2024年3月に行われたGDC 2024で,「
FP16 Shaders in Frostbite」という一風変わったテーマを掲げていたセッションがあった。
簡単に言えば,Electronic Arts(以下,EA)の独自開発ゲームエンジン「
Frostbite」で,16bit浮動小数点数(FP16)を徹底活用して性能を改善できるか検討したというものだ。
セッションを担当したAlexis Griffin-Lira氏(Software Engineer,Frostbite. EA)。Frostbiteエンジン開発チームの一員だ
 |
 |
近代ゲームグラフィックスでは,頂点シェーダが扱うジオメトリ(幾何学)的な演算において,単精度と呼ばれる32bit浮動小数点数(FP32)を活用することが多い。一方で,ピクセルシェーダが扱うテクスチャを絡めたピクセル演算では,FP16がよく使われるものの,途中の演算はすべてFP32で行う実装になっている事例も少なくはない。
ではなぜ,このタイミングでEAは,FrostbiteエンジンのFP16最適化に取り組んだのか。それは,スマートフォンや携帯電話,Nintendo Switchのような,演算性能やメモリ性能が高くないハードウェアでは,FP16のほうが演算負荷やメモリ負荷を低く抑えられるので,FP32演算時よりも高い実効性能が引き出せる可能性があるからだ。
というわけで,開発チームによる取り組みと,その結果について見ていこう。
FP16とはなにか
本題に入る前に,浮動小数点とは何かのおさらいをしておきたい。
浮動小数点とは,「小数点が動く」仕組みを取り入れた,小数を含む実数の表現手段である。正負を表す符号ビット(Sign 0が正,1が負を表す)と,指数項(Exponent),仮数項(Mantissa)からなり,実際の値としては「(−1)^(符号)×仮数×2^(指数項)」で表す。
FP32とFP16の場合,内訳はこうなる。
- FP32:符号1bit,指数項8bit,仮数項23bit
- FP16:符号1bit,指数項5bit,仮数項10bit
仮数項は,仮数の最上位ビットが必ず「1」になるように決まるので,これを省略するのが仕様だ。そのため,実行桁数は「仮数の有効ビット数+1」となる。つまり,FP32の有効桁数は24bit,FP16の有効桁数は11bitだ。
FP32とFP16の違い。FP32で仮数が24bitとあるが,23bitの間違い
 |
FP16はもともと,映画「スター・ウォーズ」の監督で知られる
George Lucas氏により,同作の特撮部門として作られた映像制作スタジオ「Industrial Light&Magic」(ILM)が,1999年に提唱した「
OpenEXR」が起源となっている。「現実世界と同等品質の情景をCGで表現するためには,3原色の赤緑青(RGB)の表現幅を,人の目における感度の上限である120dB相当にすべきだ」という根拠をもとに,ILMがFP16形式を提唱したのだ。2008年には,浮動小数点表記の標準規格である「IEEE754」の拡張仕様「IEEE754-2008」にて,FP16が正式に採用された。
こうした経緯で生まれたFP16のダイナミックレンジは,ちょうど120dBである。一方,FP32のダイナミックレンジは830dBもあり,オーバースペックなのだ。ちなみに,8bit整数は24dB,16bit整数は48dB,32bit整数は96dBである。
ゲームグラフィックスの世界では,DirectX 9世代GPUがハイダイナミックレンジ(HDR)レンダリングに対応したことで,2000年代初頭からゲーム業界でもOpenEXR相当のFP16が活用され初めた。今では,GPUがFP16を処理できるのは当たり前だ。さらに,GPUで汎用演算を行う「GPGPU」でもFP16が利用できるようになり,これが機械学習におあつらえ向きだったことから,AIの研究開発にGPGPU活用が盛んとなったのは,あまりにも有名な話である。
FP16の優位性。しかし,乗り越えるべき壁は高い
セッション冒頭にGriffin-Lira氏は,FP16の優位性と,FP16ならではの課題を上げた。
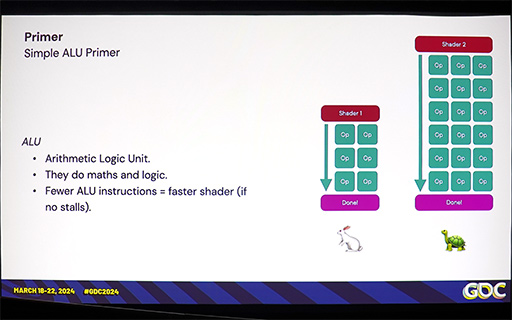
たとえば,FP16はFP32の半分の長さであるために,多くのGPUで,ひとつの32bitレジスタに2つのFP16を収納できることから,レジスタの利用効率が良くなる。演算器が32bitレジスタに2つのFP16をパックした形式で演算できれば,演算器の稼動率を上げやすくなるので,理論的にはFP32に対して2倍の演算性能が期待できるという理屈だ。
32bitレジスタに2つのFP16を入れる(パックドする)ことができれば,レジスタの利用効率が上がる
 |
レジスタの利用効率が良いと,GPUが同時に実行できるスレッド数も多くなる。
レジスタの利用効率が良ければ,GPUが多くのスレッドを同時実行しやすくなる
 |
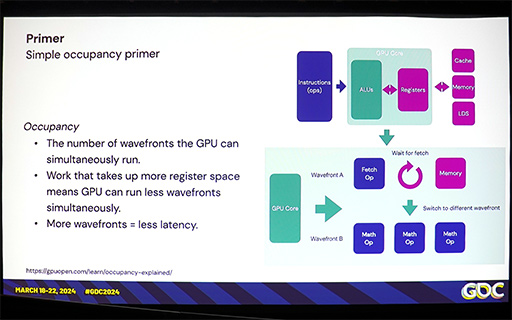
また,演算結果をレジスタからメモリに書き出すときも,メモリ帯域幅の消費量がFP32の半分で済むというメリットもある。
複数のFP16をパックドしたレジスタに対してひとつの命令で演算できれば,占有する演算器も少なくて済む
 |
もちろん,FP16にもデメリットはある。それは演算精度が低くなること。FP16は,ダイナミックレンジがFP32と比べて7分の1程度しかないので,巨大な絶対値を表現できない。またFP16は,FP32に対して有効桁数が少ないことから,多段演算で誤差が蓄積する傾向が強い。
誤差は結果的に「見た目の悪さ」につながることがある
 |
とくに,多ポリゴンによるジオメトリ表現をFP16に丸め込んで行おうとすると,遠近が正確に表現できず,破綻しやすくなる。
ジオメトリ処理をFP32からFP16に丸め込んで描画した例。ディテール部のポリゴンは,前後関係がおかしくなり,隠面処理が正常に働かなくなって奇妙な描画になった
 |
 |
そこで,Frosbiteエンジン開発チームは,エンジンが有する各種シェーダと,その実行を担当するGPUドライバ(ハードウェアドライバ)との間に,FP16化するための抽象化レイヤー「FP16 API」を挟み込む仕様を実装した。これを活用することで,Frostbiteエンジン上の各種シェーダをFP16化する実験を試みたそうだ。
シェーダプログラムとGPUドライバの間に,抽象化レイヤー「FP16 API」を設けて,FP16化を効率よく行うような仕組みを構築
 |
シェーダプログラムのHLSL(High Level Shading Language)ソースコードを各プラットフォームで実行バイナリにしていくパイプライン
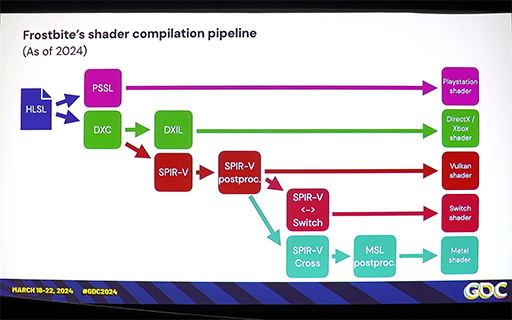 |
ここでGriffin-Lira氏は,FrostbiteのFP16 APIの設計において,対象ハードウェア(GPU)を3種類にカテゴリー分けしたと述べる。つまり,3種類の対象ハードウェアを3段階のFP16対応レベルに分けて,FP16 APIを設計したということだ。
「Full FP16」は,FP16をフルサポートできるハードウェアだ。定数バッファも16bitで定義される。いうなれば,最も理想的なFP16化を期待できるハードウェアになる。
次の「Relaxed FP16」は,FP16の対応度が少々低めのハードウェアだ。具体的には,「この命令はFP16対応だが,この命令はFP32対応」というパターンだ。このハードウェアカテゴリーでは,定数バッファが32bit仕様となる。
最後の「Remapped FP16」は,FP16の対応度が著しく低いハードウェアだ。そのため,ソフトウェア的にFP16からFP32への変換コードが,適宜介入する仕様となる。こちらも定数バッファは32bit仕様だ。
FP16の対応度合いに応じて,ハードウェアを3種類にカテゴリー分けした
 |
カスタム定義した型。「fb」はFrostbiteの略。「half」はFP16,「short」はInt16(16bit整数),「u」は符合なしを意味する。「2/3/4」はベクトルで,2x2/3x3/4x4は行列だ
 |
各ハードウェアカテゴリにおいて,カスタムの型からどう変換されるかを示したスライド。「min」が前に付く型は,最小精度を明示的に宣言するが,ハードウェアが非対応の場合は無視できるゆるい宣言だ
 |
実行結果に関しては,要素テストを開発して,対象ハードウェアがどの程度の品質で描画しているかを,視覚的にチェックできるようにしたという。
品質チェックテストは,見た目で分かりやすいものを開発
 |
テストプログラム群と成否を示している画像
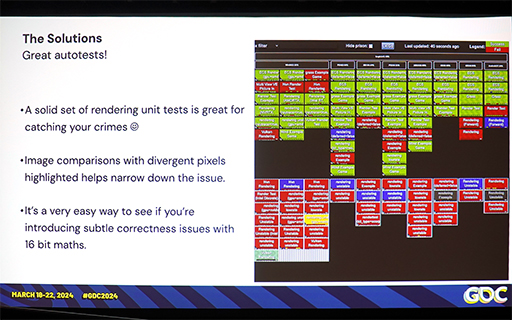 |
テストプログラムの結果例
 |
ところが,実際にさまざまなプラットフォーム(≒GPU)で結果を検証したところ,正しい動作をしていそうなプラットフォームにおいても,FP16化が性能向上につながったか否かは,まちまちだと分かったという。つまり,FP16にしても簡単には速くならないプラットフォームが,そこそこ存在したわけだ。
また,特定の処理系をFP16で行った場合の振る舞いが,プラットフォームごとに変わることもあったそうだ。
詳しく調べてみたところ,同じシェーダプログラムのソースコードをコンパイルしても,プラットフォームごとに異なる意味のFP16ネイティブ命令を出力することが分かったという。
こうした現象は,コンパイル後のシェーダプログラムが「
SPIR-V」のような中間言語を経由する場合に,とくに発生しやすい。たとえば,シェーダプログラムのHLSLソースコードと,コンパイル後のSPIR-Vコード,そしてハードウェアレベルのネイティブ命令のそれぞれに表現力の違いがあった場合,FP16への単純な置き換えは,かなり困難となる。
FP16化をしても,プラットフォームごとに問題が起きやすい要素
 |
FP16化をしても,ネイティブ命令の振る舞いに一貫性がないもの
 |
こうした問題に対処するには,特定のコードをプラットフォームごとに,個別に最適化して対応しなければならない。こうした作業を,仮に手作業で対応するにしても,場合によっては,コード内のFP16〜FP32相互変換コードが増加してしまい,最終的にはFP16の軽さが意味を成さなくなってしまうこともあるようだ。
仮にFP16化して動かせたとしても,FP16〜FP32相互変換コードが,足枷になってしまうプラットフォームもあった
 |
また,FP16の値をGPU側の32bitレジスタに2つ,64bitレジスタに4つ,128bitレジスタに8つ入れられて,さらに命令も,そうしたレジスタ内容に対して一括で演算できたとする。しかし,実際に演算器自体が内部で一括に演算できなければ意味がなく,FP16化がまったく意味をなさないこともあったようだ。
Griffin-Lira氏の肌感では,携帯端末向けGPUは,もともと「FP16を積極活用していこう」という思想で設計されているためか,FP16化の恩恵を得やすかったそうだ。それに対して,PCや据え置き型ゲーム機では,FP16化の恩恵は少なかったと振り返っていた。
PC向けGPUでは,FP16値を32bit以上のレジスタにパックする処理系自体が速くなかったり,GCN世代以前のRadeonでは,FP16とFP32のパフォーマンスがまったく変わらなかったりしたようだ。
FP16化によって生じる品質の低下
続いて,Griffin-Lira氏は,FP16化にともなって生じる品質の低下について説明した。
以下に示す2枚のスライドは,FP32ベースのピクセルシェーダによるライティングと,FP16ベースのピクセルシェーダによるライティング結果を示したものだ。
FP32シェーダでの描画結果
 |
FP16シェーダでの描画結果
 |
次のスライドは,各ピクセルの色に1%よりも大きな誤差が検出されたところを,赤い点で印を付けた画像となる。
FP32とFP16の結果を比較して,1%よりも大きな誤差が検出されたピクセルを赤くマーキングした
 |
分かりやすい相違点を拡大したスライド
 |
開発者ではないゲーマーは,その違いに不自然さを感じることはないと思う。だが,「物理ベースレンダリング×HDRレンダリング」を行うと,誤差はそれなりに発生するということだ。
Griffin-Lira氏によれば,FP16とFP32とでは,法線ベクトルや
曲げ法線ベクトルに比較的大きな誤差が生じやすい。そのため,これらのベクトルから算出した反射ベクトルをもとにするライティング結果は,FP32時とFP16時で違いが大きくなるそうだ。具体的には,先に示した相違点の拡大図のような,鏡面反射のライティング結果や鏡像表現に,大きな差が出やすいということである。
もっとも,そのゲーム映像を初めて見たときに,FP16化されたバージョンの品質に目くじらを立てる人は,ほとんどいないだろう。とくにスマートフォン向けゲームであれば,画面も小さいので気にならないのではないかと思う。
品質の差が出やすい部分とは?
 |
ただ,雑多なAndroid端末においては,GPUドライバソフトの完成度が低いことも多い。そのため,シェーダコードに問題がなくても,正体不明のライティング結果になることも多いとのこと。そうした端末での原因探しは,ほとんどあきらめるしかなかったようだ。
ドライバが原因の描画誤差は,ゲームプログラム側で対処のしようがない
 |
ドライバが原因で発生した,謎のノイズだらけの描画例
 |
肝心の描画性能はどうなった?
最後にGriffin-Lira氏は,FP32を主体としたオリジナルのFrostbiteエンジンと,FP16化したFrostbiteエンジンで,テストシーンを描画した場合の描画性能比較を示した。プラットフォームは,PlayStation 5とiPhone 12だ。
テストシーンは,比較で使った宇宙船内シーンのトーンマッピング処理と,テンポラルアンチエイリアシング(TAA)処理,そしてタイルベースのライティング処理の3種類だ。実装は,すべてComputeShaderベースである点に注意してほしい。
宇宙船内シーンのトーンマッピング処理による描画結果(上)と数値での比較(下)。iPhone 12では,FP16化で描画性能が約15%向上。一方,PS5ではほぼ効果なし
 |
 |
TAA処理による描画結果(上)と数値での比較(下)。iPhone 12では,FP16化で描画性能が約23%向上。しかし,PS5ではFP16化したほうが遅くなった
 |
 |
タイルベースライティング処理による描画結果(上)と数値での比較(下)。iPhone 12では,FP16化で描画性能が約23%,PS5でも約12%高速化できた
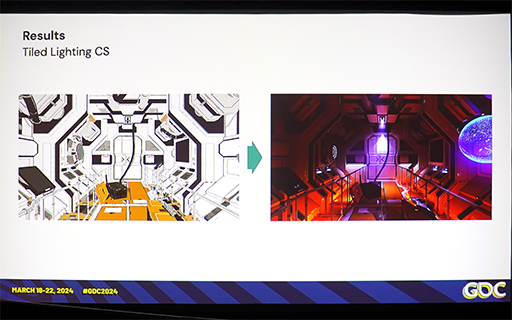 |
 |
結果は,PS5では期待したほどの性能向上は見られず,TAA処理では,FP32のほうが微妙に高速という逆転が起きてしまった。対してiPhone 12では,15〜23%程度の性能向上が見られ,FP16化で恩恵が得られることが分かる。
3種類のテストは,どれもスマートフォン向けGPUが不得意なメモリアクセスが比較的少なく,演算負荷の大小が結果に表れやすいものだ。つまりスマートフォン向けGPUでは,想定どおりにレジスタ利用効率が改善して,並列度も上がったということだろう。
FrostbiteエンジンのFP16化へのモチベーションはどこから?
Griffin-Lira氏は,FrostbiteエンジンのFP16化について,「まだ,すべてを試せたわけではない」と振り返っており,今後は,各GPUが持つ独特なベクトル命令の仕様に合わせた,より深い最適化に挑戦してみたいと述べていた。
次なるステップは,さらなる深い最適化の極みへ。ただし,ソースコードの可読性に不安が?
 |
 |
スマートフォン向けGPUでは,FP16化の恩恵が期待どおりに現れた
 |
それにしても,FrostbiteエンジンチームがFP16化に情熱を上げるのはどうしてなのだろうか。本稿のまとめとして,筆者なりの見解を述べておきたい。
Frostbiteエンジンは,かつての「Unreal Engine 3」と同様に,長らく「その時代のハイエンドプラットフォームに最適化されたゲームエンジン」であった。しかし,ここ最近は,「Unreal Engine 4」以降で開発されたゲームがPC,ゲーム機のみならず,スマートフォン向けにリリースされることも珍しくなくなってきた。
最近では,カプコンのハイエンドプラットフォーム向けとして開発されたゲームエンジン「RE ENGINE」ベースの「バイオハザード」シリーズや,Guerrilla Games製のゲームエンジンの「DECIMA」を使った「DEATH STRANDING」のようなリッチなゲームが,続々とiPhoneやiPadにリリースされている。今や,PCやPS5/4向けに作られたゲームが,スマートフォン向けに移植されることは,珍しくなくなってきている。
おそらく,EAのFrostbiteエンジンも,こうした流れに乗りたいという思惑があるのではないだろうか。













 Frostbite
Frostbite