












ニュース
4万8000個の最新Xeon Phiで中国の「天河2」が世界最速スパコンに。Intel,スパコン分野での優位を主張。次世代Xeon Phiの情報にも言及
 |
自社の製品を採用したスーパーコンピュータが世界1位を獲得したIntelは,早速プレスリリースを発表して,HPC(High Performance Computing)分野におけるIntelアーキテクチャの優位性をアピールしている。今回はIntelが公開した,天河2とそれに使われたIntel製プロセッサに関してまとめてみよう。
Xeon×3万2000基とXeon Phi×4万8000基で
構成された世界最速のスパコン 天河2
IntelがISC13に合わせて発表した内容には,大きく分けて3つのトピックがあった。1つめは,Intelアーキテクチャを採用した天河2が,TOP500 Listで1位になったこと。2つめは,HPC分野向けプロセッサ「Xeon Phi」シリーズに新製品が登場したこと。そして3つめは,後述するXeon Phiシリーズの将来製品についてである。順番に説明していこう。
 |
この天河1については,2011年に現地リポートを掲載したことがあるが,IntelのXeonプロセッサにNVIDIAのGPU「Tesla」搭載ボードを組み合わせた,ヘテロジニアス構成(異種アーキテクチャ混合構成)のスーパーコンピュータだった。
それに対して天河2は,NVIDIAのTeslaは使わずに,“オールIntelアーキテクチャ”で構成されたスーパーコンピュータとなったのが大きな違いである。TOP500 Listの情報によると,天河2が採用したのは,2013年後半に正式発表されると言われている「Xeon E5-2600 v2」シリーズの「Xeon E5-2692」を3万2000個と,4万8000個の「Xeon Phi 31S1P」であるという。
 |
Xeon Phiシリーズについてはこちらの記事で紹介しているが,x86アーキテクチャに基づくCPUコアを数十個,「Xeon Phi 5110P」の場合は60個も集積した,数値演算アクセラレータである。もとを正せば,かつて「Larrabee」(ララビー,開発コードネーム)と呼ばれて開発が進められながら,最終的に製品化を断念したGPUの技術を,HPC分野向け製品に転用したものだ。
しかし,天河2に採用されているというXeon Phi 31S1Pは,いまだ未発表の製品で,その詳細な仕様は公開されていない。
一方,Xeon E5-2600 v2シリーズとは,第3世代Coreプロセッサをベースにした,開発コードネーム「Ivy Bridge-EP」と呼ばれるサーバー向けCPUである。これまた現時点では未発表の製品で,8コア,10コア,12コアの製品がラインナップされると噂されていた。TOP500 Listによると,天河2に採用されたXeon E5-2692は12のCPUコアを内蔵し,動作クロックは2.2GHzであるようだ。
TOP500 Listで公開されている天河2のデータによると,システム全体で使われているCPUコアの総数は,312万基にも上るという。ではXeonとXeon Phiの内訳はどうなっているのだろうか。簡単に計算してみよう。
まず12コアのXeon E5-2692が3万2000個だから,CPUコア数は38万4000基となる。これは数字が出ているので確実だ。
Xeon Phi 31S1Pに搭載されているCPUコア数は不明だが,57基という噂があるうえに,後述する新しい「Xeon Phi 3100」シリーズである「Xeon Phi 3120A」と「Xeon Phi 3120P」が,ともにCPUコアを57基搭載している。そのため,Xeon Phi 31S1Pも57基であると仮定して計算すると,4万8000個で273万6000基になるから,Xeon側と合算すれば,ちょうど312万基になるわけだ。
Xeon Phi 31S1Pのコア数が57個で正しいのかは分からないが,いずれにしてもx86コアが300万基以上も使用されているという,恐るべきスーパーコンピュータが天河2であるといえよう。
天河2の理論ピーク性能は,54.9PFLOPS(ペタフロップス,約5万4900TFLOPS)に達するという。そしてTOP500 Listの公式ベンチマークである「LINPACK」(リンパック)を測定したところ,33.86PFLOPS(約3万3860TFLOPS)を実現したとされている。理論性能比では,現在世界第4位の日本製スーパーコンピュータ「京」(11.28PFLOPS)の,実に5倍にもなる。ただし,京はLINPACKで理論性能の93%という驚異的に高い実効性能を達成しているので,LINPACK性能比較では3倍程度だったりもする。
また,天河2は性能だけでなく,電力効率の高さも謳われている。その消費電力は,公称17.8MWとのこと。ちなみに,京は公称約15MWとされるので,たしかに電力効率も高いと言えそうだ。
Intelは今回の発表で,「Top 500 Listにリストされている80%以上のスーパーコンピュータが,Intelアーキテクチャを採用している」と述べるなど,Intelアーキテクチャがスーパーコンピュータの世界でも圧倒的優位にあるとアピールしている。
とくに,Xeon Phiと直接競合するGPUとの比較では,TOP500 Listに掲載されているLINPACKのスコア「Rmax」の値を,Xeon PhiとGPUでそれぞれ合計した値という,意味があるのかないのか分からないような数字を挙げて,全GPUの合計(total Rmax)よりもXeon Phiの合計のほうが大きいと主張しているほどだ。よほど今回のTOP500 Listで勝ったのが嬉しいのだろう。
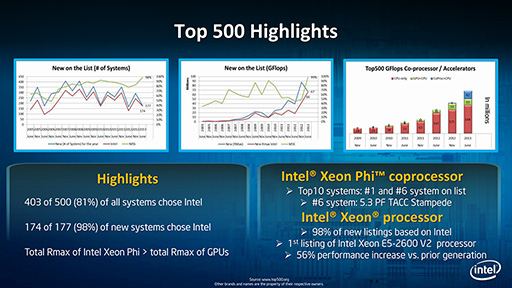 |
次世代のXeon Phiは,14nmプロセスなど
最先端技術がてんこ盛りに
冒頭で述べた2つめのトピックが,Xeon Phiに新たに3シリーズ5製品が追加されるという情報だ。
まずハイエンドの「Xeon Phi 7100」シリーズとして,PCI Express拡張カードタイプの「Xeon Phi 7120P」と「Xeon Phi 7120X」が発表された。どちらもCPUコア61基を集積して,動作クロックは1.23GHz。カード上には16GBのメモリを搭載する。既存の「Xeon Phi 5100」シリーズはメモリが8GBだったので,メモリは倍増しているわけだ。
次なるXeon Phi 3100シリーズは,先に述べたXeon Phi 3120PとXeon Phi 3120Aがラインナップされる。いずれも2012年11月に開かれた「Supercomputing Conference 2012」※で存在が明らかにされていた製品で,ようやく正式に出荷されたようだ。先述のとおりCPUコア数は57基で,動作クロックは1.1GHz。倍精度演算性能は1.1TFLOPSになるという。
※International Supercomputing Conferenceとは別のイベント。
興味深いのは,第3の「Xeon Phi 5100」シリーズだ。高密度サーバー向けの製品とされ,Xeon Phi 7100や3100のようなPCI Express拡張カードではなく,ソケット搭載式になるという。「Xeon Phi 5120D」という製品が2013年末のリリースされるというが,今のところスペックは不明だ。
 |
3つめのトピックが,次世代のXeon Phiとなる開発コードネーム「Knights Landing」(ナイツランディング)について,少しだけだが非常に興味深い情報が明らかにされたことである。
まず重要なのは,Knights Landingはコプロセッサとしてだけでなく,独立したCPUとして使える製品として供給されるという点だろう。
Intelは,現行のXeon PhiのようなPCI Expressカードでは,ホストCPUとのデータ転送の帯域が限られて性能の向上が阻害されるうえ,プログラムを複雑にする要因になっているとしている。そこで,独立したCPUとして使えるXeon Phiを提供することで,現行製品の抱えるこうした問題を解決しようというわけである。つまり,Knights Landingでは「コプロセッサ」ではないXeon Phiが登場する,ということだろう。
 |
そしてKnights Landingでは,14nmプロセスが使用されるという。これはIntelが2014年以降のCPUで導入する予定のプロセス技術であるから,つまりKnights Landingが登場するのは,2014年以降ということになる。
こちらの記事でレポートしているとおり,NVIDIAはISC13で,ARMアーキテクチャへの対応に向けて大きく踏み出している。それに対してIntelは,Xeon Phiを筆頭にx86アーキテクチャの優位性を訴えるという構図となった。Intelは天河2という強力な実績を引っさげてのアピールだけに,説得力はある。HPCの世界で,NVIDIAがIntelにどう対抗していくか,今後も見どころは多そうだ。
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー