









テストレポート
Phenom徹底分析(前):ネイティブクアッドコアに意味はないのか?
 |
AMDはかねてからPhenomについて,「ネイティブクアッドコア」(あるいは「真のクアッドコア」)だから競合より優れていると主張してきたが,少なくとも2007年末の時点では,その“優れている”部分,ネイティブクアッドコアの意義を見いだしづらい状況になっている。
だが,本当にネイティブクアッドコアCPUに意味はないのだろうか?
ゲームプログラムのマルチスレッド化が確実に進むかどうかは議論の分かれるところだが,マルチスレッド化の進んだゲームなら,クアッドコアのメリットを間違いなく享受できる。我々ゲーマーとしても,マルチコアCPUの選択肢は多いほうがいいわけで,Phenomに期待したい気持ちのある人も少なくないだろう。Phenomの可能性を感じられる,何かキラリと光る優れた面はないのか。
というわけで今回は,いつものゲームパフォーマンス検証からは少し離れ,これまでPhenomに対して行われてこなかったような,割とくどいテストを実施して,PhenomというCPUに迫ってみた。その結果を3回に分けてレポートしていくことにしよう。
→中編:B2ステッピングのエラッタで何が起こるのか
→後編:動作クロックはなぜ上がらないのか
ネイティブクアッドコアの仕組みと
“なんちゃってクアッドコア”との違いを確認する
 |
問題を整理するには,ネイティブクアッドコアが持つ意義が何なのかを再確認しておく必要がある。
現行のCore 2 Quadは2個のデュアルコアCPUダイを一つのチップ上に載せて,外部バスでつないだ格好になっている。インテルの天野“神様”伸彦氏が指摘した,「なんちゃってクアッドコア」だ。
この形がなぜ「なんちゃって」なのか。それは外部バスでつながった二つのデュアルコアCPUダイ間で頻繁にデータをやり取りしなければならないためだ。例えば“ダイ1”で,あるメモリにデータを書き込んだとしよう。同じメモリを“ダイ2”でも使用している場合,“ダイ1”が書き込んだ結果を“ダイ2”側で取り込まなければならない。そうでないと,“同じメモリにも関わらず書き込まれている内容がダイごとに異なる”問題が発生し,処理が破綻してしまう。
そこでCore 2 Quadでは,二つのダイの間でお互いを監視し合って,データが変更されたかどうかを調べて適宜,データをダイ間でやり取りしている。このやり取りは外部バス,すなわちCore 2 Quadだと1066〜1600MHz動作のフロントサイドバス(FSB)を通じて行われるわけだ。FSBの動作クロックはCPU内部のそれと比べてはるかに遅く,CPU性能の足を引っ張る。
その点,4個のCPUコアが一つのダイに載っているネイティブクアッドコアCPUであるPhenomでは,FSBに関連した問題が起こらない。「だから優れている」というのがAMDの言い分だったわけだ。
要点をまとめると「4個のCPUコアが同じメモリ領域にガシガシとアクセスするようなケースでは,ネイティブクアッドコアの威力が発揮される」ということである。「そもそも,そういうことが起こるのか?」というとケースバイケースだが,ゲームに限定すれば将来的には「十分にあり得る」といっていい。
いまのところ,ゲームのマルチスレッド化は限定されていて,レンダリングをマルチスレッド化する,あるいはサウンド処理だけ別スレッドにする,といった程度に留まっているタイトルが多い。この程度では先のような状況はさほど頻繁には起こらず,いきおい,Phenomの実力は発揮しづらい。
だが,すでにカプコンの「ロスト プラネット エクストリーム コンディション」(以下,ロスト プラネット)ではオブジェクト単位のスレッド化が行われているという。具体的にはカプコンのプログラマーとインテルのソフトウェア技術者による対談記事をがっつり読んでいただきたいのだが,今後,ゲームのマルチスレッド化を進めていくうえで,ロスト プラネットに見られる手法が取られるだろうことはほぼ確実だ。そして,先に掲載した「Phenom 9900/2.6GHz」のプレビューでは,ロスト プラネットにおいて,たしかにPhenomの可能性を感じられる結果が得られている。
もっとも,「ではどれくらい可能性があるのか」「なんちゃってクアッドコアとの違いはどれくらいあるのか」という疑問には,先のテストだけだと答えづらい。もっと分かりやすい形で差が出ないだろうか? 既存のベンチマークは,その種の処理を避けるようになっている(※その理由は後述)ので,今回は表のテスト環境において,筆者自らPhenomの実力が見えそうなコードを書いてテストを実施してみた。
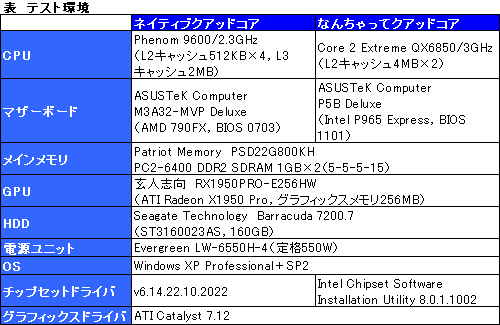 |
 |
さてこのとき,一点注意事項がある。ASUSTeK Computerから借用した「M3A32-MVP Deluxe」は発売前のエンジニアリングサンプルで,本稿のテスト期間中にも頻繁にBIOSが更新された。そして,本テストを実行したときのBIOS 0703では,標準設定でもベースクロックが210MHz程度に固定され,Phenom 9600の動作クロックが2.4GHzになってしまう。そこで,Core 2 Extreme QX6850(以下,C2E QX6850)のベースクロックを266MHzに落とし,同じ2.4GHz動作させることにしている。ただし,このテストでは同一プロセッサの相対的な特性を見ているだけなので,動作クロックは実のところほとんど影響を与えない。
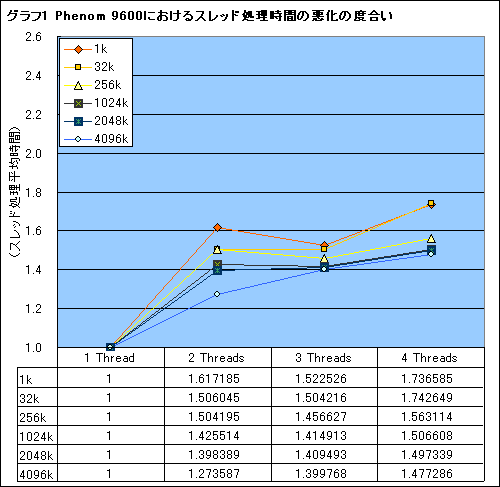
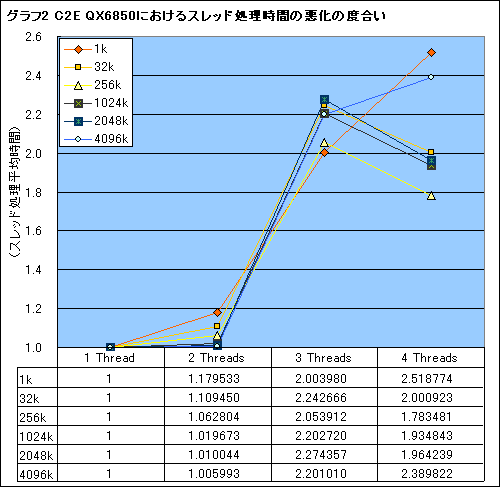
というわけで,テスト結果をまとめたのがグラフ1,2だ。1スレッド時との相対的な比較なので,スコアは1に近い(=1スレッド時の速度に近い)ほうが高速ということになる。
 |
 |
 |
少し解説してみると,Phenomではスレッド数を2〜4と増やしていっても処理時間の悪化が少なく,一方のC2E QX6850では3スレッド以上で処理時間の著しい悪化が見られる。これはC2E QX6850では3スレッド以上(=3コア以上で同じメモリに同時アクセスしたとき)で二つのCPUダイ間におけるデータのやり取りが発生し,スレッドの実行速度に大きな影響を与えているためと見て間違いないだろう。
ところで,グラフ1,2は同一プロセッサの相対的な性能を見ているだけだが,このテストにおけるPhenom 9600とC2E QX6850の絶対的な比較を知りたいという読者もいるだろう。このテストプログラムは元々Phenomの特性を見るために作ったため,アーキテクチャのクセがスコアに影響しやすく,異なるアーキテクチャの比較には向いていないのだが,メモリサイズ1MB以上ではアーキテクチャのクセが誤差範囲で,スコアが異なるアーキテクチャの比較にも使える。
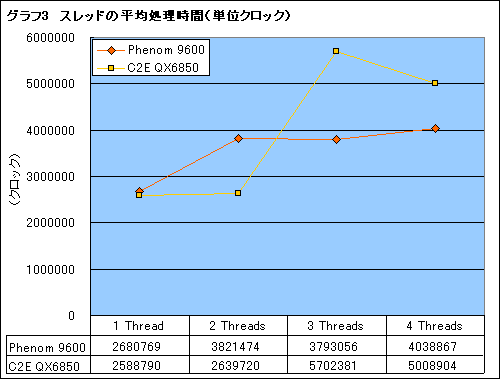
そこで,メモリサイズ1024kBにおけるスレッドの平均実行時間で両CPUを比較してみた。その結果をまとめたのがグラフ3だ。単位は処理にかかったクロック数なので低いほど速い。1〜2スレッドではCore 2 Quadのほうがよりよいスコアを出しているが,3スレッド以上ではPhenomがCore 2 Quadを圧倒することがよく分かるだろう(「PhenomがCore 2 Quadを圧倒する」などという文句が飛び出した記事は本稿が世界初かもしれない?)。両者の差は4スレッド並列実行時で平均100万クロック。決して無視できないものだ。
 |
ではなぜ,この結果が例えばロスト プラネットなどでストレートに反映されないのだろうかという疑問も出てくる。グラフ1,2にあるような差があれば,先日のプレビューで掲載したロスト プラネットの結果は,もっとPhenom 9900有利でもよかったのではないか,という疑問だ。
理由は推測しかできないが,可能性としては,多くのアプリケーションで,今回のテストで行ったような「大きなメモリ領域を複数スレッドで共有する」処理を避けていることが原因として考えられるかもしれない。
というのは,Intelが公開している「IA-32 インテル アーキテクチャー最適化 リファレンス・マニュアル」という文書の中に「(筆者が独自に行ったテストのような処理は)行うべきではなく,行う必要があるなら工夫せよ」と明記されているからだ。
 |
2007年が終わろうとしているこの時点において,主流はデュアルコアCPUや,デュアルコアCPUダイ×2のクアッドコアCPU。この状況でスレッド間のデータ共有を試みるのはペナルティが大きいため,このガイドラインの文章は妥当なものといえる。よって,多くのソフトウェア技術者はガイドラインに沿って何らかの工夫を凝らしている可能性が高い。例えば,「共有するメモリブロックを各コアのローカルメモリ領域にコピーしてアクセスし,変更の結果を適当な間隔で(そのオーバーヘッドが隠蔽されるよう)別のコアに反映させる」といった形に変えて最適化を行うわけだ。そのような最適化を行ったアプリケーションでは,ネイティブクアッドコア(=Phenom)となんちゃってクアッドコア(=Core 2 Quad)の差は出づらくなり,後者に前者が“押される”形にならざるを得ないと考えられる。
Phenomの複雑なキャッシュ構成を理解する
L3キャッシュは効いている? 効いていない?
先ほどのテストで筆者は「Phenomが優秀な結果を残した」と述べたが,C2E QX6850は1〜2スレッドだとほとんど実行時間の悪化がなく,2スレッドまではPhenom 9600より優秀だ。一方,Phenomでは2〜4スレッドにおける性能低下は少ない一方,2スレッドから性能の悪化が見られる。
その理由は,Core 2 Quadが2コアごとに共有のL2キャッシュを持ち,Phenomでは各コアに独立したL2キャッシュを持つためだろう。
もっとも,Phenomは4コアで共有する容量2MBのL3キャッシュを持つことがウリの一つ。それだけに,「L3キャッシュが機能しているのなら2スレッド以上の処理時間の悪化がさらに少ないはずでは?」という疑問を持つ読者はいるはずだ。
実は,AMDが伝統的に「Victim Cache」と呼ばれる手法を採用していることが問題を複雑にしている。
(本記事をここまで読み進めてくれるような読者なら)ご存じのとおり,キャッシュメモリはメインメモリの内容を一時的に溜めておくバッファである。メインメモリは遅いので,CPU内部の高速なキャッシュに一時的にデータを転送しておき,キャッシュに対してアクセスすることでメインメモリの遅さをカバーしているわけだ。そして現在のCPUはキャッシュに階層(Level)構造を取っている。L1,L2というアレである。
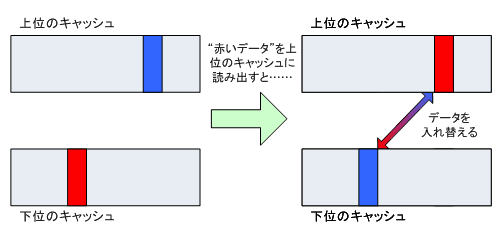
Victim Cacheは,下位のキャッシュからデータを読み取るときに,読み取るデータを下位のキャッシュから消して読み取り,空いたスペースに上位のキャッシュから溢れたデータを入れる(要するに上位と下位でデータを入れ替える)という動作を基本にするキャッシュ制御手法だ(図1)。メインメモリから最下位階層のキャッシュへ読み出すときにも,使用頻度の低いデータをメインメモリに書き戻す。ちなみにVictimではない一般的なキャッシュだと,内容に変更のあったデータを下位のキャッシュやメインメモリへ単純に書き戻したり,キャッシュに読み出したりする。
 |
Victim Cacheの利点は「全階層のキャッシュに重複したデータがないため,キャッシュ容量を有効に使える」ことや「制御法を工夫することで読み出し/書き戻し動作を最適化しやすい」ことなどが挙げられる。
だが,実際に有利かどうかは非常に難しい問題で,有利というデータもあれば,そうでもないというデータも存在する。IntelはVictim Cache手法に積極的でないが,AMDは積極的に使っているという違いも,Victim Cache手法が有利かどうかについて考え方が分かれていることの現れだ。実は,このPhenomの複雑なキャッシュ制御と階層が例のErrata問題に絡んでくるのだが,それは後の話題に取っておくことにしよう。
AMDはPhenomの3階層キャッシュでもでVictim Cache手法を使っているとしている。そして,PhenomではL1およびL2をコアごとに独立して持っているので,先のテストのように4コアで共有しつつ激しくアクセスされるメモリは「キャッシュのどの階層で共有しているのか」という疑問が出てくる。
仮にL3を共有するとすると,Victim Cache手法を使っているのなら,L2にある共有データをいったんL3に書き出し(※このときL2←→L3のデータの入れ替えかL3からメインメモリへの書き戻しが発生する)それを別コアのL2に読み出す(※ここでも入れ替えが発生する)形になる。だが,これはあまりにもオーバーヘッドが大きすぎ現実的でない。何か特別な方法を使っているのだろうと推測できる。
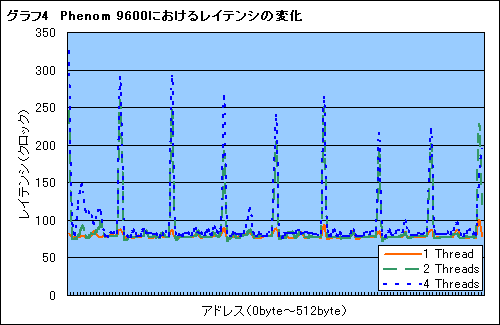
そこで,グラフ1,2と同じ条件で,同じメモリ領域に1,2,4コアで同時アクセスし,0〜512bytes間における,アクセス時のレイテンシ変化を取ってみた。その結果をまとめたのがグラフ4,5だ。
 |
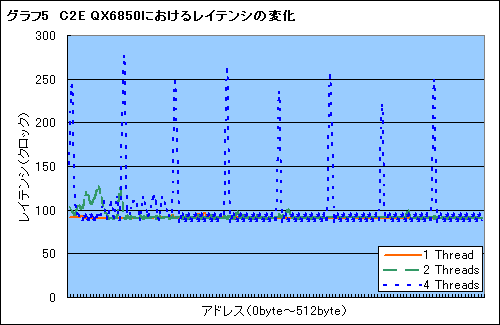 |
少し分かりにくいかもしれないが,オレンジの実線が1スレッド時,緑の波線が2スレッド時,青の点線が4スレッド時を示す(※それぞれクリックすると拡大版を別ウインドウで表示します)。縦軸がレイテンシ,横軸がメモリの位置(メモリオフセット)である。プログラムでは低位メモリから高位に順にアクセスを行っている。また,いったんメモリの全域アクセスを行い,キャッシュにヒットさせてからレイテンシを計測している。
両グラフから,非常に面白いことが分かる。キャッシュは「キャッシュライン」という単位でデータを更新する。L2キャッシュのラインサイズはPhenom,Core 2 Quadともに64bytesだが,64bytesおきにレイテンシが跳ね上がっていのだ。これはキャッシュライン単位でデータの更新が入っているためである。
さらによく見ると,Phenomでは1スレッド時にライン単位の更新(=レイテンシ)がほとんど入らず,2スレッド以上で入る。一方のCore 2 Quadでは1,2スレッド時に更新が入らず,4スレッドの時のみ更新が入っている。
これはどういう意味なのか。Core 2 QuadはVictim Cacheを使用せず,2コアで共有するL2キャッシュを持つ。そのため2スレッドまではキャッシュラインの更新は行わずにデータアクセスができる。一方,PhenomではL2がコアごとに独立しているため,2スレッド以上でキャッシュの更新が入ってしまう,と読める。
言い換えると「Phenomも複数のコアで同じメモリ領域にアクセスするときにはペナルティ(=コア間のデータのやり取り)がある」ということである。このやり取りはCPUダイの中で行われているため,外部バスに出るCore 2 Quadよりはペナルティが小さいと想像できるが,それでもペナルティはあるのだ。
もっとも,このデータだけでは「Phenomがコア間でどうやってデータのやり取りを行っているのか」までは分からない。L3を介しているのか,またはコア間でクロスバー(内部バス)を通じてデータをやり取りしているのか。先に述べたようにL3で共有するのは(Victim Cacheに従う限り)非常にオーバーヘッドが大きいので,後者の方が可能性が高そうだが,はっきりしたことは不明としかいいようがない。
ちなみに,システム情報ツール兼ベンチマークソフト「Sandra XII」(2008.1.13.12)に用意されたコア間のメモリ転送レートを計るベンチマーク「Inter-Core Bandwidth」ではPhenomがとんでもなく酷いスコア記録してしまう(グラフ6)。
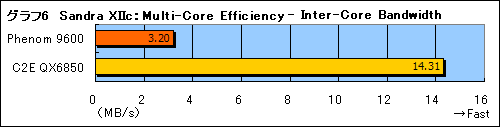 |
PhenomのスコアはざっとCore 2 Quadの4分の1。ただ,先にも紹介したロスト プラネットのスコアなどを考えても,これほど酷いスコアはちょっとあり得ないように思える。このテストはCore 2 Quadを想定し,異なるコア間で8〜32KBのデータを転送するというものなので――実際に内部で行っている処理は分からないが――Phenomでは意味のない計測を行っているのかもしれない。
いずれにせよ,3階層かつVictim Cacheという複雑なキャッシュを使用するよりも,Core 2 Extremeのように,単純にコア間で共有する巨大なL2を持った方が有利では? と思えるのだが,この辺りの設計はアーキテクトの考え方次第としか言いようがない。メモリを共有しないマルチプロセス(※異なるプロセスを複数,動作させる)では,この3階層+Victim Cacheがパフォーマンスが高い可能性もある。とくにサーバー系では,仮にマルチスレッド化されていてもメモリを緊密に共有するケースは多くはない。
 |
Phenomが,サーバー用のプロセッサである「Quad-Core Opteron」のデスクトップ版ということを考えると,この複雑な,ケースバイケースでペナルティが発生するキャッシュ構成を取っていることを納得できるかもしれない。
……前編はここまで。26日掲載予定の中編では,“話題の”Errata(エラッタ)など,Phenomの謎についてさらに掘り下げる予定だ。
- 関連タイトル:
 Phenom
Phenom
- この記事のURL:
(C)2007 Advanced Micro Devices, Inc.
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー