









テストレポート
ゲーム性能が大幅に向上したRyzen Desktop 2000シリーズは,内部で何が変わったのか
2018年4月19日,「Pinnacle Ridge」(ピナクルリッジ)という開発コードネームで知られていたRyzen Desktop 2000シリーズが登場した。4Gamerのレビューでお伝えしているとおり,新世代Ryzenは,マルチコアのメリットを発揮できる局面で高い性能を示し,同時に第1世代Ryzenでの懸案だったゲーム性能では競合を捉えている。
国内発売から1か月ほど経ち,価格もこなれつつあるため,ボーナス商戦期に向けてRyzen Desktop 2000シリーズの存在が気になっている読者も少なくないだろう。
そこで今回は,Ryzen Desktop 2000というCPUについての理解をより深めてもらうべく,実アプリケーションの性能評価から少し離れ,Ryzen Desktop 2000というCPUの特性を,前後編に分けて見てみたいと考えている。
前編となる今回は,第1世代に対して第2世代のRyzenで相対的に何が変わったのかという部分をチェックしていく。
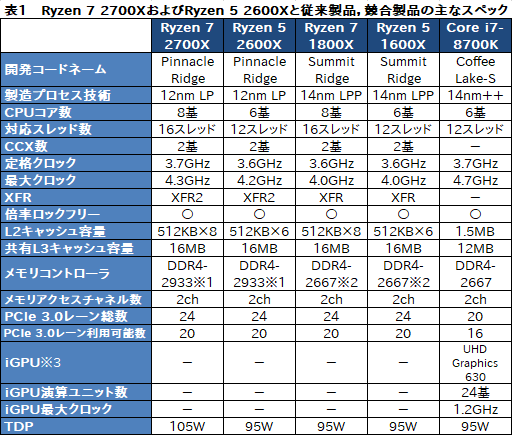
テストに先立って,Ryzen Desktop 2000シリーズの製品概要を振り返っておこう。
4月19日掲載の記事でもお伝えしているとおり,Ryzen Desktop 2000シリーズのマイクロアーキテクチャは第1世代Ryzenと同じだ。とはいえ,プロセッサとしてまったく同じというわけでもない。
最大の違いは,第1世代RyzenがGLOBALFOUNDRIESの14nm LPP(Low-Power Plus)プロセス技術を用いて製造されているのに対し,第2世代Ryzenの製造にあたってAMDは同じGLOBALFOUNDRIESの12nm LP(Leading Performance)プロセスを新たに採用している点にある。AMDによれば,12nm LPプロセス技術は「同じ電圧ならより高い動作クロック」「同じ動作クロックならより低い動作電圧」を実現できるという。第2世代Ryzenはもちろん,12nm LPの特性を「より高い動作クロック」のほうに振った製品だ。
表1に示すとおり,発表時点のシリーズ最上位モデルである8コア16スレッド対応モデル「Ryzen 7 2700X」は,置き換え対象となる「Ryzen 7 1800X」に対してブースト最大クロックが300MHz高くなっている。同様に6コア12スレッド対応モデル「Ryzen 5 2600X」も,置き換え対象となる「Ryzen 5 1600X」に対して200MHz高い。
動作クロック関連では,自動クロックアップ機能「Precision Boost」が第2世代の「Precision Boost 2」に一新となったのも大きな違いだ。
Ryzen Desktop 1000シリーズの採用していたPrecision Boostは,最大クロックに達するのが2スレッドまで,つまり最大2コアに負荷がかかっているときまでに固定されていた。一方,Precision Boost 2では負荷がかかっているコア数に依存せず,さらにコア温度とコア電圧,電流を監視して,状況に応じたクロックで動作するとされる。たとえば4コアに負荷がかかっている状況でもコア温度やコア電圧,電流の状況次第では最大クロックで動作可能だ。
なので,Precision Boostに比べPrecision Boost 2のほうが高い動作クロックを保てると考えられ,その分だけ第1世代より高い性能が期待できるというわけである。
なおRyzenの場合,製品型番に「X」が付くCPUでは,コア温度が許す限り最大クロックを超えて動作クロックを引き上げる「Extended Frequency Range」(以下,XFR)に対応するが,Ryzen Desktop 2000シリーズではここも第2世代の「XFR2」となっている。ただAMDはXFR2について「XFRよりも高いクロックで動作しやすい」と述べているだけなので,第1世代XFRと比べてどの程度の違いがあるかはよく分からない。
さらに,スペックを見るだけでは分からない部分として,キャッシュやメモリのアクセス遅延を低減することで,クロックあたりの性能(IPC,Instructions Per Clock)を3%向上させたとAMDが主張しているのも,改良点として紹介できるだろう。
たとえばRyzen 7 2700Xの場合,ブースト最大クロックはRyzen 7 1800Xに対して約7.5%高い計算になる。それでIPCが3%向上となると,単純かつ乱暴なかけ算で約11%高い性能が得られるわけだ。また同じ計算式に当てはめると,Ryzen 5 2600XはRyzen 5 1600X比で約8%高い性能を得られることになる。
以上を踏まえるに,第2世代Ryzenの特性を探るうえで何よりも優先して調べなければならないのは,AMDが主張しているとおりに第1世代Ryzenに対してキャッシュやメモリのアクセス遅延の低減を果たし,同時に3%のIPC向上が得られているかどうかと,Precision Boost 2やXFR2の挙動ということになる。
このうち本稿では,3%のIPC向上と,キャッシュやメインメモリのアクセス遅延を実現できているかをメインに,検証を進めていきたい。
そんな今回のテストで用いるのは,FinalWare製のシステムチェック&ベンチマークツール「AIDA64」(Engineer Edition,Version 5.97.4618 Beta)およびSiSoft製のシステムチェック&ベンチマークツール「Sandra 2017 SP4」(Engineer,Version 2017.12.24.61)といった基礎的なベンチマークアプリケーションだ。
使用した機材は初回レビュー時と完全に同じだが,テストしている時期が異なるためBIOSおよびドライバのバージョンは新しくなっている。具体的には表2のとおりとなる。
今回のテーマはあくまでも新旧Ryzenの違いを探ることだが,念のためIntel製CPUとの違いも見ておこうということで,レビュー記事でも用いた「Core i7-8700K」(以下,i7-8700K)をあらためて比較対象として用意している。
Ryzen 7 2700XとRyzen 5 2600Xのメモリアクセス設定は,AMDがレビュワーに推奨しているDDR4-3400(16-16-16-36)と,Single-Rank(シングルランク)のモジュール2枚に対するデュアルチャネルアクセス時定格となるDDR4-2933(16-16-16-36)の2パターンを用意した。Ryzen 7 1800XとRyzen 5 1600XではSingle-Rank(シングルランク)のモジュール2枚に対するデュアルチャネルアクセス時定格となるDDR4-2667(16-16-16-36),i7-8700Kでも定格のDDR4-2667(16-16-16-36)としている。
なお,今回はプラットフォーム間で冷却条件を揃えるため,すべてのCPU,すべてのテストでサイズ製のサイドフローCPUクーラー「MUGEN5 Rev.B」(以下,MUGEN5)を使用している。AMDの主張によれば,XFR2は冷却条件次第でクロックがかなり変わることになるので,基礎的なテストでは冷却条件を揃えることが結構重要になると思われる。
以下,グラフ中に限りRyzen 7は「R7」,Ryzen 5は「R5」と表記するので,その点はあらかじめお断りしておきたい。
まずはAIDA64からだ。
グラフ1〜3は,AIDA64のテストから,主に整数演算主体のベンチマーク結果となる4項目を抜き出したものだ。グラフを3つに分けているのは純粋に見やすさを確保するためで,他意はない。以後も見やすさ重視でグラフは複数に分けることがあるため,その点はご注意を。
グラフ1の「CPU Queen」は,古典的なNクイーン問題(N-Queens Problem,n×nの碁盤目状となるボードに縦横斜めに移動できるチェスのクイーンをn個置くとして,互いに攻撃できないよう配置するパターンがいくつあるか)を解くテストで,AVXおよびAVX2の整数演算を用いたものになる。
ここでトップスコアを示したのはRyzen 7 2700Xだが,DDR4-3400設定とDDR4-2933設定でほとんどスコア差は生じていない。Ryzen 7 1800X比では約8%高いスコアだが,理論的には約11%のスコア向上が得られるはずなので,ここでは期待にやや届いていないわけである。
一方,Ryzen 5 2600Xは,同じ6コア12スレッド対応で動作クロックも高いi7-8700Kを上回るスコアを叩き出した。やはりメモリ設定によるスコア差はほぼなく,Ryzen 5 1600Xに対してDDR4-3400設定で約11%,DDR4-2933設定で約12%高いスコアを示して期待値を上回っている。
メモリクロックがスコアにさほど影響を及ぼさないのはRyzen 7 2700X,Ryzen 5 2600Xで共通の傾向となっているため,偶然ではないだろう。Nクイーン問題はマス目の数を増やすほど使用するメモリ領域が増大するが,リニアなメモリアクセスは生じないので,アルゴリズム的にメモリクロックがあまり効かないということはあり得ると思う。
「CPU AES」はAES-NI(Advanced Encryption Standard - New Instructions)命令を用いて暗号化を行うテストだが,ここではRyzenがi7-8700Kを圧倒している。これはAMDとIntelで暗号化やハッシュのハードウェアアクセラレーションの実装が異なることに起因するのだろう。
AES-NIはAESの処理の一部を固定ハードウェアで行うので,固定ハードウェア部分が異なることでスループットも大きく変わると考えられるためだ。
Ryzen同士の比較だと,Ryzen 7 2700XはRyzen 7 1800Xに対して約10%,Ryzen 5 2600XはRyzen 5 1600Xに対して10〜11%程度高いスコアを示した。ハードウェアアクセラレーションを使用するだけに,メモリクロックの高いほうが有利になりそうなものだが,そうなっていないのは謎だ。Precision Boost 2の挙動がスコアに影響を与えているのかもしれない。
グラフ2の「CPU PhotoWorxx」は,整数演算を使って写真の加工処理を行うテストで,AVX(Advanced Vector eXtensionsと)やAVX2,SSE(Streaming SIMD Extensions)といったSIMD(Single Instruction, Multiple Data)演算を使うものになっている。
ここで頭1つ抜け出したのはRyzen 7 2700XのDDR4-3400設定だった。Ryzen 7 1800Xに対して約13%高いスコアだ。ただ,そんなRyzen 7 2700XもDDR4-2933設定時のスコアはRyzen 7 1800Xとほとんど同程度に留まってしまった。ここにはスコアのブレがあるわけだ。
「CPU Hash」はデータのハッシュ値を求めるテストで,SHA(Secure Hash Algorithm)を用いるとされるが,得られたスコア傾向はCPU AESと同じだった。
Ryzen 7 2700XのスコアはRyzen 7 1800Xに対して約7%,Ryzen 5 2600XはRyzen 5 1600Xに対して8〜9%程度高い。
続いてグラフ3は古典的なx86命令のみを使ってデータの圧縮および展開を行うテスト「CPU Zlib」の結果だが,かなり極端な数字が出ている。
というのも,Ryzen 7 2700XのDDR4-2933設定時がRyzen 7 1800X比で約88%と沈んでいるのだ。DDR4-3400設定では逆に約9%高いので,メモリアクセス設定によるギャップはかなり大きいと言える。
一方のRyzen 5 2600XはDDR4-3400設定およびDDR4-2933設定で前世代比約10%増と,うってかわって順当にスコアを伸ばした。ただし,メモリクロックの違いはスコアにほとんど影響を及ぼしていない。メモリクロックの違いが顕れたり顕れなかったりするのはやはりPrecision Boost 2の挙動によるものかもしれない。
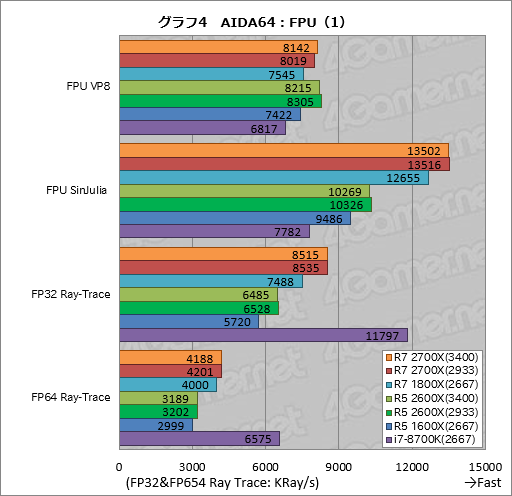
AIDA64から,浮動小数点演算を使うテスト6項目のスコアをまとめたものがグラフ4,5である。
グラフ4から見ていこう。
「FPU VP8」はVP8形式のエンコードを実行するテストで,Ryzen 7 2700XはRyzen 7 1800Xに対し,DDR4-3400設定で約8%,DDR4-2933設で約6%高いスコアを示した。期待値には届いていないものの,メモリクロック設定に対しては素直な反応を見せている印象だ。
一方のRyzen 5 2600Xだと,Ryzen 5 1600Xに対しDDR4-3400設定で約11%,DDR4-2933設定で約12%高いスコアなので,逆転現象が生じている。これもおそらくは動作クロックの挙動がもたらしているのだろう。
ちなみにここでi7-8700Kは最下位に沈んでおり,Ryzen 5 1600X比で約92%となっている。
続く「FPU SinJulia」は古典的なx87命令セットでIEEE標準の80bit精度浮動小数点演算を行い,ジュリア集合(Julia set,複素平面上である条件を満たす点の集合)を計算するテストである。
Ryzen 7 2700XのスコアはRyzen 7 1800Xに対してDDR4-3400設定,DDR4-2933設定ともに約7%高いという結果なので,メモリクロックはほとんどスコアを左右していないことが見てとれる。
ただ,Ryzen 5 2600Xの場合,Ryzen 7 1600Xに対するスコアはDDR4-3400設定時に約8%,DDR4-2933設定時に約9%高いレベルと,若干のスコア差が生じた。スコア向上の幅も8コア16スレッド対応モデルより大きい。
i7-8700Kは最下位という結果だが,x87はレガシーな命令セットなので,Intelもその性能をあまり重視していないのだろう。
次の「FP32 Ray-Trace」は32bit単精度浮動小数点演算を使ってレイトレーシングを実行するベンチマークで,AVX系のSIMD演算やFMA(Fused Multiply-Add)命令を使用するものとなっている。
ここで目を惹くのは,i7-8700Kが他を大きく引き離してトップを取っているところだ。浮動小数点数のSIMD演算やFMA命令セットの性能はIntelが優勢ということなのだろう。
Ryzen 7 2700XのスコアはRyzen 7 1800Xに対してDDR4-3400設定,DDR4-2933設定のいずれにおいても約14%高く,Ryzen 5 2600XのスコアはRyzen 5 1600Xに対してDDR4-3400設定で約13%,DDR4-2933設定で約14%それぞれ高いと,若干の違いがある。
メモリクロックに応じたスコアにはなっていないものの,スコアの向上幅は期待にほぼ沿った結果と言っていいだろう。
「FP64 Ray-Trace」は64bit倍精度浮動小数点演算を用いてレイトレーシングを行うテストだ。ここでもi7-8700KはRyzenを圧倒しており,浮動小数点数のSIMD演算やFMA命令セットを前にしたときの優位性を示している。
Ryzen 7 2700XのスコアはRyzen 7 1800Xに対してDDR4-3400設定,DDR4-2933設定とも約5%高い。Ryzen 5 2600XはRyzen 5 1600XよりDDR4-3400設定で約6%,DDR4-2933設定で約7%高いが,いずれもメモリクロックはほぼスコアを左右せず,スコアの伸びも期待値に届いていない。
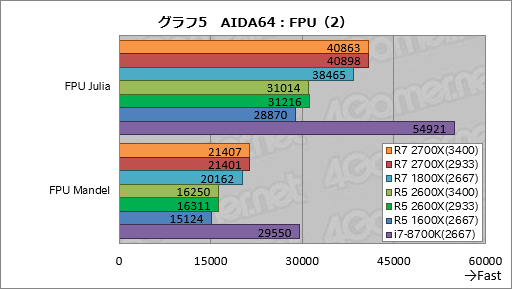
浮動小数点演算テストの残る2項目はグラフ5に結果をまとめたとおりとなる。
「FPU Julia」は32bit単精度演算を使ってジュリア集合を計算するテストだ。浮動小数点数のSIMD演算やFMA命令が使われるため,このテストでもi7-8700Kがトップを取っている。
Ryzen勢のスコア傾向はFPU SinJuliaに近い。Ryzen 7 2700XはRyzen 7 1800Xに対してDDR4-3400設定,DDR4-2933設定とも約6%高いスコアとなった。Ryzen 5 2600XはRyzen 5 1600Xに対してDDR4-3400設定で約7%,DDR4-2933設定で約8%高いスコアだ。
64bit倍精度浮動小数点演算でマンデルブロ集合(Mandelbrot set,ジュリア集合と同様に複素平面上である条件を満たす点の集合)を実行するテストとなる「FPU Mandel」も,SIMD命令やFMA命令を使うため,トップを取ったのはi7-8700Kだった。
Ryzen 7 2700XのスコアはRyzen 7 1800Xに対してメモリアクセス設定を問わず約6%高い。Ryzen 5 2600XはRyzen 5 1600Xに対してDDR4-3400設定で約7%,DDR4-2933設定で約8%高いという結果になっている。
ここまでAIDA64の整数や浮動小数点演算の結果を見てきたが,ざっくりと言えることは,
といったあたりだろう。
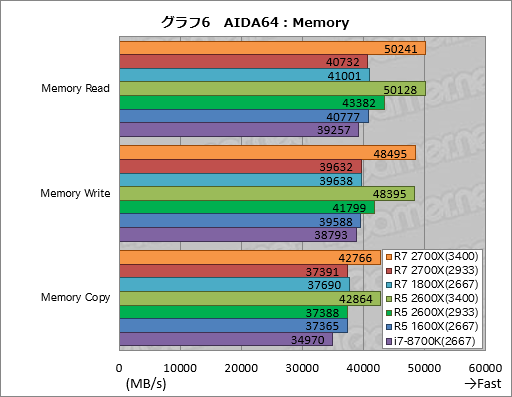
続いてはAIDA64でメモリ周りのテスト結果を見ていきたい。グラフ6はメモリバス帯域幅を調べる3テスト「Memory Read」「Memory Write」「Memory Copy」の結果をまとめたものだ。
一見して分かるのは,Ryzen 7 2700XとRyzen 5 2600XのDDR4-3400設定が比較対象に比べて好成績を収めていること。Memory Read,Memory WriteともにDDR4-2667設定の第1世代Ryzenと比べて約22%程度高いスコアを記録している。
Memory Copyだとメモリのアクセス遅延が読み出しと書き込みの双方で生じ,アクセス遅延の比重が大きくなることからスコア差は縮まるが、それでもRyzen 7 2700XはRyzen 7 1800Xに対して約14%,Ryzen 5 2600XはRyzen 5 1600Xに対して約15%高いスコアを示した。
その一方で,Ryzen Desktop 2000シリーズのDDR4-2933設定時におけるスコアは冴えない。Ryzen 5 2600XはRyzen 5 1600Xに対してMemory ReadとMemory Writeで約5%高いスコアを示して体裁は保っているものの,Memory Copyでは違いなし。Ryzen 7 2700Xに至っては3項目すべて大差のないスコアに留まってしまった。
CrystalDiskMarkにおいてDDR4-2933設定のほうがDDR4-3400設定より高いスコアを出すことが見られた以上,このスコアは解せないとしか言いようがないわけだが,ひょっとすると「DDR4-2933設定のほうがPrecision Boost 2によるコアクロックが高くなる」のかもしれない。Precision Boost 2についてはあらためて調べる予定なので,この疑問はひとまず置いておくことにする。
ちなみにメモリバス帯域幅のテストで最下位なのはi7-8700Kだった。Ryzenは第1世代からメモリバス帯域幅のテストには強かったので,この結果も妥当ではあるだろう。
グラフ7はメモリアクセス遅延を見る「Memory Latency」の結果だが,ここで最も優秀な結果を残したのはi7-8700Kだった。Intelは「Fast Memory Access(FMA)」という「DRAMのアクセス遅延を抑える技術」をCore 2 Duo時代に実装してから地道に改良し続けているので,一日の長があるということだろう。
この点でAMDはまだIntelに及ばないわけで,逆に言えば今後の最適化の余地が大きい部分と言うことができるはずだ。
ただ,それ以上に注目したいのは,第2世代Ryzenで第1世代Ryzenと比べて有意にメモリアクセス遅延が低減していることだ。Ryzen 7 1800Xと比べて,Ryzen 7 2700XのDDR4-3400設定では約18ns,DDR4-2933設定でも約7ns短い。Ryzen 5 1600Xに対するRyzen 5 2600Xも,DDR4-3400設定で約17ns,DDR4-2933設定で約11nsも短くなっている。
もっとも厳しいことを言えば,メモリクロックが高いので,第1世代Ryzenと比べてメモリアクセス遅延が短くなるのは当たり前でもある。
というのも,ここまでのテストではメモリアクセスタイミングの設定を揃えてるので,メモリクロックが高いほど遅延が低下するからだ。つまり,第2世代Ryzenでアクセス遅延が低下したかどうかについては,ここまでのテストだけでは断言できないということになる。
以上,AIDA64の結果を見てきたが,第2世代Ryzenにおける謎としては,まずDDR4-3400設定よりもDDR4-2933設定のほうがスコアが高くなる傾向が見られたことが挙げられるだろう。
その原因としてはここまで何度か触れたとおりPrecision Boost 2が考えられる。また,Precision Boost 2を有効化している限り,メモリやキャッシュのアクセス遅延の改善やIPCの向上を読み取ることは難しい。
そこで,Precision Boost 2(およびPrecision Boost)を無効化のうえ,CPUのクロック倍率を32倍,つまり動作クロックを3.2GHzに固定し,さらにメモリアクセス設定もDDR4-2667で揃えて,新旧Ryzenの4製品を比較してみることにしよう。なお,ここではあくまでもRyzen同士の比較を行いたいので,i7-8700Kのテストは省略する。
というわけでグラフ8〜10は整数演算ベンチマークのスコアをまとめたものだが,ここで第2世代Ryzenは第1世代に対してCPU PhotoWorxxとCPU Zlibで1〜2%程度高いスコアを示している。
また,Ryzen 5 2600XではCPU AESでもRyzen 5 1600Xに対して約1%高いスコアを示した。AMDが主張する3%には届かず,またすべてのテストで同様な結果が出たわけではないが,クロックを揃えた状態の比較なので,有意な違いはあると見ていいだろう。
浮動小数点演算ベンチマークの結果はグラフ11,12である。FPU VP8でRyzen 5 2600XはRyzen 5 1600Xに対して約3%というスコアの向上を見せている。一方のRyzen 7 2700Xだと約1%だが,やはり比較対象のRyzen 7 1800Xに対して高いスコアを示した。
エンコード処理ではメモリアクセスが大きな比重を占めるため,第2世代Ryzenにおけるメモリアクセス遅延の改善が効いた可能性はある。
面白いのはFP32 Ray-Traceで,ここでRyzen 7 2700XとRyzen 5 2600Xはいずれも置き換え対象の第1世代Ryzenに対して約5%高いスコアを示している。「改善点はメモリやキャッシュのアクセス遅延の低減のみ」と考えるに,FP32 Ray-Traceはそれが効きやすいテストということなのだろう。
CPUクロックとメモリクロックを揃えた整数および浮動小数点演算の結果を見る限り,一部のテストでは確かに第1世代に対し第2世代でスコアが上がることが分かる。上昇の幅は一律3%というわけではないものの,テストによっては5%程度も伸びる場合もあるので,平均してみるとAMDの主張する3%というのは,妥当なところかもしれない。
もともとマイクロアーキテクチャは変わっておらず,メモリ周りのみの性能向上なので,全般的なスコア向上が得られるわけではないというのは,ある意味で理にかなっている。
では,そのメモリ周りはどうなのか。Memory ReadとMemory Write,Memory Copyの結果をまとめたものがグラフ13となるが,メモリクロックとタイミングが揃っていることもあり,3つのテストで概ね横並びとなった。
メモリアクセス遅延を見る「Memory Latency」の結果は非常に興味深いものとなった。グラフ14で示したとおり,Ryzen 7 2700XはRyzen 7 1800Xに対して約5.5ns,Ryzen 5 2600XはRyzen 5 1600Xに対して約6.4ns,それぞれアクセス遅延が小さいのだ。
動作クロックやメモリクロック,メモリアクセスタイミングを揃えた状態で有意に低い遅延を記録した以上,AMDが主張するとおり,第2世代Ryzenでキャッシュやメモリ周りに改良は間違いなく入っていると言っていいだろう。
以上のテストから,第2世代Ryzenでメモリ周りに何らかの改良が入ったことは確かと断言できそうだ。それにより,第1世代のRyzenに対し第2世代では一部のベンチマークで1〜5%程度のスコアアップが確認できたと言っていのではないかと思う。
続いては,Sandra 2017 SP4を実行した結果を見ていくことにしたい。
5月にリリースされた「Sandra 2018」はRyzen正式対応が謳われているのだが,今回のテストには間に合わなかった点はお断りしておきたい。
まずはPrecision Boost 2やPrecision Boost,Intelの「Turbo Boost Technology 2.0」を有効化した通常利用状態での結果を見ていこう。設定はAIDA64の動作クロックを固定しないテストに準じている。
グラフ15はCPUの演算性能を見る「Processor Arithmetic」の総合スコア「Aggregate Native Performance」をまとめたものだ。
トップを取ったのはRyzen 7 2700Xで,2番手がRyzen 5 2600X,3番手がi7-8700Kという順位になった。
Ryzen 7 2700X,Ryzen 5 2600Xとも,スコアはメモリアクセス設定による違いはほぼなく,Ryzen 7 2700XはRyzen 7 1800Xに対して約5%,Ryzen 5 2600XはRyzen 5 1600Xに対して約8%高いスコアを示している。Ryzen 5 2600Xのほうはほぼ期待値どおりのスコアが出ているわけである。
次にグラフ16はProcessor Arithmeticの個別スコアをまとめたものになる。個別スコアでもRyzen 7 2700Xがトップで,その後にRyzen 5 2600X,i7-8700Kという順位になる点は揺るがない。
Ryzen 7 2700XはRyzen 7 1800Xに対してDDR4-3400設定,DDR4-2933設定のいずれでも3〜6%程度高いスコアを示しているが,DDR4-3400設定で最もスコア差の縮まった「Whetstone Single-float Native AVX/FMA」(※古典的な浮動小数点演算ベンチマークWhetstoneをAVX&FMAを使って行うテスト)でDDR4-2933設定は最もスコア差を広げていたりと,バラつきに一貫性がない。なのでPrecision Boost 2の挙動がスコアに影響を与えていると思われる。
なお,Ryzen 5 2600XはRyzen 5 1600Xに対して5〜9%程度高いスコアを示した。スコアのバラつきに一貫性がないのはこちらも同様だ。
マルチメディア処理性能を見る「Processor Multi-Media」の総合スコアにあたる「Aggregate Multi-Media Native Performance」をまとめたものがグラフ17となる。
ここで圧倒的なトップを取ったのはi7-8700Kだ。Processor Multi-MediaではAVX2やFMAが多用されるため,その種の命令におけるRyzen系との性能差がでた結果だろう。
2018年5月30日19:30頃追記:初出時,i7-7800KがAVX512をサポートすると記載していましたが,サポートしていませんでした。お詫びして訂正いたします。
Ryzen 7 2700XのスコアはRyzen 7 1800X比でDDR4-3400設定において約7%,DDR4-2933設定において約6%高い。期待値には届いていないものの,DDR4-3400設定におけるスコアのほうが伸びていることも含め,まずまずだ。
一方のRyzen 5 2600XはRyzen 5 1600Xに対してメモリアクセス設定を問わず約8%高いスコアとなった。メモリアクセス設定による違いはないものの,期待値はクリアした格好である。
グラフ18,19は「Processor Multi-Media」の個別スコアをまとめている。i7-8700Kがどうしても突出してしまうが,Ryzen同士で比較すると,マルチメディア処理をx86命令で行う「Multi-Media Quad-int Native x1 ALU」で第2世代と第1世代の間にスコア差がほとんど生じていないという,特徴的な結果が出ている。Multi-Media Quad-int Native x1 ALUは古典的なx86命令を使うテストなので,動作クロックの違いがスコアを左右しそうなものだが……。
それ以外のテストはおおむね総合スコアを踏襲する傾向が出ていると言っていいだろう。
CPUを用いた暗号化の性能を調べる「Processor Cryptographic」の結果から,総合スコア「Cryptographic Bandwidth」を見たものがグラフ20である。端的にまとめると,AIDA64の暗号化テストと同様に,Ryzenが競合に対して強さを見せている。
メモリバス帯域幅の違いがはっきりと出ているのも特徴だろう。Ryzen 7 2700XはRyzen 7 1800Xに対し,DDR4-3400設定で約8%,DDR4-2933設定で約1%高いスコアと,かなりの違いが出ている。Ryzen 5 2600XとRyzen 5 1600X間も順に約12%,約6%だ。
Processor Cryptographicの個別スコアはグラフ21のとおり。ハードウェアアクセラレーションを使用する「Encryption/Decryption Bandwidth AES256-ECB AES」だとDDR4-3400設定でRyzen 7 1800Xに対して約11%高いスコアを示すのに対し,ハードウェアアクセラレーションを利用しない「Hashing Bandwidth SHA2-256 AVX512, AVX2」だと約5%に留まり,またDDR4-2933設定との違いもほぼなくなるという対照的な結果となった。
科学技術計算を行う「Processor Scientific」の総合スコア「Aggregate Scientific Performance」をまとめたものがグラフ22となる。
このテストではFMA命令セットを多用するため,FMAの性能がいまひとつなRyzenは分が悪く,i7-8700Kがトップを取った。
Ryzen同士の比較だと,Ryzen 7 2700XはDDR4-3400設定で約10%,DDR4-2933設定で約4%,それぞれRyzen 7 1800Xより高いスコアを示し,Ryzen 5 2600XのほうもRyzen 5 1600Xに対して順に約15%,約10%高いスコアを示した。いずれもメモリアクセス設定の違いが素直に数字として出ている。
そんなProcessor Scientificの個別スコアがグラフう23,24である。
全般にi7-8700Kのスコアが高めだが,それはさておきRyzen系のスコアに注目すると,行列演算を行う「General Matrix Multiply (GEMM) FMA」と高速フーリエ変換を行う「Fast Fourier Transform (FFT) FMA」の2つにおいて,第2世代RyzenはDDR4-3400設定時にDDR4-2933設定時と比べて良好なスコアが出ている。これは双方ともメモリアクセス性能が“効く”タイプの処理だからだ。
とくにGeneral Matrix Multiply (GEMM) FMAでは,Ryzen 7 2700XのDDR4-3400設定でRyzen 7 1800Xに対して約14%,Ryzen 5 2600XのDDR4-3400設定でなんと約22%ものスコア差が生じており,インパクトが大きい。
Fast Fourier Transform (FFT) FMAだとそれほどの違いは出ていないわけだが,これはGeneral Matrix Multiply (GEMM) FMAが短時間で終わるテストのため,Precision Boost 2の効果が強く現れた結果だろうと筆者は見ている。
続いてはAVXやFMAを用いて2D画像を処理するときの性能を見る「Processor Image Processing」だ。グラフ25は総合スコアに当たる「Aggregate Image Processing Rate」をまとめたものとなる。
ここでもトップはi7-8700Kだが,Processor Image ProcessingではすべてのテストでAVXとFMA命令を利用するので,その性能がスコアを左右する。AIDA64でも見てきたようにi7-8700KはAVXの浮動小数点演算やFMAの性能に優れるため,その傾向がここでも出ているわけだ。
Ryzen同士で比較すると,Ryzen 7 2700X,Ryzen 5 2600Xともに,メモリアクセス設定がスコアを左右していない。前者はRyzen 7 1800Xに対して約6%,後者はRyzen 5 1600Xに対して約8%高いスコアとなっている。
そんなProcessor Image Processingの個別スコアを並べたのがグラフ26〜28だが,おおむねすべてのテストで総合スコアと大差ない傾向を示している。例外は画像の誤差拡散を行う「Diffusion: Randomise (256) Filter x8 AVX2/FMA」で,グラフ26を見ると,ここだけはメモリアクセス設定の違いがスコアを大きく左右している。
具体的には,Ryzen 7 2700XはRyzen 7 1800Xに対してDDR4-3400設定で約10%,DDR4-2933設定で約4%,Ryzen 5 2600XはRyzen 5 1600Xに対して順に約10%,約8%高いスコアを示した。このテストは誤差拡散法のフィルタが比較的シンプルなアルゴリズムとなっているため,メモリアクセス性能の違いがスコアとして素直に出やすいのだろう。
CPUコア間のデータ転送の帯域幅を調べる「Processor Multi-Core Efficiency」の結果がグラフ29となる。
これはなかなか興味深い結果となっており,第2世代Ryzenでは「4x 4kB Blocks」〜「16x 64kB Blocks」の間で帯域幅が第1世代Ryzenと比べて高い。具体的なスコアはグラフ画像をクリックすることで確認できるようにしてあるが,Ryzen 7 2700XはRyzen 7 1800Xに対して10〜21%程度,Ryzen 5 2600XはRyzen 5 1600Xに対して13〜26%程度も高いスコアなのだから,「メモリクロックやCPUの動作クロックが上がっただけ」では説明できないだろう。何らかの改良が入ったことを窺わせるデータだ。
メモリバス帯域幅を見る「Memory Bandwidth」の総合スコアがグラフ30だが,AIDA64と同様,このテストではRyzenがi7-8700Kを上回る結果を残した。
もっとも,そのRyzenもなかなか不思議なスコアを残している。Ryzen 7 2700XのDDR4-3400設定がRyzen 7 1800Xに対して約20%も高いスコアを叩き出す一方,DDR4-2933設定だと約98%に沈んでいるのだ。Ryzen 5 2600Xはそこまで極端でないものの,やはりDDR4-3400設定でRyzen 5 1600Xに対して約19%高いスコアを示すのに対し,DDR4-2933設定だとギャップは約4%にまで縮んでいる。
グラフ31はそんなMemory Bandwidthの個別スコアだが,ものの見事に総合スコアを踏襲する結果となった。
キャッシュおよびメモリの遅延を計測する「Cache & Memory Latency」の結果がグラフ32となる。
スコアが重なっているのでちょっと分かりにくいが,全体として第2世代Ryzenでメモリアクセス遅延は第1世代Ryzenと比べて低減を果たしている。たとえばL2キャッシュの範囲内となる64kB Range〜256kB Rangeの範囲だと,スコアには1.4nsの違いがある。
その中で興味深いのはRyzen 7 2700XのDDR4-2933設定で,スコアが安定感を欠き,4MB RangeではRyzen 7 1800Xに対して遅延状況が悪化してしまっている。4MB RangeはL3キャッシュの範囲であり,CPUのコアクロックやメモリクロックが向上していることから遅延は低下していいはずだ。そうなっていないのは,おそらくPrecision Boost 2およびPrecision Boostの挙動が関係しているのだろう。
メインメモリの範囲となる16MB Range以上のサイズでも第2世代Ryzenはメモリアクセス遅延を順当に低減している。「Ryzen 7とRyzen 5はL3キャッシュ容量16MBだから,16MB Rangeはキャッシュ内では?」と思うかもしれないが,デスクトップPC向けRyzenでは4基のCPUと容量8MBのL3キャッシュを「CPU Complex」(公式略称「CCX」,以下略称表記)とし,それを専用インタフェース「Infinity Fabric」経由で最大2基束ねている。しかも「Zen」マイクロアーキテクチャではL1とL2,L3キャッシュそれぞれに重複してはデータを保持しないという排他的なキャッシュ制御法を採用しているため,16MB Blocksはメインメモリのアクセス遅延が支配的になるのだ。
もっとも,見て分かるとおりこのレンジではi7-8700Kが非常に優秀で,現在のところRyzenでは歯が立たない。
グラフ33はキャッシュ周りの帯域幅を見る「Cache Bandwidth」のテスト結果となる。第2世代Ryzenのスコアは第1世代Ryzenに対して16MB Data Set以内で順当に上がっているが,CPUおよびメモリクロックの設定が異なるので,このスコア向上が動作クロックによるものなのか改良の結果なのかは,これだけだと判断できない。
メインメモリ領域にかかる64MB Data Set以上の帯域幅はなかなか微妙で,「Ryzen 7 2700XのDDR4-2933設定はRyzen 7 1800X(のDDR4-2667設定)に及ばない」格好になっている。DDR4-3400設定では順当にi7-8700Kを上回る成績を残しているので,この結果はよく分からないというのが正直なところだ。
以上,通常利用状態におけるSandra 2017 SP4の結果を見てきたが,AIDA64と同様,Ryzen Desktop 2000シリーズではメモリクロックの結果がスコアに反映されづらい傾向があるようだ。
スコア向上の期待値と見比べると,Ryzen 7 2700Xのほうは届かない傾向にあるものの,Ryzen 5 2600Xは前世代からの上げ幅が大きく,期待値にかなり近い成績を残すことも分かる。このあたりはAIDA64と共通している印象を受けた。
といったところで,AIDA64と同じようにCPUコアクロックを3.2GHz,メモリアクセス設定をDDR4-2667に固定した結果も見ていきたい。
まずグラフ34,35はProcessor Arithmeticの結果である。Ryzen 7 2700XとRyzen 7 1800X,Ryzen 5 2600XとRyzen 5 1600Xのスコア差はほぼないどころか,全体として第1世代Ryzenのほうがスコアは若干ながら上なので,少なくとも3%というIPCの向上は,ここでは確認できない。
グラフ36〜38はProcessor Multi-Mediaのスコアだ。ここでも総合スコアは第2世代Ryzenと第1世代Ryzenとの間で基本的に大差ない。
ただそれだけに目立つのは,グラフ38のMulti-Media Long-int Native x64 AVX512/DQW, AVX2でRyzen 7 2700XがRyzen 7 1800Xの約94%,Ryzen 5 2600XがRyzen 5 1600Xの約95%にまでスコアを落としていることだ。同じようにスコアが落ちているので偶然ではないだろうが,なら原因は何かと言われてもはっきりしない。古典的なx86命令では第2世代Ryzenにおける改良がむしろ足を引っ張る場合があるのかもしれない。
Processor Cryptographicのスコアがグラフ39,40だ。Ryzen 5 2600XがEncryption/Decryption Bandwidth AES256-ECB AESでRyzen 5 1600Xに対して約2%高いスコアを示し,結果として総合スコアでも1%高いスコアを示しているが,Ryzen 7 2700XのほうはRyzen 7 1800Xと横並びである。
グラフ41〜43はProcessor Scientificの結果だが,ここで興味深いのはGeneral Matrix Multiply (GEMM) FMAのスコアで,Ryzen 7 2700XはRyzen 7 1800Xに対して約3%,Ryzen 5 2600XにいたってはRyzen 5 1600Xに対してなんと約13%も高い。
後者のスコア差はクロックを揃えているだけに異常で,Ryzen 7 1600Xのテスト時に何らかのトラブルがあった可能性を否定できないが,テストをやり直しても結果は誤差程度にしか変わらず。したがって,Ryzen 5 2600XとRyzen 7 1600Xの大きなスコア差は計測ミスではないようだ。General Matrix Multiply (GEMM) FMAはサイズが比較的小さいテストになるので,キャッシュのアクセス遅延の改善などが大きく結果に影響を与えたのかもしれない。同じ理由で,Ryzen 7 2700XがRyzen 7 1800Xに対して高いスコアを示しているのも偶然ではないはずだ。
Processor Image Processingの結果はグラフ44〜47のとおりだ。
Ryzen 7 2700XはRyzen 7 1800Xに対し,グラフ45のDiffusion: Randomise (256) Filter x8 AVX2/FMAで約2%,メディアンフィルタによる画像のノイズ低減を行う「Noise Reduction: Median (5x5) Filter x8 AVX2/FMA」で約1%高いスコアを示しているが,Ryzen 5 2600XとRyzen 5 1600Xで同様の傾向は出ていないので,おそらくブレの範囲だろう。
それ以外のスコアはほぼ揃っている。
ここまでの結果からすると「3%というIPCの向上は確認できない」という結論になるが,グラフ48のProcessor Multi-Core Efficiencyは,非常に興味深い結果となっている。
Ryzen 7 2700XとRyzen 5 2600Xはともに,4x 4kB Blocksから4x 64kB Blocksにかけて帯域幅が大きく拡大している。動作クロックやメモリクロックが揃い,結果としてInfinity Fabricのクロックも揃った状態で,Ryzen 7 2700XはRyzen 7 1800Xに対して,Ryzen 5 2600XもRyzen 5 1600Xに対してそれぞれ5〜13%程度高いスコアを示している以上,「これは間違いなく何かが違う」と断言していい。
筆者がAMDのJoe Macri(ジョー・マクリー)CTO兼コーポレートフェローから直接聞いたところによると,Ryzen Desktop 2000シリーズの「Zen+」マイクロアーキテクチャでInfinity Fabricの仕様は第1世代から変わっていないということなので,AMDが言う「キャッシュの遅延低減」が帯域幅に“効いて”いる可能性が高いと考えられる。
気になるのは4x 1kB Blocksだと第2世代Ryzenが第1世代Ryzenと比べて94〜95%程度のスコアに留まっているところだが,なぜそうなるのかは不明だ。ひょっとすると改良の副作用が出ているのかもしれない。
グラフ49,50にまとめたMemory Bandwidthの結果も面白い。総合スコアを見ると分かるように,Ryzen 7 2700XはRyzen 7 1800Xに対して,Ryzen 5 2600XはRyzen 5 1600Xに対してそれぞれ約2%,メモリバス帯域幅が増大しているからだ。メモリアクセス設定を完全に揃えた状態でスコアが上がっている以上,ここでも何らかの改良が入ったと見るのが正しいだろう。
メモリアクセス遅延を計測するCache & Memory Latencyの結果も興味深いものになった(グラフ51)。
L1キャッシュのサイズである32kB Rangeまではスコア差が見られない一方,L2キャッシュの範囲となる64kB Range〜512kB Rangeでは1.5〜1.6ns程度の低減が見られる。また,L3キャッシュの範囲となる1MB〜4MB Rangeでも1.6〜1.7nsの遅延低減を確認できるので,キャッシュへのアクセス遅延は確実に縮まっているようだ。
Ryzen系の場合,8MB Rangeを超えると「Infinity Fabricを通るため遅延が大きくなるのだが,そんな状況でもRyzen 5 2600XでRyzen 5 1600Xに対して10.8nsも遅延が低減しているのはインパクトが大きい。前述のとおりInfinity Fabricは変わっていないそうなので,L3キャッシュの遅延低減が効いているのかもしれない。
なお,メインメモリのブロックサイズとなる16MB Range以上でも,Ryzen 7 2700XでRyzen 7 1800Xに対して5.0〜5.1ns程度,Ryzen 5 2600XでRyzen 5 1600Xに対して5.6〜5.7ns程度の遅延低減を確認できた。
キャッシュ周りの帯域幅を見る「Cache Bandwidth」のテスト結果もやはり面白い。グラフ52を見ると分かるとおり,第2世代Ryzenではキャッシュの帯域幅が大きく上がっている。
とくに上げ幅が大きいのはL3キャッシュの範囲となる1MB Data Set〜4MB Data Setの範囲で,Ryzen 7 2700XはRyzen 7 1800Xに対して16〜21%程度,最大106GB/sも向上している。Ryzen 5 2600XもRyzen 5 1600Xに対して16〜20%程度,最大70GB/s上がった。
とくに128kB Data Setでは2桁もの伸びを見せているのだが,同じ動作クロックとなっている以上,これはキャッシュ改良の結果と見ていいだろう。
以上,第2世代のRyzenでは間違いなくメモリやキャッシュの遅延が低減しているうえ,キャッシュの帯域幅も無視できないほど拡大している。
実際のアプリケーションでこの違いが出てくるかというと,テストでも見たとおり“その内容による”ということになるのだが,一部では動作クロックを揃えても3%を超えるスコアの改善があるわけで,相応の効果はあると言えるだろう。
というわけで,第2世代Ryzenで第1世代Ryzenに対して改良が入っていることは間違いなく,とくに違いが顕著なのはキャッシュアクセス遅延低減や,L2およびL3キャッシュの帯域幅改善だということが分かった。また,メインメモリのアクセス遅延も確実に低下している。
ただ,その改良がベンチマークスコアに出てくるか否かはベンチマークソフトの内容次第といったところだ。それこそ先のレビュー記事で明らかになっているとおり,ゲームやエンコードといった部分で第2世代Ryzenは性能の大幅な向上を見せ,だからこそ4Gamerでも高い評価を行ったわけだが,そのスコア向上率はキャッシュアクセス遅延の低減やキャッシュの帯域幅拡大といったことだけでは説明がつきそうにない。
つまり,第2世代のRyzenを語るうえで外せないのは,自動クロックアップ関連の機能であるPrecision Boost 2やXFR2の特性ということになるはずである。
後編ではPrecision Boost 2を中心に,もう一歩突っ込んでRyzen Desktop 2000シリーズの特性を探ってみたい。
国内発売から1か月ほど経ち,価格もこなれつつあるため,ボーナス商戦期に向けてRyzen Desktop 2000シリーズの存在が気になっている読者も少なくないだろう。
 |
そこで今回は,Ryzen Desktop 2000というCPUについての理解をより深めてもらうべく,実アプリケーションの性能評価から少し離れ,Ryzen Desktop 2000というCPUの特性を,前後編に分けて見てみたいと考えている。
前編となる今回は,第1世代に対して第2世代のRyzenで相対的に何が変わったのかという部分をチェックしていく。
キャッシュとメモリのアクセス遅延低減と自動クロックアップ機能に改善が入った第2世代Ryzen
テストに先立って,Ryzen Desktop 2000シリーズの製品概要を振り返っておこう。
4月19日掲載の記事でもお伝えしているとおり,Ryzen Desktop 2000シリーズのマイクロアーキテクチャは第1世代Ryzenと同じだ。とはいえ,プロセッサとしてまったく同じというわけでもない。
 |
 |
表1に示すとおり,発表時点のシリーズ最上位モデルである8コア16スレッド対応モデル「Ryzen 7 2700X」は,置き換え対象となる「Ryzen 7 1800X」に対してブースト最大クロックが300MHz高くなっている。同様に6コア12スレッド対応モデル「Ryzen 5 2600X」も,置き換え対象となる「Ryzen 5 1600X」に対して200MHz高い。
 |
 |
Ryzen Desktop 1000シリーズの採用していたPrecision Boostは,最大クロックに達するのが2スレッドまで,つまり最大2コアに負荷がかかっているときまでに固定されていた。一方,Precision Boost 2では負荷がかかっているコア数に依存せず,さらにコア温度とコア電圧,電流を監視して,状況に応じたクロックで動作するとされる。たとえば4コアに負荷がかかっている状況でもコア温度やコア電圧,電流の状況次第では最大クロックで動作可能だ。
なので,Precision Boostに比べPrecision Boost 2のほうが高い動作クロックを保てると考えられ,その分だけ第1世代より高い性能が期待できるというわけである。
 |
さらに,スペックを見るだけでは分からない部分として,キャッシュやメモリのアクセス遅延を低減することで,クロックあたりの性能(IPC,Instructions Per Clock)を3%向上させたとAMDが主張しているのも,改良点として紹介できるだろう。
たとえばRyzen 7 2700Xの場合,ブースト最大クロックはRyzen 7 1800Xに対して約7.5%高い計算になる。それでIPCが3%向上となると,単純かつ乱暴なかけ算で約11%高い性能が得られるわけだ。また同じ計算式に当てはめると,Ryzen 5 2600XはRyzen 5 1600X比で約8%高い性能を得られることになる。
 |
 |
このうち本稿では,3%のIPC向上と,キャッシュやメインメモリのアクセス遅延を実現できているかをメインに,検証を進めていきたい。
そんな今回のテストで用いるのは,FinalWare製のシステムチェック&ベンチマークツール「AIDA64」(Engineer Edition,Version 5.97.4618 Beta)およびSiSoft製のシステムチェック&ベンチマークツール「Sandra 2017 SP4」(Engineer,Version 2017.12.24.61)といった基礎的なベンチマークアプリケーションだ。
使用した機材は初回レビュー時と完全に同じだが,テストしている時期が異なるためBIOSおよびドライバのバージョンは新しくなっている。具体的には表2のとおりとなる。
今回のテーマはあくまでも新旧Ryzenの違いを探ることだが,念のためIntel製CPUとの違いも見ておこうということで,レビュー記事でも用いた「Core i7-8700K」(以下,i7-8700K)をあらためて比較対象として用意している。
Ryzen 7 2700XとRyzen 5 2600Xのメモリアクセス設定は,AMDがレビュワーに推奨しているDDR4-3400(16-16-16-36)と,Single-Rank(シングルランク)のモジュール2枚に対するデュアルチャネルアクセス時定格となるDDR4-2933(16-16-16-36)の2パターンを用意した。Ryzen 7 1800XとRyzen 5 1600XではSingle-Rank(シングルランク)のモジュール2枚に対するデュアルチャネルアクセス時定格となるDDR4-2667(16-16-16-36),i7-8700Kでも定格のDDR4-2667(16-16-16-36)としている。
 |
なお,今回はプラットフォーム間で冷却条件を揃えるため,すべてのCPU,すべてのテストでサイズ製のサイドフローCPUクーラー「MUGEN5 Rev.B」(以下,MUGEN5)を使用している。AMDの主張によれば,XFR2は冷却条件次第でクロックがかなり変わることになるので,基礎的なテストでは冷却条件を揃えることが結構重要になると思われる。
以下,グラフ中に限りRyzen 7は「R7」,Ryzen 5は「R5」と表記するので,その点はあらかじめお断りしておきたい。
メモリのアクセス遅延低下やメモリ帯域幅の向上が認められるRyzen Desktop 2000
まずはAIDA64からだ。
グラフ1〜3は,AIDA64のテストから,主に整数演算主体のベンチマーク結果となる4項目を抜き出したものだ。グラフを3つに分けているのは純粋に見やすさを確保するためで,他意はない。以後も見やすさ重視でグラフは複数に分けることがあるため,その点はご注意を。
 |
グラフ1の「CPU Queen」は,古典的なNクイーン問題(N-Queens Problem,n×nの碁盤目状となるボードに縦横斜めに移動できるチェスのクイーンをn個置くとして,互いに攻撃できないよう配置するパターンがいくつあるか)を解くテストで,AVXおよびAVX2の整数演算を用いたものになる。
ここでトップスコアを示したのはRyzen 7 2700Xだが,DDR4-3400設定とDDR4-2933設定でほとんどスコア差は生じていない。Ryzen 7 1800X比では約8%高いスコアだが,理論的には約11%のスコア向上が得られるはずなので,ここでは期待にやや届いていないわけである。
一方,Ryzen 5 2600Xは,同じ6コア12スレッド対応で動作クロックも高いi7-8700Kを上回るスコアを叩き出した。やはりメモリ設定によるスコア差はほぼなく,Ryzen 5 1600Xに対してDDR4-3400設定で約11%,DDR4-2933設定で約12%高いスコアを示して期待値を上回っている。
メモリクロックがスコアにさほど影響を及ぼさないのはRyzen 7 2700X,Ryzen 5 2600Xで共通の傾向となっているため,偶然ではないだろう。Nクイーン問題はマス目の数を増やすほど使用するメモリ領域が増大するが,リニアなメモリアクセスは生じないので,アルゴリズム的にメモリクロックがあまり効かないということはあり得ると思う。
「CPU AES」はAES-NI(Advanced Encryption Standard - New Instructions)命令を用いて暗号化を行うテストだが,ここではRyzenがi7-8700Kを圧倒している。これはAMDとIntelで暗号化やハッシュのハードウェアアクセラレーションの実装が異なることに起因するのだろう。
AES-NIはAESの処理の一部を固定ハードウェアで行うので,固定ハードウェア部分が異なることでスループットも大きく変わると考えられるためだ。
Ryzen同士の比較だと,Ryzen 7 2700XはRyzen 7 1800Xに対して約10%,Ryzen 5 2600XはRyzen 5 1600Xに対して10〜11%程度高いスコアを示した。ハードウェアアクセラレーションを使用するだけに,メモリクロックの高いほうが有利になりそうなものだが,そうなっていないのは謎だ。Precision Boost 2の挙動がスコアに影響を与えているのかもしれない。
グラフ2の「CPU PhotoWorxx」は,整数演算を使って写真の加工処理を行うテストで,AVX(Advanced Vector eXtensionsと)やAVX2,SSE(Streaming SIMD Extensions)といったSIMD(Single Instruction, Multiple Data)演算を使うものになっている。
ここで頭1つ抜け出したのはRyzen 7 2700XのDDR4-3400設定だった。Ryzen 7 1800Xに対して約13%高いスコアだ。ただ,そんなRyzen 7 2700XもDDR4-2933設定時のスコアはRyzen 7 1800Xとほとんど同程度に留まってしまった。ここにはスコアのブレがあるわけだ。
「CPU Hash」はデータのハッシュ値を求めるテストで,SHA(Secure Hash Algorithm)を用いるとされるが,得られたスコア傾向はCPU AESと同じだった。
Ryzen 7 2700XのスコアはRyzen 7 1800Xに対して約7%,Ryzen 5 2600XはRyzen 5 1600Xに対して8〜9%程度高い。
 |
続いてグラフ3は古典的なx86命令のみを使ってデータの圧縮および展開を行うテスト「CPU Zlib」の結果だが,かなり極端な数字が出ている。
というのも,Ryzen 7 2700XのDDR4-2933設定時がRyzen 7 1800X比で約88%と沈んでいるのだ。DDR4-3400設定では逆に約9%高いので,メモリアクセス設定によるギャップはかなり大きいと言える。
一方のRyzen 5 2600XはDDR4-3400設定およびDDR4-2933設定で前世代比約10%増と,うってかわって順当にスコアを伸ばした。ただし,メモリクロックの違いはスコアにほとんど影響を及ぼしていない。メモリクロックの違いが顕れたり顕れなかったりするのはやはりPrecision Boost 2の挙動によるものかもしれない。
 |
AIDA64から,浮動小数点演算を使うテスト6項目のスコアをまとめたものがグラフ4,5である。
グラフ4から見ていこう。
 |
「FPU VP8」はVP8形式のエンコードを実行するテストで,Ryzen 7 2700XはRyzen 7 1800Xに対し,DDR4-3400設定で約8%,DDR4-2933設で約6%高いスコアを示した。期待値には届いていないものの,メモリクロック設定に対しては素直な反応を見せている印象だ。
一方のRyzen 5 2600Xだと,Ryzen 5 1600Xに対しDDR4-3400設定で約11%,DDR4-2933設定で約12%高いスコアなので,逆転現象が生じている。これもおそらくは動作クロックの挙動がもたらしているのだろう。
ちなみにここでi7-8700Kは最下位に沈んでおり,Ryzen 5 1600X比で約92%となっている。
続く「FPU SinJulia」は古典的なx87命令セットでIEEE標準の80bit精度浮動小数点演算を行い,ジュリア集合(Julia set,複素平面上である条件を満たす点の集合)を計算するテストである。
Ryzen 7 2700XのスコアはRyzen 7 1800Xに対してDDR4-3400設定,DDR4-2933設定ともに約7%高いという結果なので,メモリクロックはほとんどスコアを左右していないことが見てとれる。
ただ,Ryzen 5 2600Xの場合,Ryzen 7 1600Xに対するスコアはDDR4-3400設定時に約8%,DDR4-2933設定時に約9%高いレベルと,若干のスコア差が生じた。スコア向上の幅も8コア16スレッド対応モデルより大きい。
i7-8700Kは最下位という結果だが,x87はレガシーな命令セットなので,Intelもその性能をあまり重視していないのだろう。
次の「FP32 Ray-Trace」は32bit単精度浮動小数点演算を使ってレイトレーシングを実行するベンチマークで,AVX系のSIMD演算やFMA(Fused Multiply-Add)命令を使用するものとなっている。
ここで目を惹くのは,i7-8700Kが他を大きく引き離してトップを取っているところだ。浮動小数点数のSIMD演算やFMA命令セットの性能はIntelが優勢ということなのだろう。
Ryzen 7 2700XのスコアはRyzen 7 1800Xに対してDDR4-3400設定,DDR4-2933設定のいずれにおいても約14%高く,Ryzen 5 2600XのスコアはRyzen 5 1600Xに対してDDR4-3400設定で約13%,DDR4-2933設定で約14%それぞれ高いと,若干の違いがある。
メモリクロックに応じたスコアにはなっていないものの,スコアの向上幅は期待にほぼ沿った結果と言っていいだろう。
「FP64 Ray-Trace」は64bit倍精度浮動小数点演算を用いてレイトレーシングを行うテストだ。ここでもi7-8700KはRyzenを圧倒しており,浮動小数点数のSIMD演算やFMA命令セットを前にしたときの優位性を示している。
Ryzen 7 2700XのスコアはRyzen 7 1800Xに対してDDR4-3400設定,DDR4-2933設定とも約5%高い。Ryzen 5 2600XはRyzen 5 1600XよりDDR4-3400設定で約6%,DDR4-2933設定で約7%高いが,いずれもメモリクロックはほぼスコアを左右せず,スコアの伸びも期待値に届いていない。
浮動小数点演算テストの残る2項目はグラフ5に結果をまとめたとおりとなる。
 |
「FPU Julia」は32bit単精度演算を使ってジュリア集合を計算するテストだ。浮動小数点数のSIMD演算やFMA命令が使われるため,このテストでもi7-8700Kがトップを取っている。
Ryzen勢のスコア傾向はFPU SinJuliaに近い。Ryzen 7 2700XはRyzen 7 1800Xに対してDDR4-3400設定,DDR4-2933設定とも約6%高いスコアとなった。Ryzen 5 2600XはRyzen 5 1600Xに対してDDR4-3400設定で約7%,DDR4-2933設定で約8%高いスコアだ。
64bit倍精度浮動小数点演算でマンデルブロ集合(Mandelbrot set,ジュリア集合と同様に複素平面上である条件を満たす点の集合)を実行するテストとなる「FPU Mandel」も,SIMD命令やFMA命令を使うため,トップを取ったのはi7-8700Kだった。
Ryzen 7 2700XのスコアはRyzen 7 1800Xに対してメモリアクセス設定を問わず約6%高い。Ryzen 5 2600XはRyzen 5 1600Xに対してDDR4-3400設定で約7%,DDR4-2933設定で約8%高いという結果になっている。
ここまでAIDA64の整数や浮動小数点演算の結果を見てきたが,ざっくりと言えることは,
- Ryzen 7 2700X,Ryzen 5 2600Xともに前世代からのスコアの伸びは理論的な期待値に届かないケースが多い
- Ryzen 5 2600Xのほうが置き換え対象からのスコア向上率は高め
- メモリアクセス設定の違いがテスト結果には反映されにくい
- 少なくないテストでDDR4-2933設定のほうがスコアが高いという不思議な現象が見られる
といったあたりだろう。
続いてはAIDA64でメモリ周りのテスト結果を見ていきたい。グラフ6はメモリバス帯域幅を調べる3テスト「Memory Read」「Memory Write」「Memory Copy」の結果をまとめたものだ。
 |
一見して分かるのは,Ryzen 7 2700XとRyzen 5 2600XのDDR4-3400設定が比較対象に比べて好成績を収めていること。Memory Read,Memory WriteともにDDR4-2667設定の第1世代Ryzenと比べて約22%程度高いスコアを記録している。
Memory Copyだとメモリのアクセス遅延が読み出しと書き込みの双方で生じ,アクセス遅延の比重が大きくなることからスコア差は縮まるが、それでもRyzen 7 2700XはRyzen 7 1800Xに対して約14%,Ryzen 5 2600XはRyzen 5 1600Xに対して約15%高いスコアを示した。
その一方で,Ryzen Desktop 2000シリーズのDDR4-2933設定時におけるスコアは冴えない。Ryzen 5 2600XはRyzen 5 1600Xに対してMemory ReadとMemory Writeで約5%高いスコアを示して体裁は保っているものの,Memory Copyでは違いなし。Ryzen 7 2700Xに至っては3項目すべて大差のないスコアに留まってしまった。
CrystalDiskMarkにおいてDDR4-2933設定のほうがDDR4-3400設定より高いスコアを出すことが見られた以上,このスコアは解せないとしか言いようがないわけだが,ひょっとすると「DDR4-2933設定のほうがPrecision Boost 2によるコアクロックが高くなる」のかもしれない。Precision Boost 2についてはあらためて調べる予定なので,この疑問はひとまず置いておくことにする。
ちなみにメモリバス帯域幅のテストで最下位なのはi7-8700Kだった。Ryzenは第1世代からメモリバス帯域幅のテストには強かったので,この結果も妥当ではあるだろう。
グラフ7はメモリアクセス遅延を見る「Memory Latency」の結果だが,ここで最も優秀な結果を残したのはi7-8700Kだった。Intelは「Fast Memory Access(FMA)」という「DRAMのアクセス遅延を抑える技術」をCore 2 Duo時代に実装してから地道に改良し続けているので,一日の長があるということだろう。
この点でAMDはまだIntelに及ばないわけで,逆に言えば今後の最適化の余地が大きい部分と言うことができるはずだ。
ただ,それ以上に注目したいのは,第2世代Ryzenで第1世代Ryzenと比べて有意にメモリアクセス遅延が低減していることだ。Ryzen 7 1800Xと比べて,Ryzen 7 2700XのDDR4-3400設定では約18ns,DDR4-2933設定でも約7ns短い。Ryzen 5 1600Xに対するRyzen 5 2600Xも,DDR4-3400設定で約17ns,DDR4-2933設定で約11nsも短くなっている。
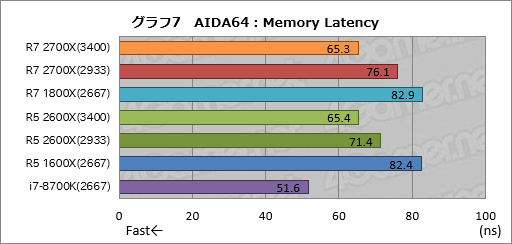 |
もっとも厳しいことを言えば,メモリクロックが高いので,第1世代Ryzenと比べてメモリアクセス遅延が短くなるのは当たり前でもある。
というのも,ここまでのテストではメモリアクセスタイミングの設定を揃えてるので,メモリクロックが高いほど遅延が低下するからだ。つまり,第2世代Ryzenでアクセス遅延が低下したかどうかについては,ここまでのテストだけでは断言できないということになる。
Ryzen Desktop 2000でメモリ周りに何らかの改善が入ったことは間違いない
以上,AIDA64の結果を見てきたが,第2世代Ryzenにおける謎としては,まずDDR4-3400設定よりもDDR4-2933設定のほうがスコアが高くなる傾向が見られたことが挙げられるだろう。
その原因としてはここまで何度か触れたとおりPrecision Boost 2が考えられる。また,Precision Boost 2を有効化している限り,メモリやキャッシュのアクセス遅延の改善やIPCの向上を読み取ることは難しい。
そこで,Precision Boost 2(およびPrecision Boost)を無効化のうえ,CPUのクロック倍率を32倍,つまり動作クロックを3.2GHzに固定し,さらにメモリアクセス設定もDDR4-2667で揃えて,新旧Ryzenの4製品を比較してみることにしよう。なお,ここではあくまでもRyzen同士の比較を行いたいので,i7-8700Kのテストは省略する。
というわけでグラフ8〜10は整数演算ベンチマークのスコアをまとめたものだが,ここで第2世代Ryzenは第1世代に対してCPU PhotoWorxxとCPU Zlibで1〜2%程度高いスコアを示している。
また,Ryzen 5 2600XではCPU AESでもRyzen 5 1600Xに対して約1%高いスコアを示した。AMDが主張する3%には届かず,またすべてのテストで同様な結果が出たわけではないが,クロックを揃えた状態の比較なので,有意な違いはあると見ていいだろう。
 |
 |
 |
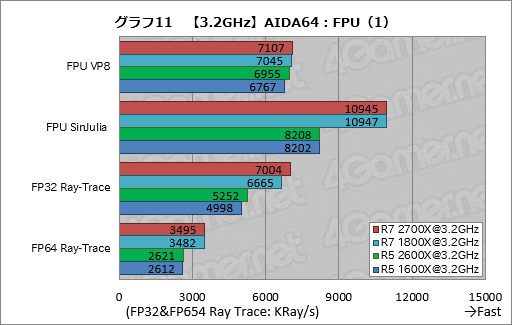
浮動小数点演算ベンチマークの結果はグラフ11,12である。FPU VP8でRyzen 5 2600XはRyzen 5 1600Xに対して約3%というスコアの向上を見せている。一方のRyzen 7 2700Xだと約1%だが,やはり比較対象のRyzen 7 1800Xに対して高いスコアを示した。
エンコード処理ではメモリアクセスが大きな比重を占めるため,第2世代Ryzenにおけるメモリアクセス遅延の改善が効いた可能性はある。
面白いのはFP32 Ray-Traceで,ここでRyzen 7 2700XとRyzen 5 2600Xはいずれも置き換え対象の第1世代Ryzenに対して約5%高いスコアを示している。「改善点はメモリやキャッシュのアクセス遅延の低減のみ」と考えるに,FP32 Ray-Traceはそれが効きやすいテストということなのだろう。
 |
 |
CPUクロックとメモリクロックを揃えた整数および浮動小数点演算の結果を見る限り,一部のテストでは確かに第1世代に対し第2世代でスコアが上がることが分かる。上昇の幅は一律3%というわけではないものの,テストによっては5%程度も伸びる場合もあるので,平均してみるとAMDの主張する3%というのは,妥当なところかもしれない。
もともとマイクロアーキテクチャは変わっておらず,メモリ周りのみの性能向上なので,全般的なスコア向上が得られるわけではないというのは,ある意味で理にかなっている。
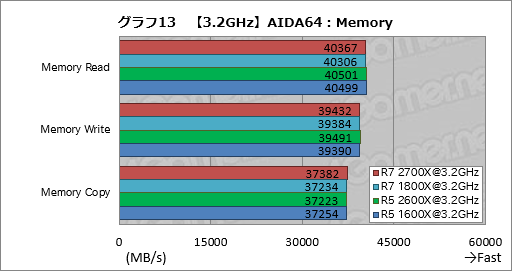
では,そのメモリ周りはどうなのか。Memory ReadとMemory Write,Memory Copyの結果をまとめたものがグラフ13となるが,メモリクロックとタイミングが揃っていることもあり,3つのテストで概ね横並びとなった。
 |
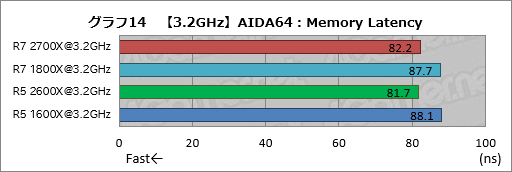
メモリアクセス遅延を見る「Memory Latency」の結果は非常に興味深いものとなった。グラフ14で示したとおり,Ryzen 7 2700XはRyzen 7 1800Xに対して約5.5ns,Ryzen 5 2600XはRyzen 5 1600Xに対して約6.4ns,それぞれアクセス遅延が小さいのだ。
動作クロックやメモリクロック,メモリアクセスタイミングを揃えた状態で有意に低い遅延を記録した以上,AMDが主張するとおり,第2世代Ryzenでキャッシュやメモリ周りに改良は間違いなく入っていると言っていいだろう。
 |
以上のテストから,第2世代Ryzenでメモリ周りに何らかの改良が入ったことは確かと断言できそうだ。それにより,第1世代のRyzenに対し第2世代では一部のベンチマークで1〜5%程度のスコアアップが確認できたと言っていのではないかと思う。
Sandra 2017 SP4では第1世代との間に明確な違いが認められる
続いては,Sandra 2017 SP4を実行した結果を見ていくことにしたい。
5月にリリースされた「Sandra 2018」はRyzen正式対応が謳われているのだが,今回のテストには間に合わなかった点はお断りしておきたい。
まずはPrecision Boost 2やPrecision Boost,Intelの「Turbo Boost Technology 2.0」を有効化した通常利用状態での結果を見ていこう。設定はAIDA64の動作クロックを固定しないテストに準じている。
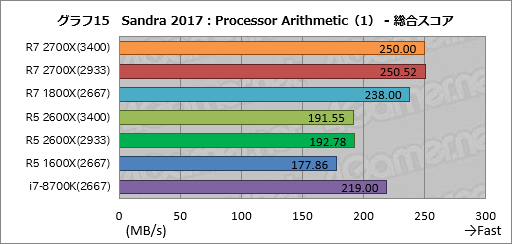
グラフ15はCPUの演算性能を見る「Processor Arithmetic」の総合スコア「Aggregate Native Performance」をまとめたものだ。
トップを取ったのはRyzen 7 2700Xで,2番手がRyzen 5 2600X,3番手がi7-8700Kという順位になった。
Ryzen 7 2700X,Ryzen 5 2600Xとも,スコアはメモリアクセス設定による違いはほぼなく,Ryzen 7 2700XはRyzen 7 1800Xに対して約5%,Ryzen 5 2600XはRyzen 5 1600Xに対して約8%高いスコアを示している。Ryzen 5 2600Xのほうはほぼ期待値どおりのスコアが出ているわけである。
 |
次にグラフ16はProcessor Arithmeticの個別スコアをまとめたものになる。個別スコアでもRyzen 7 2700Xがトップで,その後にRyzen 5 2600X,i7-8700Kという順位になる点は揺るがない。
Ryzen 7 2700XはRyzen 7 1800Xに対してDDR4-3400設定,DDR4-2933設定のいずれでも3〜6%程度高いスコアを示しているが,DDR4-3400設定で最もスコア差の縮まった「Whetstone Single-float Native AVX/FMA」(※古典的な浮動小数点演算ベンチマークWhetstoneをAVX&FMAを使って行うテスト)でDDR4-2933設定は最もスコア差を広げていたりと,バラつきに一貫性がない。なのでPrecision Boost 2の挙動がスコアに影響を与えていると思われる。
なお,Ryzen 5 2600XはRyzen 5 1600Xに対して5〜9%程度高いスコアを示した。スコアのバラつきに一貫性がないのはこちらも同様だ。
 |
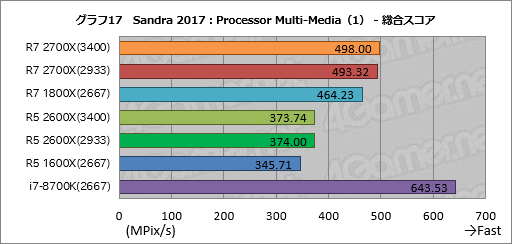
マルチメディア処理性能を見る「Processor Multi-Media」の総合スコアにあたる「Aggregate Multi-Media Native Performance」をまとめたものがグラフ17となる。
ここで圧倒的なトップを取ったのはi7-8700Kだ。Processor Multi-MediaではAVX2やFMAが多用されるため,その種の命令におけるRyzen系との性能差がでた結果だろう。
2018年5月30日19:30頃追記:初出時,i7-7800KがAVX512をサポートすると記載していましたが,サポートしていませんでした。お詫びして訂正いたします。
Ryzen 7 2700XのスコアはRyzen 7 1800X比でDDR4-3400設定において約7%,DDR4-2933設定において約6%高い。期待値には届いていないものの,DDR4-3400設定におけるスコアのほうが伸びていることも含め,まずまずだ。
一方のRyzen 5 2600XはRyzen 5 1600Xに対してメモリアクセス設定を問わず約8%高いスコアとなった。メモリアクセス設定による違いはないものの,期待値はクリアした格好である。
 |
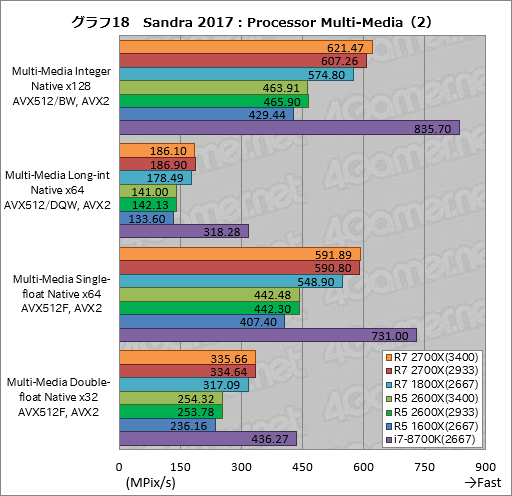
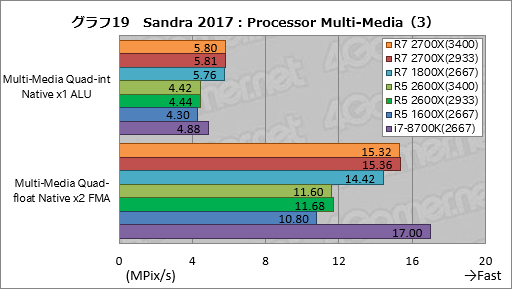
グラフ18,19は「Processor Multi-Media」の個別スコアをまとめている。i7-8700Kがどうしても突出してしまうが,Ryzen同士で比較すると,マルチメディア処理をx86命令で行う「Multi-Media Quad-int Native x1 ALU」で第2世代と第1世代の間にスコア差がほとんど生じていないという,特徴的な結果が出ている。Multi-Media Quad-int Native x1 ALUは古典的なx86命令を使うテストなので,動作クロックの違いがスコアを左右しそうなものだが……。
それ以外のテストはおおむね総合スコアを踏襲する傾向が出ていると言っていいだろう。
 |
 |
CPUを用いた暗号化の性能を調べる「Processor Cryptographic」の結果から,総合スコア「Cryptographic Bandwidth」を見たものがグラフ20である。端的にまとめると,AIDA64の暗号化テストと同様に,Ryzenが競合に対して強さを見せている。
メモリバス帯域幅の違いがはっきりと出ているのも特徴だろう。Ryzen 7 2700XはRyzen 7 1800Xに対し,DDR4-3400設定で約8%,DDR4-2933設定で約1%高いスコアと,かなりの違いが出ている。Ryzen 5 2600XとRyzen 5 1600X間も順に約12%,約6%だ。
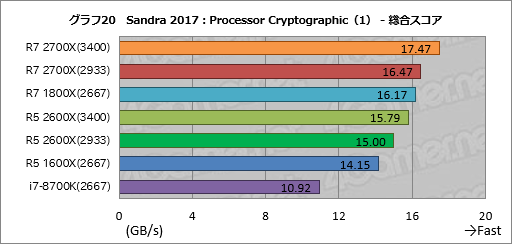 |
Processor Cryptographicの個別スコアはグラフ21のとおり。ハードウェアアクセラレーションを使用する「Encryption/Decryption Bandwidth AES256-ECB AES」だとDDR4-3400設定でRyzen 7 1800Xに対して約11%高いスコアを示すのに対し,ハードウェアアクセラレーションを利用しない「Hashing Bandwidth SHA2-256 AVX512, AVX2」だと約5%に留まり,またDDR4-2933設定との違いもほぼなくなるという対照的な結果となった。
 |
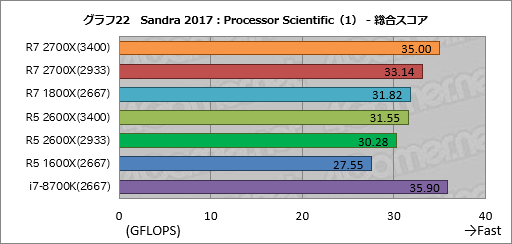
科学技術計算を行う「Processor Scientific」の総合スコア「Aggregate Scientific Performance」をまとめたものがグラフ22となる。
このテストではFMA命令セットを多用するため,FMAの性能がいまひとつなRyzenは分が悪く,i7-8700Kがトップを取った。
Ryzen同士の比較だと,Ryzen 7 2700XはDDR4-3400設定で約10%,DDR4-2933設定で約4%,それぞれRyzen 7 1800Xより高いスコアを示し,Ryzen 5 2600XのほうもRyzen 5 1600Xに対して順に約15%,約10%高いスコアを示した。いずれもメモリアクセス設定の違いが素直に数字として出ている。
 |
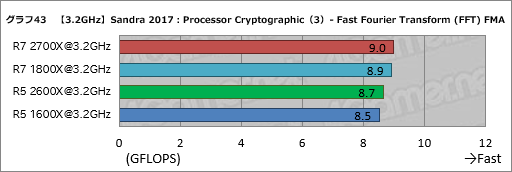
そんなProcessor Scientificの個別スコアがグラフう23,24である。
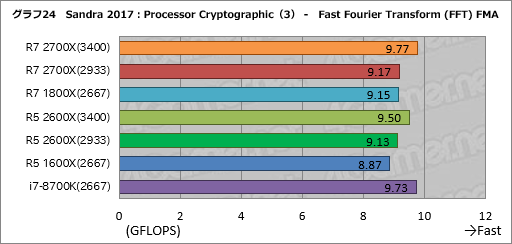
全般にi7-8700Kのスコアが高めだが,それはさておきRyzen系のスコアに注目すると,行列演算を行う「General Matrix Multiply (GEMM) FMA」と高速フーリエ変換を行う「Fast Fourier Transform (FFT) FMA」の2つにおいて,第2世代RyzenはDDR4-3400設定時にDDR4-2933設定時と比べて良好なスコアが出ている。これは双方ともメモリアクセス性能が“効く”タイプの処理だからだ。
とくにGeneral Matrix Multiply (GEMM) FMAでは,Ryzen 7 2700XのDDR4-3400設定でRyzen 7 1800Xに対して約14%,Ryzen 5 2600XのDDR4-3400設定でなんと約22%ものスコア差が生じており,インパクトが大きい。
Fast Fourier Transform (FFT) FMAだとそれほどの違いは出ていないわけだが,これはGeneral Matrix Multiply (GEMM) FMAが短時間で終わるテストのため,Precision Boost 2の効果が強く現れた結果だろうと筆者は見ている。
 |
 |
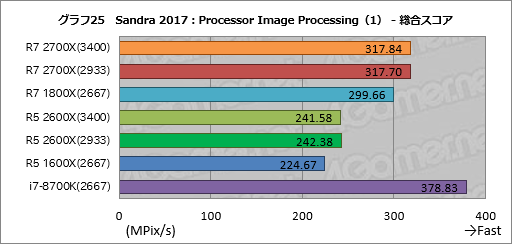
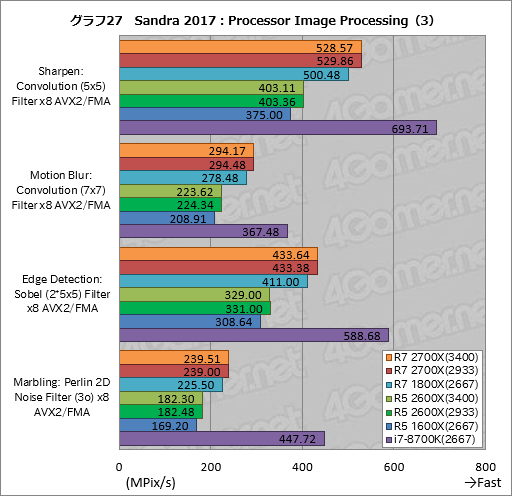
続いてはAVXやFMAを用いて2D画像を処理するときの性能を見る「Processor Image Processing」だ。グラフ25は総合スコアに当たる「Aggregate Image Processing Rate」をまとめたものとなる。
ここでもトップはi7-8700Kだが,Processor Image ProcessingではすべてのテストでAVXとFMA命令を利用するので,その性能がスコアを左右する。AIDA64でも見てきたようにi7-8700KはAVXの浮動小数点演算やFMAの性能に優れるため,その傾向がここでも出ているわけだ。
Ryzen同士で比較すると,Ryzen 7 2700X,Ryzen 5 2600Xともに,メモリアクセス設定がスコアを左右していない。前者はRyzen 7 1800Xに対して約6%,後者はRyzen 5 1600Xに対して約8%高いスコアとなっている。
 |
そんなProcessor Image Processingの個別スコアを並べたのがグラフ26〜28だが,おおむねすべてのテストで総合スコアと大差ない傾向を示している。例外は画像の誤差拡散を行う「Diffusion: Randomise (256) Filter x8 AVX2/FMA」で,グラフ26を見ると,ここだけはメモリアクセス設定の違いがスコアを大きく左右している。
具体的には,Ryzen 7 2700XはRyzen 7 1800Xに対してDDR4-3400設定で約10%,DDR4-2933設定で約4%,Ryzen 5 2600XはRyzen 5 1600Xに対して順に約10%,約8%高いスコアを示した。このテストは誤差拡散法のフィルタが比較的シンプルなアルゴリズムとなっているため,メモリアクセス性能の違いがスコアとして素直に出やすいのだろう。
 |
 |
 |
CPUコア間のデータ転送の帯域幅を調べる「Processor Multi-Core Efficiency」の結果がグラフ29となる。
これはなかなか興味深い結果となっており,第2世代Ryzenでは「4x 4kB Blocks」〜「16x 64kB Blocks」の間で帯域幅が第1世代Ryzenと比べて高い。具体的なスコアはグラフ画像をクリックすることで確認できるようにしてあるが,Ryzen 7 2700XはRyzen 7 1800Xに対して10〜21%程度,Ryzen 5 2600XはRyzen 5 1600Xに対して13〜26%程度も高いスコアなのだから,「メモリクロックやCPUの動作クロックが上がっただけ」では説明できないだろう。何らかの改良が入ったことを窺わせるデータだ。
 |
メモリバス帯域幅を見る「Memory Bandwidth」の総合スコアがグラフ30だが,AIDA64と同様,このテストではRyzenがi7-8700Kを上回る結果を残した。
もっとも,そのRyzenもなかなか不思議なスコアを残している。Ryzen 7 2700XのDDR4-3400設定がRyzen 7 1800Xに対して約20%も高いスコアを叩き出す一方,DDR4-2933設定だと約98%に沈んでいるのだ。Ryzen 5 2600Xはそこまで極端でないものの,やはりDDR4-3400設定でRyzen 5 1600Xに対して約19%高いスコアを示すのに対し,DDR4-2933設定だとギャップは約4%にまで縮んでいる。
 |
グラフ31はそんなMemory Bandwidthの個別スコアだが,ものの見事に総合スコアを踏襲する結果となった。
 |
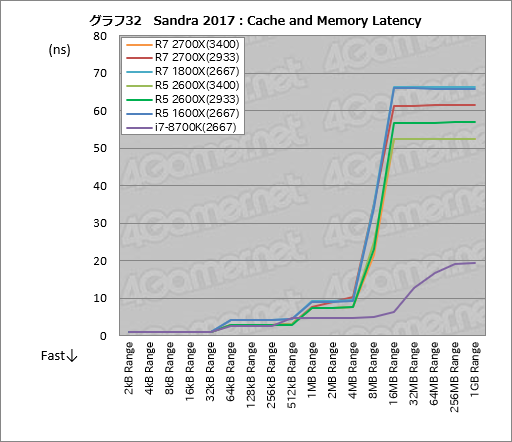
キャッシュおよびメモリの遅延を計測する「Cache & Memory Latency」の結果がグラフ32となる。
スコアが重なっているのでちょっと分かりにくいが,全体として第2世代Ryzenでメモリアクセス遅延は第1世代Ryzenと比べて低減を果たしている。たとえばL2キャッシュの範囲内となる64kB Range〜256kB Rangeの範囲だと,スコアには1.4nsの違いがある。
その中で興味深いのはRyzen 7 2700XのDDR4-2933設定で,スコアが安定感を欠き,4MB RangeではRyzen 7 1800Xに対して遅延状況が悪化してしまっている。4MB RangeはL3キャッシュの範囲であり,CPUのコアクロックやメモリクロックが向上していることから遅延は低下していいはずだ。そうなっていないのは,おそらくPrecision Boost 2およびPrecision Boostの挙動が関係しているのだろう。
メインメモリの範囲となる16MB Range以上のサイズでも第2世代Ryzenはメモリアクセス遅延を順当に低減している。「Ryzen 7とRyzen 5はL3キャッシュ容量16MBだから,16MB Rangeはキャッシュ内では?」と思うかもしれないが,デスクトップPC向けRyzenでは4基のCPUと容量8MBのL3キャッシュを「CPU Complex」(公式略称「CCX」,以下略称表記)とし,それを専用インタフェース「Infinity Fabric」経由で最大2基束ねている。しかも「Zen」マイクロアーキテクチャではL1とL2,L3キャッシュそれぞれに重複してはデータを保持しないという排他的なキャッシュ制御法を採用しているため,16MB Blocksはメインメモリのアクセス遅延が支配的になるのだ。
もっとも,見て分かるとおりこのレンジではi7-8700Kが非常に優秀で,現在のところRyzenでは歯が立たない。
 |
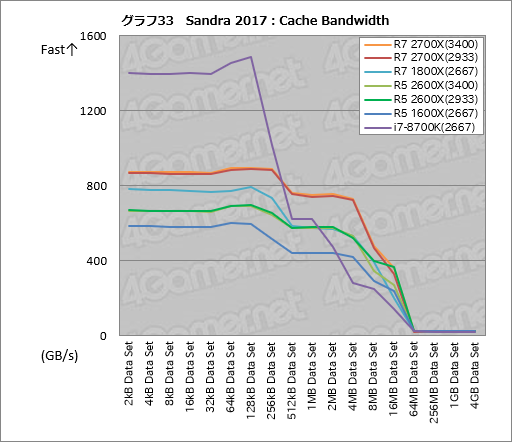
グラフ33はキャッシュ周りの帯域幅を見る「Cache Bandwidth」のテスト結果となる。第2世代Ryzenのスコアは第1世代Ryzenに対して16MB Data Set以内で順当に上がっているが,CPUおよびメモリクロックの設定が異なるので,このスコア向上が動作クロックによるものなのか改良の結果なのかは,これだけだと判断できない。
メインメモリ領域にかかる64MB Data Set以上の帯域幅はなかなか微妙で,「Ryzen 7 2700XのDDR4-2933設定はRyzen 7 1800X(のDDR4-2667設定)に及ばない」格好になっている。DDR4-3400設定では順当にi7-8700Kを上回る成績を残しているので,この結果はよく分からないというのが正直なところだ。
 |
クロックを揃えることで見えるIPCの向上
以上,通常利用状態におけるSandra 2017 SP4の結果を見てきたが,AIDA64と同様,Ryzen Desktop 2000シリーズではメモリクロックの結果がスコアに反映されづらい傾向があるようだ。
スコア向上の期待値と見比べると,Ryzen 7 2700Xのほうは届かない傾向にあるものの,Ryzen 5 2600Xは前世代からの上げ幅が大きく,期待値にかなり近い成績を残すことも分かる。このあたりはAIDA64と共通している印象を受けた。
といったところで,AIDA64と同じようにCPUコアクロックを3.2GHz,メモリアクセス設定をDDR4-2667に固定した結果も見ていきたい。
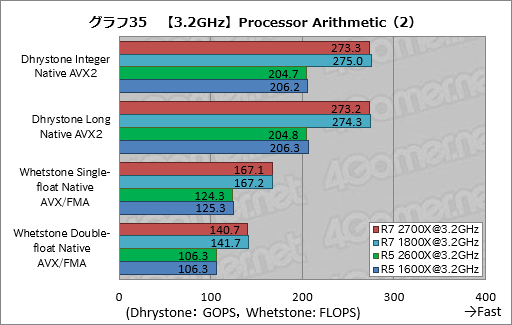
まずグラフ34,35はProcessor Arithmeticの結果である。Ryzen 7 2700XとRyzen 7 1800X,Ryzen 5 2600XとRyzen 5 1600Xのスコア差はほぼないどころか,全体として第1世代Ryzenのほうがスコアは若干ながら上なので,少なくとも3%というIPCの向上は,ここでは確認できない。
 |
 |
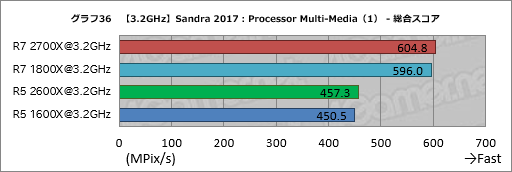
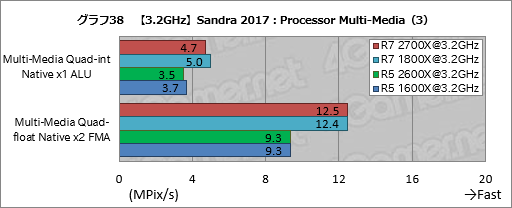
グラフ36〜38はProcessor Multi-Mediaのスコアだ。ここでも総合スコアは第2世代Ryzenと第1世代Ryzenとの間で基本的に大差ない。
ただそれだけに目立つのは,グラフ38のMulti-Media Long-int Native x64 AVX512/DQW, AVX2でRyzen 7 2700XがRyzen 7 1800Xの約94%,Ryzen 5 2600XがRyzen 5 1600Xの約95%にまでスコアを落としていることだ。同じようにスコアが落ちているので偶然ではないだろうが,なら原因は何かと言われてもはっきりしない。古典的なx86命令では第2世代Ryzenにおける改良がむしろ足を引っ張る場合があるのかもしれない。
 |
 |
 |
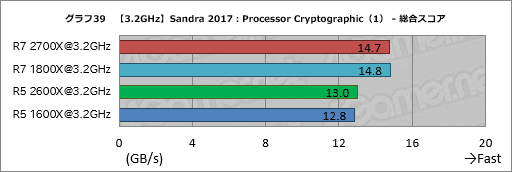
Processor Cryptographicのスコアがグラフ39,40だ。Ryzen 5 2600XがEncryption/Decryption Bandwidth AES256-ECB AESでRyzen 5 1600Xに対して約2%高いスコアを示し,結果として総合スコアでも1%高いスコアを示しているが,Ryzen 7 2700XのほうはRyzen 7 1800Xと横並びである。
 |
 |
グラフ41〜43はProcessor Scientificの結果だが,ここで興味深いのはGeneral Matrix Multiply (GEMM) FMAのスコアで,Ryzen 7 2700XはRyzen 7 1800Xに対して約3%,Ryzen 5 2600XにいたってはRyzen 5 1600Xに対してなんと約13%も高い。
後者のスコア差はクロックを揃えているだけに異常で,Ryzen 7 1600Xのテスト時に何らかのトラブルがあった可能性を否定できないが,テストをやり直しても結果は誤差程度にしか変わらず。したがって,Ryzen 5 2600XとRyzen 7 1600Xの大きなスコア差は計測ミスではないようだ。General Matrix Multiply (GEMM) FMAはサイズが比較的小さいテストになるので,キャッシュのアクセス遅延の改善などが大きく結果に影響を与えたのかもしれない。同じ理由で,Ryzen 7 2700XがRyzen 7 1800Xに対して高いスコアを示しているのも偶然ではないはずだ。
 |
 |
 |
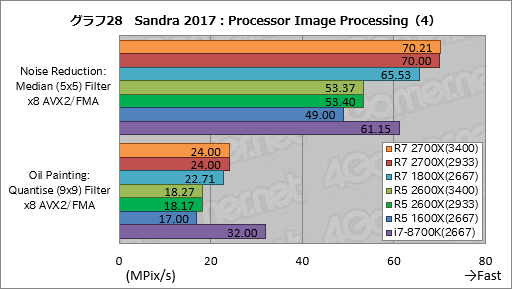
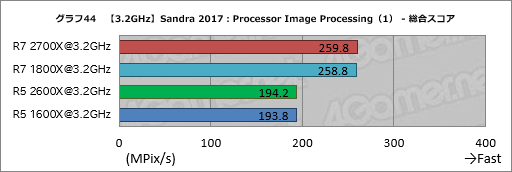
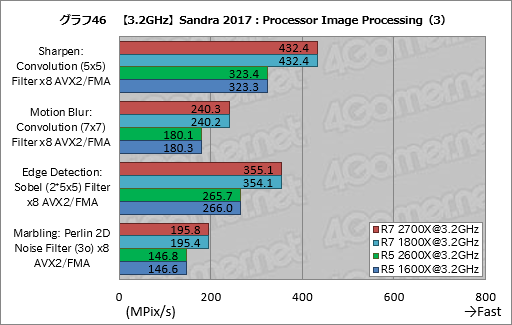
Processor Image Processingの結果はグラフ44〜47のとおりだ。
Ryzen 7 2700XはRyzen 7 1800Xに対し,グラフ45のDiffusion: Randomise (256) Filter x8 AVX2/FMAで約2%,メディアンフィルタによる画像のノイズ低減を行う「Noise Reduction: Median (5x5) Filter x8 AVX2/FMA」で約1%高いスコアを示しているが,Ryzen 5 2600XとRyzen 5 1600Xで同様の傾向は出ていないので,おそらくブレの範囲だろう。
それ以外のスコアはほぼ揃っている。
 |
 |
 |
 |
ここまでの結果からすると「3%というIPCの向上は確認できない」という結論になるが,グラフ48のProcessor Multi-Core Efficiencyは,非常に興味深い結果となっている。
Ryzen 7 2700XとRyzen 5 2600Xはともに,4x 4kB Blocksから4x 64kB Blocksにかけて帯域幅が大きく拡大している。動作クロックやメモリクロックが揃い,結果としてInfinity Fabricのクロックも揃った状態で,Ryzen 7 2700XはRyzen 7 1800Xに対して,Ryzen 5 2600XもRyzen 5 1600Xに対してそれぞれ5〜13%程度高いスコアを示している以上,「これは間違いなく何かが違う」と断言していい。
筆者がAMDのJoe Macri(ジョー・マクリー)CTO兼コーポレートフェローから直接聞いたところによると,Ryzen Desktop 2000シリーズの「Zen+」マイクロアーキテクチャでInfinity Fabricの仕様は第1世代から変わっていないということなので,AMDが言う「キャッシュの遅延低減」が帯域幅に“効いて”いる可能性が高いと考えられる。
気になるのは4x 1kB Blocksだと第2世代Ryzenが第1世代Ryzenと比べて94〜95%程度のスコアに留まっているところだが,なぜそうなるのかは不明だ。ひょっとすると改良の副作用が出ているのかもしれない。
 |
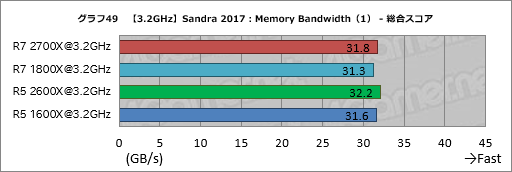
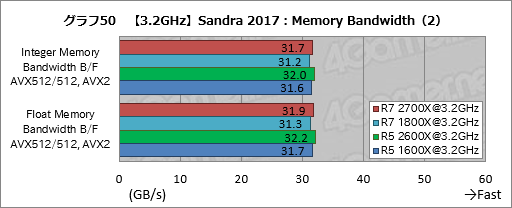
グラフ49,50にまとめたMemory Bandwidthの結果も面白い。総合スコアを見ると分かるように,Ryzen 7 2700XはRyzen 7 1800Xに対して,Ryzen 5 2600XはRyzen 5 1600Xに対してそれぞれ約2%,メモリバス帯域幅が増大しているからだ。メモリアクセス設定を完全に揃えた状態でスコアが上がっている以上,ここでも何らかの改良が入ったと見るのが正しいだろう。
 |
 |
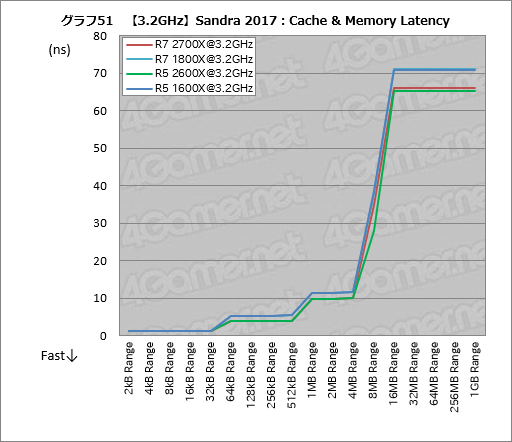
メモリアクセス遅延を計測するCache & Memory Latencyの結果も興味深いものになった(グラフ51)。
L1キャッシュのサイズである32kB Rangeまではスコア差が見られない一方,L2キャッシュの範囲となる64kB Range〜512kB Rangeでは1.5〜1.6ns程度の低減が見られる。また,L3キャッシュの範囲となる1MB〜4MB Rangeでも1.6〜1.7nsの遅延低減を確認できるので,キャッシュへのアクセス遅延は確実に縮まっているようだ。
Ryzen系の場合,8MB Rangeを超えると「Infinity Fabricを通るため遅延が大きくなるのだが,そんな状況でもRyzen 5 2600XでRyzen 5 1600Xに対して10.8nsも遅延が低減しているのはインパクトが大きい。前述のとおりInfinity Fabricは変わっていないそうなので,L3キャッシュの遅延低減が効いているのかもしれない。
なお,メインメモリのブロックサイズとなる16MB Range以上でも,Ryzen 7 2700XでRyzen 7 1800Xに対して5.0〜5.1ns程度,Ryzen 5 2600XでRyzen 5 1600Xに対して5.6〜5.7ns程度の遅延低減を確認できた。
 |
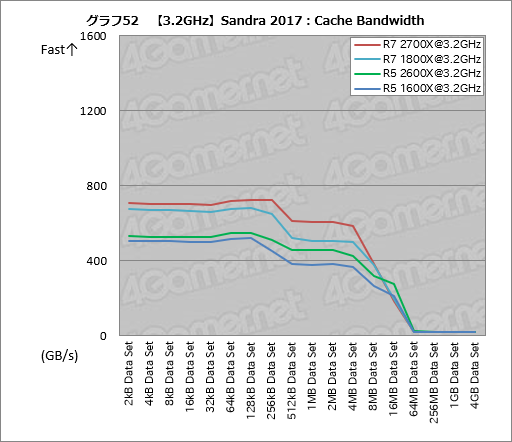
キャッシュ周りの帯域幅を見る「Cache Bandwidth」のテスト結果もやはり面白い。グラフ52を見ると分かるとおり,第2世代Ryzenではキャッシュの帯域幅が大きく上がっている。
とくに上げ幅が大きいのはL3キャッシュの範囲となる1MB Data Set〜4MB Data Setの範囲で,Ryzen 7 2700XはRyzen 7 1800Xに対して16〜21%程度,最大106GB/sも向上している。Ryzen 5 2600XもRyzen 5 1600Xに対して16〜20%程度,最大70GB/s上がった。
とくに128kB Data Setでは2桁もの伸びを見せているのだが,同じ動作クロックとなっている以上,これはキャッシュ改良の結果と見ていいだろう。
 |
以上,第2世代のRyzenでは間違いなくメモリやキャッシュの遅延が低減しているうえ,キャッシュの帯域幅も無視できないほど拡大している。
実際のアプリケーションでこの違いが出てくるかというと,テストでも見たとおり“その内容による”ということになるのだが,一部では動作クロックを揃えても3%を超えるスコアの改善があるわけで,相応の効果はあると言えるだろう。
第2世代Ryzenのカギを握るのはPrecision Boost 2か
 |
ただ,その改良がベンチマークスコアに出てくるか否かはベンチマークソフトの内容次第といったところだ。それこそ先のレビュー記事で明らかになっているとおり,ゲームやエンコードといった部分で第2世代Ryzenは性能の大幅な向上を見せ,だからこそ4Gamerでも高い評価を行ったわけだが,そのスコア向上率はキャッシュアクセス遅延の低減やキャッシュの帯域幅拡大といったことだけでは説明がつきそうにない。
つまり,第2世代のRyzenを語るうえで外せないのは,自動クロックアップ関連の機能であるPrecision Boost 2やXFR2の特性ということになるはずである。
後編ではPrecision Boost 2を中心に,もう一歩突っ込んでRyzen Desktop 2000シリーズの特性を探ってみたい。
 |
- 関連タイトル:
 Ryzen(Zen,Zen+)
Ryzen(Zen,Zen+) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー