











ニュース
PowerVRのImaginationが“ハイエンドGPU”の設計に着手。ハイブリッドレンダリングハードウェア,そして新API「OpenRL」とは?
GPUといえば,4Gamer読者ならAMDのRadeonシリーズやNVIDIAのGeForceシリーズを真っ先に連想するだろうが,最近めざましい躍進ぶりを見せているメーカーがある。
それは,「PowerVR」を有する英Imagination Technologies(以下,Imagination)だ。
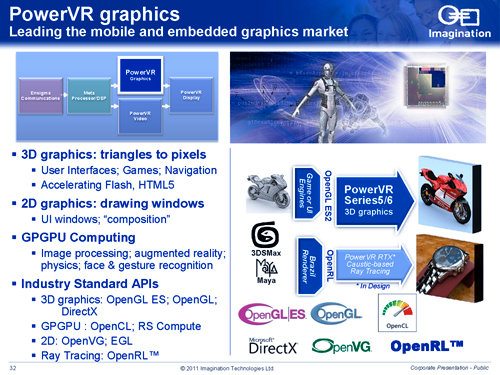
知っている読者も多いと思うが,iPhoneやiPadで採用されているGPUはPowerVRコア。Intel製Atomプロセッサの一部に統合されているグラフィックス機能「GMA500」「GMA600」もPowerVRコアだ。さらに,PlayStation Vitaも,搭載するGPUにはPowerVRコアを統合している。
そんなImaginationが「大きなプロジェクトを進行中」という情報を得た筆者は,2011年8月に開催された「SIGGRAPH 2011」の会期中に,同社への取材を行った。
果たして大きなプロジェクトとは何なのか。結論から先に述べてしまうと,ズバリ,「ハイエンドGPU開発計画」だ。
ただこのハイエンドGPU,少なくとも計画初期のフェーズでは,現行のRadeonやGeForceなどと競合する予定はなく,一風変わった製品になりそうなのである。
今回は「ImaginationのハイエンドGPU」について,順を追って解説してみたいと思う。
まずは,ImaginationがGPUの開発に乗り出した経緯から説明しておこう。
Imaginationは,2010年12月にCaustic Graphicsという企業を買収した。
Caustic Graphicsは,レイトレーシングをベースとしたレンダラの開発とレイトレーシングアクセラレータ「RTU」(Ray Tracing Unit)のハードウェア設計を行っていたベンチャー企業で,実際,2010年に「CausticOne」という第1世代のRTU搭載カードを発表していたりする。
で,現在,ImaginationとCaustic Graphicsは共同で,第2世代のRTUとなる「CausticTwo」(開発コードネーム)を開発中だ。第1世代のCausticOneが,動作クロック100MHzのFPGAを2基搭載した,いかにもテスト基板といったPCI Express x1カードだったのに対し,CausticTwoでは,レーン数などは不明であるものの一般的なPCI Express接続型拡張カードに,フルカスタムの高速ASICを載せたものになる見込みだ。つまり,CausticTwoで搭載されるこの高速ASICこそが,「ImaginationのハイエンドGPU」の正体ということになる。
CausticTwoは,ディスプレイ出力を備えていないため,“レイトレーシングアクセラレータ”として,既存のグラフィックスカードと併用される。だからこそ,現行のRadeonやGeForceと競合しないわけだ。
「グラフィックスカードと併用」というと,かつてAGEIA Technologiesが発表した物理シミュレーションエンジン「PhysX」と,そのアクセラレータとにイメージが被るだろう。ご存じのとおり,AGEIA TechnologiesはNVIDIAに買収され,PhysXがNVIDIAのGPGPUソリューションへと取り込まれている。アクセラレータの役割もCUDA CoreベースのGPU(≒GeForce)が取って代わっており,RTUにもこうした行く末が見えているわけだが,Imaginationの認識は「想定の範囲内」。なかなか潔い。
先ほど,CausticTwoはデスクトップPCやワークステーションに差せるという話をしたが,Imaginationは本製品を,民生向けではなく,業務用としてリリースする予定だ。そして,そこで得られた技術(など)をPowerVRへフィードバックさせるという戦略ロードマップを敷いている。
残念ながら,今回の取材中,ImaginationはRTUのアーキテクチャに関しては何も語ってはくれなかったのだが,おそらくはベクトル演算器アレイで構成されているはずだ。もっとはっきり言えば,GPUとよく似た設計になっているはずである。
Imaginationは,開発中だという将来の製品「PowerVR RTX」で,レイトレーシング機能を搭載する予定だ。しかし,RTUがGPUとよく似た設計になっている可能性が高いことからすると,「PowerVRにRTUを追加する」というよりは,「3Dグラフィックスのレンダリング用として用意されるシェーダユニットに,RTUとしてのポテンシャルを盛り込む」という形で統合してくることになるものと見られる。
ところで,一般的なGPUの場合,レンダリングの起点をピクセルに置く「ラスタライズベース・レンダリング」(Rasterize Based Rendering)が採用されるが,レイトレーシングにおいてはレイ(光線)起点となるため,当該処理のための「演算器の駆動のされ方」はGPUとはかなり異なる。光線ごとの条件分岐パスがかなり複雑で,ひいては光線ごとの処理時間が異なってくるため,各光線を並列に処理させる場合でも,シェーダユニットの駆動のさせ方や,各データパスの構造設計には,それ相応の最適化や設計の見直しが必要になるのだ。
「組み込み機器向けをメインフォーカスとしたPowerVRにレイトレーシング実行のポテンシャルを付けて無駄にならないか?」と考える人はいるかもしれない。実際,その疑問は的を射ていると思うが,Imaginationはこれを無駄とは考えていない。レイトレーシングのような比較的複雑なロジックを並列実行できるポテンシャルは,GPGPU用途,つまり,データ並列コンピューティング用途にも効力を発揮するからだ。
もともと組み込み機器向けGPUであるPowerVRにとって,3Dグラフィックスレンダリングだけでなく,信号処理,認識処理のようなデータ並列コンピューティング用途にもGPUコアを流用できるようになるのは願ったり叶ったりだ。実際,世の中の動きとして,組み込み機器向けのGPUをデータ並列コンピューティングでも使うべくOpenCLへ対応させる動きも活発だったりする。
レイトレーシングアクセラレータとして成功すればもちろんそれでよし。ダメでも,GPGPU用途――PowerVR系なのでOpenCL用途――での性能向上に結びつくのであれば無駄にならない。
ImaginationとCaustic Graphicsとのタッグプロジェクトは,「どう転んでも損はない」という読みの下に進められているわけである。
ただ,「レイトレーシングのハードウェアアクセラレーション」と言ったところで,Imaginationだけががんばっていてもエコシステム(ecosystem。ここでは「業界全体の収益構造」の意)は育たない。ラスタライズベースの3Dグラフィックスも,DirectX(Direct3D)やOpenGLという標準があるからこそ,ゲームから実用アプリケーションに至るまで,幅広いソフトウェアのエコシステムがなり立っているわけだ。
NVIDIA独自のGPGPUソリューションであるCUDAも,今でこそひとまずの成功を収めたといえるが,その道程は決して楽なものではなかった。ありとあらゆる(並列コンピューティングに向いた)ソフトウェアのジャンルを“CUDAに巻き込む”ような,莫大な投資の末に勝ち取ったデファクトスタンダードなのだ。
Imaginationも「エコシステム構築の重要性」をよく理解していて,Caustic Graphicsと共同でプログラマブルなレイトレーシングアーキテクチャを設計し,これを「OpenRL」というAPIの形で取りまとめている。ちなみにOpenRLのRLは,「Ray tracing Library」の略だ。
現在のところOpenRLはβ版の段階にあり,正式版は「OpenRL 1.0 SDK」として2011年第4四半期にリリースされる予定になっている。
「Open“xx”」ということで,OpenGLなどの規格策定を行っているKhronos Group(以下,Khronos)が絡んでいるようなイメージを抱くかもしれないが,現段階ではあくまでも,ImaginationとCaustic Graphicsによる独自プロジェクトという位置づけ。もっとも,Khronosへ確認したところ,2社との協議を始めているところとのことだった。
AppleのOpenCLや,ソニーの「COLLADA」のように,一企業の独自発案で始まりながらも,Khronos管轄下のオープンスタンダードAPIに組み入れられたケースは少なくない。しかもImaginationは発言力の大きな評議委員(Board of Promoters)としてKhronosに加盟しているため,よほどの独自仕様でもない限り,KhronosがOpenRLを拒絶することはないだろう。近い将来,グラフィックスAPIとして採用される可能性は高い。
なお,Imagintaionが公開している資料には「OpenRLは,AMDやNVIDIAのGPUを用いてもアクセラレーションが可能となる」という記載があるが,この件についてNVIDIAに取材してみたところ,返ってきた回答は,「水面下での動きは正直分からない。広報として公式に言えるのは,我々がレイトレーシングエンジンに(自社開発の)『OptiX』を推奨する立場であることだけだ」というものだった。ただNVIDIAは,OpenCLが登場したときも間を置かずに対応してきたので,OpenRLがKhronos管轄下になれば,そこからの対応は早いはずだ。
AMDには確認できていないが,同社は,“独自仕様GPGPUソリューション戦争”でNVIDIAに敗れてから,Khronos管轄下のオープンスタンダードAPIを協力に支持する立場に回っているため,OpenRLの規格策定にも積極的に協力するのではないかと思われる。
さて,上で紹介したように,OpenRLはバージョン1.0βとしてほぼ完成している。もちろん,Khronosの管轄下に移ればバージョン表記が変わる可能性はあるものの,ひとまず,2011年第4四半期にリリースできる程度にはできあがっているわけだ。
そして,Caustic GraphicsはSIGGRAPH 2011で,このOpenRL 1.0βをベースとしたレンダリングエンジン(=レンダラ)も発表している。その名は「Brazil 3.0」。開発担当は,Caustic Graphicsの子会社であるSplutterFishだ。
SplutterFishは,Autodeskの「Maya」「3ds Max」,そしてMcNeelの「Rhinoceros」(以下,Rhino)といった業界標準のツールに向けたレイトレーシングプラグイン「Brazil R/S」を提供してきたソフトウェアスタジオである。
Brazil 3.0は,「Brazil R/S 2.0」をOpenRL 1.0ベースに書き直してリファインしたバージョンに相当するとのことで,Brazil R/S 2.0までに使用してきたリソース類がすべて利用可能になっている。さらにMayaや3ds Max,Rhinoに対応したプラグインが提供される予定だ。
ちなみにBrazil 3.0自体は,「OpenRLをベースとした汎用のレイトレーシングベースレンダラ(とそのSDK)」という位置づけ。WindowsやMac OS X,そしてLinuxといったOSに広く対応し,動作対象ハードウェアも限定されないということになっている。要するに,OpenRLをアクセラレーションできる仕組みがシステムに実装されていれば,Intel製CPU,AMD製CPU,NVIDIA製GPU,AMD製GPU,そしてRTUのそれぞれで,スペックに見当った形のアクセラレーションが得られるというわけだ。
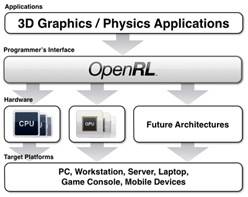
OpenRLは,ローレベルなプログラマブルレイトレーシングAPIで,レイトレーシングベースのレンダラを構築するために必要なローレベル機能が提供されるのみとなっている。
つまり,コンセプト自体はOpenGLなどと大きく変わらない。もっとはっきり言うと,特定のライティング表現や材質表現――たとえば大局照明や表面下散乱――といったものを再現するためのAPIのようなものは用意されない。なので,それらは開発者自らがOpenRLを駆使して,目的となる表現を実現するためのメソッドを構築しなければならないのだ。Brazil 3.0は,SplutterFishがOpenRLを用いて構築した,「多彩な表現を実現するレンダラ」ということになる。
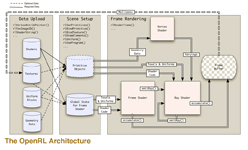
OpenRLの細かい仕様はCaustic GraphicsのOpenRL紹介ページを参照してほしいが,ここでは本質だけ解説しておこう。OpenRLのレンダリングコアは,3つのプログラマブルシェーダによって構成されている。
1つめは頂点シェーダ(Vertex Shader)で,イメージ的には,一般的なGPUで搭載される頂点シェーダと同種のものと考えて差し支えない。ジオメトリ情報(=頂点単位の情報)を司り,3Dモデルの頂点単位で座標変換や変位を行うものである。
2つめはフレームシェーダ(Frame Shader)で,これは飛ばす光線を司るプログラマブルシェーダである。。
たとえば,これからレンダリングしようとする1920×1080ピクセルのフレームがあったとして,この視点からの視界(viewport)を定義し,各ピクセルから視界の広がりに沿って光線を飛ばすのが主な役割だ。飛ばした光線が3Dオブジェクトに衝突した場合は,次に説明するレイシェーダが呼び出される。あるいは,衝突した場所からプログラマブルに新たな光線を飛ばすことも可能だ。
というわけで,3つめはいまその名が出たレイシェーダ(Ray Shader)。これは,飛ばされた光線が3Dモデル上にあるサーフェス(=ポリゴン)やそのほかのプリミティブと衝突したときに呼び出されるプログラマブルシェーダである。
たとえば,ある3Dキャラクターの部位に光線が衝突したとしよう。衝突したサーフェスが磨かれた金属である場合は,その入射してきた光線に対して鏡面反射する方向に新しい光線を生成して飛ばす処理を行うわけだ。一方,シンプルな疑似(算術的)ライティングでよいなら,適当な代表光源と視線,法線の3パラメータを使って適当なライティング計算でまかなえる。
そう,レイシェーダは,一般的なGPUにおけるピクセルシェーダにかなり似たシェーダなのだ。
3つのシェーダとも,テクスチャの参照が可能で,とくにフレームシェーダとレイシェーダはフレームバッファへの自由なアクセスも可能。ちなみにシェーディング言語はOpenGLの「GLSL」(OpenGL Shading Language)文法をそのまま踏襲した「RLSL」(OpenRL Shading Language)が採用されている。
……と,ここで,この分野に詳しい人なら,OpenRLがOptiXとよく似ていることに気づくはずだ。
右に示したのはOptiXのブロック図だが,「Traversal」がフレームシェーダ,「Ray Shading」がレイシェーダの役割とほぼ同一である。
OptiXはOpenRLの競合技術ではあるものの,OpenRLに対応する意志があるなら,OptiXからの対応が,技術的にそれほど難しくはないことが想像できよう。
ゲームグラフィックスのすべてをレイトレーシングでまかなうというのは,遠い将来はさておき,少なくとも近未来的にはかなり無理がある。しかし,画面座標系ポストプロセスのスクリーンスペース・アンビエントオクルージョン(Screen Space Ambient Occlusion,SSAO)や,それをさらに発展させたCrytekのリアルタイム・ローカルリフレクション(Realtime Local Reflections,RLR),そして法線マッピングの発展形であるパララックスオクルージョンマッピング(Parallax Occlusion Mapping)など,局所的に光線を飛ばしてシェーディング情報を得るレイトレーシング手法,言うなれば,レイトレーシングをピクセルシェーダで実践する技術はすでに実現していたりするのも確かだ。
また,リアルタイムの大域照明であるグローバルイルミネーション(Global Illumination,GI)も,レイトレーシング手法とは切っても切り離せない。
さらに続けると,2009年に注目を集めたイメージスペース・フォトンマッピング(Image Space Photon Mapping)は,主要なレンダリングを通常の3Dグラフィックスパイプラインで行い,二次光源の影響を表現するにあたっては局所的なレイトレーシングをおおざっぱに適用するという,ハイブリッドなレンダリング手法だった。
下に掲載したのは,イメージスペース・フォトンマッピングによるレンダリングの例と,それをGPGPUアクセラレーションしたときのムービーである。

このように,一般的なGPUで実践されているラスタライズベースのレンダリング手法でも,次のステップとして表現力を獲得するためにレイトレーシング的手法を融合させようという動きが自然発生的に起きているのだ。
こうした流れのなかで,レイトレーシングアクセラレーションの業界標準的な取り組みが始まったことは,決して早すぎるものではない。
また,本稿でも少し触れたように,レイトレーシングアクセラレーションは,その仕組みをデータ並列コンピューティングにも応用できるので,物理シミュレーションをRTUの機能で実行するのも不可能ではないといえるだろう。
レイトレーシングアクセラレーションの仕組みが実装されれば,有効な活用方法が見出せるわけだ。
DirectX 11登場後,やや停滞感がある3Dグラフィックスハードウェアの世界において,OpenRL,そしてレイトレーシングアクセラレーションの動向は,大きなカンフル剤になるかもしれない。
それは,「PowerVR」を有する英Imagination Technologies(以下,Imagination)だ。
知っている読者も多いと思うが,iPhoneやiPadで採用されているGPUはPowerVRコア。Intel製Atomプロセッサの一部に統合されているグラフィックス機能「GMA500」「GMA600」もPowerVRコアだ。さらに,PlayStation Vitaも,搭載するGPUにはPowerVRコアを統合している。
 |
果たして大きなプロジェクトとは何なのか。結論から先に述べてしまうと,ズバリ,「ハイエンドGPU開発計画」だ。
ただこのハイエンドGPU,少なくとも計画初期のフェーズでは,現行のRadeonやGeForceなどと競合する予定はなく,一風変わった製品になりそうなのである。
今回は「ImaginationのハイエンドGPU」について,順を追って解説してみたいと思う。
ハイエンドGPUの正体はRTU「CausticTwo」
 |
Imaginationは,2010年12月にCaustic Graphicsという企業を買収した。
Caustic Graphicsは,レイトレーシングをベースとしたレンダラの開発とレイトレーシングアクセラレータ「RTU」(Ray Tracing Unit)のハードウェア設計を行っていたベンチャー企業で,実際,2010年に「CausticOne」という第1世代のRTU搭載カードを発表していたりする。
で,現在,ImaginationとCaustic Graphicsは共同で,第2世代のRTUとなる「CausticTwo」(開発コードネーム)を開発中だ。第1世代のCausticOneが,動作クロック100MHzのFPGAを2基搭載した,いかにもテスト基板といったPCI Express x1カードだったのに対し,CausticTwoでは,レーン数などは不明であるものの一般的なPCI Express接続型拡張カードに,フルカスタムの高速ASICを載せたものになる見込みだ。つまり,CausticTwoで搭載されるこの高速ASICこそが,「ImaginationのハイエンドGPU」の正体ということになる。
CausticTwoは,ディスプレイ出力を備えていないため,“レイトレーシングアクセラレータ”として,既存のグラフィックスカードと併用される。だからこそ,現行のRadeonやGeForceと競合しないわけだ。
「グラフィックスカードと併用」というと,かつてAGEIA Technologiesが発表した物理シミュレーションエンジン「PhysX」と,そのアクセラレータとにイメージが被るだろう。ご存じのとおり,AGEIA TechnologiesはNVIDIAに買収され,PhysXがNVIDIAのGPGPUソリューションへと取り込まれている。アクセラレータの役割もCUDA CoreベースのGPU(≒GeForce)が取って代わっており,RTUにもこうした行く末が見えているわけだが,Imaginationの認識は「想定の範囲内」。なかなか潔い。
レイトレーシングのポテンシャルを盛り込む次世代PowerVR
先ほど,CausticTwoはデスクトップPCやワークステーションに差せるという話をしたが,Imaginationは本製品を,民生向けではなく,業務用としてリリースする予定だ。そして,そこで得られた技術(など)をPowerVRへフィードバックさせるという戦略ロードマップを敷いている。
残念ながら,今回の取材中,ImaginationはRTUのアーキテクチャに関しては何も語ってはくれなかったのだが,おそらくはベクトル演算器アレイで構成されているはずだ。もっとはっきり言えば,GPUとよく似た設計になっているはずである。
Imaginationは,開発中だという将来の製品「PowerVR RTX」で,レイトレーシング機能を搭載する予定だ。しかし,RTUがGPUとよく似た設計になっている可能性が高いことからすると,「PowerVRにRTUを追加する」というよりは,「3Dグラフィックスのレンダリング用として用意されるシェーダユニットに,RTUとしてのポテンシャルを盛り込む」という形で統合してくることになるものと見られる。
 |
ところで,一般的なGPUの場合,レンダリングの起点をピクセルに置く「ラスタライズベース・レンダリング」(Rasterize Based Rendering)が採用されるが,レイトレーシングにおいてはレイ(光線)起点となるため,当該処理のための「演算器の駆動のされ方」はGPUとはかなり異なる。光線ごとの条件分岐パスがかなり複雑で,ひいては光線ごとの処理時間が異なってくるため,各光線を並列に処理させる場合でも,シェーダユニットの駆動のさせ方や,各データパスの構造設計には,それ相応の最適化や設計の見直しが必要になるのだ。
「組み込み機器向けをメインフォーカスとしたPowerVRにレイトレーシング実行のポテンシャルを付けて無駄にならないか?」と考える人はいるかもしれない。実際,その疑問は的を射ていると思うが,Imaginationはこれを無駄とは考えていない。レイトレーシングのような比較的複雑なロジックを並列実行できるポテンシャルは,GPGPU用途,つまり,データ並列コンピューティング用途にも効力を発揮するからだ。
もともと組み込み機器向けGPUであるPowerVRにとって,3Dグラフィックスレンダリングだけでなく,信号処理,認識処理のようなデータ並列コンピューティング用途にもGPUコアを流用できるようになるのは願ったり叶ったりだ。実際,世の中の動きとして,組み込み機器向けのGPUをデータ並列コンピューティングでも使うべくOpenCLへ対応させる動きも活発だったりする。
 |
 |
レイトレーシングアクセラレータとして成功すればもちろんそれでよし。ダメでも,GPGPU用途――PowerVR系なのでOpenCL用途――での性能向上に結びつくのであれば無駄にならない。
ImaginationとCaustic Graphicsとのタッグプロジェクトは,「どう転んでも損はない」という読みの下に進められているわけである。
オープンスタンダードなプログラマブルレイトレーシングAPI「OpenRL」
ただ,「レイトレーシングのハードウェアアクセラレーション」と言ったところで,Imaginationだけががんばっていてもエコシステム(ecosystem。ここでは「業界全体の収益構造」の意)は育たない。ラスタライズベースの3Dグラフィックスも,DirectX(Direct3D)やOpenGLという標準があるからこそ,ゲームから実用アプリケーションに至るまで,幅広いソフトウェアのエコシステムがなり立っているわけだ。
NVIDIA独自のGPGPUソリューションであるCUDAも,今でこそひとまずの成功を収めたといえるが,その道程は決して楽なものではなかった。ありとあらゆる(並列コンピューティングに向いた)ソフトウェアのジャンルを“CUDAに巻き込む”ような,莫大な投資の末に勝ち取ったデファクトスタンダードなのだ。
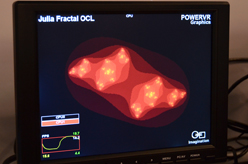
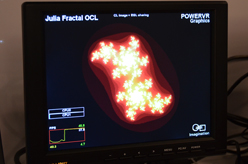
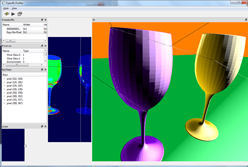
 OpenRLは,レイトレーシングのエコシステムを作り上げるためのプロジェクトだ |
 SIGGRAPH 2011のImaginationブースで実演されていたOpenRLデモの様子 |
現在のところOpenRLはβ版の段階にあり,正式版は「OpenRL 1.0 SDK」として2011年第4四半期にリリースされる予定になっている。
「Open“xx”」ということで,OpenGLなどの規格策定を行っているKhronos Group(以下,Khronos)が絡んでいるようなイメージを抱くかもしれないが,現段階ではあくまでも,ImaginationとCaustic Graphicsによる独自プロジェクトという位置づけ。もっとも,Khronosへ確認したところ,2社との協議を始めているところとのことだった。
AppleのOpenCLや,ソニーの「COLLADA」のように,一企業の独自発案で始まりながらも,Khronos管轄下のオープンスタンダードAPIに組み入れられたケースは少なくない。しかもImaginationは発言力の大きな評議委員(Board of Promoters)としてKhronosに加盟しているため,よほどの独自仕様でもない限り,KhronosがOpenRLを拒絶することはないだろう。近い将来,グラフィックスAPIとして採用される可能性は高い。
 Khronos加盟企業。灰色背景のところにあるのが,発言力の大きい評議委員メンバーだ |
 Khronos管轄下のオープンスタンダードAPIを示したスライド |
なお,Imagintaionが公開している資料には「OpenRLは,AMDやNVIDIAのGPUを用いてもアクセラレーションが可能となる」という記載があるが,この件についてNVIDIAに取材してみたところ,返ってきた回答は,「水面下での動きは正直分からない。広報として公式に言えるのは,我々がレイトレーシングエンジンに(自社開発の)『OptiX』を推奨する立場であることだけだ」というものだった。ただNVIDIAは,OpenCLが登場したときも間を置かずに対応してきたので,OpenRLがKhronos管轄下になれば,そこからの対応は早いはずだ。
AMDには確認できていないが,同社は,“独自仕様GPGPUソリューション戦争”でNVIDIAに敗れてから,Khronos管轄下のオープンスタンダードAPIを協力に支持する立場に回っているため,OpenRLの規格策定にも積極的に協力するのではないかと思われる。
さて,上で紹介したように,OpenRLはバージョン1.0βとしてほぼ完成している。もちろん,Khronosの管轄下に移ればバージョン表記が変わる可能性はあるものの,ひとまず,2011年第4四半期にリリースできる程度にはできあがっているわけだ。
そして,Caustic GraphicsはSIGGRAPH 2011で,このOpenRL 1.0βをベースとしたレンダリングエンジン(=レンダラ)も発表している。その名は「Brazil 3.0」。開発担当は,Caustic Graphicsの子会社であるSplutterFishだ。
SplutterFishは,Autodeskの「Maya」「3ds Max」,そしてMcNeelの「Rhinoceros」(以下,Rhino)といった業界標準のツールに向けたレイトレーシングプラグイン「Brazil R/S」を提供してきたソフトウェアスタジオである。
 |
ちなみにBrazil 3.0自体は,「OpenRLをベースとした汎用のレイトレーシングベースレンダラ(とそのSDK)」という位置づけ。WindowsやMac OS X,そしてLinuxといったOSに広く対応し,動作対象ハードウェアも限定されないということになっている。要するに,OpenRLをアクセラレーションできる仕組みがシステムに実装されていれば,Intel製CPU,AMD製CPU,NVIDIA製GPU,AMD製GPU,そしてRTUのそれぞれで,スペックに見当った形のアクセラレーションが得られるというわけだ。
Brazil 3.0の公式紹介動画
Brazil 3.0 SDK from Caustic Graphics on Vimeo.
Optixと構成が似ているOpenRL
 |
つまり,コンセプト自体はOpenGLなどと大きく変わらない。もっとはっきり言うと,特定のライティング表現や材質表現――たとえば大局照明や表面下散乱――といったものを再現するためのAPIのようなものは用意されない。なので,それらは開発者自らがOpenRLを駆使して,目的となる表現を実現するためのメソッドを構築しなければならないのだ。Brazil 3.0は,SplutterFishがOpenRLを用いて構築した,「多彩な表現を実現するレンダラ」ということになる。
OpenRL公式テクニカルデモ動画
OpenRL Heterogeneous Computing Example from Caustic Graphics on Vimeo.
OpenRLの細かい仕様はCaustic GraphicsのOpenRL紹介ページを参照してほしいが,ここでは本質だけ解説しておこう。OpenRLのレンダリングコアは,3つのプログラマブルシェーダによって構成されている。
 |
2つめはフレームシェーダ(Frame Shader)で,これは飛ばす光線を司るプログラマブルシェーダである。。
たとえば,これからレンダリングしようとする1920×1080ピクセルのフレームがあったとして,この視点からの視界(viewport)を定義し,各ピクセルから視界の広がりに沿って光線を飛ばすのが主な役割だ。飛ばした光線が3Dオブジェクトに衝突した場合は,次に説明するレイシェーダが呼び出される。あるいは,衝突した場所からプログラマブルに新たな光線を飛ばすことも可能だ。
というわけで,3つめはいまその名が出たレイシェーダ(Ray Shader)。これは,飛ばされた光線が3Dモデル上にあるサーフェス(=ポリゴン)やそのほかのプリミティブと衝突したときに呼び出されるプログラマブルシェーダである。
たとえば,ある3Dキャラクターの部位に光線が衝突したとしよう。衝突したサーフェスが磨かれた金属である場合は,その入射してきた光線に対して鏡面反射する方向に新しい光線を生成して飛ばす処理を行うわけだ。一方,シンプルな疑似(算術的)ライティングでよいなら,適当な代表光源と視線,法線の3パラメータを使って適当なライティング計算でまかなえる。
そう,レイシェーダは,一般的なGPUにおけるピクセルシェーダにかなり似たシェーダなのだ。
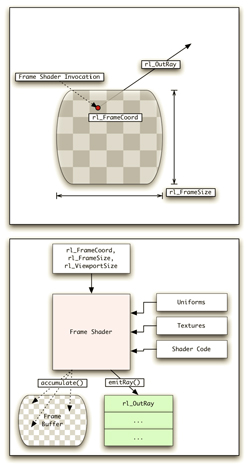 Frame Shaderの概要 |
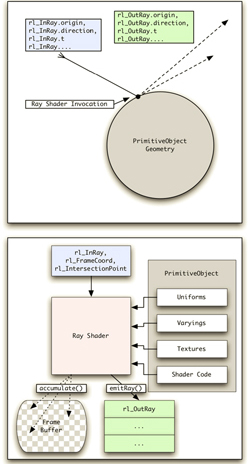 Ray Shaderの概要 |
3つのシェーダとも,テクスチャの参照が可能で,とくにフレームシェーダとレイシェーダはフレームバッファへの自由なアクセスも可能。ちなみにシェーディング言語はOpenGLの「GLSL」(OpenGL Shading Language)文法をそのまま踏襲した「RLSL」(OpenRL Shading Language)が採用されている。
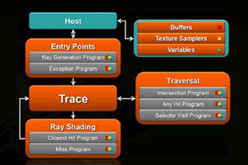 |
右に示したのはOptiXのブロック図だが,「Traversal」がフレームシェーダ,「Ray Shading」がレイシェーダの役割とほぼ同一である。
OptiXはOpenRLの競合技術ではあるものの,OpenRLに対応する意志があるなら,OptiXからの対応が,技術的にそれほど難しくはないことが想像できよう。
OpenRLは新しい3Dグラフィックスの世界を切り開くのか
ゲームグラフィックスのすべてをレイトレーシングでまかなうというのは,遠い将来はさておき,少なくとも近未来的にはかなり無理がある。しかし,画面座標系ポストプロセスのスクリーンスペース・アンビエントオクルージョン(Screen Space Ambient Occlusion,SSAO)や,それをさらに発展させたCrytekのリアルタイム・ローカルリフレクション(Realtime Local Reflections,RLR),そして法線マッピングの発展形であるパララックスオクルージョンマッピング(Parallax Occlusion Mapping)など,局所的に光線を飛ばしてシェーディング情報を得るレイトレーシング手法,言うなれば,レイトレーシングをピクセルシェーダで実践する技術はすでに実現していたりするのも確かだ。
また,リアルタイムの大域照明であるグローバルイルミネーション(Global Illumination,GI)も,レイトレーシング手法とは切っても切り離せない。
さらに続けると,2009年に注目を集めたイメージスペース・フォトンマッピング(Image Space Photon Mapping)は,主要なレンダリングを通常の3Dグラフィックスパイプラインで行い,二次光源の影響を表現するにあたっては局所的なレイトレーシングをおおざっぱに適用するという,ハイブリッドなレンダリング手法だった。
下に掲載したのは,イメージスペース・フォトンマッピングによるレンダリングの例と,それをGPGPUアクセラレーションしたときのムービーである。
 直接光のみのライティング。現状の標準的な3Dグラフィックスパイプラインのリアルタイムレンダリングで行えるライティングはこれだけだ |
 グローバルイルミネーションを考慮せず,一様に定数的環境光を付加するとこのようになる。ある意味,これが見慣れた「普通の3Dゲームグラフィックス」といえる |
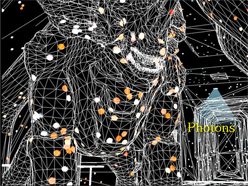 間接光の影響をGPGPUによるレイトレーシングでフォトンマッピングしているところ |
 フォトンマッピングにより正確な間接光照明を算出するとこのようになる |
 |
このように,一般的なGPUで実践されているラスタライズベースのレンダリング手法でも,次のステップとして表現力を獲得するためにレイトレーシング的手法を融合させようという動きが自然発生的に起きているのだ。
こうした流れのなかで,レイトレーシングアクセラレーションの業界標準的な取り組みが始まったことは,決して早すぎるものではない。
また,本稿でも少し触れたように,レイトレーシングアクセラレーションは,その仕組みをデータ並列コンピューティングにも応用できるので,物理シミュレーションをRTUの機能で実行するのも不可能ではないといえるだろう。
レイトレーシングアクセラレーションの仕組みが実装されれば,有効な活用方法が見出せるわけだ。
DirectX 11登場後,やや停滞感がある3Dグラフィックスハードウェアの世界において,OpenRL,そしてレイトレーシングアクセラレーションの動向は,大きなカンフル剤になるかもしれない。
 |
 |
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー