











ニュース
テクスチャマッピングに変革をもたらす「Ptex法」とは? 無駄なメモリ消費を減らす技術の正体に迫る
 |
テクスチャマッピング技術が抱える問題とは?
CGの世界に限ったことではないが,長らく使われてきた手法が必ずしも良いものだとは限らない。優れた方法が別にあると分かっていたとしても,ハードウェア性能の限界などによって「その手法しか選べない」ということはままある。そして,テクスチャマッピング技術にもそうした傾向は見られる。
その代表例がテクスチャ圧縮手法だ。
たとえば,DirectXの標準テクスチャ圧縮技術である「DXTC」は,今は亡きS3が1998年リリースのGPU「Savage 3D」で採用した「S3TC」がベースとなっている。実のところDXTCでは,テクスチャ圧縮による画質劣化がかなり大きい。しかし,固定された圧縮率が期待できることや,テクスチャマップにアクセスするときのアドレス計算が軽量かつ容易であることから,長らく標準的に使われている。
しかし,旧ATI Technologiesがハイトマップ圧縮に適した圧縮手法「ATI1N」と,法線マップ圧縮に向いた圧縮手法「3Dc」を開発し,それらが「BC4」「BC5」(※BCはBlock Compressionの略)としてDirectXに採用されたのを切っ掛けとして,DirectX 11ではその改良版となる「BC6」「BC7」という高品位の圧縮手法が採用されることになった。
このテクスチャマッピング技術では,もうひとつ解決すべき重大なテーマが残されている。それは「テクスチャマップを3Dモデルへ貼り付ける工程」そのものだ。
問題の1つは,複雑な形状をした3Dモデルに対して,テクスチャをきれいに貼り付けることが難しくなってきたことである。凹凸の少ないつるっとした人形――たとえばドラえもんやアンパンマン――の表面に,シール(テクスチャ)をきれいに貼り付けるのはそれほど難しくないだろう。だが,ゴジラの背びれにシールを貼るのはとても難しそうだ。テクスチャマッピングで生じている問題も,これと似たようなものとイメージすれば理解しやすい。
テクスチャマッピングには,「テクスチャUVの割り当て」という工程がある。これは,3Dモデル上の各ポリゴンが,テクスチャマップのどこに対応するかを示したUVマップの作成に相当するものだ。ところが,昨今の超多ポリゴンモデルに対しては,これを高品位に実現するのがなかなか難しいのである。
そしてもう1つの問題は,テクスチャメモリの利用効率だ。
3Dモデルの一部に貼り付けるテクスチャならばともかく,3Dモデル全体に貼り付ける「スキン」的なテクスチャをテクスチャメモリ上に配置すると,そのテクスチャ用に割り当てられたにも関わらず,実際にはデータが置かれない未使用領域が大量に出てきてしまう。再びシールに例えると,複雑な形状をした大きなシールでは,シール本体よりもその枠部分に使う領域が多くなってしまうようなものだ。
 |
竹重氏によれば,テクスチャメモリ領域の約30%が,こうした未使用領域として無駄になってしまっているとのこと。これは相当にもったいない話だ。平均的なゲームでは,グラフィックスレンダリングに使用されるメモリ領域の60%がテクスチャ用途ということなので,グラフィックスメモリの18%(=60%×30%)が無駄になっている計算になる。
そんな状況を改善すべく,CG映画スタジオのWalt Disney Animation Studiosが2008年に発表したのが,講演のテーマである「Per-Face Texturing」(以下,
Ptex法とはなにか?
小さな四辺形でテクスチャを管理,貼り付け
Ptex法では,まず,ポリゴンで作成された3Dモデルをクワッド(四辺形=2ポリゴン)単位で管理する。そして,クワッドを最小単位とした小さなテクスチャマップ(以下,単位テクスチャ)をモデルに貼り付けるという仕組みになっているという。
シールでたとえるならば,3Dモデルを大きなシールで無理矢理包み込むのではなく,シールのほうを小さく切り刻んでから,モザイクアートのような感じで3Dモデルにちびちび貼っていく手法といったところか。
 |
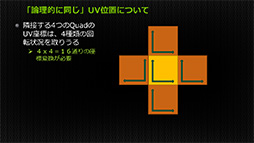
この手法を採用するPtex法ならば,複雑なUVマップをほぼ作らなくていい。シンプルなUVマップで済む,とも言える。なぜなら,小さな四辺形の単位テクスチャを3Dモデルを構成しているポリゴンに対して貼り付ければいいだけだからだ。これがPtexの利点のひとつである。
また,Ptex法では単位テクスチャが四辺形になるので,テクスチャメモリ上にタイルのように配置できるため,メモリ領域を無駄にすることはほぼ起こりえない。このメモリ使用効率の良さが,Ptex法が有するもう1つの利点というわけだ。
 |
ここまで読むと,「Ptex法万歳!」「これで行こうよ」と誰もが思うところだが,そうもいかない。現行のGPUはPtex法に対応していないのだ。
複数のテクスチャにまたがるテクスチャフィルタリングがPtex法の難題
Ptex法にはいくつか課題がある。テクスチャマップ全体を小さな四辺形の単位テクスチャで管理しているため,単位テクスチャの境界をまたぐようなテクスチャアクセスではテクスチャサンプリングが複雑になってしまうと竹重氏は述べていた。
テクスチャマッピングでは,テクスチャ上の画素(テクセル)を1つ読み出してそのまま貼り付ける,という機会は稀だ。たとえば,貼り付け対象3Dモデルが遠方にあるときは,相対的にテクスチャを小さく貼り付けなくてはならない。そうなると,1ピクセルが複数のテクセルにまたがることになる。
「1テクセル読み出し・1テクセル貼り付け」のことをポイントサンプルと呼ぶが,その描画結果は「拡大/縮小されたドット絵」みたいになってしまう。そこで,一般的なテクスチャマッピングでは,読み込み対象テクセルだけでなくその周辺のテクセルも読み込んだうえで,特殊な重み付けをした平均値の計算などによってテクセルのカラーを決定する。これが「テクスチャフィルタリング」の処理だ。
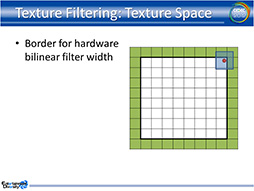
ところがPtex法では,周囲のテクスチャにアクセスするのが難しいという問題がある。なぜなら,単位テクスチャはメモリ上に不連続で格納されてしまう可能性があるので,テクスチャマッピングの対象となる単位テクスチャ(以下,対象テクスチャ)の隣に貼り付けるべき単位テクスチャが,メモリのどこに格納されているかが分からないのだ。これではテクスチャフィルタリングが行えず,クアッドの境界ではテクスチャに継ぎ目が見えてしまう。
 |
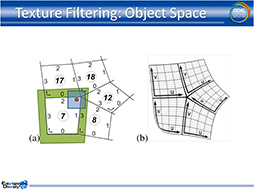
この問題に対して竹重氏が示した解決法は,単位テクスチャを管理する構造体に,対象テクスチャの周囲4方向に隣接している単位テクスチャ(以下,隣接テクスチャ)のアドレス情報も格納してしまうというものだ。これで,隣接テクスチャがどこにあるのか分からないという問題は解決できる。
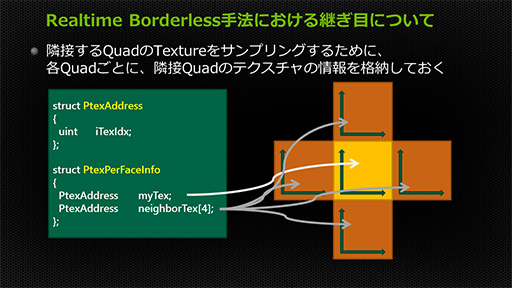 |
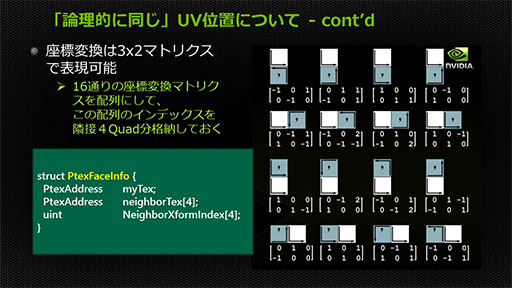
そのうえで,単位テクスチャ同士をまたがるテクスチャアクセスのために,最終的なテクセルサンプル値を決定するための被覆率計算処理を行う。
下のスライドをもとに解説しよう。まず,被覆率計算用の値を,αRGBの4チャンネルからテクスチャの1チャンネルに格納しておく。対象テクスチャは「0.0」(スライドでは黒)で,隣接テクスチャ側は「1.0」(同じく白)だ。
ここで隣接テクスチャにまたがるテクスチャアクセス(スライドの青い楕円)が発生すると,そこに含まれるのは黒が7割程度,白が3割程度だから,隣接テクスチャへの被覆率は3割程度と計算できる。つまり,対象テクスチャが7割,隣接テクスチャは3割というブレンド率でテクセルをサンプルすればいいと言うことになる。
 |
 |
 |
 |
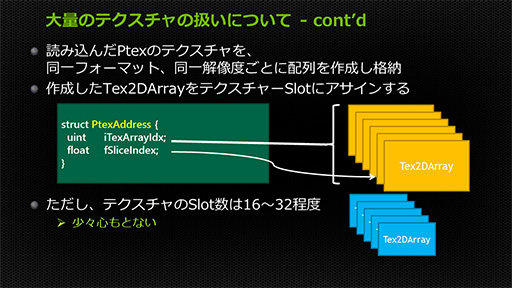
まずテクスチャ配列を,テクスチャの種類(法線マップやデカールなど)やテクスチャ解像度の種類ごとに作成しておく。作成したテクスチャ配列は,テクスチャスロットに割り当てたうえでシェーダからアクセスするのだが,現行GPUのシェーダステージはテクスチャスロット数が16〜32程度しかないので,膨大な量になるテクスチャ配列を割り当てられない。
 |
 |
Kepler世代のGPUで,テクスチャ配列をテスクチャスロットに割り当てる従来式の手法と,バインドレステクスチャとして扱う新しい手法を比較したところ,性能差はほとんどないか,新手法のほうがフレームレートにして2fps程度速くなったそうだ。速くなる理由として竹重氏は,「CPU側のオーバーヘッドが低減されるためではないか」と説明していた。
 |
 |
かなり専門的で難しい話となったが,Ptex法の基本概念は以上のようなものだ。
さらに,Ptex法を実装したシェーダコードでは,処理速度を向上させるためにさまざまな最適化も行っていると竹重氏は説明する。具体的には,隣接テクスチャの回転情報を管理する仕組みやテクスチャ管理構造体の最適化,隣接テクスチャへの不要なアクセスを減らすといった最適化手法が挙げられていた。
これらは,かなり細かい実装レベルの話なので,本稿では割愛する。興味のある人は,NVIDIAが公開した本セッションのスライドを見てほしい。
Ptex法はAMDでも検討されていた
 |
AMDの手法では,対象テクスチャと合わせて,隣接するテクセルの一部も取り込んで管理するという仕組みを採用していた。この実装は既存のテクスチャ管理手法と比較して,無駄なテクスチャ領域を37%から7%にまで削減できたということだ。
 |
 |
| AMDの実装では,単位テクスチャが隣接するテクセルも取り込んで管理する実装を採用した | |
 |
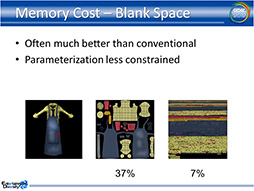 |
| AMDによるPtex法の実装は,皮剥ぎ的な従来テクスチャ管理手法と比較して,無駄なテクスチャ領域を37%から7%にまで削減できたという | |

現在のAMDで,Ptex法の研究やGPUへの応用が検討されているのかどうかは不明だ。しかし,NVIDIAがPtex法の実装に積極的な姿勢を見せれば,AMDも競合としてなんらかの動きを見せるのではないだろうか。
Ptex法への期待と課題
GPUのハードウェアによる支援が欠かせない
 |
ではすぐにでも導入が進むのかというと,そこまで簡単な話ではない。最後に竹重氏は,Ptex法の実装に残されている課題を明らかにした。
課題の1つに挙げられているのは,被覆率の計算用としてテクスチャに専用チャンネルを用意するという冗長さだ。これについては,GPU側にPtex法に合わせたハードウェアテクスチャサンプリング機能でも実装しない限り,根本的な解決はできなさそうに思える。
竹重氏は,その解決手法の案も提示した。たとえば,6面体を1枚の紙に展開したようなキューブマップテクスチャを例に考えてみよう。現在のGPUは,キューブマップの各面が接するテクスチャの境界を処理するために,対象の面に接している別の面にアクセスしてテクスチャフィルタリングを自動で行う機能をすでに持っている。
そこで竹重氏は,「こうした非連続的なテクスチャに対するアクセス機能をPtex法に対応させることができれば,実装に向けた涙ぐましい工夫は不要になるはずだ」と,既存の機能を拡張する方向で解決できるでのはないかという見方を示した。
また,現在のゲームグラフィックスがクワッドではなくポリゴンでモデリングされていることために,Ptex法との相性が悪い点も課題として挙げられている。2つのポリゴンを組み合わせれば1クワッドになるとはいえ,「頂点を共有するが辺は共有しない」特異点があると,Ptex法では例外的な処理が必要になるのだ。
超多クワッドの高精細3Dモデルともなると,Ptex法では膨大な量の単位テクスチャが必要になってしまうのもやっかいだ。この問題は,視点から3Dモデルまでの距離やレンダリング解像度に応じて,3Dモデルを自動分割したり多ポリゴン化したりする技術――要は適応型テッセレーション――と組み合わせることで,解決していく必要があると筆者は考える。
現在のGPUは,DirectX 11世代の機能を実装しきったことで,進化が一段落してしまった。だが,Ptex法に代表される次世代テクスチャリング技術は,今後のハードウェアでサポートされることが切望されている。こうした技術がDirectX 12でサポートされれば,GPU側での実装も進んでゲームスタジオも利用しやすくなるのだが,Microsoftがどう考えているのかは分からない。
ぜひとも,Ptex法を利用しやすくなる方向での改良をDirectX 12には期待したところだ
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー