













連載
西川善司の3DGE:GeForce RTX 30シリーズのアーキテクチャを探る。CUDA Coreの増量とRT Coreの高性能化に注目だ
 |
本稿では,GeForce RTX 30シリーズのアーキテクチャについて詳しく解説してみよう。
Ampere世代のGPUアーキテクチャを検証する
 |
Ampereは,2020年5月に登場した「GA100」が最初の製品なのだが,同GPUにはレイトレーシング向け演算ユニットである「RT Core」や,ビデオ処理プロセッサ「NVENC」を搭載しておらず,事実上,科学技術計算や人工知能開発用途などに向けた「GPGPU専用GPU」という位置づけであった。
それに対して今回発表となったGPUは,同じAmpereアーキテクチャではありながら,RT CoreやNVENCを搭載しており,なおかつシェーダプロセッサたるCUDA Core(事実上の32bit浮動小数点演算器)の数も増やしたグラフィックスカード向けのGPU製品となっている。
なお,今回発表となったGeForce RTX 30シリーズのGPUコアは,GeForce RTX 3080と最上位のGeForce RTX 3090が開発コードネーム「GA102」,GeForce RTX 3070は同様に「GA104」となっている。
 |
基本スペックは表1のとおり。
| GeForce RTX 3090 | GeForce RTX 3080 | GeForce RTX 3070 | |
|---|---|---|---|
| 開発コードネーム | GA102 | GA102 | GA104 |
| GPUアーキテクチャ | Ampere | Ampere | Ampere |
| 製造プロセス技術 | Samsung 8nm | Samsung 8nm | Samsung 8nm |
| トランジスタ数 | 280億 | 280億 | 174億 |
| ダイサイズ | 628mm2 | 628mm2 | 392mm2 |
| GPC数 | 7 | 6 | 4 |
| SM数 | 82 | 68 | 46 |
| CUDA Core数 | 10496 | 8704 | 5888 |
| TPC数 | 41 | 34 | 23 |
| RT Core数 | 82 | 68 | 46 |
| Tensor Core数 | 328 | 272 | 184 |
| テクスチャユニット数 | 328 | 272 | 184 |
| ROP数 | 112 | 96 | 64 |
| ベースクロック | 未公開 | 未公開 | 未公開 |
| ブーストクロック | 1695MHz | 1710MHz | 1725MHz |
| CUDA Core |
35.58 TFLOPS | 29.77 TFLOPS | 20.37 TFLOPS |
| Tensor Core |
142.33T |
119.07T |
81.49T |
| メモリタイプ | GDDR6X | GDDR6X | GDDR6 |
| メモリインタフェース | 384bit | 320bit | 256bit |
| メモリクロック | 19.5GHz | 19GHz | 14GHz |
| メモリバス帯域幅 | 936GB/s | 760GB/s | 448GB/s |
| メモリ容量 | 24GB | 10GB | 8GB |
GA102のトランジスタ数は,約280億で,ダイサイズは628mm2だ。5月発表のGA100は,トランジスタ数が約542億で,ダイサイズは826mm2だったので,チップサイズおよびチップの規模的には,依然としてGA100が世界最大の称号を維持したままとなる。
受託製造を行っているのはSamsungで,プロセスルールは8nmであるという。ちなみに,Samsungの8nmプロセスは,10nm LPP(Low-Power Plus)をマイナーチェンジしたものとのことだ。
Samsungのプロセスを採用した理由を,オンラインでの説明会でNVIDIA側に質問してみたが,「製造に最適な製造ファブを採用しただけだ」とはぐらかされてしまった。GPGPU向けのGA100は,TSMCの7nmプロセスで製造しているので,納期とコストのバランスでSamsungのプロセスを採用したということだろう。
さて今回は,GA102とGA104という2種類のGPUが発表となったわけだが,まずはハイエンドのGA102から見ていくとしよう。
GA102のブロックダイアグラムは,以下のようになっている。
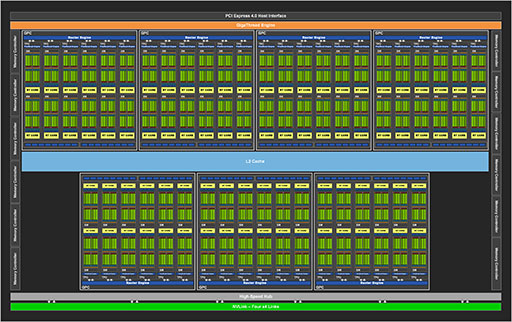 |
CPUで「コア」に相当するミニGPUクラスタ「Graphics Processor Cluster」(以下,GPC)は,見てのとおり7基ある。奇数構成は少々考えにくいので,実際は8基構成という可能性はあるのか,と思いNVIDIAに確認したところ「GPCは7基である」という答えだった。先だって発表となったGA100は,GPC 8基構成でありながら,歩留まり対策のためにGPCを1基分を無効化していたのだが,これとは異なるというわけだ。
なお,GA100では,GPU仮想化技術を効率化するために,GPCを仮想的な単体GPUとして利用できる「Multi-Instance GPU」(MIG)機能を有していたが,NVIDIAに確認したところ,GA102は同機能を搭載していないとのことだった。
さて,NVIDIAのGPUは,前出の「コア」に相当するGPCの中に,演算器であるCUDA Coreを集積してクラスタ化した「Streaming Multiprocessor」(以下,SM)を複数搭載している。NVIDIAは,SMの搭載数をGPU世代ごとに変えてくるのだが,GA100ではGPC 1基あたりSMが16基だったのに対して,GA102では12基となっている。
 |
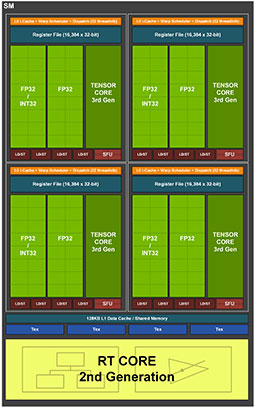 |
もともとGA100では,SM 1基あたり「INT32×64基+FP32×64基」という構成だったが,GA102では「(INT32 or FP32)×64基+FP32×64基」という構成になったという理解でいい。なお,INT32演算では,整数演算以外に論理演算や各種アドレス計算,フロー制御(GPUの場合はPredication処理,いわゆる条件付き実行制御)などを担当する。
以上を踏まえると,GA102におけるCUDA Coreの総数は,
- 7 GPC×12 SM×128 CUDA Core=10752
ということになる。
CUDA総数とSM 1基あたりのCUDA数の変遷をまとめた表2を下に示しておこう。
| 世代 | GPU名 | CUDA core総数 | SM 1基あたりのCUDA core数 |
|---|---|---|---|
| Tesla | GT200 | 240 | 8 |
| Fermi | GF100 | 512 | 32 |
| Kepler | GK104 | 1536 | 192 |
| Maxwell | GM200 | 3072 | 128 |
| Pascal | GP102 | 3840 | 128 |
| Volta | GV100 | 5120 | 64 |
| Turing | TU102 | 4608 | 64 |
| Ampere | A100 | 8192 | 64 |
| Ampere | GA102 | 10752 | 128 |
続いては,テクスチャアクセス性能を推測するのに都合のいいCUDA Core数とTPC数の関係も見ておこう。
なお,TPCとは「Texture Processing Cluster」の略で,大雑把に言えばテクスチャユニットにあたるものだ。ただ,シェーダプロセッサ(CUDA Core)が必要な各種データ――グラフィックス処理では,主にテクスチャデータ――をアクセスするときの小難しいアドレス計算や読み書きするデータの成形処理までを行ってくれる。たとえば,視線の角度に応じてアクセス対象のMIP-MAPレベルとテクスチャ座標を適宜変更しなければならない異方性テクスチャフィルタリングなどに,TPCを活用している。
というわけで,各世代のNVIDIA製GPUにおける「SM1基あたりのCUDA Core数とTPC数の関係」をまとめた表が下だ。
| GPU名 | CUDA core数 | テクスチャ |
CUDA core数: テクスチャユニット数 |
|---|---|---|---|
| Tesla GT200 | 8 | 8 | 1:1 |
| Fermi GF100 | 32 | 4 | 8:1 |
| Kepler GK104 | 192 | 16 | 12:1 |
| Maxwell GM200 | 128 | 8 | 16:1 |
| Pascal GP102 | 128 | 8 | 16:1 |
| Volta GV100 | 64 | 4 | 16:1 |
| Turing TU102 | 64 | 4 | 16:1 |
| Ampere A100 | 64 | 4 | 16:1 |
| Ampere GA102 | 128 | 4 | 32:1 |
興味深いことに,GA102ではSM 1基あたりのCUDA Core数は128基となったことで,Maxwell世代やPascal世代のバランスに戻っている。また,Maxwell以降は16:1となっていた演算能力とテクスチャ性能のバランスが,GA102では,歴代最高の演算能力重視になっているのが興味深い。
GeForce RTX 3090,3080の構成
今度は,実際にGeForce RTX 3080およびGeForce RTX 3090として発表となったGPUは,どのような構成となっているのかを見ていくことにしよう。
GeForce RTX 3080の総CUDA Core数は8704基で,GeForce RTX 3090は10496基であるが,前掲のフルチップブロックダイアグラムをよく見ると,全部で10752基のCUDA Coreがある。現時点で最上位のGeForce RTX 3090が有するCUDA Core数よりも多いわけだ。つまり,GA102の生産が安定した場合には,10752基のCUDA Coreを有効化した「SUPER」やら「Ti」モデルが登場する余地があることを意味する。
なお,GeForce RTX 3080はブロックダイアグラムが公開されていて,GPCが1基分無効化されたGPC 6基構成となっていた。さらに,GPCのうち4基分はSM数が12基の構成だが,残るGPC 2基分はSM数が10基という構成である。つまり,
- (128 CUDA Core×12 SM×4 GPC)+(128 CUDA Core
× 10 SM ×2 GPC)=8704
となるわけだ。
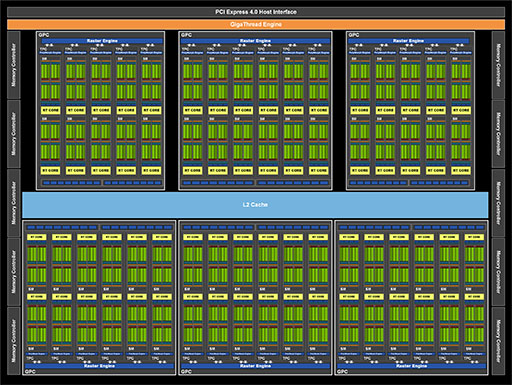 |
一方,GeForce RTX 3090の構成はどうなっているのか。NVIDIAに確認したところ,GPC 6基分はSM 12基の構成であるが,残るGPC 1基分だけはSM 10基としているそうだ。つまり以下のようになる。
- (128 CUDA Core×12 SM×6 GPC)+(128 CUDA Core×
10 SM × 1 GPC)=10496
以上を踏まえて,GeForce RTX 3080,GeForce RTX 3090の理論性能値を計算してみよう。
GeForce RTX 3080
- 8704×2 OPS×1710MHz=29.77 TFLOPS
GeForce RTX 3090
- 10496×2 OPS×1695MHz=35.58 TFLOPS
それぞれ,公称値の約30TFLOPS,約36TFLOPSに近い結果だ。
GA102が驚きの性能を実現した直接の要因は,いうまでもなく8nmプロセスルールの採用にともなうCUDA Core数の増量に他ならない。なお,意外なことに,GeForce RTX 30シリーズの動作クロックはブーストクロックで約1.7GHz前後と,12nmプロセス世代のGeForce RTX 20シリーズと比べて,あまり大きな変化はない。
さて,前述したようなフルスペック版GA102を使ったSUPERモデルが出るとしたら,どのようなものになるのか。Turing世代の場合,TU100系チップの製造が安定したあとで登場したRTX 20 SUPERシリーズでは,動作クロックが約10%向上していた。これを取り入れると,
- 10752×2 OPS×1850MHz=39.78 TFLOPS
となり,約40TFLOPSが見えてくることになる。もちろん,実際にそうした製品が登場するかは分からないが,ゲームグラフィックス向け単体GPUが,ついに40TFLOPSの大台に到達するというのは感慨深い。
GeForce RTX 3070の構成を推測してみる
 |
GA104のブロックダイアグラムは公開されておらず,構成を推測できる情報として以下の項目が明らかになっている。
- 総CUDA数は5888
- GPCは4基
SM内部の構成はGA102と同じなので,GA104のフルチップ仕様は以下のようになると計算できる。
- 128 CUDA Core×12 SM×4 GPC=6144
つまりGeForce RTX 3070も,歩留まり対策としてGPC内のSMを2基分(=CUDA Core 256基分)無効化している製品ということだ。
4基のGPCから5888基のCUDA Coreを有効化する組み合わせとしては,GPCの1基からSMを2基無効化するパターンと,GPC 2基からそれぞれSM 1基分を無効化するパターンが考えられよう。
GPC 1基からSM 2基を無効化するパターン
- (128 CUDA Core×12 SM×3 GPC)+(128 CUDA Core×10 SM×1 GPC)=5888
GPC 2基からSM 1基ずつを無効化するパターン
- (128 CUDA Core×12 SM×2 GPC)+(128 CUDA Core×11 SM×2 GPC)=5888
いずれにせよ,GeForce RTX 3070にも6144基のCUDA Coreを有効化したSUPERやらTiやらが登場する可能性はあると考えられる。
さて,そんなGeForce RTX 3070の理論性能値だが,
- 5888×2 OPS×1725MHz=20.31 TFLOPS
となり,こちらも公称値の約20TFLOPSと一致する。もし,近い将来にフルSM版×動作クロック10%向上が出るとしたら,こんな感じだろうか。
- 6144×2 OPS×1900MHz=23.35 TFLOPS
となる。値としてはなかなかリアルだ(笑)。
AmpereのSMをもう少し細かく見てみる
|
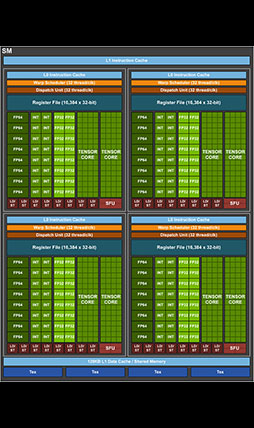
なお,SMのブロック図は現物とは違なる部分があるので,説明が必要だろう。
先述したように,GA102(およびGA104)のSMには,演算ユニットたるCUDA Coreが128基詰め込まれているが,その半分である64基のCUDA Coreは,32bit浮動小数点(FP32)演算器としてだけでなく,排他的に32bit整数(INT32)演算器として機能する能力が与えられている。
一方,ブロック図を見た範囲では倍精度浮動小数点(FP64)の演算器は見当たらないが,これはTuringと同様で単純な記載漏れ,あるいは省略のはずだ。実際には,SM 1基あたり2基のFP64演算器を実装している。
GPGPU用ではないGeForceブランドのGPUは,一部の例外を除いてFP64の演算性能は,
- FP32演算性能:FP64演算性能=32:1
という比率だった。それが今回,FP32演算器が倍増したため,GA102では,
- FP32演算性能:FP64演算性能=64:1
という比率となった。
NVIDIAによると,GeForceブランドへのFP64演算器搭載は,事実上「FP64 Tensor コードを含むすべてのFP64命令への互換性を保つため」であるため,ここで特段に高性能を謳ってはいない。
グラフィックスメモリとの読み書きを司る「ロード/ストア」(LD/ST)ユニットや,三角関数や指数関数を処理する「超越関数」(SFU)ユニットの構成は,Turing世代から変更はない。SM 1基あたりの数も同じだ。
Turing世代と比較したときに目に付く変更点は,L1キャッシュの容量拡大だろうか。Turingアーキテクチャの場合,L1キャッシュは,共有メモリと兼用仕様になっていて,総容量は96KBだった。また,L1キャッシュと共有メモリの構成は64KB+32KBか,32KB+64KBの二択でとなる。これがGA102では128KBへと拡大したことで,L1キャッシュと共有メモリの構成パターンは64KB+64KBか96KB+32KBの組み合わせが選択できるようになった。
ただ,GPGPU専用のGA100では,L1キャッシュが164KB(160KB+4KB,4KBは後述するAsync Copyの補助用)となっていたので,GA102はGA100よりも,むしろGPGPU専用だったVolta世代「GV100」の構成に近い。
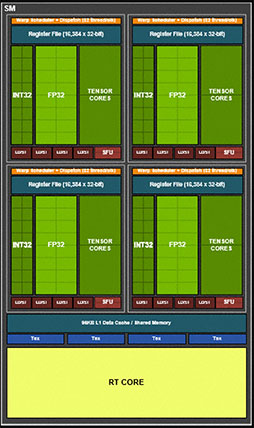 |
 |
今回の発表イベントや,その後に行われた報道関係者向け説明会で,NVIDIA側が言及することはなかったが,Ampere世代のGA100登場と同時に発表となった「CUDA11」に,GA102は当然対応する。ゆえに,CUDA11の目玉新機能である「Asynchronous Copy」(非同期コピー,以下 Async Copy)にも対応するわけだ。
非同期(Async)のコピー(Copy)とは,あるデータセットが処理中であっても,その処理終了を待つことなくGPU側がGPGPU処理系に対して,次に流し込むべきデータセットの準備を行える機能である。詳細の説明は割愛するので,興味のある人は,GA100の解説記事を参照してほしい。
RTX IOはDirectStorageのアクセラレーションレイヤに相当
さて,このAsync Copyと関係の深い新機能が,GeForce RTX 30シリーズの発表とともにアナウンスされた。それが「RTX IO」だ。
結論から述べてしまうと,RTX IOは,MicrosoftがGeForce RTX 30シリーズ発表のタイミングで発表したDirectXの新機能「DirectStorage」(関連リンク)と関係が深い機能だ。端的に言えば,「MicrosoftのDirectStorageをGPUでアクセラレーションする仕組みが,RTX IOである」という理解でいい。
RTX IOを理解するためには,大前提となる「DirectStorageとは何か」に触れておかねばなるまい。
2020年末には,次世代ゲーム機として「PlayStation 5」と「Xbox Series X」が発売となるが,「SSDから圧縮されたままのデータを読み出して,専用チップで展開したうえで,転送先のアドレス空間にDMA転送する仕組み」を実現するユニークなストレージシステムを,両製品ともが申し合わせたように採用したことを知っている人も多いかと思う。DirectStorageは,まさにこれのPC版(DirectX版と言うべきか)だ。
DirectStorageにおいて,「圧縮データを専用チップで展開」の部分をどう処理するかについては,PCのハードウェア仕様に委ねられている。つまり,展開処理はCPU処理で行ってもいいし,GPGPUで行ってもいいし,次世代ゲーム機のように専用プロセッサで行ってもいい。
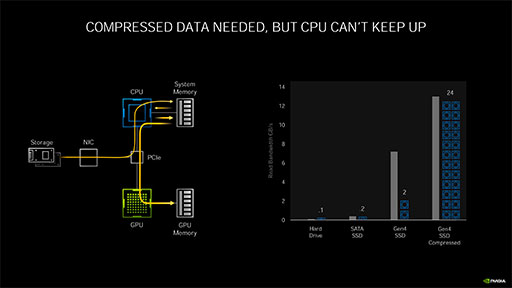
次のスライドは,DirectStorageをCPUベースで実装したときのパイプライン図だ。ストレージからデータがSystem Memory(メインメモリ)に読み込まれ,そのデータをCPUがアクセスしてメインメモリ上で展開したうえで,GPU Memory(グラフィックスメモリ)に転送している。
図の右側にあるグラフのようなものは,「もしデータが圧縮されていたら,その展開を高速に行うために,24コア分のCPUを使う必要だってあるかもしれない」という概念を示したものだ。ただ,必ずしもこうなるというわけではない。要はNVIDIAお馴染みの「CPUディスり芸」であるが,あながち的外れというわけでもない。
 |
このDirectStorageに対して,NVIDIAは,GeForce RTX 30シリーズにおいて,GPGPUで処理するソリューションを選択した。それがRTX IOというわけである。
次のスライドは,DirectStorageをGA102で実装したときのパイプライン図だ。ストレージから直接GPUに圧縮データが転送され,オンザフライで展開したうえでGPUメモリに伝送する。圧縮データの展開はGPGPUで行うわけだ。スライド右に「Asynchronously Scheduled」(非同期スケジューリング)の記述にも注目してほしい。
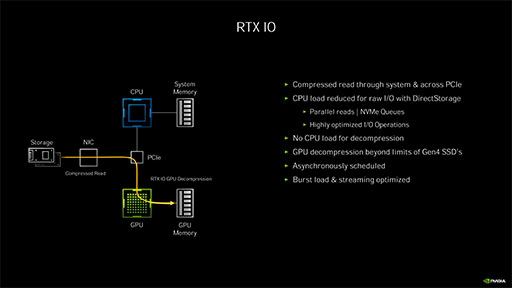 |
なお,NVIDIAによれば,RTX IOはAmpere世代GPUだけの機能ではなく,Turing世代以降のGPUで利用可能だという。ただ,ストレージから読み出された圧縮データを逐次GPUへ転送するストリーミング転送で,Ampere世代のGPUであれば,Async Copyが利用できる。
Async Copyでは,
- 前段のGPGPU処理が終わるのを待つことなく,非同期に次のGPGPU処理を開始できる
- キャッシュバイパス制御/ライトバックキャンセル制御
といった機能が利用できるので,既存のGeForceと比べて,GA102世代はDirectStorageの実効パフォーマンスで優れるはずだ。
進化したレイトレーシングユニット
「GeForce RTX 30シリーズでは,ハードウェアレイトレーシング機能を司るRT Coreの性能が劇的に向上した」とNVIDIAは猛烈にアピールしている。
とはいえ,まだまだレイトレーシングの概念は,ゲーマーの間に十分浸透したとは言い難いので,本稿でも軽くおさらいしておこう。
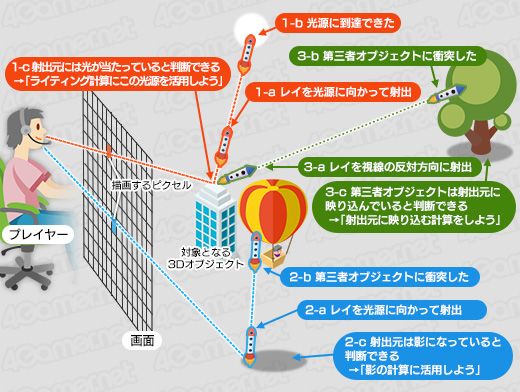
レイトレーシングとは,あるピクセルの色を計算するとき,そのピクセルが受け取っているはずの光の情報を得るために,光線(ray,レイ)を射出してたどる(trace)処理のことを指す。
光線の射出方向と角度は,得たい情報の種類によって決まる。たとえば,ピクセル(に対応するオブジェクト面)から光線を射出して,その光線が近くの光源に到達するなら,ピクセルはその光源に照らされていることが分かる(図の1-a〜1-c)。
一方,光源に達する前にほかの3Dオブジェクトと衝突すれば,そのピクセルは3Dオブジェクトの影になっていることが分かる(図の2-a〜2-c)。さらに,当該ピクセルを見つめるユーザーの視線が3Dオブジェクトに反射した方向に光線を射出して,それがさらにほかの3Dオブジェクトに衝突したとしたら,そのピクセルには「衝突した3Dオブジェクトが映り込んでいる」と判断できる
(図の3-a〜3-c,関連記事)。
 |
RT Coreが担当するのは,レイトレーシングにおける光線の生成処理と,光線を動かす「トラバース」(Traverse,横断)処理,そして衝突判定を行う「インターセクション」(Ray-Triangle Intersection,交差)判定である。
先述したとおり,5月に発表となったGPGPU専用の「GA100」は,RT Coreを搭載していないとNVIDIAは公言していたが,今回のGA102やGA104は,ちゃんと搭載しているわけだ。GA102とGA104のRT Core数は,SM 1基あたり1基なので,GeForce RTX 3090,3080,3070のRT Core数は,それぞれSMの数と同じ82基,68基,46基となる。
今のところNVIDIAは,GeForce RTX 30系RT Coreの性能公称値における目安として,「GeForce RTX 3080(GA102)の三角形との交差判定レートは,GeForce RTX 2080 SUPER(TU102)の2倍になった」と明らかにしている。ここで言う「2倍」の意味は簡単だ。GA102(およびGA104)のRT Coreが備える三角形との交差判定ユニットはデュアルパイプライン構造となっているので,並列処理できるようになったことが大きな要因だ。
なお,一部のメディアで「三角形との交差判定がモーションブラーに対応したために性能が向上した」という記述も見られたが,これは間違いである。
順を追ってこのあたりを解説しよう。
現代的なレイトレーシング技術では,三角形の交差判定を高効率に検出するために,「Bounding Volume Hierarchy」(以下,BVH)と呼ばれる構造で3Dオブジェクトを管理している。BVHとは,その3Dモデル全体を覆うことができる最小体積の直方体(BOX)のことだ。この直方体は,3D座標軸に平行,垂直な向きに揃えられた「Axis Aligned Bounding Box」(以下,AABB)構造になっており,こうした構造体を「Acceleration Structure」(以下,AS)と呼ぶ。
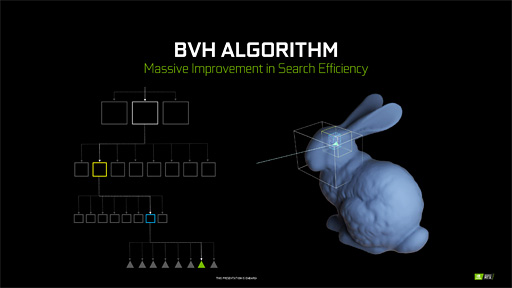 |
さて,次のスライドは,RT Coreのブロックダイアグラムで,左がTuring世代,右がAmpere世代のRT Coreを示す。
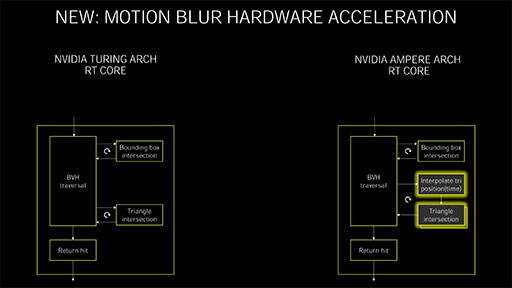 |
RT Coreでは,「BVH Traversal」で「レイの生成」と「レイの推進」処理を担当する。レイの推進処理は事実上,リスト構造への探索のようなものだ。そして,推進したレイとAABBとの衝突判定を行うのが,パイプラインの上段にある「Bounding box intersection」ユニットだ。
最下層のAABBと衝突したときに呼び出されるのが「Triangle intersection」で,ここで三角形との衝突判定を行う。ここはシンプルではあるが幾何学的な計算を行う。
左側にあるTuring世代のRT Coreは,Triangle Intersectionが1つだけだが,スライドをクリックしてよく見ると,Ampere世代のRT Coreではここが2つ重なっているのが分かるだろう。そう,これが「三角形との衝突判定」パイプラインの並列化を意味している。これにより,2つのパイプラインが個別にレイと三角形の衝突判定を計算できるので,Turing世代のRT Coreに対して2倍の性能があるというわけだ。
注目すべき点はもう1つある。Ampere世代のRT Coreをよく見ると,中央付近に「Interpolate tri position(Time)」というユニットが新設されていることが見て取れよう。これは,「投射したレイと三角形の衝突」を計算するときに,「特例事項を容認,介入させるユニット」になる。
何を容認するかというと,イメージ的には「レイとの当たり判定をゆるくすること」だ。たとえば,衝突対象の三角形に「運動(移動)している属性」が付けられているとき,Interpolate tri position(Time)ユニットは,その三角形の速度パラメータから逆算で(投射計算して)過去の位置(あるいは未来の位置)を算出する。これにより,後段のTriangle intersectionで,衝突判定がゆるくなった三角形との衝突も取れるようになった。
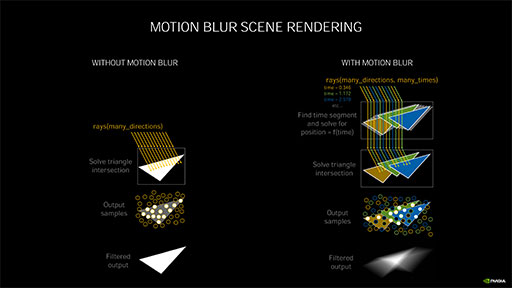 |
なぜ当たり判定をゆるくする必要があるのかと言うと,現実世界とは違い,現在のレイトレーシングでは,3Dシーン(正確にはBVH構造体)へ投げられるレイの数が有限で,高速移動体とレイの衝突判定をミスする場合があるためだ。しかし,衝突判定をゆるくする補間ユニットがあれば,今までは衝突をミスしていたかもしれない三角形と,正しく衝突を判定できるようになるのだ。
「衝突判定をゆるくして三角形との衝突を判定することに,何のメリットがあるのか?」と疑問を持つ人もいるだろう。たとえば,現在のレイに対して,1秒前にそこに存在した移動体の三角形との衝突が取れたとする。その三角形は,現在にはその場所に存在しないのだから,それは残像というわけだ。残像というのは「うっすら見えるモノ」である。であれば,その三角形をライティング,シェーディングしたうえで,うっすらと描いてやればモーションブラーのできあがり。そんなイメージでいいだろう。
結果として,Interpolate tri position(Time)ユニットのおかけで,Turing世代のRT Coreでは衝突を判定できなかったかもしれない移動体の描画品質を上げられることが期待できるわけである。
 |
「だったら,ゲームでは3Dオブジェクトが動くし,これでレイトレを使ったゲームグラフィックスも加速しそうだね」と期待されそうだが,今のところはそうなりそうにない。というのも,Interpolate tri position(Time)ユニットを,現在のDirectX Raytracingから使う手段がないからだ。Interpolate tri position(Time)ユニットは,NVIDIAがオフラインレンダリング向けのレイトレーシングエンジンフレームワークとして提供している「OptiX」から使うことになる。
OptiXでは,移動体として「Motion acceleration structure」が定義できるので,Interpolate tri position(Time)ユニットは,こうしたオブジェクトに対するレイトレーシングに有効ということなのだろう。
Tensor CoreはGA100のものとよく似ている
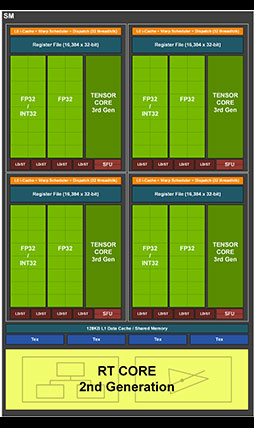
次に,AmpereにおけるAIアクセラレーション,具体的には推論アクセラレータ「Tensor Core」について見ていくことにしよう。
 |
|
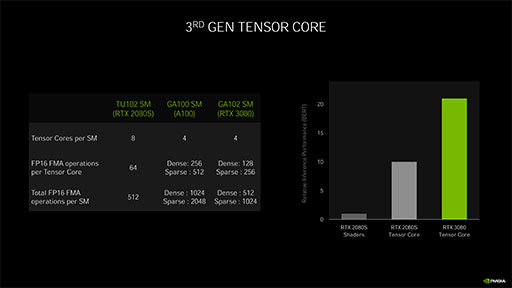
GA102(およびGA104)のTensor Coreは,SM 1基あたり4基あるので,総数はSMの個数×4倍となる。Turing世代はSM 1基あたりTensor Coreは8基だったので,数は減少しているように思える。しかし実際の演算性能は,Turing世代のそれを上回る。
その理由をシンプルに答えれば,「GA102はAmpere世代GPUなので,Tensor Coreは,GPGPU専用であるGA100のアーキテクチャを継承した新世代のものだから」ということになる。
Turingが搭載していた第2世代Tensor Coreでは,Tensor Core 1基あたり16bit半精度浮動小数点(FP16)数の積和算(FMA,Fused Multiply-Add)を1クロックに64並列で演算できた。GPGPU専用のGA100では,これを4倍に高めた256並列で演算できたのだが,グラフィックス描画用のGA102では,これよりも控えめの128並列で演算できる。
 |
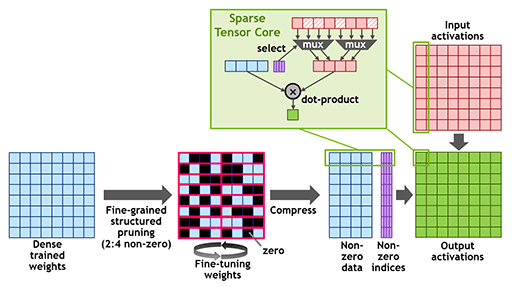
並列度はGA100に対して控えめとなったGA102だが,Tensor Coreの機能自体はGA100とまったく同等で,Turing世代のTensor Coreにはなかった「疎行列」(Sparse Matrix)に対応したのが大きなトピックだ。詳細はGA100の解説を参照してほしいが,簡単に説明しておこう。
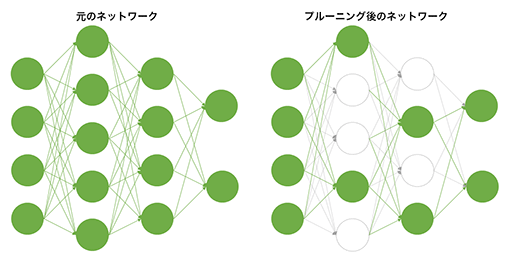
疎行列とは,スパース行列とも呼ばれるもので,行列の要素にゼロが多く含まれるものだ。ゼロに対する積算はゼロになるので,ゼロの加減算は演算を行うこと自体が無意味となる。こうした演算に対する最適化を施したのが,Ampere世代のTensor Coreというわけだ。
この疎行列は,機械学習や深層学習においてよく登場する。多層のニューラルネットワークにおいて,対象とする学習テーマによっては,特定のノード間における接続が不要であると分かった場合に,そのノード接続を無効化しても問題ない場合が多い。これを「枝刈り」(Pruning,プルーニング)と呼ぶが,プルーニングを行ったニューラルネットワークでの畳み込み演算には,疎行列が頻繁に登場するのだ。
 |
Ampere世代のTensor Coreは,疎行列に対する演算性能が通常行列に対するのと比べて2倍となっており,この特徴はGA102も同様である。
 |
 |
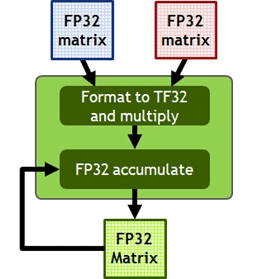 |
まず大前提となるGeForce RTX 3090,3080,3070のTensor Core数だが,総SM数の4倍に相当する328基,272基,184基である。
Tensor Coreの新旧比較スライドにある「FP16 FMA operations per Tensor Core」の項目を見ると,GA102は「Dense:128」並列とあるので,計算式は簡単に求められる。なお,FMAは積和算なので2 FLOPSだ。
GeForce RTX 3090
- 328基×1695MHz×128並列×2 FLOPS=142.33T TensorFLOPS
GeForce RTX 3080
- 272基×1710MHz×128並列×2 FLOPS=119.07T TensorFLOPS
GeForce RTX 3070
- 184基×1725MHz×128並列×2 FLOPS=81.25T TensorFLOPS
ちなみに,NVIDIAの公称値は,きっちり上記の値の2倍になっているが,公称値は疎行列(Sparse)の理論性能値を示しているためだ。Turing世代のTensor Coreとの性能値を比較する資料でもこの手口を使っているのは,ちょっとずるいと思う(笑)。
 |
 |
今後,4GamerでAmpereのTensor TFLOPSを示す場合,NVIDIA公称値を扱うかもしれないが,さすがにTuring世代と性能を比較すべきタイミングでは,同条件での比較が妥当であろう。そのため,今回は筆者による同条件の計算値を示しているわけだ。
GA102のメモリ周りと消費電力
GPGPU専用GPUのGA100は,グラフィックスメモリとして「HBM2」を採用していたが,グラフィックスレンダリング用のGA102やGA104では,HBM2の採用は見送った。その代わりに,上位のGA102では,HBM2のメモリバス帯域幅に迫る新メモリ技術「GDDR6X」を採用している。
GeForce RTX 3090と3080のメモリ帯域は,以下のように計算できる。
GeForce RTX 3090
- 384bit×19.5GHz÷8bit=936GB/s
GeForce RTX 3080
- 320bit×19GHz÷8bit=760GB/s
一方,GA104はGDDR6(関連記事)のままだ。
GeForce RTX 3070
- 256bit×14GHz÷8bit=448GB/s
それにしても,HBM系のメモリバス帯域幅である1TB/sに迫る帯域幅を,GDDR系の技術で実現したことは,実に感慨深い。
ところでGDDR6Xは,シンプルに同クロック駆動でGDDR6の2倍というメモリバス帯域幅を実現している。これがHBM2に迫る帯域を実現したポイントだ。
GDDR6Xのメモリバス帯域幅を実現する技術が,下のスライドにある「PAM4」(4Level Pulse Amplitude Modulation),「Max Transition Avoidance Coding」(以下,MTA),「NEW ALGORITHMS」(新しいアルゴリズム)だ。
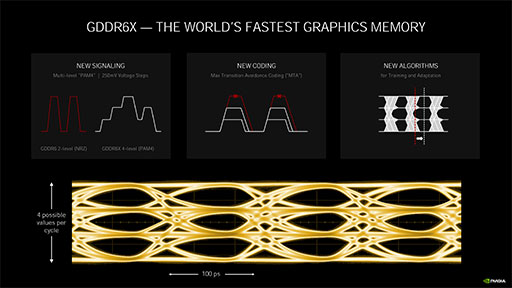 |
GDDR6XがGDDR6の2倍の帯域を実現する最も重要な技術が,PAM4の採用である。
GDDR6では,データを表現する0と1の電気信号を,電圧の高い低いの2値で表現する信号形式を使っていた。といっても,高速データ伝送で電圧の乱高下は望ましくないので,「非ゼロ復帰」(NRZ,Non Return to Zero)方式を採用していた。
GDDR6Xでは,データ表現を4段階の電圧で表現する「4段階パルス振幅変調」(=PAM4)を採用したのだ。同じ時間内に,2倍のビット情報が送れるので,同クロック駆動時にGDDR6の2倍という帯域幅を実現できるわけである。
PAM4におけるエラーを抑制するために実装したのがMTAだ。MTAを意訳するなら,「最大振幅回避符号化技術」といったところだろうか。
PAM4において,最も誤送信(エラー)が起きやすいのは,電圧の高低差が大きい表現のときだ。たとえば電圧レベル0,1,2,3の4段階で,それぞれ00,01,10,11の4状態を表現する場合,電圧が0から3に上がるときと,電圧3から0に下がるときは高低差が大きくなる。電圧の高低制御は瞬間的には行えず,高低差が大きいときほど時間がかかってしまう。そこで,その時点の電圧状態を新たな基準電圧として,電圧の高低差が最大になってしまう状態変化を避けるような符号割り当てを実現するのがMTAだ。
NEW ALGORITHMSは,とくに名前が付いていないのだが,これも要はPAM4のエラーを抑制する技術である。具体的には,伝送されてきた電気信号の読み出しタイミングを,GPUの温度条件や,そのタイミングでの電気信号における電圧基準状態を考慮して動的に調整する技術,という理解でいい。
最後に,消費電力周りの話題で締めくくろう。
GA102およびGA104のGPUコアは,動作クロックだけでなく,供給電力を回路種別で分ける設計を導入した。具体的には,演算ユニットなどのグラフィックスコアと,キャッシュやメモリインタフェースなどのメモリ周りで分けているという。これにより,消費電力と,発熱量をこれまで以上に最適化することができたそうだ。
その甲斐あって,Ampere世代のGA102とGA104は,Turing世代と比べて消費電力あたりの性能が1.9倍も向上したとNVIDIAはアピールしている。
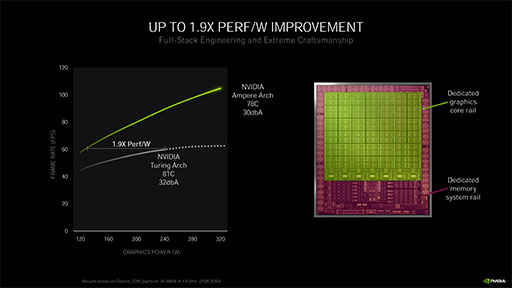 |
ここで興味深いのは,NVIDIAが決して「消費電力を抑えつつ高性能」ということだけをアピールしているのではなく,「たとえ高い消費電力状態になっても,冷却ファンのノイズが静かである」という点をアピールしていることだ。最高性能を追求するNVIDIAのハイエンドGPUらしいメッセージと言えようか(笑)。
ちなみに,こうした特性はオーバークロックの余裕があることを,間接的に訴えていることになる。
 |
GeForce RTX 30シリーズではほかにも,NVLINKや遅延低減技術「NVIDIA Reflex」,HDMI 2.1,その他のソフトウェア関連機能も盛り込まれている。それらについては,回を改めてフォローすることにしたい。
NVIDIAのGeForce RTX 30シリーズ情報ページ
- 関連タイトル:
 GeForce RTX 30
GeForce RTX 30
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー