米国時間2012年5月15日,AMDは開発コードネーム「
Trinity」(トリニティ)として知られていた第2世代AMD A-Series APU(以下,A-Series)を発表した。
Trinityのダイ写真
 |
A-Seriesは,Llano(ラノ)世代のA-Seriesと同じく,GLOBALFOUNDRIESの32nm SOIプロセス技術を採用して製造されるが,Llano時代におけるK10ベースの「Husky」コアから,Bulldozerベースの「
Piledriver」(パイルドライバー)へとCPUコアを刷新し,GPUアーキテクチャもRadeon HD 6900シリーズと同じ「
VLIW4」(Very Long Instruction Words 4)エンジンを採用することで,性能向上と省電力性の両立を図ってきた製品だ。
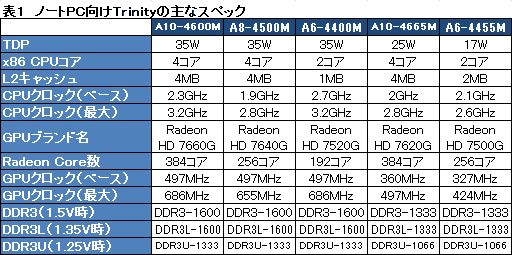
その製品ラインナップとスペックは
表1のとおり。発表時点ではノートPC向けのみが用意されており,デスクトップPC市場向け製品の投入は,2012年第2四半期末以降に始まるとされている。
Trinity事前説明会の会場となったBob Bullock Texas State History Museum
 |
4Gamerでは,「
A10-4600M」を搭載した
評価用ノートPCのレビューをすでにお伝えしているので,その実力は掴んでもらっていると思う。それを踏まえつつ,本稿では,米テキサス州オースティン市で開催された報道関係者向け事前説明会の内容を基に,そのアーキテクチャと立ち位置を整理してみたい。
より省電力&高クロックを指向したPiledriver
Bulldozerからの機能拡張も
Trinityの位置づけ。優れたエンターテイメント体験と,ゲーム体験,そして消費電力あたりの性能の向上を目指したという
 |
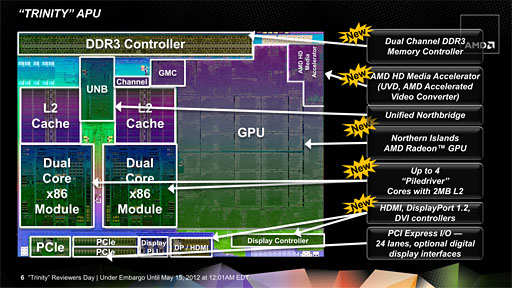
Trinityでは,第2世代の「Bulldozer Module」(以下,Bulldozerモジュール)となる「
Piledriver Module」(以下,Piledriverモジュール)が最大2基搭載され,AMD流に言うところのクアッドCPUコア製品となる。
AMDはこのPiledriverモジュールを開発するにあたって,分岐予測の精度やスケジューリングの効率を向上させるなど,Bulldozerの弱点と指摘されてきたIPC(Instruction Per Cycle:1クロックサイクルで実行できる命令数)の向上を図り,より高クロックで動作するようにも改良してきたとのことだ。
Trinityプラットフォームのブロック図。ノートPC向けプラットフォームだと,チップセットはLlano時代と同じものがそのまま採用される
 |
Turbo CORE 3.0では,負荷状況に応じてCPUとGPUの動作クロックを引き上げていく
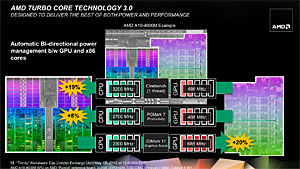 |
高クロックでの動作を実現するのと合わせて導入されたのが,自動クロックアップ機能「AMD Turbo CORE Technology」(以下,Turbo CORE)の第3世代「
Turbo CORE 3.0」である。
Turbo CORE 3.0では,CPUとGPUのクロックや消費電力,温度をモニタリングし,負荷状況に応じて“動作クロックの限界点”を融通し合えるようになった。従来はCPUの動作クロックを引き上げられるだけだったのが,Turbo CORE 3.0では,GPUコアの引き上げも行えるようになったのがトピックだ。
CPUコアに負荷がかかっているときにはGPUコアのクロックを下げてCPUコアのクロックを大きく引き上げ,逆のシチュエーションではGPUコアのクロックを引き上げられるようになったと説明したほうが分かりやすいかもしれない。
いずれにせよ,これによりノートPC向けAPUでは,Turbo COREの上限となるクロックを,CPUコア・GPUコアとも,定格よりかなり高いところへ設定することが可能になっている。
Llano時代のTurbo COREでは,GPU分の余裕を使ったCPUクロックの引き上げしか行えなかったが,Turbo CORE 3.0では,CPUコアやGPUコアの負荷や特性に応じて,きめ細かなオーバークロック制御を実現するというスライド。AMDは,クロック引き上げ時の“伸びしろ”が増えたとアピールしている
 |
ところで,
AMD FXプロセッサが発表されたときに紹介しているとおり,AMDは,Bulldozerアーキテクチャにおいて,2基のx86整数演算ユニットと1基の浮動小数点演算ユニットを1つのBulldozerモジュール上に統合した。より小さなダイサイズで,マルチスレッド処理における効率的なデータリソースの共有ができるようにしていたわけだ。
Trinityの技術仕様
 |
Piledriverは,そんなBulldozerアーキテクチャの第2世代となるわけだが,AMDはここで,L1 TLB(Translation Lookaside Buffer)の大容量化を図り,加えて,ハードウェアプリフェッチ機能の強化や,「直前にメモリでストアされたデータ」を再利用するときのレイテンシ低減なども施すことで,データリソースの,よりシームレスな共有を可能にしてきている。
また,拡張命令セットとして3オペランドで単精度浮動小数点積和演算をこなす「
FMA3」(Fused Multiply Add 3)と,単精度(32bit)浮動小数点を半精度(16bit)の浮動小数点に変換する「
F16C」を追加でサポートし,浮動小数点演算処理の効率を引き上げてきているのもポイントといえるだろう。
Trinityダイのブロック図。CPUコアやGPUコアの変更だけに留まらず,さまざまな改良が加えられている
 |
Bulldozerアーキテクチャ第2世代モデルとなるPiledriverモジュールの強化ポイント
 |
 |
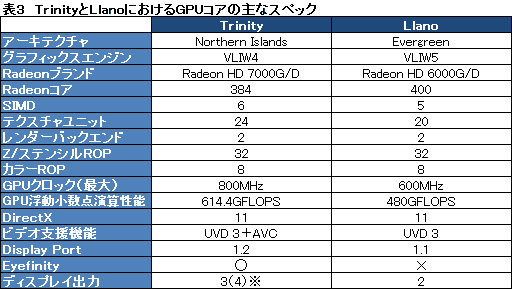
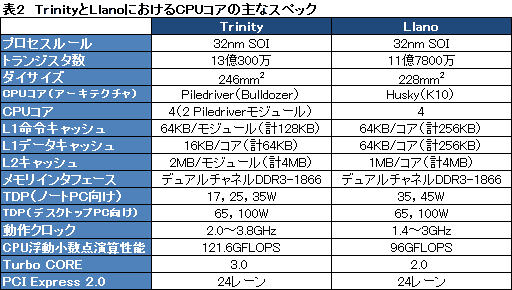
表2は,TrinityとLlanoとでCPUコア周りのスペックを比較したものになる。
Northern Islands世代のGPUコアをVLIW4ベースで実装
ビデオ関連の固定機能も搭載
冒頭でも紹介したとおり,GPUブロックでは,VLIW4エンジンを採用してきたのが大きな特徴となる。
ATI Radeon HD 2000〜5000シリーズで,AMDは,4基の32bit ALU(Arithmetic and Logical Unit。算術演算や論理演算を行うスカラユニットのこと)と,倍精度演算や超越関数に対応する「Special Function Unit」(または「T-Unit」「Transcendental-function Unit」,以下,SFU)を“4+1”の合計5基で構成するVLIW5エンジンを採用し,依存関係のない複数の命令を1命令としてまとめて実行してきた。
これに対し,Radeon HD 6900シリーズで採用されたVLIW4エンジンでは,SFUを省いた4 ALU構成へと改編し,倍精度演算や超越関数演算は4基のALUを組み合わせて処理するようにしている。もちろん,SFUを省くことで性能面でのペナルティはあるのだが,一般的なグラフィックス描画処理でSFUを用いるような複雑な演算が行われるケースは少ないため,シンプルなALU構成にすることで得られる命令発行やスケジューリング負荷低減というメリットのほうが大きい。それゆえ,より効率的な並列演算処理が行えるようになるというわけだ。
従来のVLIW5からSFUを省いたVLIW4
 |
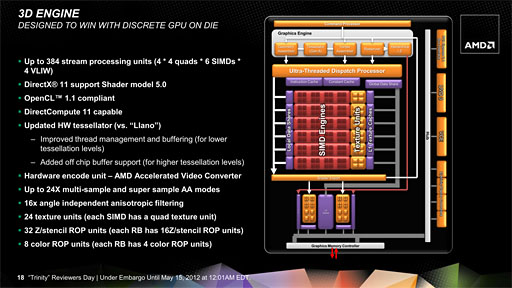
ATI Radeon HD 2000シリーズ以降のRadeonでは,8基の演算ユニットが1セットになって「SIMD Engine」を構成する仕様になっているので,VLIW5だと5×8で80基のところ,VLIW4では4×8で64基でSIMD Engineを構成できるようになる。Trinityでは,このSIMD Engineを最大6基搭載可能なので,64×6=384基のシェーダプロセッサを搭載できる計算だ。
Trinityのアーキテクチャを説明するJoe Maccri CTO。Trinityにおけるシェーダプロセッサは「Radeon Core 2.0」と位置づけられた
 |
AMDは,このシェーダプロセッサを最近「Radeon Core」と呼ぶことが多くなっているが,Radeon Coreの数だけ見ると,Llanoコアの最上位モデルとなるA8が400基なので,Trinityのほうが少ないということになる。
しかし,VLIW4アーキテクチャへの移行によって,SIMD EngineはLlanoの5基(80×5)に対してTrinityでは前述のとおり6基となり,さらに高クロック化も容易になったことで,単精度浮動小数点数の演算性能は,Llanoの最大480 GFLOPSに対してTrinityでは同614.4 GFLOPSと,1.28倍になっている。
また,VLIW4の採用によってSIMD Engineの数が増えたことにより,SIMD Engineあたり4基が組み合わせられるテクスチャユニットの数が必然的に増えている点も注目しておきたいところだ。
Trinityのグラフィックスアーキテクチャ。VLIW4アーキテクチャに変更されたことでシェーダコア数は384基に減ったが,高クロック化などによって,Llano比で最大50%の性能向上を実現したという
 |
グラフィックス関連では,4基のディスプレイコントローラが統合され,標準で3画面出力に対応するほか,DisplayPort 1.2による数珠つなぎを行った場合は最大4画面出力が可能になる点や,VLIW5アーキテクチャを採用したRadeon HD 7000&6000シリーズの下位モデルとの間でマルチGPU構成「AMD Dual Graphics」を取れる点が特徴となっている。
Display Port 1.2に対応。Eyfinityによる最大4画面出力も条件付きながらサポートする
 |
なお,AMDはかねてよりビデオ関連の支援機能に力を入れてきたが,Trinityでは,Southern Islands世代のRadeon HD 7000シリーズと同等の固定機能を,「
AMD HD Media Accelerator」として搭載してきた。具体的には,デコードエンジン「
UVD 3」と,Radeon HD 7000シリーズでは「Video Codec Engine」と呼ばれているエンコードエンジン「
AMD Acclerated Video Converter」を組み合わせて搭載してきたのだ。
ビデオのデコードとエンコードを固定機能として処理させるというのは,決して高くないCPU性能をカバーする存在として重要なポイントといえそうである。
Trinityでは,UVD3とAMD Accelerated Video Converterを固定機能として搭載してきている
 |
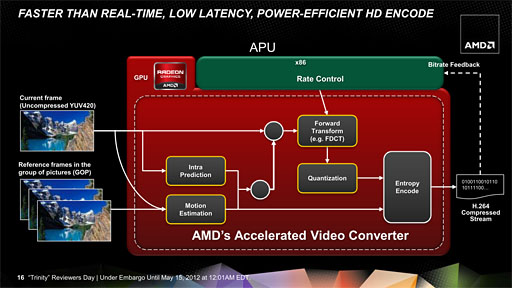 |
表3は,そんなTrinityのGPUおよびビデオ周りをLlanoのそれと比較したものになる。
※4画面出力はDisplay Port 1.2によるデイジーチェーンを有効にした場合のみ有効
 |
統合型ノースブリッジにも手が入ったTrinity
メモリアクセス周りを大幅に改善
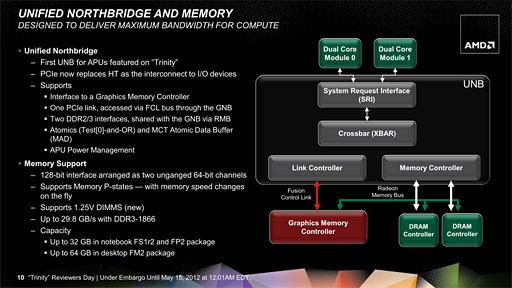
CPUコアやGPUコアだけでなく,Trinityでは統合されるノースブリッジ機能にも手が入った。CPUコアとGPUコアとが,より効率的にメモリアクセスできるよう改良され,名称も「
Unified North Bridge」(以下,UNB)に変わっている。
AMDは当初,TrinityでデュアルチャネルDDR3-2133のサポートを検討していたが,最終的にはデスクトップPC向けでDDR3-1866,ノートPC向けでDDR3-1600対応と,Llanoと同じ仕様で落ち着いた。つまり,メインメモリのバス帯域幅は最大29.8GB/sと変わらないわけで,CPUコアやGPUコアが強化されたことを考えるとやや心許ない。
そこでAMDはTrinityでノースブリッジをUNBへと切り替え,グラフィックスコア側のメモリコントローラがシステムメモリへアクセスするときにCPU側からのメモリアクセスとの調停を行えるようにしてきた。Llanoだと,CPUコアとGPUコアがシステムメモリの帯域を分割して共有していたのだが,UNBの採用により,
TrinityではGPUコアがDDR3メモリのフル帯域幅を利用できるようになっているという。
Unified North Brdigeのブロック図。GPU側のメモリコントローラから直接メモリアクセスしたときに,システムメモリバスのフル帯域幅を利用できるようにしているのが大きな特徴だ
 |
また,Trinityは,AMDが提唱する「
Heterogeneous System Architecture」(従来「Fusion System Architecture」と呼ばれていたもの)に対応した初のAPUになり,CPUコアとGPUコアが仮想メモリ空間を共有し,よりシームレスなデータ共有を実現するのも特徴だ。
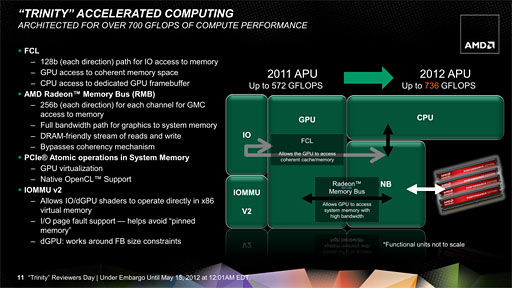
Trinityでは,GPUコアとUNBとを結ぶ128bit幅の「
Fusion Control Link」経由で,GPUコアがCPUコアのコヒーレントメモリ領域にアクセスしたり,逆にCPUがGPUのフレームバッファ領域にアクセスしたりすることも可能になる。これにより,APUに統合されたGPUの並列処理性能をアプリケーションが利用するのを容易にしているのである。
TrinityではGPUコアを利用した並列処理性能を引き出すべく,アーキテクチャの改良が施された
 |
仮想メモリのサポートなどによりCPUコアとGPUコアとがより密に連係できるようになった。これを機に,AMDはHeterogeneous System Architectureの立ち上げを加速する
 |
 |
従来製品比で大幅な低消費電力化を実現
17Wと25WのモバイルTrinityで「Ultrathin」を立ち上げ
Trinityにおいては,もう1つ,省電力性の向上も特徴とされている。
AMDはPiledriverで,リーク電流の低減を図るとともに,よりきめ細やかな電圧制御を行うことで,APU全体のTDP(Thermal Design Power,熱設計消費電力)を大幅に引き下げることを可能にしたという。
統合するUNBに搭載された電力制御機能により,Windowsのアイドル時にはメインメモリの動作クロックを動的に切り替えたり,グラフィックスメモリの利用をシングルチャネルに限定したりすることでも省電力化を図る。
Trinityの電力管理機能。CPUコアやグラフィックスコアだけでなく,UNBやメモリまでシステム全体で省電力化を図る
 |
さらに,ノートPC向けTrinityでは,タブレット端末やスマートフォンなどで利用されている1.25V動作のLow Power DDR3メモリも利用可能だ。これを組み合わせれば,ノートPCのさらなる省電力化も狙えるわけである。
Trinity搭載のUltrathinノートPCを披露するChris Cloran氏(Corporate Vice President, General Manager, Computing Solution Group, Client Division, AMD)
 |
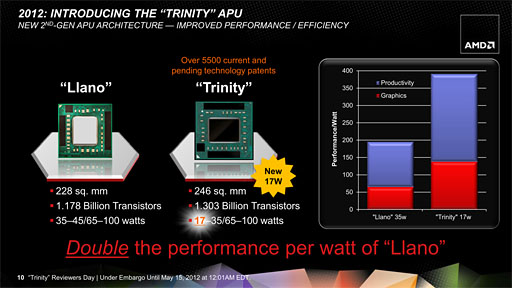
実際,Trinityでは,現行のノートPC向けA8比で約半分となる17WのTDPで,従来製品と同等の3D性能を実現したとのこと。AMDでクライアントCPU&APUビジネスを統括するChris Cloran(クリス・クローラン)副社長は,「モバイルAPUで,消費電力あたりの性能は従来製品比で2倍に向上した」とアピールしている。
AMDは,このTDP 17W版APUと,低消費電力版におけるもう1つの選択肢となるTDP 25W版Trinityによって薄型ノートPCプラットフォーム「Ultrathin」を立ち上げ,IntelのUltrabookに対抗したい考えだ。
リーク電流の低減などにより,TrinityではTDP 17Wのモデルを実現。消費電力あたりの性能では,現行のTDP 35W版A-Seriesと比べて2倍の性能を実現するという
 |
6月以降に市場投入される
デスクトップPC向けAPUの性能データが明らかに
冒頭で紹介したとおり,AMDはTrinityの第1弾として,ノートPC向けのAPU計5モデルを発表しているが,それに合わせて,性能データも公開している。そのなかには,6月以降の市場投入が計画されているデスクトップPC向けモデルのゲーム性能に関するデータも含まれていたので,以下に掲載しておこう(※いずれもクリックで拡大表示する)。
 Trinity投入後のノートPC向けAPUポジショニングマップ |
 Ultrathinプラットフォーム向けには,Visionのプレミアムロゴが用意される |
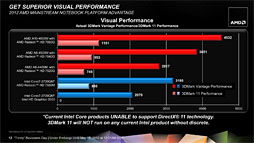 通常電圧版Trinityの3DMarkベンチマークスコアをまとめたスライド。A8-4500MでCore i7-2720QM+Radeon HD 7550Mを上回る |
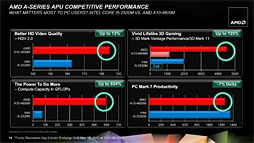 A10-4600MとCore i5-2520Mとで画質や3D性能,演算性能,アプリケーション性能を比較したスライド |
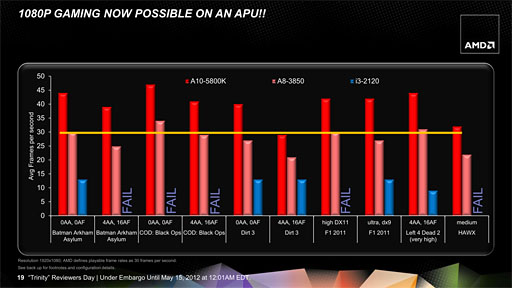
デスクトップ版Trinityの最上位モデルとされる「A10-5800K」の3Dゲームベンチマーク結果がまとめられたスライド。グラフィックスアーキテクチャの変更とメモリコントローラの改良により。1920×1080ドット解像度でも主要タイトルで30fps以上の平均フレームレートを実現できるとアピールされている。ちなみに,A10-5800KのGPUブランド名は「Radeon HD 7660D」だ
 |
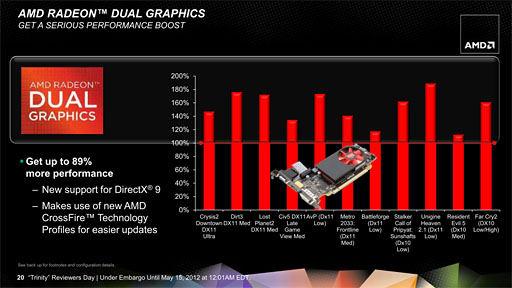
A10-5800KとRadeon HD 6570を組み合わせた「AMD Dual Graphics」環境のベンチマーク結果。最大89%の性能向上を果たすとされる。ただ,ここでのデータが解像度1280×1024ドット条件時のものとされている点は注意が必要だろう
 |
A10-5800Kを搭載したデモシステム。マザーボードにはGIGA-BYTE TECHNOLOGY製「GA-A85X-D3H」が利用されていた。この型番から見るに,デスクトップ向けTrinityでは現行製品である「AMD A75」の後継チップセットが用意されると見ていいだろう。なお,デスクトップ向けTrinityのCPUソケットは「Socket FM2」となり,Llanoの「Socket FM1」とは互換性がなくなることも,関係者の口から明かされている
 |
 |












 AMD A-Series(Trinity,Richland)
AMD A-Series(Trinity,Richland)