














連載
西川善司の3DGE:GeForce RTX 20完全理解。レイトレ以外の部分も強化が入ったTuringアーキテクチャにとことん迫る
SIGGRAPH 2018のタイミングで新世代GPUアーキテクチャ「Turing」(テューリング)と,Turing採用のGPU「Quadro RTX」を発表したNVIDIAは,その直後のgamescom 2018において,Turing世代のゲーマー向けGPUとなる「GeForce RTX 20」も発表した。
筆者の連載ではこれまで,発表時点の情報に基づいて独自に考察を行ったり,突発的に開示された追加情報の解説を行ったりしてきたわけだが,ついに,Turingアーキテクチャの詳細情報が解禁となったので,今回はそのあたりをとことん紹介してみたいと思う。
なお,本稿の内容は,NVIDIAが抱えるGPUアーキテクトの1人で,GPUエンジニアリング担当上級副社長であるJonah M.Alben(ジョナ・アルベン)氏が報道関係者向け事前説明会で語った内容がベースとなる。
まず,基本的な情報の確認からだが,「GeForce RTX 2080 Ti」(以下,RTX 2080 Ti)は「TU102」コア,「GeForce RTX 2080」(以下,RTX 2080)は「TU104」コア,「GeForce RTX 2070」(以下,RTX 2070)は「TU106」コアを採用する。トランジスタ数とダイサイズ,総CUDA Core数は以下のとおりだが,正直,3製品がすべて異なるシリコンダイだとは思わなかった。
ちなみに,従来のグラフィックス用途向けGPUだと「Graphics」もしくは「GeForce」の頭文字となる「G」の後にアーキテクチャ名の頭文字が来る――「GeForce GTX 1080」(以下,GTX 1080)なら「GP104」――仕様だったが,今回はTuringアーキテクチャの頭2文字が3桁数字の前に来るという,新しいコア名表記になっている。
さて,まずはTU102の全体ブロック図を下に示すが,ほぼ筆者が推測したとおりの内部構成だと言っていいだろう。
ここからしばらくはこの全体ブロック図を見ながら語っていきたいが,CPUで言うところの「コア」に相当するミニGPUクラスタ「Graphics Processor Cluster」(以下,GPC)は6基で,これは「Volta」アーキテクチャ世代の「GV100」や「Pascal」アーキテクチャ世代の「GP100」と同じだ。
一方,GPCが内包する演算コアクラスタ「Streaming Multiprocessor」(以下,SM)は,GV100の14基,GP100の10基に対してTU102では12基となっている。
SMあたりのブロック図は以下のとおりである。
GV100と比較してGPCあたりのSM数が2基減ったTU102だが,SM自体の構成はGV100とよく似ている。説明会では「TU102はGV100をベースにして設計した」という発言があったが,なるほどという感じである。
TU102のSMはGV100のそれと同様に4ブロック構成となっており,ブロックごとにWarpスケジューラ(Warp Scheduler)と命令発行ユニット(Dispatch Unit)がある。つまり,SMあたり同時に4つのデータスレッドに対して処理を仕掛けられるということだ。
ただ,細かく見ていくと,GV100のSMとは異なる点もいくつか確認できる。
1つはロード/ストアユニット(LD/ST)の数だ。GV100ではブロックあたり8基,SM全体で32基あったロード/ストアユニットが,TU102ではブロックあたり4基,SM全体で16基で,半分になっている。ここは,グラフィックス用途に特化した設計となるTU102ならではのチューニングといったところなのだろう。
SMあたりの32bit浮動小数点(FP32)演算器,32bit整数(INT32)演算器はともに64基ずつ。ここはPascal世代までのSMブロック図だと「CUDA Core」と呼ばれていた部分なので,「SMあたりのCUDA Core数は64基」という理解でも問題ない。
さて,そのCUDA Core数はTU102のフルスペックだと4608基だ。構成としては下記のようになる。
ただし,4608基のCUDA Coreがすべて動作するのは今のところ「Quadro RTX 8000」「Quadro RTX 6000」に限定される。RTX 2080 Tiの総CUDA Core数は4352基なので,いくつかのGPCでSMが無効になっているわけだ。
Pascal世代を振り返ってみると,GP102コアを採用する「GeForce GTX 1080 Ti」(以下,GTX 1080 Ti)の場合,6基あるGPCのうち2基でSMの数を少なくする無効化パターンを採用していたので,おそらくこれと同じような仕様になっているはずだ。構成式としては以下のような感じである。
RTX 2080 Tiは「Founders Edition」のブーストクロックが1635MHzとなるので,
で,約14.2 TFLOPSとなる。TU102フルスペックのQuadro RTX 8000だと16 TFLOPSなので,それと比べるとやや低い。
以上を踏まえつつ,TU104とTU106のブロック図も確認しておこう。まずはTU104からだ。
TU104も6GPC構成だが,GPCあたりのSM数が8基となるのがTU102との大きな違いだ。TU104のフルスペック版は総CUDA Core数3072基の「Quadro RTX 5000」で,構成としては以下のとおりである。
それに対してRTX 2080は総CUDA Core数が2944基なので,フルスペックからSMが2基無効になった製品ということになる。
続いてはTU106だが,こちらはTU102を半分にしたような構造になっており,GPCあたりのSM数もTU102と同じ12基となる。
RTX 2070はTU106のフルスペック版となるため,
という計算式が成り立つ。ここからSMをいくつか無効化すれば,“GeForce RTX 2060”的なGPUを派生させることは容易だろう。
Turingアーキテクチャにおける重要な新要素として挙げられるのは,Volta世代のGV100に対し,FP32演算器とIN32演算器が若干パワーアップした点である。
具体的に言うと,Turing世代のGPUではFP32演算器とINT32演算器をほぼ並列動作させられるようになった。
「ほぼ」なのは,1クロックでFP32演算とINT32演算を同時発行することまではできないためで,たとえば偶数クロックでFP32演算器に命令を発行し,奇数クロックではINT32演算器に命令を発行するといったメカニズムになっている。従来,そうした命令の発行は行えなかったので,Turingアーキテクチャ世代で改善が入ったという理解でいい。
FP32演算とINT32演算が事実上のオーバーラップ実行ができるので,その分の性能向上を見込めるというわけだ。
その理屈を解説したのが下の図になる。
この図は,ゲームタイトルごとの各シェーダ処理においてFP32演算だけが実行されるケースを「1.0」として黄緑バーで表したうえで,FP32演算とINT32演算の両方が実行されるケースを深緑バーで表したグラフだ。「TuringアーキテクチャのGPUであれば深緑バー部分をオーバーラップ実行できて時間短縮が見込めるため,性能向上を期待できる」ということになる。
実際のシェーダ処理において,INT32演算は画像テクスチャ処理に関連した各種論理演算などでけっこう使ったりする。なので,この改良はゲームグラフィックスにけっこう“効いてくる”はずだ。
さて,NVIDIAが公開したSMブロック図だと,倍精度浮動小数点(以下,FP64)演算器は描かれていないのだが,事前説明会では「従来のGeForceシリーズと同じ比率で実装している」という話があった。従来のGeForceだと,
という仕様なので,これをSMあたり64基のFP32演算器を搭載するTuringアーキテクチャに当てはめると,SMあたりのFP64演算器数は2基ということになる。
Turing世代のGPUにおけるキャッシュシステムとShared Memory(以下,共有メモリ)構成は,Volta世代のGV100をベースにした,サブセット的なものになっている。
振り返ると,GV100ではL1キャッシュと共有メモリを「総容量128KBのキャッシュメモリ」として統合し,このうち最大96KBをL1キャッシュとして利用し,残りを共有メモリとして利用するという仕様になっていた。
それに対してTuringアーキテクチャの場合,L1キャッシュと共有メモリを統合するところはGV100と同じながら,その総容量は96KBと4分の3に減っている。また,L1キャッシュと共有メモリの構成パターンは64KB+32KBか32KB+64KBの二択となる。
付け加えると,GTX 1080が採用するGP104コアの場合,「L1キャッシュ容量24KB×2,共有メモリ容量96KB」という,用途別に容量を固定的に割り当てる設計だったので,総容量で言えばTuringアーキテクチャにおけるL1キャッシュおよび共有メモリはGP104以下ということにもなる。
ただし,Turing世代ではGP104と比べてL1キャッシュの動作クロックを2倍にして実効帯域幅を引き上げているため,そのキャッシュ性能は劇的に向上しているとのこと。前段で触れた「FP32とINT32のオーバーラップ実行」と,本段落で触れたキャッシュ性能の引き上げによって,CUDA Coreあたりの3Dグラフィックス処理性能はGP104比で1.5倍以上になっているという。
ちなみに筆者は8月24日掲載の記事で「RTX 2080の性能を示すグラフがGTX 1080と比べて理論演算性能値以上に開いている」という話をしたが,NVIDIAの説明をそのまま受け入れるなら,これこそが「FP32とINT32のオーバーラップ実行」と「キャッシュ性能の向上」の効果なのだろう。
組み合わせるグラフィックスメモリは,Turing世代で業界初のGDDR6となった。「GDDR6とは何か」という話は大原雄介氏による解説記事を参照してほしいが,GDDR5Xと同じく実クロックの8倍速駆動となるメモリで,RTX 2080 TiとRTX 2080,RTX 2070の場合,いずれもデータ転送レートは14Gbps。4Gamerの慣例表現に従うと「14GHz相当」の動作クロックとなる。
Pascal世代の中上位モデルが採用していたGDDR5Xの場合,メモリインタフェースの設計をGDDR5と共用できることが利点として訴求されていたが,さらなる広帯域幅を実現すべく,GDDR6ではGDDR5世代と互換性のない信号設計を採用している。その新設計により,信号のクロストークはGDDR5世代に対して40%も低減できたため,GDDR6のロードマップ上ではデータ転送レート16Gbpsの製品化予定もある。
TU102コアを採用するQuadro RTX 8000とRTX 2080 Tiの場合,メモリインタフェースは順に384bit,352bitなので,その帯域幅は以下のとおりとなる。
動作クロック1.75GHz相当のHBM2を搭載し,4096bitのメモリインタフェースでGPUと接続させたVolta世代のGPUだとメモリバス帯域幅は900GB/sとなるが,GDDR系の帯域幅がそんなHBM系に少しずつ近づいてきているのは興味深い。
ちなみにPascal世代のGeForceだと,GTX 1080 Tiで484GB/s,GTX 1080で320GB/sだった。
Turingアーキテクチャにおける最大の特徴が,これまでのGPUにはなかった「リアルタイムレイトレーシングアクセラレータ」的な機能の搭載にあることは論を俟(ま)たないだろう。
このリアルタイムレイトレーシングアクセラレータに相当するのが「RT Core」である。RTは当然「Ray Tracing」(レイトレーシング)の略だ。
そもそも,レイトレーシングとはどういうものなのだろうか? 「DirectX Raytracing」が発表になった3月のタイミングで詳しく紹介しているが,ここでも簡単に紹介しておこう。
レイトレーシングは,あるピクセルの色を計算するとき,当該ピクセルが受け取っているはずの光の情報を探るために光線(ray)を射出してたどる(trace)処理のことを指す。
光線の射出方向と角度は回収したい情報の種類によって決まる。たとえば,近くの光源に向かって光線を射出して光源に到達できれば,そのピクセルはその光源に照らされていることが分かる(下図1)。光源に達する前にほかの3Dオブジェクトと衝突すれば,そのピクセルは3Dオブジェクトによって影になっていることが分かる(下図2)。さらに,当該ピクセルを見つめるユーザーの目線の反射方向に光線を射出して,他の3Dオブジェクトに衝突したとしたら,そのピクセルには「衝突した3Dオブジェクトが映り込んでいる」と判断できる(下図3)。
RT Coreというハードウェアが担当するのは,そんなレイトレーシングにおける光線の生成処理と,光線を動かす「トラバース」(traverse,横断)処理,衝突判定を行う「インターセクション」(Ray-sphere intersection,交差)判定なのである。
基本概念の理解としてはこれで十分なので,ここからはもう少しハードウェアに近い視点でRT Coreの処理系を見ていくことにしよう。
光線の生成は初期設定を行う処理系であり,その後に続く処理のために作業用のメモリ領域を確保して,そこに光線の初期パラメータを設定するだけのものだと言うとイメージしやすいだろう。この下準備の発動はプログラマブルシェーダ(=CUDA Core)から行われる。
イメージしにくいのはトラバースとインターセクションのところだと思う。
最もシンプルなアルゴリズムは,光線を一定距離分だけ進めて,その先で何らかの3Dオブジェクトに衝突していないかを判定するという処理系になる。ただ,何も考えずにこの処理系を実装した場合,光線が一定距離進むたびに「その3Dシーンを構成するすべてのポリゴン」に対して総当たりで衝突判定を行わなければならなくなる。言うまでもないが,これはとんでもなく重い処理になってしまって現実的ではない。
そこで近代レイトレーシングのアルゴリズムでは,3Dシーンに存在する3Dオブジェクトを囲うようなXYZ各軸に平行な直方体(=箱)の階層構造で表現しておき,ポリゴン単位の衝突を突き止める前段階として直方体との衝突判定を行うような実装になっていることが多い。
下の図ではウサギのモデルを複数の直方体で囲っているが,もしこのウサギがウサギ小屋の中にいるなら,ウサギ小屋を囲うような「上位層の直方体」も定義することになる。
この実装を行えば,光線は「3Dシーンをおおざっぱに囲った,大きな直方体」との衝突判定を行うだけで済む。もしこれらの直方体と衝突しなければ,「射出した光線は何モノとも衝突しなかった」という結果を,「光線を1回進める」だけの処理で得ることができる。
一方,光線が何かしらの箱と衝突した場合は,階層を一段降りて,「より細かい直方体」への衝突判定へと移行することになる。
最も小さな直方体との衝突を突き止めらたら,最終的に,この直方体に含まれるポリゴンと,ここでようやく総当たりの衝突判定を行うのである。
衝突判定の計算はどれほど複雑なのかという話だが,イメージできるように,直方体との衝突判定は難しくない。直方体は8つの頂点を持っているので,光線の通過する座標が8頂点の内部に入り込んでいるか否かを計算するだけでいい。高級言語で言うところの「IF A<B」の組み合わせだけで判定できてしまう。用いる計算も減算だけだ。
最下層にある一番小さな直方体へたどり着いたときに生じる「光線とポリゴンとの衝突判定」も,計算内容自体は,いま述べた「直方体との衝突判定」と大差ない。ただし,当該直方体が含む複数のポリゴンすべてとの衝突判定は必要なので,反復的な処理系にはなる。
さて,衝突したポリゴンを特定できたら,このタイミングで当該ポリゴンに関する情報を光線の射出元に返すわけだ。
光線とポリゴンがいずれも「3D的な向き」を持っているというのは想像できるだろう。そのとき,ポリゴンと衝突したレイの反射ベクトルを求めたりするのはプログラマブルシェーダ(=CUDA Core)の仕事であって,RT Coreの仕事ではない。また,光線が持ち帰った情報を基にしてさまざまなシェーディング処理やライティング処理などを行うのもプログラマブルシェーダ(=CUDA Core)側の仕事になる。
ここで,「なんだ,RT Coreってシンプルな仕事しかしてないじゃん」と思った人もいると思う。しかし,いま述べた処理をプログラマブルシェーダでシェーダプログラムとして実装しようとすると,かなり大変だ。
そもそも,「直方体の階層によって成立しているデータ構造を読み出して,そこから必要な情報を取り出す」処理系の難度が高い。直方体の階層構造はいわゆる「木構造」(入れ子構造)データなので,その読み出しはほとんど「デコード処理」的なものになる。
また,衝突判定もいわば条件分岐処理なので,GPUにとっては苦手なものとなる(※)。
※複数のデータに対して並列にプログラムを適用していくという実行スタイルを採用するGPUにとって,たとえばA分岐とB分岐があった場合,すべてのデータに対する総処理実行時間は「A分岐とB分岐の両方を実行したサイクル数」に近いものとなってしまう。これは分岐命令のPredication(叙述)実行による弊害である。
なので,直方体の木構造データをデコードする処理と,光線と直方体との衝突判定処理,光線とポリゴンとの衝突判定処理を,NVIDIAはRT Coreという専用ハードウェアで実装したというわけなのだ。
NVIDIAいわく,RT Coreの性能は「GTX 1080 Ti(でプログラマブルシェーダベースの実装を行ったとき)と比べて約10倍高速」とのこと。さすがは専用ハードウェアといったところである。
ちなみに,RT Coreはプログラマブルシェーダではないため,プログラムすることはできない。完全な固定ユニットだ。だからこそ,解像度1920
さてここで,筆者の連載バックナンバー「GeForce RTX 20なぜなに相談室(gamescom 2018版)」における予測が1つ外れたことに触れなければならない。
筆者は,総CUDA Core数が4352基のRTX 2080 Tiと4608基のQuadro RTX 8000(とその下位モデルである「Quadro RTX 6000」)とで,RT Coreの性能値が毎秒100億レイであることから「RT CoreはSMに内包されない実装なのではないか」という予測を述べていた。ただ,本稿の序盤でも示したTU102のSMブロック図から明らかなとおり,RT CoreはSMに内包される実装となっている。
つまり「SM数=RT Core数」ということだが,それを踏まえ,GeForce RTX 20シリーズのRT Core数と毎秒あたりの公称レイ生成数を下に示す。
ここであることに気付く。そう,RT Core数にGPUごとのブーストクロックを掛けてやると,「毎秒あたりのレイ生成数」の10倍に近い数字が得られるのだ。そこから「レイの生成に10クロックくらいかかる」という考察も行えるが,ともあれ計算すると,
と,かなりそれっぽい値になることが分かる。
1つのレイを生成するのに要するクロック数が正確かというのはともかく,Turingアーキテクチャを採用するGPUにおけるRT Coreの公称性能値が,SM数(≒RT Core数)とブーストクロックに比例したものになっていることだけは間違いない。
「Tensor Core」(テンサーコア)は,各要素が最大16bit浮動小数点形式(以下,FP16)で最大4×4要素の行列同士を積和算できるプロセッサだ。この積和算はデータ列同士で畳み込み演算を行うときに多用されるものなので,実際のところGPUをGPGPU的に活用するときにも利用できなくはない。
しかし,機械学習や深層学習における学習処理,あるいは学習データを基に入力データから推論を導き出す推論処理において,行列同士の積和算が多用されることから,NVIDIAはVolta世代のGPUで,専用ユニットとしてのTensor Coreを搭載してしまった。
もちろんVolta世代のGPUは事実上のAI研究開発用途に向けプロセッサなので,Tensor Coreの搭載も「AI開発支援に向けたNVIDIAの傾倒はすごいな」という話だったのだが,GeForceとして市場投入されるTuringアーキテクチャのGPUでもTensor Coreを搭載してくることまでは想像していなかった人のほうが多いのではなかろうか。
TuringアーキテクチャのGPUがTensor Coreを搭載する理由は,8月23日掲載の記事でもお伝えしたとおり,深層学習型AIを用いたポストプロセス処理「DLSS」(Deep Learning Super Sampling)を実行するためである。
「描画済みのグラフィックスに対して,学習データに基づいてAIがレタッチするメカニズム」を実用化するため,NVIDIAはTuring世代のGPUにもTensor Coreを搭載したのだ。
それだけではなく,ゲーム用途におけるTensor Coreの活用の環境整備に向けて,NVIDIAは「NGX」を発表している。
NGXは,「膨大な画像を深層学習させて得た学習データを基に,AI的な推論的画像処理を行うアプリケーション」を開発するためのフレームワークである。実のところDLSSは,NGXのお手本的な応用事例という位置づけだったりする。
AI研究者や開発者はNGXを利用することでAI的な推論的画像処理を行うアプリケーションを開発できる。それに対して一般的なゲーマーはNGXの枠組みを利用して,当面はDLSSを利用することになるわけだ。
DLSSで提供されるAI画像処理というのは,具体的には「アンチエイリアシング処理」「超解像アップスケール処理」「時間方向のチラツキ(≒フリッカー)低減」「(レイトレーシングなどの)ノイズ低減」など。学習自体はNVIDIA側で行うか,ゲームデベロッパとの協業で行う仕様となっており,ゲーマーはその結果としての「DLSSプロファイル」的なものを,「GeForce Experience」など経由で定期的に受け取ることになる。
NVIDIAによれば,学習データは広く使える汎用タイプのものや,特定のゲームタイトル専用のものまで多岐にわたるらしい。
Turingアーキテクチャにおいても,Volta世代と同じく,Tensor CoreはSMに内包されている。SMあたりのTensor Core数は8基なので,72 SM構成のRTX 2080 Tiだと,総Tensor Core総数は576基となるわけだ。
理論性能値は,4×4要素の行列同士による積和算だと,計算量としては「4×4の16要素に対して4回の積和算(2 FLOPS)を行う」ことから,やはりブーストクロック基準で,
となって,公称値である113.8T Tensor FLOPSとほぼ一致する。
なお,画像処理用の深層学習型AIや機械学習型AIの学習データを推論エンジンに載せる場合,FP16精度は不要で,整数で表せる固定小数点形式でも精度的に十分だ。そのため,TuringアーキテクチャのGPUが搭載するTensor Coreでは8bit整数(以下,INT8)や4bit整数(以下,INT4)の演算も取り扱えるようになっている。ここは地味ながら,Volta世代と比べて機能向上した部分だと言える。
8月23日掲載の記事で「数値の根拠が不明」と述べることしかできなかった,NVIDIA独自のGPU性能指標「RTX-OPS」だが,この謎がついに解けた。
結論から先にお伝えすると,RTX-OPSはあくまでもNVIDIAが発明した独自の性能指標であって,正確な理論性能値とは言いがたい。イメージ的には,かつてAMDがCPUで採用していた,「競合製品と比べてどれくらいの性能が得られるかをイメージした数字」に近いものだ。実クロック2.4GHzのCPUを「Athlon 64 X2 4800+」と呼ぶ,みたいな感じである。
そのRTX-OPSだが,算出の根拠は,先の記事で同じく謎キーワードだとしていた「1 Turing Frame」にあった。
1 Turing FrameというのもNVIDIAが独自に考案したものなだが,意味合い的には「Turing世代のGPUをフルに使ってグラフィックスを描画するケースにおける各演算ユニットの稼働率としてNVIDIAが想定した内容を,フレーム単位で図示したもの」だ。
言うまでもないが,「稼働率」はゲームやゲームエンジンごとのグラフィックス処理の設計や実装形態によって異なる。なので,相当レベルでNVIDIAの恣意的な想定に基づいた値になるのだが,とにかくその1 Turing Frameにおける「演算ユニットごとの稼働率」を,NVIDIAは以下のとおり,追加で公開してきた。
このスライドによると,稼働率はFP32演算ユニットが80%,INT32演算ユニットが28%,RT Coreが40%,Tensor Coreが20%になるのだそうだ。そして,このパーセンテージを係数として,各演算ユニットの理論性能値に対してそれぞれ掛ける。そのうえで総和を求めると,それがRTX-OPSとなるのだ。たとえばRTX 2080 Tiの場合,計算式は以下のとおりとなり,NVIDIAの主張する78 RTX-OPSの計算式と合致する。
ただそれでも「数値の根拠はよく分からない」とは思う。とくに理解の難度を上げているのは,100 TFLOPSという,RT Coreの途方もなく高い「見立て性能値」だと筆者は考えているが,その背後にあるのは,NVIDIAによる,極めて独自性の高い解釈である。
いわく,「理論性能値11.3 TFLOPSのGTX 1080 TiのプログラマブルシェーダででRT Coreの処理を再現したとすると,1.1G Rays/sのレイ投射性能が得られる。だから,約1G Rays/sを実現するために必要な理論演算性能は約10 TFLOPSだ。よって,公称値として10G Rays/sを達成しているRTX 2080 TiのRT Coreの理論演算性能値は100 TFLOPSなのである」とのことだ。
正直,これはさすがにやりすぎ感が否めない。そもそもの話として,「RTX-OPSの計算式に入れているほかの演算ユニットはFP32基準なのに,Tensor CoreだけFP16」とか,「INT32の理論性能値をFLOPS性能値と同列にして加算していいのか」とか,いくらでもツッコミを入れられてしまう。
実際,この「トンデモ算数」の発表時には,事前説明会に参加していた各国のメディア陣から静かな笑いが起きていたが,まあ,根拠を示さない数字がいくらでも出てくる世の中にあって,計算結果をちゃんと求められる数値を出したNVIDIAは立派だと言えなくもない(?)。
プログラマブルシェーダの歴史はDirectX 8(≒Direct3D 8)とともに始まったわけだが,その後,
がそれぞれジオメトリパイプラインに追加となった。DirectX 8の時点では頂点シェーダ(Vertex Shader)しかなかったジオメトリパイプラインは,良くも悪くもずいぶんと複雑になってきたのである。
問題は,ゲーム機であるPlayStation 4やXbox One,そしてNintendo SwitchのGPUにもジオメトリシェーダとテッセレーションステージが搭載されるほど一般化したにもかかわらず,それらを活用しているゲームタイトルがほとんどないことだ。頂点シェーダを除くと,ジオメトリパイプライン上のプログラマブルシェーダは今やほとんど盲腸化している。
もっとも,ジオメトリシェーダはまだいいほうで,GPU制御のパーティクルシステム実装や,キューブマップのレンダリングやボクセルデータ構造の生成に使われるケースはある。
悲惨なのはテッセレーションステージのほうだ。
テッセレーションステージはもともと,「遠方の3Dモデルはシンプルな形状の少ポリゴンで描画」「近傍の3Dモデルはディテールのしっかりした多ポリゴンで描画」「その間はポリゴンを適宜分割して無段階の詳細度の3Dモデルを生成して描画」という,高い理想を実現するために考案されたものだった。
しかし,これを実現しようとすると,3Dモデルのデータ構造をあらかじめ,テッセレーションステージの活用に適合した仕様にしなければならず,これが面倒だということで敬遠されてしまった。そもそもDirectX 11時代最初期に登場したGPUのテッセレーションステージは遅くて使いものにならず,そこでミソが付いてしまったというのもあるように思う。
遠方,近傍,中間距離の3レベル程度で異なる詳細度の3Dモデルを用意しておいて,それらを視点からの距離に合わせて適当に切り換えて描画する,昔ながらのLoD(Level of Detail)システムの運用でも,動的なキャラクターだと見栄えに違和感はほとんどなかったりするので,「これでいいや」という判断が続いてしまったというのも大きい。
とはいえ,地形や木々,建物などの「動かない,大きめの背景物オブジェクト」は,プレイヤーがフィールドを歩み進んでいく流れで,一定距離でまとめてLoDレベルが切り替わったりするため,切り替わりが目に付きやすい。LoDレベルの切り換えポイントで3Dモデルの体積が大きく変わることを「ポッピング」というが,これを目の当たりにしたことはゲーマーなら必ずあるはずだ。
そこでNVIDIAは,「昔ながらのLoDシステム」の実装形態ほぼそのままでテッセレーションステージの恩恵を受けられる,新しいプログラマブルシェーダをTuring世代のGPUに新設した。それが,「メッシュシェーダ」(Mesh Shader)である。
実際には,メッシュシェーダを制御する上層のプログラマブルシェーダとしてNVIDIAは「タスクシェーダ」(Task Shader)も新設している。パイプライン構造としては,あらかじめ複数のLoDレベルに分かれた3Dモデルをタスクシェーダの管轄下に置いておいて,タスクシェーダが適宜メッシュシェーダを活用するというものになる。
流れをもう少し詳しく見てみよう。
タスクシェーダは,これから描画する3Dモデルと視点との距離,視点との向きに応じて,適切なLoDレベルを計算する。そして,LoDレベルがたとえば「2.5」だった場合,LoDレベル2の3DモデルとLoDレベル3の3Dモデル,それらの中間となるディテールを持った3Dモデルをメッシュシェーダで生成するのだ。
この説明だと,タスクシェーダとメッシュシェーダの処理系が3Dモデル単位のように思えるかもしれないが,実際の処理系はポリゴン単位となるので,その点は注意してほしい。
要するに,異なるLoDレベルの3Dモデル同士に対してポリゴンがどう対応するか,トポロジーの定義が不可欠ということである。なので,「従来型の離散的なLoDシステムを採用したグラフィックスエンジンがTuring世代のGPU上で実行された場合,自動的に無段階LoDシステムに変身してしまう」わけではない。
いずれにせよ,テッセレーションステージと比べると面倒は少なそうだが,それでも,3Dモデルのデータ構造は,タスクシェーダやメッシュシェーダで実装したシェーダプログラムの仕様に合わせて弄る必要はある。
下に示した動画はNVIDIAが開発した,タスクシェーダとメッシュシェーダの効果を分かりやすく示したものだ。
デモ自体は,岩の塊が浮遊する宇宙空間を突き進むというシンプルなものだが,ここでシーンを埋め尽くす隕石の数は総数30万〜40万個。これを最も詳細度の高いLoDレベル0ですべて描画したとすると1フレームあたり約5兆ポリゴンの描画になってしまう。ところが,タスクシェーダとメッシュシェーダを活用することで,実描画数は1000万ポリゴン程度に抑えられるというのが,このデモのアピールポイントになる。
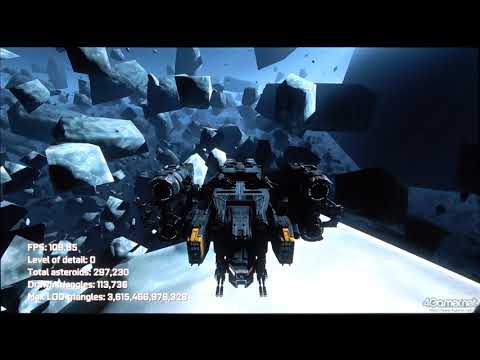
要するに,「メッシュシェーダの活用によって,描画するポリゴン数を実に50万分の1にまで削減できている」というアピールなのだが,実際には,視点に近い側の隕石に遮蔽されて視点から見えなくなった隕石や,1ピクセル未満となってしまった遠方の隕石は,いずれも描画対象から外す「カリング処理」をメッシュシェーダと組み合わせた成果となっている。
そう,タスクシェーダはLoDレベルの選択だけでなく,プログラム次第で早期カリング処理をも実装できるということなのだ。
ちなみに,こうしたジオメトリパイプラインの改良版の発表は,AMDも「Radeon RX Vega」発表時に行っている。AMDが発表したのは「プリミティブシェーダ」(Primitive Shader)だった。
ただこのプリミティブシェーダ,発表こそ大々的になされたものの,どうやれば使えるのかがいまだ明らかになっておらず,当然のことながら誰も使っていない。
その意味では,今回のタスクシェーダとメッシュシェーダも「使い方は明らかになっていない」点でプリミティブシェーダと同じなのだが,事前説明会場にいたNVIDIA関係者によれば,こうした改良版ジオメトリパイプラインは次世代のDirectXから使えるようにすべく,Microsoft側で準備を進めているとのことだった。
どこまで信用していいのかという話ではあるが,ひょっとすると,この秋の正式リリースが予定されている「DirectX Raytracing」に合わせて,タスクシェーダとメッシュシェーダ,プリミティブシェーダが利用可能になるかもしれない。
ジオメトリパイプラインに対してのみならず,ピクセルパイプラインに対しても,TuringアーキテクチャでNVIDIAは独自の改良を行い,その新しいピクセルパイプラインのレンダリング概念に「Variable Rate Shading」(ヴァリアブルレートシェーディング,以下 VRS)という名を与えている。
VRSが採用するのは非常に独特なメカニズムで,Turingアーキテクチャ世代のGPUが搭載する専用のハードウェアによってアクセラレーションを行うため,現行のDirectXからは利用できない。その点ではタスクシェーダやメッシュシェーダと同じだ。
ではどういうものかというと,ピクセルシェーダによってライティングおよびシェーディングされるピクセルの解像度をプログラマブルに制御するものとなる。
言うまでもないことだが,通常,ポリゴンがラスタライズされてピクセルに分解されたあとは,ピクセル単位でピクセルシェーダが起動され,当該ピクセルの色を計算する。光源からのライティング計算や,当該ピクセルの材質パラメータに見合った変調を行った結果などから最終的な色は決まるわけだ。
それに対してVRSは,この「ピクセルシェーダの起動解像度」を1×1ピクセルと2×2ピクセル,2×1ピクセル,1×2ピクセル,4×2ピクセル,2×4ピクセルから任意に選択できるようになっている。言い換えると,VRSを使えば,画面内の任意の箇所においてピクセルシェーダの計算解像度を落とせるのである。
なぜこのようなメカニズムが必要なのか。NVIDIAは「世の中には,まじめにフル解像度でレンダリングしても報われない状況がいっぱいあるから」だとしている。
直観的に分かりやすいのは,VR(Virtual Reality,仮想現実)における視線追従描画システム(Foveated Rendering,フォヴィエイティドレンダリング)だろう。ユーザーが注視している領域は「意識的に集中して見られている」のでフル解像度でレンダリングしつつ,それ以外の領域では「注視している領域」からの距離に応じて解像度を落としていったとしても,ユーザーにはバレにくい。このアプローチこそが視線追従描画システムの基本概念であり,実際,これまでにさまざまな実装手法が提唱されてきた。
VRSは,そうしたさまざまな視線追従描画システムの手法をハードウェアでアクセラレーションする仕組みと言っていい。NVIDIAは「VRにおいては,ヘッドマウントディスプレイに搭載される接眼レンズの拡大率不均衡特性にも応用できるだろう」とも述べている。
さらにNVIDIAは,「VR以外の一般的なゲームグラフィックスに対してもVRSは効果を発揮できる」として,「Wolfenstein II: The New Colossus」へ独自にVRSを組み込んだ改造版(以下,Wolfenstein II改)を披露した。Wolfenstein II改では,「Content Adaptive Shading」(コンテントアダプティブシェーディング,以下 CAS)と「Motion Adaptive Shading」(モーションアダプティブシェーディング,以下 MAS)をVRSにより実装してあるそうだ。
CASは,情報量が低い領域に対して解像度を下げてライティングおよびシェーディングする手法である。画像工学的に言えば「情報量が低い領域」は「低周波成分が多い領域」だが,「のっぺりした面表現が主体となっている領域」という理解でいい。
逆に「情報量が多い領域」は「高周波成分が多い領域」で,「ごちゃごちゃとディテールが描写されている領域」のことを指すが,ごちゃごちゃしている領域に対して低解像度でライティングやシェーディングを行うとアラが見えてしまう。なのでそこはなるべくフル解像度で処理し,一方でのっぺりした領域は適宜解像度を落として処理するイメージになる。MPEG-4圧縮において,低周波成分を低解像度ブロックで圧縮して情報量を減らす仕組みとちょっと似ている。
続いてMASだが,こちらは画面内にあるオブジェクトの移動速度に合わせてライティングとシェーディングの解像度を変える手法である。
高速に動いている動体は,人間が目で追ってもボケて視覚されやすいので,この特性を逆手にとるわけだ。具体的には,高速度で移動しているオブジェクトほど低解像度でライティングおよびシェーディング処理し,遅いオブジェクトほど高解像度でライティングおよびシェーディング処理することになる。
FPSで視点移動をすると,近景は速く動き,遠景は遅く動くので,MASを実装した場合,近景は低解像度で,遠景は高解像度でそれぞれライティングおよびシェーディング処理されることになる。シーン内を動き回っている敵キャラクターだけがMASの対象というわけではなく,画面全体の総合的な動き速度を吟味してライティングおよびシェーディング処理の解像度は決まる仕様だ。
ちなみにCASは「あらかじめ用意しておいた周波数情報を仕込んだテクスチャ」の情報を基にして,MASは「モーションブラーの生成などに利用されるベロシティバッファ」の情報を基にして実現する。

なお,誤解のないようにあえて補足しておくが,Turingアーキテクチャで実現しているのは,VRSというアクセラレーションメカニズムだけであり,「VRSを活用するとプログラム次第でこうしたCASやMASを実現できる」ということである。VRSがCASやMASと同義ということではない。
以上が,Turingアーキテクチャ解説のメインディッシュだが,細かな情報も判明したので紹介しておこう。
まずはビデオプロセッサからだが,H.264/MPEG-4 AVCとH.265/HEVCのエンコードおよびデコード処理に対応しているのはPascal世代と同じながら,その性能はTuring世代で向上している。
とくに重要なのはスループットがPascal世代比で約2倍になっている点で,これにより,ついに7680
Pascal世代でNVIDIAは3840
また,エンコーダの圧縮アルゴリズムにも改良が入っており,Pascal世代と比較して,同じ画質ならH.264で15%,H.265なら25%も低ビットレート化できるようになった。逆に言えば,同じビットレートならPascal世代のGPUを使うよりも高い画質を得られるということだ。
次にインタフェースだが,HDMI周りのアップデートはとくにない。期待されていたHDMI 2.1のアップデートはなく,Pascal世代と同様にHDMI 2.0bまでの対応となる。
一方,DisplayPortではPascal世代の1.4から1.4aに変わり,1本のDisplayPortケーブルで8K 60Hz出力が可能になった。DisplayPort 1.4aでは,ライン・バイ・ライン(≒走査線ごとの)不可逆圧縮伝送方式である「DSC」(Display Stream Compression)を採用したことで,映像の劣化を許容しながらも8K 60Hz伝送に対応したのだ。余談気味に続けると,HDMI 2.1でも同様の伝送方法をサポートしている。
DisplayPort 1.4aでDSCを使わない場合,1本のケーブルだと8K 30Hz出力が上限だ。もちろん2本のケーブルを同期させて伝送すれば劣化なしの8K 60Hz出力を行えるが,このあたりはPascal世代から変わっていない。
もう1つビデオ出力周りで重要なのは,USB 3.1 Gen.2 Type-Cインタフェースを採用したことだろう。USBコントローラはGPUコアに統合されているため,搭載するグラフィックスカードから直接Type-Cインタフェースを利用できる。
このUSB Type-CポートはUSBポートのマルチユースに対応した「USB Alternative」(以下,USB Alt)モードに対応しており,USB AltモードでDisplayPort信号を出力できるDisplayPort Alternativeモードを利用できる。また,最大27Wの給電も可能だ。
表向きの用途は「Type-Cケーブル1本でVR対応ヘッドマウントディスプレイと接続して,データと映像の伝送を同時に行う『VirtualLink』用」だが,当然,汎用のUSB 3.1 Gen.2端子としても利用可能だ。
なお,ビデオ出力周りでは,「BT.2100」規格に準拠した,HDR映像のトーンマッピングハードウェアを搭載するというアピールもNVIDIAは行っていたが,現在のところ詳細は明らかになっていない。おそらくは,NVIDIAが推進中の「G-SYNC HDR」関連か,HDMIあるいはDisplayPort出力にあたってVESAのHDR規格「DisplayHDR」(※正式名称は「VESA High-Performance Monitor and Display Compliance Test Specification」)に適合するディスプレイマッピング(※ディスプレイの輝度スペックにあわせて階調特性を調整すること)処理を行うものと見られる。
2枚のグラフィックスカードでマルチGPU構成とするSLIは,TU102コアのRTX 2080 TiとTU104コアのRTX 2080でのみサポートとなり,TU106コアのRTX 2070ではサポートされない。
また,Turing世代のGPUにおけるSLIは,従来のSLIと互換性がない点も押さえておきたい。今世代で採用するSLIでは,GPUとGPUとを専用インタフェースで相互接続する「NVLink」ベースだ。
NVLinkは,Pascal世代コアのGP100を採用したGPGPU専用製品「Tesla P100」とともに登場した相互接続リンクで(関連記事),複数のGPUを協調動作させるためのものとなる。
従来のSLIは,レンダリング結果として出力されたピクセルデータだけを共有するものだったが,NVLink時代のSLIでは,2基のGPUがまるであたかも1つのGPUのように振る舞って動作できるところに特徴がある。
たとえばRTX 2080 Tiを2枚差ししたシステムでは,総CUDA Coreが8704基(=4352基×2)に上る1基のGPUとして動作させることができるのだ。なので,これまでのSLIのように「Alternate Frame Rendering」(AFR)や「Split-Frame Rendering」(SFR)のような特別なレンダリングモードでGPUを駆動する必要がない。
またグラフィックスメモリも共有できるため,RTX 2080 TiのSLI構成であれば,グラフィックスメモリは22GB(=11GB
なお,ここまで「2基のGPU」と書いてきたことから想像できると思うが,NVLinkベースの新世代SLIで対応するグラフィックスカードは2枚までだ。
ちなみにTU102だとNVLinkは2リンク,TU104は1リンクだとのこと。リンクあたりの帯域幅は片方向25GB/s,双方向50GB/sなので,RTX 2080 Tiは双方向100GB/s,RTX 2080は双方向50GB/sの相互接続が行えることになる。
GP100だと4リンク,GV100は6リンクという仕様だったが,このあたりの仕様に違いがあるのは,GPGPU用途とグラフィックス用途という設計思想の違いから来ているのだと思われる。
恐ろしく長くなってしまったが,最後にGeForce RTX 20シリーズの主なスペックを表にまとめたので参考にしてほしい。Founders Editionではブースト最大クロックが上がっているが,それ以外のスペックはリファレンスと変わらない。
Pascal世代と比較してCUDA Coreの増加率はそれほどでもないTuring世代だが,リアルタイムレイトレーシングアクセラレータとしてのRT Core,推論エンジンアクセラレータとしてのTensor Coreを搭載し,さらにジオメトリパイプラインとピクセルパイプラインの改善など,技術的に飛躍しているポイントはかなり多い。端的に述べて,非常に興味深いGPUである。
NVIDIAのJensen Huang(ジェンスン・フアン)CEOは先の発表会で繰り返し「Turing世代コアはリアルタイムグラフィックスの再発明を行うものだ」と述べていたが,確かにそのインパクトは,プログラマブルシェーダを初めて搭載した「GeForce3」登場時に優るとも劣らないと思う。
競合であるAMD,そして2020年にも単体GPUを市場投入する予定となっているIntelの動きもあるため,短期的にどうなるかは分からないものの,中長期的にはほぼ間違いなく,RT Coreに相当するリアルタイムレイトレーシングアクセラレータがすべてのGPUに載るだろう。
2019〜2020年頃に登場すると噂されている次世代PlayStationや次世代XboxのGPUが,万が一にもレイトレーシングアクセラレータに相当するものを搭載してくるなら,その普及には弾みが付くはずだが,すでにお伝えしているとおり,その可能性は低い。NVIDIAとしても長期戦は織り込み済みではなかろうか。
一方,Tensor Coreをゲーマーがどう受け止めるかはなかなか想像しにくい。
Tensor Coreを活用するAIベースのポストプロセス処理,その一例としてのDLSSは,サービスとしては非常に面白い試みだと言えるが,GeForce Experienceによる「ゲーム設定の自動最適化」と同じように受け止められるのではないか,という気はしている。
GeForce RTX 20シリーズ搭載グラフィックスカードのユーザーが知らないうちにTensor Coreを活用しているような状況を作り出せれば,ミドルクラス市場以下に向けた製品の登場後,カジュアルゲーマー層には浸透するかもしれない。
また,ジオメトリパイプラインとピクセルパイプラインの改善は非常に高尚な試みだが,AMDのプリミティブシェーダと同じように,しばらく放置されることになってしまうかもしれず,そこが心配だ。
なのでNVIDIAが,いま挙げたTuring世代の新技術や目玉機能の数々を,今後,どのような規模で展開,訴求していくのかというのが重要になると思う。
たとえば,「RT Coreを搭載するのはハイクラス市場向けGPU以上」(≒ミドルクラス以下では「GeForce GTX」を継続)という戦略をNVIDIAが取るなら,ゲームスタジオはレイトレーシング対応を渋ってくる可能性が高い。またDLSSも「AIが高画質化してくれる」というコンセプト聞く限り,ミドルクラス以下のGPUでこそ効果が高そうな機能だが,これもTensor Coreが載っていなければ利用できないわけで,やはりNVIDIAがどういう判断を行うか次第ということになるだろう。
現時点では筆者の勝手な想像でしかないが,「2060」以下の型番を採用するTuring世代のGPUは,そう遠くない将来に出揃うはずだ。それら下位モデルの製品群が,本稿で紹介した新技術,新機能を実用レベルで動かせるか否かが,TuringというGPUアーキテクチャ成功のカギを握っているとまとめておきたい。
 |
 |
なお,本稿の内容は,NVIDIAが抱えるGPUアーキテクトの1人で,GPUエンジニアリング担当上級副社長であるJonah M.Alben(ジョナ・アルベン)氏が報道関係者向け事前説明会で語った内容がベースとなる。
RTX 2080 TiはTU102,RTX 2080はTU104,RTX 2070はTU106コアを採用
まず,基本的な情報の確認からだが,「GeForce RTX 2080 Ti」(以下,RTX 2080 Ti)は「TU102」コア,「GeForce RTX 2080」(以下,RTX 2080)は「TU104」コア,「GeForce RTX 2070」(以下,RTX 2070)は「TU106」コアを採用する。トランジスタ数とダイサイズ,総CUDA Core数は以下のとおりだが,正直,3製品がすべて異なるシリコンダイだとは思わなかった。
- RTX 2080 Ti(TU102):186億,754mm2,4352基
- RTX 2080(TU104):130億6000万,545mm2,2944基
- RTX 2070(TU106):108億,445mm2,2304基
ちなみに,従来のグラフィックス用途向けGPUだと「Graphics」もしくは「GeForce」の頭文字となる「G」の後にアーキテクチャ名の頭文字が来る――「GeForce GTX 1080」(以下,GTX 1080)なら「GP104」――仕様だったが,今回はTuringアーキテクチャの頭2文字が3桁数字の前に来るという,新しいコア名表記になっている。
さて,まずはTU102の全体ブロック図を下に示すが,ほぼ筆者が推測したとおりの内部構成だと言っていいだろう。
 |
ここからしばらくはこの全体ブロック図を見ながら語っていきたいが,CPUで言うところの「コア」に相当するミニGPUクラスタ「Graphics Processor Cluster」(以下,GPC)は6基で,これは「Volta」アーキテクチャ世代の「GV100」や「Pascal」アーキテクチャ世代の「GP100」と同じだ。
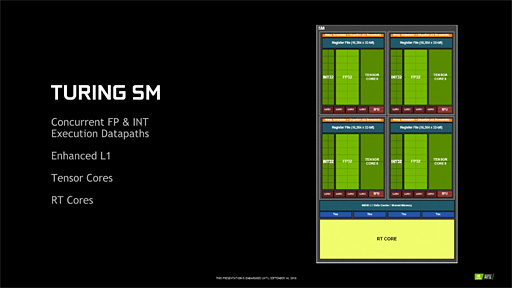
一方,GPCが内包する演算コアクラスタ「Streaming Multiprocessor」(以下,SM)は,GV100の14基,GP100の10基に対してTU102では12基となっている。
SMあたりのブロック図は以下のとおりである。
 |
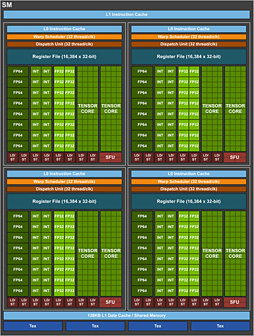 |
TU102のSMはGV100のそれと同様に4ブロック構成となっており,ブロックごとにWarpスケジューラ(Warp Scheduler)と命令発行ユニット(Dispatch Unit)がある。つまり,SMあたり同時に4つのデータスレッドに対して処理を仕掛けられるということだ。
ただ,細かく見ていくと,GV100のSMとは異なる点もいくつか確認できる。
1つはロード/ストアユニット(LD/ST)の数だ。GV100ではブロックあたり8基,SM全体で32基あったロード/ストアユニットが,TU102ではブロックあたり4基,SM全体で16基で,半分になっている。ここは,グラフィックス用途に特化した設計となるTU102ならではのチューニングといったところなのだろう。
SMあたりの32bit浮動小数点(FP32)演算器,32bit整数(INT32)演算器はともに64基ずつ。ここはPascal世代までのSMブロック図だと「CUDA Core」と呼ばれていた部分なので,「SMあたりのCUDA Core数は64基」という理解でも問題ない。
さて,そのCUDA Core数はTU102のフルスペックだと4608基だ。構成としては下記のようになる。
- 6(GPC)×12(SM)×64(CUDA Core)=4608 CUDA Core
ただし,4608基のCUDA Coreがすべて動作するのは今のところ「Quadro RTX 8000」「Quadro RTX 6000」に限定される。RTX 2080 Tiの総CUDA Core数は4352基なので,いくつかのGPCでSMが無効になっているわけだ。
 |
- 4(GPC)×12(SM)×64(CUDA Core)+ 2(GPC)×10(SM)×64(CUDA Core)=4352 CUDA Core
RTX 2080 Tiは「Founders Edition」のブーストクロックが1635MHzとなるので,
- 4608(CUDA Core)×1.635GHz×2 FLOPS=14231.04 GFLOPS
で,約14.2 TFLOPSとなる。TU102フルスペックのQuadro RTX 8000だと16 TFLOPSなので,それと比べるとやや低い。
以上を踏まえつつ,TU104とTU106のブロック図も確認しておこう。まずはTU104からだ。
 |
TU104も6GPC構成だが,GPCあたりのSM数が8基となるのがTU102との大きな違いだ。TU104のフルスペック版は総CUDA Core数3072基の「Quadro RTX 5000」で,構成としては以下のとおりである。
- 6(GPC)×8(SM)×64(CUDA Core)=3072 CUDA Core
それに対してRTX 2080は総CUDA Core数が2944基なので,フルスペックからSMが2基無効になった製品ということになる。
続いてはTU106だが,こちらはTU102を半分にしたような構造になっており,GPCあたりのSM数もTU102と同じ12基となる。
 |
RTX 2070はTU106のフルスペック版となるため,
- 3(GPC)×12(SM)×64(CUDA Core)=2304 CUDA Core
という計算式が成り立つ。ここからSMをいくつか無効化すれば,“GeForce RTX 2060”的なGPUを派生させることは容易だろう。
FP32演算とINT32演算のオーバーラップ実行で性能向上を図るTuring
Turingアーキテクチャにおける重要な新要素として挙げられるのは,Volta世代のGV100に対し,FP32演算器とIN32演算器が若干パワーアップした点である。
具体的に言うと,Turing世代のGPUではFP32演算器とINT32演算器をほぼ並列動作させられるようになった。
「ほぼ」なのは,1クロックでFP32演算とINT32演算を同時発行することまではできないためで,たとえば偶数クロックでFP32演算器に命令を発行し,奇数クロックではINT32演算器に命令を発行するといったメカニズムになっている。従来,そうした命令の発行は行えなかったので,Turingアーキテクチャ世代で改善が入ったという理解でいい。
FP32演算とINT32演算が事実上のオーバーラップ実行ができるので,その分の性能向上を見込めるというわけだ。
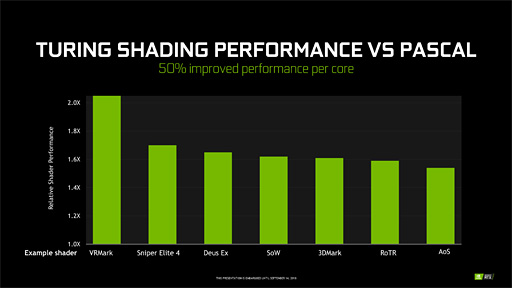
その理屈を解説したのが下の図になる。
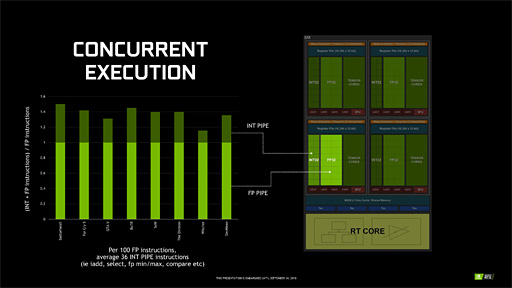 |
この図は,ゲームタイトルごとの各シェーダ処理においてFP32演算だけが実行されるケースを「1.0」として黄緑バーで表したうえで,FP32演算とINT32演算の両方が実行されるケースを深緑バーで表したグラフだ。「TuringアーキテクチャのGPUであれば深緑バー部分をオーバーラップ実行できて時間短縮が見込めるため,性能向上を期待できる」ということになる。
実際のシェーダ処理において,INT32演算は画像テクスチャ処理に関連した各種論理演算などでけっこう使ったりする。なので,この改良はゲームグラフィックスにけっこう“効いてくる”はずだ。
 |
さて,NVIDIAが公開したSMブロック図だと,倍精度浮動小数点(以下,FP64)演算器は描かれていないのだが,事前説明会では「従来のGeForceシリーズと同じ比率で実装している」という話があった。従来のGeForceだと,
- FP32演算性能:FP64演算性能=32:1
という仕様なので,これをSMあたり64基のFP32演算器を搭載するTuringアーキテクチャに当てはめると,SMあたりのFP64演算器数は2基ということになる。
Turing世代のキャッシュシステム
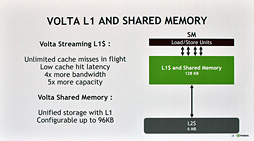 |
振り返ると,GV100ではL1キャッシュと共有メモリを「総容量128KBのキャッシュメモリ」として統合し,このうち最大96KBをL1キャッシュとして利用し,残りを共有メモリとして利用するという仕様になっていた。
それに対してTuringアーキテクチャの場合,L1キャッシュと共有メモリを統合するところはGV100と同じながら,その総容量は96KBと4分の3に減っている。また,L1キャッシュと共有メモリの構成パターンは64KB+32KBか32KB+64KBの二択となる。
付け加えると,GTX 1080が採用するGP104コアの場合,「L1キャッシュ容量24KB×2,共有メモリ容量96KB」という,用途別に容量を固定的に割り当てる設計だったので,総容量で言えばTuringアーキテクチャにおけるL1キャッシュおよび共有メモリはGP104以下ということにもなる。
ただし,Turing世代ではGP104と比べてL1キャッシュの動作クロックを2倍にして実効帯域幅を引き上げているため,そのキャッシュ性能は劇的に向上しているとのこと。前段で触れた「FP32とINT32のオーバーラップ実行」と,本段落で触れたキャッシュ性能の引き上げによって,CUDA Coreあたりの3Dグラフィックス処理性能はGP104比で1.5倍以上になっているという。
 |
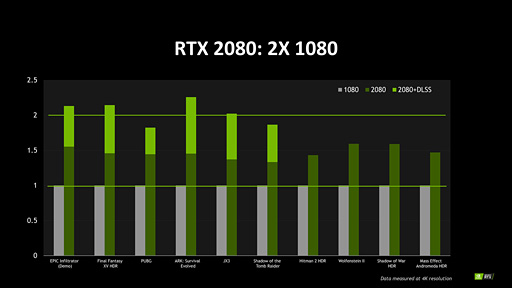
ちなみに筆者は8月24日掲載の記事で「RTX 2080の性能を示すグラフがGTX 1080と比べて理論演算性能値以上に開いている」という話をしたが,NVIDIAの説明をそのまま受け入れるなら,これこそが「FP32とINT32のオーバーラップ実行」と「キャッシュ性能の向上」の効果なのだろう。
 |
組み合わせるグラフィックスメモリは,Turing世代で業界初のGDDR6となった。「GDDR6とは何か」という話は大原雄介氏による解説記事を参照してほしいが,GDDR5Xと同じく実クロックの8倍速駆動となるメモリで,RTX 2080 TiとRTX 2080,RTX 2070の場合,いずれもデータ転送レートは14Gbps。4Gamerの慣例表現に従うと「14GHz相当」の動作クロックとなる。
 |
Pascal世代の中上位モデルが採用していたGDDR5Xの場合,メモリインタフェースの設計をGDDR5と共用できることが利点として訴求されていたが,さらなる広帯域幅を実現すべく,GDDR6ではGDDR5世代と互換性のない信号設計を採用している。その新設計により,信号のクロストークはGDDR5世代に対して40%も低減できたため,GDDR6のロードマップ上ではデータ転送レート16Gbpsの製品化予定もある。
TU102コアを採用するQuadro RTX 8000とRTX 2080 Tiの場合,メモリインタフェースは順に384bit,352bitなので,その帯域幅は以下のとおりとなる。
- Quadro RTX 8000:384bit×14GHz÷8bit≒672GB/s
- RTX 2080 Ti:352bit×14GHz÷8bit≒616GB/s
動作クロック1.75GHz相当のHBM2を搭載し,4096bitのメモリインタフェースでGPUと接続させたVolta世代のGPUだとメモリバス帯域幅は900GB/sとなるが,GDDR系の帯域幅がそんなHBM系に少しずつ近づいてきているのは興味深い。
ちなみにPascal世代のGeForceだと,GTX 1080 Tiで484GB/s,GTX 1080で320GB/sだった。
RT Coreの秘密〜RT Coreは一体何をしているのか
Turingアーキテクチャにおける最大の特徴が,これまでのGPUにはなかった「リアルタイムレイトレーシングアクセラレータ」的な機能の搭載にあることは論を俟(ま)たないだろう。
このリアルタイムレイトレーシングアクセラレータに相当するのが「RT Core」である。RTは当然「Ray Tracing」(レイトレーシング)の略だ。
そもそも,レイトレーシングとはどういうものなのだろうか? 「DirectX Raytracing」が発表になった3月のタイミングで詳しく紹介しているが,ここでも簡単に紹介しておこう。
レイトレーシングは,あるピクセルの色を計算するとき,当該ピクセルが受け取っているはずの光の情報を探るために光線(ray)を射出してたどる(trace)処理のことを指す。
光線の射出方向と角度は回収したい情報の種類によって決まる。たとえば,近くの光源に向かって光線を射出して光源に到達できれば,そのピクセルはその光源に照らされていることが分かる(下図1)。光源に達する前にほかの3Dオブジェクトと衝突すれば,そのピクセルは3Dオブジェクトによって影になっていることが分かる(下図2)。さらに,当該ピクセルを見つめるユーザーの目線の反射方向に光線を射出して,他の3Dオブジェクトに衝突したとしたら,そのピクセルには「衝突した3Dオブジェクトが映り込んでいる」と判断できる(下図3)。
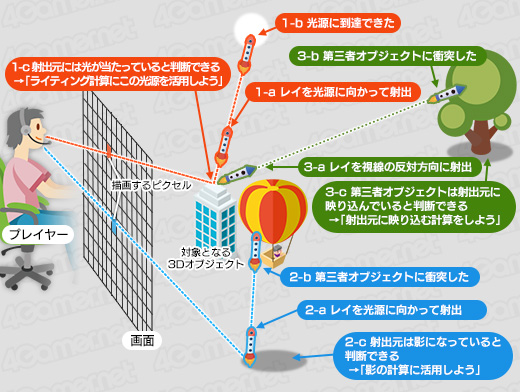 |
RT Coreというハードウェアが担当するのは,そんなレイトレーシングにおける光線の生成処理と,光線を動かす「トラバース」(traverse,横断)処理,衝突判定を行う「インターセクション」(Ray-sphere intersection,交差)判定なのである。
基本概念の理解としてはこれで十分なので,ここからはもう少しハードウェアに近い視点でRT Coreの処理系を見ていくことにしよう。
光線の生成は初期設定を行う処理系であり,その後に続く処理のために作業用のメモリ領域を確保して,そこに光線の初期パラメータを設定するだけのものだと言うとイメージしやすいだろう。この下準備の発動はプログラマブルシェーダ(=CUDA Core)から行われる。
イメージしにくいのはトラバースとインターセクションのところだと思う。
最もシンプルなアルゴリズムは,光線を一定距離分だけ進めて,その先で何らかの3Dオブジェクトに衝突していないかを判定するという処理系になる。ただ,何も考えずにこの処理系を実装した場合,光線が一定距離進むたびに「その3Dシーンを構成するすべてのポリゴン」に対して総当たりで衝突判定を行わなければならなくなる。言うまでもないが,これはとんでもなく重い処理になってしまって現実的ではない。
 |
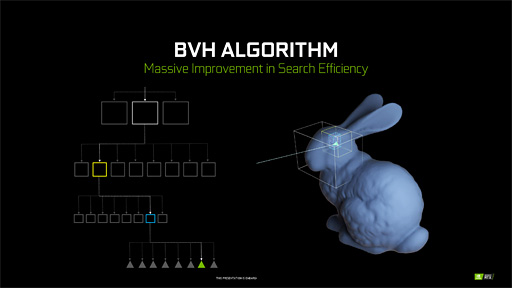
 |
そこで近代レイトレーシングのアルゴリズムでは,3Dシーンに存在する3Dオブジェクトを囲うようなXYZ各軸に平行な直方体(=箱)の階層構造で表現しておき,ポリゴン単位の衝突を突き止める前段階として直方体との衝突判定を行うような実装になっていることが多い。
下の図ではウサギのモデルを複数の直方体で囲っているが,もしこのウサギがウサギ小屋の中にいるなら,ウサギ小屋を囲うような「上位層の直方体」も定義することになる。
 |
この実装を行えば,光線は「3Dシーンをおおざっぱに囲った,大きな直方体」との衝突判定を行うだけで済む。もしこれらの直方体と衝突しなければ,「射出した光線は何モノとも衝突しなかった」という結果を,「光線を1回進める」だけの処理で得ることができる。
一方,光線が何かしらの箱と衝突した場合は,階層を一段降りて,「より細かい直方体」への衝突判定へと移行することになる。
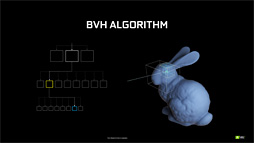 光線が直方体に衝突したと判定できた場合,その一段下に相当する階層の「より小さな直方体」への当たり判定フェーズへと移行する |
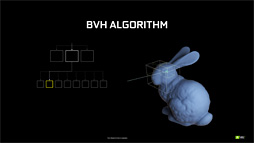 「より小さな直方体における当たり判定」を,最下層の直方体に到達するまで繰り返す |
最も小さな直方体との衝突を突き止めらたら,最終的に,この直方体に含まれるポリゴンと,ここでようやく総当たりの衝突判定を行うのである。
 |
衝突判定の計算はどれほど複雑なのかという話だが,イメージできるように,直方体との衝突判定は難しくない。直方体は8つの頂点を持っているので,光線の通過する座標が8頂点の内部に入り込んでいるか否かを計算するだけでいい。高級言語で言うところの「IF A<B」の組み合わせだけで判定できてしまう。用いる計算も減算だけだ。
最下層にある一番小さな直方体へたどり着いたときに生じる「光線とポリゴンとの衝突判定」も,計算内容自体は,いま述べた「直方体との衝突判定」と大差ない。ただし,当該直方体が含む複数のポリゴンすべてとの衝突判定は必要なので,反復的な処理系にはなる。
さて,衝突したポリゴンを特定できたら,このタイミングで当該ポリゴンに関する情報を光線の射出元に返すわけだ。
光線とポリゴンがいずれも「3D的な向き」を持っているというのは想像できるだろう。そのとき,ポリゴンと衝突したレイの反射ベクトルを求めたりするのはプログラマブルシェーダ(=CUDA Core)の仕事であって,RT Coreの仕事ではない。また,光線が持ち帰った情報を基にしてさまざまなシェーディング処理やライティング処理などを行うのもプログラマブルシェーダ(=CUDA Core)側の仕事になる。
ここで,「なんだ,RT Coreってシンプルな仕事しかしてないじゃん」と思った人もいると思う。しかし,いま述べた処理をプログラマブルシェーダでシェーダプログラムとして実装しようとすると,かなり大変だ。
そもそも,「直方体の階層によって成立しているデータ構造を読み出して,そこから必要な情報を取り出す」処理系の難度が高い。直方体の階層構造はいわゆる「木構造」(入れ子構造)データなので,その読み出しはほとんど「デコード処理」的なものになる。
また,衝突判定もいわば条件分岐処理なので,GPUにとっては苦手なものとなる(※)。
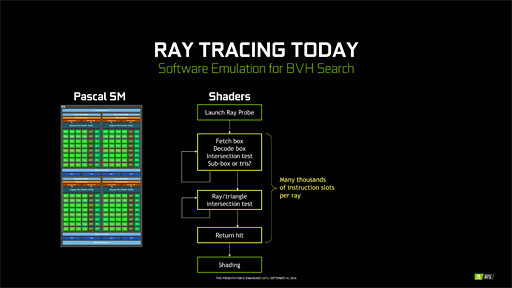 |
※複数のデータに対して並列にプログラムを適用していくという実行スタイルを採用するGPUにとって,たとえばA分岐とB分岐があった場合,すべてのデータに対する総処理実行時間は「A分岐とB分岐の両方を実行したサイクル数」に近いものとなってしまう。これは分岐命令のPredication(叙述)実行による弊害である。
なので,直方体の木構造データをデコードする処理と,光線と直方体との衝突判定処理,光線とポリゴンとの衝突判定処理を,NVIDIAはRT Coreという専用ハードウェアで実装したというわけなのだ。
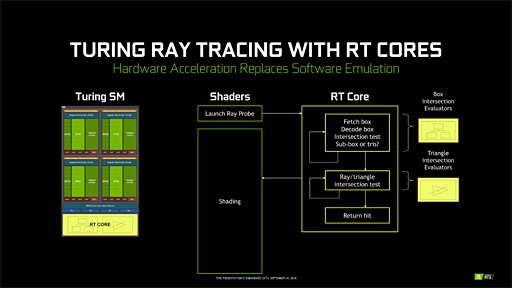 |
NVIDIAいわく,RT Coreの性能は「GTX 1080 Ti(でプログラマブルシェーダベースの実装を行ったとき)と比べて約10倍高速」とのこと。さすがは専用ハードウェアといったところである。
ちなみに,RT Coreはプログラマブルシェーダではないため,プログラムすることはできない。完全な固定ユニットだ。だからこそ,解像度1920
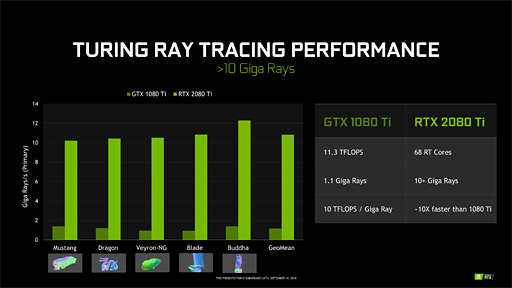 |
さてここで,筆者の連載バックナンバー「GeForce RTX 20なぜなに相談室(gamescom 2018版)」における予測が1つ外れたことに触れなければならない。
 |
つまり「SM数=RT Core数」ということだが,それを踏まえ,GeForce RTX 20シリーズのRT Core数と毎秒あたりの公称レイ生成数を下に示す。
- RTX 2080 Ti:68 RT Core,10G Rays/s
- RTX 2080:48 RT Core,8G Rays/s
- RTX 2070:36 RT Core,6G Rays/s
ここであることに気付く。そう,RT Core数にGPUごとのブーストクロックを掛けてやると,「毎秒あたりのレイ生成数」の10倍に近い数字が得られるのだ。そこから「レイの生成に10クロックくらいかかる」という考察も行えるが,ともあれ計算すると,
- RTX 2080 Ti:68×1.545GHz÷10=10.5G Ray/s
- RTX 2080:48×1.710GHz÷10=8.2G Ray/s
- RTX 2070:36×1.620GHz÷10=5.8G Ray/s
と,かなりそれっぽい値になることが分かる。
1つのレイを生成するのに要するクロック数が正確かというのはともかく,Turingアーキテクチャを採用するGPUにおけるRT Coreの公称性能値が,SM数(≒RT Core数)とブーストクロックに比例したものになっていることだけは間違いない。
AI的ポストプロセスを行うために搭載されたTensor Core
「Tensor Core」(テンサーコア)は,各要素が最大16bit浮動小数点形式(以下,FP16)で最大4×4要素の行列同士を積和算できるプロセッサだ。この積和算はデータ列同士で畳み込み演算を行うときに多用されるものなので,実際のところGPUをGPGPU的に活用するときにも利用できなくはない。
しかし,機械学習や深層学習における学習処理,あるいは学習データを基に入力データから推論を導き出す推論処理において,行列同士の積和算が多用されることから,NVIDIAはVolta世代のGPUで,専用ユニットとしてのTensor Coreを搭載してしまった。
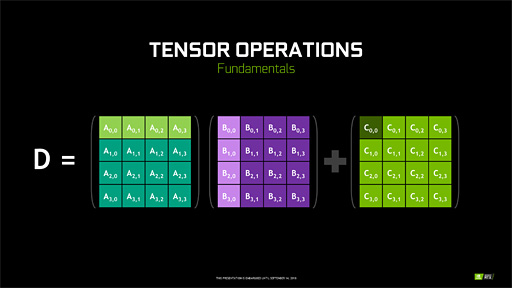 |
 |
TuringアーキテクチャのGPUがTensor Coreを搭載する理由は,8月23日掲載の記事でもお伝えしたとおり,深層学習型AIを用いたポストプロセス処理「DLSS」(Deep Learning Super Sampling)を実行するためである。
「描画済みのグラフィックスに対して,学習データに基づいてAIがレタッチするメカニズム」を実用化するため,NVIDIAはTuring世代のGPUにもTensor Coreを搭載したのだ。
 |
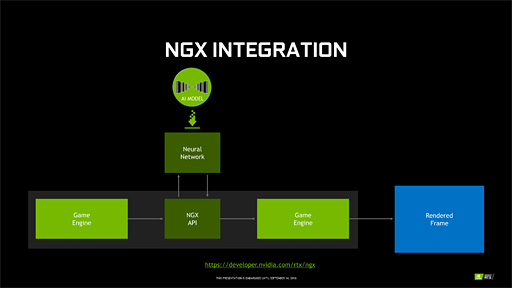
それだけではなく,ゲーム用途におけるTensor Coreの活用の環境整備に向けて,NVIDIAは「NGX」を発表している。
NGXは,「膨大な画像を深層学習させて得た学習データを基に,AI的な推論的画像処理を行うアプリケーション」を開発するためのフレームワークである。実のところDLSSは,NGXのお手本的な応用事例という位置づけだったりする。
 |
 |
DLSSで提供されるAI画像処理というのは,具体的には「アンチエイリアシング処理」「超解像アップスケール処理」「時間方向のチラツキ(≒フリッカー)低減」「(レイトレーシングなどの)ノイズ低減」など。学習自体はNVIDIA側で行うか,ゲームデベロッパとの協業で行う仕様となっており,ゲーマーはその結果としての「DLSSプロファイル」的なものを,「GeForce Experience」など経由で定期的に受け取ることになる。
 |
NVIDIAによれば,学習データは広く使える汎用タイプのものや,特定のゲームタイトル専用のものまで多岐にわたるらしい。
 |
| フレーム間のピクセル相関性の情報を利用して,空間方向でも時間方向でもジャギーを低減させるTAA(Temporal Anti-alising)という技法はよく知られているが,相関性の検出がうまくいかないワーストケースでは,理想的なアンチエイリアシング処理にならず,元画像を掻き乱してしまうことになったりする(左)。それに対し,事前にしっかり学習させておいたDLSSだと,そうしたエラーはほぼ生じないという(右) |
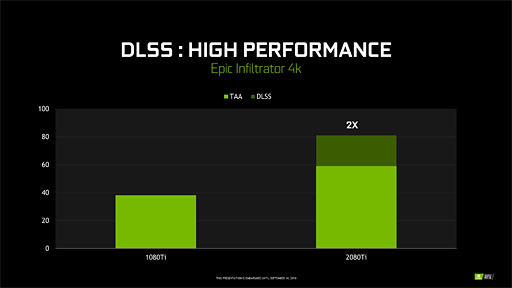 |
| Epic Gamesのリアルタイムデモ「Infiltrator」を4Kで描画させたときの平均フレームレートをGTX 1080 TiとRTX 2080 Tiとで比較したグラフ。「GTX 1080 TiでTAAを使うより,RTX 2080 TiでDLSSを使ったほうが2倍高速」というのがNVIDIAの主張だ(関連記事) |
Turingアーキテクチャにおいても,Volta世代と同じく,Tensor CoreはSMに内包されている。SMあたりのTensor Core数は8基なので,72 SM構成のRTX 2080 Tiだと,総Tensor Core総数は576基となるわけだ。
理論性能値は,4×4要素の行列同士による積和算だと,計算量としては「4×4の16要素に対して4回の積和算(2 FLOPS)を行う」ことから,やはりブーストクロック基準で,
- 576基×1.545GHz×(16要素×4回×2 FLOPS)=113910G Tensor FLOPS
となって,公称値である113.8T Tensor FLOPSとほぼ一致する。
なお,画像処理用の深層学習型AIや機械学習型AIの学習データを推論エンジンに載せる場合,FP16精度は不要で,整数で表せる固定小数点形式でも精度的に十分だ。そのため,TuringアーキテクチャのGPUが搭載するTensor Coreでは8bit整数(以下,INT8)や4bit整数(以下,INT4)の演算も取り扱えるようになっている。ここは地味ながら,Volta世代と比べて機能向上した部分だと言える。
 |
解明!? RTX-OPSの謎
8月23日掲載の記事で「数値の根拠が不明」と述べることしかできなかった,NVIDIA独自のGPU性能指標「RTX-OPS」だが,この謎がついに解けた。
結論から先にお伝えすると,RTX-OPSはあくまでもNVIDIAが発明した独自の性能指標であって,正確な理論性能値とは言いがたい。イメージ的には,かつてAMDがCPUで採用していた,「競合製品と比べてどれくらいの性能が得られるかをイメージした数字」に近いものだ。実クロック2.4GHzのCPUを「Athlon 64 X2 4800+」と呼ぶ,みたいな感じである。
そのRTX-OPSだが,算出の根拠は,先の記事で同じく謎キーワードだとしていた「1 Turing Frame」にあった。
1 Turing FrameというのもNVIDIAが独自に考案したものなだが,意味合い的には「Turing世代のGPUをフルに使ってグラフィックスを描画するケースにおける各演算ユニットの稼働率としてNVIDIAが想定した内容を,フレーム単位で図示したもの」だ。
 |
言うまでもないが,「稼働率」はゲームやゲームエンジンごとのグラフィックス処理の設計や実装形態によって異なる。なので,相当レベルでNVIDIAの恣意的な想定に基づいた値になるのだが,とにかくその1 Turing Frameにおける「演算ユニットごとの稼働率」を,NVIDIAは以下のとおり,追加で公開してきた。
 |
このスライドによると,稼働率はFP32演算ユニットが80%,INT32演算ユニットが28%,RT Coreが40%,Tensor Coreが20%になるのだそうだ。そして,このパーセンテージを係数として,各演算ユニットの理論性能値に対してそれぞれ掛ける。そのうえで総和を求めると,それがRTX-OPSとなるのだ。たとえばRTX 2080 Tiの場合,計算式は以下のとおりとなり,NVIDIAの主張する78 RTX-OPSの計算式と合致する。
- 14.2 TFLOPS×80%+14.2 TIPS×28%+100 TFLOPS×40%+113.8 FP16 Tensor FLOPS×20%=78.096 RTX-OPS
ただそれでも「数値の根拠はよく分からない」とは思う。とくに理解の難度を上げているのは,100 TFLOPSという,RT Coreの途方もなく高い「見立て性能値」だと筆者は考えているが,その背後にあるのは,NVIDIAによる,極めて独自性の高い解釈である。
いわく,「理論性能値11.3 TFLOPSのGTX 1080 TiのプログラマブルシェーダででRT Coreの処理を再現したとすると,1.1G Rays/sのレイ投射性能が得られる。だから,約1G Rays/sを実現するために必要な理論演算性能は約10 TFLOPSだ。よって,公称値として10G Rays/sを達成しているRTX 2080 TiのRT Coreの理論演算性能値は100 TFLOPSなのである」とのことだ。
正直,これはさすがにやりすぎ感が否めない。そもそもの話として,「RTX-OPSの計算式に入れているほかの演算ユニットはFP32基準なのに,Tensor CoreだけFP16」とか,「INT32の理論性能値をFLOPS性能値と同列にして加算していいのか」とか,いくらでもツッコミを入れられてしまう。
実際,この「トンデモ算数」の発表時には,事前説明会に参加していた各国のメディア陣から静かな笑いが起きていたが,まあ,根拠を示さない数字がいくらでも出てくる世の中にあって,計算結果をちゃんと求められる数値を出したNVIDIAは立派だと言えなくもない(?)。
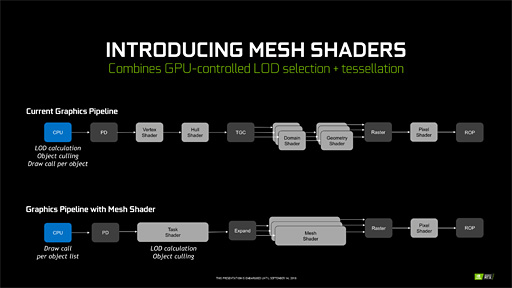
新しいプログラマブルシェーダ「メッシュシェーダ」とは何か?〜NVIDIAもジオメトリパイプラインの刷新に取り組む
プログラマブルシェーダの歴史はDirectX 8(≒Direct3D 8)とともに始まったわけだが,その後,
- DirectX 10ではポリゴンの増減を司るジオメトリシェーダ(Geometry Shader)
- ポリゴンの分割を司るテッセレーションステージが追加となったDirectX 11ではハルシェーダ(Hull Shader)とドメインシェーダ(Domain Shader),そしてポリゴン分割ユニットであるテッセレータ(Tessellator)
がそれぞれジオメトリパイプラインに追加となった。DirectX 8の時点では頂点シェーダ(Vertex Shader)しかなかったジオメトリパイプラインは,良くも悪くもずいぶんと複雑になってきたのである。
問題は,ゲーム機であるPlayStation 4やXbox One,そしてNintendo SwitchのGPUにもジオメトリシェーダとテッセレーションステージが搭載されるほど一般化したにもかかわらず,それらを活用しているゲームタイトルがほとんどないことだ。頂点シェーダを除くと,ジオメトリパイプライン上のプログラマブルシェーダは今やほとんど盲腸化している。
もっとも,ジオメトリシェーダはまだいいほうで,GPU制御のパーティクルシステム実装や,キューブマップのレンダリングやボクセルデータ構造の生成に使われるケースはある。
悲惨なのはテッセレーションステージのほうだ。
テッセレーションステージはもともと,「遠方の3Dモデルはシンプルな形状の少ポリゴンで描画」「近傍の3Dモデルはディテールのしっかりした多ポリゴンで描画」「その間はポリゴンを適宜分割して無段階の詳細度の3Dモデルを生成して描画」という,高い理想を実現するために考案されたものだった。
しかし,これを実現しようとすると,3Dモデルのデータ構造をあらかじめ,テッセレーションステージの活用に適合した仕様にしなければならず,これが面倒だということで敬遠されてしまった。そもそもDirectX 11時代最初期に登場したGPUのテッセレーションステージは遅くて使いものにならず,そこでミソが付いてしまったというのもあるように思う。
遠方,近傍,中間距離の3レベル程度で異なる詳細度の3Dモデルを用意しておいて,それらを視点からの距離に合わせて適当に切り換えて描画する,昔ながらのLoD(Level of Detail)システムの運用でも,動的なキャラクターだと見栄えに違和感はほとんどなかったりするので,「これでいいや」という判断が続いてしまったというのも大きい。
とはいえ,地形や木々,建物などの「動かない,大きめの背景物オブジェクト」は,プレイヤーがフィールドを歩み進んでいく流れで,一定距離でまとめてLoDレベルが切り替わったりするため,切り替わりが目に付きやすい。LoDレベルの切り換えポイントで3Dモデルの体積が大きく変わることを「ポッピング」というが,これを目の当たりにしたことはゲーマーなら必ずあるはずだ。
そこでNVIDIAは,「昔ながらのLoDシステム」の実装形態ほぼそのままでテッセレーションステージの恩恵を受けられる,新しいプログラマブルシェーダをTuring世代のGPUに新設した。それが,「メッシュシェーダ」(Mesh Shader)である。
実際には,メッシュシェーダを制御する上層のプログラマブルシェーダとしてNVIDIAは「タスクシェーダ」(Task Shader)も新設している。パイプライン構造としては,あらかじめ複数のLoDレベルに分かれた3Dモデルをタスクシェーダの管轄下に置いておいて,タスクシェーダが適宜メッシュシェーダを活用するというものになる。
 |
流れをもう少し詳しく見てみよう。
タスクシェーダは,これから描画する3Dモデルと視点との距離,視点との向きに応じて,適切なLoDレベルを計算する。そして,LoDレベルがたとえば「2.5」だった場合,LoDレベル2の3DモデルとLoDレベル3の3Dモデル,それらの中間となるディテールを持った3Dモデルをメッシュシェーダで生成するのだ。
この説明だと,タスクシェーダとメッシュシェーダの処理系が3Dモデル単位のように思えるかもしれないが,実際の処理系はポリゴン単位となるので,その点は注意してほしい。
要するに,異なるLoDレベルの3Dモデル同士に対してポリゴンがどう対応するか,トポロジーの定義が不可欠ということである。なので,「従来型の離散的なLoDシステムを採用したグラフィックスエンジンがTuring世代のGPU上で実行された場合,自動的に無段階LoDシステムに変身してしまう」わけではない。
いずれにせよ,テッセレーションステージと比べると面倒は少なそうだが,それでも,3Dモデルのデータ構造は,タスクシェーダやメッシュシェーダで実装したシェーダプログラムの仕様に合わせて弄る必要はある。
 |
デモ自体は,岩の塊が浮遊する宇宙空間を突き進むというシンプルなものだが,ここでシーンを埋め尽くす隕石の数は総数30万〜40万個。これを最も詳細度の高いLoDレベル0ですべて描画したとすると1フレームあたり約5兆ポリゴンの描画になってしまう。ところが,タスクシェーダとメッシュシェーダを活用することで,実描画数は1000万ポリゴン程度に抑えられるというのが,このデモのアピールポイントになる。
要するに,「メッシュシェーダの活用によって,描画するポリゴン数を実に50万分の1にまで削減できている」というアピールなのだが,実際には,視点に近い側の隕石に遮蔽されて視点から見えなくなった隕石や,1ピクセル未満となってしまった遠方の隕石は,いずれも描画対象から外す「カリング処理」をメッシュシェーダと組み合わせた成果となっている。
そう,タスクシェーダはLoDレベルの選択だけでなく,プログラム次第で早期カリング処理をも実装できるということなのだ。
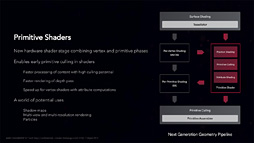 |
ただこのプリミティブシェーダ,発表こそ大々的になされたものの,どうやれば使えるのかがいまだ明らかになっておらず,当然のことながら誰も使っていない。
その意味では,今回のタスクシェーダとメッシュシェーダも「使い方は明らかになっていない」点でプリミティブシェーダと同じなのだが,事前説明会場にいたNVIDIA関係者によれば,こうした改良版ジオメトリパイプラインは次世代のDirectXから使えるようにすべく,Microsoft側で準備を進めているとのことだった。
どこまで信用していいのかという話ではあるが,ひょっとすると,この秋の正式リリースが予定されている「DirectX Raytracing」に合わせて,タスクシェーダとメッシュシェーダ,プリミティブシェーダが利用可能になるかもしれない。
1フレーム内でレンダリング解像度を変えられるVRSとは何か
ジオメトリパイプラインに対してのみならず,ピクセルパイプラインに対しても,TuringアーキテクチャでNVIDIAは独自の改良を行い,その新しいピクセルパイプラインのレンダリング概念に「Variable Rate Shading」(ヴァリアブルレートシェーディング,以下 VRS)という名を与えている。
VRSが採用するのは非常に独特なメカニズムで,Turingアーキテクチャ世代のGPUが搭載する専用のハードウェアによってアクセラレーションを行うため,現行のDirectXからは利用できない。その点ではタスクシェーダやメッシュシェーダと同じだ。
ではどういうものかというと,ピクセルシェーダによってライティングおよびシェーディングされるピクセルの解像度をプログラマブルに制御するものとなる。
言うまでもないことだが,通常,ポリゴンがラスタライズされてピクセルに分解されたあとは,ピクセル単位でピクセルシェーダが起動され,当該ピクセルの色を計算する。光源からのライティング計算や,当該ピクセルの材質パラメータに見合った変調を行った結果などから最終的な色は決まるわけだ。
それに対してVRSは,この「ピクセルシェーダの起動解像度」を1×1ピクセルと2×2ピクセル,2×1ピクセル,1×2ピクセル,4×2ピクセル,2×4ピクセルから任意に選択できるようになっている。言い換えると,VRSを使えば,画面内の任意の箇所においてピクセルシェーダの計算解像度を落とせるのである。
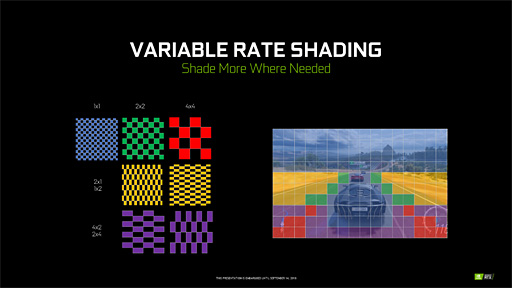 |
なぜこのようなメカニズムが必要なのか。NVIDIAは「世の中には,まじめにフル解像度でレンダリングしても報われない状況がいっぱいあるから」だとしている。
 |
VRSは,そうしたさまざまな視線追従描画システムの手法をハードウェアでアクセラレーションする仕組みと言っていい。NVIDIAは「VRにおいては,ヘッドマウントディスプレイに搭載される接眼レンズの拡大率不均衡特性にも応用できるだろう」とも述べている。
 |
CASは,情報量が低い領域に対して解像度を下げてライティングおよびシェーディングする手法である。画像工学的に言えば「情報量が低い領域」は「低周波成分が多い領域」だが,「のっぺりした面表現が主体となっている領域」という理解でいい。
逆に「情報量が多い領域」は「高周波成分が多い領域」で,「ごちゃごちゃとディテールが描写されている領域」のことを指すが,ごちゃごちゃしている領域に対して低解像度でライティングやシェーディングを行うとアラが見えてしまう。なのでそこはなるべくフル解像度で処理し,一方でのっぺりした領域は適宜解像度を落として処理するイメージになる。MPEG-4圧縮において,低周波成分を低解像度ブロックで圧縮して情報量を減らす仕組みとちょっと似ている。
 |
続いてMASだが,こちらは画面内にあるオブジェクトの移動速度に合わせてライティングとシェーディングの解像度を変える手法である。
高速に動いている動体は,人間が目で追ってもボケて視覚されやすいので,この特性を逆手にとるわけだ。具体的には,高速度で移動しているオブジェクトほど低解像度でライティングおよびシェーディング処理し,遅いオブジェクトほど高解像度でライティングおよびシェーディング処理することになる。
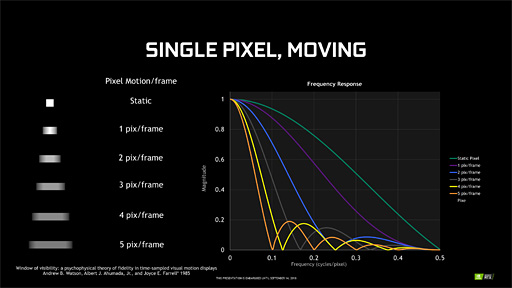 |
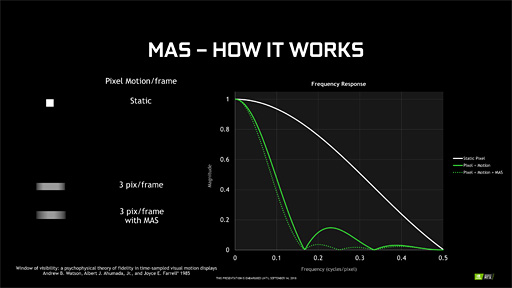 |
FPSで視点移動をすると,近景は速く動き,遠景は遅く動くので,MASを実装した場合,近景は低解像度で,遠景は高解像度でそれぞれライティングおよびシェーディング処理されることになる。シーン内を動き回っている敵キャラクターだけがMASの対象というわけではなく,画面全体の総合的な動き速度を吟味してライティングおよびシェーディング処理の解像度は決まる仕様だ。
ちなみにCASは「あらかじめ用意しておいた周波数情報を仕込んだテクスチャ」の情報を基にして,MASは「モーションブラーの生成などに利用されるベロシティバッファ」の情報を基にして実現する。
なお,誤解のないようにあえて補足しておくが,Turingアーキテクチャで実現しているのは,VRSというアクセラレーションメカニズムだけであり,「VRSを活用するとプログラム次第でこうしたCASやMASを実現できる」ということである。VRSがCASやMASと同義ということではない。
ビデオプロセッサー部と接続インタフェース,そしてSLI
以上が,Turingアーキテクチャ解説のメインディッシュだが,細かな情報も判明したので紹介しておこう。
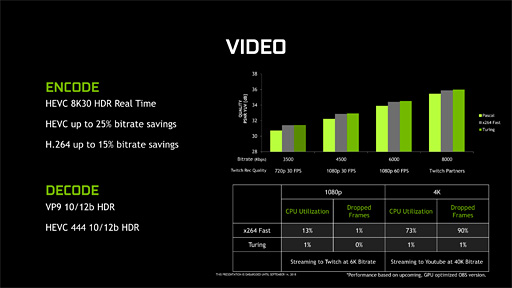
まずはビデオプロセッサからだが,H.264/MPEG-4 AVCとH.265/HEVCのエンコードおよびデコード処理に対応しているのはPascal世代と同じながら,その性能はTuring世代で向上している。
とくに重要なのはスループットがPascal世代比で約2倍になっている点で,これにより,ついに7680
Pascal世代でNVIDIAは3840
また,エンコーダの圧縮アルゴリズムにも改良が入っており,Pascal世代と比較して,同じ画質ならH.264で15%,H.265なら25%も低ビットレート化できるようになった。逆に言えば,同じビットレートならPascal世代のGPUを使うよりも高い画質を得られるということだ。
 |
次にインタフェースだが,HDMI周りのアップデートはとくにない。期待されていたHDMI 2.1のアップデートはなく,Pascal世代と同様にHDMI 2.0bまでの対応となる。
一方,DisplayPortではPascal世代の1.4から1.4aに変わり,1本のDisplayPortケーブルで8K 60Hz出力が可能になった。DisplayPort 1.4aでは,ライン・バイ・ライン(≒走査線ごとの)不可逆圧縮伝送方式である「DSC」(Display Stream Compression)を採用したことで,映像の劣化を許容しながらも8K 60Hz伝送に対応したのだ。余談気味に続けると,HDMI 2.1でも同様の伝送方法をサポートしている。
DisplayPort 1.4aでDSCを使わない場合,1本のケーブルだと8K 30Hz出力が上限だ。もちろん2本のケーブルを同期させて伝送すれば劣化なしの8K 60Hz出力を行えるが,このあたりはPascal世代から変わっていない。
もう1つビデオ出力周りで重要なのは,USB 3.1 Gen.2 Type-Cインタフェースを採用したことだろう。USBコントローラはGPUコアに統合されているため,搭載するグラフィックスカードから直接Type-Cインタフェースを利用できる。
このUSB Type-CポートはUSBポートのマルチユースに対応した「USB Alternative」(以下,USB Alt)モードに対応しており,USB AltモードでDisplayPort信号を出力できるDisplayPort Alternativeモードを利用できる。また,最大27Wの給電も可能だ。
表向きの用途は「Type-Cケーブル1本でVR対応ヘッドマウントディスプレイと接続して,データと映像の伝送を同時に行う『VirtualLink』用」だが,当然,汎用のUSB 3.1 Gen.2端子としても利用可能だ。
なお,ビデオ出力周りでは,「BT.2100」規格に準拠した,HDR映像のトーンマッピングハードウェアを搭載するというアピールもNVIDIAは行っていたが,現在のところ詳細は明らかになっていない。おそらくは,NVIDIAが推進中の「G-SYNC HDR」関連か,HDMIあるいはDisplayPort出力にあたってVESAのHDR規格「DisplayHDR」(※正式名称は「VESA High-Performance Monitor and Display Compliance Test Specification」)に適合するディスプレイマッピング(※ディスプレイの輝度スペックにあわせて階調特性を調整すること)処理を行うものと見られる。
 |
2枚のグラフィックスカードでマルチGPU構成とするSLIは,TU102コアのRTX 2080 TiとTU104コアのRTX 2080でのみサポートとなり,TU106コアのRTX 2070ではサポートされない。
また,Turing世代のGPUにおけるSLIは,従来のSLIと互換性がない点も押さえておきたい。今世代で採用するSLIでは,GPUとGPUとを専用インタフェースで相互接続する「NVLink」ベースだ。
NVLinkは,Pascal世代コアのGP100を採用したGPGPU専用製品「Tesla P100」とともに登場した相互接続リンクで(関連記事),複数のGPUを協調動作させるためのものとなる。
従来のSLIは,レンダリング結果として出力されたピクセルデータだけを共有するものだったが,NVLink時代のSLIでは,2基のGPUがまるであたかも1つのGPUのように振る舞って動作できるところに特徴がある。
たとえばRTX 2080 Tiを2枚差ししたシステムでは,総CUDA Coreが8704基(=4352基×2)に上る1基のGPUとして動作させることができるのだ。なので,これまでのSLIのように「Alternate Frame Rendering」(AFR)や「Split-Frame Rendering」(SFR)のような特別なレンダリングモードでGPUを駆動する必要がない。
またグラフィックスメモリも共有できるため,RTX 2080 TiのSLI構成であれば,グラフィックスメモリは22GB(=11GB
なお,ここまで「2基のGPU」と書いてきたことから想像できると思うが,NVLinkベースの新世代SLIで対応するグラフィックスカードは2枚までだ。
ちなみにTU102だとNVLinkは2リンク,TU104は1リンクだとのこと。リンクあたりの帯域幅は片方向25GB/s,双方向50GB/sなので,RTX 2080 Tiは双方向100GB/s,RTX 2080は双方向50GB/sの相互接続が行えることになる。
GP100だと4リンク,GV100は6リンクという仕様だったが,このあたりの仕様に違いがあるのは,GPGPU用途とグラフィックス用途という設計思想の違いから来ているのだと思われる。
まだ見ぬ下位モデルこそがTuring世代の命運を握る!?
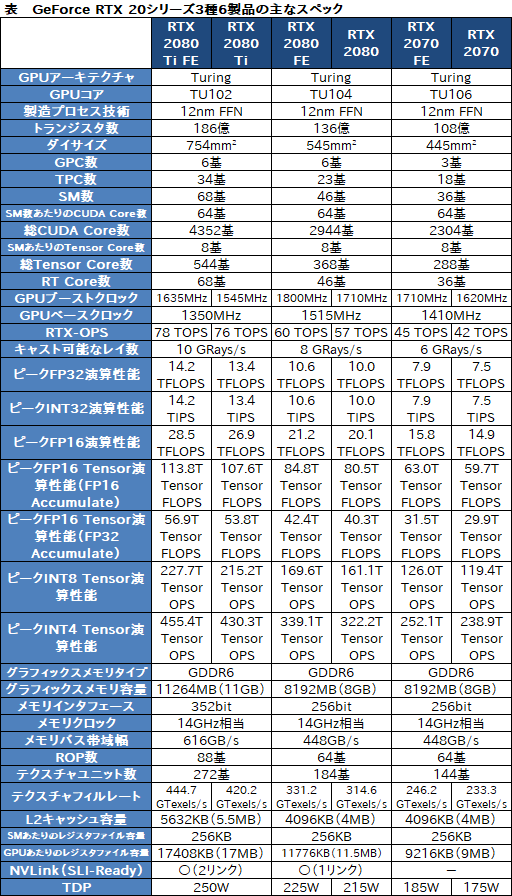
恐ろしく長くなってしまったが,最後にGeForce RTX 20シリーズの主なスペックを表にまとめたので参考にしてほしい。Founders Editionではブースト最大クロックが上がっているが,それ以外のスペックはリファレンスと変わらない。
 |
Pascal世代と比較してCUDA Coreの増加率はそれほどでもないTuring世代だが,リアルタイムレイトレーシングアクセラレータとしてのRT Core,推論エンジンアクセラレータとしてのTensor Coreを搭載し,さらにジオメトリパイプラインとピクセルパイプラインの改善など,技術的に飛躍しているポイントはかなり多い。端的に述べて,非常に興味深いGPUである。
NVIDIAのJensen Huang(ジェンスン・フアン)CEOは先の発表会で繰り返し「Turing世代コアはリアルタイムグラフィックスの再発明を行うものだ」と述べていたが,確かにそのインパクトは,プログラマブルシェーダを初めて搭載した「GeForce3」登場時に優るとも劣らないと思う。
 |
競合であるAMD,そして2020年にも単体GPUを市場投入する予定となっているIntelの動きもあるため,短期的にどうなるかは分からないものの,中長期的にはほぼ間違いなく,RT Coreに相当するリアルタイムレイトレーシングアクセラレータがすべてのGPUに載るだろう。
2019〜2020年頃に登場すると噂されている次世代PlayStationや次世代XboxのGPUが,万が一にもレイトレーシングアクセラレータに相当するものを搭載してくるなら,その普及には弾みが付くはずだが,すでにお伝えしているとおり,その可能性は低い。NVIDIAとしても長期戦は織り込み済みではなかろうか。
一方,Tensor Coreをゲーマーがどう受け止めるかはなかなか想像しにくい。
Tensor Coreを活用するAIベースのポストプロセス処理,その一例としてのDLSSは,サービスとしては非常に面白い試みだと言えるが,GeForce Experienceによる「ゲーム設定の自動最適化」と同じように受け止められるのではないか,という気はしている。
GeForce RTX 20シリーズ搭載グラフィックスカードのユーザーが知らないうちにTensor Coreを活用しているような状況を作り出せれば,ミドルクラス市場以下に向けた製品の登場後,カジュアルゲーマー層には浸透するかもしれない。
また,ジオメトリパイプラインとピクセルパイプラインの改善は非常に高尚な試みだが,AMDのプリミティブシェーダと同じように,しばらく放置されることになってしまうかもしれず,そこが心配だ。
なのでNVIDIAが,いま挙げたTuring世代の新技術や目玉機能の数々を,今後,どのような規模で展開,訴求していくのかというのが重要になると思う。
たとえば,「RT Coreを搭載するのはハイクラス市場向けGPU以上」(≒ミドルクラス以下では「GeForce GTX」を継続)という戦略をNVIDIAが取るなら,ゲームスタジオはレイトレーシング対応を渋ってくる可能性が高い。またDLSSも「AIが高画質化してくれる」というコンセプト聞く限り,ミドルクラス以下のGPUでこそ効果が高そうな機能だが,これもTensor Coreが載っていなければ利用できないわけで,やはりNVIDIAがどういう判断を行うか次第ということになるだろう。
現時点では筆者の勝手な想像でしかないが,「2060」以下の型番を採用するTuring世代のGPUは,そう遠くない将来に出揃うはずだ。それら下位モデルの製品群が,本稿で紹介した新技術,新機能を実用レベルで動かせるか否かが,TuringというGPUアーキテクチャ成功のカギを握っているとまとめておきたい。
NVIDIAのGeForce RTX 20シリーズ製品情報ページ
- 関連タイトル:
 GeForce RTX 20,GeForce GTX 16
GeForce RTX 20,GeForce GTX 16 - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー