













ニュース
APUが目指した1つのゴール「Kaveri」のアーキテクチャを読み解く。SteamrollerコアとGCN世代GPU,そしてHSAが実現するものとは?
2014年1月14日22:01,AMDは新世代のAPU「Kaveri」(カヴェリ,開発コードネーム)の第1弾製品を発表した。2011年からAPUを投入し続けていたAMDにとって,ひとまずのゴールである「Heterogeneous System Architecture」(以下,HSA)を実現した記念すべき製品である。
Kaveriのラインナップや性能の概要については,14日掲載の記事を参照してもらうとして,本稿では,北米時間1月5日にラスベガスで開催された報道関係者向け説明会「AMD Kaveri Tech Day」の中から,アーキテクチャ面についての解説を担当した,AMD Business UnitのCTO(最高技術責任者)を務めるJoe Macri(ジョー・マクリー)氏によるセッションを要約してレポートしよう。
KaveriコアのAPUは,大手ファウンドリであるGLOBALFOUNDRIESの,性能重視製品向けプロセスである「28nm SHP」(Super High Performance)プロセスで製造される。
このSHPでは,GPUコア部分に関してはトランジスタの密度を重視しつつ,CPUコア部分に関しては低抵抗で高クロック動作が可能という,いわば「APUに最適化された」製造プロセスになっているという。
ただし,このAPU最適化製造プロセスは,高クロック動作時には熱容量的に若干不利な部分もあるともいわれる。この点に関しては,搭載製品や用途別の最適化で対応したり,省電力技術で対応したりするようだ。
14日に発売されたKaveriベースのAPUは,どれもデスクトップPC向けの製品だ。とはいえ,AMDはKaveriのアーキテクチャを,「ノートPCのためにデザインした」としており,Kaveri世代のノートPC向けAPUや組み込み機器,サーバー向けAPUもまた,追って発表される見込みである。
ちなみに,今回発売されたKaveriのダイサイズは245mm2。総トランジスタ数は約24億1000万個だ。2013年6月に発表された「Richland」世代のデスクトップ向けAPUでは,32nmプロセスで,ダイサイズが246mm2,トランジスタ数は約13億300万個というスペックであった。つまり,Kaveriのダイサイズはデスクトップ向けRichlandとほぼ同等ながら,トランジスタ数は10億個以上も増えているわけだ。
Kaveriの最も重要なコンセプトは,CPUとGPUがメモリ空間を共有して動作できるHSAを実現することにある。
HSAがAPUに導入されることで,CPUとGPUはソフトウェアから見て,同列のコンピューティングリソース(演算ユニット)として扱えるようになる。これまでPCのアーキテクチャでは,CPUがホスト(指揮者)であり,その指揮に応じてGPUは超並列演算を行い,その演算結果をCPUに返すという流れで,プログラムは動作していた。だがHSA環境下では,CPUとGPUもいずれもが,ホストになり得るわけだ。
そうした特徴もあって,KaveriではCPUコアとGPUコアをまとめて,「Compute Core」と称している。今回発売された「A10-7850K with Radeon R7 Graphics」(以下,A10-7850K)の場合,4コアのCPUと8基のGCN(Graphics Core Next)世代GPUコアを搭載するので,合わせて「12Compute CoreのAPU」となるわけだ。
KaveriはCPUコアとして,開発コードネーム「Bulldozer」と呼ばれたCPUコアの改良版となるアーキテクチャ「Steamroller」を初めて採用したAPUだ。2つのCPUコアを1つのモジュールに収めるという構成は,初代のBulldozerや2代目の「Piledriver」と変わらない。だがSteamrollerの内部は,性能向上を実現するためにかなり細かく改良されている。
たとえばSteamrollerでは,L1命令キャッシュがBulldozerの64KBに対して,
また,分岐予測の精度を向上させるために,分岐パターン履歴テーブルのエントリ数をBulldozerの5Kエントリから10Kエントリに拡大。この改良で「分岐予測ミスは20%低減された」(Macri氏)ということだ。
さらに,アウトオブオーダー実行を含めた命令スケジューリングを行うためのエントリーバッファも,Bulldozerの40エントリから48エントリに拡大された。スケジューリングの効率はBulldozerに対して,5〜10%向上したそうだ。
整数命令スケジューラの改良も注目すべき点の1つである。BulldozerとPiledriverでは,1つの整数命令スケジューラが2つのCPUコアで共有されていたが,Steamrollerでは各コア用に独立した2つが用意される。これによって,各コアに対して命令を同時に発行できるようになり,1スレッドあたりの命令発行効率は,Bulldozerに対して25%ほど向上したとされている。
CPUコアの改良点はまだまだある。Piledriverコアではメモリへの書き出し(ストア命令)の発行が,コアごとに1サイクルあたり1個であったところが,Steamrollerは2個まで発行可能となった。さらに,メモリアクセスのためのキューサイズも拡大されたので,結果としてメモリアクセス速度では,Piledriver世代のCPUコアを搭載するRichlandと比べて,20%ほどの高速化が実現されたということだ。
こうした地道な改善を積み重ねた結果,Steamrollerコア全体では,1サイクルあたりの命令実行効率(IPC,Instruction Per Cycle)がBulldozerと比べて,ピーク時で20%,平均でも10%向上しているのだという。
先にも触れたが,KaveriにはGPUコアとして,8基のGCN世代GPUコアが搭載される。「8基のGPUコア」とは,Radeon HD 7000シリーズで採用されたGCNアーキテクチャでいう「Compute Unit」(以下,CU)の数が8基ある,という意味だ。
下に掲載したスライドは,CUの構造図となる。KaveriではGPUコアとして,このCUが最大8基内蔵されているわけだ。
さて,上の図をよく見ると,16基で1つのブロックが,「Vector Unit」として濃いオレンジ色で描かれているのが分かるだろう。このブロック内の1つ1つが,GCNでいう「Stream Processor」(シェーダプロセッサ。以下,SP)であり,32bit単精度浮動小数点演算に対応したスカラ演算ユニットとなっている。これら16基が力を合わせることで,最大でSIMD16(16要素ベクトルの演算)の演算を可能とするわけだ。
なお,Macri氏はセッションのなかで,「基本的にGPUコアは,Radeon R9
GPUコアの仕様に戻ろう。A10-7850Kの場合,16SPを4つ搭載したCUが全部で8基あるので,総SP数は16×4×8=512基ということになる。GPU動作クロックは最大720MHzと公表されているので,理論性能値は737.28GFLOPSとなるわけだ。
ところでこのスペックを,PlayStation 4(以下,PS4)が採用するAPUと比較してみると面白い。まずPS4のAPUが内蔵するGPUは,800MHz駆動で18CUなので,理論性能値は1.84TFLOPS(1843GFLOPS)に達する。
つまり,同じGCNコア搭載のAPUとはいっても,PS4に採用されたAPUは,グラフィックス性能がかなり高くなるよう設計されていることが分かるだろう。
Kaveriコアに搭載されるGPUのジオメトリプロセッサ部分は,Hawaii世代GPUと同様の改良が施されている。具体的には,ジオメトリシェーダやテッセレーションステージを介して頂点情報が増大する場合,相対的に遅いグラフィックスメモリ側へ出力されるのを抑制するために,CUに実装されている容量64KBのオンチップ高速メモリ「Local Data Share」(LDS)を積極的に活用するといった改良だ。
一方で,KaveriのGPUが内蔵するレンダーバックエンド(Render Back-Ends)は,わずか2基しかない。レンダーバックエンドは,PS4のAPUだと8基搭載されることを考えると,ここもやや非力といえよう。
KaveriコアのGPUには,GPGPU用途に向けた改良も施されている。それは「Asynchronous Compute Engine」(以下,ACE)が,Hawaii世代GPUやPS4と同じく増加しているという点だ。
ACEとはなにかを簡単に説明すると,GPUにGPGPUのタスクを発注する機能ブロックのことである。8基あるACEからは,CUに対してそれぞれ異なるGPGPUカーネルを発行したうえで,それらを完全に並列実行させることが可能だ。それに加えて,GPGPUタスクとグラフィックスレンダリングを同時に実行できるようにもなっている。
なお,Radeon HD 7000シリーズGPUでは,ACEは2基しか搭載されていなかった。それが4基に拡張されたのは,前世代APUである「Kabini」や「Temash」のこと(関連記事)。Radeon R9世代GPUや同世代GPUを内蔵したAPUでは,8基のACEを搭載するのが標準となるようだ。
Kaveriでは、Hawaii世代のGPUで導入されたプログラマブルサウンドエンジン「TrueAudio」が搭載され、独自グラフィックスAPI「Mantle」のサポートも行われる。
各機能の説明について,それぞれのリンク先を参照してもらうとして,説明会ではKaveriでこれらを使う場合の利点が説明された。
まずMantle対応に関しては,「Civilization V」の開発者などが参加している新興ゲームスタジオOxide Gamesが開発中のRTS向けゲームエンジンのデモ「Starswarm Demo」が披露された。A10-7850Kベースのシステムを使い,DirectXとMantleで同じデモを実行して,フレームレートの違いを示すという内容だ。
宇宙での艦隊戦シーンを描くこのデモでは,全部で6500を超えるユニットが入り乱れて闘うのだが,DirectX版では10fps前後のフレームレートが精一杯。これに対してMantle版では,30〜40fps前後で動作していた。「同じグラフィックスを表現するのにも,Mantleであれば同一GPUでのパフォーマンスは3倍も優れる」というわけだ。
現時点では,デモで披露されたOxide Gamesのエンジンと「Battlefield 4」に使われたエンジン「Frostbyte 3」以外,
さて,そのほかにもKaveriには,ハードウェアビデオデコーダの「UVD4」(Unified Video Decoder 4)やハードウェアビデオエンコーダの「VCE2」(Video Coding Engine 2)などが搭載されている。
UVD4は映像ストリーミングの欠損フレームデコード処理の改良が,VCE2は「Miracast」や「WiDi」といった無線映像伝送技術への対応が,新機能としてあげられていた。
Kaveriの性能や消費電力といったベンチマークテストに関しては,14日公開のレビュー記事を参照してもらうとして,ここではAMDが発表した性能に関する数値について,軽く触れておくとしよう。
まず,同一TDPでの性能をRichland(詳細不明)と比較した場合,「PCMark 8」のVersion 2によるWork Testスコアで8%〜15%の性能向上が,「3DMark」のFire Strikeテストでは,37%〜75%の性能向上が見られるとのことだ。
また消費電力に関しては,いわゆるスリープに当たる「S3」状態での消費電力は25mW程度に止まり,14インチ液晶パネルと58Whの6セルバッテリー,TDP35WのKaveriを搭載したノートPC試作機で,Webブラウジングであれば9時間程度の連続動作が可能とのことだ。
冒頭でも触れたが,Kaveri最大のトピックは,HSAがハードウェアレベルで実装された点にある。
HSAはそもそも,GPUコンピューティングを容易にするための仕組みであり,CPUとGPUで同じメモリ空間を共有する技術「hUMA」は,その実現に必要な要素だ。とはいえ,「CPUとGPUがメモリ空間を共有」といわれるだけでは,何ができるのか分からないという人も多いだろう。
そこでMacri氏は,CPUとGPUがメモリ空間を共有できるようになるまで,APUはどのように進化してきたのかを説明した。少々難しい話が多くなるが,なるべく簡単に説明してみよう。
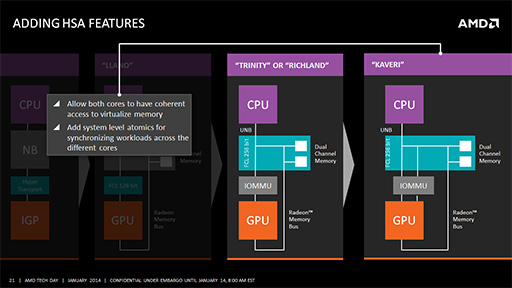
まず,APUの第1世代である「Llano」(ラノ,開発コードネーム)では,同じダイにCPUとGPUを搭載することで,メインメモリを物理的に共有してはいたものの,
また,GPUがグラフィックスレンダリングをするときには,レンダリング速度を最優先させるために,CPUの都合を一切関知しない「Radeon Memory Bus」(開発コードネーム Garlic)という仕組みを使って,メインメモリにフルスピードでアクセスできるようになっていた。ただし,この仕組みはあくまでGPU専用の高速道路のようなもので,これでアクセスされたメモリは,CPUとGPUの間での「データの一貫性」(コヒーレンシ)がまったくないという問題がある。
このままだと,単にCPUとGPUを1チップ化しただけなので,Llanoではグラフィックス描画以外のメモリアクセス用に,GPUからCPU側メモリ空間をアクセスする仕組みを付け焼き刃的に用意した。これが「Fusion Compute Link」(FCL,開発コードネーム Onion)と呼ばれるバスだ。簡単にいえば,「CPUの物理アドレスで,GPUからメモリにアクセスできるバス」というイメージだろうか。
Llanoに続く世代のAPUである「Trinity」やRichlandでは,FCLのバス幅が拡張されたうえ,「IOMMU」(Input/Output Memory Management Unit)を搭載するという改良が加えられた。Llano世代のGPUは,物理メモリアドレスでしかCPU側のメモリ空間にアクセスできなかったのだが,IOMMUが搭載されたことで,CPU側メモリにGPU側から仮想メモリアドレスでアクセスできるようになったのだ。
これがどういうことかというと,Llano世代まではOSやドライバソフトレベルでしかメモリの共有を行えなかったのが,Trinity/Richlandではアプリケーションからも,仮想メモリアドレスでメモリの共有が可能になったということを意味する。アプリケーション開発者から見れば,大きな進化といえるだろう。
ただし,CPU側メモリとGPU側メモリで,コヒーレンシが維持されないのは変わっていなかった。
そしてKaveriではついに,コヒーレンシを維持したメモリアクセスが可能になる。簡単にいえば,CPU側でメモリを書き換えると,GPU側からもその書き換えが正しく反映された状態のメモリにアクセスできるというものだ。もちろん,GPUとCPUを逆にしても同様だ。
またKaveriでは,4CPUと8CUの各Compute Coreが,「あるアドレスのメモリが書き換えられた」ことを知る「同期」の仕組みも導入されている。これにより,たとえばCPU1がアドレスAを書き換えたら,ほかのCPU2〜4やGPU側のCU1〜8は,書き換えられたことを把握できるようになった。そのため,各Compute Core
注意したいのは,Trinity/Richland以前で導入された「コヒーレンシが維持されない従来通りのアクセス方法」も,Kaveriでサポートされるという点である。これはソフトウェア側の互換性を維持するためでもあるが,それ以上に「コヒーレンシの維持が不要で,メモリアクセス速度を優先させたいとき」のために用意されているとみられる。
コヒーレンシを維持するための動作では,そのためだけのメモリアクセスが避けられない。メモリアクセスの実行効率を上げたい場合は,コヒーレンシ維持は避けたいところなのだ。
HSAを実現したKaveriでは,メモリ空間がアプリケーションレベルで共有化でき,CPUとGPUの関係性に上下関係もなくなる……といわれても,ではそれでソフトウェアがどう変わるのか,すんなりイメージできるという人は多くないだろう。
HSAがもたらすものに関して,Macri氏は面白い例を挙げて説明していたので,ここでもその例を引用して説明しよう。
これまでのGPGPUといえば,CPU上で動くプログラムが処理を準備して,並列演算をGPUに発注するのが通例だ。演算結果を取りまとめたり,結果に対する高度な判断をしたりといった仕事も,CPU側のプログラムが担当するのが一般的だった。先にも述べたが,指揮者(ホスト)はCPUであり,GPUはその指揮で楽器を弾く演奏者といった構図である。
しかし,HSAベースのAPUでは,GPUプログラムがホストを務めて,CPUを使うといったプログラムも可能になる。
たとえば,入力画像をタイル状に分割して,各タイルの平均輝度をGPUスレッドによる並列演算で調べて,一定輝度以上のタイルに対しては,CPUで演算したデータを使った特別な処理を行うプログラムを作るとしよう。
これまでのGPGPUでは,まずは並列起動したGPUスレッドで各タイルの平均輝度を求めてから,次に「各タイルの平均輝度が高いタイルに,CPUからのデータを受け取って特別処理を行う」GPUスレッドを起動して処理させるという,2段階の処理が必要だった。
これがHSAベースのGPGPUになると,各GPUスレッドが平均輝度を求めて特別処理を行う必要があったなら,GPUスレッド側が特別処理を行うCPUスレッド(CPUサブルーチン)を起動できるようになる。
特別処理自体が頻繁に発生するケースであれば,2段階処理モデルにしたほうが高速だろうが,特別処理がそれほど頻繁に発生しない場合なら,CPUに特別処理をさせるほうが高速だし,プログラムのアルゴリズムも分かりやすくなるはずだ。
このように,これまでのGPGPUプログラミングではできなかった,CPUとGPUの柔軟な処理分担が可能となるのが,HSA最大の利点である。正直にいえば,HSAが直ちにゲーマーにとって役立つことはなさそうだが,AMDのAPUがこの方向へ進化しているということは,覚えておいて損はないだろう。
AMDは2014年に,Kaveriよりもさらに低消費電力な,ノートPCや組み込み機器向けのAPUとして,「Beema」(ビーマ,開発コードネーム)や「Mullins」(ムリン,開発コードネーム)の投入を予定している(関連記事)。ただし,これらはGCNベースのGPUを搭載するものの,HSAには対応しないそうだ。
とはいえ,AMDは「低消費電力が重視される組み込み機器向けAPUにHSAは不要」と考えているわけではなく,これらにもHSAを展開していくというロードマップを公開している。HSAが本領を発揮するのは,HSA対応のAPUが全製品レンジに対して揃ったときからになりそうだ。
AMDは今回のKaveriの発表を「APUプロジェクトにおけるひとまずのゴール」と表現したが,ユーザー側からすれば,むしろ「ここからがスタート」という印象ではないか。2014年はMantleとともに,APUの動向についても注目していく必要があるだろう。
 |
 |
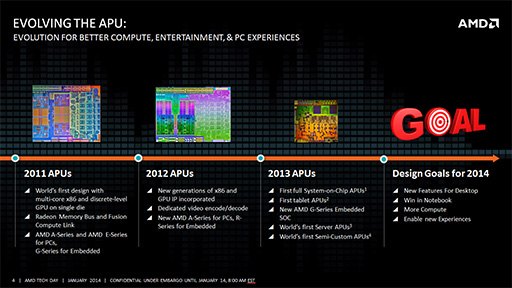
総トランジスタ数は24億超
APUに最適化されたプロセスで製造
KaveriコアのAPUは,大手ファウンドリであるGLOBALFOUNDRIESの,性能重視製品向けプロセスである「28nm SHP」(Super High Performance)プロセスで製造される。
このSHPでは,GPUコア部分に関してはトランジスタの密度を重視しつつ,CPUコア部分に関しては低抵抗で高クロック動作が可能という,いわば「APUに最適化された」製造プロセスになっているという。
ただし,このAPU最適化製造プロセスは,高クロック動作時には熱容量的に若干不利な部分もあるともいわれる。この点に関しては,搭載製品や用途別の最適化で対応したり,省電力技術で対応したりするようだ。
 |
 |
ちなみに,今回発売されたKaveriのダイサイズは245mm2。総トランジスタ数は約24億1000万個だ。2013年6月に発表された「Richland」世代のデスクトップ向けAPUでは,32nmプロセスで,ダイサイズが246mm2,トランジスタ数は約13億300万個というスペックであった。つまり,Kaveriのダイサイズはデスクトップ向けRichlandとほぼ同等ながら,トランジスタ数は10億個以上も増えているわけだ。
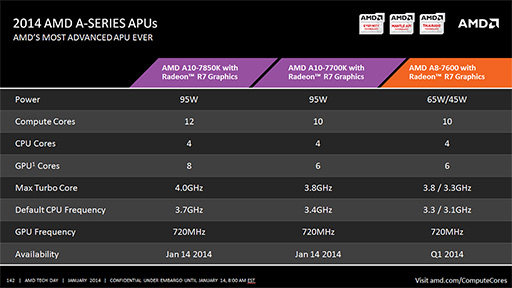 |
Kaveriの最も重要なコンセプトは,CPUとGPUがメモリ空間を共有して動作できるHSAを実現することにある。
 |
そうした特徴もあって,KaveriではCPUコアとGPUコアをまとめて,「Compute Core」と称している。今回発売された「A10-7850K with Radeon R7 Graphics」(以下,A10-7850K)の場合,4コアのCPUと8基のGCN(Graphics Core Next)世代GPUコアを搭載するので,合わせて「12Compute CoreのAPU」となるわけだ。
 |
新CPUコア「Steamroller」を初採用
KaveriはCPUコアとして,開発コードネーム「Bulldozer」と呼ばれたCPUコアの改良版となるアーキテクチャ「Steamroller」を初めて採用したAPUだ。2つのCPUコアを1つのモジュールに収めるという構成は,初代のBulldozerや2代目の「Piledriver」と変わらない。だがSteamrollerの内部は,性能向上を実現するためにかなり細かく改良されている。
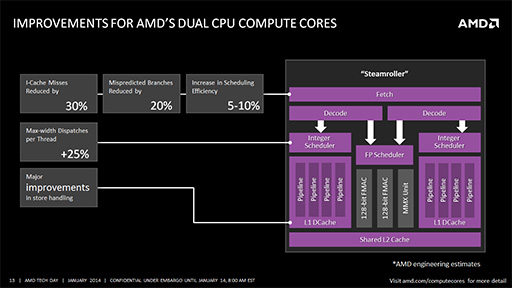 |
たとえばSteamrollerでは,L1命令キャッシュがBulldozerの64KBに対して,
また,分岐予測の精度を向上させるために,分岐パターン履歴テーブルのエントリ数をBulldozerの5Kエントリから10Kエントリに拡大。この改良で「分岐予測ミスは20%低減された」(Macri氏)ということだ。
さらに,アウトオブオーダー実行を含めた命令スケジューリングを行うためのエントリーバッファも,Bulldozerの40エントリから48エントリに拡大された。スケジューリングの効率はBulldozerに対して,5〜10%向上したそうだ。
整数命令スケジューラの改良も注目すべき点の1つである。BulldozerとPiledriverでは,1つの整数命令スケジューラが2つのCPUコアで共有されていたが,Steamrollerでは各コア用に独立した2つが用意される。これによって,各コアに対して命令を同時に発行できるようになり,1スレッドあたりの命令発行効率は,Bulldozerに対して25%ほど向上したとされている。
CPUコアの改良点はまだまだある。Piledriverコアではメモリへの書き出し(ストア命令)の発行が,コアごとに1サイクルあたり1個であったところが,Steamrollerは2個まで発行可能となった。さらに,メモリアクセスのためのキューサイズも拡大されたので,結果としてメモリアクセス速度では,Piledriver世代のCPUコアを搭載するRichlandと比べて,20%ほどの高速化が実現されたということだ。
こうした地道な改善を積み重ねた結果,Steamrollerコア全体では,1サイクルあたりの命令実行効率(IPC,Instruction Per Cycle)がBulldozerと比べて,ピーク時で20%,平均でも10%向上しているのだという。
KaveriコアのGPUはRadeon R9と同世代
先にも触れたが,KaveriにはGPUコアとして,8基のGCN世代GPUコアが搭載される。「8基のGPUコア」とは,Radeon HD 7000シリーズで採用されたGCNアーキテクチャでいう「Compute Unit」(以下,CU)の数が8基ある,という意味だ。
 |
下に掲載したスライドは,CUの構造図となる。KaveriではGPUコアとして,このCUが最大8基内蔵されているわけだ。
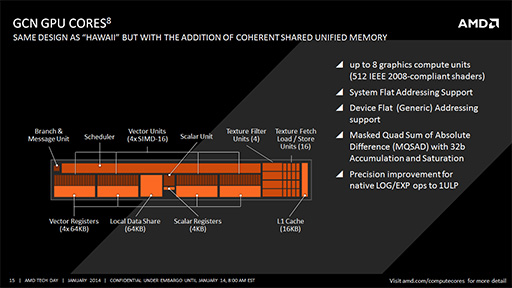 |
さて,上の図をよく見ると,16基で1つのブロックが,「Vector Unit」として濃いオレンジ色で描かれているのが分かるだろう。このブロック内の1つ1つが,GCNでいう「Stream Processor」(シェーダプロセッサ。以下,SP)であり,32bit単精度浮動小数点演算に対応したスカラ演算ユニットとなっている。これら16基が力を合わせることで,最大でSIMD16(16要素ベクトルの演算)の演算を可能とするわけだ。
なお,Macri氏はセッションのなかで,「基本的にGPUコアは,Radeon R9
GPUコアの仕様に戻ろう。A10-7850Kの場合,16SPを4つ搭載したCUが全部で8基あるので,総SP数は16×4×8=512基ということになる。GPU動作クロックは最大720MHzと公表されているので,理論性能値は737.28GFLOPSとなるわけだ。
ところでこのスペックを,PlayStation 4(以下,PS4)が採用するAPUと比較してみると面白い。まずPS4のAPUが内蔵するGPUは,800MHz駆動で18CUなので,理論性能値は1.84TFLOPS(1843GFLOPS)に達する。
つまり,同じGCNコア搭載のAPUとはいっても,PS4に採用されたAPUは,グラフィックス性能がかなり高くなるよう設計されていることが分かるだろう。
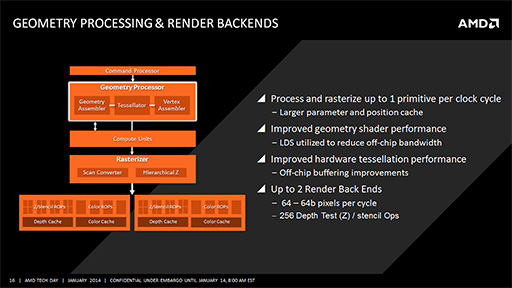
Kaveriコアに搭載されるGPUのジオメトリプロセッサ部分は,Hawaii世代GPUと同様の改良が施されている。具体的には,ジオメトリシェーダやテッセレーションステージを介して頂点情報が増大する場合,相対的に遅いグラフィックスメモリ側へ出力されるのを抑制するために,CUに実装されている容量64KBのオンチップ高速メモリ「Local Data Share」(LDS)を積極的に活用するといった改良だ。
一方で,KaveriのGPUが内蔵するレンダーバックエンド(Render Back-Ends)は,わずか2基しかない。レンダーバックエンドは,PS4のAPUだと8基搭載されることを考えると,ここもやや非力といえよう。
 |
KaveriコアのGPUには,GPGPU用途に向けた改良も施されている。それは「Asynchronous Compute Engine」(以下,ACE)が,Hawaii世代GPUやPS4と同じく増加しているという点だ。
ACEとはなにかを簡単に説明すると,GPUにGPGPUのタスクを発注する機能ブロックのことである。8基あるACEからは,CUに対してそれぞれ異なるGPGPUカーネルを発行したうえで,それらを完全に並列実行させることが可能だ。それに加えて,GPGPUタスクとグラフィックスレンダリングを同時に実行できるようにもなっている。
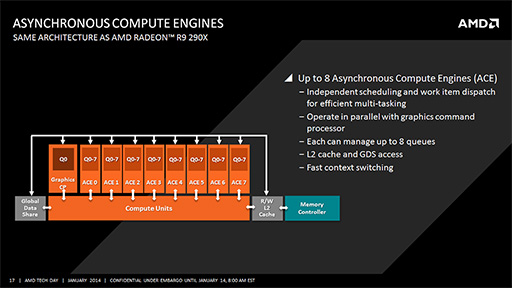 |
なお,Radeon HD 7000シリーズGPUでは,ACEは2基しか搭載されていなかった。それが4基に拡張されたのは,前世代APUである「Kabini」や「Temash」のこと(関連記事)。Radeon R9世代GPUや同世代GPUを内蔵したAPUでは,8基のACEを搭載するのが標準となるようだ。
MantleやTrueAudioにも対応
Mantle対応ゲームなら性能は1.45〜3倍に?
Kaveriでは、Hawaii世代のGPUで導入されたプログラマブルサウンドエンジン「TrueAudio」が搭載され、独自グラフィックスAPI「Mantle」のサポートも行われる。
各機能の説明について,それぞれのリンク先を参照してもらうとして,説明会ではKaveriでこれらを使う場合の利点が説明された。
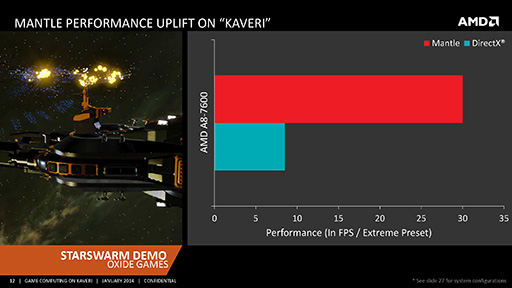
まずMantle対応に関しては,「Civilization V」の開発者などが参加している新興ゲームスタジオOxide Gamesが開発中のRTS向けゲームエンジンのデモ「Starswarm Demo」が披露された。A10-7850Kベースのシステムを使い,DirectXとMantleで同じデモを実行して,フレームレートの違いを示すという内容だ。
 |
 |
| 開発中のRTS用ゲームエンジンのMantle対応デモ「Starswarm Demo」(左)と,開発元のDan Baker氏(右,CO-Founder,Oxide Games) | |
宇宙での艦隊戦シーンを描くこのデモでは,全部で6500を超えるユニットが入り乱れて闘うのだが,DirectX版では10fps前後のフレームレートが精一杯。これに対してMantle版では,30〜40fps前後で動作していた。「同じグラフィックスを表現するのにも,Mantleであれば同一GPUでのパフォーマンスは3倍も優れる」というわけだ。
 |
 |
さて,そのほかにもKaveriには,ハードウェアビデオデコーダの「UVD4」(Unified Video Decoder 4)やハードウェアビデオエンコーダの「VCE2」(Video Coding Engine 2)などが搭載されている。
UVD4は映像ストリーミングの欠損フレームデコード処理の改良が,VCE2は「Miracast」や「WiDi」といった無線映像伝送技術への対応が,新機能としてあげられていた。
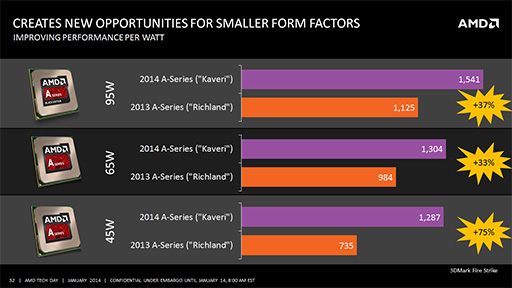
Kaveriの性能や消費電力といったベンチマークテストに関しては,14日公開のレビュー記事を参照してもらうとして,ここではAMDが発表した性能に関する数値について,軽く触れておくとしよう。
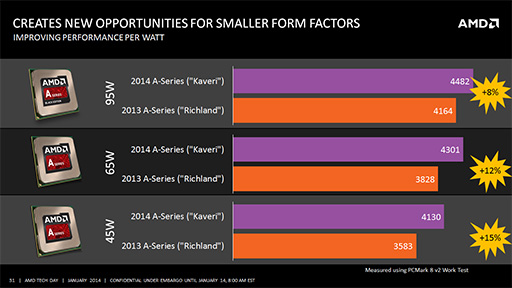
まず,同一TDPでの性能をRichland(詳細不明)と比較した場合,「PCMark 8」のVersion 2によるWork Testスコアで8%〜15%の性能向上が,「3DMark」のFire Strikeテストでは,37%〜75%の性能向上が見られるとのことだ。
 |
 |
 |
Kaveriでようやく実装されたHSAは,何を実現するのか
冒頭でも触れたが,Kaveri最大のトピックは,HSAがハードウェアレベルで実装された点にある。
HSAはそもそも,GPUコンピューティングを容易にするための仕組みであり,CPUとGPUで同じメモリ空間を共有する技術「hUMA」は,その実現に必要な要素だ。とはいえ,「CPUとGPUがメモリ空間を共有」といわれるだけでは,何ができるのか分からないという人も多いだろう。
そこでMacri氏は,CPUとGPUがメモリ空間を共有できるようになるまで,APUはどのように進化してきたのかを説明した。少々難しい話が多くなるが,なるべく簡単に説明してみよう。
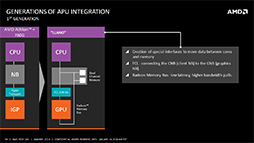
まず,APUの第1世代である「Llano」(ラノ,開発コードネーム)では,同じダイにCPUとGPUを搭載することで,メインメモリを物理的に共有してはいたものの,
また,GPUがグラフィックスレンダリングをするときには,レンダリング速度を最優先させるために,CPUの都合を一切関知しない「Radeon Memory Bus」(開発コードネーム Garlic)という仕組みを使って,メインメモリにフルスピードでアクセスできるようになっていた。ただし,この仕組みはあくまでGPU専用の高速道路のようなもので,これでアクセスされたメモリは,CPUとGPUの間での「データの一貫性」(コヒーレンシ)がまったくないという問題がある。
 |
Llanoに続く世代のAPUである「Trinity」やRichlandでは,FCLのバス幅が拡張されたうえ,「IOMMU」(Input/Output Memory Management Unit)を搭載するという改良が加えられた。Llano世代のGPUは,物理メモリアドレスでしかCPU側のメモリ空間にアクセスできなかったのだが,IOMMUが搭載されたことで,CPU側メモリにGPU側から仮想メモリアドレスでアクセスできるようになったのだ。
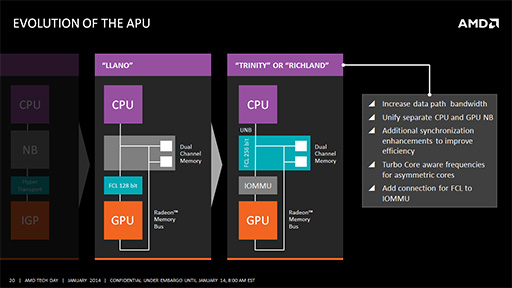 |
これがどういうことかというと,Llano世代まではOSやドライバソフトレベルでしかメモリの共有を行えなかったのが,Trinity/Richlandではアプリケーションからも,仮想メモリアドレスでメモリの共有が可能になったということを意味する。アプリケーション開発者から見れば,大きな進化といえるだろう。
ただし,CPU側メモリとGPU側メモリで,コヒーレンシが維持されないのは変わっていなかった。
そしてKaveriではついに,コヒーレンシを維持したメモリアクセスが可能になる。簡単にいえば,CPU側でメモリを書き換えると,GPU側からもその書き換えが正しく反映された状態のメモリにアクセスできるというものだ。もちろん,GPUとCPUを逆にしても同様だ。
またKaveriでは,4CPUと8CUの各Compute Coreが,「あるアドレスのメモリが書き換えられた」ことを知る「同期」の仕組みも導入されている。これにより,たとえばCPU1がアドレスAを書き換えたら,ほかのCPU2〜4やGPU側のCU1〜8は,書き換えられたことを把握できるようになった。そのため,各Compute Core
注意したいのは,Trinity/Richland以前で導入された「コヒーレンシが維持されない従来通りのアクセス方法」も,Kaveriでサポートされるという点である。これはソフトウェア側の互換性を維持するためでもあるが,それ以上に「コヒーレンシの維持が不要で,メモリアクセス速度を優先させたいとき」のために用意されているとみられる。
コヒーレンシを維持するための動作では,そのためだけのメモリアクセスが避けられない。メモリアクセスの実行効率を上げたい場合は,コヒーレンシ維持は避けたいところなのだ。
 |
上下関係のなくなったCPUとGPUがもたらすソフトウェアの革新
HSAを実現したKaveriでは,メモリ空間がアプリケーションレベルで共有化でき,CPUとGPUの関係性に上下関係もなくなる……といわれても,ではそれでソフトウェアがどう変わるのか,すんなりイメージできるという人は多くないだろう。
HSAがもたらすものに関して,Macri氏は面白い例を挙げて説明していたので,ここでもその例を引用して説明しよう。
これまでのGPGPUといえば,CPU上で動くプログラムが処理を準備して,並列演算をGPUに発注するのが通例だ。演算結果を取りまとめたり,結果に対する高度な判断をしたりといった仕事も,CPU側のプログラムが担当するのが一般的だった。先にも述べたが,指揮者(ホスト)はCPUであり,GPUはその指揮で楽器を弾く演奏者といった構図である。
しかし,HSAベースのAPUでは,GPUプログラムがホストを務めて,CPUを使うといったプログラムも可能になる。
 |
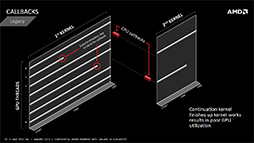
これまでのGPGPUでは,まずは並列起動したGPUスレッドで各タイルの平均輝度を求めてから,次に「各タイルの平均輝度が高いタイルに,CPUからのデータを受け取って特別処理を行う」GPUスレッドを起動して処理させるという,2段階の処理が必要だった。
これがHSAベースのGPGPUになると,各GPUスレッドが平均輝度を求めて特別処理を行う必要があったなら,GPUスレッド側が特別処理を行うCPUスレッド(CPUサブルーチン)を起動できるようになる。
特別処理自体が頻繁に発生するケースであれば,2段階処理モデルにしたほうが高速だろうが,特別処理がそれほど頻繁に発生しない場合なら,CPUに特別処理をさせるほうが高速だし,プログラムのアルゴリズムも分かりやすくなるはずだ。
 |
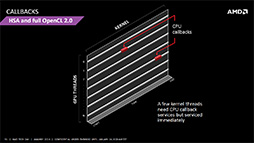 |
| 従来のGPGPUでは,例外処理を含むプログラムを実行するには,2段階に分けてデータ並列演算を行う必要があった(左)。それがHSAになると,GPUスレッドから例外処理に関してだけ,CPUスレッドをサブルーチン的に呼び出すことが可能になる | |
このように,これまでのGPGPUプログラミングではできなかった,CPUとGPUの柔軟な処理分担が可能となるのが,HSA最大の利点である。正直にいえば,HSAが直ちにゲーマーにとって役立つことはなさそうだが,AMDのAPUがこの方向へ進化しているということは,覚えておいて損はないだろう。
1つのゴールに到達したAPU。本領発揮はこれから
 |
とはいえ,AMDは「低消費電力が重視される組み込み機器向けAPUにHSAは不要」と考えているわけではなく,これらにもHSAを展開していくというロードマップを公開している。HSAが本領を発揮するのは,HSA対応のAPUが全製品レンジに対して揃ったときからになりそうだ。
AMDは今回のKaveriの発表を「APUプロジェクトにおけるひとまずのゴール」と表現したが,ユーザー側からすれば,むしろ「ここからがスタート」という印象ではないか。2014年はMantleとともに,APUの動向についても注目していく必要があるだろう。
- 関連タイトル:
 AMD A-Series(Kaveri)
AMD A-Series(Kaveri) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー