









レビュー
デスクトップPC向けLlano「A8-3850」レビュー,CPUコア編
A8-3850/2.9GHz
 |
開発コードネーム「Llano」(ラノ)として知られてきたA-Seriesにおける最大の強みは,Radeon HD 6000のブランドを冠した強力なGPUコアを統合している点にある。そして,その性能に関しては「GPUコア編」としてレビュー記事を用意しているが,では,CPUコアやメモリ周りの性能はどれほどのものに仕上がっているのだろうか。本稿では「CPUコア」編として,「GPUコア周り以外」に焦点を当て,A8-3850を掘り下げてみたい。
製品概要とGPUコア編のレビューは,下記のリンクからチェックしてもらえればと思う。
A-SeriesのCPUコアは
K10系「Stars」の改良版
 |
| A-Seriesのパッケージは905ピンのFM1 |
 |
| 対応ソケットはSocket FM1。リテンションモジュールはSocket AM2&AM3世代と互換性があるため,CPUクーラーを“APUクーラー”として使い回せる |
1つの半導体上にCPUコアとGPUコアが載るのだから,従来のAM3パッケージ(≒Socket AM3)との互換性が失われるのはむしろ当然。PGAの中央部にピンのない箇所が設けられるなど,見た目にもAM3パッケージとは異なるものになっている。
そのほか,モデルナンバーによって統合されるGPUコア数に違いがあるとか,GPUコアにはRadeon HD 6000系のモデルナンバーが与えられており,今回入手したA8-3850だと「Radeon HD 6550D」になっているとか,組み合わされるチップセットが,27日に先行発表された「AMD A75」「AMD A55」の両FCH(Fusion Controller Hub)であるとか,AMD A75はUSB 3.0コントローラを内蔵しているとか,とにかくGPUコア周り,そしてとチップセットの話題は事欠かないA-Series。
ただ,ことCPUコアに関していうと,実のところ,大した情報は公開されていなかったりもする。
 |
 |
さらに,AMDからこれまでにもたらされている情報では,A-Seriesにおいて,整数演算用の除算ユニット(DIV Unit)が追加され,整数の除算が従来比最大2分の1のクロック数で実行できるようになったとされている。除算はパイプライン実行が難しく実行効率を上げにくいため,除算のスループット改善が図られたのだろう。
そのほか,プリフェッチやロード/ストア/バッファのウインドウ拡大といった細かな改良が加えられているとも伝えられているが,残念ながら,これらの詳細はほとんど公開されていない。
いずれにしても,「改良版Starsコア」である以上,その「改良」が目に見える違いとなって現れるのかどうかが,本稿の検証ポイントトになるわけだ。
GIGA-BYTE製のA75マザーを利用して検証
Phenom II X4&Athlon II X4はダウンクロック
というわけで,テストのセットアップに入りたい。今回テストに用いたマザーボードは,AMD A75(以下,A75)チップセットを搭載したGIGA-BYTE TECHNOLOGY製ATXマザーボード「GA-A75-UD4H」。4Gamerで独自に入手して6月20日の記事で情報をお伝えした個体は開発途上版だったが,今回用いるのは,日本ギガバイトから貸し出しを受けた製品版である。
 |
 |
なお,テスト時点ではマニュアルが未完成だったが,2本用意されたPCI Express x16スロットは,Socket FM1に近いほうだけを使ったときはPCI Express 2.0 x16で,2本使ったときはPCI Express 2.0 x8 ×2で動作するようだ。
 PCI Expres x16スロットを2本搭載し,CrossFireXに対応 |
 Serial ATAは6Gbps×5がチップセットレベルでサポートされる |
 VRMは8+2フェーズ |
 本体背面はシンプルだ |
 |
そのため今回は,GPUコア編のレビューと同じく,G.Skill International Enterprise製のPC3-14900モジュール2枚セット「F3-14900CL9D-8GBSR DDR3-1866 8GB」を,秋葉原のPC&PCパーツショップであるパソコンショップ アークの協力で用意した。今回は,4GBモジュール2枚を用いるため,A8-3850で用いるグラフィックスメモリサイズは大きめの1GBにBIOSから設定している。
A8-3850がDDR3-1866に対応するため,今回はこれで利用すべく,PC3-14900モジュールを用意したというのは先に述べた。今回は,それ以外に「共通のメモリ設定」としてDDR3-1600も採用し,A8-3850ではDDR3-1866時とDDR3-1600時の両方でテストすることにしている。
「残るCPUはDDR3-1333かDDR3-1066対応だろう」というご指摘はもっともなのだが,今回テストに用いたGIGA-BYTE TECHNOLOGY製の「AMD 890GX」および「Intel Z68 Express」マザーボードでは,いずれもF3-14900CL9D-8GBSR DDR3-1866 8GBを差すと自動的にDDR3-1600動作になったことと,X4 645でもDDR3-1600動作が安定したことを受けて,DDR3-1600で揃えた次第だ。揃えるのが目的なので,この点はご了承のほどを。なお,DDR3-1600時のレイテンシ設定は共通である。
 |
そのほかテスト環境は表1のとおり。今回,比較対象としては「Phenom II X4 965 Black Edition/3.4GHz」(以下,X4 965BE),「Athlon II X4 645/3.1GHz」(以下,X4 645),そして,4コア4スレッド動作ということで,「Core i5-2500K/3.30GHz」(以下,i5-2500K)と用意。X4 965BEでは,BIOSに「14.5倍」という設定がなかったため「AMD OverDrive」から,X4 645とi5-2500KはBIOSから,それぞれ動作倍率を変更し,動作クロックをA8-3850と同じ2.9GHzに固定している。
以下,オーラスの消費電力計測を除き,「Cool’n’Quiet」や「Enhanced Intel SpeedStep Technology」といった電力機能も無効化して,すべて動作クロックの変動を意識する必要をなくしているので,この点は注意してほしい。
なお,GPUコア編では,AMDから全世界のレビュワーに配布されたドライバ「8.862-110607a-120249E」をできる限り統一して用いたが,本稿ではテスト開始タイミングの都合により,A8-3850以外では「Catalyst 11.6」を用いている。8.862-110607a-120249Eは,そのバージョン的にCatalyst 11.6ベースと思われるため,大きな問題はないはずだが,念のためお断りしておきたいと思う。
 |
PC総合ベンチマークテストでは
同クロックのPhenom II X4を上回る
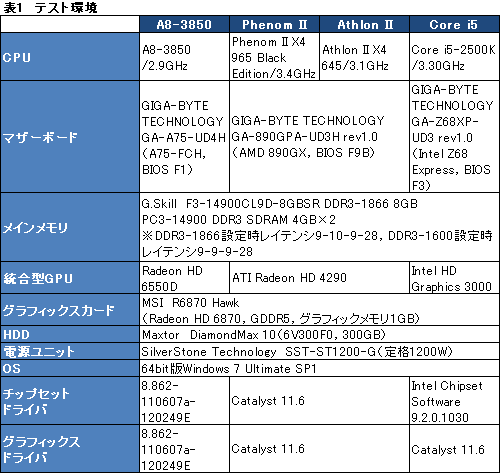
さて,まずは総合ベンチマークで大まかな特性をチェックしてみよう。今回は,Futuremarkが2011年5月にリリースした「PCMark 7」(Version 1.04)を用いる。
PCMark 7の概要は解説記事をチェックしてほしいと思うが,ここでは,用意した4つのプラットフォームすべてで,APUおよびCPU,チップセット側のグラフィックス機能のみを使った場合と,別途R6870 Hawk(以下,HD 6870)を差して,グラフィックス周りの仕様を揃えた場合との両方でスコアを取得することにした。
その総合スコアがグラフ1だ。20前後のテストを行った結果から算出したスコアなので,統一的なパターンは見いだしづらいが,それでも,動作クロックとメモリアクセス仕様,そしてGPUのスペックを統一したときのスコアで,A8-3850がPhenom II X4をわずかながら上回ったのは注目に値しよう。同じクロックで比較する限り,Athlon II X4どころか,Phenom II X4よりCPU性能が高いかもしれないわけである。
ただ,AMD 890GXの統合型グラフィックス機能である「ATI Radeon HD 4290」(※グラフ中は「HD 4290」と表記。以下同)と組み合わせたX4 965BEやX4 645のスコアが芳しくなく,同条件のA8-3850比で10%程度低いスコアに留まっているところからは,HD 4290のグラフィックス性能が足を引っ張っている可能性も見て取れよう。まだ確定的なことは言えそうにない。
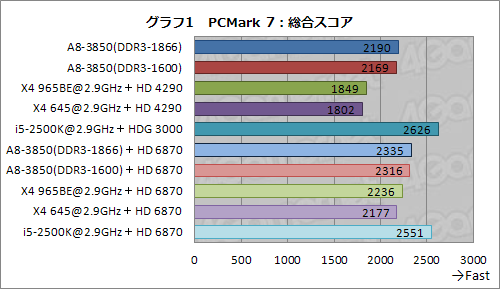 |
ところで,グラフ1において総合スコアが最も高かったのは,グラフィックスカードを差さなかったi5-2500Kだが,これには裏がある。
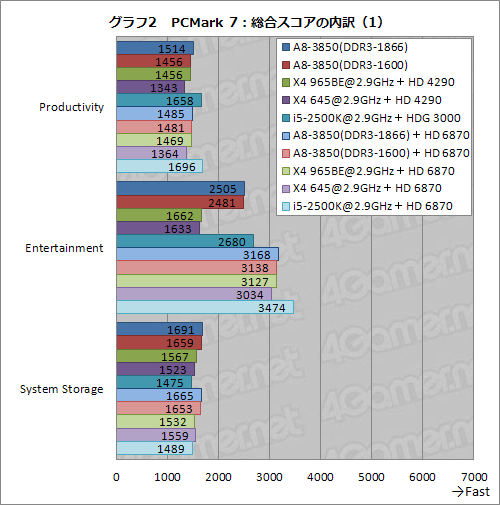
グラフ2,3は,総合スコアを「Productivity」「Entertainment」「Creativity」「Computation」「System Storage」の5分野へと細分化させたものだ。そのうち,Creativityの一部とComputationの全テストに動画のトランスコードが含まれているのだが,i5-2500K,というかSandy BridgeコアのCPUでは,統合型グラフィックス機能が有効な場合,自動的にハードウェアトランスコーダ「Intel QuickSync Video」(以下,QuickSync)が有効になるため,飛び抜けたスコアを叩き出してしまうのだ。
 |
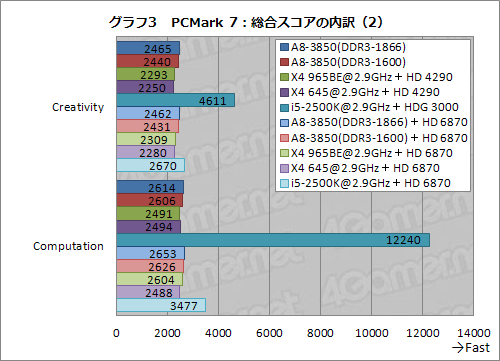 |
つまりCreativityとComputationだと,ハードウェアトランスコード機能を持たないAMD製プロセッサが圧倒的に不利。PCMark 7がアップデートされ,VISION Engine Control Center(≒Catalyst Control Center)から利用できる「AMD Video Converter」に対応してくれれば状況は変わるのではないかと思われるが,今のところはいかんともしがたい。
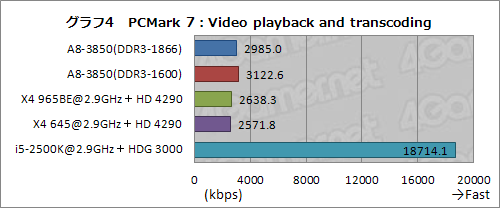
では実際のところ,トランスコード周りにはどの程度の違いがあるのか。今度はいずれのプラットフォームでもグラフィックスカードを差さない条件で,トランスコード関連のテスト項目データ「Video playback and transcoding / Video transcoding - downscaling」(以下,Video playback and transcoding)のスコアを抜き出して,グラフ4にまとめてみた。
Video playback and transcodingは,「動画を再生しつつサイズを縮小しながらトランスコードを行ったとき」のスループットを表している。
ここで用いられるのは,i5-2500KだとQuickSyncで,AMD製プロセッサではソフトウェアトランスコーダ。正確を期すと,AMDプラットフォームでも再生にはUVDなどによるハードウェア支援が用いられるが,トランスコードがハードウェア処理されているのと比べれば,その効果は限定的。結果として,こういう大差になっているわけである。
ところで,AMD製プロセッサだけで比較すると,A8-3850のスコアがX4 965BEやX4 645と比べてやや高めのスコアになっているのも分かるだろう。グラフィックス機能などテスト条件が異なるとはいえ,ソフトウェアトランスコーダが機能しているという点では同じなので,「A8-3850におけるCPUコアとGPUコアとの統合効果が出ているのかも?」という気はする。
 |
グラフ2に戻ると,動画のトランスコードを含まず,テキスト編集とWebブラウジングが主体のProductivityだと,メモリクロックまで揃えたA8-3850とX4 965BEが同じスコアで並んでいる。X4 645よりは高スコアだ。L3キャッシュを持つ格上のX4 965BEと対等に戦えるのは2D描画の高速化の効果かもしれないが,その点については次のグラフ5,6で実際のところを確認できる。
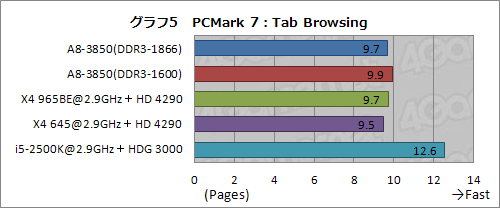
グラフ5の「Tab Browsing」は,Webブラウザのタブ切り替え速度を示したもので,グラフ6の「Text Editing」はワープロソフトによるテキスト編集速度を示したものと考えてもらっていい。いずれもPCMark 7のProductivityスコアから個別に抜き出したものだ。
AMDプラットフォーム内で比較すると,A8-3850とX4 965BEにおけるTab Browsingのスコア差は誤差程度。Text Editingだと,L3キャッシュ効果かX4 965BEのスコアが若干高めに出るが,やはり大きな差ではない。いずれにせよ,A8-3850の統合型GPUコアが,これらの操作に与える影響は大きくないらしい」ということが,この2つの結果からは言えそうだ。
 |
 |
なお,ここまでとくに触れてこなかったグラフ2のEntertainmentだが,GPUテストの占める割合が相応に大きいため,GPUコア性能の高いA8-3850が順当にスコアを伸ばす。ただ,CPU負荷の高いゲームアルゴリズム関連テストが含まれることもあって,i5-2500Kを逆転するところまでは行っていない。
以上の結果からすると,A8-3850はGPUが絡まないテスト,具体的にはオフィス系アプリケーションやソフトウェアを使った動画のトランスコードにおいて,従来のAMDプラットフォームと比べ,クロックあたりの性能がやや高い傾向を示すことが分かった。
では,その理由はどのあたりにあるのか? 以降は,このあたりを課題にテスト結果を考察していこう。
Sandra 2011における
GPU関連のテストもチェック
PCの基本性能を推し量る定番のベンチマークスイートといえる「Sandra」。その最新版となる「Sandra 2011.SP3」(Version 17.64,以下 Sandra 2011)では,GPUなどグラフィックス関連のテストも含まれている。3Dゲームを前にしたときの性能はGPUコア編のベンチマークをチェックしてもらうとして,ここでは,3D性能以外の部分について,Sandra 2011の結果を基に分析してみたい。
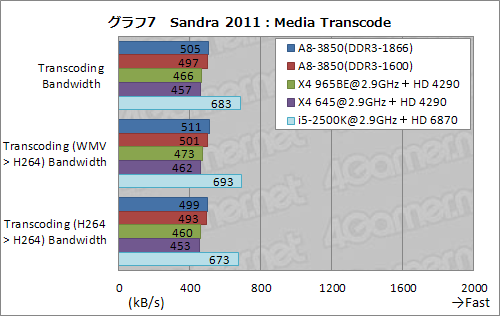
まずは,「Media Transcode」だ。テストすると出てくる3つのスコアのうち,「Transcode Bandwidth」はトランスコード性能の総合スコアで,その残る2つは「WMVからH.264」,「H.264からH.264」のトランスコードにおけるスループットをそれぞれ見るものとなる。
このTranscode Bandwidthでも,i5-2500Kの統合型グラフィックス機能が有効な場合はQuickSyncが使われる。一方,AMDプラットフォームではソフトウェア処理になるため,ここではi5-2500Kもソフトウェア処理させるべく,同製品のみHD 6870を差した状態でテストすることにした。その結果をまとめたのがグラフ7である。
「それでもi5-2500Kのスコアが高い」のはさておくとして,残る4製品では,A8-3850のスコアが高めだ。PCMark 7のVideo playback and transcodingにおけるスコアと共通の傾向といえ,やはりここには何かあるようだ。
 |
 |
「GPUのローカルメモリ」といっても,統合型グラフィックス機能では,システムメモリの一部をCPUとシェアすることになるわけだが,(少なくとも現時点だと)GPUのプログラミングモデル上,GPUとCPUのメモリは分かれているので,GPUのローカルメモリはCPU側のシステムメモリから独立している点に注意してほしい。
さて,Internal Memory Bandwidthだと,A8-3850とAMD 890GXのスコア差が顕著だ。優に2倍を超えているわけだが,これは当然ながら,GPUコアとメモリコントローラとの物理的な距離が近くなった,というか,同じダイに実装された効果である。i5-2500Kが同様の結果を示していることからも,それは分かるだろう。
一方,Data Transfer Bandwidthは「どんぐりの背比べ」といったところ。ただ,グラフには示さなかったが,A8-3850では,CPU→GPUが4.37GB/sなのに対し,GPU→CPUは2.16GB/sという非対称性を示すのが,ほかのテスト対象とは異なっていた。
A-Seriesでは,GPUのバスが二重化され,またCPU側のメモリとGPU側のローカルメモリとの間に共有メモリ領域を設けるなどの工夫が施されていると聞く。そのため,CPU→GPUで4GB/s超えという性能が得られているのだろう。
ちなみに,PCI Express x16接続のGPUだと,Data Transfer Bandwidthのスコアはおよそ5GB/s前後に収まるので,4GB/sというスコアは悪くない。
 |
続いてグラフ9に示す「GP Processing」は,マンデルブロ集合を描くテストで,GPGPU性能を比較したものである。
「Aggregate Shader Performance」はGPGPUとしての総合スコア,「Native Float Shaders」は32bit浮動小数点演算を用いたテストのスコアで,「Emulate Double Shaders」は,エミュレートによる倍精度浮動小数点演算テスト結果となっている。
まず,Native Float Shadersのテストでは,さすがにA8-3850がダントツのスコアを残した。400基もの「Streaming Processing Unit」(以下,SP)――A-Seriesでは「Radeon Core」と呼ばれているが――を搭載するのは伊達ではないようだ。
ちなみにグラフには示していないが,HD 6870だと,同じテストで2GMPix/sというを叩き出すので,A8-3850のスコアはおよそ4分の1弱ということになる。ただ,HD 6870のSP数は1170基。さらに動作クロックはA8-3850比
で1.5倍となる900MHzなので,メモリ周りの違いを加味すると,A8-3850のスコアは相当に頑張っていると述べていいのではなかろうか。
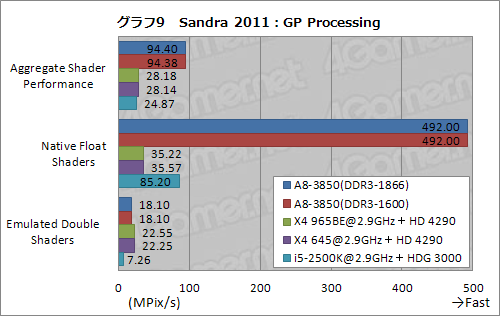 |
なお,グラフ9でやや注意が必要なのは,本テストにおいて,AMDプラットフォームだとOpenCL,i5-2500KだとDirectComputeが用いられているということ。使われる言語が異なるので,単純比較はできない。
いずれにしても,GPUコア周りは,順当に性能が向上していると述べていいだろう。GPGPUとしての利用時も,従来製品と比べて高い性能を期待できるので,活用するソフトウェアが増えてくれば使いでがありそうだ。
コア間の内部転送周りに
改良が見えるA-Series
GPUコア周りの挙動を確認したところで,引き続きSandra 2011を用いて,今度はCPUコアやメモリ周りのテスト結果を見ていくことにしたい。
まずは単純な演算性能を競う「CPU Arithmetic」からだ。CPU Arithmeticの場合,i5-2500Kで強制的にAVX命令セットが使われてしまい,単純には公平な比較ができないため,今回はAMDの4製品のみで比較を行う。
というわけでグラフ10はAMDの4製品におけるテスト結果である。整数演算性能を示す「Dhrystone ALU」ではPhenom IIが最低,Athlon II X4が最高という,意外な結果になったが,いずれによ差はわずか。「整数演算命令でA8-3850が有意に高い性能を持つ」とは,この結果からは言えない。
SSE3を使う「Whetstone iSSE3」も同様。というか,むしろA8-3850は低めだ。このあたりに改良の跡は見られない。
 |
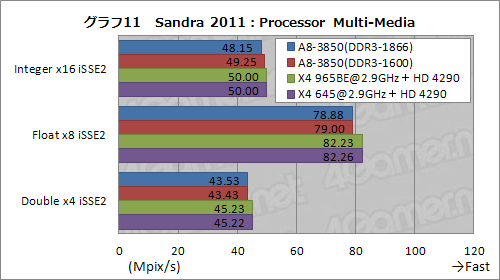
CPU Arithmeticと同じ理由でi5-2500Kを除外した「Processor Multi-Media」でも,テスト結果はProcessor ArithmeticのWhetstone iSSE3と同じ傾向が見られる(グラフ11)。もっとはっきりいうと,A8-3850のスコアは若干低めで,A8-3850のCPUコアに何らかの改良が入っているような様子は,このテストからも窺えない。
Processor Multi-Mediaは,SSE命令セットでマンデルブロ集合の演算を行ってパフォーマンスを見るというテストだが,そこで用いられるALUやSSE系命令の処理能力は,Phenom II X4やAthlon II X4と同じか,やや低いくらいのものしか持っていないようだ。
 |
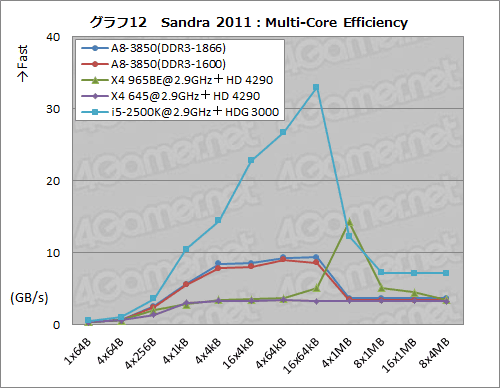
テストしていて「おや?」と思わされたのが,「Multi-Core Efficiency」の結果である。
A-SeriesのCPUコアは,コアごとに独立したL2キャッシュを持ち,コア間で共有されるL3キャッシュを持たないということを今一度確認のうえ,グラフ12を見てほしい。
Multi-Core Effeciencyでは,同じメモリ領域をコア間でアクセスし,コア間のデータ転送速度を見ることになる。そして,コア間で共有されるキャッシュメモリがあるなら,それ経由でデータが受け渡されるので,そういうタイプのキャッシュメモリを持つプロセッサが,本テストでは高いスコアを記録する。i5-2500KやX4 965BEの4x1MBブロックにおけるスコアは,L3キャッシュ(もしくはLast Level Cache)の効果と判断してまず間違いない。
一方,共有L3キャッシュを持たないX4 645では,ブロックサイズが変わっても低いスコアで推移するのだが,それと比べると,A8-3850のスコアは明らかに異なる。4x256B〜16x64kBで高めのスコアを示しているが,これは何を意味するのだろう?
 |
X4 645のL2キャッシュ容量はコアあたり512KB。A8-3850の半分しかないが,そのせいだろうか。だが,キャッシュ容量に依存した結果になるなら,X4 645のスコアは,容量512KBのキャッシュサイズに収まる範囲とそうでない範囲でスコアに変化が出るはずなのに,そうなっていない。
共有L3キャッシュがないCPUにおいてコア間のデータを共有する場合,「L2キャッシュ同士で行うデータのやり取り」がカギになる。あるコアがメモリ領域を書き換え,そのメモリ領域に別のコアがアクセスするとき,「L2キャッシュ間でキャッシュデータの一貫性を保つためのデータのやり取り」が発生して,データの共有が行われるというような形になるからだ。
このことから「A-Seriesでは,L2キャッシュ間のデータ転送速度,そしてキャッシュの一貫性を保つスヌーピング周りが改良された可能性が高い」と言える。GPUを含めたクロスバースイッチが一新されているなど,内部バス周りにはかなり手が入っているので,その効果がL2キャッシュ間のデータ転送速度を押し上げ,Multi-Core Effeciencyの好結果につなげているのだろうと推測できる。
……少し視点を変えて,ここからはメモリ周りを重点的に見てみよう。
まず,やはりAVX命令が使われてしまうのでi5-2500Kを外した「Memory Bandwidth」だが,同じDDR3-1600設定設定で,A8-3850のスコアが従来製品を21〜25%高い帯域幅を実現できている点は要注目(グラフ13)。また,DDR3-1866設定ではさらに高い帯域幅を記録しており,メモリコントローラにも改良の跡が窺えると評してよさそうだ。
 |
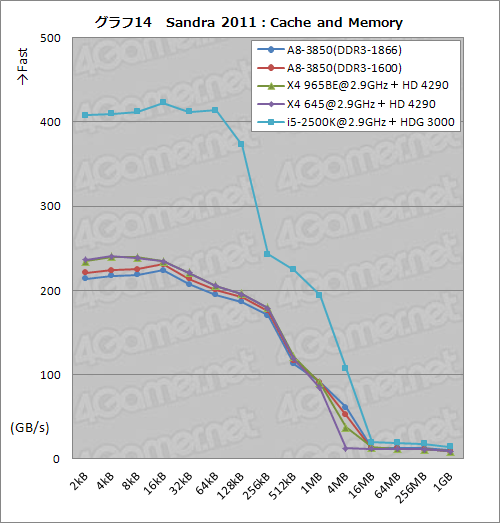
キャッシュおよびメモリの帯域幅を調べるCache and Memoryのスコアをまとめたのがグラフ14だが,見る限り,A8-3850とX4 965BE,X4 645の間にはそれほど大きな違いはない。「L2キャッシュ容量が小さいAthlon II X4だと,4MBブロックでスコアが落ちる」という,ある意味当たり前のことを確認できる程度だ。
ただ,面白いのは,その4MBブロックで,L3キャッシュを持つPhenom IIよりもA8-3850のほうが高いスコアを示していること。このあたりにも何らかの改良が入っているようだ。
 |
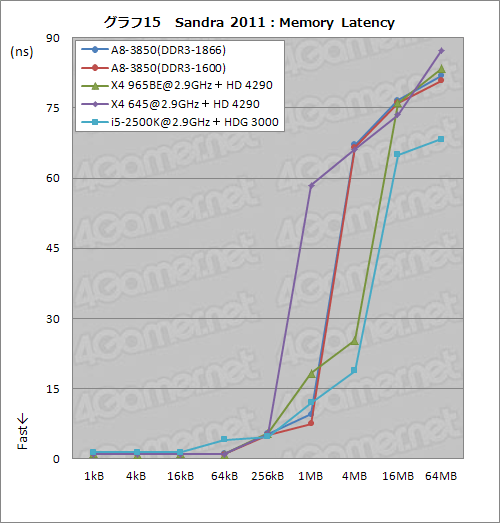
メモリ周りの遅延をテストする「Memory Latency」だと,A8-3850は,L1キャッシュに収まる範囲で1〜1.1ns(グラフ15)。L2キャッシュに収まる範囲内でも,A8-3850はかなり低レイテンシだ。
キャッシュから外れる範囲だと,レイテンシにはバラつきが見られているのも興味深い。今回は基本的にDDR3-1600設定でレイテンシも揃えているが,BIOS設定の外で,何か違いがあるのかもしれない。
なお,DDR3-1866設定時にキャッシュから外れる範囲でレイテンシが増大するのは,そもそもBIOS設定が異なるので当然である。
 |
以上の結果から,A-Seriesが持つCPUコアの演算性能は,Phenom II X4やAhtlon II X4とほとんど変わらず,むしろメモリコントローラや,コア間をつなぐバスの改良こそ,性能面で大きなインパクトを持っている可能性を指摘できそうだ。
それを裏付けるために,もう1つの基礎性能ベンチマークテスト,「AIDA64」(Version 1.80)の結果も見ておきたい。
やはりCPU演算性能は
従来製品とほとんど変わらず
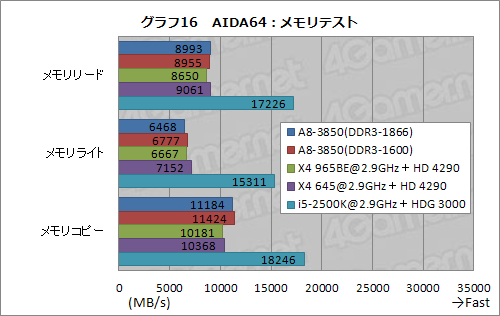
単純な演算性能を見るのに適したAIDA64から,まずはメモリバス帯域幅のテスト結果をまとめたのがグラフ16だ。
Sandraほど分かりやすい違いは生じなかったものの,「メモリコピー」でA8-3850はX4 965BEやX4 645比で10〜12%高いスコアを記録しているのは見て取れるので,やはりメモリ周りに特性差がありそうな結果といえる。
 |
グラフ17は,AIDA64に含まれる整数演算テストのうち,「CPU Queen」と「CPU Photoworxx」の結果を抜き出したものだ。
どちらでも,A8-3850とX4 645はほぼ同じスコア。CPUの演算性能だけでなく,メモリバス帯域幅,そしてマルチスレッド性能がスコアを左右するとされるCPU PhotoworxxでX4 965BEがスコアを伸ばしたのは,L3キャッシュの効果だろう。
 |
対してグラフ18は浮動小数点演算系のテスト結果をまとめたものだが,語ることがないくらい,A8-3850とX4 965BE,X4 645のスコアは横並びである。
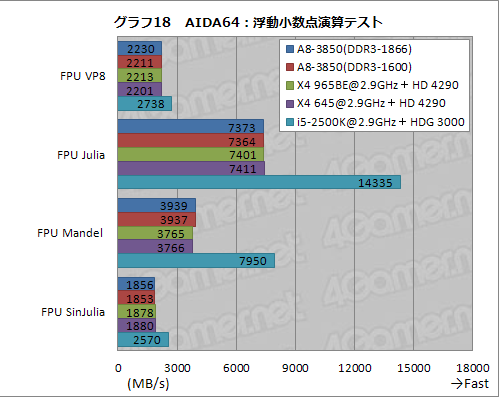 |
以上,AIDA64の結果からも,純粋なCPUの演算性能は,従来のAMD製クアッドコアCPUとほぼ同程度と断じてしまってよさそうだ。
テストによって高めのスコアが出るのは,メモリ周りの改良や,コア間のデータ転送の改良といった,主に足回りの改良によるところが大きいのだろう。「最大6%」かどうかはともかく,IPCの向上は確かに認められるものの,それはCPUコアそのものではなく,足回りの改良による恩恵という理解が正しいと思われる。
Sandy Bridgeほどではないにせよ
A-Seriesの消費電力はかなり低い
震災の影響で省電力が叫ばれる折り,PCにとって消費電力も重要なチェック項目だろう。GPUコア編のレビュー記事では,主にゲームプレイ中の消費電力を計測しているが,本稿では,主にCPUコアを使ったときの消費電力をチェックしてみたい。
テストに用いるのは,ログの取得が可能なワットチェッカー「Watts up? PRO」。今回は,PCの起動後30分放置した時点を「アイドル時」とし,PCMark 7の通し実行時,そしてストレスツール「OCCT」でシステムに100%の負荷をかけ続けたときの消費電力を取得することにした。実使用環境を想定し,アイドル時とPCMark 7実行時については,省電力機能を有効にした場合と無効にした場合とで分けてスコアを取る。また,同じ理由により,PCMark 7のスコアはピークではなく,平均値を取っていることも,あらかじめお断りしておきたい。
なお,前述のとおり,X4 965BEでは,動作クロックを2.9GHzへ固定するためにAMD OverDriveを使っている都合上,Cool'n Quiet(以降,CnQ)を有効化できていないため,CnQ有効時のスコアはN/Aとなる。それを踏まえてグラフ19を見てほしい。
全体的にはi5-2500Kの優秀さが目を引いてしまうのだが,AMDプラットフォーム内では,A8-3850の低消費電力性がかなり優秀だと分かる。とくに,PCMark 7実行時は,X4 645と同程度に収まっており,GPUが高性能になったのを考えるとかなりのお得感がある。32nm High-kプロセスが“効いている”印象だ。
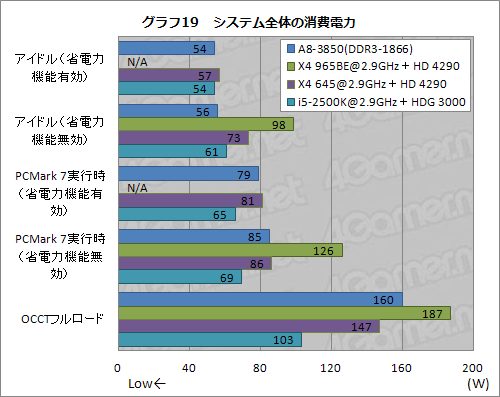 |
個人的には,アイドル時に,CnQの有効無効に関わらず,A8-3850の消費電力がほとんど変わらなかった点に少々驚かされた。「AMD System Monitor」から確認すると,CnQ有効時のA8-3850はアイドル時にCPUクロックを800MHzにまで下げているので,違いが出てもよさそうなのだが,そうなっていないのは不思議である。
A-Seriesの場合,パワーゲーティングをフルに使った省電力設計になっているとのことなので,そのあたりの成果が出ているのかもしれない。
CPU性能に目新しさはなし
あくまでもGPUコアが主役
 |
AMDはA-Seriesで,明らかに「GPU性能推し」の態度を打ち出している。CPU性能はそこそこに,これまでとは異質のGPU性能でユーザーを獲得していく設計なわけで,CPUコアの検証結果がこうなったのも,AMDからすれば織り込み済みなのではなかろうか。
- 関連タイトル:
 AMD A-Series(Llano)
AMD A-Series(Llano) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー