



![[CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」](/games/000/G000000/20120823055/TN/019.jpg)




イベント
[CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」
![画像ギャラリー No.001のサムネイル画像 / [CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」](/games/000/G000000/20120823055/TN/001.jpg) |
昨今ではプログラマブルシェーダ技術の発展により,多くの物質の表面状態をかなり正確に描画できるようになってきているのだが,ゲームグラフィックスに代表されるリアルタイム3Dグラフィックスで,いまなお正確な表現が難しい要素に「毛髪」や「毛皮」がある。
人間の頭髪表現は,テクニカルデモのレベルであれば,NVIDIAのデモやスクウェア・エニックスの「Agni's Philosophy」のように,長い髪の毛をラインで生やしてジオメトリシェーダで増毛するようなアプローチなどが考案されており,今後,いっそうの発展が期待されている。
一方,毛皮表現のほうは,昆虫や動物……それこそゲームならばモンスターなどのモワっと密集した短毛表現がしばしば用いられるようになっており,現世代ゲームにおいては比較的実用化が進んでいるテクニックだ。
今回,早稲田大学の研究グループが開発した技術は,後者に関連するものになる。なお,この技術論文は,SIGGRAPH 2012においても採択されたもので,ある意味,まだ世に発表されたから間もない新しいテクニックの解説となる。
Shell法による毛皮表現とは?
![画像ギャラリー No.002のサムネイル画像 / [CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」](/games/000/G000000/20120823055/TN/002.jpg) |
過去の関連研究の詳細はこちらなどを参考にしてほしいが,これは毛皮を断面テクスチャとしてデータ化し,レンダリング時にはこのテクスチャを積層させて描画することで表現するテクニックになる。ある種,簡易的なボリュームレンダリングの一種ということができるかもしれない。
![画像ギャラリー No.003のサムネイル画像 / [CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」](/games/000/G000000/20120823055/TN/003.jpg) |
![画像ギャラリー No.004のサムネイル画像 / [CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」](/games/000/G000000/20120823055/TN/004.jpg) |
![画像ギャラリー No.005のサムネイル画像 / [CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」](/games/000/G000000/20120823055/TN/005.jpg) |
このテクニックは,既存の3Dモデルに対してスケーラブルに毛皮を実装できるというメリットがある。例えば,視点に近い位置の3Dモデルは大写しになるので多層で描画し,視点から遠い位置の3Dモデルは積層数を削減するといった処理が簡単に実装できる。
PS3,Xbox 360のような現世代機では,「3Dモデルのどの表皮に積層させるか」という部分で,事前にジオメトリレベルでのモデルリングが必要だが,自在にポリゴンの生成や消失が可能なジオメトリシェーダが利用できることになるはずの次世代機では,事前準備なしに積層型の毛皮生成手法が利用できるはずだ。
![画像ギャラリー No.006のサムネイル画像 / [CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」](/games/000/G000000/20120823055/TN/006.jpg) |
「積層している毛皮の断面」というのは直接見ることができない画像である。実物の毛皮を参考にしても,毛先の層だけだとどんなテクスチャになるのかと言われて絵の描ける人はまずいないだろう。まして,中間層となると試行錯誤を重ねてそれらしいものを作っていくほかない。
密度や毛質を設定して,パラメトリックに毛皮断面テクスチャを生成するツールを開発する……というアイデアも思いつくが,希望する毛皮状態を作れるようになるにはそれなりの熟成が必要になるだろう。
Shell法に用いる毛皮断面テクスチャを
プロシージャル生成する方法
これに対して,今回の早稲田大学の研究グループが開発した手法は,かなり大胆かつシンプルな手法になる。
![画像ギャラリー No.009のサムネイル画像 / [CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」](/games/000/G000000/20120823055/TN/009.jpg) |
用意するのは,「どんな毛皮にしたいか」の例として,あらかじめ撮影しておいた毛皮の写真1枚でいいのだ。
これを“ネタ・テクスチャ”としてシステムに入力してやると,この写真を解析して,自動的にShell法のファーシェーダで用いる毛皮の断面テクスチャを,任意の積層数で生成してくれるのである。毛皮写真を種にした「プロシージャルテクスチャ生成手法」といっていいかもしれない。
![画像ギャラリー No.010のサムネイル画像 / [CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」](/games/000/G000000/20120823055/TN/010.jpg) |
早稲田大学で開発されたシステムでは,毛皮を散乱媒質と見なし,毛皮の写真に生じた明暗は奥行き方向の指数関数的な輝度減衰によるものだと仮定している。この仮定に基づけば,毛皮の写真から,見えている毛までの深度情報が推測できることになる。
つまり,1枚の毛皮写真をもとに,直上から見た深度分布を推測するわけだ
![画像ギャラリー No.011のサムネイル画像 / [CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」](/games/000/G000000/20120823055/TN/011.jpg) |
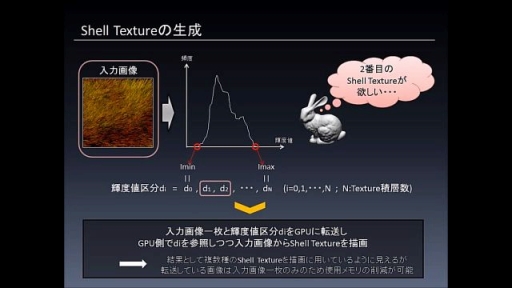
推測された深度情報分布をもとに,実際にほしい毛皮断面テクスチャの枚数分だけ横からスライスして,毛髪との交叉点のところにドットを打つようなアルゴリズムで毛皮断面テクスチャを生成している。
深度情報分布を指定枚数でスライスするためには,深度情報分布の最大値と最小値が必要になるが,これは入力写真の輝度のヒストグラムから算出できるので,実行時,あるいは事前に求めればよい。
![画像ギャラリー No.012のサムネイル画像 / [CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」](/games/000/G000000/20120823055/TN/012.jpg) |
また,毛皮の表現の精度は入力写真の解像度のみに依存しており,レンダリングしようとしている3Dグラフィックス解像度や積層させたい毛皮断面テクスチャ枚数に対して,最良の解像度の毛皮を描画させることができる。やはり,この手法はプロシージャルテクスチャ生成技法なのである。

課題もあるが
応用範囲が広そうなプロシージャルテクスチャ生成技術
発表の最後には,実際にこの手法でリアルタイムにレンダリングしたデモが示された。
かなり入力写真に近いイメージのモワモワとした毛皮表現ができていることが分かるだろう。


![画像ギャラリー No.014のサムネイル画像 / [CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」](/games/000/G000000/20120823055/TN/014.jpg) |
今回発表されたテクニックは,プロシージャルテクスチャ技術なので,入力写真に用いるのは別に毛皮でなくてもいい。明暗差のある写真ならばなんでもいいので,発表では,「芝生」の写真を入力しての作例も公開された。

![画像ギャラリー No.017のサムネイル画像 / [CEDEC 2012]毛皮表現用プロシージャルテクスチャ生成技法はモフモフウサギの夢を見るか? 「実写画像を用いたShell Texture自動生成手法」](/games/000/G000000/20120823055/TN/017.jpg) |
さらに,今回のシステムはすべてランタイム状でリアルタイムで処理できるため,入力写真自体を時間方向に入れ替えていくことも可能だ。すなわち,入力するのは動画でもいいことになる。
そこで,デモンストレーションでは,水が流れ落ちる滝の動画を,今回のシステムに入力させてレンダリングさせる作例も示された。
毛皮とは違って,こちらは微細な凹凸が動く感じになるので,ドット単位の水しぶきの質感が伝わってきて興味深い(輝度と上下関係の条件が毛皮とは違うので前後関係は多少怪しい?)。とにかく,こういったものは形状としてモデリングしづらく,なおかつノイジーで微細な凹凸表現を含んでいる。それをフェイクではない正確なジオメトリ表現で再現できそうな手法としても,この研究は画期的といえるのではないだろうか。

ただ,課題も残されているようで,実際にジオメトリレベルでの凹凸に復元してしまう特性上,入力写真の境界線がレンダリング時に顕在化してしまっている。シームレステクスチャ化の処理などは必須となるだろう。
また,個人的に感じたのは,入力写真はあくまで写真であり,表層しか捉えていないことからか,埋もれていて上から見えない下層の毛が密度不足になっているように感じられた。ここは,入力写真から毛の密度を推測したり,あるいは密度パラメータを与えてプロシージャルに埋もれて遮蔽されている下層の毛を生成すると面白いかもしれない。いずれにせよ,今後の発展が楽しみな研究である。
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー