








ニュース
NVIDIA,次世代のスーパーコンピュータ向けボード「Grace」を発表。次世代のGPUとArmアーキCPUを搭載する
 |
さて,2020年に引き続いてオンライン開催となった今回は,基調講演でNVIDIAのCEOであるJensen Huang(ジェンスン・フアン)氏が「Grace」と呼ばれるスーパーコンピュータ向けのCPUボードを発表したのが大きなトピックだ。2023年に提供開始予定ということもあり,Graceの正体は,まだ雲を掴むような所も多いのだが,その概要を簡単に紹介しておきたい。
次世代アーキテクチャのGPUとCPUを搭載したGrace
Graceは,CPUとGPUを搭載するボード製品だ。NVIDIAの説明をざっくりまとめると,次世代アーキテクチャのGPUとCPU,そして次世代のNVLinkを搭載する製品であるという。
 |
4Gamer読者の注目が集まるのは,当然ながら次世代アーキテクチャのGPUだろうが,現時点で詳細は明かせないそうで,性能はもちろん,アーキテクチャのコード名すら公表していない。ただ,「現行GPUであるAmpereアーキテクチャの次は,『Hopper』(ホッパー)と呼ばれるアーキテクチャになる」という話を聞いたことがある人もいるだろう。Hopperは,アメリカの計算機科学者にしてプログラミング言語「COBOL」の開発者として知られるGrace Hopper(グレース・ホッパー)氏の名から取られているという。
今回,発表されたボードの名前がGraceなので,Hopperアーキテクチャが登場するという話の信憑性が増したとは言えそうだ。ただ,HopperというGPU名はNVIDIAが公式に発表しているものではない。
さて,Graceで用いるCPUには,Armがサーバー向けに展開している「Neoverse」シリーズの次世代CPUコアが使われるそうだ。そのため,現時点ではCPUも詳細は発表されておらず,わずかに整数演算ベンチマーク「SPECrate2017_int_base」のスコアが300を超えるということが明らかとなっただけである。
なお,これらのCPUとGPUは,将来の高性能半導体向け5nmプロセス技術で製造するとのことだった。
NVIDIAがとくに強調しているのが,メモリとGPUやCPU間のデータ転送における帯域の広さだ。CPUとGPUの接続には,NVIDIA独自のインタフェース技術「NVLink」の次世代版を用いており,キャッシュメモリのデータを矛盾なく共有するコヒーレンシを保証する。さらに,CPUとGPU間の帯域幅は,現行の14倍となる900GB/sを超えるという。
また,CPUのメインメモリにはLPDDR5xメモリを採用しており,CPUとメモリとの帯域は500GB/sを超えるとのことだ。
NVIDIAによると,最近のAIモデルや,AIモデルが使用するパラメータは巨大化が急激に進んでおり,最も帯域幅が広いGPUのローカルメモリ(グラフィックスメモリ)だけでは処理しきれなくなっているという。しかし,容量が大きいCPU側のメインメモリにモデルやパラメータを配置した場合,メインメモリとGPU間の帯域幅が狭いため,そこが大きなボトルネックになってしまうとNVIDIAは指摘している。
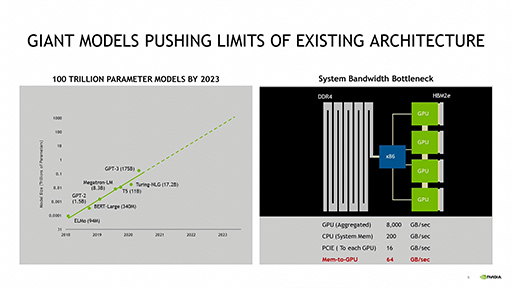 |
Graceは,このボトルネックを解消するアーキテクチャを採用しているそうだ。次のスライドはその概要を示したもので,GPUは広帯域なローカルメモリとして,合計最大8000GB/sのメモリバス帯域幅を有する「HBM2」(High-Bandwidth Memory 2)を備えるのと同時に,CPUやGPU,そしてLPDDR5xメモリがNVLinkで格子状に結ばれる。
 |
ひとつのCPU(図中のGRACE)とLPDDR5xメモリ間の帯域幅は500GB/sだが,GPUからは4つのメモリバンクをひとつの大きなメモリ空間として扱うことができるので,GPUとメインメモリ間は最大500GB×4=2000GB/sの帯域幅になるそうだ。現行のアーキテクチャに比べて実に31倍の帯域ということになる。
巨大なインタフェース帯域幅を実現するGraceは,「現在では1か月かかる大きなモデルの学習を,3日で終えるほどの性能を発揮する」とNVIDIAは予告している。
なおGraceは,スイス国立スーパーコンピュータセンター(Swiss National Supercomputer Center,CSCS)が2023年稼働開始の予定で構築中のスーパーコンピュータ「ALPS」が採用するそうだ。ALPSはAIの処理において,20 ExaFLOPSの処理性能を達成する計画というから驚きである。
 |
というわけで,Grace自体は4Gamer読者にとって縁遠いものだが,Graceの発表でいくつか予測はできるだろう。たとえば,次のNVIDIA製GPUアーキテクチャが2023年頃に登場する可能性があるということだ。ただ,噂レベルでは,次世代GPUのコード名としてAda Lovelace(エイダ・ラブレス)も取りざたされている。Graceに搭載されるGPUのコード名がHopperだと仮定すると,Lovelaceはどうなるのだろうか。
Graceが搭載するGPUは,HBM2とGPUを1パッケージに収めたマルチチップモジュール(Multi Chip Module,MCM)のようだ。MCMのGPUは,AMDが組み込み向けに投入していたが,コスト的な問題もありNVIDIAはスーパーコンピュータ向けに限定している。そう考えると,NVIDIAがコンシューマ向けとスーパーコンピュータ向けのアーキテクチャを分ける――かつてのVoltaアーキテクチャとPascalアーキテクチャのように――可能性もある。Graceで採用するGPUのアーキテクチャを将来のゲーマーが利用できるのかは,まだなんとも言えないというところだろうか。
- 関連タイトル:
 NVIDIA RTX,Quadro,Tesla
NVIDIA RTX,Quadro,Tesla
- この記事のURL:
Copyright(C)2010 NVIDIA Corporation
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー