













連載
西川善司の3DGE:IntelのノートPC向けGPU「Arc」とはいかなるGPUなのか。性能から機能までをひもといてみた
 |
Intelが2020年に発表した「Iris Xe MAX」は,同社が,Intel 740(i740)をリリースした1998年以来,22年ぶりにリリースした単体GPU(Discrete GPU)だった。その進化版となるGPUが,今回のArcである。
発表イベント前に行われた技術説明会では,Arcに関する詳しい解説が行われたので,考察も交えて詳細に見ていきたい。
ArcシリーズはACM-G10とACM-G11の2種類が存在
Arcの開発コードネームは,もともと第2世代単体GPU(Discrete Graphics 2nd)の意味である「DG2」だったが(※第1世代の「DG1」がIris Xe MAX),2021年に「Alchemist」(錬金術師)へと改められた。今回発表となったArcシリーズは,Alchemistの頭文字を採って,Arc Aシリーズと呼ばれている。
ちなみに,今後の開発コードネームも決まっており,「Battlemage」(魔闘士),「Celestial」(天人,神官),「Druid」(ドルイド僧)であるという。括弧内の和訳は,筆者のつたないRPG知識から適当にあてたものだが,ファンタジーRPGにおける魔道師系職業の名前から引用するようだ。一見お堅そうなIntelにしては,遊び心のある開発コードネームである。
本題に戻ろう。Arcシリーズは,まずは,ノートPC向けGPUから登場することになっており,2022年4月に「Arc 3」が,やや間をあけて初夏(Early Summer)に上位モデルとなる「Arc 5」と「Arc 7」が登場する予定だ。
Arc 3シリーズは,「CPUの統合グラフィックス機能(以下,統合GPU)よりも上位のゲーム体験が楽しめる」というコンセプトの「Enhanced Gaming」(拡張ゲーミング)を提供するGPUであるという。
Arc 5は,「多様なゲームを満足いく品質でプレイできる」ことをコンセプトにした「Advanced Gaming」(先進ゲーミング)を提供するGPUである。実質的には,いわゆるメインストリーム(≒ミドル)クラスのGPUということだ。
最後のArc 7は,「高品位なゲーム体験が楽しめる」ゲーマー向けデスクトップPCに迫る性能を提供する「High Performance Gaming」(ハイパフォーマンスゲーミング)クラスのGPUで,2022年に登場するArcシリーズの中では上位製品に相当する。
 |
さて,GPU製品としてはArc 3/5/7というブランドで分けられるが,半導体ダイは,「ACM-G10」と「ACM-G11」の2種類が製造される。ACM-G10が上位モデルで,ACM-G11が下位モデルだ。
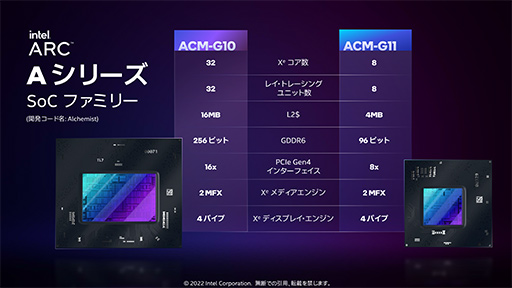 |
Arcの製造はIntelではなく,台湾TSMCの6nmプロセスで行われる。ダイサイズとトランジスタ総数は,以下のとおり。
| ダイサイズ | トランジスタ総数 | |
|---|---|---|
| ACM-G10 | 406mm2 | 約217億個 |
| ACM-G11 | 157mm2 | 約72億個 |
トランジスタ数で近いGPUを挙げると,ACM-G10は,「GeForce RTX 2080 Ti」系(TU102)の約186億個を上回り,ACM-G11は,「Radeon RX 6500 XT」(Navi 24)の約54億個を上回る規模だ。
ACM-G11は,Arc 3として,ACM-G10は,Arc 7/5として製品化される。
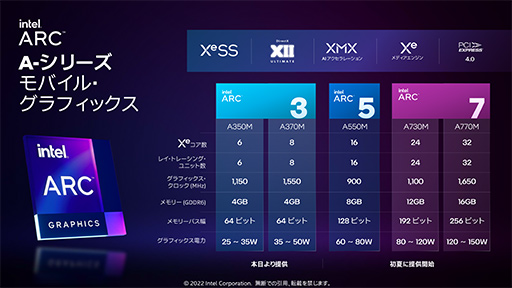 |
上のスライドを見ると分かりやすいが,ACM-G11を採用したArc 3の下位モデルが「A350M」で,上位モデルが「A370M」だ。Arc 5は,「A550M」のみであるが,実はACM-G10のコア半分を無効化した製品になるとのこと。Arc 7もACM-G10ベースの製品で,実動するコア数の違いで下位モデルの「A730M」と上位モデルの「A770M」という2製品がラインナップされる。
なお,すべてのArcシリーズがPCI Express 4.0接続に対応する。
ところで,ACM-G11のメモリインタフェースが96bitであるにもかかわらず,それを採用しているArc 3製品では,64bitになっているのは不思議だ。おそらく,いずれは96bitすべてを活用して容量6GBのグラフィックスメモリを搭載する上位モデルが追加されて,今は1製品しかないArc 5の下位モデルとして登場する可能性があるのではなかろうか。
動作クロックを示す「Graphics Clock」(グラフィックス・クロック)について,Intelは,時間を割いて補足説明を行っていた。それによると,「競合他社は,瞬間的な最大クロックをスペック情報に記す傾向があるが,Intelは,最も高負荷な瞬間最大クロックと,最も低負荷な動作クロックの中間値をGraphics Clockと定義する」そうだ。つまり,スライドに書かれているGraphics Clockも動作クロックの一例にすぎず,実際はPCの熱設計に応じて多少は上下するようである。
 |
 |
 |
GeForceやRadeonとよく似ているArcの内部構造
IntelのArc Aシリーズのアーキテクチャに「Xe HPG」という名を与えている。「Xeは,IntelのGPU技術におけるブランド名で,最初の世代は「Xe LP」という名称で,Tiger Lake世代以降のCoreプロセッサにおける統合GPUに採用されている。なお,「LP」は省電力(Low Power)の意味だ。一方,Xe HPGのHPGとは,「High Performance Graphics」の略であるという。
Xe HPGは,Xe LPから性能や機能面で大幅に強化されている。とくにリアルタイムレイトレーシングユニットの実装は,目に付く違いであるが,まずはXe HPGの構造全体から見ていこう。
Intelは,Xe HPG全体のブロックダイアグラムを公開していない。ただ,上位ダイであるACM-G10の全体像を掴めそうなものはある。それが次のスライドだ。メモリインタフェースなどが描かれていないので不自然ではあるが,参考にはなろう。
 |
さて,上のスライドを見ると,「Render Slice」が8つあることに気がつく。Xe系GPUでは,このRender Sliceというクラスタが最も大きな塊となっており,GPUとして機能する一通りの機能が1セットになっている。これは,CPUでいうところのCPUコアに近いイメージであり,NVIDIAのGeForce系GPUで言うところの「Graphics Processor Cluster(GPC),AMDのRadeon系GPUで言うところの「Shader Engine」(SE)に相当するものとたとえれば理解しやすいかもしれない。
Arcの上位モデルであるACM-G10は,Render Sliceを8つ組み合わせているので,先のスライドは,ACM-G10の全体像に近いと言えるわけだ。ちなみに,下位モデルのACM-G11は,Render Sliceが2つしかない。
Render Sliceを拡大したものが,次のスライドである。
 |
この図に描かれている要素のひとつひとつに関する詳細はあとで説明するとして,スライド内の分かりにくそうな用語から説明していこう。
まず,Render Sliceは,4つの大きな「Xe-Core」で構成される。Xe-Coreは,与えられたスレッドグループを処理する最小の単位だ。つまり,GeForceでいうところの「Streaming Multiprocessor」(SM),Radeonでの「Compute Unit」(CU)に相当する。
Xe-Coreの中には,16基の「XVE」(Xe Vector Engine)と,16基の「XMX」(Xe Matrix Engine),Load/Store(ロード/ストア)ユニット,命令キャッシュ(I$),L1キャッシュ兼SLM(Shared Local Memory)がある。
「Thread Sorting Unit」は,Xe-Coreに流し込むスレッドグループの制御を行うものだ。
「Ray Tracing Unit」は,読んで字の如くで,レイトレーシングを行うユニットのこと。具体的には3Dシーンに対してレイのキャスト(放出あるいは生成すること),トラバース(横断あるいは推進すること),インターセクション(交叉)判定を行うユニットである。Intelによると,このレイトレーシングユニットは,MicrosoftのDirectX 12 Ultimateにおける「DirectX Raytracing」と,Vulkanにおける「Vulkan Ray Tracing」に対応するそうだ。
4基ある「Sampler」は,テクスチャユニットに相当するものだと思われる。
「Geometry」はジオメトリエンジンに相当するもので,頂点単位(ポリゴン単位)のタスク生成と管理を行うものだ。
「Rasterizer」は,頂点パイプラインの処理を経て出力された各ポリゴンを,ピクセル単位のタスクに分解するラスタライズ処理ユニット(ラスタライザ)である。
「HiZ」は,「Hierarchical Z」の略で,階層型Zバッファ処理ユニットのことだ。レンダリングされる見込みのないポリゴン(あるいはピクセル)をXe-Coreに流し込む前に破棄する「早期Zカリング」(Early Culling)の処理などに関わる(関連記事)。
最後の「Pixel Backend」は,GeForceにおける「Rendering Output Pipeline」(ROP)や,Radeonにおける「Render Backend」に相当するもので,最終的に演算を終えたピクセルを描画する,すなわちグラフィックスメモリに出力するユニットである。
こうして見ると,名前は違えど,GeForceやRadeonとよく似た構造になっているのが分かる。
Arcのシェーダコアは256bitSIMD浮動小数点数ベクトル積和算演算器
続いて,Xe-Coreの構成ユニットを細かく見ていこう。
 |
Xe-Core内に16基あるXVEは,実体として256bitのSIMD(Single Instruction Stream-Multiple Data)浮動小数点数ベクトル積和算演算器である。32bit浮動小数点数(FP32)ならば,SIMD8,つまり1命令で8要素のデータに対して同時に計算できる演算器として動作できるわけだ。
 |
これが分かると,ArcにおけるFP32の理論性能値が以下の計算式で求められる。
- Xe-Core数×XVE 16基×SIMD8×2 FLOPS(積和算)×動作クロック(MHz)
この式を元にした,Arc Aシリーズの理論性能値を表2にまとめておこう。
| 型番 | Xe-Core | 動作クロック | FP32理論性能値 | |
|---|---|---|---|---|
| Arc 7 | A770M | 32 | 1650MHz | 13.5 TFLOPS |
| A730M | 24 | 1100MHz | 6.8 TFLOPS | |
| Arc 5 | A550M | 16 | 900MHz | 3.7 TFLOPS |
| Arc 3 | A370M | 8 | 1550MHz | 3.2 TFLOPS |
| A350M | 6 | 1150MHz | 1.8 TFLOPS |
A350Mは,2 TFLOPS未満で,Xe LPシリーズ(※最大で約2 TFLOPS)と性能面ではそれほど変わらない性能だ。そう考えると,3.1 TFLOPSのA370Mあたりから,Xe HPGアーキテクチャが本領を発揮しそうといったところか。
A550Mの3.6 TFLOPSは,A370Mの3.1 TFLOPSから大きくは向上していない。ただ,A370Mのメモリインタフェースが64bitなのに対して,A550は128bitなので,この違いが実効性能で大きな違いを生むだろう。
A730Mの6.8 TFLOPSは,フルHD解像度であれば,最新ゲームのグラフィックス品質を高品位に設定してもストレスなく遊べそうだ。最上位であるA770Mの13.2 TFLOPSは,ハイエンドのGeForceやRadeonには勝てないまでも,中堅クラスには拮抗できる性能を期待できそうである。
表3に,Arc Aシリーズと理論性能値の近いGeForceシリーズをまとめてみた。大雑把な性能をイメージできるのではないだろうか。
| FP32理論性能値 | |
|---|---|
| A770M | 13.5 TFLOPS |
| GeForce RTX 3060 | 12.7 TFLOPS |
| A730M | 6.8 TFLOPS |
| GeForce RTX 2060 | 6.5 TFLOPS |
| A550M | 3.7 TFLOPS |
| A370M | 3.2 TFLOPS |
| GeForce GTX 1650 | 2.9 TFLOPS |
| A350M | 1.8 TFLOPS |
ちなみに,アーキテクチャや動作クロックが違うので,直接の比較にはならないが,参考値としてゲーム機の理論性能値を挙げておくと,PlayStation 4が1.84 TFLOPSで,PlayStation 4 Proが4.2 TFLOPS,Xbox One Xは6 TFLOPS,PlayStation 5は10.3 TFLOPS,Xbox Series Xは12.1 TFLOPSである。
次のスライドは,はXe-Coreをもう少し拡大したものだ。
 |
このスライドにあるとおり,Xe-Core内のXVEユニットとXMXユニット,そして「EM」(Extended Math,超越関数)ユニットは,それぞれ2個ずつがペアの1基となっており,分岐ユニット(Branch)を,共有している。
ちなみに,AMDで「ミスターRadeon」と呼ばれ,後にIntelへ移籍したRaja Koduri氏(Senior Vice President,General Manager,Accelerated Computing Systems and Graphics Group,Intel)の手腕によるものなのかは分からないが,2基ずつの実行ユニットペアが分岐ユニットなどのユニットを共有する構造は,RDNA世代のRadeonにおけるCUと構造がそっくりだ。
また,XVE×2基,XMX×2基,EM×2基からなるこのクラスタにおいては,浮動小数点数演算命令,整数演算命令,超越関数命令,XMX命令は同時に発行でき,担当実行ユニットが暇で,かつ命令同士に依存関係がなければ,並列実行も行える仕様だ。このあたりは,今どきのGPUでは,もはや当然の方式である。
次のスライドにもあるように,Xe-Coreには,命令キャッシュ(I$)とは別に,容量192KBのL1キャッシュ(L1$/SLM)がある。これは,Xe-Core内すべてのXVEとXMXで共有される仕組みだ。
 |
さらに,192KBのL1キャッシュは,任意の容量をXVEやXMX同士の連携を図るための共有メモリとして利用できるようになっている。このあたりは,GeForceにおけるCUDA Coreのアーキテクチャとよく似ている。
XMXはArc版Tensor Core
さて,ここまでたびたび名前が出てきたXMXは,Xe-Coreに組み込まれたIntel版Tensor Coreとも言うべき演算ユニットだ。その数はXVEと同じ16基である。
Intelは,1基あたりXMXが,1024bit幅の浮動小数点数行列積和算演算器であると説明している。
 |
NVIDIA製GPUにTensor Coreが搭載されるようになってからだいぶ経ち,最近では「Tensor Coreとは何か」の解説を4Gamerでもしなくなっていた。Intel製GPUにこうしたユニットが搭載されたのは,今回が初めてなので,改めて簡単に説明しておくとしよう。
行列同士の積和算は,データ列同士で畳み込み演算を行うときに多用されるもので,GPUをGPGPU的に活用することで行える。しかし,機械学習(深層学習)におけるAIの学習処理,あるいはその学習データから推論を導き出す推論処理では,行列同士の積和算が多用されることから,専用の行列積和算演算器に対する需要が高まってきた。スマートフォン向けのSoC(System-on-a-Chip)に搭載されるようになった「AIチップ」という名前のアレも,要はこうした行列積和算演算器の塊である。
AI関連処理に用いられる行列積和算は,高い演算精度が必要ないことが多く,4bitや8bit整数,16bit浮動小数点数が用いられる。また,そうした行列積和算演算器には,グラフィックス処理に用いられるシェーダプロセッサのような汎用性も必要ない。そんな理由もあって,NVIDIA製GPUのTensor Coreは,CUDA CoreがサポートしていないようなAI関連処理に用いる特殊な数値形式を数多くサポートしていた。
XMXはどうだろう。Intelによると,XMXは,16bit浮動小数点数(FP16),BF16,INT8(8bit整数),INT4(4bit整数),INT2(2bit整数)をサポートするそうだ。BF16(bfloat16)は,AI業界で利用頻度の高い形式で,精度よりもダイナミックレンジを重視した浮動小数点数形式である。具体的には,指数部はFP32と同等の8bitであるが,精度に関わる仮数部を7bitに減らして,値が正か負かを示す符号ビットと合わせて16bitにした16bit浮動小数点数フォーマットだ。ちなみに,NVIDIAのTensor CoreもBF16をサポートしている。
XMXは,1024bit幅の行列積和算演算器なので,FP16における4×4要素の行列(256bit)積和算を4並列=1024bit÷256bit実行できる。
 |
上に掲載したスライドでFP16またはBF16のクロック辺りの演算数(=同時実行数)が「128」となっている根拠は,Xe-Core 1基にXMXが16基あるためだ。式にするとこうなる。
4 並列×2 FLOPS(積和算)×XMX 16基=128/クロック
ちなみに,XMXのスループットは,NVIDIAにおけるTuring世代以降のTensor Coreと同じだ。
INT8やINT4/INT2も同じ理屈だ。INT8の4×4要素行列(128bit)なら8並列,INT4なら16並列で実行できる。そこで,これらの並列数に「2 FLOPS(積和算)×XMX 16基」をかければ,スライドにある各数値形式ごとの値が出てくるわけだ。
次のスライドは,左と中央がXVEによるスループット,右がXMXのスループットを示している。
なお,「MAC」は「Multiply Accumulate」の略だ。Accumulateの訳は演算だが,計算器業界では和算を意味するので,MACは積和算となる。一方,DP4aとは,「Signed Integer Dot-Product of 4 Elements and Accumulate」の略で,意味は「符号付き整数による4要素行列(ベクトル)積和算」となる。ここで言う符号付き整数とは,8bit整数(INT8)のことだ。
 |
これを踏まえたうえで上のスライドを見ると,「ArcのXVEは,INT8の4要素行列積和算に対応する」ことが読み取れる。XMXを用いなくても,XVEでINT8の4要素行列積和算は行えるのだ。
ちなみに,Tensor Coreを搭載していないPascal世代のNVIDIA製GPUも,CUDA CoreによるDP4aに対応していたので,Arcの仕様は驚くことではない。
推論アクセラレータXMXでXeSSを実現
XMXの有用さを,ゲーマーにも直接アピールできる機能として,Intelは,AIベースでゲームグラフィックスのアンチエイリアシングや超解像処理を行う「Xe Super Sampling」(XeSS)技術を提供する。これは,NVIDIAのGeForce RTX以上で利用できる「DLSS」と,ほぼ同系の機能である。

DLSSがそうであるように,XeSSは,過去の映像フレームを参照したテンポラル処理を行うため,ゲームグラフィックス側から各フレームにおける1ピクセル単位のモーション情報(ベロシティバッファ)をもらう必要がある。こうした複雑な処理系であるため,XeSSを利用するには,ゲーム側が個別に対応しなくてはならない。
2022年4月時点で,14タイトルがXeSS対応表明をしているとのこと。リリースされたばかりの「Ghostwire Tokyo」があることは目を惹く。
 |
また,これもアプリ側の個別対応が必要になるが,ゲーム映像だけではなく,動画に対するフィルタ処理にXMXを用いるソリューションも,さまざまなものが計画中とのことである。
XMXを活用した動画処理アプリで,最も早くArcユーザーに提供されそうなのは,さまざまなAI処理ベースの画像・動画フィルタをリリースしていることで有名なTopaz Labsの「Video Enhance AI」になりそうだ。

Arcのビデオプロセッサ「Xe Media Engine」は世界初の「AV1」エンコードに対応
Arcシリーズは,内蔵のビデオプロセッサとして「Xe Media Engine」を搭載する。GeForceでお馴染みの「NVENC」的なものだ。
Xe Media Engineでは,最大で12bit HDR形式で8K/60fpsの動画をリアルタイムデコードできる。一方,エンコードは,10bit HDR形式で8K解像度に対応しており,リアルタイムエンコードにこだわらなければ,上限フレームレートは(※常識の範囲内で)とくに設けられていない。
対応コーデックは,「VP9」「H.264」(AVC),「H.265」(HEVC)に加えて,「AV1」が上げられている。
 |
AV1は,非営利団体のAlliance for Open Mediaが策定した動画コーデックだ。使用するのに特許使用料が不要なライセンスフリーのコーデックであり,最近ではYouTubeがAV1に対応したこともあって,普及が期待されている。
AV1は,同等の画質であればH.265比で20〜30%ほどビットレートを下げられるという高圧縮率が最大の長所だが,一方で,エンコード処理の負荷が非常に高いという短所も持つ。具体的には,CPUベースでAV1圧縮を行った場合の所要時間は,同一条件でH.265を用いた場合の2倍以上かかるそうで,高速なエンコーダの登場が望まれていた。
GeForce RTX 30シリーズやRadeon RX 6000シリーズのビデオプロセッサは,AV1のハードウェアデコードには対応しているものの,エンコードにはまだ対応していない。そんな状況でIntelは,AV1ハードウェアエンコーダを業界で初めてGPUに搭載した。映像制作現場やYouTuberといった高速な動画エンコードが必要なユーザーには,魅力的な機能として響きそうだ。
 |
Intelは,「Xe Media Engineのエンコード速度は,CPUによるエンコード処理の約50倍は高速である」とアピールしている。実際,XSplitでAV1を用いて,「ELDEN RING」のゲーム実況を配信するデモが公開されたが,たしかにフルHD解像度でビットレート5Mbpsの設定では,リアルタイムエンコードが実現できているようだ。

残念ながら,Xe Media EngineのAV1エンコーダが,リアルタイムエンコードでどのくらいのビットレート設定や解像度まで対応できるのかについての情報は,明らかになっていない。実効性能は,実際の製品リリース後のレポートを待つ必要がある。
いずれにせよ,Xe Media EngineのAV1エンコード対応は,AV1の普及に一役貢献しそうだ。
Arc単体ではHDMI 2.1には未対応
オプションの「PCON」を活用すれば可能に
すべてのArcシリーズは,映像出力ユニットの「Xe Display Engine」を備えており,最大4系統の同時映像出力が可能だ。Xe Display Engineで伝送可能な解像度モードは,非可逆圧縮モードのDSC(Display Stream Compression)を利用すれば,8K HDRで60Hzの映像を2画面分か,4K HDRで120Hzを4面分となっている。ただ,実際のArc搭載ノートPCが4系統の映像出力端子を搭載するかどうかは,各PCメーカーの判断によって異なる。
 |
Arcが標準で対応している映像出力インタフェースは,HDMI 2.0bとDisplayPort 1.4aの2種類だ。DisplayPortについては,DisplayPort 2.0規格の「10Gbps×4レーン」モードに対応可能なポテンシャルがあると,Intelは,アピールしている。
だが,HDMI 2.1に未対応なのは残念だ。この点について筆者が指摘したところ,Intelは,Arcシリーズ用のオプションパーツとして「DisplayPort To HDMI Protocol Converter」(PCON)なるオプションを用意しており,これをPCメーカーがArc搭載ノートPCに組み込むことで,40Gbpsまでの伝送帯域幅に対応したHDMI 2.1準拠のHDMI出力端子を搭載できるということだった。
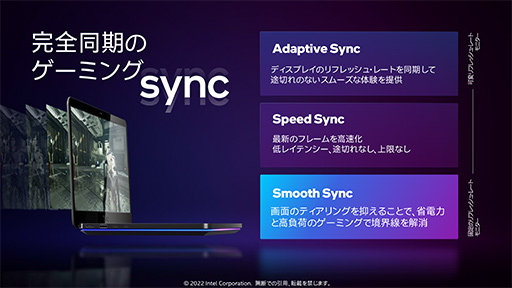
また,Xe Display Engineは,VESA標準規格であるディスプレイ同期技術(可変フレームレート出力技術)である「Adaptive-Sync」に対応しており,Adaptive-Sync対応ディスプレイや,ほぼ同一の技術であるHDMI 2.1の「Variable Refresh Rate」(VRR)対応ディスプレイで,テアリングやスタッター(映像のカクつき)がないスムーズな表示を行える。
なお,テアリングとは,フレーム「A」を表示中に,表示対象が描画完了直後のフレーム「B」に切り換わってしまうことで映像が分断されたように見える現象のことだ。
 |
Intelは,Arcの発表に合わせて,新しいディスプレイ同期技術として「Speed Sync」と「Smooth Sync」を発表した。どちらもVsync(垂直同期)オフ時に利用できる機能で,Arcのハードウェアとドライバソフトウェアの連携で実現するものだという。Speed SyncとSmooth Syncの実現に,特別な追加ハードウェアは不要で,ごく一般的な既存のディスプレイと組み合わせても利用できるそうだ。
どういった機能かと言うと,Speed SyncとSmooth Syncは,垂直同期オフ時に発生するテアリング現象を低減させる機能である。
Speed Syncでは,テアリングが起きそうな表示進行中のタイミングではフレームBに切り換えず,最後までフレームAを表示させるように制御する。こうすることで,フレームAもフレームBも正常に表示されてテアリングを回避できる理屈だ。簡単に言えば,ソフトウェア的に垂直同期オンのように振る舞う表示手法ということになる。
 |
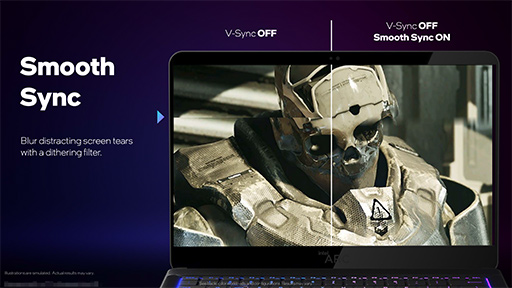
それに対して,Smooth Syncは,Xe Display Engineの専用ユニットが実現する技術とのこと。具体的には,垂直同期オフ時に発生するテアリングを許容する一方で,テアリング部分をハードウェア的にぼかしてしまう機能である。先の例で言うと,フレームAとフレームBの境界線周辺をテアリングが目立たなくなるようにぼかすのだ。
Smooth Syncの実現には,フレームAとフレームBの表示が交叉する画面上の垂直座標(Y座標)を把握することが必要となる。というのも,交叉タイミングが判明しないと,ぼかしフィルタの適用タイミングが確定できないからだ。
 |
テアリングが起きてしまうY座標から下は,表示する映像がフレームBなので,表示するときにぼかせばいい。しかし,Y座標より上は,フレームAの表示が完了してしまっているので,後からではぼかす処理は間に合わない。
そこでSmooth Syncでは,このような仕組みで動作する。
- ぼかしフィルタ幅の半分に当たるライン数――ぼかしフィルタが32ライン分なら,16ライン分――だけ映像を随時溜め込む。
- 映像フレームの表示が始まるタイミングを,溜めたライン数分だけ遅らせながら表示する。
- フレームAの表示が終わってないうちに,フレームBのデータが送られてくる。これにより,テアリング発生ラインが確定する。
- フレームAのバッファ分に対して,ぼかしフィルタをかけながら表示する。
- フレームBのバッファ分に対して,ぼかしフィルタをかけながら表示する。
- 残りのフレームBは,ぼかさずにそのまま表示する。
Smooth Syncは,映像を少しずつバッファに溜め込みながら描画することで,テアリングが発生したら,発生ラインの上下をぼかして表示するわけだ。テアリングがなくなるわけではないが,目立ちにくくはなるので見栄えはましになる。
 |
溜め込みながら表示する仕組みであるため,Smooth Syncを有効化すると,映像を溜め込んだライン数分だけ,表示は遅延する。Intelによると,「わずか十数ライン分の遅延なので,ゲームプレイに支障はないと考える」とのことだった。
CPUとGPUをIntelで揃えるといいことあるDeep Link
かつてAMDは,CPUをRyzen,GPUをRadeonで揃えると,CPUとGPU間のデータ伝送を高効率に行える「Smart Access Memory」機能をアピールしていた。言うなれば,「CPUとGPUをAMDで揃えるといいことがある」と囲い込みを狙った戦略だ。
Intelもせっかく,単体GPUを出したのだから「CPUもGPUもIntelで揃えよう」というプラットフォーム戦略をやらない理由はない。ということで,Arc登場に合わせてIntelは,「Deep Link」という新プラットフォーム戦略をアナウンスしたのだ。
Intelが,Deep Linkで提供するのは,以下に示す3つの機能だ。
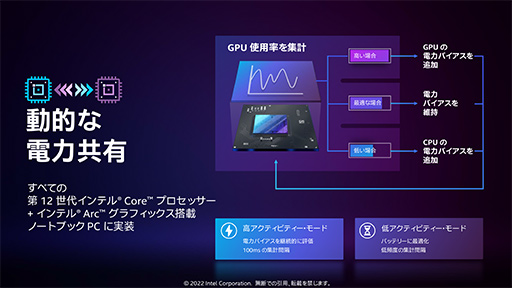
- Dynamic Power Share(動的な電力共有)
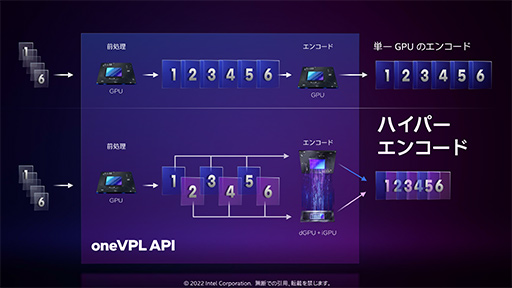
- Hyper Encode(ハイパーエンコーディング)
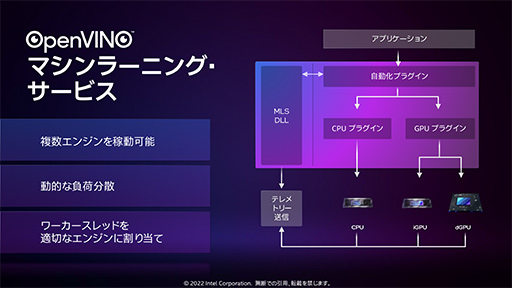
- Hyper Compute(ハイパーコンピューティング)
 |
まず,Dynamic Power Shareは,第12世代CoreプロセッサとArcを組み合わせた構成で可能になる機能で,CPUとGPUそれぞれの負荷状況に応じて,電力を最適に振り分けるものである。Dynamic Power Shareは,AMDがノートPC向けRyzen APUとRadeonを組み合わせたプラットフォーム向けに提供している「SmartShift」と,コンセプトは同じとみていいだろう。
 |
2つめのHyper Encodeは,1つの動画ストリームに対するエンコード処理を,CPUに組み込まれた統合GPU側のビデオプロセッサと,Arc内蔵のビデオプロセッサを両方とも使って処理するものだ。動画の編集や配信をPC 1台で行うユーザーには,魅力的な機能だといえる。
ただ,既存の映像編集ソフトが,IntelのCPU+GPU環境で自動的にHyper Encode対応になるわけではない。ソフト側がHyper Encodeに対応するためには,Intel製のフレームワーク・開発キットである「oneVPL」APIを使って対応機能を作る必要がある。
 |
3つめのHyper Computeは,AI処理やコンピュータビジョン処理を,統合GPUとArcの協調動作で加速する技術だ。こちらも,Intel製CPU+GPU環境環境であれば自動で適用されるものではなく,IntelがAI開発やコンピュータビジョン系技術開発向けフレームワークとして推進してきた「OpenVINO」を利用して,Hyper Compute対応アプリを開発する必要がある。
 |
Dynamic Power Shareは,第12世代Coreプロセッサと組み合わせた場合にしか利用できないようだが,Hyper EncodeとHyper Computeは,oneVPL APIやOpenVINOが利用できれば,Coreプロセッサの世代は問わないそうである。
だとすると,「RyzenとArcを組み合わせたときにDeep Linkは使えるのか?」という疑問も湧くわけだが,これに対してIntelは,「他社を締め出すつもりはない。しかし,Hyper EncodeとHyper Computeは統合GPUの機能を活用するため,他社製統合GPUにoneVPL APIやOpenVINOへ対応してもらう必要がある」と,ジョークとも本気ともつかぬ回答をしていた。まあ,対応の可能性は低いだろう。
デスクトップ版のArc Aシリーズが限定発売される?
NVIDIAのGeForceには「GeForce Experience」が,AMDのRadeonには「AMD Radeon Software」といったコンパニオンソフトウェアがあるように,Intelは,Arc専用ソフトウェアとして,「Intel Arc Control」(以下,Arc Control)をユーザー向けに提供するそうだ。
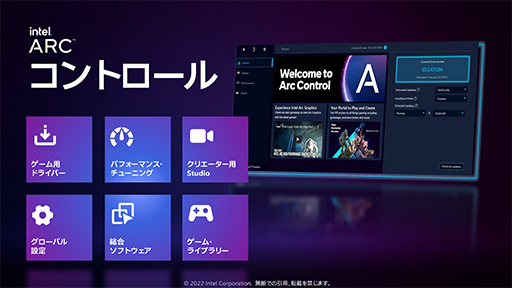 |
Arc Controlには,ドライバソフトウェアの自動更新,パフォーマンスモニタ,動画配信・録画機能,ゲームライブラリ管理や,各ゲームごとの設定管理といった機能が実装されるそうで,競合他社のコンパニオンソフトウェアに対して見劣りする部分はなさそうだ。
Intelは現在,Intelが認証した薄型軽量ノートPCプログラムとして「Intel Evoプラットフォーム」というブランディング戦略を行っている。2022年4月以降は,Intel Evoに準拠したArc搭載ノートPCが,PCメーカーから多数発売されると,Intelは予告していた。要は,「Intel Evo印のArc搭載ノートPCを買えば安心です」というブランディングを展開していくわけだ。
 |
今回のメインテーマはノートPC向けのArc Aシリーズであるが,Intelは,Arc Aシリーズを搭載するデスクトップPC向けグラフィックスカードの姿も公開している。その名は「Intel Arc A-Series Limited Edition Graphics」だ。
 |
AMDやNVIDIAは,ノートPC向けGPUとデスクトップPC向けGPUで同じダイを活用しているので,IntelがノートPC向け単体GPUとして発表したArc Aシリーズを,デスクトップPC向けグラフィックスカードに搭載しても,不思議なことではない。
仮にそうだとすれば,ノートPC版GPUとして用いる場合の動作クロックよりも,高めのクロックで動かすことになるはずだ。たとえば,Arc 7の上位モデルであるA770Mを搭載する場合,13 TFLOPSを大きく超えた性能を見せるかもしれない。
グラフィックスカード版の登場は今夏とのことなので。今から楽しみである。
- 関連タイトル:
 Intel Arc(Intel Xe)
Intel Arc(Intel Xe)
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー