









ニュース
Imagination,PowerVR Series6の実動デモを公開。MIPS買収後,次の一手は?
Imagination Technologies(以下,Imagination)は,2012年11月13日,都内にある英国大使館で報道関係者向けイベントを開催し,2012年の総括と,2013年に向けての製品戦略説明を行った。
本イベントにおける目玉は,Imaginationの主力製品である組み込み向けグラフィックスIPコアの新製品で,開発コードネーム「Rogue」(ローグ)と呼ばれていた「PowerVR Series6」と,先頃発表された,CPUメーカーMIPS Technologiesの買収の件だ。
PowerVRのグラフィックスIPコアは,AppleのiPhoneやiPad,IntelのAtomプロセッサでも採用されており,組み込み機器向けとしてはトップクラスのシェアを持っている。それだけに,PowerVR Series6は,今後の組み込み機器向けグラフィックスのベンチマーク的存在になるはずだが,今回は,従来,SoCベンダーをはじめとするライセンシーにしか明らかにされていなかった,その製品概要がついに明らかになったのだ。
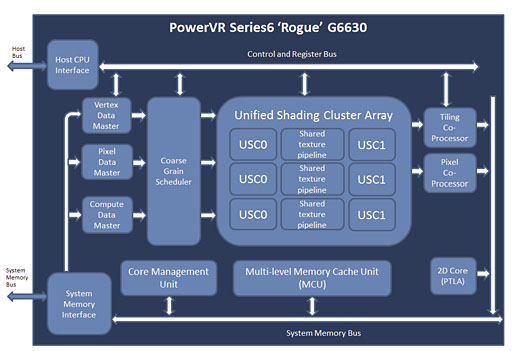
さっそく,ブロック図から見ていこう。下に示した図は,最上位モデル「G6630」のものになる。
PowerVRは統合型シェーダアーキテクチャを採用しており,実行ユニットは汎用シェーダユニットとして構成されている。グラフィックスレンダリングにおいて各汎用シェーダユニットは,頂点シェーダ,ジオメトリシェーダ,ピクセルシェーダとして適宜利用されるわけだ。OpenCLなどのGPGPU実行とグラフィックスレンダリングのタスクは,汎用シェーダユニットが“空いている”限り,同時実行が可能だとされている。
ブロック図を簡単に解説してみると,まず,「ポリゴンを構成する頂点データ」を取り揃えるのが「Vertex Data Master」,後段にある汎用シェーダユニット「Unified Shading Cluster Array」(以下,USCA)を管理したり発注したりするのが「Coarse Grain Scheduler」(以下,CGS)になる。
画面座標系に変換されたポリゴン達をタイルに割り付けて,実際のピクセルレンダリングに向けた各種準備を行うのが,ラスタライズ処理担当のコプロセッサ「Tiling Coprocessor」。そして,実際のピクセル描画に向けて関連データを用意するのが「Pixel Data Master」だ。
最終的な画像のピクセル処理は,USCA内の汎用シェーダユニット「Unified Shading Cluster」(以下,USC)をピクセルシェーダとして起用することで行われる。「Shared texture pipeline」はテクスチャユニットだ。
最後に,出力されたピクセル値を「Pixel Coprocessor」が取りまとめて書き出すことになる。
以上,大まかな流れは現行製品シリーズ「PowerVR Series5」から変わっていないが,PowerVR Series5で「Universal Scalable Shader Engine」(以下,USSE)と呼ばれていた部分が,PowerVR Series6ではUSCAと名を変え,実際,内部構成は大きく変更されているのがポイントだ。
右にクローズアップを示したとおり,USCAは最大6基のUSCからなる。
図には書かれていないのだが,USCには16基のALU(Arithmetic Logic Unit,演算装置)が搭載されている。USCのALUはスカラプロセッサと見られており,G6630全体では「16 ALU×6 USC」で96基のALUが搭載される計算だ。
演算精度に関する情報開示はなかったものの,常識的に考えて,各ALUは32bit単精度浮動小数点演算に対応するものと思われる。PowerVR Series6ではOpenCL 1.2への対応が公言されているので,2サイクル,もしくは2 ALU動作によって64bit倍精度浮動小数点演算に対応しているはずだ。
テクスチャユニットたるShared texture pipelineは,図中「USC0」「USC1」と書かれた2基のUSCで共有される設計になっている。単基のテクスチャユニットでは1クロックあたり4テクセルの処理が可能だという。PowerVR Series5で,テクスチャユニットはUSSE全体で1基しか用意されていなかったことを考えると,ここが最大3基となったのは,大きく強化された部分だと言える。
ちなみに,「汎用シェーダユニットを複数個ひとまとめにする」という構成は,近年のNVIDIA製GPUコアとよく似ている。NVIDIAはこのひとまとめを最新世代では「Streaming Multiprocessor Extreme」(SMX)と命名しているが,それのImagination版がUSCだと述べることもできるだろう。USCAがNVIDIA製GPUでいう「Graphics Processor Cluster」(GPC)のイメージだ。
なお,グラフィックスIPコアとしての製品構成は,最上位から順に,G6630,G6430,G6400,G6230,G6200となっている。
「G」の後ろに続く4桁数字は,頭の「6」がPowerVR Series6であることを示し,次がUSCの数を示している。その次は「フレームバッファ圧縮ロジックが搭載されているか」で,「3」があり,「0」がなしだそうだ。“1の位”の「0」が何かは説明されていない。
もちろん今後,これ以外のバリエーションモデルが登場してくる可能性はあるとのこと。Imaginationは「PowerVR Series6は,コンフィギュレーション(=コア数や動作クロック周波数)によって,100 GFLOPSから1 TFLOPSまでの性能を提供できる」としている。
1 TFLOPSの性能というと,2008年当時におけるNVIDIAのハイエンドGPU「GeForce GTX 280」相当。かなり高いレベルのグラフィックスレンダリングを実現でき,GPGPU用途にも十分なポテンシャルを持つということになる。
ところで,上で示したロードマップ図において,PowerVR Series6の5製品に,いずれも「DX10/ES 3.0」という括弧書きがあるのに気づいただろうか。これは対応するグラフィックスAPI世代の表記で,DX10はDirectX 10,ES 3.0はOpenGL ES 3.0のことを指している。
ここで問題になるのは,DirectX 10のほうだ,Harold氏は,2011年の来日時,PowerVR Series6がDirectX 11フル対応であると明言していた(関連記事)。これはいったいどういうことなのか。
会場で話を聞いたImaginationのMartin Ashton氏(Vice president Engineering, PowerVR IP, Imagination Technologies)はこの点について,「ハードウェア的にはDirectX 11のテッセレーションステージにまで対応しているが,リリース当初はDirectX 10のジオメトリシェーダまでの対応とした」と述べている。
その理由は「PowerVR Series6は当面の間,携帯機器や情報端末,カーナビゲーションシステムなどといった組み込み機器向けがメインとなる。つまり,テッセレーションステージを活用する場面がない」(Ashton氏)ためだそうだ。
そのためImaginationは,Windowsプラットフォーム向けのドライバがWHQL準拠のDirectX 10対応版のみになるとしている。将来的に,Windows 8やそれ以降のWindowsで採用が進めば,DirectX 11にフル対応したドライバが出てくることになるのだろう。
カンファレンス会場には,FPGA版PowerVR Series6を搭載したカードが差さったWindowsベースの開発プラットフォーム実機が展示され,実動デモを見ることができるようになっていた。撮影を許可されたため,公開されたデモを一通り,本稿でも紹介しておこう。
結論から言うと,基本的には「PowerVR Series6がOpenGL ES 3.0の全要素に対応している」ことをアピールするものとなっている。なお,OpenGL ES 3.0そのものについては,筆者が執筆した解説記事を参照してほしい。
なお,今回のデモにあたって,Imaginationから「コア自体がFPGAベースであり,あくまでもAPIなどの動作チェックなどを目的とした試作カードによるもの。そのため性能は,最終的に製品に組み込まれるコアの10分の1程度だと思ってもらいたい」と断りが入っているので,その点をあらかじめお伝えしておきたい。
シーン内で計362枚の枯れ葉が風に舞うデモ。枯れ葉1枚あたりのポリゴン数は約100程度だ。シーンには木枯らし(=小さな竜巻状の風)のフォースが存在しており,362枚の葉は,この風のフォースに影響されて舞うことになる。
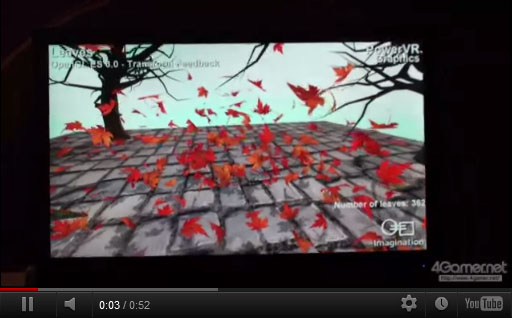
362枚ある葉の描画にあたってGPUには1枚分のジオメトリしか転送しておらず,362枚分のアニメーションパラメータのみを更新することで,すべての葉を描画しているのが本デモのポイントだ。
このような,「あらかじめ転送しておいた単一のジオメトリデータを,複数のパラメータに基づき複数個同時に描画する手法」は,OpenGL ES 3.0の新機能,Instanced Rendering(インスタンスト・レンダリング)によるものだ。同一形状のモデルを複数描画する局面に限ってではあるものの,ジオメトリ転送や描画コールを激減させられるので性能向上に“効く”とされている。
風の影響や地面への衝突判定など,物理シミュレーションによって更新された1枚1枚の葉のパラメータは,再度,レンダリングパイプラインの最初へと戻され,物理シミュレーション処理のために利用される。これは,頂点ステージの処理結果を頂点バッファオブジェクト(Vertex Buffer Object,VBO)に格納するOpenGL ES 3.0の新機能「Transform Feedback」(トランスフォームフィードバック)によって実現されているものだ。
OpenGL ES 3.0では,1回のレンダリングパスで最低でも四つのバッファに出力できるようにするマルチレンダーターゲット(Multi Render Target,以下 MRT)が標準仕様に組み入れられた。
下にムービーで示したデモは,MRTを用いた「Deferred Shading」(ディファードシェーディング)の実装例となっている。
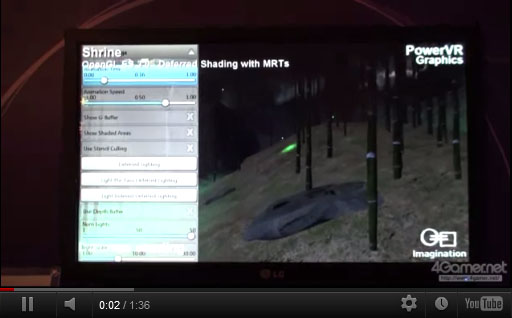
Deferred Shadingは,MRTを利用して,レンダリングに必要な中間パラメータ群を画面座標系で複数枚のバッファに出力し,このバッファの内容を参照しながらライティングやシェーディングを行うレンダリング技法だ。ライティングやシェーディングを遅らせて後段で行うから「Deferred」(遅らせた)という名称になっているわけである。
Deferred Shadingが持つ最大の利点は動的光源を無制限に置けることだ。ちなみに,今回のデモだと,シーン内で舞う無数の蛍が動的光源として扱われている。
デモの前半は下にサブウインドウが四つ見えるが,これらはMRTによって出力された中間パラメータのバッファ内容で,左から最終フレーム(シーンテクスチャ),法線情報,デプス(depth,深度)情報,アルベド(albedo,反射率)情報だ。つまり4 MRT(=4枚のMRT出力)が行われているということになる。
なお,映像では1分過ぎ以降の部分は,同じシーンでレンダリング技法を「Light Indexed Deferred Lighting」(ライトインデクスト・ディファードライティング)へ切り換えたデモになっている。
Light Indexed Deferred Lightingは,「Forward+」(フォワードプラス)とも呼ばれるレンダリング技法だ。以下Forward+と表記するが,本技法ではまず,画面を複数のタイルに分割し,「シーン内に配置されている無数の光源がどのタイルのライティングやシェーディングに関わるのか」を事前に探査して「光源リスト」化する。あとは,タイルごとにライティングやシェーディングするとき,「当該タイルに影響する光源があるかどうか」を,光源リストを参照しながら,普通にレンダリングするだけだ。
Forward+の利点は,MRTによる中間パラメータ生成を行うことなく,Deferred Shadingよろしく動的光源を無制限に配置できる点にある。また,Deferred Shadingが特殊なレンダリング手法であるがゆえ,適用が難しかったアンチエイリアシングも,本技法ならなんの問題もなく利用できる。
ちなみにこのForward+は,新世代のレンダリング技法として研究開発が進められているものだ。直近では,AMDがSouthern Islands世代のRadeon HD 7000シリーズ向けとして公開した「Leo」デモで採用して話題になった。

前段で紹介したDeferred Shadingデモと同じく,MRTの応用を見せるデモを撮影したものが下のムービーだ。

画面の左下には,MRTによって出力された二つのバッファが可視化されているが,左は通常のレンダリング結果,右は「ブルームエフェクト用のタネ」としてのイルミネーションレンダリング結果だ。
最終フレームは,通常レンダリング結果と,MRT出力されたイルミネーションレンダリングの結果をボカしたものとを合成することで生成する。MRT出力されたイルミネーションレンダリングの結果をボカすのは,発光物から光が溢れ出ている表現を行うためである。
なお,シーン内には1000を超えるビルが建ち並んでいるが,建物の種類自体は数種類で,Instanced Renderingによって描画されているという。
約300万ポリゴンで表現されたヴェネチア(ヴェニス)風の街をさまようデモ。それを撮影したものが下のムービーだ。。
PowerVR Series6は,最大で8x MSAAに対応しているのだが,直接的にはこの効果を見せるデモとなっている。PowerVR Series5ではアンチエイリアシングを有効化すると性能の低下が大きかったのに対し,PowerVR Series6ではその特性が劇的に改善されたとImaginationはアピールしている。
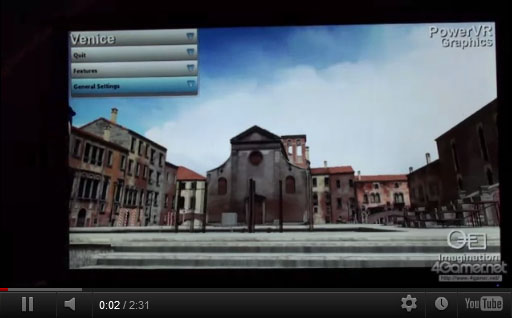
水面に,ジオメトリレベルで上下する波の効果が見られるが,これはディスプレースメントマッピング(Displacement Mapping)によるものと説明されている。
ただし,テッセレーションステージを活用しているものではなく,事前に分割しておいた水面に対して,変位量を記載したテクスチャで,各頂点を摂動させるものだ。そう,いわゆる頂点テクスチャフェッチング(Vertex Tecture Fetching)的なアプローチになっているのである。
下は,グレムリンの顔がアニメーションするデモだ。
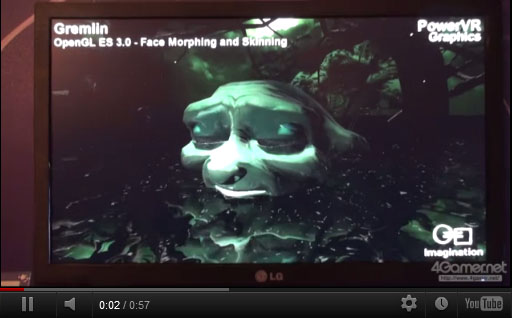
標準状態の表情から変化後の表情にモーフィングさせるとき,顔面の全頂点に対して頂点ブレンディングの処理を行っていたのではメモリバス帯域幅の消費が大きくなる。そこで,ある時点におけるアニメーション結果を前出のTransform Feedbackでレンダリングパイプラインの最初に戻し,「その表情状態から動く頂点」に対してだけ変移を更新するようにする。
Transform Feedback機能の応用としては,非常に直接的かつシンプルなデモといえるだろう。
会場では,Imaginationが開発を進めているレイトレーシングアクセラレータ「RTU」(Ray Tracing Unit)の試作カードを使ったデモも公開されていた。
今回もカード自体の撮影は禁止だったのだが,実物を手にとって見せてはもらえた。
ImaginationでRTUビジネスのディレクターを務めるAlex Kelley氏は,「仕様の詳細や価格などは12月に発表される」としつつ,現状の情報として,
ことを明らかにしている。
基本的には,「3ds Max」や「Maya」「Rhinoceros」といったDCCツールソフトウェアに,Imaginationが開発したビューポートプラグインを組み込んで使うことになるため,当面はプロフェッショナル用途向けの製品になるだろうとのことだ。
ブースで公開していたデモ映像の一部を撮影できたので,下に示そう。
この映像はリアルタイムレンダリングによるもので,登場する自動車は1台あたり約100万ポリゴン程度。後半に出てくる街並みのシーンだと全体で400万ポリゴン程度だそうだ。
今回のデモでは大局照明(Global Illumination,グローバルイルミネーション)処理を2バウンス(≒反射)に制限し,1920×1080ドットの全画面表示だと3〜5fpsといったところか。ムービー前半に出てくるMaya上のプレビューサイズだと30fps前後は出ていた。
PC/IT系メディアの報道で知っている人も少なくないと思われるが,英国時間2012年11月6日,Imaginationは,近代におけるRISC型CPUの先駆者であり,最近は組み込み機器向けCPUメーカーとして活躍していたMIPS Technologies(以下,MIPS)を買収したと発表した(※)。買収額は6000万ドル(約48億円)。このニュースは組み込み機器の世界だと,比較的大きな業界動向として受け止められている。
冒頭でも紹介したとおり,今回のプレスカンファレンスでは,このMIPS買収についての説明も行われた。
MIPSはゲーム業界とも無縁ではない。たとえばソニーは初代PlayStationとPlayStation 2で,任天堂はニンテンドー64でそれぞれMIPSコアベースのCPUを採用していた。
現在,組み込み機器向けではARMのCPU IPコアが大きなシェアを獲得しているので,組み込み用CPUというとARMアーキテクチャを連想する人が多いと思うが,実のところAndroid OSをネイティブに動作させられるCPUアーキテクチャはMIPSとARM,x86の三つ。そう,MIPSは,Android OSにおいてARMやx86と並ぶCPUコアアーキテクチャなのである。
Imaginationは,今回の買収によってMIPSアーキテクチャの関連特許を広範に取得。1990年代にMIPSコアは64bit化への対応を終えているが,これをさらに独自拡張したCPUアーキテクチャの設計ができるようになる。
現在,競合のARMは,ARMアーキテクチャのCPU IPコアと,ARM系グラフィックスIPコアの「Mali」をセットにした,いわば“オールARM”的なプラットフォームのSoCソリューションを強力に訴求してきている。今回のMIPS買収は,組み込みの世界におけるグラフィックスIPコアの巨人が取った対抗手段だと見るのが妥当だろう。
ちなみにImaginationはすでに,独自アーキテクチャのCPU「Meta」を持っているのだが,これは高度なモダンOSを動かすというよりは,周辺I/Oとの仲介制御処理を主体とした,マイクロコントローラ的な性格が強いプロセッサだ。
モダンな64bitアーキテクチャのCPU獲得は,Imaginationに,これまで手を出しづらかった分野への進出の機会を与えるはずだ。また,PowerVRにMIPS系CPUコアをセットにした“オールImagination”プラットフォームを訴求できるようになる。
この動きと合わせて注目しておきたいのは,Imaginationが,AMDが立ち上げた異種混合コンピューティングプラットフォーム「HSA」(Heterogeneous System Architecture)への参画を発表済みということだ。
HSAは,「CPU管理下のメモリ空間とGPU管理下のメモリ空間を論理的に共有・一体化させたアーキテクチャを採用し,一つのプログラムコードを,単一のアドレッシングで,CPUとGPUに対して透過的に実行を仕掛けられる」という思想を採用している。これにはCPUとGPUの双方における高い設計力がなければ実現が難しい。
CPU技術を持たないNVIDIAが,ARMからCPUのライセンスを受けて,「Project Denver」としてCPUとGPUの融合を図ろうとしていることを知っている読者は多いだろうが,Imaginationは,HSAに自前の技術で取り組むことができるようになったわけである。
今回のMIPS買収は,対ARMの重要戦略であり,同時に次世代の異種混合コンピューティングへの対応を目指すためのものなのだ。
昨年のレイトレーシングプロセッサたるRTUと,そのRTUの将来的なPowerVRへの統合計画,そして今年の老舗MIPS買収。Imaginationは,「PowerVRのImagination」から,あるいは「組み込み向けソリューションベンダー」といったスタンスからさえ,大きく飛躍しようとしているのかもしれない。
本イベントにおける目玉は,Imaginationの主力製品である組み込み向けグラフィックスIPコアの新製品で,開発コードネーム「Rogue」(ローグ)と呼ばれていた「PowerVR Series6」と,先頃発表された,CPUメーカーMIPS Technologiesの買収の件だ。
 Imaginationの製品戦略全体について語ったDavid Harold氏(Director of PR, Imagination Technologies) |
 各プロセッサの技術解説を行ったTony King-Smith氏(Vice President Marketing Technology Division, Imagination Technologies) |
アーキテクチャを刷新したPowerVR Series6
 |
さっそく,ブロック図から見ていこう。下に示した図は,最上位モデル「G6630」のものになる。
 |
 |
ブロック図を簡単に解説してみると,まず,「ポリゴンを構成する頂点データ」を取り揃えるのが「Vertex Data Master」,後段にある汎用シェーダユニット「Unified Shading Cluster Array」(以下,USCA)を管理したり発注したりするのが「Coarse Grain Scheduler」(以下,CGS)になる。
画面座標系に変換されたポリゴン達をタイルに割り付けて,実際のピクセルレンダリングに向けた各種準備を行うのが,ラスタライズ処理担当のコプロセッサ「Tiling Coprocessor」。そして,実際のピクセル描画に向けて関連データを用意するのが「Pixel Data Master」だ。
最終的な画像のピクセル処理は,USCA内の汎用シェーダユニット「Unified Shading Cluster」(以下,USC)をピクセルシェーダとして起用することで行われる。「Shared texture pipeline」はテクスチャユニットだ。
最後に,出力されたピクセル値を「Pixel Coprocessor」が取りまとめて書き出すことになる。
以上,大まかな流れは現行製品シリーズ「PowerVR Series5」から変わっていないが,PowerVR Series5で「Universal Scalable Shader Engine」(以下,USSE)と呼ばれていた部分が,PowerVR Series6ではUSCAと名を変え,実際,内部構成は大きく変更されているのがポイントだ。
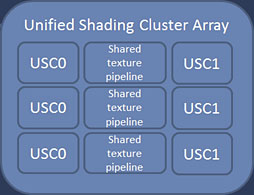 |
図には書かれていないのだが,USCには16基のALU(Arithmetic Logic Unit,演算装置)が搭載されている。USCのALUはスカラプロセッサと見られており,G6630全体では「16 ALU×6 USC」で96基のALUが搭載される計算だ。
演算精度に関する情報開示はなかったものの,常識的に考えて,各ALUは32bit単精度浮動小数点演算に対応するものと思われる。PowerVR Series6ではOpenCL 1.2への対応が公言されているので,2サイクル,もしくは2 ALU動作によって64bit倍精度浮動小数点演算に対応しているはずだ。
テクスチャユニットたるShared texture pipelineは,図中「USC0」「USC1」と書かれた2基のUSCで共有される設計になっている。単基のテクスチャユニットでは1クロックあたり4テクセルの処理が可能だという。PowerVR Series5で,テクスチャユニットはUSSE全体で1基しか用意されていなかったことを考えると,ここが最大3基となったのは,大きく強化された部分だと言える。
ちなみに,「汎用シェーダユニットを複数個ひとまとめにする」という構成は,近年のNVIDIA製GPUコアとよく似ている。NVIDIAはこのひとまとめを最新世代では「Streaming Multiprocessor Extreme」(SMX)と命名しているが,それのImagination版がUSCだと述べることもできるだろう。USCAがNVIDIA製GPUでいう「Graphics Processor Cluster」(GPC)のイメージだ。
なお,グラフィックスIPコアとしての製品構成は,最上位から順に,G6630,G6430,G6400,G6230,G6200となっている。
 |
「G」の後ろに続く4桁数字は,頭の「6」がPowerVR Series6であることを示し,次がUSCの数を示している。その次は「フレームバッファ圧縮ロジックが搭載されているか」で,「3」があり,「0」がなしだそうだ。“1の位”の「0」が何かは説明されていない。
もちろん今後,これ以外のバリエーションモデルが登場してくる可能性はあるとのこと。Imaginationは「PowerVR Series6は,コンフィギュレーション(=コア数や動作クロック周波数)によって,100 GFLOPSから1 TFLOPSまでの性能を提供できる」としている。
1 TFLOPSの性能というと,2008年当時におけるNVIDIAのハイエンドGPU「GeForce GTX 280」相当。かなり高いレベルのグラフィックスレンダリングを実現でき,GPGPU用途にも十分なポテンシャルを持つということになる。
PowerVR Series6は
DirectX 10&OpenGL ES 3.0対応
ところで,上で示したロードマップ図において,PowerVR Series6の5製品に,いずれも「DX10/ES 3.0」という括弧書きがあるのに気づいただろうか。これは対応するグラフィックスAPI世代の表記で,DX10はDirectX 10,ES 3.0はOpenGL ES 3.0のことを指している。
ここで問題になるのは,DirectX 10のほうだ,Harold氏は,2011年の来日時,PowerVR Series6がDirectX 11フル対応であると明言していた(関連記事)。これはいったいどういうことなのか。
会場で話を聞いたImaginationのMartin Ashton氏(Vice president Engineering, PowerVR IP, Imagination Technologies)はこの点について,「ハードウェア的にはDirectX 11のテッセレーションステージにまで対応しているが,リリース当初はDirectX 10のジオメトリシェーダまでの対応とした」と述べている。
その理由は「PowerVR Series6は当面の間,携帯機器や情報端末,カーナビゲーションシステムなどといった組み込み機器向けがメインとなる。つまり,テッセレーションステージを活用する場面がない」(Ashton氏)ためだそうだ。
そのためImaginationは,Windowsプラットフォーム向けのドライバがWHQL準拠のDirectX 10対応版のみになるとしている。将来的に,Windows 8やそれ以降のWindowsで採用が進めば,DirectX 11にフル対応したドライバが出てくることになるのだろう。
PowerVR Series6の実動デモが公開される
 |
結論から言うと,基本的には「PowerVR Series6がOpenGL ES 3.0の全要素に対応している」ことをアピールするものとなっている。なお,OpenGL ES 3.0そのものについては,筆者が執筆した解説記事を参照してほしい。
なお,今回のデモにあたって,Imaginationから「コア自体がFPGAベースであり,あくまでもAPIなどの動作チェックなどを目的とした試作カードによるもの。そのため性能は,最終的に製品に組み込まれるコアの10分の1程度だと思ってもらいたい」と断りが入っているので,その点をあらかじめお伝えしておきたい。
 |
●Instanced Rendering&Transform Feedback
シーン内で計362枚の枯れ葉が風に舞うデモ。枯れ葉1枚あたりのポリゴン数は約100程度だ。シーンには木枯らし(=小さな竜巻状の風)のフォースが存在しており,362枚の葉は,この風のフォースに影響されて舞うことになる。
362枚ある葉の描画にあたってGPUには1枚分のジオメトリしか転送しておらず,362枚分のアニメーションパラメータのみを更新することで,すべての葉を描画しているのが本デモのポイントだ。
このような,「あらかじめ転送しておいた単一のジオメトリデータを,複数のパラメータに基づき複数個同時に描画する手法」は,OpenGL ES 3.0の新機能,Instanced Rendering(インスタンスト・レンダリング)によるものだ。同一形状のモデルを複数描画する局面に限ってではあるものの,ジオメトリ転送や描画コールを激減させられるので性能向上に“効く”とされている。
風の影響や地面への衝突判定など,物理シミュレーションによって更新された1枚1枚の葉のパラメータは,再度,レンダリングパイプラインの最初へと戻され,物理シミュレーション処理のために利用される。これは,頂点ステージの処理結果を頂点バッファオブジェクト(Vertex Buffer Object,VBO)に格納するOpenGL ES 3.0の新機能「Transform Feedback」(トランスフォームフィードバック)によって実現されているものだ。
●Deferred Shading with MRTs
OpenGL ES 3.0では,1回のレンダリングパスで最低でも四つのバッファに出力できるようにするマルチレンダーターゲット(Multi Render Target,以下 MRT)が標準仕様に組み入れられた。
下にムービーで示したデモは,MRTを用いた「Deferred Shading」(ディファードシェーディング)の実装例となっている。
Deferred Shadingは,MRTを利用して,レンダリングに必要な中間パラメータ群を画面座標系で複数枚のバッファに出力し,このバッファの内容を参照しながらライティングやシェーディングを行うレンダリング技法だ。ライティングやシェーディングを遅らせて後段で行うから「Deferred」(遅らせた)という名称になっているわけである。
Deferred Shadingが持つ最大の利点は動的光源を無制限に置けることだ。ちなみに,今回のデモだと,シーン内で舞う無数の蛍が動的光源として扱われている。
デモの前半は下にサブウインドウが四つ見えるが,これらはMRTによって出力された中間パラメータのバッファ内容で,左から最終フレーム(シーンテクスチャ),法線情報,デプス(depth,深度)情報,アルベド(albedo,反射率)情報だ。つまり4 MRT(=4枚のMRT出力)が行われているということになる。
なお,映像では1分過ぎ以降の部分は,同じシーンでレンダリング技法を「Light Indexed Deferred Lighting」(ライトインデクスト・ディファードライティング)へ切り換えたデモになっている。
Light Indexed Deferred Lightingは,「Forward+」(フォワードプラス)とも呼ばれるレンダリング技法だ。以下Forward+と表記するが,本技法ではまず,画面を複数のタイルに分割し,「シーン内に配置されている無数の光源がどのタイルのライティングやシェーディングに関わるのか」を事前に探査して「光源リスト」化する。あとは,タイルごとにライティングやシェーディングするとき,「当該タイルに影響する光源があるかどうか」を,光源リストを参照しながら,普通にレンダリングするだけだ。
Forward+の利点は,MRTによる中間パラメータ生成を行うことなく,Deferred Shadingよろしく動的光源を無制限に配置できる点にある。また,Deferred Shadingが特殊なレンダリング手法であるがゆえ,適用が難しかったアンチエイリアシングも,本技法ならなんの問題もなく利用できる。
ちなみにこのForward+は,新世代のレンダリング技法として研究開発が進められているものだ。直近では,AMDがSouthern Islands世代のRadeon HD 7000シリーズ向けとして公開した「Leo」デモで採用して話題になった。
●Instanced Rendering and MRT
前段で紹介したDeferred Shadingデモと同じく,MRTの応用を見せるデモを撮影したものが下のムービーだ。
画面の左下には,MRTによって出力された二つのバッファが可視化されているが,左は通常のレンダリング結果,右は「ブルームエフェクト用のタネ」としてのイルミネーションレンダリング結果だ。
最終フレームは,通常レンダリング結果と,MRT出力されたイルミネーションレンダリングの結果をボカしたものとを合成することで生成する。MRT出力されたイルミネーションレンダリングの結果をボカすのは,発光物から光が溢れ出ている表現を行うためである。
なお,シーン内には1000を超えるビルが建ち並んでいるが,建物の種類自体は数種類で,Instanced Renderingによって描画されているという。
●8x MSAA,Displacement Mapping
約300万ポリゴンで表現されたヴェネチア(ヴェニス)風の街をさまようデモ。それを撮影したものが下のムービーだ。。
PowerVR Series6は,最大で8x MSAAに対応しているのだが,直接的にはこの効果を見せるデモとなっている。PowerVR Series5ではアンチエイリアシングを有効化すると性能の低下が大きかったのに対し,PowerVR Series6ではその特性が劇的に改善されたとImaginationはアピールしている。
水面に,ジオメトリレベルで上下する波の効果が見られるが,これはディスプレースメントマッピング(Displacement Mapping)によるものと説明されている。
ただし,テッセレーションステージを活用しているものではなく,事前に分割しておいた水面に対して,変位量を記載したテクスチャで,各頂点を摂動させるものだ。そう,いわゆる頂点テクスチャフェッチング(Vertex Tecture Fetching)的なアプローチになっているのである。
●Face Morphing and Skinning
下は,グレムリンの顔がアニメーションするデモだ。
標準状態の表情から変化後の表情にモーフィングさせるとき,顔面の全頂点に対して頂点ブレンディングの処理を行っていたのではメモリバス帯域幅の消費が大きくなる。そこで,ある時点におけるアニメーション結果を前出のTransform Feedbackでレンダリングパイプラインの最初に戻し,「その表情状態から動く頂点」に対してだけ変移を更新するようにする。
Transform Feedback機能の応用としては,非常に直接的かつシンプルなデモといえるだろう。
レイトレーシングアクセラレータカード
「RTU」のデモも公開される
 |
今回もカード自体の撮影は禁止だったのだが,実物を手にとって見せてはもらえた。
ImaginationでRTUビジネスのディレクターを務めるAlex Kelley氏は,「仕様の詳細や価格などは12月に発表される」としつつ,現状の情報として,
- 1枚のカードに2基のRTUを搭載している
- 総容量16GBのメモリをカード上に搭載している
- 表示用には別途グラフィックスカードが必要になる
ことを明らかにしている。
基本的には,「3ds Max」や「Maya」「Rhinoceros」といったDCCツールソフトウェアに,Imaginationが開発したビューポートプラグインを組み込んで使うことになるため,当面はプロフェッショナル用途向けの製品になるだろうとのことだ。
ブースで公開していたデモ映像の一部を撮影できたので,下に示そう。
この映像はリアルタイムレンダリングによるもので,登場する自動車は1台あたり約100万ポリゴン程度。後半に出てくる街並みのシーンだと全体で400万ポリゴン程度だそうだ。
今回のデモでは大局照明(Global Illumination,グローバルイルミネーション)処理を2バウンス(≒反射)に制限し,1920×1080ドットの全画面表示だと3〜5fpsといったところか。ムービー前半に出てくるMaya上のプレビューサイズだと30fps前後は出ていた。
ImaginationがMIPSを買収
CPUコアを手に入れた同社の次なる一手は?
PC/IT系メディアの報道で知っている人も少なくないと思われるが,英国時間2012年11月6日,Imaginationは,近代におけるRISC型CPUの先駆者であり,最近は組み込み機器向けCPUメーカーとして活躍していたMIPS Technologies(以下,MIPS)を買収したと発表した(※)。買収額は6000万ドル(約48億円)。このニュースは組み込み機器の世界だと,比較的大きな業界動向として受け止められている。
冒頭でも紹介したとおり,今回のプレスカンファレンスでは,このMIPS買収についての説明も行われた。
 |
現在,組み込み機器向けではARMのCPU IPコアが大きなシェアを獲得しているので,組み込み用CPUというとARMアーキテクチャを連想する人が多いと思うが,実のところAndroid OSをネイティブに動作させられるCPUアーキテクチャはMIPSとARM,x86の三つ。そう,MIPSは,Android OSにおいてARMやx86と並ぶCPUコアアーキテクチャなのである。
Imaginationは,今回の買収によってMIPSアーキテクチャの関連特許を広範に取得。1990年代にMIPSコアは64bit化への対応を終えているが,これをさらに独自拡張したCPUアーキテクチャの設計ができるようになる。
現在,競合のARMは,ARMアーキテクチャのCPU IPコアと,ARM系グラフィックスIPコアの「Mali」をセットにした,いわば“オールARM”的なプラットフォームのSoCソリューションを強力に訴求してきている。今回のMIPS買収は,組み込みの世界におけるグラフィックスIPコアの巨人が取った対抗手段だと見るのが妥当だろう。
ちなみにImaginationはすでに,独自アーキテクチャのCPU「Meta」を持っているのだが,これは高度なモダンOSを動かすというよりは,周辺I/Oとの仲介制御処理を主体とした,マイクロコントローラ的な性格が強いプロセッサだ。
モダンな64bitアーキテクチャのCPU獲得は,Imaginationに,これまで手を出しづらかった分野への進出の機会を与えるはずだ。また,PowerVRにMIPS系CPUコアをセットにした“オールImagination”プラットフォームを訴求できるようになる。
 |
HSAは,「CPU管理下のメモリ空間とGPU管理下のメモリ空間を論理的に共有・一体化させたアーキテクチャを採用し,一つのプログラムコードを,単一のアドレッシングで,CPUとGPUに対して透過的に実行を仕掛けられる」という思想を採用している。これにはCPUとGPUの双方における高い設計力がなければ実現が難しい。
CPU技術を持たないNVIDIAが,ARMからCPUのライセンスを受けて,「Project Denver」としてCPUとGPUの融合を図ろうとしていることを知っている読者は多いだろうが,Imaginationは,HSAに自前の技術で取り組むことができるようになったわけである。
今回のMIPS買収は,対ARMの重要戦略であり,同時に次世代の異種混合コンピューティングへの対応を目指すためのものなのだ。
昨年のレイトレーシングプロセッサたるRTUと,そのRTUの将来的なPowerVRへの統合計画,そして今年の老舗MIPS買収。Imaginationは,「PowerVRのImagination」から,あるいは「組み込み向けソリューションベンダー」といったスタンスからさえ,大きく飛躍しようとしているのかもしれない。
- 関連タイトル:
 PowerVR
PowerVR - この記事のURL:
(C)2011 Imagination Technologies Ltd. All rights reserved
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー