









イベント
圧倒的低消費電力,ARMのCPUロードマップの中で重要な位置を占めるCortex-A7詳報
 |
本稿では,「モバイルの技術革新を可能にするCortex-A7プロセッサ」と題された技術セッションの模様を紹介したい。このセッションは,もともとはCPUのロードマップ解説に位置づけられていたものだが,内容はタイトルの通りCortex-A7の概要が中心。それだけ同社のロードマップの中でCortex-A7が占める位置が重要ということだろう。
高い電力効率と,そこそこの性能を併せ持つCortex-A7
Cortex-A7は,今年10月に英ARMが発表した新しいプロセッサIPコアだ。Cortexファミリーの型番は,Aがスマートフォンなど高性能機器向けのアプリケーションプロセッサを表し,後ろの数字はおおよその性能ランクを表している。Cortex-A7は,高性能携帯電話に多く採用されていたCortex-A5よりは上,現在のメインストリーム製品に採用が進んできているCortex-A9よりは下という性能ランクに位置づけられるコアだ。
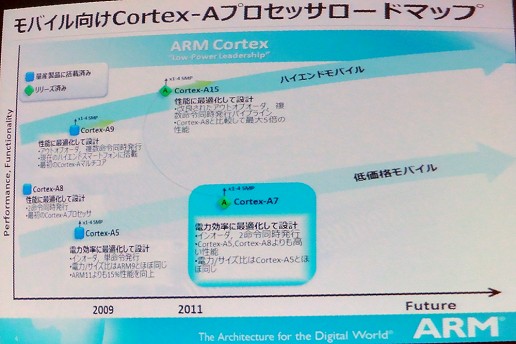 |
Cortex-A9より下のランクの製品がARMのロードマップの中で,どうして重要なポジションにあるのだろうか。そのあたりを含めながらCortex-A7の特徴をセッションの内容をもとに紹介してみたい。
 |
小林氏が最初に挙げるCortex-A7の特徴は「電力効率に注力して設計されている」という点だ。「Cortex-A8がメインストリームだった頃と同じ性能のスマートフォンが,Cortex-A8に比べておよそ1/6程度の消費電力で実現できるだろう」(小林氏)というほど電力効率が高くなっている。
この電力効率の高さの理由の一つに,プロセスルールの違いがある。Cortex-A8は45nmプロセス向けだが,Cortex-A7は28nmプロセス向けで,プロセスの微細化の分だけ消費電力的にも,またフットプリント(プロセッサIPコアの面積)的にも有利になる。
 |
低消費電力,小さなフットプリントでありながら,上位版であるCortex-A15と完全な互換性を持っていることも特徴で,これが後述する”Big.LITTLE”戦略にとってきわめて重要な意味を持っている。
低消費電力を実現している理由の2つ目は,シンプルなパイプラインにある。「Cortex-A7はCortex-A5をベースに,消費電力を抑えながら,いくつかの拡張を加えたもの」(小林氏)で,シンプルなCortex-A5の特徴を多く引き継いでいる。
その一方で,Cortex-A5では1命令発行だったパイプラインが「限定的な2命令発行」に拡張されている。同時に,発行できる命令の組み合わせに制限があるので完全な2命令同時発行ではないが,この種の限定的な2命令同時発行は,回路規模を抑えつつ性能を上げるのに有利であり,たとえばx86系では初代Pentiumが似たような2命令同時発行で成功したプロセッサとして知られている。
 |
Cortex-A7は,スライドのような8ステージのパイプラインを採用するが,浮動小数点演算が統合されたことも,実は大きなトピックだ。もともとARMのVFP(Vector Floating Point)はSoCメーカーが取捨選択できるコプロセッサだったが,Cortex-A7ではCPU内部の演算パイプラインに統合されたものとして扱われているわけだ。
また,L2キャッシュが統合されたことも非常に大きな意味を持つ。Cortex-A5やCortex-A9ではSoCメーカーが必要に応じてL2C310と呼ばれるL2キャッシュコントローラを外付けするよう設計されているが「アプリケーションプロセッサは非常に高い周波数で動作するためL2キャッシュが不要というケースはほとんどない」(小林氏)のが実情だ。
そのため,Cortex-A7ではL2キャッシュ(最大4MB)が別モジュールではなく完全にコアに統合されている。その結果,「従来よりデータレイテンシが低くなっている。また,L2キャッシュのソフトウェアからの制御が,従来よりやりやすくなっているほか,電力性能も(L2C310に比べ)高くなっている」(小林氏)といった具合に大幅に改良されているのだ。
そのほかにも,TLBのエントリ数の増加,メモリレイテンシの低減など,従来のCortexファミリーから細かな改善が多数,図られており,高い電力性能と高パフォーマンスが実現されていると小林氏はCortex-A7の特徴をまとめていた。
L2キャッシュやメモリアクセス効率の低さは,とくにx86系と比べた場合,Cortex-Aファミリの欠点といわれた部分だが,そのあたりがCortex-A7では大きく改善されたと理解しておくといいだろう。
 |
big.LITTLEプロセッシングの核になるCortex-A7
というような特徴を持つCortex-A7だが,大方の想像通り,まずは2013年頃のローエンドのスマートフォン/タブレット製品が主要なターゲットとして想定されている。
 |
Cortex-A8よりもむしろ上の演算性能を持つというCortex-A7だけに,ローエンドの製品といっても現在のメインストリームの製品と同程度の性能を持つことが予想される。スライドのように販売助成金なしで75ドルといった非常に安価な製品が高い性能を持つことが実現されるというわけだ。
もう一つ,Cortex-A7が重要なのはbig.LITTLEプロセッシングにおける高効率プロセッサにCortex-A7が位置づけられている点である。
 |
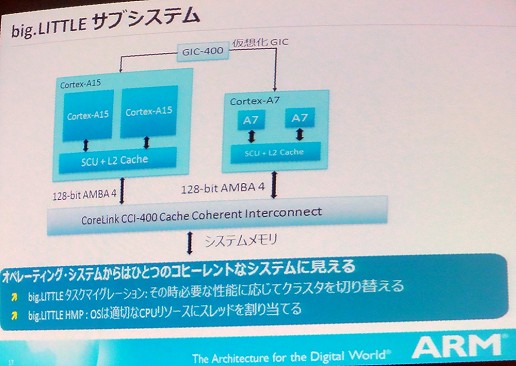
big.LITTLEプロセッシングは,NVIDIAが先に発表したTegra 3のvSMP(Variable Symmetric Multiprocessing)に似た発想の技術だ。講演では小林氏も軽くvSMPに触れていたが,vSMPでは同じCortex-A9を使ってプロセスレベルで4コアの高効率プロセッサと1コアの高性能プロセッサを組み合わせる方法をとっているのに対して,big.LITTLEではCortex-A15とCortex-A7という,内部アーキテクチャが異なるプロセッサを組み合わせている。先に述べたように,Cortex-A15とCortex-A7はソフトウェアレベルでは完全な互換性を持つので,同列の組み合わせが可能になるのだ。
もう一つ,vSMPとの大きな違いとして,高効率プロセッサと高性能プロセッサを切り替える方法が二種類が想定されているということが挙げられる。
vSMPでは,高効率プロセッサと高性能プロセッサの切り替えは完全にハードウェアに任されており,OSからは4コアとして見えると説明されている。そのためOS側での特別な対応は不要だ。
big.LITTLEでもvSMPと同じように,OSからは完全に隠蔽され,ハードウェアレベルで切り替える「タスクマイグレーション」という方法がサポートされている。タスクマイグレーションでは,拡張された割り込みコントローラ(GIC-400)によって,負荷に応じて,適宜,高効率プロセッサか高性能プロセッサのいずれかにタスクが割り当てられる。
さらにbig.LITTLEではもう一つ,big.LITTLE HMPと呼ばれるOSのスケジューラで割り当てる方法も検討されているという。OSのスケジューラが負荷やタスク優先度に応じて高効率プロセッサと高性能プロセッサを使い分けるというやり方だ。
この場合,OSのスケジューラにbig.LITTLE HMP対応のコードを追加する必要があるが,その代わりにOSが把握しているタスク優先度を反映できるというメリットも出てくる。
 |
どれが主流になるかはまだ分からないようだったが,OSサイドから言えば,big.LITTLE HMPが理にかなっているように思う。vSMPやタスクマイグレーションでは,優先度を無視して性能が低いプロセッサに重いタスクが割り当てられてしまう可能性があるからだ。
いずれにしても,Cortex-A7はARMにとって非常に重要な意味を持つプロセッサIPで,それだけに今回のARM Technical Symposia 2011でも,ロードマップと題してCortex-A7のセッションが設けられたのだろう。2013年のモバイルデバイスがどうなるのか,登場を楽しみに待ちたい。
- 関連タイトル:
 Cortex-A
Cortex-A
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー