












ニュース
NVIDIA,「CUDA 5.5」をリリース。CUDAでARMプラットフォームがフルサポートに
 |
そんなISC13に先立つ形で,NVIDIAは,アジア太平洋地域の報道関係者を対象に,ISC13で発表する予定となっているテーマの概要を解説した。今回は,Tesla部門のマーケティングマネージャーを務めるKim Roy氏が語ったその内容をお伝えしてみたい。
なお,この書き出しで分かるとおり,ゲームとの直接的な関係性は皆無だ。「GPU業界の動向」として読み進めてもらえればと思う。
CUDA 5.5でARMアーキテクチャをフルサポート
International Supercomputing Conference 2012(ISC12)は,第2世代Keplerである「GK110」を採用した数値演算アクセラレータ製品「Tesla K20」の概要を明らかにするという,NVIDIAにとっての大きなイベントになっていた(関連記事)。
 |
そんななか,ISC13における最も大きなトピックとなるのは,冒頭でも触れたCUDAのバージョンアップである。ISC13では,CUDA 5世代の最新版「CUDA 5.5」が登場し,ARMアーキテクチャをフルサポートすることになる。
 |
ホストCPUアーキテクチャに依存するマイナーな修正で対応できると推測されるため,CUDAをARM向けに提供することそれ自体がビッグニュースというわけではない。しかし,ARMアーキテクチャに対応したGPUコンピューティング向け開発環境の頒布を開始したことは,CUDA互換のGPUコアが集積される将来のTegraに向けた布石として,(NVIDIAとしては)大いに意味があるのだ。
Roy氏は,ARMアーキテクチャのCPUとNVIDIA製GPUを組み合わせること(以下,ARM+GPU)をSC12で発表したBarcelona Supercomputing Centerの例などを挙げながら,「ARMプラットフォームにも多数のCUDA採用アプリケーションが移植され,スーパーコンピュータ分野においてもARMアーキテクチャへの移行準備が整っている」と強調していた。氏によれば,x86アーキテクチャのプロセッサと比べても,ARMアーキテクチャのプロセッサとNVIDIA製GPUを組み合わせた環境は,消費電力あたりの性能だけでなく,絶対的な演算性能にも優れるという。
下のスライドは,右の枠内がARM+GPUに移植されたアプリケーション一覧を示している。左にある2つのグラフは,いずれも分子動力学シミュレーションを行うソフトウェア「HOOMD-Blue」「AMBER」のスコアとなっている。
HOMD-Blueはシミュレーション時間ステップあたりの電力性能(Time Steps per sec/Watt)が,AMBERにおいては1日でシミュレートできた分子数(Ns/day)が,それぞれSandyBridge-Eアーキテクチャを採用した「Xeon E5-2670」を2基搭載する16コアマシンを圧倒する……と,NVIDIAは言いたいわけだ。
ただし,消費電力あたりの性能比較で用いられているGPUは「GeForce GT 640」,純然たる性能比較で用いられているGPUは「GeForce GTX 680」と,組み合わされているGPUが両者で異なる点は注意してほしい。
 |
ISC13においては,あと2つ,発表が予定されている。
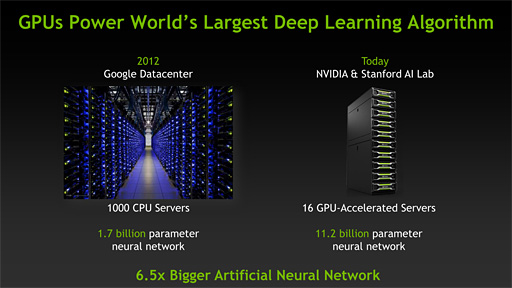
1つは,NVIDIAのGPUを用いて,世界最大のニューラルネットワークが構築されたというもの。NVIDIA製GPU搭載のサーバー16基で米スタンフォード大学のStanford Artificial Intelligence Laboratoryが構築したニューラルネットワークは,2012年にGoogleの研究部隊とされる「Google X Lab」が1000基のサーバーを用いて構築したニューラルネットワークと比べて6.5倍の規模になるという。
ちなみにニューラルネットワークとは,コンピュータ上で人間の脳の神経細胞ネットワークをシミュレートしようというもの。かつては実験レベルに留まっていたが,大規模なCPUクラスタを用いたニューラルネットワークでは画像認識や音声認識といった分野で価値ある具体的な成果を上げつつあり,実際にRoy氏も大規模なニューラルネットワークは自然音声認識のような分野を切り開く可能性があると話していた。
 |
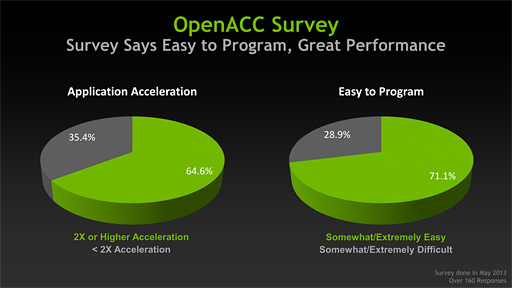
残る1つは「OpenACCの採用が指数関数的に伸びている」という,一種のアピールである。OpenACCは。NVIDIAがCUDAと並んで推しているGPU開発言語で,ホストCPUとGPUのコードを1つのソースコード内に混在させられるというものだ。
 |
似たようなアプローチはいくつかあり,大雑把に言えば,AMDが推すHSA(Heterogeneous System Architecture)もその1つと言える(※ただし,HSAに比べると,OpenACCはGPU寄りのアプローチで,抽象度が低い)。GPUコア「Mali」を擁するARMもHSAを推進する団体「HSA Foundation」に名を連ねていたりもするので,NVIDIAがCUDAのARMサポートと同時にOpenACCをアピールするあたりは少々興味深いところだ。
NVIDIAにとっては,x86プラットフォームで蓄積したアプリケーション資産こそがARMプラットフォームにおいても強みになる。したがって,ARMプラットフォームにおいても,CUDAやOpenACCといった,x86プラットフォームと変わらぬ開発環境があることをアピールする必要があるのだろう。
 |
 |
スーパーコンピュータの場合,ユーザーがソースコードでアプリケーションを管理していることも多く,その場合,ホストCPUは何でもいいということもある。そのため,コンシューマ向けデバイスと比べると,確かにARMアーキテクチャへ移行しやすいという話はあるかもしれない。
スーパーコンピュータ側の成果を原動力に,Tegraを広く普及させていきたいというのがNVIDIAの本音ではなかろうか。
- 関連タイトル:
 CUDA
CUDA
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー