













連載
西川善司の3DGE:「Radeon R9 Fury X」とはいかなるGPUか。「Fiji」のアーキテクチャに迫る
北米時間2015年6月16日,AMDは,開発コードネーム「Fiji」(フィジー)こと「Radeon R9 Fury」シリーズを発表した(関連記事)。
ラインナップは,シングルGPU仕様の最上位モデルで,簡易液冷クーラーを搭載する「Radeon R9 Fury X」(以下,R9 Fury X)と,その下位モデルとなる空冷仕様の“無印”Radeon R9 Fury(以下,R9 Fury),空冷でカード長が6インチ(≒152.4mm)に抑えられた「Radeon R9 Nano」(以下,R9 Nano),そして名称未公開のデュアルGPUカード,以上4モデルだ。R9 Fury Xは,24日21:00の時点で国内販売も始まっている。
最大の特徴は,「High Bandwidth Memory」(以下,HBM)技術の1つである「HBM1」で,GPUパッケージ上に積層メモリ(Stacked Memory)を実装していることだが,GPU側に拡張はあるのかないのか。そもそも,HBMの採用によってRadeon R9 Furyでは何が変わるのか。E3 2015に合わせて開催されたAMDによる説明会の内容を踏まえながら,今回はそのあたりを整理してみたいと思う。
Fijiと,Radeon R9 290シリーズの「Hawaii」コアは,いずれもTSMCの28nmプロセス技術を用いて製造されるGPUだ。そのダイサイズは前者が596mm2,後者が438mm2で,トランジスタ数は順に89億,62億。ダイ面積比で約36%大きなFijiで,トランジスタ数は約44%多くなった計算だが,ここは,物理設計の最適化が可能にしたという理解でいいだろう。
Fijiの場合,積層メモリをオンパッケージで実装するため,パッケージ(=チップ)としてのサイズが1011mm2になっているという大きなポイントもあるが,この点は後述したい。
そのアーキテクチャは基本的に,「Radeon R9 285」で知られる「Tonga」コアを踏襲したものだ。異なるカーネルに切り換えて実行するために有用な「GPU Graphics Preemption」「GPU Compute Context Switch」といった,Tongaコアの特徴的な要素は,そのままFijiへ継承されている。
“ミニGPU”ともいえる「Shader Engine」が4クラスタ構成なのも,Tonga(やHawaii)と同じである。
Fijiは,Shader Engineあたり16基の演算ユニット「Compute Unit」を搭載している。「Graphics Core Next」(以下,GCN)アーキテクチャに基づき,Compute Unitは,AMDが「Stream Processor」と呼ぶシェーダプロセッサを16基ひとまとめにした実行ユニットを4基搭載するため,Fijiのフルスペックでは,
という総シェーダプロセッサ数になる計算だ。ちなみにHawaiiは“64×11×4”で2816基,Tongaは“64×8×4”で2048基なので,Fijiは,Shader EngineあたりのCompute Unit数を増やすことによって,より大きなプロセッサ規模を実現したものと理解することも可能だろう。
Shader Engineごとに1基用意される「Geometry Processor」に,大きな仕様変更はないとのこと。GPGPU(Compute Shader)のタスクを発注する機能ブロックである「Asynchronous Compute Engine」(ACE)の数が8基というのも,TongaやHawaiiから変わっていない。
描画結果をメモリ側に出力するユニットに相当する「Render Back-End」(レンダーバックエンド)が,Shader Engineあたり4基用意される構成も,HawaiiやTongaと同じ。Shader Engineの数が4基で変わっていないため,Render Back-Endの総数もHawaiiやTongaと同じ16基だ。1基のRender Back-Endはクロックあたり4ピクセルの能力を持つため,NVIDIA的なROP(Rendering Output Pipeline)換算でいえば64基と紹介することもできる。
以上,ここまでがFijiアーキテクチャの解説となるが,GPUコア自体に,大きな変革はないということが分かってもらえたと思う。だからこそAMDは,Fijiにおける最大の特徴を,HBMの採用に置いたのだ。
「HBMとは何か」という話は2015年5月19日の記事に詳しいが,簡単にいえば,メモリチップを高層ビルのように積み上げて(=スタックさせて)配置し,それを「TSV」(Through Silicon Via:シリコン貫通ビア)技術によって串刺しに貫通させて配線するメモリ実装技術のことである。
GDDR5からHBMへ移行させた理由を,Joe Macri(ジョー・マクリー)CTOは,次のように述べている。
「世代を刷新するごとに,GPU側の演算性能は1.4倍となり,それに見合うメモリ性能をGDDR5で実現しようとすると,消費電力が指数関数的に上昇していく。一方で,PCシステム全体の消費電力を抑えていこうというトレンドがあるため,限られた“消費電力予算”をGPU演算性能とメモリ性能に振り分けていかなければならないため,このままではGPU性能もメモリ性能も上げられなくなる。
こうした事態に対処できる最もシンプルな解決策がHBMだったのだ」。
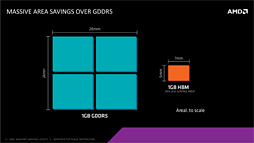
ハイエンドモデルを中心に,最近ではグラフィックスメモリ搭載量が増えていくトレンドにある。そのなかでグラフィックスメモリチップの実装数が増えれば,グラフィックスカード上で多くの物理的な領域をメモリチップが占める占めることになる。最近のハイエンドグラフィックスカードにおける長尺化の要因の1つには,メモリチップ搭載量の増加も挙げられるわけだが,HBMであれば,GPUパッケージ内にメモリチップを積層して載せられるため,カード長を短くできるというメリットもある。
グラフィックスメモリをプロセッサ内部に内蔵するというアイデアもあるにはあるが,大容量のDRAMをプロセッサに内蔵すると,ダイサイズが肥大化してしまい,トランジスタ数も増える。当然のことながら,数GB単位の大容量DRAMを内蔵したチップの場合,プロセッサロジック部よりもDRAM部にトランジスタが割かれることになり,DRAMに不良があって,良品として出荷できなくなる」可能性が高くなる。これは,製品製造コストの観点から,よろしくない。
また,メモリバス帯域幅を引き上げるためのシンプルな解決策は,バスの高クロック化だが,クロックが上がれば上がるほど,安定的なデータ伝送を行うために信号電圧を上げなければならないため,消費電力削減が求められているトレンドに逆行することとなってしまう。
その点,HBMであれば,プロセッサとは別に製造したメモリチップをパッケージ上で実装するため,プロセッサダイにメモリを内蔵して一括製造するよりも製造コストを抑えられる。加えて,メモリを三次元的に積層実装して貫通配線するため,メモリバス幅を引き上げるためのもう1つのシンプルな解決策である多ビット化を,「積層させたメモリの高さ分」の配線で実現できる。高クロック化することなく,メモリバス帯域幅を引き上げられるのだ。
AMDとしては,あらゆる角度から見て,GDDRよりもHBMに未来があるため,その実用化に踏み切ったというわけである。
下に示したスライドは,Fijiチップに採用されたHBM,正確にはHBM1の仕様を,GDDR5と比較したものだ。数字はGDDR5が1チップ,HBM1が1スタックあたりのものとなる。なので,GDDR5の場合,1チップあたりのメモリバス幅は32bitだが,Hawaiiの場合はこれが16枚あったので512bitとなり,Fijiの場合は1スタックあたり1024bitで,それが4スタックで4096bitとなる。いうまでもなく,この圧倒的なバス幅こそがHBMの特徴だ。
一方,GDDR5の場合,GPU向けに実用化されている最上位製品の動作クロックは1750MHz。GDDR5のデータレートは4倍なので,7GHz相当となる。それに対してHBM1の場合,動作クロック500Hzの2倍データレートで1GHz相当。動作クロックが低すぎると不安に思うかもしれないが,HBM1では4096bitメモリインタフェースで低下した動作クロックを補う仕組みなので,チップ(クラスタ)/スタックあたりのバス帯域幅は,
と,HBM1が圧倒的に上回る。
ちなみに最終製品で比較した場合,HawaiiコアのRadeon R9 290Xだと,動作クロック5GHz相当(実クロック1250MHz)のGDDR5,グラフィックスメモリ16枚で容量4GBだったので,メモリバス帯域幅は32bit×5GHz×16で320GB/s。対するR9 Fury Xは動作クロック1GHz相当(実クロック500MHz)のHBM1,4スタックで容量4GBのため,1024bit×1GHz×4で512GB/sという計算だ。
ちなみに駆動電圧は,GDDR5の1.5Vに対し,HBM1は1.3Vと低い。理由は,HBMだと動作クロックを低くできるためだが,結果として,電力効率もGDDR5よりHBM1のほうが優れる,ということになる。
なお,いま紹介したのはFijiとHawaiiの比較だが,FijiはTongaベースなので,Tongaで採用された,ピクセルデータを可逆圧縮して,実効メモリ帯域幅を向上させる機能「Lossless Delta Color Compression」機能も搭載される。本機能の詳細はTongaの詳細解説記事を参考にしてほしいが,その分,FijiのほうがHawaiiより有利という点は押さえておいてもらえればと思う。
「NVIDIAは次世代GPU『Pascal』で,メモリバス帯域幅1TB/sを実現すると言っていなかったか?」と疑問に思った読者はいるかもしれない。
なぜFijiで1TB/sを実現していないのか。これは簡単にいえば,ここまで繰り返してきているとおり,Fijiで採用しているHBM技術が第1世代のHBM1だからだ。HBM技術も,GDDRメモリ技術と同様に,今後,高クロック化とデータレート引き上げの方向へ進化していくロードマップになっている。NVIDIAは,HBM投入の時期を遅らせて,世代の新しいものを採用することに決め,AMDは第1世代のHBMでも十分なメリットが得られると判断した,というわけだ。
Fijiのスペックでは,メモリ容量が少ないと思った人もいるだろう。「HBMで高性能なのは分かったけど,ハイエンドGPU搭載のグラフィックスカードでグラフィックスメモリ容量が4GBは少なくない?」と疑問を感じた読者はいると思うが,種明かしをすれば,これもHBM技術が第1世代であるのがその理由だ。Fijiで採用されたHBM1では1スタックあたり4チップ積層となるが,「HBM2」と呼ばれる次世代HBMではこれが8チップ積層タイプとなる。そうなれば,4スタック構成でもメモリ容量8GBを実現できるはずだ。
HBM1に対しては「メモリチップを積み上げて実装するとということはメモリチップの排熱効率が良くないように思える」とか「GPUとメモリチップの高さが違いすぎてちゃんと冷却できるの?」など,冷却周りが気になる人もいると思う。
まず排熱だが,Macri氏いわく,「HBMでは駆動電圧が下がり,動作クロックも下がった。結果,メモリチップあたりの発熱量は下がっているので問題ない」とのこと。その仕様上,下層のメモリチップほど熱が籠もりそうに見えるが「評価実験において,違いは数℃レベルしかなく,実害はない」という判断が下ったそうだ。
GPUダイと積層メモリとの間にある高さの違いについては「イラストだと全然高さが違うように見えるけど,実際には大した違いはないよ(笑)」とMacri氏。実際に,製造段階で,高さは揃えて組み付けられ,わずかな違いは,モールド樹脂による封止で均等化されるとのことだった。
Macri氏によれば,FijiにおいてGPUと積層メモリはヒートスプレッダ経由でつながっているため,「熱は温度の高いところから低いところへ移動する」という法則に基づき,GPUの熱は積層メモリ側へ移るという。つまり,積層メモリもGPUコアのヒートスプレッダ的に利用できるということだ。
「HBMだと発熱が心配」どころか,GPUコアの冷却に一枚噛んでいるというのは,正直,驚きである。
まとめよう。Fijiにおいて,GPUコア側の大きな変革はない。Compute Unit数の増強によって性能強化を図れるという,GCNアーキテクチャの強みを最大限に生かし,今回は演算ユニットの増量だけに留め,開発リソースは「HBMをモノにする」ことに振ったということなのだと思われる。
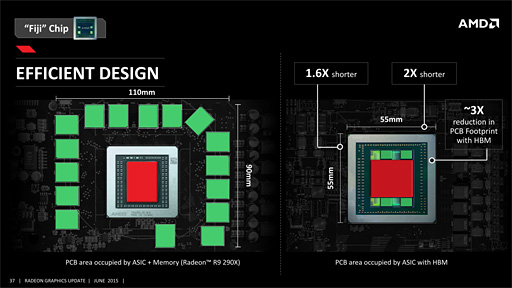
実際,強化されたメモリ周りへの期待は大きい。HBMには将来性がある。また,なんと言っても,HBMの採用によってRadeon R9 Furyシリーズのカード長が圧倒的に短くなる点は,大いに歓迎できるのではないだろうか。
そんなRadeon R9 Furyシリーズだが,1つだけ気になったことがある。それは,今回もHDMI 2.0への対応が見送られたことだ。
Fijiは内部的に6画面出力対応の「Eyefinity」機能を備える一方,HDMI出力周りはHDMI 1.4対応に留まる。つまり,Radeon R9 Furyシリーズにおいても,4K解像度の60fps出力を行えるのはDisplayPort接続時に限られ,HDMI接続時は30fpsまでとなるのだ。「TongaベースのCompute Unit増強版GPU」という観点からすると,さもありなんという仕様ではあるのだが,GeForce GTX 900シリーズで完全対応したNVIDIAに対しては,水をあけられた感じがする。
Koduri氏はこの点について,「今なお,HDMI 2.0対応機器は少ない。AMDとしては,HDMI 2.0機器へ接続するときは,DisplayPort 1.2→HDMI 2.0変換アダプターの利用を推奨する」と述べるに留まったが,少なくとも2014年後半以降に発売された現行世代の4KテレビはほぼすべてがHDMI 2.0に対応しているわけで,氏の認識は,現実からやや乖離している印象が否めない。
いずれにせよ,HDMI 2.0のネイティブ対応は次世代GPUへと再び持ち越された格好であり,この決断が日本市場のPCゲーマーからどう受け止められるかは気になるところだ。
ラインナップは,シングルGPU仕様の最上位モデルで,簡易液冷クーラーを搭載する「Radeon R9 Fury X」(以下,R9 Fury X)と,その下位モデルとなる空冷仕様の“無印”Radeon R9 Fury(以下,R9 Fury),空冷でカード長が6インチ(≒152.4mm)に抑えられた「Radeon R9 Nano」(以下,R9 Nano),そして名称未公開のデュアルGPUカード,以上4モデルだ。R9 Fury Xは,24日21:00の時点で国内販売も始まっている。
 |
 |
「Tongaの演算ユニット増強版」となるFiji
 |
| Fijiの製品概要 |
 |
| GPUクーラーを外した状態のRadeon R9 Fury Xリファレンスカード |
Fijiの場合,積層メモリをオンパッケージで実装するため,パッケージ(=チップ)としてのサイズが1011mm2になっているという大きなポイントもあるが,この点は後述したい。
そのアーキテクチャは基本的に,「Radeon R9 285」で知られる「Tonga」コアを踏襲したものだ。異なるカーネルに切り換えて実行するために有用な「GPU Graphics Preemption」「GPU Compute Context Switch」といった,Tongaコアの特徴的な要素は,そのままFijiへ継承されている。
“ミニGPU”ともいえる「Shader Engine」が4クラスタ構成なのも,Tonga(やHawaii)と同じである。
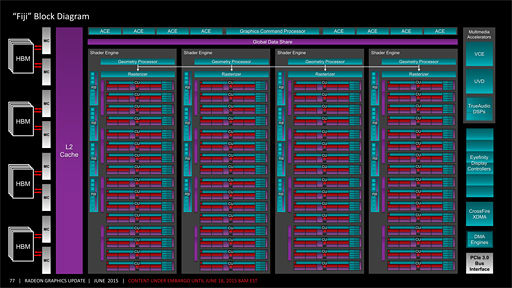 |
Fijiは,Shader Engineあたり16基の演算ユニット「Compute Unit」を搭載している。「Graphics Core Next」(以下,GCN)アーキテクチャに基づき,Compute Unitは,AMDが「Stream Processor」と呼ぶシェーダプロセッサを16基ひとまとめにした実行ユニットを4基搭載するため,Fijiのフルスペックでは,
 |
- 64(Stream Processor)
× 16 (Compute Unit) × 4 (Shader Engine) = 4096
という総シェーダプロセッサ数になる計算だ。ちなみにHawaiiは“64×11×4”で2816基,Tongaは“64×8×4”で2048基なので,Fijiは,Shader EngineあたりのCompute Unit数を増やすことによって,より大きなプロセッサ規模を実現したものと理解することも可能だろう。
Shader Engineごとに1基用意される「Geometry Processor」に,大きな仕様変更はないとのこと。GPGPU(Compute Shader)のタスクを発注する機能ブロックである「Asynchronous Compute Engine」(ACE)の数が8基というのも,TongaやHawaiiから変わっていない。
描画結果をメモリ側に出力するユニットに相当する「Render Back-End」(レンダーバックエンド)が,Shader Engineあたり4基用意される構成も,HawaiiやTongaと同じ。Shader Engineの数が4基で変わっていないため,Render Back-Endの総数もHawaiiやTongaと同じ16基だ。1基のRender Back-Endはクロックあたり4ピクセルの能力を持つため,NVIDIA的なROP(Rendering Output Pipeline)換算でいえば64基と紹介することもできる。
AMDはなぜ,他社に先行してHBM採用へ踏み切ったのか
 |
「HBMとは何か」という話は2015年5月19日の記事に詳しいが,簡単にいえば,メモリチップを高層ビルのように積み上げて(=スタックさせて)配置し,それを「TSV」(Through Silicon Via:シリコン貫通ビア)技術によって串刺しに貫通させて配線するメモリ実装技術のことである。
GDDR5からHBMへ移行させた理由を,Joe Macri(ジョー・マクリー)CTOは,次のように述べている。
 |
こうした事態に対処できる最もシンプルな解決策がHBMだったのだ」。
 |
 |
| Radeon R9 290X(左)とRadeon R9 Furyシリーズのグラフィックスメモリレイアウト。前者の場合,性能を考えると,メモリチップはGPUの外周近隣に実装せざるを得ないため,かなりの面積を必要とするが,HBMであればメモリチップの実装を基板上で行う必要がなくなる |
 |
| 結果としてR9 Fury Xでは,カード長を7.5インチ(≒190.5mm)にまで短くできた。Radeon R9 290Xのリファレンスデザインだと実測約278mm(※突起部除く)なので,約69%まで縮んだ計算だ |
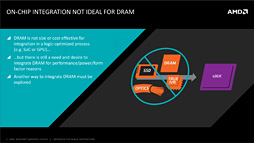 |
| 大容量メモリをプロセッサダイへ統合するのは,現実的な解決策ではない |
 |
| これ以上のGDDR5高クロック化も,もはや現実的ではない |
また,メモリバス帯域幅を引き上げるためのシンプルな解決策は,バスの高クロック化だが,クロックが上がれば上がるほど,安定的なデータ伝送を行うために信号電圧を上げなければならないため,消費電力削減が求められているトレンドに逆行することとなってしまう。
その点,HBMであれば,プロセッサとは別に製造したメモリチップをパッケージ上で実装するため,プロセッサダイにメモリを内蔵して一括製造するよりも製造コストを抑えられる。加えて,メモリを三次元的に積層実装して貫通配線するため,メモリバス幅を引き上げるためのもう1つのシンプルな解決策である多ビット化を,「積層させたメモリの高さ分」の配線で実現できる。高クロック化することなく,メモリバス帯域幅を引き上げられるのだ。
AMDとしては,あらゆる角度から見て,GDDRよりもHBMに未来があるため,その実用化に踏み切ったというわけである。
Fijiに搭載されたHBMの仕様,そしてこれにまつわる疑問に対する回答
下に示したスライドは,Fijiチップに採用されたHBM,正確にはHBM1の仕様を,GDDR5と比較したものだ。数字はGDDR5が1チップ,HBM1が1スタックあたりのものとなる。なので,GDDR5の場合,1チップあたりのメモリバス幅は32bitだが,Hawaiiの場合はこれが16枚あったので512bitとなり,Fijiの場合は1スタックあたり1024bitで,それが4スタックで4096bitとなる。いうまでもなく,この圧倒的なバス幅こそがHBMの特徴だ。
 |
一方,GDDR5の場合,GPU向けに実用化されている最上位製品の動作クロックは1750MHz。GDDR5のデータレートは4倍なので,7GHz相当となる。それに対してHBM1の場合,動作クロック500Hzの2倍データレートで1GHz相当。動作クロックが低すぎると不安に思うかもしれないが,HBM1では4096bitメモリインタフェースで低下した動作クロックを補う仕組みなので,チップ(クラスタ)/スタックあたりのバス帯域幅は,
- GDDR5:32bit(=4Bytes)×7GHz=28GB/s
- HBM1:1024bit(=128Bytes)×1GHz=128GB/s
と,HBM1が圧倒的に上回る。
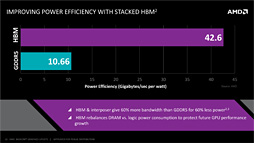 |
ちなみに駆動電圧は,GDDR5の1.5Vに対し,HBM1は1.3Vと低い。理由は,HBMだと動作クロックを低くできるためだが,結果として,電力効率もGDDR5よりHBM1のほうが優れる,ということになる。
なお,いま紹介したのはFijiとHawaiiの比較だが,FijiはTongaベースなので,Tongaで採用された,ピクセルデータを可逆圧縮して,実効メモリ帯域幅を向上させる機能「Lossless Delta Color Compression」機能も搭載される。本機能の詳細はTongaの詳細解説記事を参考にしてほしいが,その分,FijiのほうがHawaiiより有利という点は押さえておいてもらえればと思う。
 |
「NVIDIAは次世代GPU『Pascal』で,メモリバス帯域幅1TB/sを実現すると言っていなかったか?」と疑問に思った読者はいるかもしれない。
なぜFijiで1TB/sを実現していないのか。これは簡単にいえば,ここまで繰り返してきているとおり,Fijiで採用しているHBM技術が第1世代のHBM1だからだ。HBM技術も,GDDRメモリ技術と同様に,今後,高クロック化とデータレート引き上げの方向へ進化していくロードマップになっている。NVIDIAは,HBM投入の時期を遅らせて,世代の新しいものを採用することに決め,AMDは第1世代のHBMでも十分なメリットが得られると判断した,というわけだ。
Fijiのスペックでは,メモリ容量が少ないと思った人もいるだろう。「HBMで高性能なのは分かったけど,ハイエンドGPU搭載のグラフィックスカードでグラフィックスメモリ容量が4GBは少なくない?」と疑問を感じた読者はいると思うが,種明かしをすれば,これもHBM技術が第1世代であるのがその理由だ。Fijiで採用されたHBM1では1スタックあたり4チップ積層となるが,「HBM2」と呼ばれる次世代HBMではこれが8チップ積層タイプとなる。そうなれば,4スタック構成でもメモリ容量8GBを実現できるはずだ。
 |
 |
まず排熱だが,Macri氏いわく,「HBMでは駆動電圧が下がり,動作クロックも下がった。結果,メモリチップあたりの発熱量は下がっているので問題ない」とのこと。その仕様上,下層のメモリチップほど熱が籠もりそうに見えるが「評価実験において,違いは数℃レベルしかなく,実害はない」という判断が下ったそうだ。
GPUダイと積層メモリとの間にある高さの違いについては「イラストだと全然高さが違うように見えるけど,実際には大した違いはないよ(笑)」とMacri氏。実際に,製造段階で,高さは揃えて組み付けられ,わずかな違いは,モールド樹脂による封止で均等化されるとのことだった。
Macri氏によれば,FijiにおいてGPUと積層メモリはヒートスプレッダ経由でつながっているため,「熱は温度の高いところから低いところへ移動する」という法則に基づき,GPUの熱は積層メモリ側へ移るという。つまり,積層メモリもGPUコアのヒートスプレッダ的に利用できるということだ。
「HBMだと発熱が心配」どころか,GPUコアの冷却に一枚噛んでいるというのは,正直,驚きである。
「GCNのスケーラブルな設計」とHBM1を生かしたFiji。HDMI 2.0対応は見送りに
 |
実際,強化されたメモリ周りへの期待は大きい。HBMには将来性がある。また,なんと言っても,HBMの採用によってRadeon R9 Furyシリーズのカード長が圧倒的に短くなる点は,大いに歓迎できるのではないだろうか。
 |
Fijiは内部的に6画面出力対応の「Eyefinity」機能を備える一方,HDMI出力周りはHDMI 1.4対応に留まる。つまり,Radeon R9 Furyシリーズにおいても,4K解像度の60fps出力を行えるのはDisplayPort接続時に限られ,HDMI接続時は30fpsまでとなるのだ。「TongaベースのCompute Unit増強版GPU」という観点からすると,さもありなんという仕様ではあるのだが,GeForce GTX 900シリーズで完全対応したNVIDIAに対しては,水をあけられた感じがする。
Koduri氏はこの点について,「今なお,HDMI 2.0対応機器は少ない。AMDとしては,HDMI 2.0機器へ接続するときは,DisplayPort 1.2→HDMI 2.0変換アダプターの利用を推奨する」と述べるに留まったが,少なくとも2014年後半以降に発売された現行世代の4KテレビはほぼすべてがHDMI 2.0に対応しているわけで,氏の認識は,現実からやや乖離している印象が否めない。
いずれにせよ,HDMI 2.0のネイティブ対応は次世代GPUへと再び持ち越された格好であり,この決断が日本市場のPCゲーマーからどう受け止められるかは気になるところだ。
 |
- 関連タイトル:
 Radeon R9 Fury
Radeon R9 Fury - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー