









テストレポート
Phenom徹底分析(中):B2ステッピングのエラッタで何が起こるのか
というわけで,Phenom検証記事の中編である。テスト環境は前編から変わっておらず,また,グラフや表の番号も,前編の続きとなっているので,まだ前編を読んでいない人は,まずそちらを読んでから戻ってきてほしい。
→前編:ネイティブクアッドコアに意味はないのか?
→後編:動作クロックはなぜ上がらないのか
前編でキャッシュについて長々述べてきたが,そこでも軽く触れたとおり,この複雑なキャッシュ構成が例のErrata(エラッタ)問題に深く関わっている。Errataに関してあまり深く説明されている日本語記事がないためか,やや誤解したような記述も方々で見かけるので,ここで説明を試みることにしたい。ただ,非常に込み入った話なので,その点はご承知おきを。
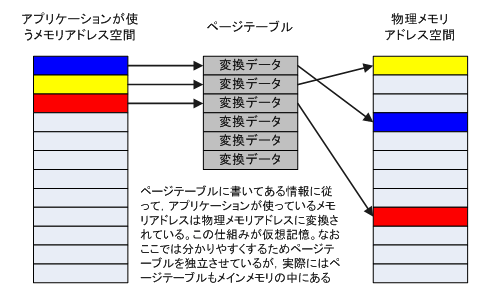
さて,現在のCPUはすべて仮想記憶という方法を使ってメモリを管理している。物理メモリを4KB単位の「ページ」で分割し,必要に応じてアプリケーションに割り当てる,という方法を使っているのだ。アプリケーションソフトがアクセスするメモリアドレスは,ページテーブルというアドレス変換テーブルを通して実際のアドレス「物理アドレス」に変換されている(図2)。
ページテーブルはメインメモリにあるが,先に述べたようにメインメモリはとても遅い。アドレス変換にいちいちメインメモリのページテーブルを参照していたら遅くてどうしようもないわけで,昨今のCPUは,ページテーブルの一部を取り込んでおき高速に変換する仕組み「Translation Lookaside Buffer」(TLB)を持っている。「いまアクセスされている周辺」のメモリアドレスの変換テーブルをTLBに読み込んでおき,TLBを使って高速にメモリアドレス変換を行っているわけだ。
TLBに記憶できるテーブル数はCPUの種類によって異なる。Phenomに関しては正確なデータがないため分からないのだが,Athlon 64ファミリーと同じとすれば,1024個程度の変換データを保持できる程度だろう。なお,TLBとキャッシュを混同している人もいるようだが,TLBとキャッシュは厳密には異なる。x86系CPUの大半において,TLBはL2キャッシュよりもCPUに近いところにある。
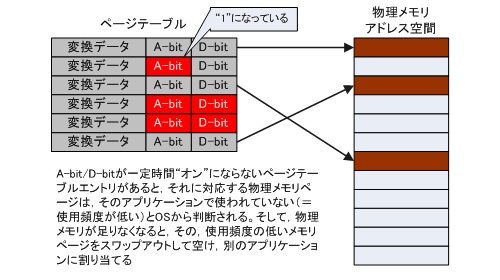
ページテーブルに入っているデータは(簡単にいうと)「足し算すると物理アドレスになる数」だが,それだけではなくページに関する情報も一緒に入っている。問題になったErrataは,ページ情報のうちAccess bitとDirty bit(以降,順にA-bit,D-bit)に関わるものだ。
A-bitは,そのページにアクセスされたとき1になり,D-bitはページの内容が変更されたとき(メモリページに書き込みがあったとき)1になる。この変更はCPUがハードウェア的に行っている。
A-bitとD-bitは,OSがページテーブルを管理するとき,そのページにアクセスがあったかや,変更があったかを知るために使われる。たとえば,アクセスや変更が一定時間以上ないメモリページは「ほとんど使われていない」としてディスクにスワップアウトすることでメモリを空け,他に使い回すといったような使い方がされている。これがいわゆるスワップだ(図3)。
以上が前振り。B2リビジョンのPhenomで話題を集めたErrataは,この「A-bit,D-bitが壊れる」というものだ。壊れる理由がキャッシュと関係している。
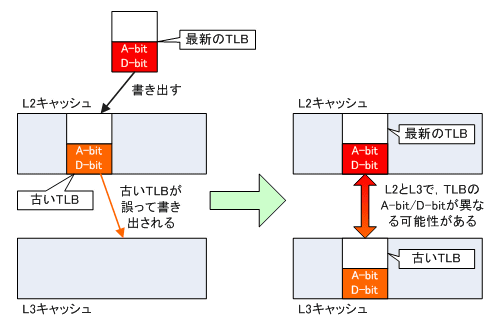
CPU内部のTLBに読み出されているデータが使われなくなると,メインメモリ中のページテーブルに書き戻しが行われるわけだが,このときx86 CPUではメインメモリに書き戻すのではなく,いったんキャッシュに書き戻しが行われる。これは,すぐに再利用する可能性があるためである。
そしてB2ステッピングのPhenomは,ここに「L2キャッシュにTLBの書き戻しが行われるときの微妙なタイミングで,L3キャッシュに古いTLBが書かれてしまう可能性がある」ということらしい。
なぜ,そのようなことが起こるのかは明らかにされていないが,Victim Cache手法と関係しているのではないかという推測もできる。というのも,CPU内部のTLBにあるデータと,“そのデータの古い内容”が必ずL2に存在するからだ。
図4はTLBのErrataが発生する様子だが,CPUに近い側(L1など)から更新されたTLBがL2に書き出されるとき,L2にあった古いTLBがL3に書き出されてしまう,という不正動作がVictim Cacheの制御法と一致することが分かる。
いずれにしても,このErrataのため,B2ステッピングのPhenomでは,L2のTLBのデータとL3のTLBのデータでA-bit/D-bitが異なる可能性がある。CPU内部でA-bitとD-bitがセットされてL2へ書き出されたのに,L3のデータではセットされていない場合は起こりえるわけだ。そして最悪の場合,A-bit/D-bitがセットされていないTLBのデータが使われてしまう。
これがどのような症状を引き起こすか推測するのは難しい。というのは,A-bit/D-bitの使い方はOSの内部処理によるからである。最悪のケースでは,「OSがD-bitを見て(実際にはページの内容が変更されているのに)変更されていないと判断し,ディスクにスワップアウトしないままページをほかに使い回してしまう」可能性があり,この事態が発生すると,ページの内容が壊れてOSはハングアップする。
逆にスワップが発生していない場合,大抵のOSでA-bit/D-bitはあまり使われないので,問題は発生しない可能性が高い。AMDが「高負荷時に問題が生じる」としているのはそのためだろう。
なお,以上から分かると思うが,Phenomのデビューに前後して流れた噂,「高クロック時に問題が生じる」というのは,根拠がない。低クロックで動作していても問題が起きるときには起きる。動作クロックとは無関係だ。
また,“A-bit/D-bitが壊れる”症状は常に発生するわけではない点も,認識しておく必要がある。AMDがこれまでに明らかにした情報によれば,「L2キャッシュにTLBを書き出そうとする瞬間に“キャッシュラインの走査”(※キャッシュの中から古いデータを探す動作のことだろうと思う)が行われているとき」に限って,ここまで説明したような不正動作が発生する,ということのようだ。3階層かつVictim Cacheという非常に複雑なキャッシュを使用するPhenomだけに,この種のErrata発生の予測や発見が非常に難しかっただろうことは想像に難くない。
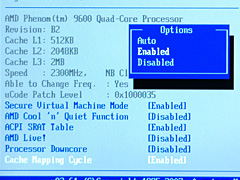
2007年11月22日の記事でお伝えしているように,このErrataはBIOSで修正されることになった。本稿で使用しているASUSTeK Computer製の「AMD 790FX」チップセット搭載マザーボード「M3A32-MVP Deluxe」の場合,BIOSリビジョン0703でアップデートがあり,エラッタ修正の有効/無効を選択できる「Cache Mapping Cycle」が追加され,「Auto」もしくは「Disabled」を選択すると,Errata修正に対応した動作となる。
どのようにBIOSで修正しているかは,原稿執筆時点でAMDがドキュメントを公開していないので不明だが,TLBのキャッシュそのものを無効にしているのではなかろうか。ちなみに,OSカーネルレベルでの修正法はLinuxカーネルに対応するコードをAMD自らAMD64開発者向けメーリングリストに流している。カーネルレベルではTLBのキャッシュを無効にする代わりにA-bit/D-bitのエミュレートを行うので,BIOSレベルでの修正よりもパフォーマンス低下が少ないようだ。
しかし,Windowsではカーネルレベルでの修正は望むべくもない。TLBの説明から分かると思うが,最も影響が出るのはメインメモリの性能だろう。グラフ7は,「Sandra XII」(2008.1.13.12)に用意された,2kB〜2GBブロックのキャッシュやメインメモリの帯域幅を測定する「Cache/Memory Bandwidth」の結果だ。キャッシュにヒットする3MB以下のサイズでは,Errata修正の無効/有効で誤差レベルの違いしか生じていないのに対し,キャッシュから溢れる4MB以上のブロックでは,Errata修正を有効にすることで,スコアが若干下がり気味になることが分かる。
メインメモリのバス帯域幅をテストするSandra XIIcの「Memory Bandwidth」では,さらにはっきりとした差が出てくる。その結果をまとめたのがグラフ8だが,違いは一目瞭然。Errata修正を有効にすると,メモリパフォーマンスが5%強下がる。これがパフォーマンスの大幅低下につながるわけだ。
実際,何が起きているのかをもう少し詳しく調べてみた。Phenomに限らず,CPUのメモリアクセスではページ境界(4KBごと)で大きなレイテンシが発生するが,TLBのキャッシュを無効にしているのなら,このレイテンシが大きくなっているはずである。
そこで,グラフ3,4と同じテストプログラムを使って,4KBページ境界のアクセスレイテンシを計測し抜き出してみた(グラフ9)。
Errata修正を有効にすると,ページ境界で1.6倍ほどレイテンシが大きくなることが分かる。このテストではスレッド間でメモリリード/ライトの依存関係を持つように実行していることもあり,レイテンシの悪化は最大2000クロック近くに及ぶ。
TLBのキャッシュが無効化されているとすると,影響はグラフで示したようなページ境界だけにとどまらないだろう。とくに広いメモリ範囲をアクセスするようなアプリケーションでは性能の低下が大きいと予測できる。
また,これがゲームにどのような影響を与えるかは予測しづらいものの,パフォーマンスが落ちることだけは確かだ。参考までに,Errata修正の無効/有効を切り替えつつ「3DMark06 Build 1.1.0」を実行してみたところ,やはりパフォーマンスの低下を確認できた(グラフ10)。
はっきり述べると,このErrataが修正されるまでPhenomの購入はお勧めしづらいのだが,購入予定の人や,すでに手に入れた人には,大容量のメインメモリを搭載することを勧めたい。32bit OSで4GBフルに積むとA-bit/D-bitのミスは(おそらく,そしてほとんど)影響しなくなると思われるからだ。その状態で,BIOSのErrata修正を無効化して使うのが正解だろう。もっとも,Windowsが内部でA-bit/D-bitをどう扱っているかは想像の域を出ないため,何か起きても筆者,4Gamer編集部とも責任は取れないが……。
期待を外してくれたPhenomには,Errata以外にもいくつかの謎がある。そのうち,ゲーム用途など,クライアントPCレベルで重要な2点について触れておこう。
PhenomのCPUコアはAthlon 64ファミリー同一のアーキテクチャだが,整数演算が強化され,128bitの浮動小数点演算ユニットの導入でSSE系の処理も高速になるとされていた。整数演算は当初から小改良に留まることが分かっていたが,SSE系はCore 2ファミリーに肩を並べるのではという期待があった(※Athlon 64ファミリーのSSEは基本2命令/2クロックのスループット,Core 2ファミリーは同1命令/1クロック)。
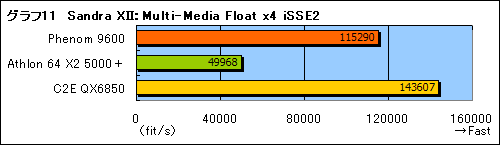
グラフ11は,同じ2.4GHz動作時(※Phenom 9600/2.3GHzを2.4GHz動作させている理由は前編を参照のこと)で,Phenom 9600とCore 2 Extreme QX6850(以下,C2E QX6850)を比較したものだ。参考のため,L2キャッシュ512KB×2の「Athlon 64 X2 5000+/2.6GHz」を,倍率変更で2.4GHzさせた状態(※そのほかのテスト環境はPhenom 9600とまったく同じ)も用意して,Sandra XIIの「Processor Multi-Media」にある「Multi-Media Float x4 iSSE2」のスコアを取得している。
結果はグラフ11のとおりで,こうして並べてみると,SSEの浮動小数点演算において,PhenomはAthlon 64 X2より劇的に高速化しているのが分かる。それでもCore 2 Quadには一歩及ばないが。
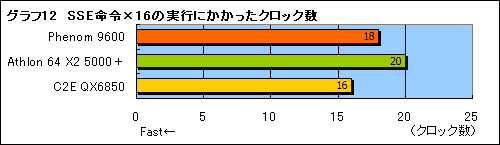
どの程度速くなったのか,もう少し突っ込んで調べてみよう。SSE命令16個(32bit浮動小数点×4の加算および乗算処理)の命令並びを実行するのにかかるクロック数を調べてみた。
結果はグラフ12のとおり。Athlon 64 X2と比べるとやや高速化しているらしい結果は得られたが,このテストでもCore 2 Quadの1命令/クロックには及ばないことが分かる。Core 2 Quadと伍していくに当たっては,さらなるスループットの改善が必要だろう。
なお,パイプライン実行が基本となっている現在のCPUで小さな命令ブロックのクロック数を計るのは簡単ではない。そのため,詳しい人なら「どうやったんだ?」とツッコミを入れたくもなると思われる。この種のことをやってみたい人のために,テストの方法を記しておこう。
現在のクロックカウンタを計測するRDTSC命令は,ユーザープログラムレベルで使えるものの,パイプライン実行されるため記録されるクロックカウンタの値は実際の命令実行時より数十から数百クロックものズレがある。そこで,RDTSC命令を実行する前後で命令のシリアライズを行う命令――筆者はCPUID命令を使用したが,何でもかまわない――を実行。記録したクロックカウンタの値からシリアライズに使った命令のオーバーヘッド分を差し引くことで,小さな命令ブロックの実行にかかるクロック数を(割と)正確に見積もることができる。
既報のとおり,Phenomは64bit単位でアクセスできる二つのメモリコントローラを持ち,両コントローラを並列動作させるUngangedモードと,並列動作させない代わりに128bitアクセスを行うGangedモード,二つのメモリアクセス方法をサポートしている。
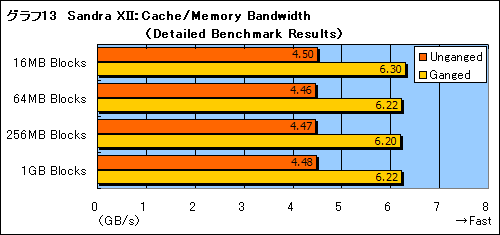
Unganged/Gangedの設定の違いで確かにベンチマーク結果は微妙に変化する。グラフ13は,Sandra XIIのMemory/Cache Bandwidthから,Phenomのキャッシュを越える容量の結果を抜き出したものだが,Gangedモードの方が好結果を残すことが分かる。4種類のメモリブロックサイズ,そのすべてで変化が見られるから誤差ではないだろう。
Gangedモードは要するに従来のデュアルチャンネルと同じ動作といわれている。この種のベンチマークはメモリを平たくアクセスして(=アドレス順にアクセスして)帯域幅を計測するだけなので,Athlon 64ファミリーでいうところのデュアルチャネルモード,すなわちPhenomにおけるGangedモードが好結果を残すのは納得といったところだ。
前編で筆者は,本稿のテストで基本的にUngangedモードを採用すると述べた。それだけに,「なぜスコアが高いGangedモードを使わないのか」と疑問を持つ人もいると思われる。
AMDがメモリアクセス方式としてUngangedモードを追加した理由はおそらく,Phenomがクアッドコアだからだ。というのも,四つのCPUコアがメモリにアクセスするときには,2組のメモリコントローラを並列動作させた方がレイテンシが低下する可能性があるからだ。メモリコントローラが1組だと,一つのCPUコアがメモリアクセスを行っている間,他のコアは待たなければならないが,2組あれば待つ必要がない。「メモリモジュールをインタリーブでアクセスするため,二つのコアからアクセスされるメモリアドレスが上手い具合にズレていなければならない」,という制約はあるが。
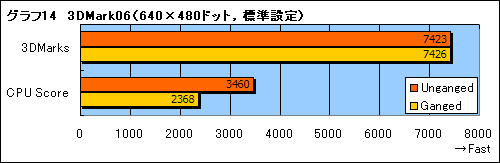
実際,「3DMark06 Build 1.1.0」のCPU Scoreでは,Ungangedモードのほうがやや高いスコアを出すことが分かった(グラフ13)。そう大きな差ではないが,複数回テストしても再現する,確実な違いである。これは,3Dmark06のCPU Testがマルチスレッドに対応しているためだろう。
Ungangedモードが有利になるケースはほかにも考えられる。Phenom――だけでなくAthlon 64ファミリーも含まれるが――では,I/Oバス(=PCI Express)上のデバイスがメインメモリにアクセスするのにもPhenom内部のメモリコントローラが使われるわけで,メモリコントローラが2組あれば,CPUのメモリアクセスを阻害せずに(例えばグラフィックスカードなどの)デバイスがメインメモリにアクセスできるわけだ。
AMDがUngangedモードを推しているのは,これらが理由だろう。本稿では,クアッドコアCPUとしてのPhenomを検証する意味から,設定を基本的にUngangedモードで統一した次第である。
とはいえ,Sandra XIIのテスト結果からも分かるように,Ungangedの利点がベンチマークテストで必ず現れるわけではない。シングルスレッドのアプリケーション(※過去のゲームタイトルはほとんどがこれに当てはまる)ではGangedモードのほうがパフォーマンスは高くなる可能性が高い。現状,ゲームのマルチスレッド化は限定的なので,読者がよくプレイするゲームを使って,両設定を切り替えながらプレイするなりフレームレートを測るなりして,よりパフォーマンスの上がる設定を使うべきと思われる。そこで迷った場合は,AMDが推すUngangedが正解かもしれない,といったところだ。
Phenomはかなり低くしか評価されていない。これが実情だが,前編のグラフ1〜3で示したとおり,Phenomが優れた成績を残す例もあるわけで,「まったく期待できないCPU」では断じてない。だが,今回のテストでは同時に,二つの明確な課題も見えてきた。それを中編の最後にまとめておこう。27日掲載の後編では,いま市場に存在するB2リビジョン版Phenomの動作クロックと性能を,あらためて冷静に見つめてみたい。
→前編:ネイティブクアッドコアに意味はないのか?
→後編:動作クロックはなぜ上がらないのか
PhenomのErrataとは何なのか
Errataの影響を考察する
 |
さて,現在のCPUはすべて仮想記憶という方法を使ってメモリを管理している。物理メモリを4KB単位の「ページ」で分割し,必要に応じてアプリケーションに割り当てる,という方法を使っているのだ。アプリケーションソフトがアクセスするメモリアドレスは,ページテーブルというアドレス変換テーブルを通して実際のアドレス「物理アドレス」に変換されている(図2)。
 |
ページテーブルはメインメモリにあるが,先に述べたようにメインメモリはとても遅い。アドレス変換にいちいちメインメモリのページテーブルを参照していたら遅くてどうしようもないわけで,昨今のCPUは,ページテーブルの一部を取り込んでおき高速に変換する仕組み「Translation Lookaside Buffer」(TLB)を持っている。「いまアクセスされている周辺」のメモリアドレスの変換テーブルをTLBに読み込んでおき,TLBを使って高速にメモリアドレス変換を行っているわけだ。
TLBに記憶できるテーブル数はCPUの種類によって異なる。Phenomに関しては正確なデータがないため分からないのだが,Athlon 64ファミリーと同じとすれば,1024個程度の変換データを保持できる程度だろう。なお,TLBとキャッシュを混同している人もいるようだが,TLBとキャッシュは厳密には異なる。x86系CPUの大半において,TLBはL2キャッシュよりもCPUに近いところにある。
ページテーブルに入っているデータは(簡単にいうと)「足し算すると物理アドレスになる数」だが,それだけではなくページに関する情報も一緒に入っている。問題になったErrataは,ページ情報のうちAccess bitとDirty bit(以降,順にA-bit,D-bit)に関わるものだ。
A-bitは,そのページにアクセスされたとき1になり,D-bitはページの内容が変更されたとき(メモリページに書き込みがあったとき)1になる。この変更はCPUがハードウェア的に行っている。
A-bitとD-bitは,OSがページテーブルを管理するとき,そのページにアクセスがあったかや,変更があったかを知るために使われる。たとえば,アクセスや変更が一定時間以上ないメモリページは「ほとんど使われていない」としてディスクにスワップアウトすることでメモリを空け,他に使い回すといったような使い方がされている。これがいわゆるスワップだ(図3)。
 |
以上が前振り。B2リビジョンのPhenomで話題を集めたErrataは,この「A-bit,D-bitが壊れる」というものだ。壊れる理由がキャッシュと関係している。
CPU内部のTLBに読み出されているデータが使われなくなると,メインメモリ中のページテーブルに書き戻しが行われるわけだが,このときx86 CPUではメインメモリに書き戻すのではなく,いったんキャッシュに書き戻しが行われる。これは,すぐに再利用する可能性があるためである。
そしてB2ステッピングのPhenomは,ここに「L2キャッシュにTLBの書き戻しが行われるときの微妙なタイミングで,L3キャッシュに古いTLBが書かれてしまう可能性がある」ということらしい。
なぜ,そのようなことが起こるのかは明らかにされていないが,Victim Cache手法と関係しているのではないかという推測もできる。というのも,CPU内部のTLBにあるデータと,“そのデータの古い内容”が必ずL2に存在するからだ。
図4はTLBのErrataが発生する様子だが,CPUに近い側(L1など)から更新されたTLBがL2に書き出されるとき,L2にあった古いTLBがL3に書き出されてしまう,という不正動作がVictim Cacheの制御法と一致することが分かる。
 |
いずれにしても,このErrataのため,B2ステッピングのPhenomでは,L2のTLBのデータとL3のTLBのデータでA-bit/D-bitが異なる可能性がある。CPU内部でA-bitとD-bitがセットされてL2へ書き出されたのに,L3のデータではセットされていない場合は起こりえるわけだ。そして最悪の場合,A-bit/D-bitがセットされていないTLBのデータが使われてしまう。
これがどのような症状を引き起こすか推測するのは難しい。というのは,A-bit/D-bitの使い方はOSの内部処理によるからである。最悪のケースでは,「OSがD-bitを見て(実際にはページの内容が変更されているのに)変更されていないと判断し,ディスクにスワップアウトしないままページをほかに使い回してしまう」可能性があり,この事態が発生すると,ページの内容が壊れてOSはハングアップする。
逆にスワップが発生していない場合,大抵のOSでA-bit/D-bitはあまり使われないので,問題は発生しない可能性が高い。AMDが「高負荷時に問題が生じる」としているのはそのためだろう。
なお,以上から分かると思うが,Phenomのデビューに前後して流れた噂,「高クロック時に問題が生じる」というのは,根拠がない。低クロックで動作していても問題が起きるときには起きる。動作クロックとは無関係だ。
また,“A-bit/D-bitが壊れる”症状は常に発生するわけではない点も,認識しておく必要がある。AMDがこれまでに明らかにした情報によれば,「L2キャッシュにTLBを書き出そうとする瞬間に“キャッシュラインの走査”(※キャッシュの中から古いデータを探す動作のことだろうと思う)が行われているとき」に限って,ここまで説明したような不正動作が発生する,ということのようだ。3階層かつVictim Cacheという非常に複雑なキャッシュを使用するPhenomだけに,この種のErrata発生の予測や発見が非常に難しかっただろうことは想像に難くない。
Errataの修正でパフォーマンスは大きく低下
レイテンシの増大が致命的
 |
どのようにBIOSで修正しているかは,原稿執筆時点でAMDがドキュメントを公開していないので不明だが,TLBのキャッシュそのものを無効にしているのではなかろうか。ちなみに,OSカーネルレベルでの修正法はLinuxカーネルに対応するコードをAMD自らAMD64開発者向けメーリングリストに流している。カーネルレベルではTLBのキャッシュを無効にする代わりにA-bit/D-bitのエミュレートを行うので,BIOSレベルでの修正よりもパフォーマンス低下が少ないようだ。
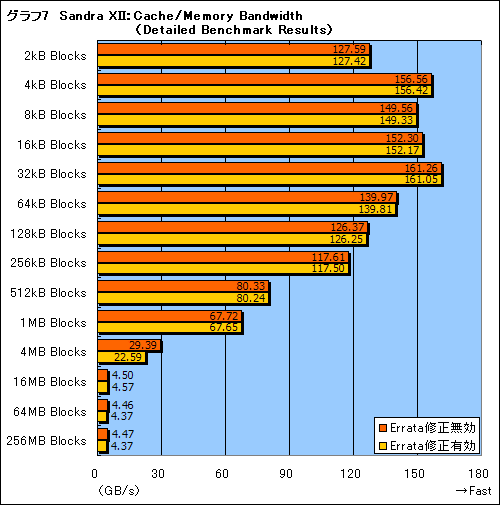
しかし,Windowsではカーネルレベルでの修正は望むべくもない。TLBの説明から分かると思うが,最も影響が出るのはメインメモリの性能だろう。グラフ7は,「Sandra XII」(2008.1.13.12)に用意された,2kB〜2GBブロックのキャッシュやメインメモリの帯域幅を測定する「Cache/Memory Bandwidth」の結果だ。キャッシュにヒットする3MB以下のサイズでは,Errata修正の無効/有効で誤差レベルの違いしか生じていないのに対し,キャッシュから溢れる4MB以上のブロックでは,Errata修正を有効にすることで,スコアが若干下がり気味になることが分かる。
 |
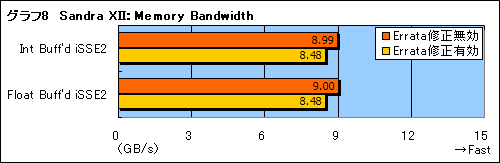
メインメモリのバス帯域幅をテストするSandra XIIcの「Memory Bandwidth」では,さらにはっきりとした差が出てくる。その結果をまとめたのがグラフ8だが,違いは一目瞭然。Errata修正を有効にすると,メモリパフォーマンスが5%強下がる。これがパフォーマンスの大幅低下につながるわけだ。
 |
実際,何が起きているのかをもう少し詳しく調べてみた。Phenomに限らず,CPUのメモリアクセスではページ境界(4KBごと)で大きなレイテンシが発生するが,TLBのキャッシュを無効にしているのなら,このレイテンシが大きくなっているはずである。
そこで,グラフ3,4と同じテストプログラムを使って,4KBページ境界のアクセスレイテンシを計測し抜き出してみた(グラフ9)。
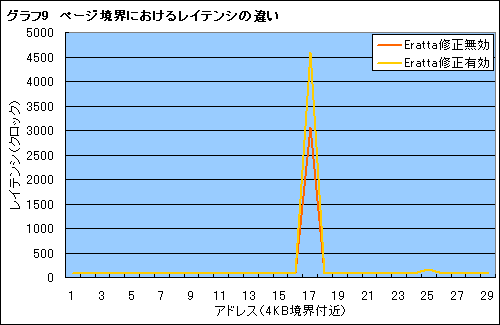 |
Errata修正を有効にすると,ページ境界で1.6倍ほどレイテンシが大きくなることが分かる。このテストではスレッド間でメモリリード/ライトの依存関係を持つように実行していることもあり,レイテンシの悪化は最大2000クロック近くに及ぶ。
TLBのキャッシュが無効化されているとすると,影響はグラフで示したようなページ境界だけにとどまらないだろう。とくに広いメモリ範囲をアクセスするようなアプリケーションでは性能の低下が大きいと予測できる。
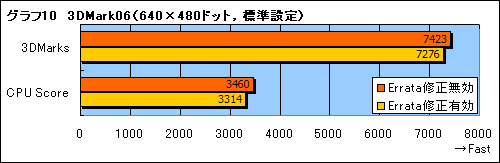
また,これがゲームにどのような影響を与えるかは予測しづらいものの,パフォーマンスが落ちることだけは確かだ。参考までに,Errata修正の無効/有効を切り替えつつ「3DMark06 Build 1.1.0」を実行してみたところ,やはりパフォーマンスの低下を確認できた(グラフ10)。
 |
はっきり述べると,このErrataが修正されるまでPhenomの購入はお勧めしづらいのだが,購入予定の人や,すでに手に入れた人には,大容量のメインメモリを搭載することを勧めたい。32bit OSで4GBフルに積むとA-bit/D-bitのミスは(おそらく,そしてほとんど)影響しなくなると思われるからだ。その状態で,BIOSのErrata修正を無効化して使うのが正解だろう。もっとも,Windowsが内部でA-bit/D-bitをどう扱っているかは想像の域を出ないため,何か起きても筆者,4Gamer編集部とも責任は取れないが……。
Phenomに残されたその他の謎
SSEとUnganged/Gangedモード
期待を外してくれたPhenomには,Errata以外にもいくつかの謎がある。そのうち,ゲーム用途など,クライアントPCレベルで重要な2点について触れておこう。
SSEは高速化しているのかいないのか
PhenomのCPUコアはAthlon 64ファミリー同一のアーキテクチャだが,整数演算が強化され,128bitの浮動小数点演算ユニットの導入でSSE系の処理も高速になるとされていた。整数演算は当初から小改良に留まることが分かっていたが,SSE系はCore 2ファミリーに肩を並べるのではという期待があった(※Athlon 64ファミリーのSSEは基本2命令/2クロックのスループット,Core 2ファミリーは同1命令/1クロック)。
グラフ11は,同じ2.4GHz動作時(※Phenom 9600/2.3GHzを2.4GHz動作させている理由は前編を参照のこと)で,Phenom 9600とCore 2 Extreme QX6850(以下,C2E QX6850)を比較したものだ。参考のため,L2キャッシュ512KB×2の「Athlon 64 X2 5000+/2.6GHz」を,倍率変更で2.4GHzさせた状態(※そのほかのテスト環境はPhenom 9600とまったく同じ)も用意して,Sandra XIIの「Processor Multi-Media」にある「Multi-Media Float x4 iSSE2」のスコアを取得している。
結果はグラフ11のとおりで,こうして並べてみると,SSEの浮動小数点演算において,PhenomはAthlon 64 X2より劇的に高速化しているのが分かる。それでもCore 2 Quadには一歩及ばないが。
 |
どの程度速くなったのか,もう少し突っ込んで調べてみよう。SSE命令16個(32bit浮動小数点×4の加算および乗算処理)の命令並びを実行するのにかかるクロック数を調べてみた。
結果はグラフ12のとおり。Athlon 64 X2と比べるとやや高速化しているらしい結果は得られたが,このテストでもCore 2 Quadの1命令/クロックには及ばないことが分かる。Core 2 Quadと伍していくに当たっては,さらなるスループットの改善が必要だろう。
 |
なお,パイプライン実行が基本となっている現在のCPUで小さな命令ブロックのクロック数を計るのは簡単ではない。そのため,詳しい人なら「どうやったんだ?」とツッコミを入れたくもなると思われる。この種のことをやってみたい人のために,テストの方法を記しておこう。
現在のクロックカウンタを計測するRDTSC命令は,ユーザープログラムレベルで使えるものの,パイプライン実行されるため記録されるクロックカウンタの値は実際の命令実行時より数十から数百クロックものズレがある。そこで,RDTSC命令を実行する前後で命令のシリアライズを行う命令――筆者はCPUID命令を使用したが,何でもかまわない――を実行。記録したクロックカウンタの値からシリアライズに使った命令のオーバーヘッド分を差し引くことで,小さな命令ブロックの実行にかかるクロック数を(割と)正確に見積もることができる。
Unganged/Gangedモードの謎
既報のとおり,Phenomは64bit単位でアクセスできる二つのメモリコントローラを持ち,両コントローラを並列動作させるUngangedモードと,並列動作させない代わりに128bitアクセスを行うGangedモード,二つのメモリアクセス方法をサポートしている。
Unganged/Gangedの設定の違いで確かにベンチマーク結果は微妙に変化する。グラフ13は,Sandra XIIのMemory/Cache Bandwidthから,Phenomのキャッシュを越える容量の結果を抜き出したものだが,Gangedモードの方が好結果を残すことが分かる。4種類のメモリブロックサイズ,そのすべてで変化が見られるから誤差ではないだろう。
Gangedモードは要するに従来のデュアルチャンネルと同じ動作といわれている。この種のベンチマークはメモリを平たくアクセスして(=アドレス順にアクセスして)帯域幅を計測するだけなので,Athlon 64ファミリーでいうところのデュアルチャネルモード,すなわちPhenomにおけるGangedモードが好結果を残すのは納得といったところだ。
 |
前編で筆者は,本稿のテストで基本的にUngangedモードを採用すると述べた。それだけに,「なぜスコアが高いGangedモードを使わないのか」と疑問を持つ人もいると思われる。
AMDがメモリアクセス方式としてUngangedモードを追加した理由はおそらく,Phenomがクアッドコアだからだ。というのも,四つのCPUコアがメモリにアクセスするときには,2組のメモリコントローラを並列動作させた方がレイテンシが低下する可能性があるからだ。メモリコントローラが1組だと,一つのCPUコアがメモリアクセスを行っている間,他のコアは待たなければならないが,2組あれば待つ必要がない。「メモリモジュールをインタリーブでアクセスするため,二つのコアからアクセスされるメモリアドレスが上手い具合にズレていなければならない」,という制約はあるが。
実際,「3DMark06 Build 1.1.0」のCPU Scoreでは,Ungangedモードのほうがやや高いスコアを出すことが分かった(グラフ13)。そう大きな差ではないが,複数回テストしても再現する,確実な違いである。これは,3Dmark06のCPU Testがマルチスレッドに対応しているためだろう。
 |
Ungangedモードが有利になるケースはほかにも考えられる。Phenom――だけでなくAthlon 64ファミリーも含まれるが――では,I/Oバス(=PCI Express)上のデバイスがメインメモリにアクセスするのにもPhenom内部のメモリコントローラが使われるわけで,メモリコントローラが2組あれば,CPUのメモリアクセスを阻害せずに(例えばグラフィックスカードなどの)デバイスがメインメモリにアクセスできるわけだ。
AMDがUngangedモードを推しているのは,これらが理由だろう。本稿では,クアッドコアCPUとしてのPhenomを検証する意味から,設定を基本的にUngangedモードで統一した次第である。
とはいえ,Sandra XIIのテスト結果からも分かるように,Ungangedの利点がベンチマークテストで必ず現れるわけではない。シングルスレッドのアプリケーション(※過去のゲームタイトルはほとんどがこれに当てはまる)ではGangedモードのほうがパフォーマンスは高くなる可能性が高い。現状,ゲームのマルチスレッド化は限定的なので,読者がよくプレイするゲームを使って,両設定を切り替えながらプレイするなりフレームレートを測るなりして,よりパフォーマンスの上がる設定を使うべきと思われる。そこで迷った場合は,AMDが推すUngangedが正解かもしれない,といったところだ。
少なからず見えてきた可能性から
現時点におけるPhenomの課題を整理する
 |
- 基本性能向上
SSE命令を始めとする基本性能が期待通りには上がっていない。最適化を進めて,より高い性能が出せるようにするか,それが無理ならクロックを上げる必要があるだろう。後者を選択するなら,最低でも動作クロックが3GHzを超えてこないと,競合の上位モデルとは戦えない - マルチスレッド性能向上
同一メモリをアクセスし続けるという特殊なマルチスレッドテストではCore 2 Quadを越える性能を見せるPhenomだが,それでも2スレッド以上で無視できないペナルティが発生してしまう。ネイティブクアッドコアを誇るのであれば,2スレッド以上でもスレッドの実行速度が変わらないくらいの性能を見せつけてほしいところだ。足を引っ張っていると思われるキャッシュ制御プロトコルにまで手を付けられるかどうかは微妙だろうが,たとえば4スレッド実行時の性能低下幅が20%程度くらいにまでなれば「さすがネイティブクアッドコア」と評価を受けるに違いない
- 関連タイトル:
 Phenom
Phenom
- この記事のURL:
(C)2007 Advanced Micro Devices, Inc.
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー