









イベント
西川善司の3DGE:第10世代Coreプロセッサに統合されたGPUの正体。性能はRyzen 7 3700Uの内蔵Vegaとほぼ同等で,Variable Rate Shadingにも対応
先日行われたCOMPUTEX 2019のIntelによる基調講演の中で,10nm製造プロセスで製造される第10世代Coreプロセッサ,開発コードネーム「Ice Lake」がついに出荷されたことが発表された。採用製品の市場展開ももうすぐという状況だが,Intelがこの「Ice Lake」の試作チップを実際に動かしてのデモを見せている。
今回,幸運にもその様子を取材することができたのでレポートしたい。
Ice Lakeには第11世代統合型グラフィックス機能が内蔵されるが,今回のデモでは,その描画パフォーマンスがお披露目された。
まず示されたのは第9世代統合型グラフィックス(UHD Graphics 620)を内蔵したCore i7-8565U(Whiskey Lake)との性能の違いだ。どちらのプロセッサもTDPは15Wである。
テストに用いられたのは発売されたばかりのThe Creative Assembly開発のリアルタイムストラテジーゲーム「Total War: THREE KINGDOMS」のベンチマークモードだった。
結果はIce Lakeの圧勝。そのパフォーマンスの向上率は約2.0倍近くとなっていた。UHD Graphics 620のEU(Execution Units:実行ユニット)は24基,対するIce Lake側の統合型グラフィクスはEUが64基もあるため,その違いが出たことが大きいと思うが,組み合わされるメモリの速度の違いも一因となっていると見るべきか。
というのもWhiskey Lakeは組み合わされるメモリがDDR4-2400/LPDDR3-2133なのに対し,Ice LakeではDDR4-3200/LPDDR4X-3733となっているはずだからだ。ちなみに,今回のデモではCore i7-8565U(Whiskey Lake)側のメモリがDDR4-2400だったのに対し,Ice Lake側のメモリ仕様は「秘密」とのことであった。
ところで,なぜIce Lake内蔵の第11世代統合型グラフィックスと第9世代を比較しているのか疑問に思った人もいるのではないだろうか。先代と比較するならば第10世代と比較するのが筋ではないのか,と。
これについては,Intelとしてはあまり突っ込まれたくない事情がある。第10世代統合型グラフィックスは,うまく軌道に乗せられなかった初期の10nm製造プロセス製造による開発コードネーム「Cannon Lake」に内蔵されたものだからだ。ある種,第10世代統合型グラフィックスはIntelの中では欠番扱い……なのであろう。
テストのあとには,この組み合わせで別のベンチマークテストを実行した結果も示されたが,Intel側の発表によればIce LakeのほうがWhiskey Lakeに対しておよそ1.5倍から2.0倍のパフォーマンスを出せているようである。
なお,実機検証こそ見せてはもらえなかったが,Intelによれば,Ice Lakeの第11世代統合型グラフィクスプロセッサは,AMDのVega 10ベースのGPUを内蔵したAPU,Ryzen 7 3700U(Zen+コアベース。12nm製造プロセス)のパフォーマンスとほぼ互角であるという分析であった。
ちなみにRyzen 7 3700UのGPUは,Radeon RX Vega(Vega 10ベースの10CU構成)で,組み合わされるメモリはDDR-2400(最大)である。最新世代のグラフィックスを駆使したゲームをフルHD解像度で30fpsくらいでプレイすることはできそうな性能といったところだ。グラフィックス負荷が軽めの最近のeスポーツ系のゲームであればフルHDでギリギリ60fpsのプレイが可能か……といったところ。
グラフィックスがらみでは,Ice Lakeの第11世代統合型グラフィクスプロセッサの新フィーチャーについてのデモも行われたので触れておきたい。
その新フィーチャーとは「Variable Rate Shading」である。
これは,これからレンダリングするフレームのシェーディング解像度(陰影計算を行う解像度)を,「特定のアルゴリズム」にて「臨機応変」「適材適所」に,ドットバイドットの1×1ピクセル(最上位)から2×2ピクセル,4×4ピクセル……といった具合に解像度を下げて実行する仕組みである。
そう,VRSとはNVIDIAがGeForce RTX/Quadro RTXシリーズで導入した新機能である。
「特定のアルゴリズム」というのは「レンダリング先フレームが,どのような映像になるかをあらかじめ予測する」処理系のことである。これはGPU側で自動的には行えず,ゲームエンジンなりグラフィックスプログラマが自前でソフトウェア的に実装する必要がある。
ではどういう処理するかというと,例えば「ポリゴンの輪郭付近は高解像度で」「なだらかなグラデーションベースのテクスチャ表現主体の箇所は低解像度で」「動きの速い表現は低解像度で」「動きの遅い表現は高解像度で」といったアルゴリズムになる。
前者2つの「ポリゴンの輪郭付近は高解像度で」「なだらかなグラデーションベースのテクスチャ表現主体の箇所は低解像度で」はVRSの中でも「Content Adaptive Shading」(コンテントアダプティブシェーディング,以下 CAS)と呼ばれるものであり,「動きの速い表現は低解像度で」「動きの遅い表現は高解像度で」は「Motion Adaptive Shading」(モーションアダプティブシェーディング,以下 MAS)と呼ばれるものになる。
CASは前フレームのデプスバッファの差分値や,あらかじめ定義しておいたマテリアル/テクスチャなどの情報からVRS解像度を決定する。MASは前フレームと現在フレームとの両方で描かれることになる同一ポリゴンの移動速度をピクセル単位の速度で表したベロシティバッファの情報からVRS解像度を決定する。
これらの処理系はすべてシェーダで書かなければならないので,ではどこがハードウェアで実行されるかというと,代表ビクセルで計算した陰影情報を2×2=4ピクセルや,4×4=16ピクセルといった低解像度に相当する複数ピクセルにコピーする仕組みの部分だけである。
VRS実装! ……というと凄そうに思えるが,シェーダユニットのデータパスを組み替えただけなので,それほど実装にはコストが掛からないメカニズムなのである。VRSのための特別な演算ユニットなどは一切不要なのだ。
ただ,効果のほどは絶大だ。
実機を使って行われた,第9世代統合型グラフィックス(UHD Graphics 620)を内蔵したCore i7-8565U(Whiskey Lake)マシンとのフレームレート比較ではなんと3倍ものの違いを見せつけていた。
テストに使われた2台のマシンは前出の最初のテストと同じものだ。最初のテストは生レンダリング同士の比較で2倍のパフォーマンスを見せつけていたわけだが,このVRSではさらに性能向上率を3倍にまで広げた格好である。
実際には両者のレンダリング結果は異なっているわけだが,見た目的には分からない。「だからこそ,VRSを積極的に使ったほうがいい」というのがIntel側の主張だ。
Intelの担当者によれば,業界標準3Dグラフィックスベンチマークの3DMarkには近々新テストモードとして「VRS Feature Test」が追加されるそうなのだが,そのβ版を使ったIntel側のテストでも,VRSのオフ/オンでパフォーマンスを比較すると40%ほどのスコアアップが見られたとのこと。
また,上で比較対象として挙げたRayzen 7 3700Uとパフォーマンス的には互角だったIce Lakeだが,VRSオンでは当然ながら,VRS未対応のRyzen 7 3700Uよりも高いスコアを獲得できたこともアピールしていた。
Ice Lakeは,AVX-512に対応し,またそれをさらに機械学習型AIの推論処理に向けた特別命令セット「DL Boost」にも対応しているわけだが,最後に,そのあたりの実効パフォーマンスがどの程度高められたかを示すデモを披露した。
用いられたのはPrincipled Technologiesが開発を進めている画像認識AIベンチマークソフトの「AIXPRT」のβ版だ。
テストに用いたマシンはこれまでと同じで,Core i7-8565U(Whiskey Lake)マシンとIce Lake搭載試作マシンの組み合わせとなる。
このAIXPRTは,もともと無数の画像データを学習済みの「画像分類AI」のResNet(Residual Network) に対し,分類対象画像を見せて,それを分類する処理速度を計測するものだ。分類が不正解か,正解かの正確性については無視しているテストで,どんなマシンを使っても何度実行しても得られる分類結果は変わらない。要はAIXPRTとは画像を認識するための推論処理速度を計測するベンチマークというわけである。
実際の実行結果はCore i7-8565U(Whiskey Lake)マシンで毎秒63枚の分類が行えたのに対し,Ice Lake搭載試作マシンではこれが毎秒176枚であった。Ice Lakeでは,Whiskey Lakeの約3倍のAI推論パフォーマンスが得られるといこうとになる。
ちなみに,Ice Lake搭載マシンで動作させられていたAIXPRTは,AVX-512/DL Boost最適化オプションを適用したビルドで,Whiskey Lake搭載マシンで実行させたAIXPRTはそうした最適化は外されたビルドだとのことである。詳細は不明とのことだったが,AVX2はAMD製CPUにも対応が広がっているため,推測にAVX2までは使用したビルドだと思われる。
Intelが,AIXPRTのほかのテストモードで計測した結果も示されたが,推論処理を32ビット浮動小数点数(FP32)ではなく8ビット整数(INT8)で行うと,さらにパフォーマンスが増強されることなどを指摘していた。
画像処理系のAI処理は,学習時はまだしも,入力を与えて学習データをもとに推論を導出する処理系においては浮動小数点演算はややオーバースペックなので,8ビット整数に対応したDL Boostの効果は非常に大きいのだ。AVX-512は512ビット幅のSIMD演算器なので,FP32だと16個分の同時演算しか行えないが,INT8であればこれが64個分の同時演算へと拡大される。実際にはメモリへのアクセスが足を引っ張るため,INT8ベースの推論処理がFP32ベースの推論処理の4倍に高速化されることはないのだが,INT8ベースの推論処理はFP32ベースの推論処理に対して約2倍の高速化が実行されていることは,Intelの示したベンチマーク結果グラフから読み取れる。
今回のデモを通して,IntelのIce Lakeは,統合型グラフィックスプロセッサが相応に優秀であること,AI推論処理が得意であること……などがおぼろげながらに見えてきた気はする。
さすがにAMDやNVIDIAのGPUを完璧に打ち負かすようなものではないにせよ,「IntelCPU単体でできること」が,改善されていることは間違いなさそうである。
こうした「グラフィックス処理の向上」「AI処理への高速化」といった性能向上は,いわゆるゲーマー向けノートPCでなはい,ごく普通のノートPCにおいても,メディア処理能力の底上げの効果を生むので,歓迎すべきポイントではある。
Ice Lake搭載製品の市場投入まではまだ少し待つ必要があるが,その日を楽しみにしたい。
今回,幸運にもその様子を取材することができたのでレポートしたい。
かなり高性能なIce Lake内蔵の第11世代統合型グラフィックス
Ice Lakeには第11世代統合型グラフィックス機能が内蔵されるが,今回のデモでは,その描画パフォーマンスがお披露目された。
まず示されたのは第9世代統合型グラフィックス(UHD Graphics 620)を内蔵したCore i7-8565U(Whiskey Lake)との性能の違いだ。どちらのプロセッサもTDPは15Wである。
テストに用いられたのは発売されたばかりのThe Creative Assembly開発のリアルタイムストラテジーゲーム「Total War: THREE KINGDOMS」のベンチマークモードだった。
結果はIce Lakeの圧勝。そのパフォーマンスの向上率は約2.0倍近くとなっていた。UHD Graphics 620のEU(Execution Units:実行ユニット)は24基,対するIce Lake側の統合型グラフィクスはEUが64基もあるため,その違いが出たことが大きいと思うが,組み合わされるメモリの速度の違いも一因となっていると見るべきか。
というのもWhiskey Lakeは組み合わされるメモリがDDR4-2400/LPDDR3-2133なのに対し,Ice LakeではDDR4-3200/LPDDR4X-3733となっているはずだからだ。ちなみに,今回のデモではCore i7-8565U(Whiskey Lake)側のメモリがDDR4-2400だったのに対し,Ice Lake側のメモリ仕様は「秘密」とのことであった。
ところで,なぜIce Lake内蔵の第11世代統合型グラフィックスと第9世代を比較しているのか疑問に思った人もいるのではないだろうか。先代と比較するならば第10世代と比較するのが筋ではないのか,と。
これについては,Intelとしてはあまり突っ込まれたくない事情がある。第10世代統合型グラフィックスは,うまく軌道に乗せられなかった初期の10nm製造プロセス製造による開発コードネーム「Cannon Lake」に内蔵されたものだからだ。ある種,第10世代統合型グラフィックスはIntelの中では欠番扱い……なのであろう。
 |
 |
 |
 |
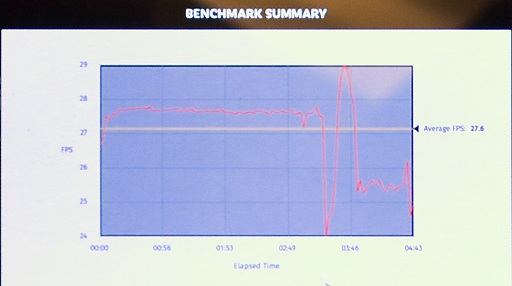 |
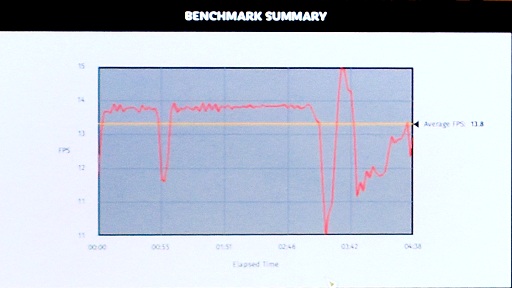
テストのあとには,この組み合わせで別のベンチマークテストを実行した結果も示されたが,Intel側の発表によればIce LakeのほうがWhiskey Lakeに対しておよそ1.5倍から2.0倍のパフォーマンスを出せているようである。
なお,実機検証こそ見せてはもらえなかったが,Intelによれば,Ice Lakeの第11世代統合型グラフィクスプロセッサは,AMDのVega 10ベースのGPUを内蔵したAPU,Ryzen 7 3700U(Zen+コアベース。12nm製造プロセス)のパフォーマンスとほぼ互角であるという分析であった。
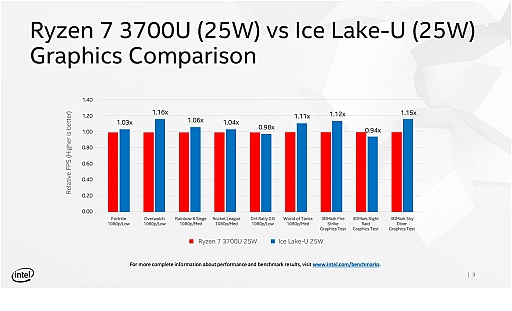 |
ちなみにRyzen 7 3700UのGPUは,Radeon RX Vega(Vega 10ベースの10CU構成)で,組み合わされるメモリはDDR-2400(最大)である。最新世代のグラフィックスを駆使したゲームをフルHD解像度で30fpsくらいでプレイすることはできそうな性能といったところだ。グラフィックス負荷が軽めの最近のeスポーツ系のゲームであればフルHDでギリギリ60fpsのプレイが可能か……といったところ。
VRSシェーディングに対応するIce Lake
グラフィックスがらみでは,Ice Lakeの第11世代統合型グラフィクスプロセッサの新フィーチャーについてのデモも行われたので触れておきたい。
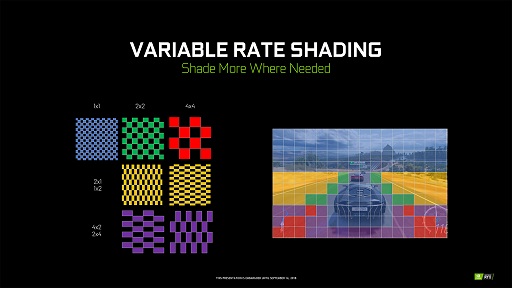
その新フィーチャーとは「Variable Rate Shading」である。
これは,これからレンダリングするフレームのシェーディング解像度(陰影計算を行う解像度)を,「特定のアルゴリズム」にて「臨機応変」「適材適所」に,ドットバイドットの1×1ピクセル(最上位)から2×2ピクセル,4×4ピクセル……といった具合に解像度を下げて実行する仕組みである。
そう,VRSとはNVIDIAがGeForce RTX/Quadro RTXシリーズで導入した新機能である。
 |
「特定のアルゴリズム」というのは「レンダリング先フレームが,どのような映像になるかをあらかじめ予測する」処理系のことである。これはGPU側で自動的には行えず,ゲームエンジンなりグラフィックスプログラマが自前でソフトウェア的に実装する必要がある。
ではどういう処理するかというと,例えば「ポリゴンの輪郭付近は高解像度で」「なだらかなグラデーションベースのテクスチャ表現主体の箇所は低解像度で」「動きの速い表現は低解像度で」「動きの遅い表現は高解像度で」といったアルゴリズムになる。
前者2つの「ポリゴンの輪郭付近は高解像度で」「なだらかなグラデーションベースのテクスチャ表現主体の箇所は低解像度で」はVRSの中でも「Content Adaptive Shading」(コンテントアダプティブシェーディング,以下 CAS)と呼ばれるものであり,「動きの速い表現は低解像度で」「動きの遅い表現は高解像度で」は「Motion Adaptive Shading」(モーションアダプティブシェーディング,以下 MAS)と呼ばれるものになる。
CASは前フレームのデプスバッファの差分値や,あらかじめ定義しておいたマテリアル/テクスチャなどの情報からVRS解像度を決定する。MASは前フレームと現在フレームとの両方で描かれることになる同一ポリゴンの移動速度をピクセル単位の速度で表したベロシティバッファの情報からVRS解像度を決定する。
これらの処理系はすべてシェーダで書かなければならないので,ではどこがハードウェアで実行されるかというと,代表ビクセルで計算した陰影情報を2×2=4ピクセルや,4×4=16ピクセルといった低解像度に相当する複数ピクセルにコピーする仕組みの部分だけである。
VRS実装! ……というと凄そうに思えるが,シェーダユニットのデータパスを組み替えただけなので,それほど実装にはコストが掛からないメカニズムなのである。VRSのための特別な演算ユニットなどは一切不要なのだ。
 |
ただ,効果のほどは絶大だ。
実機を使って行われた,第9世代統合型グラフィックス(UHD Graphics 620)を内蔵したCore i7-8565U(Whiskey Lake)マシンとのフレームレート比較ではなんと3倍ものの違いを見せつけていた。
テストに使われた2台のマシンは前出の最初のテストと同じものだ。最初のテストは生レンダリング同士の比較で2倍のパフォーマンスを見せつけていたわけだが,このVRSではさらに性能向上率を3倍にまで広げた格好である。
実際には両者のレンダリング結果は異なっているわけだが,見た目的には分からない。「だからこそ,VRSを積極的に使ったほうがいい」というのがIntel側の主張だ。
 |
 |
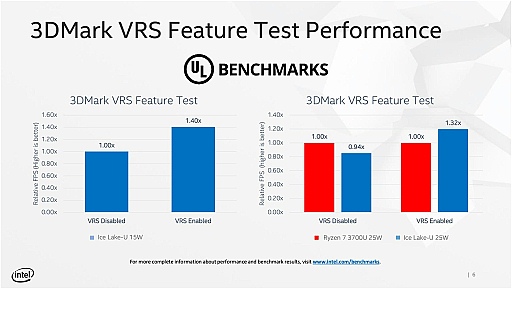
Intelの担当者によれば,業界標準3Dグラフィックスベンチマークの3DMarkには近々新テストモードとして「VRS Feature Test」が追加されるそうなのだが,そのβ版を使ったIntel側のテストでも,VRSのオフ/オンでパフォーマンスを比較すると40%ほどのスコアアップが見られたとのこと。
また,上で比較対象として挙げたRayzen 7 3700Uとパフォーマンス的には互角だったIce Lakeだが,VRSオンでは当然ながら,VRS未対応のRyzen 7 3700Uよりも高いスコアを獲得できたこともアピールしていた。
 |
Ice LakeのAI推論処理性能はRyzen 7 3700Uの7倍,Whiskey Lakeの2倍?
Ice Lakeは,AVX-512に対応し,またそれをさらに機械学習型AIの推論処理に向けた特別命令セット「DL Boost」にも対応しているわけだが,最後に,そのあたりの実効パフォーマンスがどの程度高められたかを示すデモを披露した。
用いられたのはPrincipled Technologiesが開発を進めている画像認識AIベンチマークソフトの「AIXPRT」のβ版だ。
テストに用いたマシンはこれまでと同じで,Core i7-8565U(Whiskey Lake)マシンとIce Lake搭載試作マシンの組み合わせとなる。
このAIXPRTは,もともと無数の画像データを学習済みの「画像分類AI」のResNet(Residual Network) に対し,分類対象画像を見せて,それを分類する処理速度を計測するものだ。分類が不正解か,正解かの正確性については無視しているテストで,どんなマシンを使っても何度実行しても得られる分類結果は変わらない。要はAIXPRTとは画像を認識するための推論処理速度を計測するベンチマークというわけである。
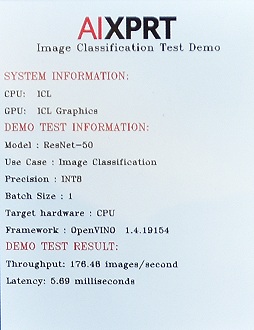
実際の実行結果はCore i7-8565U(Whiskey Lake)マシンで毎秒63枚の分類が行えたのに対し,Ice Lake搭載試作マシンではこれが毎秒176枚であった。Ice Lakeでは,Whiskey Lakeの約3倍のAI推論パフォーマンスが得られるといこうとになる。
 |
 |
ちなみに,Ice Lake搭載マシンで動作させられていたAIXPRTは,AVX-512/DL Boost最適化オプションを適用したビルドで,Whiskey Lake搭載マシンで実行させたAIXPRTはそうした最適化は外されたビルドだとのことである。詳細は不明とのことだったが,AVX2はAMD製CPUにも対応が広がっているため,推測にAVX2までは使用したビルドだと思われる。
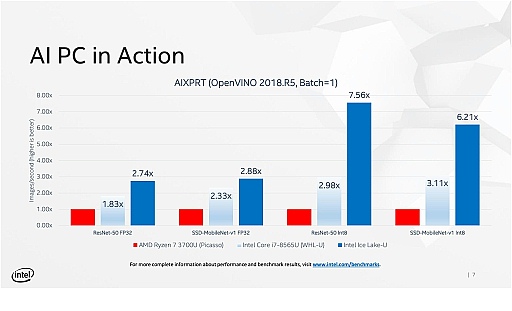
Intelが,AIXPRTのほかのテストモードで計測した結果も示されたが,推論処理を32ビット浮動小数点数(FP32)ではなく8ビット整数(INT8)で行うと,さらにパフォーマンスが増強されることなどを指摘していた。
画像処理系のAI処理は,学習時はまだしも,入力を与えて学習データをもとに推論を導出する処理系においては浮動小数点演算はややオーバースペックなので,8ビット整数に対応したDL Boostの効果は非常に大きいのだ。AVX-512は512ビット幅のSIMD演算器なので,FP32だと16個分の同時演算しか行えないが,INT8であればこれが64個分の同時演算へと拡大される。実際にはメモリへのアクセスが足を引っ張るため,INT8ベースの推論処理がFP32ベースの推論処理の4倍に高速化されることはないのだが,INT8ベースの推論処理はFP32ベースの推論処理に対して約2倍の高速化が実行されていることは,Intelの示したベンチマーク結果グラフから読み取れる。
 |
 |
さすがにAMDやNVIDIAのGPUを完璧に打ち負かすようなものではないにせよ,「IntelCPU単体でできること」が,改善されていることは間違いなさそうである。
こうした「グラフィックス処理の向上」「AI処理への高速化」といった性能向上は,いわゆるゲーマー向けノートPCでなはい,ごく普通のノートPCにおいても,メディア処理能力の底上げの効果を生むので,歓迎すべきポイントではある。
Ice Lake搭載製品の市場投入まではまだ少し待つ必要があるが,その日を楽しみにしたい。
 |
- 関連タイトル:
 第10世代Core(Ice Lake,Comet Lake)
第10世代Core(Ice Lake,Comet Lake) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー