









ニュース
2017年に登場するARMの新CPUコア「Cortex-A73」と新GPUコア「Mali-G71」は,どんな特徴を備えているのか
 |
日本で販売されているスマートフォンで広く使われているSoCには,ハイエンド系がQualcommのSnapdragonシリーズや,
そしてこれらのうち,SamsungやMediaTekのSoCは,ARM製のCPUコアとGPUコアを組み合わせた製品が主流だ。
ARMは,CPUコアだけでなくGPUコアにも力を入れており,これらの処理性能をさらに上げようとしているのだが,性能向上を制約する問題として必ず出てくるのが,消費電力や発熱,そしてバッテリー駆動時間だ。
図1は,2010〜2016年のハイエンドスマートフォンを比較した,ARMによるスライドを引用したものである。より薄く,より高性能を追求し続けているのが分かるだろう。
 |
ところが,筐体が薄くなるというのは同時に,表面温度を低く抑える工夫,たとえばヒートパイプのような仕組みを盛り込むことが難しくなるということでもある。そうなると,スマートフォンが熱くなりすぎて素手で持てなくなくなるのを避けるために,動作クロックを下げて発熱を減らすしかない。
ARMが示したスライド(図2)では,性能と消費電力や発熱は,トレードオフの関係にあると示しているが,薄型化によって表面温度を抑える工夫がしにくくなるということは,温度を抑えるために処理性能が制約されてしまうことにもつながるわけだ。
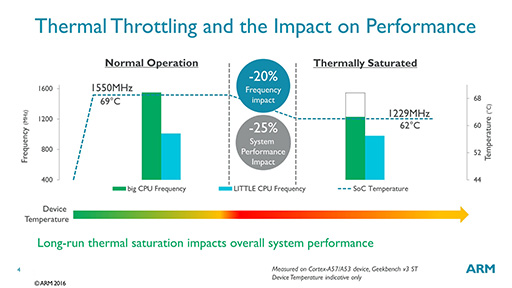 |
こうした問題に対する解決策としてARMが2016年6月に発表したのが,新型CPUコアの「Cortex-A73」と,新型GPUコアである「Mali-G71」のセットである(関連記事)。
本稿では,これら新型CPUコアとGPUコアの特徴について,解説してみたい。
2015年のCPUコアと比べて,10nmプロセスで2倍の性能向上を謳うCortex-A73
まずはCortex-A73から説明していこう。
ARMはCortex-A73の特徴を,従来のCPUコアである「Cortex-A72」と比較して,処理性能と電力効率が3割向上したことや,ダイ全体のうち,CPUコアが占める面積である「エリアサイズ」の縮小を実現したことであるとアピールしている(図3)。
 |
ARMは,同一消費電力に設定したCPUコアによるベンチマークテストの結果を示し,Cortex-A73は2015年のハイエンドCPUコアであった「Cortex-A57」に対して2.1倍,Cortex-A72との比較では1.3倍も高性能であるという(図4)。
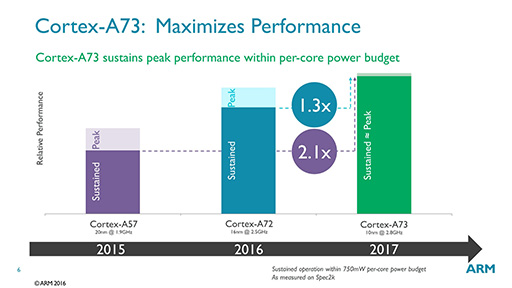 |
図4を見ると,Cortex-A73の動作クロックが2.8GHzなのに対して,Cortex-A72は2.5GHz,Cortex-A57は1.9GHzとなっているので,クロック自体も上がっている。ただ,ARMが主張する性能向上の度合いは,動作クロックの向上分よりも大きいので,クロック以外での性能向上が大きいことになる。この性能向上を,ARMはどうやって実現したのだろうか。
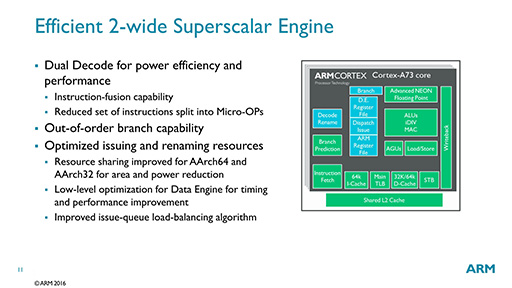
まず,要である命令パイプラインは,「Cortex-A15」からCortex-A72まで利用してきた「3命令デコード8命令同時発行」のアウトオブオーダー構造(関連記事)を捨て,2命令デコードとしたことがポイントだ(図5)。
同時にデコードできる命令数が減るというのは,普通に考えると性能が下がりそうに思える。だがARMによれば,Cortex-A73の性能は実際に向上しており,同一のプロセスで製造したCortex-A73とCortex-A72を同一の動作クロックで動作させて比較すると,Cortex-A73では5〜15%ほどの性能改善が見られると,ARMは主張している。
 |
なぜこのような逆転現象が起きているのか。その理由の1つに,Cortex-A15〜A72までのCPUコアは,モバイル用途だけでなく,サーバー用途のようなヘビーなワークロードでの利用を念頭に置いた,性能重視のCPUコアであるという事情があった。
ここでいうヘビーなワークロードとは,大量の処理やアプリケーションを同時に実行するデータ処理量が多い用途を示す。ところが,モバイル向けCPUコアでは,このような使い方はあまりされない。その結果,ヘビーなワークロードを念頭に置いた3命令デコードのアウトオブオーダー構成は,モバイル向けではフルに活用されているとは言いがたい状況にある。
これに対してCortex-A73は,サーバー用途でのヘビーなワークロードに向けた仕様をばっさり切り落とし,モバイル向けアプリケーションの性能に最適化した。2命令のアウトオブオーダーでも十分性能が出ているというのが,ARMの主張であるわけだ。
モバイル向けへの最適化には,消費電力あたりの性能改善と,性能そのものの向上という2通りの手法を用いているという。
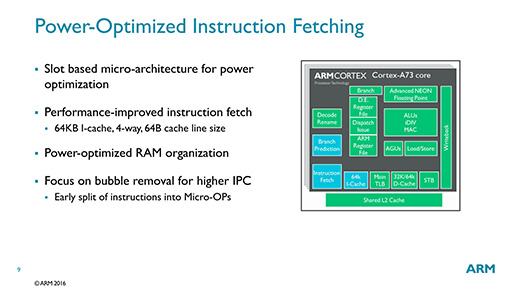
たとえば,消費電力あたりの性能改善では,命令のフェッチに「スロット」という概念を導入した点が挙げられる。Cortex-A73は8つのスロットを持ち,それぞれのスロットが独立して,ARM命令の塊を管理できる仕組みを備えるという。小さな命令ループの管理であれば,1つのスロットがまとめて処理できるので,命令ループの変換に便利であり,結果として命令フェッチの省電力化につながるということだ(図6)。
 |
また性能向上に関しては,連続して命令の解釈と実行を行うときに,この流れを途切れさせるような処理(※バブルと呼ばれる)を排除するための改良を導入している。これは,クロックあたりの命令実行数(Instructions Per Clock,以下 IPC)を上げるというよりも,IPCを下げないことに注目した改良といえよう。
この「IPCを下げない」配慮のために欠かせないのが,分岐予測である(図7)。Cortex-A73では,分岐命令の移動先アドレスを保存しておく「分岐先アドレスキャッシュ」(Branch Target Address Cache,BTAC)の容量を拡大している。それに加えて,直近の分岐を高速に呼び出す機能「Micro-BTAC」を新たに追加して,分岐予測の精度を上げた。
さらに,従来はメモリに保存していた「戻り先アドレス格納スタック」(Return Stack)の専用エリアをCPUコア内に設けたり,性能面では有利だが消費電力の多かった動的な分岐予測機構(Dynamic Prediction)に加えて,性能面ではやや劣るが消費電力面で有利な静的な分岐予測機構(Static Prediction)を追加したりすることで,分岐予測の精度を上げるとともに消費電力低下を狙っているとのことだ。
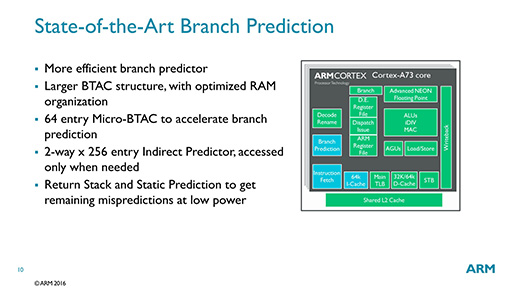 |
そのほかに,性能向上を実現するために行った実行ユニット側の改良としては,浮動小数点演算ユニット(FPU)とSIMD演算機能「NEON」の性能改善が挙げられていた(図8)。「NEONやFPU命令のデータアクセスを最適化した」とスライドにはあるが,この措置は一般的に最大動作クロックの引き上げに効果があるため,動作クロックの向上につながるのではないだろうか。
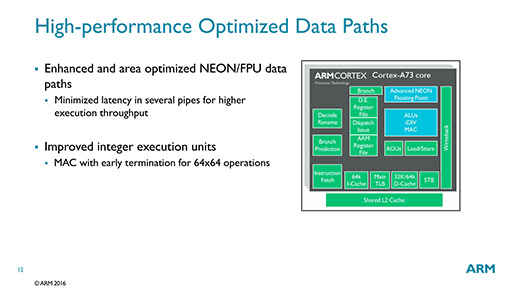 |
また,ロード/ストア(Load/Store)ユニットを2基にして,アウトオブオーダー実行できるように改良したことや(図9),一種のアドレス変換キャッシュである「Translation Lookaside Buffer」(TLB)の効率改善,L2キャッシュの内部構造変更(図10)といった改良によって,メモリアクセス効率を改善しているとのことだ。
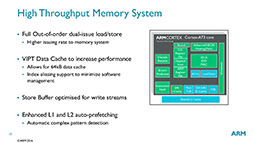 図9:ロード/ストアユニットやデータキャッシュの性能向上,L1およびL2の自動プリフェッチなどの改良が施された |
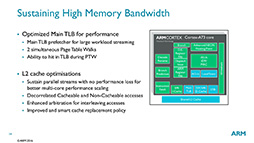 図10:TLBの効率改善やL2キャッシュ内部構造を最適化したことにより,メモリアクセス効率を改善した |
ちなみにスライドはないのだが,実行ユニットそのものは7つになっている。内訳は以下のとおり。
- ALU(算術論理演算ユニット)×2
- ロード/ストア×2
- NEON/FPU×2
- 分岐
Cortex-A72には,処理が複数サイクルにまたがる命令を実行する「Multi Cycle Multiply」というユニットがあったのだが,Cortex-A73では,これがALUに取り込まれたらしい。
いずれにせよ,「Cortex-A73は,2命令デコードのアウトオブオーダー構成になった」とARMは主張しているものの,実行ユニット自体は,Cortex-A72とそう大きくは違わないわけだ。
モバイル向けに不要な仕様を省いて性能向上を実現
それでは,Cortex-A73はどうやって消費電力を落としたのか。答えは明確で,モバイルに不要なものを徹底的に取り去ったからである。
たとえば,Cortex-A72のL1 キャッシュが備えていたメモリエラー回避機能である「ECC」(Error Correcting Code)が,Cortex-A73にはない。サーバー用途の場合,放射線などの影響でデータ化けを起こした場合,それを検出して修正するためにECCのサポートは絶対に必要だ。しかし,一般消費者向けのモバイル端末であれば,「おかしくなったら再起動」が許されるので,ECCは必須とはいえない。省略することで消費電力とエリアサイズを節約できるのならば,省略してしまおうというわけだ。
そのほかにも,「サーバー用途には必須だが,モバイルにはいらない」機能は,全部省いたとのこと。こうした設計によって,Cortex-A73はサーバー用途には適さない,純粋なモバイル向けのCPUコアとなったわけである。
こうした最適化の結果として,先述したとおり,同一の製造プロセスと同一の動作クロックという条件では,Cortex-A73はCortex-A72に対して演算性能が5〜15%程度の改善を果たした(図11)。
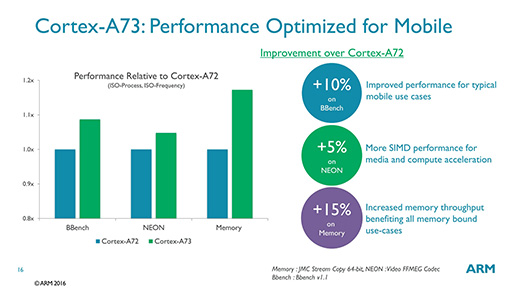 |
一方,基本性能が上がったことにより,同等の処理性能であれば,消費電力を平均20%ほど削減できたという(図12)。
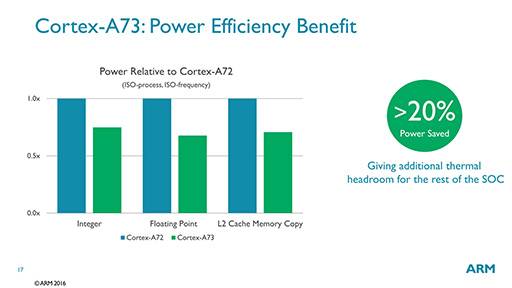 |
面白いのは,性能向上による恩恵は,Cortex-A73の主たるターゲットとなるハイエンドスマートフォンだけに限らないと,ARMが主張していることだ。
ハイエンドスマートフォンは大抵の場合,高性能CPUコアと低消費電力CPUコアを組み合わせる「big.LITTLE」処理を採用するSoCを搭載している。そうしたSoCは,big側にCortex-A57やCortex-A72を,LITTLE側にCortex-A53を採用する構成が一般的だ。一方,ミドルクラスのスマートフォンで使われるSoCでは,bigコアを省いてCortex-A53を8基集積するようなSoCが利用されている。
ところがARMの試算では,Cortex-A73×2にCortex-A53×4を組み合わせたbig.LITTLE構成にすると,Cortex-A53×8とほぼ同等のエリアサイズで平均30%の性能向上を,シングルスレッド性能では90%の向上が可能であるというのだ(図13)。こうした理由によって,ARMでは,ハイエンド向けSoCだけでなく,ミドルクラスSoCにもCortex-A73が採用されるだろうと見込んでいる。
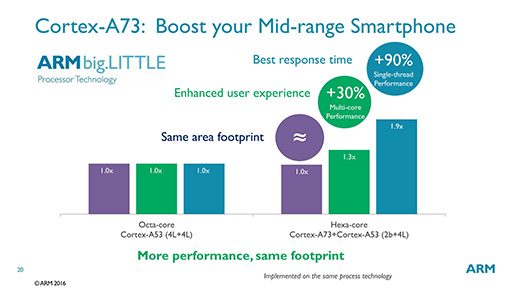 |
ところで,先に掲載した図4では,Cortex-A73が10nmプロセスを前提にしているように見えるが,実際は10nmプロセスでしか製造できないわけではない。2016年6月7日には,TSMCの16FF+プロセスに対応するPOP IP(Processor Optimization Package IP)をARMが提供すると発表しているように(関連リンク,16nmプロセスで製造することも可能である。
現時点では,さまざまなSoCメーカーがCortex-A73を採用したSoCの設計と製造に取り組んでいる段階だ。これを搭載したスマートフォンが年内に出る可能性は,限りなく低いだろう。しかし2017年には,搭載製品が市場に登場してくると思われる。ただ,Cortex-A73の本命は,2017年に量産が始まるTSMCの10FFプロセスであり,これを使って製造したSoCを搭載するスマートフォンが登場するのは,2017年末以降になるだろう。日本国内では2018年の春〜夏商戦モデルあたりといったところだろうか。
Mali-G71のターゲットはVRコンテンツを実用的に動かすこと
続いては,ARMの新しいGPUコアであるMali-G71の特徴を見ていこう。
Mali-G71の狙いは明確で,VR(仮想現実)コンテンツを実用的に動かせるだけの描画性能を実現することである(図14)。
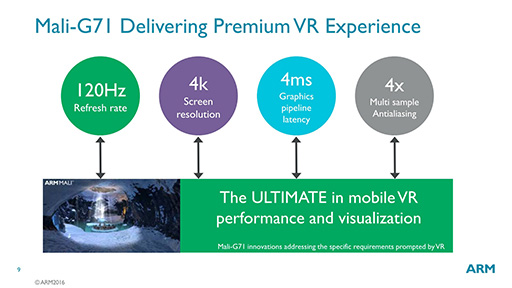 |
もちろん,従来のARM製GPUコアであるMali-Tシリーズで,VRコンテンツが利用できないわけではない。たとえば,「Mali-T760 MP8」を採用する「Galaxy S6 edge」(搭載SoCはExynos 7420)でも,Samsung製の簡易VR HMD「Gear VR」は利用できる。
ただGear VRは,4Gamerで掲載したレビュー記事にもあるとおり,あくまでも手軽なVRコンテンツを扱える程度のものだ。今後,描画品質をより高めてゆこうとすると,性能面で不満が出てくる可能性は高い(図15)。VR以外のゲームグラフィックスも同様で,アプリケーションが要求する描画性能は,どんどん上がっている。
 |
ところが既存のMali-Tシリーズは,そろそろ拡張の上限に達しつつある。たとえば,最上位モデルである「Mali-T880」の場合,シェーダコアを最大16基集積可能(※Mali-T880 MP12では12基集積)といった具合で,この先にさらに性能を上げてゆくのは難しい。加えていえば,描画以外にGPGPU的な用途で使われるケースも増えてきた。たとえば,最近では機械学習における学習結果の実行といった用途だ。
こうした状況に対応すべく,Mali-Tシリーズよりも高い性能と拡張性を持つGPUコアとしてARMが開発したのがMali-Gシリーズというわけだ。そしてMali-G71は,新しいBifrostアーキテクチャを採用した最初の製品となる(図16)。
 |
余談だが,「Bifrost」(発音はビーフロストゥが一番近いと思う)とは,北欧神話に出てくる,地上とアースガルドを結ぶ虹の橋のこと。Mali-Tシリーズは「Midgard」(北欧神話で人間が住む場所),初代のMaliは「Utgard」(ロキの治めていた巨人の国にある都市名)であり,今回も引き続き北欧神話由来の命名となる。
さて,そのMali-G71のスペックや性能をMali-T880と比較したスライドが図17である。シェーダコアを最大32基に倍増し,性能対消費電力比,性能対エリアサイズ比も改善。メモリ帯域幅も2割ほど向上したとARMでは主張しているわけだ。
 |
ベンチマークテストを使った直接の性能比較ではないのは,消費電力を引き上げてもいいのであれば,いくらでも性能は上げらるので,むしろ性能対消費電力比のほうが重要な要素となると,ARMでは説明している。
こうした性能向上による結果として,2016〜2017年にかけて出てくるであろうハイエンド向けSoCが搭載するMali-G71は,モバイルというよりも,2015年のノートPC向け単体GPU並みのグラフィックス性能を発揮するだろうと,ARMは予測を示していた(図18)。
 |
性能向上と消費電力削減に重点を置いたBifrostアーキテクチャの特徴
ではそのMali-G71が採用するBifrostアーキテクチャとは,いったいどんなものなのか。図19は,システム全体の構造を示したスライドだが,これだけを見ても,Mali-TシリーズのMidgardと大きな違いはない。変化があったのは,この中身である。
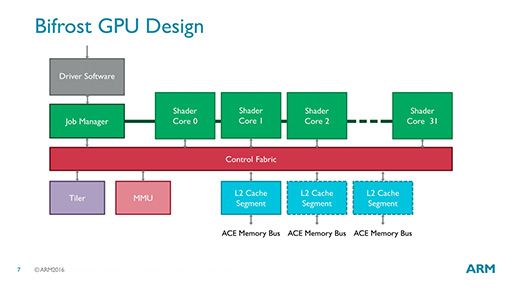 |
図20は,Midgardの構造を細かく図示したスライドだ。Midgardには,2つのALUパイプ(Arithmetic Pipe)とロード/ストア,テクスチャという,独立して実行可能な4つの演算パイプがあった。
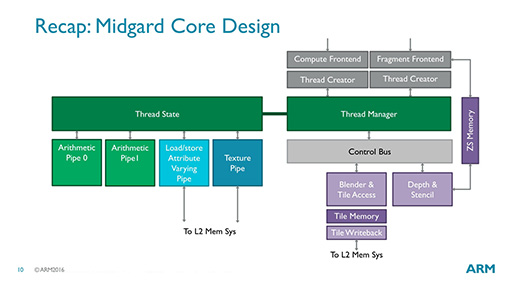 |
続く図21は,Bifrostの構造を細かく図示したスライドである。スライドに多数出てくる「Quad」(クアッド)は,Midgardまでの「Thread」(スレッド)単位の処理に変わって,新しく導入された処理単位の概念だ。
Bifrostでは,演算ユニット「Execution Engine」が3基あるほか,ロード/ストア,テクスチャ,さらにMidgardではALUの中に含まれていた「Attribute」や「Varying」というユニット――どちらもポリゴンに対する処理を行う――の7ユニット,Midgard風にいえば7つの演算パイプで構成されている。
ただし,Midgardはスレッド,Bifrostではクアッドと処理の単位が異なるので,パイプの数だけを比較することに意味はない。
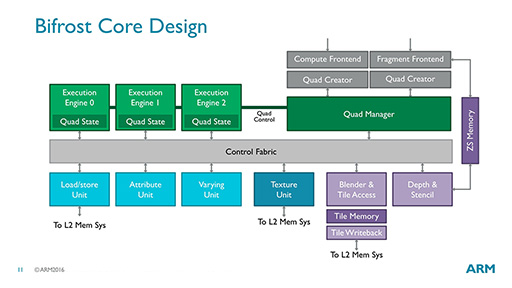 |
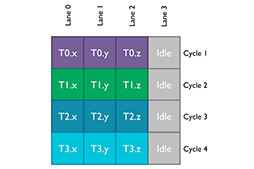 |
たとえば,RGBそれぞれが8bitとなる24bitカラーのデータに4-way SIMD演算を行おうとした場合,4つあるSIMD演算ユニットのレーンは,1つが使われないままになってしまう(図22)。この例では,データを処理するのに4サイクルがかかっているわけだ。
 |
この並び替えに何サイクルかかるのか,ARMでは明言していないのだが,ハードウェアで処理するなら1サイクルもかからないと思われる。そして,GPUのパイプラインは大抵の場合とても長いので,演算の前後に並び替え処理が入っても結果的にスループットは向上するだろう。そうなれば,トータルでの処理時間は短くなるし,消費電力も減らせるというのが,ARMの主張するBifrostの利点というわけだ。
もちろん,最低でも4つのスレッドが動作する状態にできなければ,クアッドの効果は得られにくいという問題はあるものの,その点についてARMは,シビアな問題ではないという見解を示している。
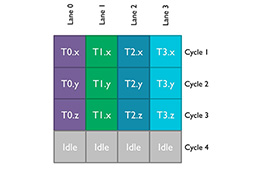
性能向上を目的に導入されたクアッドに対して,省電力に効果がある機能として導入されたものに「Clause」(クローズ)というものがある。
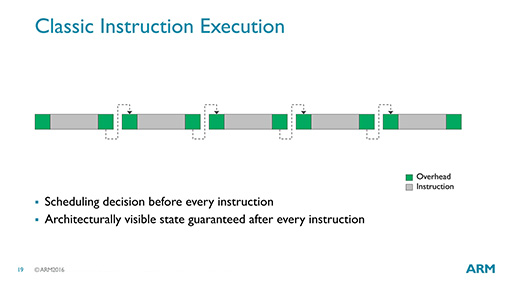
図24はMidgardにおける処理の流れを,図25はBifrostにおける処理の流れを示した概念図だ。端的にいえば,まとめて処理できる命令はまとめて処理することで,オーバーヘッドを減らそうというのが,Clauseの基本的な仕組みだ。
 |
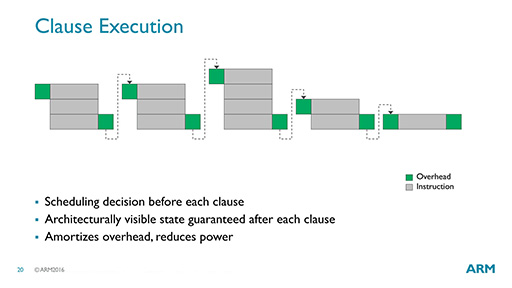 |
とはいえ,この図だけを見て,どんな処理が行われているのかをイメージできる人は,あまりいないだろう。ほとんどの読者には意味不明であることを承知のうえで,ARMが提示したマシン語のサンプルコード(図26)を使って説明してみよう。
図26の左側にあるのが,本来のプログラムコード(Linear Source)だ。簡単にいえば,「LOAD.32」の行でメモリからレジスタ「r0」へとデータを読み出し,「FADD.32」の行でデータが2倍になるように,レジスタ内のデータ同士を加算して別のレジスタ――r0+r0なら「r1」――に結果を保存する。そして,この加算を6回繰り返したうえで,「STORE.32」の行で最終的な値を,r0からメモリに書き戻すという処理を記したコードである。
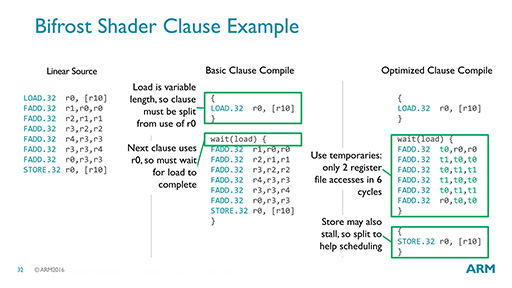 |
この処理におけるオーバーヘッドとは,ALUパイプラインの外に置かれた外部レジスタ「r1,r2,r3,r4」に対する不必要な保存や読み出しのことだ。高速で動作する外部レジスタであるため,これらを遅延なしでアクセスしようとすると,データの転送だけで消費電力が余計にかかってしまう。そこで,これをどうにかして削減しようというのが,Clauseの基本的な概念である。
Clauseでは,図25のコードを,最初のLOAD(r0への読み込み)と最後のSTORE(r0からメモリへの書き出し),計算部分という3つに分解する。そして,計算部は外部レジスタではなく,図25の右側で「t0,t1」と書かれた2つのテンポラリレジスタを利用するように組み替えて,外部レジスタへのアクセスを減らすのだ。このテンポラリレジスタは外部レジスタではなく,ALUパイプラインの中にあると思われ,外部レジスタよりもアクセスに要する消費電力が少なくて済む。
Clauseによる処理を実装しても,処理速度そのものはまったく変わらない。FADD.32の命令数が減るわけではないからだ。だが,消費電力の多いr1〜r4のレジスタアクセスを消費電力の少ないテンポラリレジスタで代替できるので,トータルでの消費電力は減らせますよというのが,Clauseのメリットである。
ちなみに,BifrostのALUは一種のSIMD演算ユニットとなっており,FMA演算を含む演算を行える(図26)。図26にある「ADD/SF」のSFは「Special Function」(特殊な演算)であるが,Midgardまでと比べて,Bifrostではユニットのサイズを縮小したとARMは説明していた。
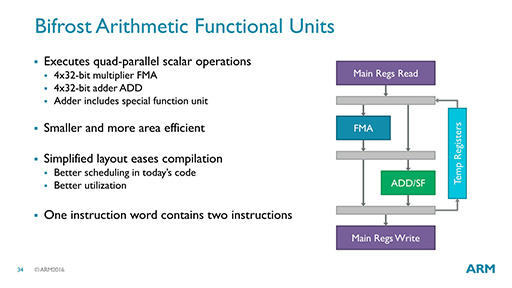 |
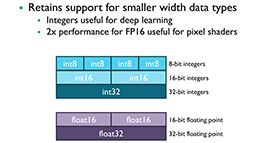 |
機械学習では,32bitでの演算よりも,16bitあるいは8bitの演算でも十分な
結果が得られる場合があるのは知られた話だ。ARMによれば,Bifrostのアーキテクチャなら,小サイズデータでの処理性能が上がるので,消費電力の削減にもつながるのだという(図27)。
Bifrostにおける省電力に関する改良点では,もう1つポイントがある。Bifrostでは,テクスチャデータの持ち方をMidgardまでと大きく変更したのだ(図28)。
図28左端のように,三角形のテクスチャが5つあるとしよう。拡大しないと見えないが,左端の右上にある赤い三角形の斜め下に,黄色のごく小さい三角形があるので,計5つとなっている。Midgardでは,各テクスチャの大きさに合わせて,最小単位(左から2番め),その縦横2倍(左から3番め),縦横4倍(一番右)というように,最小単位を基準にサイズを変えながら,メモリ内でテクスチャデータを管理していた。しかし,このやり方では図を見てのとおり,かなり無駄が多い。右端のテクスチャに至っては,最小単位の16倍ものデータ量となっている。
そこでBifrostでは,メモリ管理の最小単位が撤廃され,各テクスチャの大きさに合わせたサイズのメモリ――図28の各三角形を囲んでいる破線――だけを使うようになった。これによって,テクスチャメモリの使用量が減り,延いてはメモリアクセスにともなう消費電力も削減できたというわけだ。
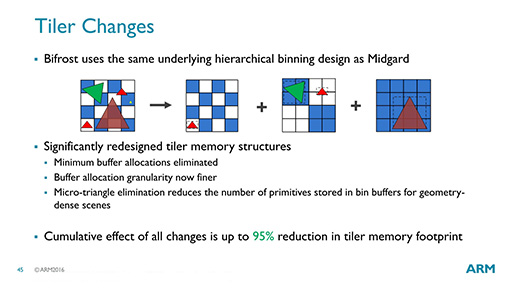 |
なお,黄色のごく小さな三角形は,「Micro-triangle elimination」という機能によって省略されるという。1ピクセル未満に満たないサイズで,描画品質に影響のないような小さいテクスチャを省いてしまうことで,効率を改善しようという仕組みによるものだ。
こうした積み重ねによって,Bifrostではテクスチャメモリの利用効率を最大95%も改善できるというのが,ARMの主張だった。
さらに,ARMはBifrostで,「Index-driven Position Shading」という技法も導入した(図29)。これは,何らかのデータの処理をするときに,データそのものをいちいち転送するのではなく,データのを示すインデックスを渡せば済ませられる部分はそれで済ませすことで,データ転送量を減らそうというものだ。
データそのものを処理する必要がある部分では,転送量は変わらないが,いくつかの処理はインデックスを渡せば,データ転送量を減らせるという。そしてデータ転送量を減らせば,結果として消費電力も減らせるという理屈である。
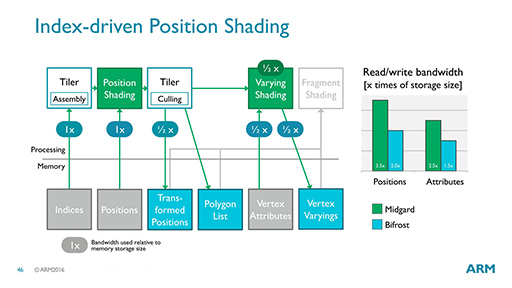 |
既存のMali-T880 MP16を16FF+プロセスで製造した場合,17億ポリゴン(トライアングル)/secを処理できるが,スループットは104億ピクセル/secにしかならない。一方,Mali-G71を16FF+プロセスで製造した場合,850MHzで駆動して8億5000万ポリゴン/sec,272億ピクセル/secというスループットを実現できるとのこと(※ただしコア数は未公表)。ポリゴン性能面では微妙だが,スループットの増大で描画性能の大幅な向上が期待できると,ARMは主張している。
Cortex-A73でも触れたが,Mali-G71も本命の製造プロセスは,TSMCかSamsung,あるいはGLOBALFOUNDRIESの10nm世代だ。とはいえ,最初の製品はTSMCの16FFか,SamsungかGlobalFoundriesの14LPPあたりで製造され,
2017〜2018年に登場する採用製品に期待が高まる
ということで,Cortex-A73とMali-G71の主な特徴は,以上のとおりとなる。
Cortex-A73とMali-G71を使ったスマートフォンがあれば,グラフィックス負荷の高い3Dゲームを一日中,それも途中での充電なしで遊べるようになるかといわれると,さすがにそれは無理そうだ。2017年末に登場するであろう,次世代のハイエンドSoCを使うスマートフォンでも厳しいと思う。
スマートフォンの長時間駆動を実現するには,単にCPUコアやGPUコアの改善だけでなく,ディスプレイパネルや通信機能,GPSの消費電力も下げないと難しい。だがそれらは,現在のARMにはどうしようもない要素であるためだ。
とはいえ,次世代SoCを見据えて,さらに負荷の高いゲームやVRコンテンツが登場してくるのは確実であろうし,そうしたゲームやコンテンツでは,Cortex-A73やMali-G71が活躍することになると思われる。将来のスマートフォン向けSoCがどのような力を示せるか,今から楽しみだ。
- 関連タイトル:
 Cortex-A
Cortex-A
- 関連タイトル:Mali,Immortalis
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー