












ニュース
Intelの新CPU「Core Ultra Series 3」の「Xe3 GPU」は,なぜ理論性能値を覆すほど高性能なのか? 実機でもRadeon 890Mを上回る
 |
関連記事


新世代のノートPC向けSoC「Core Ultra Series 3」が登場。性能向上と長時間のバッテリー駆動を実現
米国時間2026年1月5日,IntelはノートPC向け新型SoC「Core Ultra Series 3」を正式発表した。前世代製品から,CPUコアと内蔵GPUのアーキテクチャを変更することで性能向上と,最大27時間の長時間駆動を実現したという。
CES 2026の会期中,Intelは,Core Ultra Series 3が内蔵する新GPUのゲーム性能をアピールするため,報道関係者が任意のゲームを,Core Ultra Series 3搭載PCで動作させるテストの機会を提供していた。それだけ性能に自信があると言うことなのだろう。
本稿では,Core Ultra Series 3の内蔵GPUの概要と,テスト機によるインプレションをレポートしよう。
 |
Xe3 GPUの名称は「Arc B3xx」
Core Ultra Series 3のGPU tileに組み込まれているGPUは,Xeアーキテクチャ系GPUの第3世代であるため,「Xe3」と呼ばれている。ただし,その中身はXe2と同じ「Battlemage」系であることが,明らかとなった。
もともとIntelは,
- Xe1=Alchemist,Axxx
- Xe2=Battlemage,Bxxx
- Xe3=Celestial,Cxxx
というロードマップを示していたが,Core Ultra Series 3では,A/B/Cと1/2/3の対応がずれたわけだ。
 |
色んな裏事情はあるにせよ,今後登場するかもしれないCelestial世代GPUと,Xe3を誤認させるわけにもいかないといった都合もあるのだろう。
Core Ultra Series 3内蔵GPUは,すべてXe3世代であることに間違いはない。ただ,12コア仕様のGPU Tileを搭載するモデルでは,GPU名として「Intel Arc B300」シリーズのブランド名を与えることとなった。
CPU内蔵GPUのイメージが強い「Xe3」よりも,ゲーム性能の高いBattlemage世代を強調したブランド名を付けたかったのだろう。
関連記事


Intel Arc B570はエントリー向けGPUの新たな選択肢となるか? 「Intel Arc B570 Challenger 10GB OC」レビュー
IntelのXe2ベースのGPU「Intel Arc B580」は,「GeForce
ちなみに,Xe3コア数が12基のフルスペック版が「Arc B390」で,コアを2基無効化した10基仕様のバージョンは「Arc B370」となっている。
 |
 |
Xe3は,Battlemage系のままではあるものの,Intelは,Panther Lakeの発表時から「かなりハイチューンを施した自信作である」と強気を見せていた。
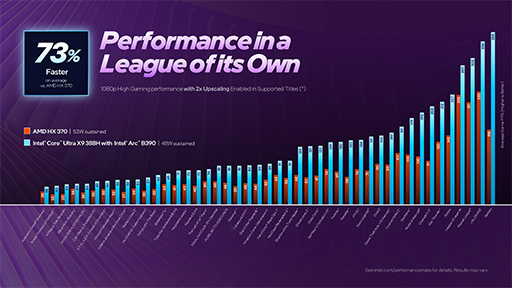
今回,Intelは,その高性能ぶりを,Xe3コア12基構成のArc B390を搭載する最上位CPU「Core Ultra X9 388H」と,AMDの「Ryzen AI 9 HX370」(内蔵GPUは「Radeon 890M」のCU 16基モデル)との性能比較グラフでアピールしている。
計測条件は,Ryzenはワット数の高い消費電力53Wで持続した状態で,Core Ultraは,競合より低い消費電力45Wでの計測だということも,Intelは強調していた。
消費電力は高いほうが,高性能を発揮しやすくなるので,「あえて不利なハンデを負って計測したよ」というIntelのアピールでもある。
その結果は以下のとおり。
 |
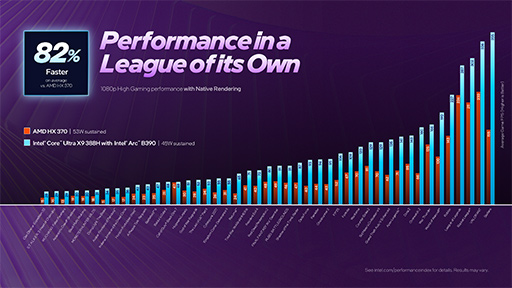 |
不利な計測条件であっても,Intelのほうが多くのゲームタイトルで高い性能を発揮したことになっている。
理論性能値を覆すArc B390の下剋上
Xe3の理論性能値にも注目してみよう。
GPUのFP32理論性能値は,Core Ultra X9 388HのArc B390が7.68 TFLOPSである。
- 7.68 TFLOPS≒12 Xe3×128 SIMD×2 FLOPS×2.5GHz
一方で,Ryzen AI 9 370HXのRadeon 890Mは,11.88 TFLOPSと高いのだ。
- 11.88 TFLOPS≒16 CU×128 SIMD×2 FLOPS×2.9GHz
つまり,理論性能値では約1.55倍も高いRadeon 890Mを相手に,Arc B390は逆転劇を演じたことになる。
ちなみに,Arc B390がRadeon 890Mを理論スペックで上回る部分といえば,メモリバス帯域幅がある。
メモリバス帯域幅は,Ryzen AI系のLPDDR5xの場合,上限が8000MT/sとなるため128GB/sだ。一方,Core Ultra Series 3は,9600MT/sが上限となるため,Ryzen AI系を約20%上回る153GB/sとなる。
この差がすべてではないだろうが,プラスに働いたことは間違いないだろう。
ちなみに,「Radeon 890Mは,SIMD演算器がデュアルイシューだから(関連記事),見かけだけの理論性能値が高いのでは?」というツッコミがきそうだが,それはお互い様である。
Arc B390も,Render Slice数――NVIDIA製GPUで言うところのGPC――を据え置いたアーキテクチャを採用しているので,並列性は変えずにSIMD演算器を増強しただけだ。つまり,どちらもハイチューンの方向性は同じ。それでいて,ここまでの下剋上を達成しているのは面白いではないか。
モンハンワイルズ ベンチで実力を検証
というわけで,Arc B390の実力を検証すべく,Core Ultra X9 388Hを搭載する試作ノートPCを試すこととなった。試用機は,Lenovo製である。
 |
「PCMark 10」のようなPC総合性能テストや,「CINEBENCH」のようなCPU特化型ベンチマークの類は「絶対に計測してはダメ」といわれたので,筆者は,今どきのゲームグラフィックスベンチマークとしては,処理負荷が高くて利用者も多い定番の「モンスターハンターワイルズ ベンチマーク」(以下,モンハンワイルズ ベンチ)を使うことにした。
なお,会場のネットワーク速度の制限もあり,与えられた時間でしっかり試せたのはモンハンワイルズ ベンチだけだった。
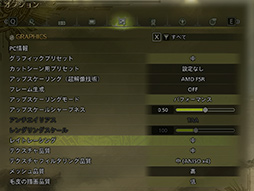
テスト時の設定は,「グラフィックスプリセット:中」「レイトレーシング:中」とした。こうした設定にしたのは「そこそこの負荷をかける」のと,「レイトレーシング性能はチェックしたい」ためだ。
 |
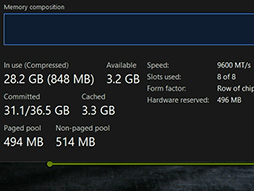 |
Arc B390では,Intel製GPUの設定アプリ「ARC Control Software」を使い,メインメモリからGPUに割り当てるメモリ量を設定できる。今回のテストでは,12GBとした。
メインメモリの総量は32GBなので,CPU側に割り当てられたメインメモリ容量は,20GB前後になる。
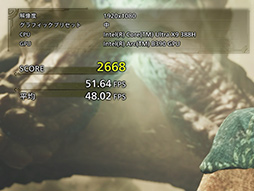 |
序盤のシーンは,登場人物が多いため,その顔や肌に対する(皮下散乱)シェーダや,衣服類やアクセサリ類の多様な材質シェーダ,砂嵐のように画面全体に適用されるポストエフェクト処理などが重い。
どちらかといえばピクセルヘビーなシーンが多いという感じだ。
このシーンの平均フレームレートは,35〜50fps程度といったところ。なかなか頑張っている。
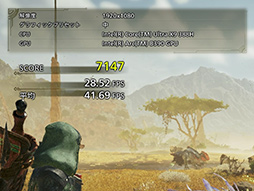
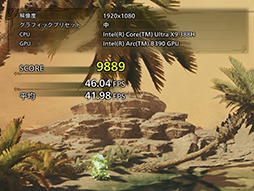
中盤は,騎乗した主人公がエリアを探索する様子が描かれる。
シーンの始めは,生い茂る植物群と,その中を闊歩する草食恐竜との遭遇が描かれ,見るからにジオメトリ(ポリゴン)ヘビーなシーンが続く。
一方,終わり頃になるとオアシスが描かれ,レイトレーシングによって映り込みが描かれる。
結果は,ジオメトリヘビーなシーンは30fps前後。オアシスのシーンは想像よりはだいぶ軽く,45fps前後をマークした。
 |
 |
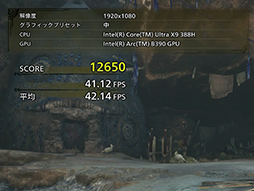
終盤の村のシーンは,歩き回る村人や楽しそうな食事のシーンが描かれる。ナンの上に乗せられた軟体オブジェクトのチーズの表現が面白い場面だが,ここも登場人物の多さと,特殊材質表現が多い影響で,そこそこに重いシーンとなっている。
ここは40〜50fps程度で推移していた。
 |
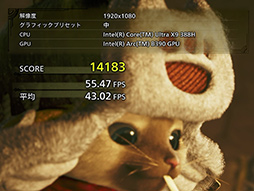 |
総合スコアは「14725」(平均43.37fps)となり,「快適にプレイできます」の判定を得ている。
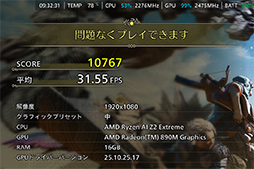 |
その結果は,総合スコアが「10767」(平均31.55fps)で,「問題なくプレイできます」となった。これは,Core Ultra X9 388Hよりも,1ランク下の評価だ。
Ryzen Z2 Extremeの内蔵GPUは,Ryzen AI 9 HX370と同じRadeon 890Mで,動作クロックやメモリクロック,CU数も同じなのだ。
Ryzen Z2 ExtremeのCPU部は,Zen 5×3とZen 5c×5の8コア16スレッド仕様なので,先にIntelが示したグラフにおける比較対象とはスペックが異なる。しかし実質的には,かなり近い環境でテストが行えたと思っている。
たしかに,Intel側の示した1.7倍近い結果にはならなかったが,理論性能値を覆し,約37%もArc B390の方がRadeon 890Mを上回った事実だけは確認できた。
少なくとも理論性能値を下剋上できるポテンシャルがArc B390にはあるということなのだろう。
下剋上の理由は,データパスとメモリアクセスの最適化
Radeon 890Mに対する下剋上が起きた理由について,質疑応答でIntel側のGPU担当者に聞いてみた。すると,「GPU内部のデータパスの最適化と,GPUコアからのメモリアクセスの最適化を極限まで進めた。その結果と思っていい」そうだ。
理論性能値は,あくまでもスペックから求めた数値でしかない。
だが,実際のゲームグラフィックス描画では,GPUが描画パイプラインを多段で実行するので,演算結果を次のパイプラインに早く受け渡すことが重要になってくる。レイトレーシングについても,処理の大部分は演算よりも,「BVH量子化」された3Dシーンデータをランダムに探索するため,キャッシュアーキテクチャの善し悪しのほうが性能に結びつく。
さらに筆者は,Arc B390のホワイトペーパーにも目を通したところ,興味深いポイントをいくつか発見した。
Xe3では,Render Slice数はそのままであるが,汎用レジスタファイル(GRF)の割り当て粒度を動的に変化させることで,シェーダプロセッサである「Xe Vector Engine」(XVE)1基当たりの実行スレッド数を,4〜8スレッドから10スレッドまで向上させたのだ。
 |
レイトレーシングユニットについても,新しい機構を導入したという。
レイトレーシングの実行中,GPU内の各処理ステージ間で同期を取らず,独立性を持って進められるところはどんどん進行させる非同期レイトレーシングの仕組みを実装したそうだ。
 |
また,描画結果を書き出す工程を担当するレンダーバックエンドも,Xe3では手厚く改善しているという。
レンダーバックエンドの一部には,Intelが「Unified Return Buffer」(URB)と呼ぶバッファがある。過去のIntel製内蔵GPUでは,L3キャッシュの一部をURBに流用していた。一方,Xe GPUでは,URBとしてSRAMによる専用バッファを用意したという経緯がある。
そしてXe3では,レンダーバックエンドに対するURBの割り当てや更新の粒度を最適化した,新URBマネージャを搭載したそうだ。こうしたチューニングの巧さが,Xe3による下剋上につながった,ということになるかと思う。
逆にいえば,AMDは,かなり高い理論性能値を持ちながら,それをうまくいかせていないことにもなる。次のRyzen APUに組み込まれるGPUには,Intelが行ったような演算器の出力を高効率でやりとりできるようなチューニングが望まれる。
その兆候は,すでにある。Radeon 890MはRDNA 3.5世代のGPUであるが,すでにAMDは,内部データパスを改善してキャッシュ階層構造の最適化を行ったRDNA 4世代のGPUを,Radeon RX 9000シリーズとして投入済みだ。
AMDの雪辱戦は,RDNA 4世代GPUがRyzen APUに組み込まれたときになるのかもしれない。
次戦の成り行きも楽しみである。
- 関連タイトル:Intel Core Ultra 300(Series 3,Panther Lake)
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー