









ニュース
見えてきたAMDの次世代GPUアーキテクチャ。なぜAMDはVLIWを捨てるのか
 |
同社はまず,2011年内の市場投入が予定されている「Southern Islands」(サザンアイランド)の上位モデルで,この次世代GPUコアアーキテクチャを採用。さらに2012年の次次世代GPUファミリー「Central Islands」(セントラルアイランド)ではメインストリームまで採用を拡大し,2013年にはFusion APUへ統合する計画である。
SIMD方式へ戻ることで
GPUとCPUのデータ共有が容易になる
 |
振り返ってみると,ATI Radeon HD 2900 XT以降のRadeonシリーズでは,並列処理できる複数の命令を1つのVLIW命令にまとめ直すことで並列処理性能を高めるアプローチが採られていた。しかし,命令同士に依存関係が多い処理を前にすると,VLIW命令の発行時に無効な命令が多く含まれるようになり,いきおい,演算リソースを使い切ることができなくなって,パフォーマンスが大幅に低下する。これが,ATI Radeon HD 6000に至るまでの,AMD製GPUが抱える大きな弱点だ。
そこでAMDはVLIWを捨て、NVIDIAがFermiアーキテクチャで採用し,旧ATI TechnologiesもDirectX 9世代まで使っていた,よりシンプルなSIMD(Single Instruction, Multiple Data)方式へ戻ることになったというわけなのである。
そんなAMDの次世代GPUアーキテクチャでは,SIMD方式の16-wayベクトル演算器をまとめた「SIMD Unit」4基と,スカラ演算ユニット1基とで構成される「Compute Unit」(以下,CU)が最小単位となる。
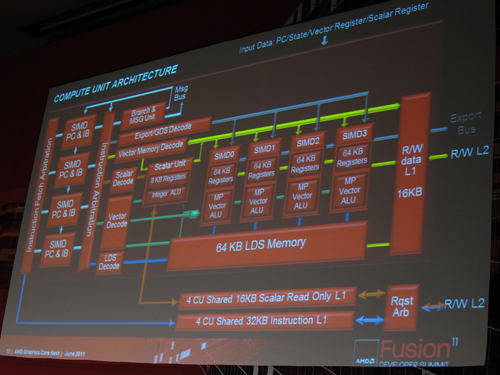 |
CUに搭載されるベクトル演算器は浮動小数点積和算と整数演算をサポートするものになっているため,VLIW5アーキテクチャで採用されているような,超越関数の演算能力を持つ“ビッグSP”的なユニットは用意されない。あくまでも16基のベクトル演算器がひとまとめになった構成ゆえ,32bit単精度で16の同一命令演算を1サイクルスループットで実行可能だ。
スループットは低下するものの,64bit倍精度演算や超越関数演算も,これら16基のベクトル演算器を利用して処理されることになる。
 ベクトル演算ユニットの構成。16基のSIMDベクトルプロセッサが備わっている |
 ベクトル演算ユニットは命令バッファリングとフェッチングに対応 |
また,スカラ演算ユニットがフル機能を備えるものになっていることも,次世代GPUコアアーキテクチャの特徴といえるだろう。
スカラ演算ユニットは,SIMD Unitを効率よく機能させられるよう,CU内の分岐やディスパッチなどといった流れ全般や,AMD製GPUの演算実行単位である「Wavefront」(※64スレッドをまとめたもの。32スレッドをまとめたNVIDIAの「Warp」と同様の演算実行単位)の制御を行う。
 CUは,ベクトル演算ユニットに加えてスカラ演算ユニットも搭載している |
 スカラ演算ユニットの構成 |
AMDの関係者は,「従来のアーキテクチャにおいて,SIMD Unitで処理するデータを変更するときは,ホストCPUからGPUへのデータ転送を必要とする『Clause』が生じることがあった。これが次世代GPUコアアーキテクチャでは,スカラ演算ユニットがこの役割を果たすようになるため,パフォーマンスが向上する」という言い方で,フルスペックのスカラ演算ユニットを搭載するメリットを表現している。
Clause(クローズ)はそのまま訳すと「節」や「条項」といった意味だが,ここでは「各ユニットで“処理”するデータ群」といったところである。
なので,上の発言を噛み砕くなら,「SIMD Unitで処理するデータ群を変更するときにはこれまで,CPU側でデータをまとめる必要があった。しかし次世代GPUコアアーキテクチャでは,スカラエンジンがこの役を果たすようになるので,GPU内部だけでより効率的なデータ処理ができるようになる」といった感じになるだろうか。
従来のアーキテクチャでは,VLIWで扱えるデータ量が大きく,また,SIMD Unitを構成するGPUのコア数も多かったため,Clauseが重要だった。ただ,CPUに新しいClauseをまとめさせた場合,オーバーヘッドになっていたのも事実なので,次世代GPUコアアーキテクチャでは,このオーバーヘッドの解消が図られるというわけである。
 |
命令発行ユニットはCUごとに搭載され,CU内のSIMD Unitごとにプログラムカウンタと命令バッファも用意されているため,SIMD Unit単位で異なる処理が実行可能だ。
 |
なお,AMDが2011年6月の「AMD Fusion Developers Summit 11」(以下,AFDS11)で公開したブロックダイアグラムだと,テクスチャユニットの実装場所は確認できないが,同社でグラフィックスアーキテクチャの開発を統括するEric Demers(エリック・デメル)CTOは,CUごとに搭載されていると説明している。
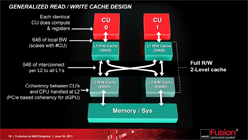
 マルチレベルリード&ライトキャッシュのアーキテクチャ概要 |
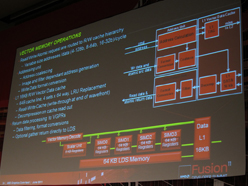 ベクトル演算ユニットにおけるメモリオペレーションを示したスライド |
また,次世代GPUコアアーキテクチャでは,GPU側にアドレス変換キャッシュ(Address Translation Cache,以下 ATC)を搭載しており,CPUとGPUが同じ仮想アドレスに64bitポインタでアクセスできるようになることも大きな特徴だ。
まず,CPU側のIOMMU(Input/Output Memory Management Unit)がGPU側の仮想メモリアドレスを物理アドレスに変換。続けて,GPU側のMMU(Memory Management Unit)がATCを用いてCPUの仮想アドレスを物理アドレスに変換すると,OSがIOMMUとMMUを管理下に置けるようになるため,仮想メモリ空間上でCPUとGPUのデータ共有を実現できるという流れである。
さらに,GPUとCPU間でのキャッシュのスヌープ(Cache Snooping)も,次世代GPUコアアーキテクチャではサポートされる。
キャッシュのスヌープとは,プロセッサキャッシュのデータ書き換えに伴うシステムメモリ上のデータ更新があったとき,同データを共有しているほかのプロセッサコアに通知し,そのデータを参照する必要がある場合はメモリ上のデータをキャッシュに再読込する仕掛けのこと。これにより,複数のプロセッサコアが仮想メモリ空間上のデータを共有したときでも,「ある1つのコアがメモリデータを書き換えてしまってデータ共有に不整合が生じる」ことが防がれるため,CPUとGPUのよりシームレスな連携が実現できるのだ。
ちなみに,IOMMUはAMD製CPUにおける仮想メモリ管理ユニット名で,Microsoftも同様の呼称を用いているが,「Intel製CPUでVT-dにあたるもの」と説明したほうが分かりやすい人もいるだろう。
 |
これらのアーキテクチャ拡張は,一にも二にも,AMDが提唱する「Fusion System Architecture」(以下,FSA)への最適化を果たし,GPUによる汎用演算処理の効率化を図るためのものだ。かつてCPUのコプロセッサとして活躍していた浮動小数点演算プロセッサが現代ではCPUに統合された歴史を,AMDはFusion APUにおけるGPUで繰り返してきたわけだが,そういったシリコン上の統合だけでなく,システムアーキテクチャ上でCPUとGPUとが完全に統合されるような環境を作り出そうというのがFSAである。
ヘテロジニアスコンピューティング環境において,CPUとGPUとの連係を高めるには,メモリ内のデータ共有を効率化しなければならない。だがそのためには,メモリ内でデータ共有の一貫性を保つ必要があり,CPUかGPUのどちらか一方が共有データを書き換えてしまうと,データの不整合が生じ,アプリケーションの動作に大きく影響してしまう。
そのため,GPUを使う今日(こんにち)的なアプリケーションでは,CPUと共有するデータを,グラフィックスメモリなど,GPUから直接管理するメモリスペースにコピーしたうえで利用するような仕組みになっている。CPUやチップセットの統合型グラフィックス機能で,システムメモリの一部をグラフィックスメモリとして使うとき,メモリアドレスがCPU用とGPU用とに分けられているのはよく知られているが,このときも,GPUが使うデータはGPUのメモリアドレス空間へコピーすることで,データの共有が図られているのである。
また,単体グラフィックスカードの場合でも,PCI Expressリンクを介してシステムメモリにアクセスする必要が生じ,これがCPUとGPUとのシームレスな連携を妨げる大きな要因となっているが,AMDの次世代GPUコアアーキテクチャでは,この部分に大きくメスが入ることになるのだ。
未だ不明な部分の多い
3Dグラフィックスアーキテクチャ
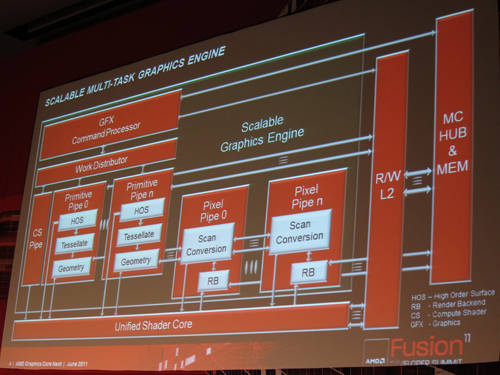
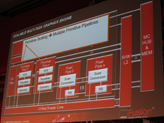
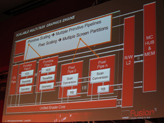
気になる3Dグラフィックス周りでは,テッセレータやジオメトリ演算を担当するプリミティブパイプ(Primitive Pipe)と,ラスタライザのスキャンコンバータおよびROPを備えたピクセルパイプ(Pixel Pipe)を,従来製品よりも多く搭載して性能向上を図ることが明らかになっている。
 |
 |
 |
 |
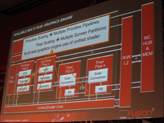 |
もう1つ重要なのは,AMDが次世代GPUコアアーキテクチャで「Asynchronous Compute Engine」(非同期コンピュート・エンジン)を搭載することだ。簡単にいえば「GPUコアのマルチタスク対応」であり,グラフィックス処理を行っているときでも,一部のSIMDユニットを使って,物理演算やポストプロセスといったDirectComputeの処理を効率よく動作させられるようになると考えておけばいいだろう。
 |
 |
冒頭でも紹介したとおり,Demers氏は,この新GPUアーキテクチャを,2011年内に市場投入する製品で採用する計画とのこと。これはつまり,Sounthern Islandsの開発コードネームで知られる次世代GPUシリーズの一部で新アーキテクチャが採用されることを意味するわけだが,氏はCaymanコア投入時の遅れを例に「来年初頭にずれ込む可能性もゼロではない」としていることを心に留めておきたい。
「なら,Fusion APUではいつか」だが,AMDで次世代GPUの新アーキテクチャ開発を担当しているMike Mantor(マイク・メンター)上級研究員は,拡張版「Bulldozer」コアを統合して2012年に市場投入されると見込まれるメインストリーム市場向け次期Fusion APU「Trinity」(トリニティ,開発コードネーム)について「Caymanと同じVLIW4アーキテクチャを採用する」と明言している。そのため,2012年中の話にならないことだけは確かだ。
Fusion APUは,1年ごとの刷新が予告されているので,2013年と見ておくのが無難だろう。
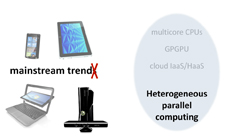
ヘテロジニアスコンピューティングに向けて
プログラミング環境の整備に注力するAMD
AMDがGPUコアアーキテクチャの大規模な変更へと積極的に乗り出した背景には,同社の目指すFusionをシステムやアーキテクチャレベルでも加速する必要性の存在が挙げられる。
 |
その意味で,AMD A-Seriesと次世代GPUコアアーキテクチャは,メインストリームPC環境をヘテロジニアスコンピューティング時代へ加速させる足掛かりとも言えるのだ。
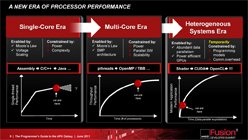 PC性能を向上させ続けるためにCPUとGPUがシームレスに連係できるヘテロジニアスコンピューティング環境への移行が必須だが,プログラミングの難しさがネックとなる |
 Rogers氏によれば,ヘテロジニアスコンピューティング環境を普及させるには,アーキテクチャレベルでの環境整備が不可欠とのこと |
しかし,ヘテロジニアスコンピューティングへと移行させるには,乗り越えなければならないハードルが数多く存在する。
例えば,GPUを使った演算処理を実現するためには,DirectComputeやOpenCLなどを使ってプログラミングする必要があるが,これらは「熟練したプログラマーでも敬遠したくなる」と言われるほど難度が高いうえ,前述のとおり,少なくとも現時点ではCPUとGPUとでそれぞれ専用のメモリエリアを利用しているため,両者でデータを共有するためには,片方のメモリエリアにある情報をもう一方にコピーして利用しなければならないなど,専用の“お作法”が必要だったりするうえ,その“お作法”がパフォーマンスに与える影響も看過できなかったりする。
AMDの提唱するFSAは,まさにこの問題へ対処するためのものだ。システムアーキテクチャレベルでのFusionとなるFSAを,オープンスタンダードなアーキテクチャとして広めることで,AMDプラットフォームに限らず,ほかのプラットフォームでも,CPUとGPUの連係を高めたヘテロジニアスコンピューティング環境への移行を加速させようというのが,AMDの計画である。
さてRogers氏は,FSAが広がっていくのに必要不可欠な要素として,APUのエコシステム(ecosystem,ここでは関係企業の収益構造)を例に,下記の5項目を挙げている。
- プログラミングの容易さ
- 最適化の容易さ
- CPUとGPUのロードバランスの図りやすさ
- 優れたパフォーマンス
- 低い消費電力
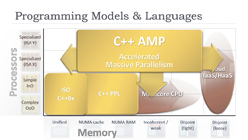
氏はこのなかでも「プログラミングの容易さ」に重点を置き,「これまでのヘテロジニアスシステムでは,Cgなどのシェーダ言語や,CUDAなどといったハードウェア特化型言語から,オープンスタンダードなOpenCLなどへの移行が進んできた」と説明しつつ,「これはあくまでも一時的なものだ」とする。熟練したプログラマーでないと手を出せないOpenCLやDirectComputeといったドライバベースAPIのプログラミング環境は,Microsoftが開発を表明したGPU向けC++拡張「C++ AMP」(AMP:Accelerated Massive Parallelism)によって,より身近なものになるというのが,Rogers氏の見解だ。
 |
 |
 |
 |
 |
 |
で,C++ AMPとは一体何なのかというと,一言でまとめるなら,DirectXプラットフォーム,つまりDirectCompute上にヘテロジニアスプロセッサ処理環境を構築するもの。GPUとCPUとの機能差を吸収したり,仮想メモリによるメモリの抽象化をサポートしたりすることで,CPUとGPUとのシームレスなデータ連係を可能にすると謳われるプログラミング言語拡張環境である。
MicrosoftでC++ AMPの開発を担当するDaniel Moth(ダニエル・モス)氏によれば,「GPUコンピューティングを可能にするC++ AMPをVisual Studioに統合すると,CUDAやOpenCLなどのシェーダ言語を学ぶ必要がなくなるので,より多くのプログラマーがGPUを活用できるようになる」とのことだ。
 |
 |
Fusion System Architectureの
キモとなる「FSAIL」&「JIT」
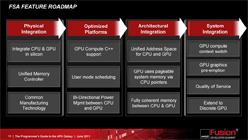 |
プラットフォームの最適化に向けてAMDがまず始めるのは,GPUプログラミング環境の整備。OpenCLやDirectComputeに向けて用意されていた「AMD x86 Open64 Compiler」をC++ AMPへと対応させるほか,複数世代のGPU命令セットへ透過的なアクセスを可能にする新しい中間レイヤー兼中間言語「FSAIL」(Fusion System Architecture Intermediate Layer/Language)と,ランタイムコンパイラたる「AMD JIT」(JIT:Just In-time Compiler,以下 JIT)を提供することで,よりシームレスにGPUとCPUが連係できる環境を作り出す計画だ。
並行して,ソフトウェアパートナーとも協力し,既存のアプリケーションをヘテロジニアスコンピューティング環境へ移植するプラットフォームの提供にも力を入れるとしている。
 AMDはFSAをオープンプラットフォームとして,ハードウェアベンダーやOSベンダー,ミドルウェアデベロッパ,ソフトウェアデベロッパなどに提供していく |
 FSAのカギを握る中間レイヤーとなるFSAIL。JITによってGPUだけでなくCPUも抽象化し,メモリ空間の共有や,マルチプラットフォーム対応を容易にする |
 |
| FSA対応プログラムは,リアルタイムにJITがGPUのネイティブ命令セットに変換し,実行できる |
 |
| JITと仮想技術とを組み合わせると,ハードウェアやソフトウェアの互換性が高まる。ただし,中間レイヤーの存在がオーバーヘッドとなり,フルパフォーマンスを引き出しにくくなるデメリットもあるとも説明された |
FSAに対応したプログラムは,JITがリアルタイムでGPUのネイティブ命令セットに変換して実行するため,既存のGPUとの互換性だけでなく,将来登場するであろうGPUでも同様にプログラムを実行できるようになる。また,FSAILによって,OpenCLやDirectComputeなどといったドライバ依存のプログラミング環境から脱却でき,逆に,1つのプログラムでOpenCLやDirectComuteといったマルチプラットフォームへ対応するのが容易になる。
AMDでJITの開発を担当するGang Chen氏などは,「最新のゲームを古いGPUで動かせるようにしたり,逆に古いゲームを最新プラットフォームで動作させることもできるようになる」という表現を行っていたほどだ。
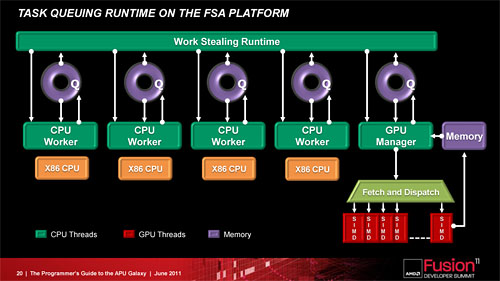 FSAによって,アプリケーションはCPUと同じようにGPUを扱えるようになる |
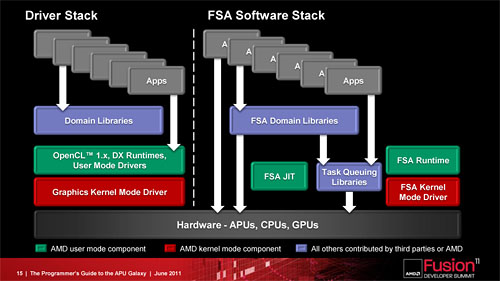 これまでのドライバモデルによるGPUコンピューティング環境(左)とFSAのソフトウェアスタック(右)の違い。アプリケーションがより透過的にCPUやGPUを活用できるようになる |
 |
 |
……と,ここまで読み進めた読者は気づいたのではないかと思うが,AMDが目指しているヘテロジニアスコンピューティング環境というのは,必ずしも「スーパーコンピューティングや科学演算がメインターゲットで,PC用途ではビデオ編集などに少し使われる程度」といったものではない。
実際,AFDS11では,PCゲームで積極的に採用されていくという見通しのもと,「ナチュラルユーザーインタフェース」関連の技術がいくつか披露されている。
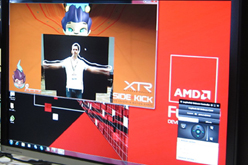
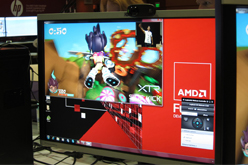
 XTRは,一般的なWebカメラで動作する。赤外線方式の3Dカメラに比べ廉価なうえ,明るい場所でも利用ができるとのこと |
 2Dカメラを使ったジェスチャー認識技術であるXTRのデモを披露するOfer Sadka氏(CTO, Extreme Reality) |
Extreme Realityで技術開発を統括するOfer Sadka(オフェール・サダカ)CTOいわく,「ジェスチャーコントロールとモーションキャプチャ技術を組み合わせることで,2Dカメラでも10箇所以上のコントロールポイントによるゲーム操作が可能になる」。さらに,GPUの演算能力を活用すれば,より分解能の高い2Dカメラを利用できるようになり,マルチプレイや,より多くのコントロールポイントを有効化した,きめ細かな操作が可能になると,ヘテロジニアスコンピューティングへ移行するメリットをアピールしていた。
 |
 |
 |
 |
 |
これまで,GPUコンピューティングという言葉は,ゲームの世界とは縁遠い存在のように語られてきた。しかし,AMDが提唱するFSAは,次世代GPUコアアーキテクチャともども,PCゲームの世界を広げるきっかけになりそうな気配を感じさせてくれており,4Gamerとしても大いに期待したいところである。
ただ,そんなGPUコンピューティングの今後に向けて,MicrosoftのSutter氏がAFDS11で「ヘテロジニアスコンピューティング時代はジャングルの時代」と表現していたことも,憶えておく必要があるだろう。向かう先に何が待ち構えているかは未知数であり,それゆえ,「AMDの望むヘテロジニアスコンピューティング時代」へと移行するには,ソフトウェアデベロッパの協力,そして何より,Fusionに社運を賭けるAMD自体の努力が必要不可欠だ。
業界を見渡すと,IntelやNVIDIA,ARMといった主要ベンダーも,コンピュータの未来がヘテロジニアスコンピューティングにあるという意見では一致している。AMDのFSAと,それに向けた次世代GPUコアアーキテクチャが,どのように足場を築いていくのか,今後の動向には注目していく必要があるだろう。
- 関連タイトル:
 Radeon HD 7900
Radeon HD 7900
- 関連タイトル:Central Islands(開発コードネーム)
- この記事のURL:
キーワード
- HARDWARE:Radeon HD 7900
- HARDWARE
- GPU
- AMD
- Radeon
- ニュース
- 業界動向
- ライター:本間 文
- HARDWARE:Central Islands(開発コードネーム)
(C)2011 Advanced Micro Devices, Inc.
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー