









テストレポート
「AMD FX」の謎を探る基礎検証レポート。FXはなぜ「ゲーマー向けでない」のか
 |
しかし,その“投資先”に,「AMD FX」を検討している読者はというと,あまり多くないかもしれない。4Gamerで先に掲載したレビューでは「アップグレードパスとしての意味はあるが,新規導入用としては微妙」という判断が下されているほか,メディアの評価は全世界規模で低く,少なくとも,離陸に失敗した感は否めない。
FXプロセッサでは,2003年の「K8」以来となる,完全なる新世代アーキテクチャ「Bulldozer」(ブルドーザ)を採用したのが大きなトピックとなるため,主因はおそらくBulldozerアーキテクチャにあるということになるが,では,Bulldozerに長所はないのか。今回は,ゲームから少し離れたテストをいろいろ行いつつ,Bulldozerアーキテクチャの本質に迫り,同時に,FXプロセッサへ投資する意義があるのかをあらためて考えてみたいと思う。
Bulldozerモジュールの特性が
すべての原因か
FXプロセッサの製品概要は発表時にお伝えしているので,興味のある人はぜひ合わせて参考にしてほしいと思うが,最大の見どころは,アーキテクチャの名前にもなっている「Bulldozer Module」(以下,Bulldozerモジュール)だろう。
 |
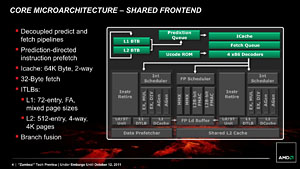 |
AMDの言を借りれば,「完全に独立した2コアと比べて回路規模を小型化でき,かつ,HTTよりも性能を上げられる」のが,Bulldozerモジュールのメリットである。
ただ,HTTと同じように,Windows 7がBulldozerモジュールを2コアとして認識する点は,注意が必要だろう。
Windows 7では,HTTが有効なとき,論理コアの利用で不利益をもたらすようなスレッドやプロセスのスケジューリングが行われないよう,物理コアと論理コアの使い分け方に調整が入っている。しかし,FXプロセッサに向けてそういった調整機構は用意されていないため,2つのスレッドやプロセスを1基のBulldozerモジュール内でスケジューリングした場合と,2基の異なるBulldozerモジュールに振り分けてスケジューリングした場合とで性能差が大きくなる可能性があるからだ。
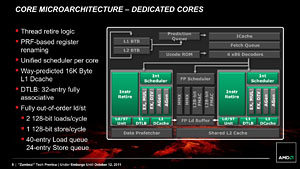 |
ちなみに,同じ見方をしたとき,コア単位の整数演算パイプラインは2本,メモリへのロード/ストアを行うためのアドレスジェネレータパイプラインは2本で,これはFusion APUのCPUコア「Bobcat」と同じ構成だ。Bobcatでは2-wayの命令デコーダを採用しているので,キャッシュ周りなどを抜きに,アーキテクチャだけで話をするなら,BulldozerモジュールはBobcatコアの拡張版と言うことができるかもしれない。
また,FXプロセッサで第2世代を迎えた「AMD Turbo CORE Technology」(以下,Turbo CORE)もチェックしておく必要がありそうだ。第1世代では,ゲームプレイ時にほとんど何のメリットももたらさなかったものが,FXプロセッサでは効果のほどを確認できるからである。
 |
念のため書き記しておくと,比較対象として用意したのは「Phenom II X6 1090T/3.2GHz」(以下,X6 1090T)と「Core i7-2600K/3.4GHz」(以下,i7-2600K)。FX-8150のレビュー時,AMDの評価キットに含まれていた「AMD 990FX」マザーボード「Crosshair V Formula」を用いたところ,挙動が怪しかったというのはすでにお伝えしたとおりだが,今回はASUSTeK Computerから製品版のCrosshair V Formulaを借り,それを用いている点は,あらかじめお断りしておきたい。
レビュー時に使った個体はDDR3-1866設定を行えなかったが,製品版のCrosshair V Formulaではまったく問題なく設定できている。
 |
総合ベンチではメリットとデメリットが
高コントラストを描く
まずは,一般的なPC用途を想定した総合ベンチマークソフト「PCMark 7」(Version 1.0.4)のテスト結果から見ていくことにしよう。
先ほど述べたとおり,今回のテスト環境ではDDR3-1866設定を行えるため,FX-8150ではDDR3-1866設定を行いつつ,X6 1090Tとテスト条件を揃えるべく,DDR3-1600設定でもテストを行う。また,今回用意したCPUのなかで最も動作クロックが低いX6 1090Tと揃えるため,FX-8150とi7-2600Kを3.2GHz動作させた状態でもスコアを取ることとした。加えて,Turbo COREや「Intel Turbo Boost Technology」(以下,Turbo Boost)の有効/無効を切り替えたりもしている。グラフ中,Turbo COREはTC,Turbo BoostはTBと表記することもここでお断りしておきたい。
 |
Core C6 Stateについては後ほどあらためて説明したいと思うが,FX-8150でTurbo COREを有効化すると,同時にCore C6 Stateも有効になり,アイドル状態になったコアの動作クロックは1.4GHzにまで低下する。一方,テスト条件を揃えるためCnQを無効化したX6 1090Tの場合,Core C6 Stateは存在しないため,Turbo COREに入らないときの動作クロックは定格のままとなる。このあたりはCPU仕様の違いによるものなので,あらかじめご了承のほどを。
なお,FX-8150を3.2GHz動作させたときのTurbo COREコア数とクロックは,X6 1090Tと同じ「3コア,3.6GHz」としている。これも条件をなるべく揃えるためだ。一方,i7-2600Kは,「Enhanced Intel SpeedStep Technology」(以下,EIST)がTurbo Boostと連動するため,Turbo Boost有効時はEISTも有効,Turbo Boost無効時はEISTも無効となる。3.2GHzへの倍率変更時はTurbo Boost,EISTともに無効だ。
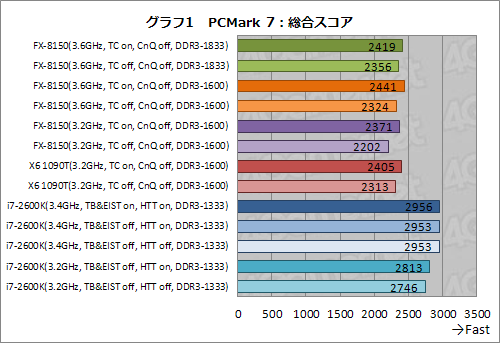
というわけでグラフ1は,各種条件を切り替えながらCPU 3製品の総合スコアを取得した結果である。ざっと見るだけでも,FX-8150とX6 1090Tのスコア差が大きくなく,また,両製品ともi7-2600Kにはまったく歯が立たないことが分かってもらえると思う。3.2GHz動作のi7-2600Kにも置いて行かれているのは,なかなか感慨深い。
同じ3.2GHz動作で比較したときに,FX-8150がX6 1090Tに及ばないのも目を引く。コア数を増やしたメリットよりも,コアあたりの性能が低下したデメリットが出ている印象だ。
ただ,Turbo COREの上限を揃えた3.2GHz設定時に,X6 1090TよりFX-8150のほうが,より大きなTurbo COREの効果を得られている点は押さえておく必要があるだろう。X6 1090TではTurbo CORE有効時に4.0%のスコア上昇なのに対し,3.2GHz動作のFX-8150は7.7%。冒頭でも述べたが,やはりFXプロセッサのTurbo COREには改良が入っているようである。
 |
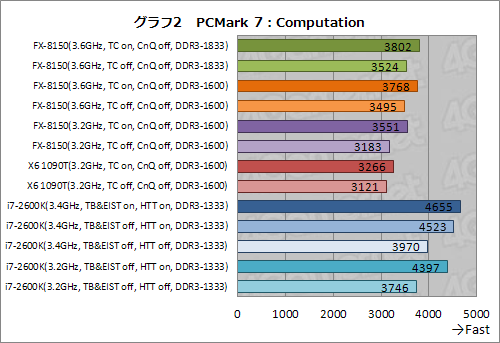
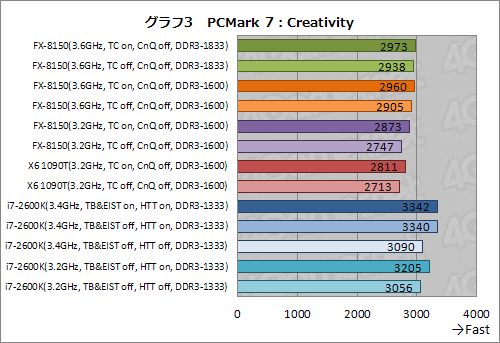
FX-8150のスコアがX6 1090Tとあまり変わらない理由は,スコアの詳細を見ていくと納得できる(グラフ2〜5)。ビデオや音声のトランスコードを含む「Computation」や「Creativity」でFX-8150が高めのスコアを残す一方,Webブラウジングやテキスト編集が含まれる「Productivity」や,Webブラウジングやビデオ再生を含む「Entertainment」ではX6 1090Tに及ばないスコアを残しているからだ。
ComputationやCreativityに含まれるトランスコードは,マルチスレッド化されているため,広義のコア数がスコアを左右しやすい(グラフ2,3)。実際,i7-2600KにおけるHTT有効/無効時の違いも大きいが,こうしたテストではFX-8150が持つ,4 Bulldozerモジュール(≒8コア)の効果が多少なりとも得られている。
また,ここでは,FX-8150のDDR3-1833設定時におけるスコアがDDR3-1600設定時よりも若干高めに出ていることも見て取れる。劇的ではないものの,より高いデータレートを持つメモリモジュールの搭載に相応の意味はあるというわけだ。
 |
 |
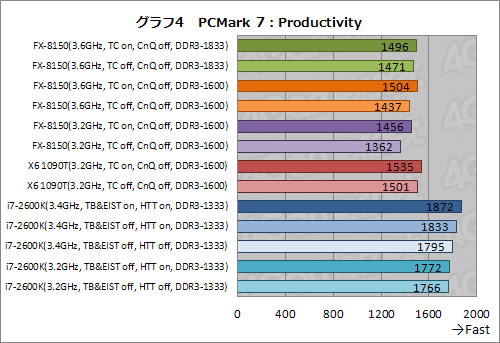
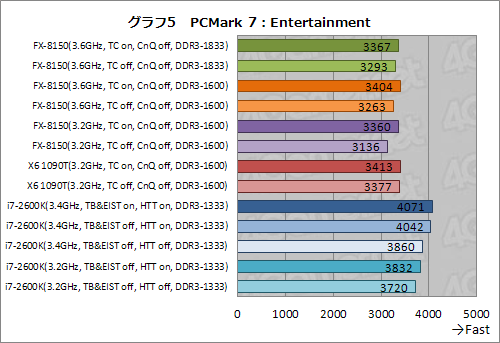
一方,マルチスレッド処理があまり含まれないProductivityやEntertainmentではコア数の違いがあまりスコアを左右しない(グラフ4,5)。FX-8150のメモリ設定も,スコアにはほとんど影響していないようで,結果としてFX-8150のスコアは,X6 1090Tよりも低くなった。
 |
 |
以上の有利不利が総合的に働いて,FX-8150とX6 1090Tでは,総じてあまり変わらないスコアに落ち着いている,ということなのだろう。FX-8150が新世代アーキテクチャを採用していることを考えるに,なんとも寂しい結果だが,これが2011年12月時点の現実である。
整数演算では光るものも見せるFX
浮動小数点演算はやや不得手か
総合ベンチマークソフトで,CPUそのものの特性を把握するのは難しい。そこで,システムチェッカ兼ベンチマークテストである「AIDA64」(Version 2.00.1700)に用意されたいくつかのテストを行っていきたい。
ここでは,CPUそのものの特性をチェックする目的から,Turbo COREやTurbo Boostは無効化している。
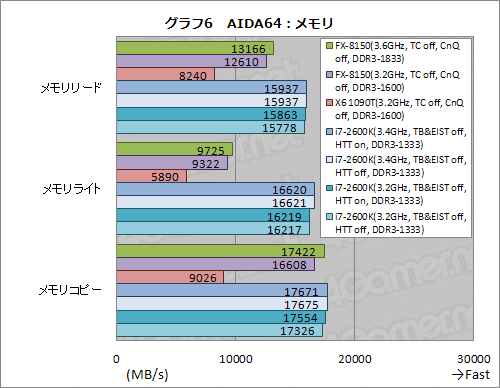
さて,まずはメモリ周りのテストからだ。メモリ周りについては,先のFX-8150レビュー記事で「Sandra 2011」を用いたテスト結果を掲載し,FX-8150がPhenom IIに対してメモリ性能の向上が認められることをお伝えしているが,DDR3-1833設定時のFX-8150がX6 1090Tに対してメモリリードで約1.6倍のスコアを示すなど,AIDA64でもその傾向は見て取れる(グラフ6)。i7-2600Kには及ばないものの,Phenom IIと比べてメモリ周りの性能が高くなっているのは確かなようだ。
 |
このメモリ周りの性能向上がスコアとして如実に反映されたのが「CPU Photoworxx」というテストである(グラフ7)。
CPU Photoworxxは,整数演算を用いて静止画を加工するときの性能を見るもので,マルチスレッド処理の対応力とメモリ周りの性能がスコアを左右するとされている。そういったテストで,FX-8150がX6 1090Tから60〜70%もスコアを伸ばしているわけだ。
 |
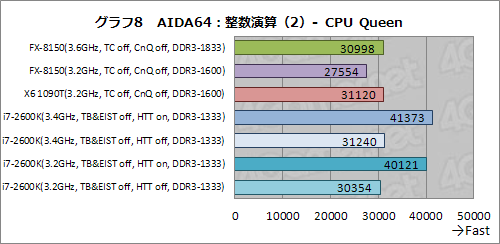
しかし,同じ整数演算系のテストでも,「CPU Queen」だとFX-8150はあまり振るわず,3.6GHz動作のFX-8150が,3.2GHzで動作するX6-1090Tの後塵を拝した(グラフ8)。CPU Queenはマルチコアに対応しているため,コア数が“効く”はずなのだが,結果がそうなっていないことからすると,コア性能そのものがスコアに反映されてしまっている可能性が高い。
 |
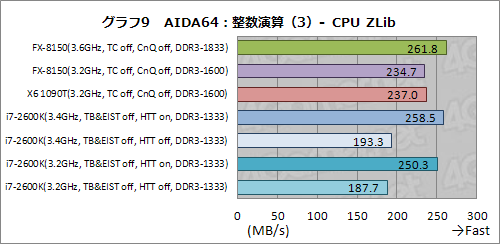
グラフ9は,圧縮アルゴリズム「zlib」を用いた圧縮解凍性能を見るもので,コア数がスコアを左右するテストだ。
i7-2600KではHTTの無効化によってスコアが大きく落ち込むのに対し,FX-8150やX6 1090Tは比較的順当に高めのスコアを示している。ただ,3.2GHzに動作クロックを引き下げたFX-8150はX6 1090Tのスコアを下回っており,X6 1090Tよりも2コア多い分の優位性が,コアあたりの性能が低いことによって相殺されてしまっているのも見て取れよう。
 |
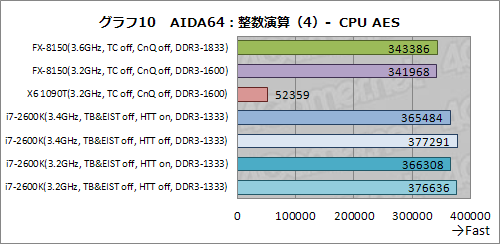
AES(Advanced Encryption Standard)暗号における暗号化性能を見る「CPU AES」テスト。その結果がグラフ10となる。
FXプロセッサやSandy Bridge世代のCore iプロセッサでは,AES暗号化を支援する命令セットがサポートされているため,非対応のX6 1090Tと比べると,スコアが圧倒的に高い。FX-8150とi7-2600Kでは,i7-2600Kのほうがスコアは高いものの,ここはFX-8150がよく健闘していると見るべきかもしれない。
 |
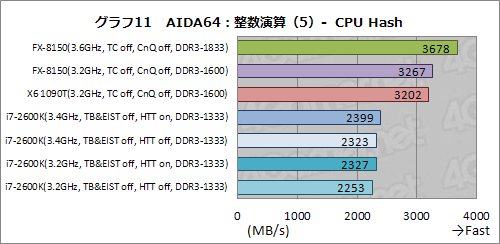
グラフ11はSHA1ハッシュアルゴリズムを用いてハッシュを求める処理の速度を見るテストだが,ここではFX-8150がトップに立った。i7-2600Kに対して50%以上という大きなスコア差をつけているのは見逃せない。
今回用いたAIDA64は,CPU Hashテストで拡張命令セット「XOP」(eXtended OPerations)に対応したという。そして,今回用意したCPUでXOPアクセラレーションに対応するのはFXプロセッサだけなので,この結果はXOPのおかげ……といきたいところなのだが,実際にはそうではない。というのも,3.2GHz動作させたFX-8150と,XOP非対応となるX6 1090Tとのスコア差が大きくないからである。ここはむしろ,「コアあたりの性能ではX6 1090Tに及ばないFX-8150だが,8コア化とXOP命令セットのサポートによって,同一クロックでもX6 1090T+α程度のスコアを出せている」,と見るべきだろう。XOP命令セットのサポートがもたらす優位性はそれほど大きくないようだ。
i7-2600Kのスコアがパッとしないのは,HTT有効時のスコアがほとんど伸びないことからして,ネイティブ4コアである点に求めることができそうである。
 |
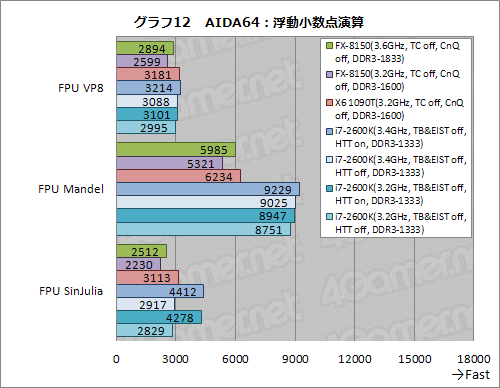
以上,整数演算系のテストでは,条件次第でX6 1090Tからスコアが伸びるものもあると確認できるのだが,浮動小数点演算テストでは様相が変わってくる。
グラフ12を見てほしい。ここではAIDA64の浮動小数点演算系テストから,「FPU VP8」「FPU Mandel」「FPU SinJulia」のスコアをグラフ化しているのだが,定格動作するFX-8150のスコアがいずれもX6 1090Tより低いのだ。古典的な浮動小数点演算命令やSSE命令を前にすると,FX-8150の性能は,X6 1090Tよりやや低い,というわけである。
AMDによれば,FXプロセッサで,浮動小数点演算ユニットに若干の強化が入っているはずなのだが,スコアを見る限り,その効果はないか,あってもほとんど無視できるレベルのように思われる。
 |
浮動小数点演算性能が上がらない可能性として挙げられるのは,先に述べたとおり,Bulldozerモジュールで,2基の整数演算ユニットが浮動小数点演算ユニットを共有する形になっているところだろう。浮動小数点演算ユニットの性能が上がっていたとしても,2つのスレッドが同時に1つの浮動小数点演算ユニットを使おうとして奪い合いが生じ,そこがボトルネックとなって性能が低下するというのは,十分にあり得る話だ。
ただ,「何がボトルネックとなっているか」までは,AIDA64では分からない。ここから先は,筆者自作のテストツールをいくつか実行して,ボトルネックの原因を探っていこう。
2スレッドを同一Bulldozerモジュール内で
動作させたときの性能低下率はHTTより小さい
ここで調べたいのは,「Bulldozerモジュールで共有されるリソースが,マルチスレッドのアプリケーションを前にしたとき,どの程度の性能低下を招くか」だ。
冒頭でも紹介したように,Bulldozerモジュールは2基の整数演算ユニット(≒コア)で1基の浮動小数点演算ユニットを共有する。これはHTTも同じで,1基の物理コアで2つのスレッドを動作させたときには,1基の浮動小数点演算ユニットを2スレッドで共有することになる。一方,ネイティブの6コアCPUであるX6 1090Tの場合は,コアごとに1基ずつ浮動小数点演算ユニットが用意され,共有されることはない。なので理論的には,浮動小数点演算を含むコードを実行したとき,X6 1090Tの効率を100とした場合,FX-8150とi7-2600Kではそれが50にまで低下する可能性があるわけだ。その実態を調べる必要がある。
というわけで,今回は自作のツールを2つ作成してみた。1つは「円周率6万5536桁を『2回』求める」(以下,円周率計算)ソフトだ。円周率を求めるアルゴリズムをマルチスレッド化するのは難しく,限られた時間では無理なので,代わりに,並列で2回求める――つまり2つのスレッドで処理する――という変則的なことを行っている。
円周率のコードのうち,浮動小数点演算の占める割合は約2割。残りが整数演算という比率だ。ゲームを含む一般的なアプリケーションで,浮動小数点演算の使用比率は高くないため,今回の円周率計算は,多くのPCゲームよりも浮動小数点演算の比率がやや高い程度と考えてもらっていいと思う。おそらく,AIDA64の浮動小数点演算系テストよりは低い比率だろう。いずれにせよ,今回の円周率計算は,テストのためのテストではなく,「浮動小数点演算ユニットを共有するBulldozerモジュールやHTTの,ごく一般的なアプリケーションにおけるペナルティを調べるもの」という理解をしてもらえれば幸いだ。
もう1つは,「整数演算だけを用いて素数を求める」(以下,素数計算)というテストツールだ。小数点演算のツールが,整数演算と浮動小数点演算が入り交じるコードになっているので,より単純なものを用意したというわけである。素数計算は2スレッド化しやすく,2スレッド化するとスレッドあたりの計算量が2分の1になるというのがポイントだ。
なお,このテストでは純粋にリソースが共有されることでのペナルティを調べたいので,Turbo COREやTurbo Boostといった変動要因はすべて無効化した。
さてまずは,円周率計算において,「2つのスレッドをどこに割り当てるか」を切り替えつつ,「シングルスレッドで2回処理するのと比べてどの程度の性能向上率があるか」を求めてみることとしよう。
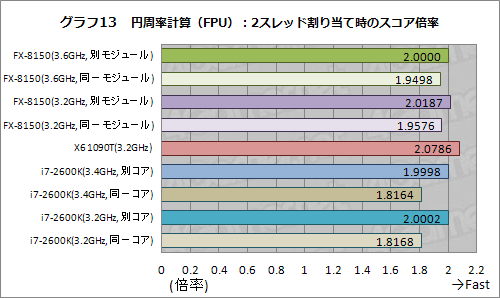
2つのスレッドには競合する部分がほとんどないため,理論的には,完全に独立した2つのコアへ2つのスレッドを別々に割り当てた場合,倍率は2倍となるはずだが,BulldozerモジュールやHTTのように「完全に独立したコア」にならない場合は2倍にならない。なので,Bulldozerモジュールの場合,同一モジュール内にある2コアを使ったときに,別モジュールの1コアずつを使ったときと比べてどれくらい倍率が下がるか。下がったとして,HTTで同一CPUコアに2スレッド振ったときと比べて倍率はどうかといったあたりがチェックポイントだ。
グラフ13は,整数演算と古典的な浮動小数点演算命令のみを用いて,円周率計算を行ったときのテスト結果だ。バーを見てみると,FX-8150では,同じBulldozerモジュール内に2スレッドを割り振った場合,異なるモジュールに割り振ったときと比べて,約5%の性能低下が見られる。ゲームを始めとした一般的なアプリケーションでは,この程度の性能低下があるというわけだ。
HTTの場合だと,同一コアに2スレッド振ると約18%も性能が低下しているので,HTTと比べて共有リソースの少ないBulldozerモジュールのほうが,マルチスレッド処理時のペナルティも少ないというのがよく分かる。
 |
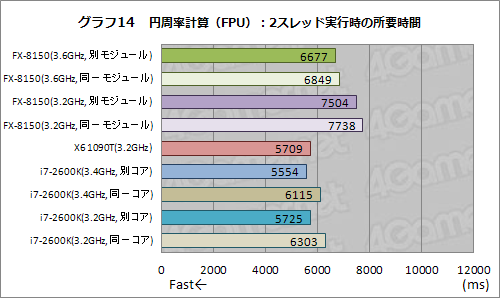
もっとも,Bulldozerモジュールの浮動小数点演算ユニットが持つ絶対性能がやはりそれほど高くないということも,グラフ14からは見て取れよう。
グラフ14は円周率計算の実所要時間を示したものなので,ここではバーが短いほど性能が高いことを示す点は注意してほしい。X6 1090Tが,HTTを有効化したi7-2600Kと同程度のスコアを示している一方,FX-8150は2基の異なるBulldozerモジュールで2スレッドを動作させた場合でもそれらにまったく届いていないのは,なかなか印象的だ。
 |
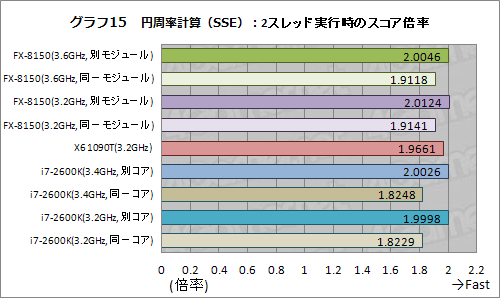
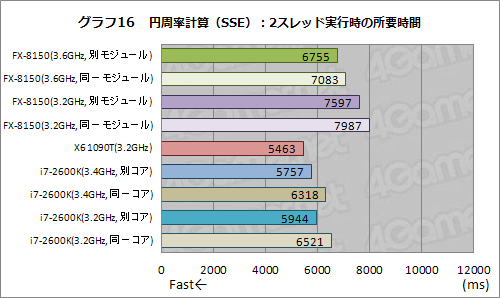
古典的な浮動小数点演算命令でなく,SSEやAVXを用いた場合はどうなるだろうか。プログラムの一部にSSE命令を用いた場合と,AVXを用いた場合とで,円周率計算を行った結果がグラフ15〜18となる。
SSE命令を用いたテストだと,同じBulldozerモジュール内に2スレッドを割り振ったときに,異なるモジュールに割り振ったときと比べて,約9%のスコア低下が見られる。古典的な浮動小数点演算命令を用いたときは約5%だったので,それと比べると落ち込みが大きくなるものの,それでも,約18%落ち込むHTTよりは優秀だ。
もっとも,純粋に性能の話をすると,最も高いスコアを示したのはX6 1090Tで,FX-8150のスコアは振るわない。
 |
 |
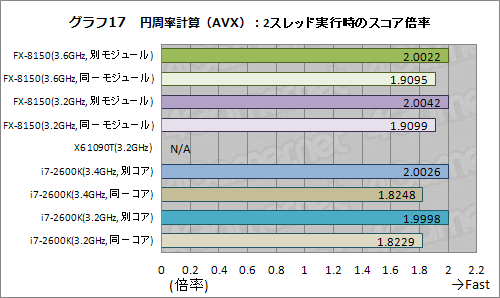
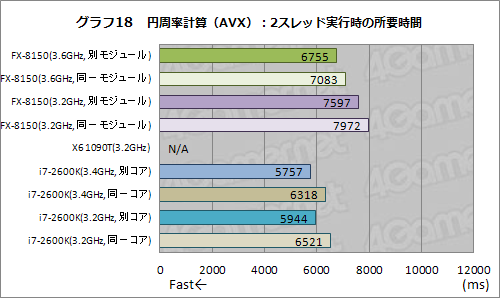
グラフ17,18はAVX命令を使った場合だが,SSE命令を使う場合とほとんど同じ傾向が得られている。SSEと同じ演算器が用いられることに加えて,AVX命令はほとんど使っていない――整数から倍精度に変換するところだけしか使っていない――ので,SSE命令と変わらないというのは納得できる結果,ではあるのだが。
なお,ここでX6 1090TのスコアがN/Aとなっているのは,X6 1090TがAVX命令をサポートしないためである。
 |
 |
いずれにせよ,絶対的な性能を見たときに,FX-8150はSSE,AVXのどちらでもあまり良好なスコアを残せていない。古典的な浮動小数点演算命令の結果やAIDA64の結果と併せて考えるに,「FX-8150の浮動小数点演算ユニットはさほど優れた性能を持っていない」と結論づけてよさそうに思える。
つまり,「Bulldozerモジュールで共有されるリソースの競合自体はあまり足を引っ張っておらず,そもそも浮動小数点演算そのものが高速ではない」ということになるわけだが,では,浮動小数点演算を含まない場合どういう結果になるだろうか。
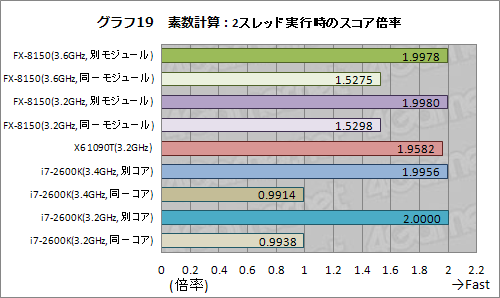
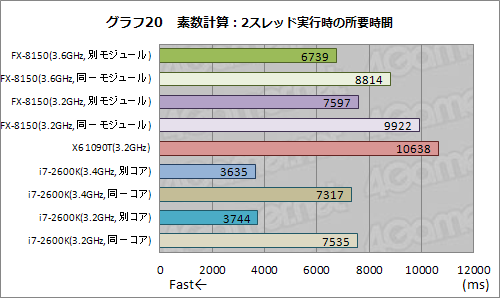
2つめのテストである素数計算について,1スレッド処理に対する2スレッド処理時のスコア倍率を見たものがグラフ19となる。
グラフの見方そのものはグラフ13,15,17と同じだが,ここで最初に注目しておきたいのは,HTTの物理コア+論理コアに割り振ったとき,倍率が1倍をわずかに割り込む結果となっている点だ。ここで用いているのは,加算と剰余を求めるという単純極まりないものなので,リソースの競合がモロに出てしまい,HTTの効果がまったく得られないのである。
もっとも,HTTでこういう事態が生じ得ることは割とよく知られており,いまさら驚くほどのことではない。
Bulldozerモジュール内の2コアを用いたときにも,競合するリソースの競合は大きく出ており,別モジュールの2コアに割り当てたときと比べて,約47%の性能低下を確認できた。さすがにHTTほどひどいことにはならないものの,同一Bulldozerモジュールに2スレッドを割り当てると,性能面で足をかなり引っ張る可能性があるわけだ。
 |
なお,絶対的な性能ではi7-2600Kが他を圧倒する(グラフ20)。i7-2600Kの同一コアに2スレッドを割り当てたりしない限り,FX-8150やX6 1090Tはi7-2600Kの足下にも及ばないと言っていいだろう。実のところ,実のところ,Core i系はこの種の単純な整数演算にめっぽう強いのだ。
FX-8150とX6 1090Tでは,FX-8150のほうがやや高めのスコアを残したことも指摘しておきたい。ここまでのテスト結果からしてコアあたりの性能はX6 1090TのほうがFX-8150よりもやや高いはずなので,「単純なループを回して単純な演算を続ける」ような処理に対して,FXプロセッサで何かしらの最適化が行われた可能性があると筆者は見ている。
 |
これまでのことをまとめると以下のような感じになる。
- FXプロセッサが持つCPUコアあたりの性能はPhenom II X6に及ばない
- FXプロセッサの整数演算性能はさほど低くなく,メモリ周りの拡張が“効く”こともある
- FXプロセッサは浮動小数点演算が得意ではない
- BulldozerモジュールはHTTより確実に高い効率で動作するが,リソースの競合が発生した場合,最大50%弱の性能低下が生じ得る
Turboモードに入りやすくなり
“上げ幅”も増えたTurbo CORE
Turbo COREはPhenom II世代の一部製品で取り入れられた機能だが,冒頭でも紹介したとおり,FXプロセッサでは第2世代へと進化している。
今回用意したCPUを例に述べてみると,X6 1090Tの場合,定格3.2GHz,Turbo CORE有効時には3コアが最大3.6GHz動作という仕様になっており,4コア以上に負荷がかかる場合は(AMD OverDriveやBIOSを使って,ユーザーが自己責任で設定変更したりしない限り)Turbo CORE動作には移行しない。
Phenom IIで,Turbo COREにおける動作クロックの切り替えはP-Stateを用いて行われており,OSがCPUをP0-Stateに入れたとき,Turbo CORE側でP0-Stateを「Boost State」へ移行させることで,定格よりも高い動作クロックを実現するようになっていた。このあたりは,第1世代Turbo COREの挙動をチェックした記事が詳しいので,併せて参考にしてもらえればと思う。
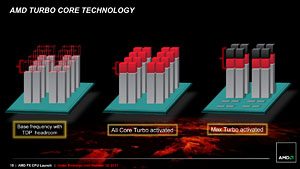
それに対し,FXプロセッサの第2世代Turbo COREにおける拡張は大きく2つある。1つは,「P-Stateをシフトさせてターボに入れる」という基本仕様を継承しつつ,引き上げの段数が2段階になっている点。もう1つは,TDP(Thermal Design Power,熱設計消費電力)に余裕があるなら,全コアの1段階引き上げが可能になった点である。
負荷が生じているコアが4コア(=2 Bulldozerモジュール)以内であれば,Turbo COREは2段階引き上げた最大クロック「Max Turbo」にまで引き上げられる。また,5コア(=3 Bulldozerモジュール)以上に負荷が生じても,TDPに余裕さえあれば,すべてのクロックを1段階引き上げる「All Core Turbo」を維持できるというのが,第2世代Turbo COREのウリだ。
 |
Core C6 Stateは,少なくとも現時点だと,OSの省電力制御から独立しているのもトピックだ。Windows 7の電源設定を「高パフォーマンス」とした状態からでも,BIOSからCore C6 Stateを有効化すると,アイドル時の動作クロックは1.4GHzにまで下がるので,Core C6 Stateによって,なるべくTDPの余裕を確保するような仕掛けになっているのではなかろうか。あるいは,Core C6 StateでTDPに余裕を持たせない限り,Turbo COREを安定的に動作させられる可能性もゼロではない。
ちなみに,AMD製CPUでおなじみとなるCnQの場合は,Windowsの電源設定と連動し,アイドル時に最低800MHzまで引き下げるようになっており,Core C6 Stateと併用が可能。Core C6 StateとCnQを両方とも有効化した場合,動作クロックは最低800MHzまで落ちる。
※State(ステート)というのは,プロセッサの動作状態を段階的に示したもの。Stateは一般にP-StateとC-Stateがあり,今日(こんにち)のCPUは,アクティブ時にP0〜Pn,アイドル時にC0〜Cnといった形で,負荷状況に合わせて,動作状態を変化させていくのが一般的となっている。P-StateのP0が,いわゆる「定格動作クロック」。C-StateのC0は最もアクティブに近いアイドルで,数字が大きくなるほど,CPU内部で停止させる部分を増やし,消費電力を0に近づけていくが,停止する部分が多い分,復帰に要する時間も長くなる。Core C6 Stateは,「Bulldozerモジュール単位でC6-Stateに移行させる機能」だ。
もう1つ,Turbo COREに影響を与える設定として,「HPC Mode」というのもある。HPC Modeを有効化すると,「TDPの枠内で」という上限が取り払われ,All Core Turboの最大クロック――FX-8150では4.2GHz―――に貼り付くという,不思議な挙動が見られるようになるのだ。
この点について,HPC Modeの設定項目を用意しているASUSTeK Computerに聞いてみると,「CPUの仕様」という回答が返ってきたので,HPC Modeでは,この挙動が正しいということでいいのだろう。
 |
というわけで今回は,第2世代TurboCOREの挙動を確かめるべく,各コアへ順番に負荷をかけていく自作ツールを用いて,クロックの挙動を記録してみることにした。クロックの記録にはこれまた自作のツールを用いている。
ちなみに,CPU-Zが開発しているクロック監視ツール「TMonitor」は,バージョン1.04以降でFXプロセッサに対応している。なので,「そちらを使えばいいんじゃないの?」と思った人もいると思うが,今回,TMonitorを使わなかった理由は,挙動に疑問が残ったためだ。
筆者も最初はTMonitorを使うつもりでいたのだが,いざ動かしてみると,Core C6 Stateを無効化しても,アイドル時のクロックを1.4GHzと表示するケースがあった。アイドル時や,Turbo CORE有効時のクロック値に100%の信頼が置けないため,やむなく自分で作った次第である(※断言はできないが,TMonitorはACPIから情報を取っていて,それゆえ挙動がおかしくなっているのかもしれない)。
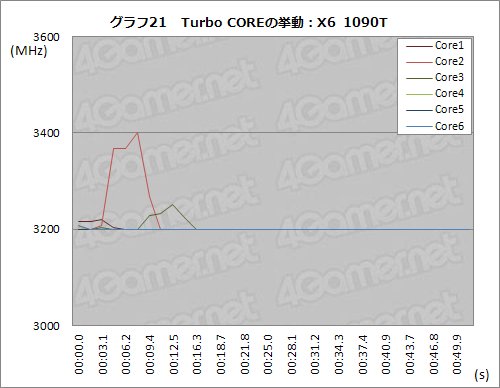
さて,グラフ21は,自作の負荷ツールとクロックロギングツールを用い,X6 1090TのTurbo COREを追ったものだ。
自作負荷ツールは,約5秒ごとに,負荷をかけるコアの数を1つずつ増やすものとなっている。今回は約50秒間のクロックを追っているが,X6 1090Tの場合は6コアなので,約30秒経過時点で全コアに負荷がかかり,その後は維持されることとなるわけだ。一方,ロギングツールのほうは,約10msごとにクロックの平均値を取るようにしてあるため,瞬間的に最大クロックへ達してもそれを検出したりはできない(≒10ms以上最大クロックに達してくれないと記録できない)ので,その点は踏まえてもらえればと思うが,ご覧のとおり,3.6GHzは記録されなかった。
また,2コア以上に負荷がかかった状況ではクロックの引き上げ頻度が急激に下がり,3コア以上ではほとんど見られなくなるということも分かる。このあたりは,先に第1世代Turbo COREをテストしたときと同じ結果だ。
 |
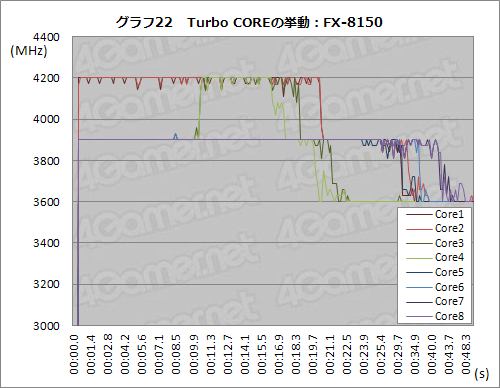
まったく同じツール,まったく同じテスト方法でFX-8150に負荷をかけた結果がグラフ22となる。
FXプロセッサにおいて,動作クロックは2コア(=1 Bulldozerモジュール)単位で切り替わるため,動作クロックの変化が,約5秒単位でなく,約10秒単位で生じる点は注意してほしいと思うが,負荷をかけ始めるとまず2コアが4.2GHzへと上がり,残るコアも引きずられるように3.9GHzへと上がっているのが分かる。3.9GHzはAll Core Turboのクロックなので,一部のコアがMax Turboまで引き上げられた状態でも,TDPに余裕があれば残るコアがAll Core Turboのクロックを維持できるようだ。
4コア以上に負荷がかかる状態だと,一部のコアが定格の3.6GHzにまでクロックを落としていくが,これはTDPの余裕がなくなったためだと推測される。
いずれにせよ,X6 1090Tとの違いは一目瞭然で,4.2GHzや3.9GHzというTurbo時のクロックがしっかりと記録されているのが最大の見どころということになるだろう。FXプロセッサでは秒単位でターボモードに入り続けているわけで,第1世代でほとんど効果のなかったTurbo COREが第2世代で意味のあるものになった理由は,ここに求めることができそうだ。
 |
ところで,グラフ21,22で,経過時間の刻み方に違いがあると気づいただろうか。これはExcelの処理をミスした……わけではもちろんなく,FXとPhenom IIとで,外部から取得できるクロック値取得方法周りに違いが生じているため,こういう結果になっている。一言でまとめるなら,「CPUの仕様によるもの」である。何か意図的に変化を加えているわけではないので,その点はご容赦を。
ゲーム用途以外のところになら
可能性があるFX
 |
FXプロセッサで採用されるBulldozerアーキテクチャは,「コアをシンプルにしてコア数を増やす」という思想の下で設計されている。コアあたりの回路規模が小さくなると,コアあたりの性能は必然的にやや落ちるが,それでもコア数を増やして,並列処理性能を引き上げようという方向性だ。
コアがシンプルになったため,コアあたりの演算性能はPhenom IIよりも確実に下がったが,一部の整数演算系のテストでは高スコアをマークしたりもするなど,AMDが頑張ってシンプルなコアの性能を引き上げようとした形跡も,今回のテストからは見て取れる。
しかし,今回テスト結果を示したPCMark 7で想定されるような一般PC用途や,それこそ4Gamerで取りあげるようなPCゲームでは,依然としてシングルスレッド性能こそが最も重要だ。そしてその意味において,Core Microarchitectureとの比較だけでなく,K8(K10)アーキテクチャを採用したX6 1090Tと比べても下回るスコアを示すFX-8150をあえて選ぶメリットは,ゲームをはじめとした一般PC用途では見出せない。
いずれにせよ,いまのまま競合と対抗していくというのであれば,早急に定格動作クロックを5GHz,6GHzへと引き上げていくしかないが,FX-8150は負荷がかかると消費電力が急増し,オーバークロック設定を行おうものなら,いとも簡単にTDP 200Wクラスへ達することが,4Gamerのテストで明らかになっている。おそらく,クロックを矢継ぎ早に引き上げていくというのは,まず不可能だろう。
ただ,まったく光が差していないわけでもない。
確かに一部のリソースを2コアで共有するペナルティはあるのだが,それでもBulldozerモジュールは,HTTよりも並列処理時の性能低下が少ない。つまり,OSから見たCPUコア数を増やしていくときに,Intelよりも性能面での犠牲が少ないのだ。コアを小さくしているので,実装コストが少なく済むのもメリットといえる。4Gamerとはあまりにも無関係なのでテストする予定もないが,複数のトランザクションを多数のプロセス&スレッドで処理するサーバーでは,この特性がコストパフォーマンスの面で有利となるかもしれない。
そしておそらく,現行のFXが進むべき道は,おそらくサーバー向けCPUと同じところ,つまり,コア数勝負の世界しかない。Bulldozerモジュールを採用する予定の次世代Fusion APU「Trinity」(トリニティ,開発コードネーム)では,モジュールの小ささを利用して,限られたダイサイズでよりコア数の多いGPUを組み合わせるといった展開も考えられるが,「デスクトップPC向けフラグシップCPU」としてのFXでは,そうもいかないからである。
AMDは当初,FXをゲーマー向けCPUとして訴求していたが,「そうでない」ことは明らかだ。ならば,エンコードのように,コア数が効いてくる用途をアピールしたほうが,受け入れられやすいのではなかろうか。さらに言うなら,サーバー向けにOpteron 6200シリーズとして発表している16コアの製品を,ビデオのエンコードマニア向けとしてデスクトップPC市場へ投入したほうがよさそうに思える。
ゲーマーとしては,「Fusion APUとメニーコアFXで,Intelが持っていない市場を狙う」という方向性をAMDに期待しつつ,当面は,足音が少しずつ聞こえてきた次世代GPUシリーズ「Southern Island」(サザンアイランド,開発コードネーム)を待つのが正解だろう。
- 関連タイトル:
 AMD FX(Zambezi)
AMD FX(Zambezi) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー