












連載
西川善司の3DGE:GeForceの隠し機能「Tiled Caching」が明らかに。PowerVRの特徴を取り入れて高性能化を図る!?
 |
主なスペックや価格,イベントの概要などはレポート記事で報じたとおりで,
4Gamerでは別途レビュー記事も掲載済みだが,今回は,それら2つの記事で触れていない「2つの技術」を取りあげてみたいと思う。
 |
NVIDIAの自社イベントで技術解説を担当した同社のJonah M.Alben(ジョナ・アルベン)氏によると,実のところTiled Cachingは,GTX 1080 Tiどころか,Pascal世代の新機能ですらなく,Maxwell世代のGPUで導入済みのものとのこと。それをGTX 1080 Ti発表のタイミングで,「実は,こんな機能があってね……」と明らかにしたのである。
もう1つのDual DualFET(もしくは「DualFET
今回は,より重要なTiled Cachingを中心に,NVIDIAが語った新情報をまとめてみたいと思う。
Zバッファのおさらい
重複描画はGPUの処理時間を無駄にする
というわけで,まずはTiled Cachingからだが,いくつか前提となる情報を説明しておく必要があるので,そこから始めよう。現代的な3Dグラフィックス技術を熟知している人にとっては既知の情報となるが,おさらいと思って付き合ってもらえれば幸いだ。
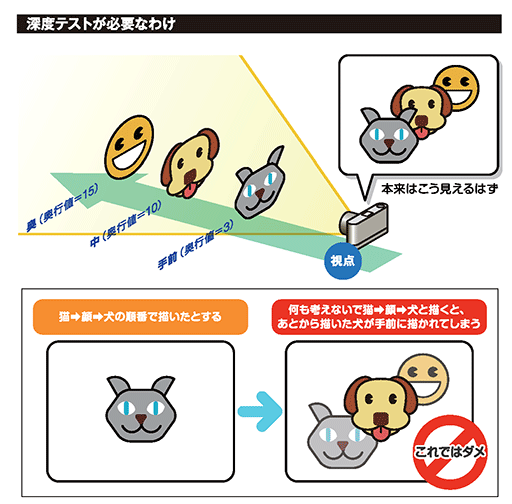
ゲーム画面において,背景とキャラクターを描画する場面を考えてみよう。
一般的なGPUでは,GPUに描画コマンドが送られてきた順に描画は行われる。たとえば,先にキャラクターを描画したあとから,背景の描画コマンドが送られてきた場合,あとから描画する背景は,手前にあるキャラクターを避けて描画しなければならない。こうした処理に有用なのが,「Zバッファ」(深度バッファ)という概念である。
 |
Zバッファとは,描画進行中のフレームにおいて「各ピクセルがどういう前後関係にあるのか」を表すの都合のよい奥行き情報(≒Z座標値)を記録する作業領域だ。
すでに描画済みのキャラクターと,これから描画する背景の描画が重なる場合,Zバッファに記録されているピクセル単位の奥行き値を比較して,上書きしてもよいか,それとも上書きしない(避けるべき)かを判断するのだ。
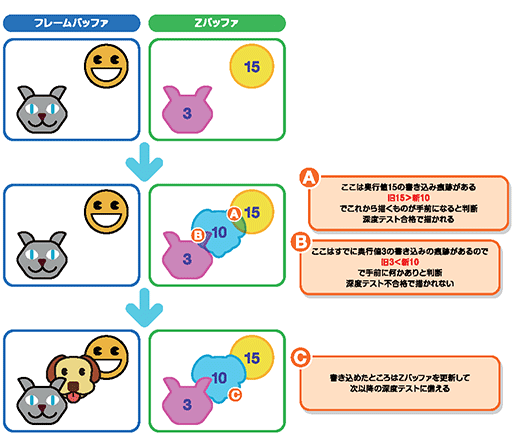 |
ここでは,先にキャラクターを描画してから,次に背景を描画する事例なので,Zバッファがあれば,重複描画を避けることが可能になる。だが,これが先に背景を描画したあとで,キャラクターの描画を行う場合はどうなるか。
描画済みの背景は,キャラクターよりも奥にあるので,すでに描画した背景の上にキャラクターを上書きで描画することになる。つまり背景のあとにキャラクターを描画するケースでは,上書きされた背景部分の描画は,結果として無駄な描画だったことになる。背景に美しい映り込み表現があったり,微細凹凸の法線マッピングが適用されていたりして,高負荷なピクセルシェーダを実行したとしても,塗りつぶされてしまえば,すべて水の泡だ。
このように,処理はしたのに見た目には何の結果も残せなかった描画のことを,本稿では「重複描画」と呼ぶことにする。
タイルベースレンダリングの基本的な概念とは
いきなり話が脱線するようで申しわけないが,Imagination Technologies(以下,
さて,このPowerVR。登場当時は「Zバッファを持たないGPU」としてアピールしていたのだが,ここにはウソが混じっている。PowerVRも,Zバッファにあたるものは持っているのだ。
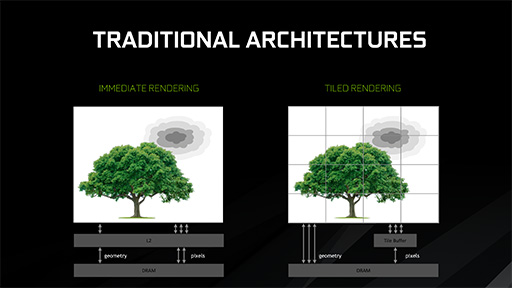
PowerVRシリーズは,「タイルベースレンダリング」(タイルレンダリングと呼ばれることもある)というアーキテクチャを採用している。
タイルのサイズは,PowerVRの世代や設定によって異なるのだが,おおむね16×16ドットや,32×32ドットの矩形を1タイルとして扱う。そして,1920×1080ドットの画面をレンダリングする場合なら,画面全体を横60×縦34個のタイルに分けて,タイル単位で描画を行う仕組みとなっているのだ。
 |
PowerVRで実際にレンダリングを行うときは,まず最初のレンダリングパスで,シーン内に登場するすべてのポリゴン(ジオメトリ)のレンダリングを,画面(=フレームバッファ)への描画を行わずに実行して,どのタイルにどのポリゴンが配置されるかの情報,ポリゴンリストを作成する。
そして続くレンダリングパスでは,各タイル単位でのレンダリングを行う。各タイルにどのポリゴンを描画するかは,最初のレンダリングパスで把握できているので,その情報をもとに,タイル単位でポリゴンをドットに分解するラスタライズを行うのだ。
ちなみに,タイル単位の描画をいくつ同時に実行できるかは,PowerVR GPUの世代やコア数(シェーダーユニットの数)によって変わる。コア数の多いGPUほど,一度に同時のタイルベースレンダリングを行えることは,容易に想像できるだろう。
ここで,前段でも例に挙げた,背景を描画したあとから,背景の手前にキャラクターを描画するケースを考える。通常のレンダリングでは,無駄な重複描画が生じるのだが,タイルベースレンダリングでは,この重複描画を行わずに描画することが可能だ。
タイルベースレンダリングでは,「どのポリゴンが手前に来るのか」や「どのポリゴンが,他のポリゴンによって上書きされるのか」といったことを,タイル単位で判定する。つまり,Zバッファ処理に相当することを,タイル単位で行っているのだ。
これにより,タイル内の各ピクセルは,どのポリゴンを最終的に描画すべきか確定している。キャラクターで上書きされてしまう背景のピクセルは,背景描画用のピクセルシェーダを実行せずに,キャラクターを描画するピクセルシェーダだけを実行することが可能になるというのが,タイルベースレンダリングの大きな利点なのだ。
さて,この一連の工程で行われるポリゴンの奥行きや重なりを確認する実質的なZバッファ処理には,GPU内蔵の高速なメモリ「On-Chip Depth Buffer」を使用する。つまり,この高速メモリは事実上,タイルサイズのZバッファであるのだから,PowerVRの都市伝説「PowerVRはZバッファを持たない」は,半分正解だが半分間違いといったところか。
ここまでの説明で,Zバッファの基本と,PowerVRのタイルベースレンダリングでも,Zバッファに相当する処理があることは把握できたと思う。だが,結局はZバッファを使うのなら,タイルベースレンダリングのメリットはどこにあるのだろうか。
一般的なGPUの場合,Zバッファはグラフィックスメモリ上に置かれる。つまりZバッファの処理は,グラフィックスメモリへのアクセスを必要とするわけだ。
一方,PowerVRのタイルベースレンダリングで行う「タイル単位のZバッファ処理系」は,GPU内部のキャッシュメモリ上で行われる。つまり,グラフィックスメモリ上にZバッファを持たないため,グラフィックスメモリへのアクセスを減らせるのだ。GPUの外にあるグラフィックスメモリへのアクセスと,GPUコア内部のキャッシュに対するアクセスで,どちらが高速かは明白だろう。
 |
とはいえ,タイルベースレンダリングには弱点もある。
先述したように,タイルとジオメトリの対応を計算するためには,フレームバッファに描画しないジオメリレンダリングをプリプロセス(前段処理)として実行する必要があるのだが,この工程には,普通にグラフィックスメモリのアクセスがともなう。
1フレームあたり,1000万ポリゴンを超えるほどの描画を行うこともある現代のゲームグラフィックスにおいて,ジオメトリデータの読み出しは相当なメモリアクセスが必要だ。「タイルベースレンダリングによる性能面での利点は小さい」と言われる由縁である。
一方で,PCや据え置き型ゲーム機ほどは多ポリゴンの描画を行わないスマートフォン向けゲームグラフィックスならば,タイルベースレンダリングの効果が大きいのも事実。実際,PowerVRだけでなく,QualcommのGPUコアであるAdrenoシリーズや,ARMのGPUコアであるMaliシリーズといったスマートフォン向けのGPUは,すべてがタイルベースレンダリングを採用しているのだ。
スマートフォン向けSoCはメモリバス帯域幅が狭いため,とにかくメモリアクセスを低減させることが性能向上に結びつくと言われているので,タイルベースレンダリングを使うGPUアーキテクチャが主流になったのだろう。
タイルベースレンダリングの利点を通常のレンダリングでも得られる?
さて,ここからがようやく本題だ。
NVIDIAは,MaxwellとPascal世代のGPUコアで,このタイルベースレンダリングのアーキテクチャを取り込むことにした。それがNVIDIAのTiled Cachingである。
といっても,アプリケーション側は,タイルベースレンダリング的な処理が行われていることを気にしないで済むような形でだ。言い換えると,タイルベースレンダリングの利点を,通常のGPUパイプラインに組み込んだハイブリッドアーキテクチャを実装したと言っていいのかもしれない。
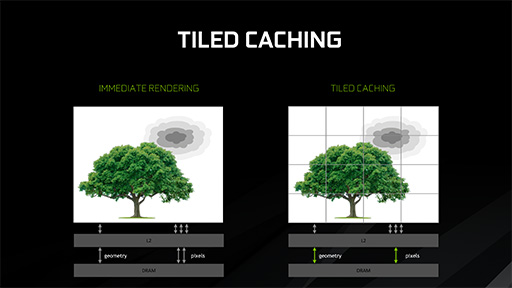 |
頂点シェーダやテッセレーションステージ,ジオメトリシェーダを有するジオメトリパイプライン(※下に掲載した図にあるVertex,Tessellation,Geometry)からの出力をもとに,どのポリゴンがどのタイルに配置されるかの情報(※図中ではattributes)を生成する。そのうえで,この情報をL2キャッシュに書き込む。図中では「Post-Transform Geometry」と記載されている部分だ。
タイルベースレンダリングにおけるフレームバッファ出力なしのジオメトリレンダリングに相当する処理を,ここで行っていると考えれば分かりやすい。
続いて「Binner」と呼ばれる工程では,L2キャッシュに書き込まれた「ポリゴンとタイルの割り当て情報」をもとにタイルベースレンダリング的な局所Zバッファ処理を行って,ほかのポリゴンで上書きされるのが確実な無駄なポリゴンを破棄しておく。そのうえで,確実に表示されるピクセルのラスタライズを,後段のラスタライザで行うのだ。
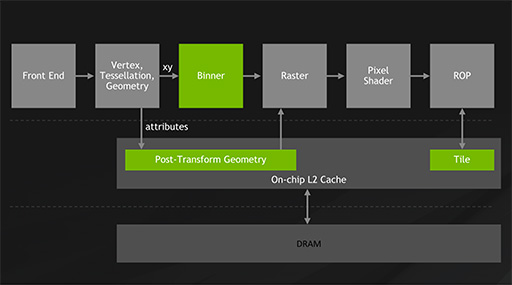 |
そのあとは,通常ならピクセルシェーダがROPを通してレンダリング結果を描き出すのだが,この時点ではグラフィックスメモリではなく,ひとまずは各ピクセルの座標に対応する「L2キャッシュ上に用意した仮想的なタイル」(※図中のTile)に描き出す。
GPU内では,次から次へとオブジェクトの描画が続いているので,「Post-Transform Geometry」の内容も更新され続けている。この内容とレンダリング結果との整合性を取る必要があるので,グラフィックスメモリには直接出力せず,L2キャッシュ上の仮想タイルを更新するわけだ。
L2キャッシュ内でタイルベースレンダリング的な処理をするから,Tiled Cachingという名称になったのだろう。
NVIDIAによれば,Tiled Cachingによるメモリ帯域節約と,Pascal世代で実装となった新しいロスレスカラー圧縮技術を組み合わせると,メモリバス帯域幅が1200GB/sほど増えたことに匹敵する性能を発揮できると,Alben氏は述べていた。
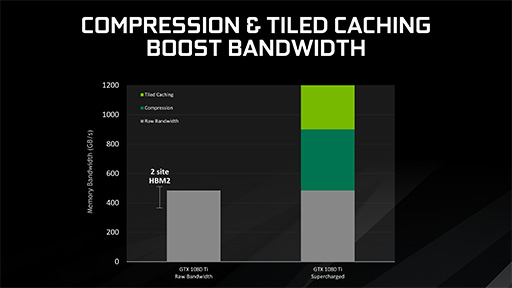 |
 |
Dual DualFET採用の新電力供給部と新開発の冷却システム
GPUのような最新のプロセッサが,低い電圧の直流電流で動いていることを知っている人は少なくないだろう。そして,低電圧の直流電流を安定的に供給するために,直流電流をプロセッサの駆動電圧に下げる用途で使われているのが,「スイッチング電源」だ。
スイッチング電源とは,電圧の変換処理をトランジスタ(MOSFET)による高速のスイッチング(オン/オフ)で行う電源である。大雑把な例を挙げると,10Vの電圧を0.5秒間通電し,0.5秒間は通電してなかった場合,1秒間の合計電圧は半分の5Vになる,といった仕組みと考えればいい。
ところがGPUのように,「消費電力を下げるために低電圧で動かしたい」という要求と,「回路規模が大きいので大電流が欲しい」という要求があるプロセッサを動かすには,スイッチング電源にもいろいろな工夫が必要になる。そして,安定したノイズの少ない電源のほうが電力供給効率を高くできるので,動作特性が近いMOSFETを複数組み合わせたスイッチング電源「DualFET」が適するという。
「GeForce GTX 1080」(以下,GTX 1080)では,電源回路にDualFETを採用したのだが,より多くの電力を消費するGTX 1080 Tiでは,さらに効率を高める目的で,DualFETを二重化して使う「Dual DualFET」(DualFET×2)を採用したそうだ。
下に示したスライドは,GTX 1080 TiとGTX 1080,そして「GeForce GTX 980」の消費電力(横軸)と電力供給効率(縦軸)を比較したグラフだ。
いずれも80W付近が電力供給効率のピークであるが,GTX 1080 Tiでは,効率が85%を超える範囲が30〜140W程度までに拡大していることが分かる。つまり,より広範囲のGPU動作領域で電力効率に優れるわけだ。
また,電力消費が最大となる200W近辺でも,GTX 1080 Tiの電力効率は,従来製品より良好であることが分かるだろう。
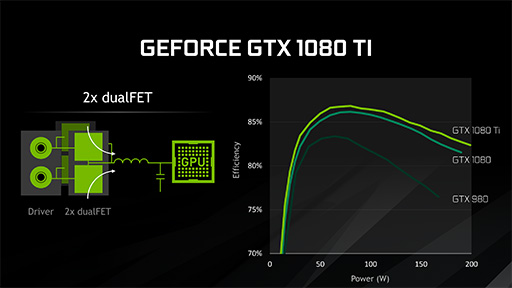 |
またAlben氏は,「GTX 1080 Tiでは,冷却システムをGTX 1080よりも改善した」ともアピールしていた。
イベントの時点では,具体的な構造の違いは説明されなかったのだが,後日配付となった資料を確認したところ,GPUやグラフィックスメモリなどが,銅製ヒートパイプを経由して2スロットサイズの大型ヒートシンクに接続する構造にしたことと,ブラケット部上段に実装していたHDMI出力端子とDual-link DVI-D出力端子を省略し,上段側を開口部にすることで2倍のエアフローが得られるようになったことが,改良のポイントとして挙げられている。
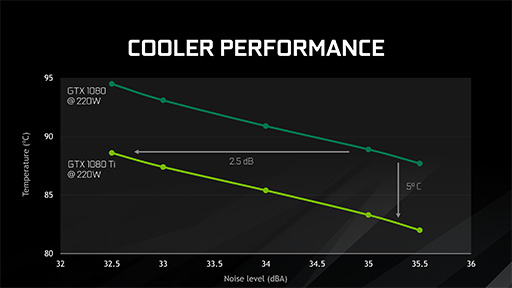
GTX 1080の場合,消費電力220Wの最大パフォーマンス発揮時には35dB以上の騒音レベルで空冷ファンを駆動しないと,安定動作領域となる90℃以下までGPUの表面温度を下げることができなかったという。
それがGTX 1080 Tiでは冷却システムの改良によって,騒音レベルが2.5dB低い32.5dBでも,90℃以下まで温度を下げられるようになったそうだ。
 |
明らかになったTiled Cachingの秘密
Radeon RX Vegaは,いかにして対抗するのか?
2016年夏に発表となった「NVIDIA TITAN X」のGeForceバージョンといった製品であるため,GTX 1080 Tiだけの新情報はあまりなかったな,というのが正直なところ。とはいえTiled Cachingは,Maxwell世代以降のGeForceにおける高性能ぶりを裏付ける技術として,興味深いものではあろう。
AMDが,2017年第2四半期中に投入予定の次世代GPU「Radeon RX Vega」は,北米での価格が699ドルというGTX 1080 Tiに対して,性能と価格のどちらで挑んでくるのかも気になる。筆者としては,HBM2を搭載するRadeon RX Vegaの性能が,Tiled Caching搭載のGTX 1080 Tiにどれくらい迫れるのかが,見物になるだろうと期待しているところだ。
- 関連タイトル:
 GeForce GTX 10
GeForce GTX 10 - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー