












連載
西川善司の3DGE:囲碁でトッププロに勝利したDeepMindのAIは,「StarCraft II」でも人間に勝てるか?
 |
GTC 2018で支配的だったのは自動運転関連だが,機械学習ベースのAIをゲームに応用するセッションもいくつかあり,なかでも個人的に興味を惹かれたのとしては,DeepMindによるセッション「StarCraft II as an Environment for Artificial Intelligence Research」(AI研究開発環境としてのStarCraft II)が挙げられる。
4Gamerでも過去何度かDeepMind(ディープマインド)は取り上げているが,念のため簡単に紹介しておくと,同社はGoogle傘下のAI開発企業で,創設者はDemis Hassabis(デミス・ハサビス)氏だ。
Hassabis氏は,13歳でチェスの世界ランキング2位になったり,Peter Molyneux(ピーター・モリニュー)氏の一番弟子として,17歳で箱庭シミュレーション「Theme Park」(邦題 テーマパーク)の共同デザイナー兼リードプログラマーを務めたりという輝かしい経歴を持つ人物である。10代の頃の氏に筆者は何度かインタビューしたことがあるのだが,語ることがどれも高尚で,いかにも天才をいう雰囲気を醸し出していたことが思い出される。
氏は,Molyneux氏の下を離れてからは難解な政治シミュレーション「Republic: The Revolution」を開発するなど異彩を放っていたが,数本リリースしてゲーム開発から引退。その後はアカデミックな世界に身を投じ,2010年にAI開発企業のDeepMindを設立した。
2014年に同社はGoogle傘下となったが,それ以降で最も話題を集めたのは,同社の「AlphaGo」(アルファ碁)というAIが,囲碁界の2大巨塔である韓国のLee Sedol(イ・セドル)九段と中国のKe Jie(カ・ジエ)九段を立て続けに破ったことだろう(関連記事)。
 |
本稿では,このセッションの内容をまとめつつ,「ゲームをプレイするAI」の可能性を考えてみたいと思う。
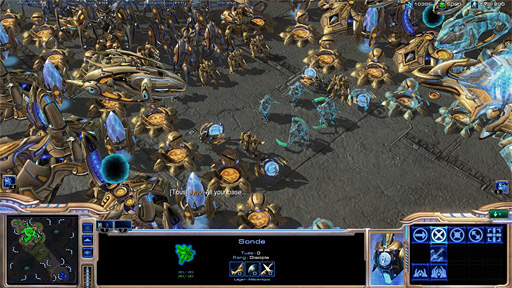 |
DeepMindのAI開発遍歴(1)〜ゲームのルールを知らないAI
 |
「知性とは何か」を探求するために創立されたというDeepMindだが,現在とくに力を入れているのが強化学習(Reinforcement Learning)というテーマだそうだ。
知性とは「環境を認識して行動を選択」する存在で,その存在を一般に「AI Agent」(AIエージェント)と呼ぶが,本稿では「AI Agentが起こした行動」を漠然とした用語としてのAIと呼ぶことにする。つまり,特別に書き分ける必要がない限り,DeepMindの言うAIエージェントもAIと表記するので,この点は注意してほしい。
 |
Hassabis氏がゲーム畑出身ということもあるのか,DeepMindは開発するAIのターゲットとしてゲームを選ぶことが多い。たとえば,DeepMindが業界を最初に驚かせたのは,2015年にAtariのレトロゲーム機「Atari 2600」用のインベーダーゲームやブロック崩しといったコンピュータゲーム49本をAIにプレイさせたところ,そのうち23タイトルでAIのプレイが人間のトッププレイヤーを上回ったという報告を上げたときだ。
 |
DeepMindが研究開発しているAIは,ゲームの「攻略」にあたってルールを知らされない。「敵の座標」などといったゲームプログラム側の数値パラメータなども,もちろん提供されない。マニュアルを読まないタイプのゲーマーと同じように,画面の表示だけを頼りに“初見プレイ”から入っていくのである。
AIは最初,ゲームの基本ルールすら知らないので,当然すぐゲームオーバーとなる。それこそインベーダーゲームならば「敵の弾に当たらないように避けながら敵を撃ち落とす」という基礎情報すら知らないのだから,ただでたらめに(=ランダムに)自機を動かし,ビーム発射するだけだ。
ゲームオーバーごとに,以前のプレイよりもスコアが高ければ,AIに対して「お前はいいプレイをした」という評価を与える。そのうえで再び同じゲームを繰り返しプレイさせる強化学習を行うのである。

AIが機械学習する要素は「連続したゲーム画面の画像」と「ゲームの操作に相当するレバーとボタンの入力」,そして「先刻のプレイは良かったか否かの評価」だけ。これを繰り返して機械学習させていくと,「ゲーム画面の連続時間における画像変化データ」と「ゲームプレイ時の入力遷移データ」という膨大な情報から,「うまいプレイと判断できる学習データ」を抽出できる。
「ゲーム画面の連続時間における画像変化データ」と「ゲームプレイ時の入力遷移データ」は一見まったく相関性がないように見えるものの,これらを機械学習で高次元データに変換して分析すると,「うまいプレイ」との相関性を探り出せたそうだ。
時間方向に遷移するランダムに上下移動するデジタル数値の変化である音声波形をフーリエ変換し,周波数領域の高次元データに変換すると,低音部や高音部のヒストグラムを抽出できて,当該音声の特性を分析できたりするのだが,ディープラーニング(Deep Learning)に代表される機械学習はこのプロセスとよく似ているところがある。
さて,DeepMindは,Atariのレトロゲームを用いた実験の後,このAIの仕組みを一般化すべく,より難度の高いゲームテーマに挑戦していく。
続いて挑戦対象となったのは3Dグラフィックスのゲームだ。この実験ではレースゲーム「TORCS」(The Open Racing Car Simulator)におけるタイムアタックや,三次元の迷路でアイテムを回収しつつ脱出するというDOOM風のオリジナル一人称ゲームなどで,レトロゲームに相対したときと同種の実験を行った。つまり,ゲームのルールは一切教えることなく,「ゲームの映像」をAIに入力して対応する「ゲーム操作」を受け付け,ゲームオーバー時の評価を与えるという繰り返しだけの強化学習を行ったということである(関連リンク)。
下に示したムービーはその結果だが,これらの実験では人間のプレイヤーとほぼ同等か,やや劣るくらいの腕前にまでAIは成長しているのが分かる。
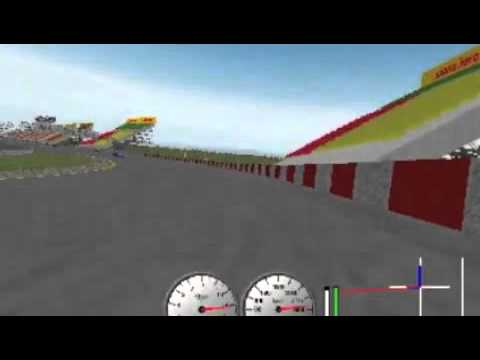
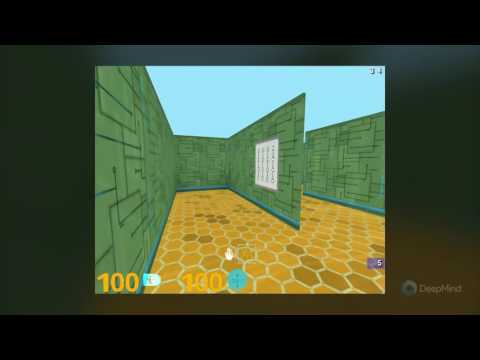
DeepMindのAI開発遍歴(2)〜対人対戦ゲームAIへの昇華
ここまでの実験で手応えを得たDeepMindは,実験対象をこれまでの「シングルプレイヤーゲーム」から「対人対戦型ゲーム」へと移すことにした。
最初に取り組んだのは囲碁であり,つまりはAlphaGoだ。

囲碁や将棋,チェス用の一般的なAI――日本ではいわゆる将棋ソフトなどにおける採用例が多い――は基本的に,最良手を求めるために評価関数を実行し,当該ゲーム局面における次の一手を決定するというものになっている。
評価関数で最もシンプルなのは,「ゲームの定石に則りつつも無意味な手を排除し,自分と相手がそれぞれいくつかの最良手候補で互いに差し合った後の局面で自分が最も有利になりそうなものを最終的な最良手とする」アルゴリズムだ。こうした評価関数ベースのゲームAIは,囲碁なら囲碁,将棋なら将棋,チェスならチェスのゲームルールに基づいたプログラムで構成される。当たり前だ。
しかし,DeepMindが囲碁向けに開発したAlphaGoは驚くべきことに,Atariのレトロゲーム攻略AIと同様,囲碁のルールを知らないAIだった。学習方法もAtari用と同じとのことである。
 |
囲碁というゲームでは,縦19本,横19本の直線が混じり合う盤上の交点へ,白と黒の石が1個ずつ交互に置かれることになるが,そうした「一手ずつ進んでいく棋譜のデータ」を,19
AlphaGoは,囲碁のゲーム開始から勝負が付くまでを「白いピクセルと黒いピクセルからなる19
Atariのレトロゲーム攻略用AIと異なるのは,AlphaGoの機械学習にあたって,膨大な数に上る世界トッププレイヤー同士の対戦棋譜を「畳み込みニューラルネットワーク」(Convolutional Neural Network,CNN)に入力して,これを「基礎知識」として持たせたあとで,同じ基礎知識を持ったAI同士で対戦させた点。結果,勝敗が付いたら勝ったほうのゲーム展開を「良い棋譜」として学習結果に加えることで,腕前の強化を図ったのだ。
その結果が,冒頭でもお伝えした「人間の世界チャンピオンに勝利する」というものだったことは,よく知られているとおりである。
 |
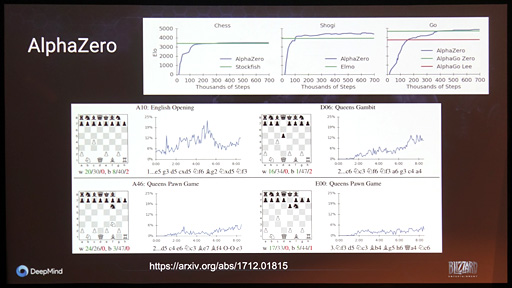
AlphaGoに満足したDeepMindは2017年,AlphaGoの仕組みを一般化して,同種のマス盤面を採用する対戦型ボードゲーム向け汎用AI「AlphaZero」とした(関連リンク)。AlphaZeroは,わずか24時間の機械学習だけで,それまで世界最強と呼ばれてきた将棋AI「elmo」やチェスAI「Stockfish」との100番勝負でいずれも勝ち越すという成績を収めている。
 |
StarCraft IIが次なるDeeMindの挑戦となった理由
 |
そこでDeepMindは,「敵はこちらの状況すべてを知ることができず,自分も相手の状況すべてを知ることはできない」という,これまでのタイプとは少し異なる環境認識をテーマに,対人対戦型ゲームのAI開発に進むことにした。
そこで“お題”として選択したのが,世界的に人気の高いRTSであるStarCraft IIだったという。
DeepMindによると,StarCraft IIでは,ここまで同社が扱ってきたゲームとは,「敵の様子が分からないため,相手の出方を予測する必要がある」点で大きく異なるが,実はこれとは別に,以下のとおり5つも興味深い要素があるとのことだ。
- 戦闘ユニットは自由に動かせるうえ,攻撃手段も多彩で,戦闘ユニット特有の行動もある
〜「コマが必ず盤面のグリッドに沿う」ことになる,囲碁や将棋,チェスにはない要素だ - 独特な内製(経済)活動がある
〜資源を集めて施設を建造し,その施設で戦闘ユニットを製造する仕様のため,施設や戦闘ユニットをどの規模でいつ作るのかはプレイヤーにとって重大な決断ポイントになる - ゲームがリアルタイムで進行する
〜囲碁や将棋,チェスは自分の手番が終わるまで(時間制限の限り)敵は待ってくれるが,StarCraft IIでは,自分が何もせずぼーっとしている間にも,敵は自軍を行動させている - 先を見越して「とるべき戦略」を策定する必要がある
〜短期的には「資源を集める」「集めた資源で施設を作る」「作った施設で戦闘ユニットを生産する」という細々とした小さなゴールがあるものの,最終的には「敵を全滅させる」必要がある。「敵を全滅させる」という究極ゴールのために,細々とした行動を積み重ねていく必要があるため,囲碁や将棋,チェスとは相当に異なる戦略設計が求められる - 能力の違う軍勢(種族)同士で戦うことがある
〜囲碁や将棋,チェスは,「敵も味方も同じ能力を持った軍勢」同士が戦うゲームだが,StarCraft IIでは,能力の異なる種族から1つを選択することになる。StarCraft IIには「平均的なTerran」「能力は高いが高コストなProtoss」「コストが低く,数で圧倒するのが得意なZerg」の3種族が存在するため,自分がどの種族で敵がどの種族なのかでとるべき戦術は異なってくる
 |
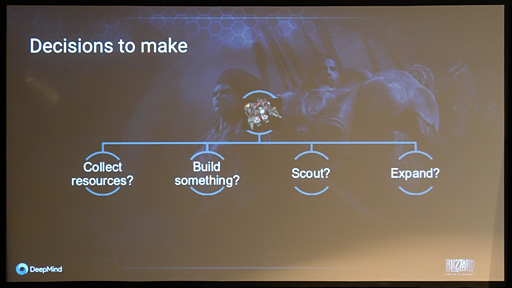
DeepMindは,そんなStarCraft IIの攻略AI開発へ取り組みにあたって,SrarCarft IIが持つゲームメカニクスの要素分解とその理解をまず行ったそうだ。 具体的には,ゲームの展開として「資源の確保」「施設の建造」「施設で戦闘ユニットを製造」「敵と対峙」という4要素に分解し,AIとして決断すべき要素には「資源を確保するか」「施設を建設するか」「偵察を行うか」「領土を拡大するか」があるというところまで整理したという。
 |
 |
未プレイの人のため,簡単に補足しておくと,StarCraft IIで,ゲーム世界において探索できていないエリアには黒い靄(もや)がかかっていて,自軍のユニットがそこに到達すると周囲の視界が開かれて「探索済み」となり,そこに敵のユニットが侵入すれば把握できるようになる。
条件は敵側も同じいで,自軍から見えるのは自軍のエリアと探索済みエリアのみ。お互いの陣地がどこにあるのかは分からないため,偵察は敵の陣地がどこにあるのか,敵が攻めてきているか否かを把握するのに重要だ。
なお,領土の拡大は自軍の施設を建設していくことに相当する。偵察と関係が深く,敵陣に向かって領土を広げる戦略や,あえて敵陣から遠ざかるように自軍施設を建設していく戦略もある。
AI開発のために「SC2 API」を利用
問題はどうAIを作っていくかである。
StarCraft IIでは,画面上に戦闘ユニットや建造物以外に数字パラメータなどが出てくる。ゲーム世界全体を表した全体マップ,行動アイコンなどの表示もある。さらに,メイン画面の建造物や戦闘ユニットはアニメーションしながら動き,資源などもきらきらと揺らめく
たとえば,ある戦闘ユニットが画面の左右方向に動くときは側面を向いたようなグラフィックスで動き,上下方向なら背面や正面を向いて動く。つまり,これらを「同じユニットの異なる動き」と解釈するには,AIそのものを開発する以前の問題として,コンピュータビジョン的な「画面内にある各オブジェクトの認識と解釈」が必要になる。
ここまで多要素(≒多次元)なゲーム映像を,Atariのレトロゲーム的に「連続した画像」として入力して,コンピュータビジョン処理までを行って,ここからゲーム戦略AIを機械学習ベースのAIを構築するのは現在のコンピュータの演算能力で行うのは酷だと考えたようである。
「ちなみに,人間はこれらの処理や戦術の更新をこのレベルでやってのける」の例として上がったのが次のムービーだ。StarCraft IIプロプレイヤーであるLosira選手が実際にゲームをプレイしているときの映像だが,まるで楽器でも弾いているかのような指裁きでショートカットキーを叩き続けているのが分かる。

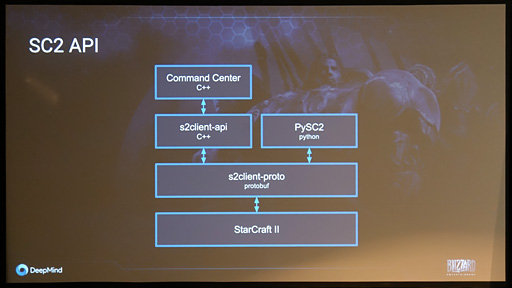
DeepMindは最終的にBlizzard Entertainmentの協力を仰ぎ,StyarCraft IIの動作中に利用できるAPI「SC2 API」を用いて,「その時点で進行しているStarCraft IIのゲーム展開に対して,自軍の情報や自軍から見たゲーム世界の状況を引き出す」形で,コンピュータビジョン的な処理の軽減を図ることになった。
SC2 APIはStarCraft IIの関連アプリケーションや,それこそAI開発のために公開されているアプリケーション開発APIで,そのソフトウェアスタックは以下のようなものになっている。
 |
筆者個人としては,この時点でAtariのレトロゲーム攻略用AIが持つ「連続した画像の入力の情報だけで勝負する」というシンプルなコンセプトからだいぶズレてきている気もしたが,よくよく考えれば,AlphaZeroも,実在する盤面の撮影映像のみに頼っているのではなく,相手の手番を入力しているので,「StarCraft IIにおいては情報入力の部分をAPIで処理する」と考えれば,それほどブレていないのかもしれない。
さて,ソフトウェアスタックだが,最下層はもちろんStarCraft IIのアプリケーション本体だ。
その上にある「s2client-proto」はStarCraft IIに制御コマンドを送るネイティブインタフェース部分になる。シリアライズした制御プロトコル(=実行順に並べられたStarCraft IIを制御するための命令コード)をここからStarCraft IIアプリケーションへ伝送したり,ゲーム進行に関わる情報の問い合わせを送ってその回答を受け取ったりするわけである。
 |
s2client-protoの上に来る「S2client-api(C++)」「PySC2(Python)」は,それぞれC++およびPythonのプログラムからStarCraft IIとやりとりするためのインタフェースAPI部分だ。s2Client-protoと各言語からの関数呼び出しの作法との間にある違いを吸収するレイヤーという理解でいい。
なお,DeepMindはPythonからSC2 APIを利用するPySC2をオープンソースとしてGitHubで公開している。アマチュアも含めて,DeepMind以外のAI研究機関も,PySC2を利用すればStarCraft IIプレイAIを開発可能だ。
最上層の「Command Center C++」は,加ニューファンドランドメモリアル大学(Memorial University of Newfoundland,MUN)の助教で,「EverQuest」から「Overwatch」に至るまでのゲームAIについて研究を行っているDavid Churchill氏のプロジェクトが開発した,C++ベースのStarCraft II向けAI開発ライブラリである。「戦闘ユニットを選択する」「施設を建造する」といった,StarCraft IIのゲームを進行させるうえで必要な戦術操作をマクロライブラリ的に構築したものというイメージだ。AI開発ミドルウェア的な存在と言えるだろう。
Churchill氏は,さまざまなゲームに対してこの種のライブラリを提供しているので,同氏のライブラリを使ってAIや関連アプリを開発している人には使いやすいということになる。
さて,このSC2 APIを使ってプログラム的にStarCraft IIを操作するプロセスと,人間のプレイ操作の対比を分かりやすく示しているのが下のムービーだ。
人間ならば画面を見てキーボードとマウスで操作するところを,AIは(今のところは)手や指を持たないため,こうしてSC2 APIの関数群を使ってゲームを操作することになるわけである。
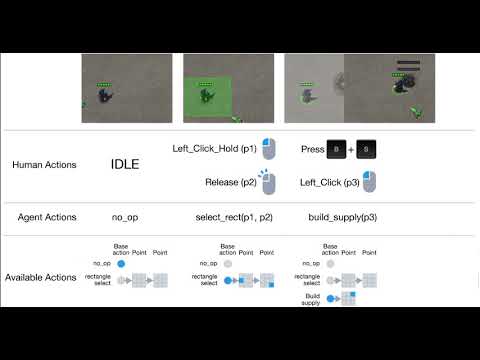
SC2 APIを使うと,「Rendered」「Feature Layer」「Raw」という3種類の情報を取得できるそうだ。
Renderedは,実際のゲーム画面を指すが,ゲーム画面全体ではなく,StarCraft IIを構成する画面要素のうち,任意のものを取得できるという。メイン画面やミニマップ,コマンド一覧画面など,「人間が集中して見ることになるゲーム画面の要素に近いものを切り出して取得できる」イメージである。
取得する画像の解像度自体は自在に設定可能。人間にはまったく役に立たないだろうが,メイン画面全体を128
前述のとおり,SC2 API自体はAI開発専用ではなく,関連アプリの開発にも使えるようになっているため,こうした柔軟な仕様になっていると思われるが,現状の機械学習システムでは抽象化された低解像度画像の方が学習に適している場合もあるので,おあつらえ向きの機能といったところかもしれない。
 |
 |
機械学習での学習やコンピュータビジョンによる知覚を行うのに都合の良い画像としてゲーム内の情報を得ることができるわけだ。

Rawは,ゲームの状況データを,そのまま「数値の塊」をした構造体データとして得るものとなる。これを使うことで,カメラ(=視点)操作やマウスによる戦闘ユニットの選択も関係なしに,任意のゲーム操作をゲーム世界全体の座標系で軍事ユニットや建造物に対して指示できる。これはアルゴリズム的なプログラムAIには有用な機能と言えるだろう。
 |
StarCraft IIのプレイAIは人間に敗れる
DeepMindは,SC2 APIが持つこれら機能を活用して,「StarCraft IIをプレイするAI」をいくつか開発した。仕組みはもちろんAtariのレトロゲーム攻略AIやAlphaZeroと同じ要領で,つまりは「ランダムなゲーム操作と,その結果として表示される連続したゲーム画像」を用いた機械学習である。
ただし,StarCraft IIの場合,その「連続したゲーム画像」に相当するものが,SC2 API経由で取得した「ゲーム画面要素ごとに分解された画像」になる。イメージ的には下のような感じだ。
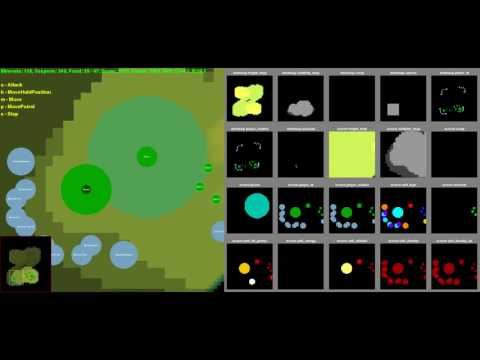
DeepMindが開発した「StarCraft IIプレイAI」のいくつかから,2例を取り上げてアーキテクチャを図解したものが下の画像だ。
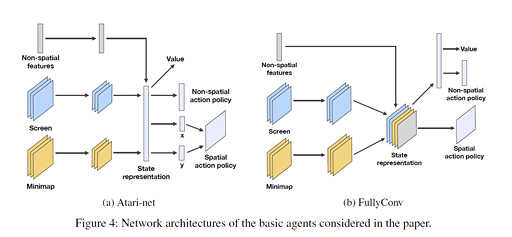 |
(a)の「Atari-net」は,ゲームのメイン画面(「Screen」)と,ゲーム世界マップ(「Minimap」),ステータス情報(「Non-spatial feature」)を1画面に配置し,連続した画像として入力していくものになる。StarCraft IIのゲーム画面をSC2 APIでコンピュータに分かりやすい要素へ分解し,それを1画面に再配置してまとめたものを機械学習させるイメージだ。
(b)の「FullyConv」は,メイン画面とゲーム世界マップ,ステータス情報を1画面に配置せず,そのまま決められた順番で入力して機械学習させるイメージになっている。
いずれの場合もゲームプレイ時の行動は「1フレームあたり1アクション」となっていて,人間との間でプレイ条件は対等にしてあるとのこと。つまり,コンピュータだからといって,一度に複数のゲーム操作を連続で行っているわけではないわけだ。ちなみにゲーム操作の意志決定はざっくり20フレームごとに行っているという。
その結果の一例が下のムービーだ。左は機械学習が浅い状態,右が深くなった状態におけるAIのプレイになるが,右はかなり人間に近い。
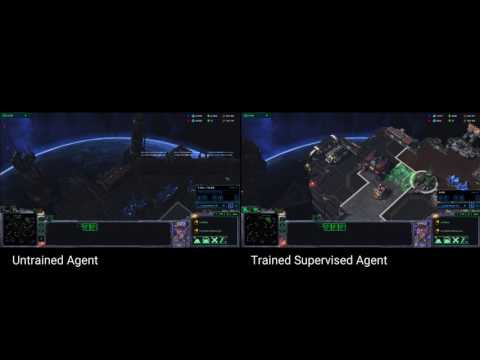
ただし,対人戦でAIは人間にまったく歯が立たず,勝率はゼロ。「対プロゲーマーでは」という話ではなく,DeepMindの社員プレイヤーにも勝てなかった。もっと言うと,StarCrarft II標準の,スクリプトベースのAI(=BOT)にも勝てなかったというから,惨敗と言っていい。経緯は論文「StarCraft II: A New Challenge for Reinforcement Learning」(スタークラフトII: 強化学習のための新たな挑戦)にまとまっているので(※リンクをクリックするとpdfファイルのダウンロードが始まります),興味のある人は読んでみるといいだろう。
ただし,DeepMindとしても「まだ挑戦は始まったばかり」というステータスだそうで,現時点では,「これまでうまく結果を残せてきた『連続した画像から学習していく,Atariのレトロゲーム攻略AIや,AlphaGo,AlphaZeroのアーキテクチャ』が,そもそもRTSでもそのまま利用できるのか」という根本的な部分でも最終的な判断には至っていないそうだ。
 |

「StarCraft IIプレイAI」が人間に勝つ日がきたとき,その先にあるもの
現在のStarCraft IIプレイAIは,Feature Layerから得た特殊画像を取得してプレイ操作しているため,ディスプレイに表示されているゲーム画面だけを見てプレイする人間とは対等ではない気もするが,取り組みの第一歩としてここから始めるのは必然だと思う。
今回紹介したStarCraft IIのプレイAIが機械学習ベースで強くなってくると,「今はまだ画面に見えていない敵の行動を推測し,それに対応した戦略を組み立てられる」ようになるので,AIとしての応用範囲はさらに広がるはずだ。
囲碁用AIのAlphaGoがボードゲーム用汎用AIのAlphaZeroへ昇華したように,高いレベルのStarCraft IIプレイAIを実現できれば,RTS汎用AIに発展させることもできるだろう。
ただ,RTS汎用AIが完成したとして,これがありとあらゆる他のゲームAIに展開できるかと言えば,それはおそらく「NO」である。たとえばサッカーやバスケットボールといった,多数の選手ユニット(≒戦闘ユニット) が同一フィールド内でチーム戦を行うタイプのスポーツゲームなら,勝手な想像ではあるけれども,RTS汎用AIでいいところまでいけるかもしれない。しかし,同じ球技系でも野球だと様相が異なるため,おそらく対処できないはずだ。
今回DeepMindが語った「StarCraft IIにおけるAIの敗北」は,もちろん挑戦の初期段階であるという事実を踏まえる必要があるわけだが,それはそれとして,「Atariのレトロゲーム攻略AI」あるいはAlphaGo的な「ルールを知らず,ゲーム画面だけを見てプレイするAI」からの転換点がやってきたということなのかもしれない。つまり,AIがプレイする対象となるゲームのメカニクスが複雑化するに伴い,それに合わせたニューラルネットワークの構造や学習モデルを,根本から見直す必要が出てきたということである。
この世界には,まだまだDeepMindが挑戦すべきゲームはある。それに向けたAIの再設計は,DeepMindがさまざまなゲームプレイAIの開発に挑戦する限り,これから何度も起こることになるのだろう。
汎用RTSゲームプレイAIが完成する前から気が早いが,DeepMindには今後,StarCraft IIに続いて,格闘ゲームや対戦型落ちものパズルゲームに向けたプレイAIの開発に挑戦してほしいところである。格闘ゲームも対戦型落ちものパズルも,1画面でゲームが展開するという意味ではAtariのレトロゲーム攻略AIを応用できると思うかもしれないが,必ずしもそうではないからだ。
格闘ゲームは技のコマンド入力という複雑性の高い要素や,醍醐味でもあるキャンセル技にまで配慮すると,「時間方向のコマンド入力の組み合わせ」をどう学習していくかが興味深い。対人戦の場合は,上級人間プレイヤーが繰り出すさまざまなフェイント動作にAIがどう反応するのかが気になる。
対戦型落ちものパズルは,「次に落とすピース」がランダムなので,まだ見ぬ先のピースを予見しつつ,連鎖落ちなどを組み立てていく必要がある。未来予測とそれに合わせた戦術組み立てのロジックは相当に高次元なものになるはずだ。
GTC 2018のDeepMindは敗戦報告を行ったが,いずれは人間以上のStarCraft IIプレイAIを完成させてしまうだろう。
というか,その先の展開を見たいので,早く完成させてほしいと思う。
- 関連タイトル:
 StarCraft II: Wings of Liberty
StarCraft II: Wings of Liberty
- 関連タイトル:StarCraft II: Heart of the Swarm
- 関連タイトル:StarCraft II: Legacy of the Void
- この記事のURL:
キーワード
- HARDWARE
- PC:StarCraft II: Wings of Liberty
- PC:StarCraft II: Heart of the Swarm
- PC:StarCraft II: Legacy of the Void
- PC
- 連載
- ライター:西川善司
- 西川善司の3Dゲームエクスタシー
- GTC 2018
- GPU Technology Conference
(C)2007 Blizzard Entertainment. All rights reserved.

4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー