock信号(WCK)の2つを使用していた。たとえば,CKが1.5GHzの場合,WCKは3GHzとなる。
GDDR5では,WCKの両端(信号の立ち上がりと立ち下がり)を使うので,3GHzの倍となる6GHzで伝送を行っていた。これがGDDR5Xになると,メモリチップとメモリコントローラの双方が,WCK信号をもとにしてそれぞれ6GHzのクロック信号を作ったうえで,6GHzの信号の両端を使った12GHzで転送を行う,というちょっとトリッキーな技法を必要としたのである。
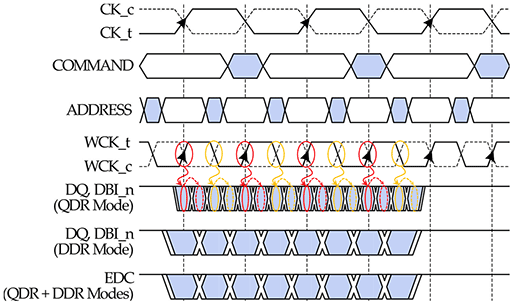 |
ここで問題となるのは,12GHzのクロックは,メモリコントローラとメモリチップの間で直接は同期しておらず,同期しているWCKを使った間接的な同期にすぎないことだ。つまり,微妙にずれる可能性があるわけで,ずれてしまえばデータが正しく送受信できる保証がなくなってしまうし,もし間違って送受信したとしても,それを検出する手段もない。これが,GDDR5Xにおける問題であった。
問題のあるGDDR5Xの仕組みをそのまま使うわけにはいかなかったので,GDDR6ではWCKをCKの4倍速――CKが1.5GHzならWCKは6GHz――にした(スライド6)。この4倍速WCKは,メモリコントローラ側で生成するもので,メモリチップはWCKをそのまま利用して,両端で送受信を行うというわけだ。
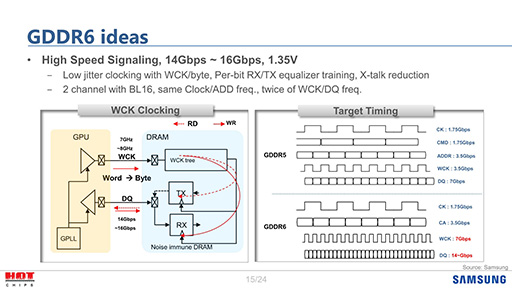 |
搭載GPUはNVIDIAのVolta,AMDのNavi世代か
GDDR6について,現状明らかになっている情報は以上のとおり。
GDDR5Xは,GDDR5との互換性を最大限に確保するため,いろいろとトリッキーなテクニックを使っていた。それに対してGDDR6は,互換性を捨てて,ある程度の最適化を行ったことで,GDDR5と同程度の消費電力で倍近いメモリバス帯域幅を利用できるようになったわけだ。
ちなみに,「プリフェッチ」の数は現状不明だが,SK Hynixのプレスリリースを読む限り,GDDR6の製造には,同社の2Znm――おそらく21nmと思われる――プロセスを利用しており,これは同社のDDR4やLPDDR4と同じプロセスである。したがって32nプリフェッチ以上でないと,ピンあたり16Gbpsの速度は到底実現できない計算になるため,おそらくはGDDR5Xと同じ,16nプリフェッチ×2(※アドレスを2つ指定して,各々が16個分の連続したデータを送り出す)という構成ではないかと思う。
 |
この写真をよく見ると,18列×5行のピン(※実際はボール)が2段となっているので,ピン数は180ピンとなるのだが,これが本当かどうかは分からない。というのも,GDDR5Xのピン数は190ピンもあるからだ。GDDR6では,先述したエンコードの導入で信号線の数が増えていると思われるので,この写真が本物ならば,ピン数が減っているのはちょっと不思議である。
もっともGDDR5Xの場合,190ピンの大半は電源とGNDに費やされているから,消費電力がより低いGDDR6では,これらを減らしても大丈夫と判断したのかもしれない。
 |
最後に,GDDR6搭載製品の登場時期を推測してみよう。
SK Hynixのリリースでは,量産開始時期について,以下のような記述がある。
“SK Hynix has been planning to mass produce the product for a client to release high-end graphics card by early 2018 equipped with high performance GDDR6 DRAMs”
(SK Hynixは,2018年初頭にリリース予定のGDDR6 DRAMを搭載するハイエンドグラフィックカードにあわせて,量産を予定している)
これからすると,SK HynixがGDDR6の本格量産に入るのは,2017年第3四半期辺りになりそうだ。タイミング的に言えば,NVIDIAのVolta世代GPUや,AMDの次々世代GPU「Navi」あたりが,最初のGDDR6搭載カードになるのではないだろうか。
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー