













連載
西川善司の3DGE:「Polaris」世代のRadeonは何が新しいのか(1)GPUアーキテクチャを丸裸にする
「Polaris」(ポラリス)マクロアーキテクチャを採用するGPU,「Radeon RX 480」「Radeon RX 470」「Radeon RX 460」は,AMDにとって非常に戦略的な重みを持つ製品となる。
現在,単体GPU市場のシェアをAMDとNVIDIAで二分しているのは多くの人が知るところだが,直近のデータだとAMDのシェアは3割前後しかない(関連記事)。Polaris世代のGPUは,そんな状況を打破すべく,最上位モデルでも199ドル(税別)という,戦略的な北米市場におけるメーカー想定売価で,起死回生を狙って市場投入される製品なのだ。
当然ながらAMDの気合は並々ならぬものがあり,それゆえに(?),筆者のようなメディア側は,さんざん振り回されることとなった。
2016年5月下旬に突然マカオへ招集され,NDA(Non Disclosure Agreement,機密保持契約)の下で技術説明会に参加するも,その場では一切のスライド撮影が禁止。さらに,日本時間6月29日のNDA期限を設定されたかと思えば,6月初頭にあったCOMPUTEX TAIPEI 2016中のプレスカンファレンスでは,AMD自らがNDA期限を反故にするかのようにRadeon RX 480を発表し(関連記事),E3 2016の会期中にはRadeon RX 470とRadeon RX 460を発表(関連記事)。最後は海外の一部メディアに対してだけ,先週末の時点で(日本のメディアには何の連絡もないまま)Radeon RX 480搭載カードの写真掲載を許可するという状況だった。
「事前の告知なしに,段階的な開示期限と開示範囲を設定する」という,複雑極まりないNDA制御からやっと解放され,これでやっと落ち着ける……というのが偽らざる感想だが,ともあれ今回は,Polarisマクロアーキテクチャを採用するRadeon RX 400シリーズの技術解説を行っていきたい。
さて,まず押さえてほしいのは,Polarisマクロアーキテクチャを採用するGPUコアには「Polaris 10」「Polaris 11」の2種類があるということだ。
Radeon RX 480とRadeon RX 470はPolaris 10コア,Radeon RX 460はPolaris 11コアを採用する。
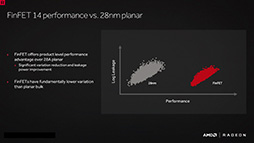
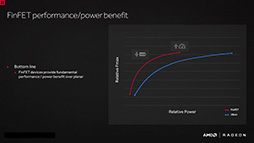
Polaris 10とPolaris 11はいずれも,S
ダイサイズは,Polaris 10が232mm2,Polaris 11が124mm2とのこと。トランジスタ数は,Polaris 10のみ約57億個とAMDは発表している。
そんなAMDによる各製品の位置づけは以下のとおりだ。
●Radeon RX 480
〜2560
●Radeon RX 470
〜1920
●Radeon RX 460
〜「Radeon R7 370」に代わるコストパフォーマンス追求型モデルで,e-Sportsタイトル向けGPU
これらAMDのメッセージからも分かるように,Polarisは「新世代トップエンドGPU」ではなく,従来世代のハイクラス,もしくはミドルクラスGPUと同等の性能を最新のプロセス技術で実現して製造コストを下げ,ひいてはユーザーにとって魅力的な店頭販売価格の実現を目指した製品だ。
ここからは,Polaris 10とPolaris 11という2つのGPUコアを,より深く見ていくことにしよう。
というわけでさっそくだが,両GPUコアの全体ブロック図は以下のとおり。ざっくりといえば,どちらも,「Graphics Core Next」(以下,GCN)アーキテクチャを採用してからのAMD製GPUで見慣れたブロック図といったところだ。
AMDは,今回のRadeon RX 400シリーズが採用するGCNアーキテクチャを「第4世代」(4th Gen. GCN)と位置づけている。
Radeon HD 7000シリーズとして立ち上がったSouthern Islands世代がGCN 1.0,Sea IslandsとそのリフレッシュであるCaribbean IslandsがGCN 1.1,Volcanic IslandsとそのHBM(High Bandwidth Memory)対応版となるPirate IslandsがGCN 1.2で,今回のPolarisはGCN 1.3ベースだ。
「Shader Engine」(シェーダエンジン)は,Polaris 10が最大4クラスタ構成,Polaris 11が最大2クラスタ構成となっている。
Shader Engineとは,演算ユニットとしての「Compute Unit」(コンピュートユニット)とは別に,頂点次元のデータを処理して頂点単位単位の仕事に分解する「Geometry Processor」(ジオメトリプロセッサ),そしてジオメトリとピクセルの対応を割り付けてピクセル単位の仕事に分解する「Rasterizer」(ラスタライザ)が各1基と,さらに演算結果として得られたピクセル単位のデータを実際にグラフィックスメモリへと出力する「Render Back-Ends」(レンダーバックエンド)4基をひとまとめにしたものである。それ単体でGPUに必要な処理系をすべて持っていることから,4Gamerではよく“ミニGPU”と呼んでいるが,実際,イメージとしては「マルチコアCPUにおけるCPUコア1基」に近い。
実際に演算処理を行うスカラプロセッサとしてのシェーダプロセッサは,64基で1つのCompute Unitを構成しており,このCompute Unitを,Shader Engineのクラスタごとに複数基搭載するのが,GCN系GPUの基本構成である。
Shader EngineあたりのCompute Unit数はGPUごとにバラつくのだが,Radeon RX 480では9基,Radeon RX 460では8基となっている。Radeon RX 470は「Radeon RX 480からCompute Unitを4基削減したモデル」とされているが,どのように削減したかは明らかになっていないので,4基あるShader EngineのCompute Unit構成は必ずしも「8+8+8+8」とは限らない。極論,「9+9+9+5」という可能性もあり得るだろう。
ひとまず今回は「Radeon RX 470におけるShader EngineあたりのCompute Unit数は8基」と仮定して話を進めるが,総シェーダプロセッサ数の計算式は以下のとおりとなる。
動作クロックは,Radeon RX 480がベースクロック1120MHz,ブースト最大クロック1266MHz。Radeon RX 470とRadeon RX 460のスペックは,原稿執筆時点である6月26日の時点で開示されていない。
仮に,Radeon RX 470とRadeon RX 460の動作クロックもRadeon RX 480と同じであるとした場合,ブースト最大クロックにおける最大理論性能値としての単精度浮動小数点演算性能は以下のとおりだ。なお,下の計算式で「×2 FLOPS」としているのは,シェーダプロセッサ1基が1クロックで単精度浮動小数点数の積和算を実行できる「2 Ops」仕様だからだ。
AMDは「Polaris 10は5 TFLOPS以上」「Polaris 11は2 TFLOPS以上」とアナウンスしていたので,ほぼその説明どおりの数字が得られている。
ちなみに,Polaris登場後も最上位のRadeonとして君臨することになる「Radeon R9 Fury X」だと,総シェーダプロセッサ数が4096基,ブースト最大クロック1050MHzで,最大理論性能値は約8.602 TFLOPSとなる。
Hawaiiコアを採用するRadeon R9 200シリーズのハイエンドモデル「Radeon R9 290X」だと順に2816基,1000MHz,約5.632 TFLOPS。HawaiiコアのリフレッシュとなるGrenadaコアを採用した「Radeon R9 390X」だと,順に2816基,1050MHz,約5.914 TFLOPSなので,Radeon RX 480は,「Radeon R9 290Xを上回り,Radeon R9 390Xに迫る演算性能値を持ちつつも,製造プロセスの微細化効果でダイサイズを小型化して製造コストを下げたGPU」と言うこともできそうである。
では,第4世代GCNとなるGCN 1.3で何が新しくなったのかだが,実は,「GCN 1.2に対して細かなチューニングを行ったもの」という一言でまとめることができる。
まず,ジオメトリエンジンたるGeometry Processorにおける強化ポイントは2点,「Primitive Discard Accelerator」(プリミティブディスカードアクセラレータ)と「Index Cache for Small Instanced Geometry」(インデックスキャッシュ・フォー・スモールインスタンストジオメトリ)である。
Primitive Discard Acceleratorは,ジオメトリデータ(≒ポリゴンデータ)をレンダリングパイプラインの下流へ流す前に,ジオメトリエンジンの上流側で,「明確に描画対象にならないもの」を排除してしまう機能だ。
いわゆる「早期カリング」(Early Culling)機能の一種であるだけに,「最近のGPUなら実装済みなのでは?」と思う人もいると思うが,一般的な早期カリングだと,視界外ポリゴンや裏面ポリゴンを除外するのに対し,Primitive Discard Acceleratorは,この早期カリングを“すり抜けてきた”ポリゴンに対して適用するものになる。
具体的な“効能”は,MSAA(Multi-Sampled Anti-Aliasing,マルチサンプルアンチエイリアシング)の処理面積――実質的にはレンダリング解像度の1ピクセルサイズ――に満たない微小なポリゴンの排除である。
MSAAの処理面積に満たない微小なポリゴンは,演算処理対象になったとしても,最終的にピクセルとして描画されることはない。であれば,早期に排除してしまおうというわけだ。オープンワールドのゲームなどで,遠方に多くのオブジェクトが配置されるようなゲームグラフィックスでは高い効果を発揮することだろう。
Geometry Processorの強化ポイント,2つめのIndex Cache for Small Instanced Geometryは,「同一の3Dモデルを異なるパラメータで複数大量に描画するときに用いるインスタンシング描画」を高効率化するために新設となった,専用キャッシュメモリのこと。インスタンシング描画で頻繁にアクセスすることとなるインデックスバッファをキャッシュに載せて内部バス消費を低減し,GPUのトータルな性能を向上させようという意図の新機能になる。
こちらは,同一のユニットを大量に描画するようなRTSや,同一モデルからなる自然物を,パラメータで変調させながら大量に描画する機会の多いオープンワールドのゲームで効果を発揮することだろう。
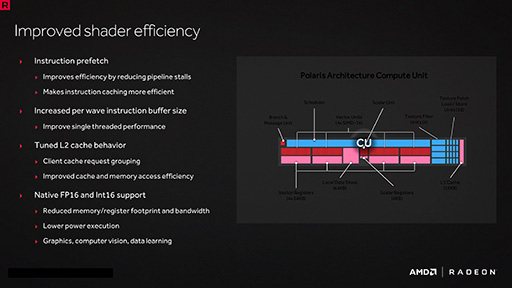
前出のブロック図だと,PolarisでCompute Unit自体の構成に大きな変化はなさそうに見えるのだが,AMDは,Compute Unitの実行効率を上げるために,Compute Unit自体,そしてCompute Unitの周辺に細かい改良を施している。
まず,「Command Processor」(コマンドプロセッサ)が命令語の先読み(Prefetch,プリフェッチ)に対応した。これは,CPUの高速化手法として,CPU業界では当たり前のように採用されている技術だ。
先読みは,CPUだと分岐実行が入ったとき無駄になってしまうが,GPUの場合,プログラムはSIMT(Single Instruction, Multiple Thread)実行形態であるため,条件分岐があって分岐するスレッドと分岐しないスレッドに分かれたとして,分岐するスレッドにおいても,実際にはジャンプせずにジャンプ先までの命令を無視し続け,分岐しないスレッドと歩調を合わせるような動作となる。つまり命令語の先読みは,GPUだと,分岐のありなしにかかわらず効果が大きいのである。
AMDのGCN系Radeonでは,データスレッドは64個をひとかたまりの「WAVE」として扱う(※NVIDIAのGPUだと32データスレッドを1つの「WARP」として扱うのはご存じのとおり)。
Polarisでは今回,各Compute Unitにおいて,このWAVE単位で割り当てられる命令バッファのサイズを増加させる改良が入った。これにより,WAVEごとにバッファリングできる命令数が増加し,結果,各スレッドの実行効率が向上したと,AMDは述べている。
L2キャッシュの制御にも改善が入った。キャッシュメモリへのデータの出し入れをメモリチップのグループ分けに最適化した形で行う工夫を取り入れている(※L2キャッシュは容量の増加もトピックだが,その点は後述する)。
もう1つ,16bit半精度浮動小数点数と16bit整数を内部レジスタにてネイティブで取り扱えるようになったことも,Compute Unitにおける重要な機能拡張の1つとしてAMDは挙げている。
こう聞くと,「NVIDIAがPascal世代の『GP100』で採用した,16bitサイズのデータを2つ同時に32bit演算器で処理することによって2倍のスループットを稼ぐ,あのアクセラレーションを身に付けたのか!?」(関連記事)と思う人も多いだろう。筆者も一瞬そう思ってしまったのだが,確認したところ,あくまでも,レジスタファイル上のフットプリント(≒占有量)として32bit幅に2つ格納しておけるだけで,演算スループットは変わらないとのことだ。
要するに,2つの16bitデータを処理するにあたって,2つのレジスタを合わせて32bitに収めたうえで,実際の演算時には2つの32bitデータとして扱うということだ。得られる効果は,レジスタファイルの節約と内部バス帯域幅消費の節約のみとなるので,この点は注意してほしい。
PolarisではグラフィックスメモリとしてGDDR5を採用する。NVIDIAが「GeForce GTX 1080」で採用したGDDR5XをAMDは見送ったわけだが,その理由を同社は「供給安定性やコスト面に配慮したため」としている。「それならRadeon R9 FuryシリーズのHBMは……?」という疑問もなくはないが,まあ,Radeon RX 400シリーズはいずれも価格対性能比重視のGPUなので,説明自体は納得できよう。
リファレンスデザインにおけるグラフィックスメモリ容量は,Radeon RX 480が4GBないしは8GB,Radeon RX 470が4GB,Radeon RX 460が2GB。動作クロックに関する説明は,少なくともマカオの説明会においてはなかったが,「最大で8GbpsデータレートのGDDR5をサポートする」という言及はあった。
メモリインタフェースはPolaris 10が256bit,Polaris 11が128bitとなるので,仮に3製品がすべてメモリクロック8GHz相当(実クロック2GHz)のGDDR5メモリを搭載するとするなら,メモリバス帯域幅は以下のとおりとなる。
なおPolarisでは,Tonga世代の「Radeon R9 285」以降で導入された,ピクセルデータを可逆圧縮することで実効メモリ帯域幅を向上させる機能「Lossless Delta Color Compression」(以下,Lossless DCC)も引き続き搭載している。
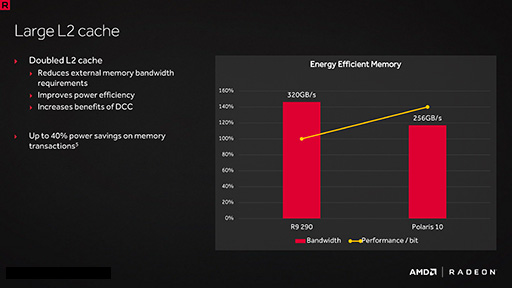
Lossless DCC自体に大きな改良はないように見える一方,AMDは今回,前段で後述するとしたL2キャッシュ容量を,Polaris 10で2MBと,Hawaii(およびそのリフレッシュとなるGrenada)コアの2倍に増量している。
GCN系RadeonのL2キャッシュは,Render Back-Endごとに1つのパーティションという割り当てになっている。Polaris 10全体で抱えるRender Back-Endの数は8基なので,Render Back-EndあたりのL2キャッシュ容量は(2048÷8)で256KBという計算だ。
このL2キャッシュ大増量により,実効メモリ性能は,Hawaiiコアを採用するRadeon R9 290シリーズの512bitメモリインタフェースが実現する320GB/sに迫るとAMDは説明している。また,L2キャッシュの容量増は,GDDR5メモリへのアクセス低減にもつながり,メモリアクセスに伴う消費電力をRadeon R9 290シリーズ比で40%も削減できたという。
ちなみに,Polaris 11においてもL2キャッシュ増量は実現している。Radeon RX 460の場合,Render Back-End数は4基なので256KB×4=1024KBとなり,総L2キャッシュ容量は1MBとなる計算だ。
従来,ほとんどドライバ内で行われていた(≒CPUで実行処理されてきた)GPUスレッドのスケジューリングと発行を,PolarisではGPU内部に新設された「Hardware Scheduler」(以下,HWS)で実行するようになった。
より正確を期すと,このHWS自体はTonga&Fiji世代から存在するのだが,PolarisのHWSでは,プログラマビリティと柔軟性,効率を引き上げるため,大規模なアップデートを行ったという。
本稿の序盤で,Polaris 10のトランジスタ数は約67億個,シェーダプロセッサ数は2304基とお伝えしている。2560基のシェーダプロセッサを搭載する「Hawaii」コアだとトランジスタ数は約62億個なので,この「シェーダプロセッサ数が少ないにもかかわらず,HawaiiよりもPolaris 10のほうがトランジスタ数が多い」理由の大きな要因がこのHWSである可能性は高い。
さてこのHWSだが,個人的には,Polarisマクロアーキテクチャにおける最も革新的な改良点はここだと感じている。
従来,この部分をドライバ任せにしていたのは,アプリケーションごとに最適なスケジューリングを行うにあたって,そのほうが適していたからだ。ではなぜ今回AMDは,HWSをGPU側に内蔵したのだろうか。
GPU内にHWSを置くことによって得られる最大のメリットは,GPU内部にあるリソースの状態(ステータス)をリアルタイムで把握し,その変移に瞬時かつ臨機応変に対応するスケジューリングを行えるようになることである。これはもちろん,GPU内のリソース,具体的にはシェーダプロセッサを有効活用できるようになることにつながる。
ソフトウェア処理だと,瞬間瞬間におけるGPU内部の状況が分かりにくく,制御自体は完璧に行えるとしても,どうしてもワンテンポ遅れてしまう。CPUから見れば,GPUはPCI Expressリンクの向こうにいる存在だからだ。
従来,GPUの活用といえばグラフィックスレンダリングがメインで,GPGPU用途利用はおまけ的な感じがあった。だからこそ,そうしたスケジューリングをドライバ側でやっていてもそれほど不都合が起きてこなかったのだが,近年ではそうでもなくなってきている。
とくに近年ブームとなりつつあるVR(Virtual Reality,仮想現実)では,非同期タイムワープ処理などの実行を,グラフィックスレンダリングの実行中にリアルタイムかつ非同期に割り込ませる必要があるため,GPU内部のリアルタイムなリソース徹底活用は重大なテーマとなってきた。だからこそAMDはこのタイミングで,GPUスレッドのスケジューリングと発行のための機能ブロックをGPU内部に実装してきたのである。
ちなみにこのHWS,「Hardware」とは言うものの,実のところ,GPU内部に実装された専用CPUにプログラムを実行させる仕様であることが明らかになっている。AMDによれば,この実装のため,ドライバなどのアップデートによって,HWSソフトウェアは適宜アップデートが可能だという。
なお,HWS専用としてGPUコアにどんなプロセッサを実装しているかまでは,AMDは明らかにしていない。
いずれにせよ,このHWSのおかげで,Polarisでは,GPU内部のCompute Unitを,グラフィックスレンダリングタスクとGPGPUタスク(=Computeタスク)に切り換えことができるようになったわけだ。
動作モードは「Preemption」(プリエンプション)と「Asynchronous Shaders」(アシンクロナスシェーダ),「Asynchronous Shaders with Quick Response Queue」(アシンクロナスシェーダ・ウィズ・クイックレスポンスキュー)の3種類である。
Preemptionは,グラフィックスレンダリング,ないしはGPGPUタスクのどちらかを割り込みで強制的に実行させるモードだ。リアルタイム性が高く,実行優先度の高いタスク,具体的にはVRにおける非同期タイムワープ処理などに適しているという。
Asynchronous Shaders(Async Shaders)は,優先度の高いタスクを実行しているとき,“遊んでいる”Compute Unitに対し,優先度の低いタスクを割り当てて実行するモードである。比較的優先度の高いグラフィックスレンダリングと,更新サイクルの低いパーティクル処理や背景物の物理シミュレーションなどを並行実行させるのに適したモードと言える。
最後のAsynchronous Shaders with Quick Response Queueは,「with」の前が同じであることから想像できるように,基本的にはAsynchronous Shadersと同じ。ただそのとき,グラフィックスレンダリングとGPGPUタスクとに,一定の比率でCompute Unitを割り当てて実行することになる。たとえば,低優先度でのんびり実行していたタスクを急遽終わらせる必要が出てきたときや,実行しているグラフィックスレンダリングタスクとGPGPUタスクの実行所要時間が事前に分かっていて,実行完了目標時間がおよそ見繕えている場合などに有効なモードとされる。
こちらも,VRにおけるタイムワープ処理に有効だろう。
なお,AMDはAsynchronous Shaders with Quick Response Queueについて,「サウンド関連の機能とも関係が深い」と説明してもいる。
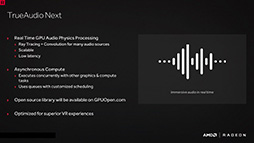
従来のGCN系Radeonが一部で「TrueAudio」に対応していたことを憶えている読者も多いだろうが,Polarisでこれは「TrueAudio Next」となった。
「Next」と聞くと,何となく新世代感を感じてしまうが,実はこのTrueAudio Next,機能拡張が入ったというよりも,実行メカニズムに大きな変更が入ったバージョンという理解のほうがより正しい。
従来のGCN系Radeon(の一部)が搭載していたTrueAudio機能は,Cadence Design SystemsのTensilica部門が開発するDSP(Digital Signal Processor,デジタル信号処理に特化したプロセッサ)「HiFi EP Audio DSP」によって実現していたが(関連記事),PolarisではこのDSPを省略してしまったのだ。そしてその代わりに,TrueAudio機能をCompute Unitが処理するようになった。そう,TrueAudio Nextとは,シェーダプロセッサを活用してTrueAudioの音響処理を行う考え方のことなのである。
TrueAudio NextではGPUで音響処理をソフトウェア実行することになるわけだが,これは当然のことながら,レンダリングタスクではなく,GPGPUタスクとしての処理となる。これを効率よくGPUで行うには,HWSがなくてはならなかったというわけだ。
AMDは,音響処理用DSPの省略を,前向きに捉えている。確かに今までは同じRadeonでもTrueAudioをサポートしていたりいなかったりしたわけだが,Polaris以降でそういう心配は無用になるわけで,だからこそAMDは「Next」なTrueAudioとしたのだろう。
ちなみにAMDは,「より複雑な反射音効果や音響遮蔽の効果を,実際のジオメトリ構造(=ゲーム世界の構成)に辻褄の合う形で表現するには,オーディオレイトレーシングを行う必要がある。そしてそれを実現することを考えると,既存の音響処理用DSPでは能力的に不十分で,GPGPUタスクで処理するのが望ましい」といったことも言っていたりする。
レイトレーシングというと,極めて負荷の高い処理であるように思うかもしれないが,AMDは,ゲーム音響のような限定された活用であれば,それほど高負荷にはならないと主張している。
たとえば,ゲーム世界で音を聞く聴者はユーザーだけなので,処理はユーザー基準の計算だけで済む。また,レイトレーシングで取り扱う音も,ユーザーの近い位置で発音されたものだけで限定してしまっていいだろう。そうした音源の発音位置座標からユーザーに向けた方向を基底ベクトル(=計算する際の基準ベクトル)にして数本のレイを全方位に投げて,聴者に届く音の音量の大きいものだけに音響処理を施す実装であれば,それほど高負荷にならず,しかも,かなりリアルな音響効果を得ることができるはずだ。
「VR時代にレイトレーシングオーディオは重要な要素になる」とまで力説しているAMDによる主要な実装例は,今後,AMDが提唱し始めたオープンソースプロジェクト「GPUOpen」で公開予定とのことである。
奇しくも,NVIDIAも同様の考え方を「VRWorks Audio」として提唱を始めているため(関連記事),音のレイトレーシングは,今後のトレンドとなるかもしれない。
今回はここまで。
Polarisという製品の位置付けや,従来のRadeonとはアーキテクチャ的に何が違っているのか,新機能は何かという部分について理解が進んだのであれば幸いだ。4Gamerでは別途,Radeon RX 480のレビュー記事を掲載しているので,ぜひそちらもチェックしてほしい。
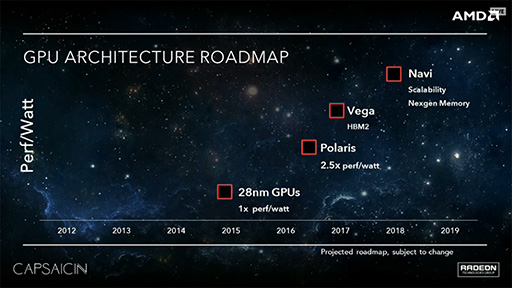
一方で,多くの読者は,「Radeon RX 480がRadeon R9 290Xとそのリフレッシュモデル並みの性能を199ドル(税別)という低コストで実現するものだとすれば,Radeon R9 Furyシリーズの後継はどうなるの?」と思ったことだろう。現時点でAMDはその情報をほとんど開示していないが,グラフィックスメモリとしてHBM2(High Bandwidth Memory 2)を,マクロアーキテクチャとして「Vega」(ヴェガ,開発コードネーム)をそれぞれ採用したGPUを2017年に市場投入予定とはしているので,これが「それ」になる可能性は大いにある。
Polaris解説の後編は,ディスプレイ出力周り,ビデオ機能周りなど,周辺機能をチェックしていくことにしたい。
 |
現在,単体GPU市場のシェアをAMDとNVIDIAで二分しているのは多くの人が知るところだが,直近のデータだとAMDのシェアは3割前後しかない(関連記事)。Polaris世代のGPUは,そんな状況を打破すべく,最上位モデルでも199ドル(税別)という,戦略的な北米市場におけるメーカー想定売価で,起死回生を狙って市場投入される製品なのだ。
当然ながらAMDの気合は並々ならぬものがあり,それゆえに(?),筆者のようなメディア側は,さんざん振り回されることとなった。
 |
「事前の告知なしに,段階的な開示期限と開示範囲を設定する」という,複雑極まりないNDA制御からやっと解放され,これでやっと落ち着ける……というのが偽らざる感想だが,ともあれ今回は,Polarisマクロアーキテクチャを採用するRadeon RX 400シリーズの技術解説を行っていきたい。
Polaris 10&11の2コア展開となる新世代GPU
さて,まず押さえてほしいのは,Polarisマクロアーキテクチャを採用するGPUコアには「Polaris 10」「Polaris 11」の2種類があるということだ。
Radeon RX 480とRadeon RX 470はPolaris 10コア,Radeon RX 460はPolaris 11コアを採用する。
 |
 |
 |
 |
 |
ダイサイズは,Polaris 10が232mm2,Polaris 11が124mm2とのこと。トランジスタ数は,Polaris 10のみ約57億個とAMDは発表している。
そんなAMDによる各製品の位置づけは以下のとおりだ。
●Radeon RX 480
〜2560
 |
●Radeon RX 470
〜1920
 |
●Radeon RX 460
〜「Radeon R7 370」に代わるコストパフォーマンス追求型モデルで,e-Sportsタイトル向けGPU
 |
これらAMDのメッセージからも分かるように,Polarisは「新世代トップエンドGPU」ではなく,従来世代のハイクラス,もしくはミドルクラスGPUと同等の性能を最新のプロセス技術で実現して製造コストを下げ,ひいてはユーザーにとって魅力的な店頭販売価格の実現を目指した製品だ。
Polaris 10&11の演算性能
 |
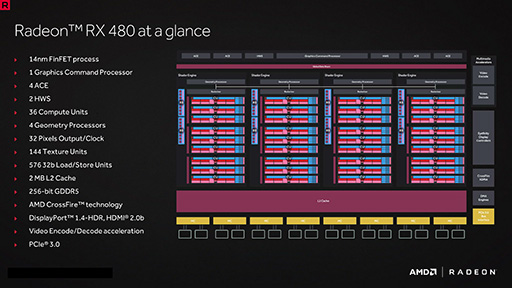
というわけでさっそくだが,両GPUコアの全体ブロック図は以下のとおり。ざっくりといえば,どちらも,「Graphics Core Next」(以下,GCN)アーキテクチャを採用してからのAMD製GPUで見慣れたブロック図といったところだ。
 |
 |
 |
Radeon HD 7000シリーズとして立ち上がったSouthern Islands世代がGCN 1.0,Sea IslandsとそのリフレッシュであるCaribbean IslandsがGCN 1.1,Volcanic IslandsとそのHBM(High Bandwidth Memory)対応版となるPirate IslandsがGCN 1.2で,今回のPolarisはGCN 1.3ベースだ。
 |
Shader Engineとは,演算ユニットとしての「Compute Unit」(コンピュートユニット)とは別に,頂点次元のデータを処理して頂点単位単位の仕事に分解する「Geometry Processor」(ジオメトリプロセッサ),そしてジオメトリとピクセルの対応を割り付けてピクセル単位の仕事に分解する「Rasterizer」(ラスタライザ)が各1基と,さらに演算結果として得られたピクセル単位のデータを実際にグラフィックスメモリへと出力する「Render Back-Ends」(レンダーバックエンド)4基をひとまとめにしたものである。それ単体でGPUに必要な処理系をすべて持っていることから,4Gamerではよく“ミニGPU”と呼んでいるが,実際,イメージとしては「マルチコアCPUにおけるCPUコア1基」に近い。
実際に演算処理を行うスカラプロセッサとしてのシェーダプロセッサは,64基で1つのCompute Unitを構成しており,このCompute Unitを,Shader Engineのクラスタごとに複数基搭載するのが,GCN系GPUの基本構成である。
 |
 |
ひとまず今回は「Radeon RX 470におけるShader EngineあたりのCompute Unit数は8基」と仮定して話を進めるが,総シェーダプロセッサ数の計算式は以下のとおりとなる。
- Radeon RX 480:64(シェーダプロセッサ)
× 9(Compute Unit) × 4(Shader Engine)=2304 - Radeon RX 470:64(シェーダプロセッサ)
× 8(Compute Unit) × 4(Shader Engine)=2048 - Radeon RX 460:64(シェーダプロセッサ)
× 8(Compute Unit) × 2(Shader Engine)=1024
動作クロックは,Radeon RX 480がベースクロック1120MHz,ブースト最大クロック1266MHz。Radeon RX 470とRadeon RX 460のスペックは,原稿執筆時点である6月26日の時点で開示されていない。
仮に,Radeon RX 470とRadeon RX 460の動作クロックもRadeon RX 480と同じであるとした場合,ブースト最大クロックにおける最大理論性能値としての単精度浮動小数点演算性能は以下のとおりだ。なお,下の計算式で「×2 FLOPS」としているのは,シェーダプロセッサ1基が1クロックで単精度浮動小数点数の積和算を実行できる「2 Ops」仕様だからだ。
- Radeon RX 480:2304(シェーダプロセッサ)
× 1266MHz × 2 FLOPS=5.834 TFLOPS - Radeon RX 470:2048(シェーダプロセッサ)
× 1266MHz × 2 FLOPS=5.186 TFLOPS - Radeon RX 460:1024(シェーダプロセッサ)
× 1266MHz × 2 FLOPS=2.593TFLOPS
AMDは「Polaris 10は5 TFLOPS以上」「Polaris 11は2 TFLOPS以上」とアナウンスしていたので,ほぼその説明どおりの数字が得られている。
ちなみに,Polaris登場後も最上位のRadeonとして君臨することになる「Radeon R9 Fury X」だと,総シェーダプロセッサ数が4096基,ブースト最大クロック1050MHzで,最大理論性能値は約8.602 TFLOPSとなる。
Hawaiiコアを採用するRadeon R9 200シリーズのハイエンドモデル「Radeon R9 290X」だと順に2816基,1000MHz,約5.632 TFLOPS。HawaiiコアのリフレッシュとなるGrenadaコアを採用した「Radeon R9 390X」だと,順に2816基,1050MHz,約5.914 TFLOPSなので,Radeon RX 480は,「Radeon R9 290Xを上回り,Radeon R9 390Xに迫る演算性能値を持ちつつも,製造プロセスの微細化効果でダイサイズを小型化して製造コストを下げたGPU」と言うこともできそうである。
GCN 1.3は何が新しくなったのか
では,第4世代GCNとなるGCN 1.3で何が新しくなったのかだが,実は,「GCN 1.2に対して細かなチューニングを行ったもの」という一言でまとめることができる。
まず,ジオメトリエンジンたるGeometry Processorにおける強化ポイントは2点,「Primitive Discard Accelerator」(プリミティブディスカードアクセラレータ)と「Index Cache for Small Instanced Geometry」(インデックスキャッシュ・フォー・スモールインスタンストジオメトリ)である。
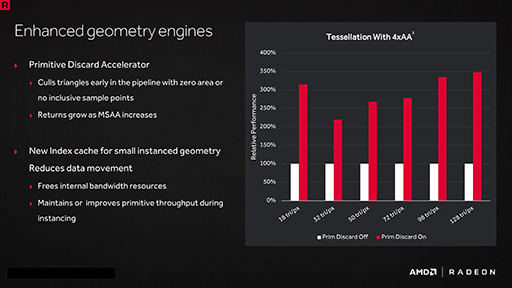 |
Primitive Discard Acceleratorは,ジオメトリデータ(≒ポリゴンデータ)をレンダリングパイプラインの下流へ流す前に,ジオメトリエンジンの上流側で,「明確に描画対象にならないもの」を排除してしまう機能だ。
いわゆる「早期カリング」(Early Culling)機能の一種であるだけに,「最近のGPUなら実装済みなのでは?」と思う人もいると思うが,一般的な早期カリングだと,視界外ポリゴンや裏面ポリゴンを除外するのに対し,Primitive Discard Acceleratorは,この早期カリングを“すり抜けてきた”ポリゴンに対して適用するものになる。
具体的な“効能”は,MSAA(Multi-Sampled Anti-Aliasing,マルチサンプルアンチエイリアシング)の処理面積――実質的にはレンダリング解像度の1ピクセルサイズ――に満たない微小なポリゴンの排除である。
MSAAの処理面積に満たない微小なポリゴンは,演算処理対象になったとしても,最終的にピクセルとして描画されることはない。であれば,早期に排除してしまおうというわけだ。オープンワールドのゲームなどで,遠方に多くのオブジェクトが配置されるようなゲームグラフィックスでは高い効果を発揮することだろう。
Geometry Processorの強化ポイント,2つめのIndex Cache for Small Instanced Geometryは,「同一の3Dモデルを異なるパラメータで複数大量に描画するときに用いるインスタンシング描画」を高効率化するために新設となった,専用キャッシュメモリのこと。インスタンシング描画で頻繁にアクセスすることとなるインデックスバッファをキャッシュに載せて内部バス消費を低減し,GPUのトータルな性能を向上させようという意図の新機能になる。
こちらは,同一のユニットを大量に描画するようなRTSや,同一モデルからなる自然物を,パラメータで変調させながら大量に描画する機会の多いオープンワールドのゲームで効果を発揮することだろう。
GPU全体の強化ポイント
前出のブロック図だと,PolarisでCompute Unit自体の構成に大きな変化はなさそうに見えるのだが,AMDは,Compute Unitの実行効率を上げるために,Compute Unit自体,そしてCompute Unitの周辺に細かい改良を施している。
 |
まず,「Command Processor」(コマンドプロセッサ)が命令語の先読み(Prefetch,プリフェッチ)に対応した。これは,CPUの高速化手法として,CPU業界では当たり前のように採用されている技術だ。
先読みは,CPUだと分岐実行が入ったとき無駄になってしまうが,GPUの場合,プログラムはSIMT(Single Instruction, Multiple Thread)実行形態であるため,条件分岐があって分岐するスレッドと分岐しないスレッドに分かれたとして,分岐するスレッドにおいても,実際にはジャンプせずにジャンプ先までの命令を無視し続け,分岐しないスレッドと歩調を合わせるような動作となる。つまり命令語の先読みは,GPUだと,分岐のありなしにかかわらず効果が大きいのである。
 |
Polarisでは今回,各Compute Unitにおいて,このWAVE単位で割り当てられる命令バッファのサイズを増加させる改良が入った。これにより,WAVEごとにバッファリングできる命令数が増加し,結果,各スレッドの実行効率が向上したと,AMDは述べている。
L2キャッシュの制御にも改善が入った。キャッシュメモリへのデータの出し入れをメモリチップのグループ分けに最適化した形で行う工夫を取り入れている(※L2キャッシュは容量の増加もトピックだが,その点は後述する)。
もう1つ,16bit半精度浮動小数点数と16bit整数を内部レジスタにてネイティブで取り扱えるようになったことも,Compute Unitにおける重要な機能拡張の1つとしてAMDは挙げている。
こう聞くと,「NVIDIAがPascal世代の『GP100』で採用した,16bitサイズのデータを2つ同時に32bit演算器で処理することによって2倍のスループットを稼ぐ,あのアクセラレーションを身に付けたのか!?」(関連記事)と思う人も多いだろう。筆者も一瞬そう思ってしまったのだが,確認したところ,あくまでも,レジスタファイル上のフットプリント(≒占有量)として32bit幅に2つ格納しておけるだけで,演算スループットは変わらないとのことだ。
要するに,2つの16bitデータを処理するにあたって,2つのレジスタを合わせて32bitに収めたうえで,実際の演算時には2つの32bitデータとして扱うということだ。得られる効果は,レジスタファイルの節約と内部バス帯域幅消費の節約のみとなるので,この点は注意してほしい。
L2キャッシュの増量によりメモリ効率を引き上げ
PolarisではグラフィックスメモリとしてGDDR5を採用する。NVIDIAが「GeForce GTX 1080」で採用したGDDR5XをAMDは見送ったわけだが,その理由を同社は「供給安定性やコスト面に配慮したため」としている。「それならRadeon R9 FuryシリーズのHBMは……?」という疑問もなくはないが,まあ,Radeon RX 400シリーズはいずれも価格対性能比重視のGPUなので,説明自体は納得できよう。
リファレンスデザインにおけるグラフィックスメモリ容量は,Radeon RX 480が4GBないしは8GB,Radeon RX 470が4GB,Radeon RX 460が2GB。動作クロックに関する説明は,少なくともマカオの説明会においてはなかったが,「最大で8GbpsデータレートのGDDR5をサポートする」という言及はあった。
メモリインタフェースはPolaris 10が256bit,Polaris 11が128bitとなるので,仮に3製品がすべてメモリクロック8GHz相当(実クロック2GHz)のGDDR5メモリを搭載するとするなら,メモリバス帯域幅は以下のとおりとなる。
- Radeon RX 480&470:256(bit)×8(GHz)÷8(bit)=256GB/s
- Radeon RX 460:128(bit)×8(GHz)÷8(bit)=128GB/s
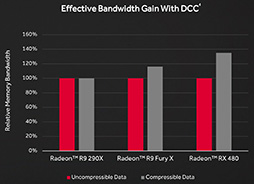 |
Lossless DCC自体に大きな改良はないように見える一方,AMDは今回,前段で後述するとしたL2キャッシュ容量を,Polaris 10で2MBと,Hawaii(およびそのリフレッシュとなるGrenada)コアの2倍に増量している。
GCN系RadeonのL2キャッシュは,Render Back-Endごとに1つのパーティションという割り当てになっている。Polaris 10全体で抱えるRender Back-Endの数は8基なので,Render Back-EndあたりのL2キャッシュ容量は(2048÷8)で256KBという計算だ。
このL2キャッシュ大増量により,実効メモリ性能は,Hawaiiコアを採用するRadeon R9 290シリーズの512bitメモリインタフェースが実現する320GB/sに迫るとAMDは説明している。また,L2キャッシュの容量増は,GDDR5メモリへのアクセス低減にもつながり,メモリアクセスに伴う消費電力をRadeon R9 290シリーズ比で40%も削減できたという。
 |
ちなみに,Polaris 11においてもL2キャッシュ増量は実現している。Radeon RX 460の場合,Render Back-End数は4基なので256KB×4=1024KBとなり,総L2キャッシュ容量は1MBとなる計算だ。
ハードウェア化されたスケジューラ
従来,ほとんどドライバ内で行われていた(≒CPUで実行処理されてきた)GPUスレッドのスケジューリングと発行を,PolarisではGPU内部に新設された「Hardware Scheduler」(以下,HWS)で実行するようになった。
より正確を期すと,このHWS自体はTonga&Fiji世代から存在するのだが,PolarisのHWSでは,プログラマビリティと柔軟性,効率を引き上げるため,大規模なアップデートを行ったという。
本稿の序盤で,Polaris 10のトランジスタ数は約67億個,シェーダプロセッサ数は2304基とお伝えしている。2560基のシェーダプロセッサを搭載する「Hawaii」コアだとトランジスタ数は約62億個なので,この「シェーダプロセッサ数が少ないにもかかわらず,HawaiiよりもPolaris 10のほうがトランジスタ数が多い」理由の大きな要因がこのHWSである可能性は高い。
さてこのHWSだが,個人的には,Polarisマクロアーキテクチャにおける最も革新的な改良点はここだと感じている。
 |
従来,この部分をドライバ任せにしていたのは,アプリケーションごとに最適なスケジューリングを行うにあたって,そのほうが適していたからだ。ではなぜ今回AMDは,HWSをGPU側に内蔵したのだろうか。
GPU内にHWSを置くことによって得られる最大のメリットは,GPU内部にあるリソースの状態(ステータス)をリアルタイムで把握し,その変移に瞬時かつ臨機応変に対応するスケジューリングを行えるようになることである。これはもちろん,GPU内のリソース,具体的にはシェーダプロセッサを有効活用できるようになることにつながる。
ソフトウェア処理だと,瞬間瞬間におけるGPU内部の状況が分かりにくく,制御自体は完璧に行えるとしても,どうしてもワンテンポ遅れてしまう。CPUから見れば,GPUはPCI Expressリンクの向こうにいる存在だからだ。
 |
とくに近年ブームとなりつつあるVR(Virtual Reality,仮想現実)では,非同期タイムワープ処理などの実行を,グラフィックスレンダリングの実行中にリアルタイムかつ非同期に割り込ませる必要があるため,GPU内部のリアルタイムなリソース徹底活用は重大なテーマとなってきた。だからこそAMDはこのタイミングで,GPUスレッドのスケジューリングと発行のための機能ブロックをGPU内部に実装してきたのである。
ちなみにこのHWS,「Hardware」とは言うものの,実のところ,GPU内部に実装された専用CPUにプログラムを実行させる仕様であることが明らかになっている。AMDによれば,この実装のため,ドライバなどのアップデートによって,HWSソフトウェアは適宜アップデートが可能だという。
なお,HWS専用としてGPUコアにどんなプロセッサを実装しているかまでは,AMDは明らかにしていない。
いずれにせよ,このHWSのおかげで,Polarisでは,GPU内部のCompute Unitを,グラフィックスレンダリングタスクとGPGPUタスク(=Computeタスク)に切り換えことができるようになったわけだ。
動作モードは「Preemption」(プリエンプション)と「Asynchronous Shaders」(アシンクロナスシェーダ),「Asynchronous Shaders with Quick Response Queue」(アシンクロナスシェーダ・ウィズ・クイックレスポンスキュー)の3種類である。
Preemptionは,グラフィックスレンダリング,ないしはGPGPUタスクのどちらかを割り込みで強制的に実行させるモードだ。リアルタイム性が高く,実行優先度の高いタスク,具体的にはVRにおける非同期タイムワープ処理などに適しているという。
Asynchronous Shaders(Async Shaders)は,優先度の高いタスクを実行しているとき,“遊んでいる”Compute Unitに対し,優先度の低いタスクを割り当てて実行するモードである。比較的優先度の高いグラフィックスレンダリングと,更新サイクルの低いパーティクル処理や背景物の物理シミュレーションなどを並行実行させるのに適したモードと言える。
 |
こちらも,VRにおけるタイムワープ処理に有効だろう。
 |
従来のGCN系Radeonが一部で「TrueAudio」に対応していたことを憶えている読者も多いだろうが,Polarisでこれは「TrueAudio Next」となった。
「Next」と聞くと,何となく新世代感を感じてしまうが,実はこのTrueAudio Next,機能拡張が入ったというよりも,実行メカニズムに大きな変更が入ったバージョンという理解のほうがより正しい。
従来のGCN系Radeon(の一部)が搭載していたTrueAudio機能は,Cadence Design SystemsのTensilica部門が開発するDSP(Digital Signal Processor,デジタル信号処理に特化したプロセッサ)「HiFi EP Audio DSP」によって実現していたが(関連記事),PolarisではこのDSPを省略してしまったのだ。そしてその代わりに,TrueAudio機能をCompute Unitが処理するようになった。そう,TrueAudio Nextとは,シェーダプロセッサを活用してTrueAudioの音響処理を行う考え方のことなのである。
 |
AMDは,音響処理用DSPの省略を,前向きに捉えている。確かに今までは同じRadeonでもTrueAudioをサポートしていたりいなかったりしたわけだが,Polaris以降でそういう心配は無用になるわけで,だからこそAMDは「Next」なTrueAudioとしたのだろう。
ちなみにAMDは,「より複雑な反射音効果や音響遮蔽の効果を,実際のジオメトリ構造(=ゲーム世界の構成)に辻褄の合う形で表現するには,オーディオレイトレーシングを行う必要がある。そしてそれを実現することを考えると,既存の音響処理用DSPでは能力的に不十分で,GPGPUタスクで処理するのが望ましい」といったことも言っていたりする。
 |
たとえば,ゲーム世界で音を聞く聴者はユーザーだけなので,処理はユーザー基準の計算だけで済む。また,レイトレーシングで取り扱う音も,ユーザーの近い位置で発音されたものだけで限定してしまっていいだろう。そうした音源の発音位置座標からユーザーに向けた方向を基底ベクトル(=計算する際の基準ベクトル)にして数本のレイを全方位に投げて,聴者に届く音の音量の大きいものだけに音響処理を施す実装であれば,それほど高負荷にならず,しかも,かなりリアルな音響効果を得ることができるはずだ。
「VR時代にレイトレーシングオーディオは重要な要素になる」とまで力説しているAMDによる主要な実装例は,今後,AMDが提唱し始めたオープンソースプロジェクト「GPUOpen」で公開予定とのことである。
奇しくも,NVIDIAも同様の考え方を「VRWorks Audio」として提唱を始めているため(関連記事),音のレイトレーシングは,今後のトレンドとなるかもしれない。
 |
RX 480はR9 290Xとそのリフレッシュモデル並みの性能を199ドルで実現する
今回はここまで。
Polarisという製品の位置付けや,従来のRadeonとはアーキテクチャ的に何が違っているのか,新機能は何かという部分について理解が進んだのであれば幸いだ。4Gamerでは別途,Radeon RX 480のレビュー記事を掲載しているので,ぜひそちらもチェックしてほしい。
一方で,多くの読者は,「Radeon RX 480がRadeon R9 290Xとそのリフレッシュモデル並みの性能を199ドル(税別)という低コストで実現するものだとすれば,Radeon R9 Furyシリーズの後継はどうなるの?」と思ったことだろう。現時点でAMDはその情報をほとんど開示していないが,グラフィックスメモリとしてHBM2(High Bandwidth Memory 2)を,マクロアーキテクチャとして「Vega」(ヴェガ,開発コードネーム)をそれぞれ採用したGPUを2017年に市場投入予定とはしているので,これが「それ」になる可能性は大いにある。
 |
Polaris解説の後編は,ディスプレイ出力周り,ビデオ機能周りなど,周辺機能をチェックしていくことにしたい。
- 関連タイトル:
 Radeon RX 400
Radeon RX 400 - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー