











連載
西川善司の3DGE:GeForce RTX 20なぜなに相談室(gamescom 2018版)
リアルタイムレイトレーシング専用の「RT Core」を採用した世界初のGPUアーキテクチャ「Turing」(テューリング)。それを採用する新世代GPUたるGeForce RTX 20シリーズがついに発表となった。
GeForce RTXシリーズのラインナップや現時点で判明しているスペックといった基本的な話は速報記事,「そもそもRT Coreって何?」といった技術的な側面については筆者の連載バックナンバーを参照してもらうとして,今回は,GeForce RTXシリーズについて現時点(※ドイツ時間2018年8月21日時点)で判明している情報から考察した内容を,「想定問答集」的にまとめてみることとしたい。
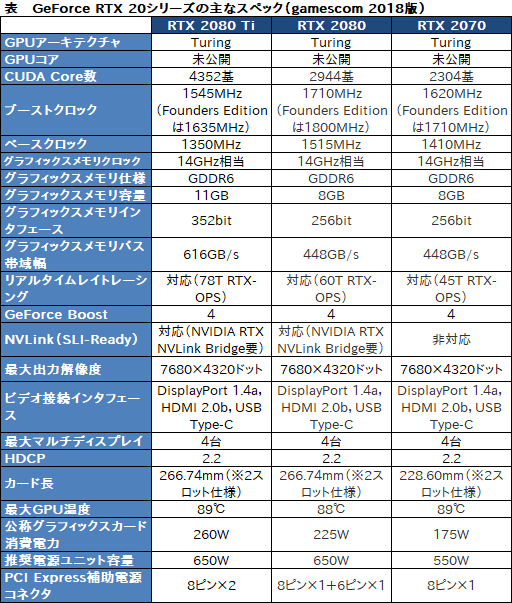
なお,本稿では「GeForce RTX 2080 Ti」「GeForce RTX 2080」「GeForce RTX 2070」(以下順にRTX 280 Ti,RTX 2080,RTX 2070)のスペック情報を前提として扱うので,適宜,下にまとめた表の内容をチェックしてもらえればと思う。
GeForce RTX 20の発表イベントで,NVIDIAのJensen Huang(ジェンスン・フアン)CEOは「ハイブリッドレンダリング」(Hybrid Rendering)という言葉を多用していた。
これを理解するには,従来からあるリアルタイムグラフィックスがすべて「ラスタライズ」(Rasterizing)というレンダリング手法を用いていることを知る必要がある。
ラスタライズ法というのは,「ディスプレイの画面に相当するピクセルで構成された平面にポリゴンを投射して,当該ピクセルを起点に,ライティングやシェーディングを行う」処理系のこと。描画対象となる3Dシーンのうち,画面に入らない領域や視点から見て視界外となる領域――画面より手前の領域や,視点から見て裏側の領域――はレンダリング対象から除外するという,極めて大胆な手抜きを行うことで高速に描画するのが特徴だ。
一方でレイトレーシング法は,視線から画面上の各ピクセルを通る視線の延長線上に描画対象が存在する場合,そこからレイ(Ray,光線)と呼ばれる「情報回収探査船」のようなものを射出して,画面外であろうと視界外であろうと,とにかく当該3Dシーンでレイが到達した先にある光の伝搬情報を回収して描画に反映するというものになっている(※もちろん計算予算は有限なので,レイの発射数はプロセッサの性能に応じて変わる)。
これらラスタライズとレイトレーシング,両方の手法を適材適所で使い分けるのがハイブリッドレンダリングである。
では,いかにして「適材適所の振り分け」を行うかだが,
といった形が,当面の定番レシピになりそうだ。いまレイトレーシング法に振り分けるとした要素はいずれもラスタライズ法だと一筋縄で描画できないものであり,また(計算量はともかく)レイトレーシング法だと手堅くシンプルで,かつスケーラブルな実装ができるためである。
もちろん,ハイブリッドレンダリングの中でレイトレーシングに任せる要素が多くなればなるほど,レイトレーシング法で射出されるレイの数(≒3Dシーンの中に旅立つ「情報回収探査船」の数)が多くなり,レイの存在時間(=レイの処理時間)も長くなるので,すべての「レイトレーシングに向いた要素」の描画をレイトレーシング法で行うのは,Turingアーキテクチャを採用するGPUには難しいだろう。
ただ,Turingアーキテクチャが登場していなかったGDC 2018の時点だと,「レイトレーシング法で行える要素は(先ほど列挙したレイトレーシング法に振り分けたほうがよいもののうちの)1個が限界では?」という見通しだったりした。それに対し,GeForce RTXのRT Core性能が見えてきたgamescom 2018のタイミングでは,「全部とは言わずとも,複数はいけるのではないか」という明るい未来が見えてきており,これはゲーム業界にとってよい兆候だと言える。
2018年3月に開催されたGDC 2018の時点でNVIDIAは,同社独自の「RTX Technology」(以下,RTX)について,MicrosoftがレイトレーシングパイプラインをDirectXに統合した「DirectX Raytracing」(以下,DXR)のランタイム(Runtime,プログラムを動作させるために必要な要素)に相当するものと紹介していた。
もちろんこの説明は間違っていないのだが,今回のイベントでは,従来のラスタライズ法によるレンダリングから,レイトレーシング法によるレンダリング,CUDAによるGPGPU処理,そして「Tensor Core」による推論アクセラレーションまでを含む統合ランタイムであることが新たに判明している。
ただ,RTXはGPUドライバにかなり近い層にあるため,レイトレーシングレンダラーの開発者なら「OptiX」,ゲーム開発者はDXRや「Vulkan」を使えばいい。なので,このランタイム構造を強く意識する必要はとくにないはずだ。
上で示したRTXの最上層にMDL(Material Definition Language)があるが,これは物理ベースで材質の反射特性や光源の放射特性などをプロシージャル的に記述できるものだ。
現状,MDLはゲーム用途にあまり関係なく,映画などのプロ映像制作におけるオフラインレンダリング用となっている。ゲームグラフィックスの場合,いくら物理ベースレンダリングが主流になったとはいえ,物理反射特性のメカニクスが非常にシンプルで原始的かつ簡略的なためだ。何より,グラフィックスエンジンがサポートする反射特性パラメータがまちまちで,MDLライブラリで記述された定義を再生できるレベルにはとても到達していない。
いずれ,ゲームグラフィックスレンダリングがリアルタイムレイトレーシング主体になってくればその限りではないものの,「ラスタライズ法が主体で,ワンポイントリリーフ的にレイトレーシング法も用いる」という,今後しばらくゲームグラフィックスにおいて主流となるはずのハイブリッドレンダリングにおいては,これまで同様「MDLはゲームでは無関係」という認識で構わない。
まとめると,NVIDIAは,リアルタイムレイトレーシングに対応するRT Coreを動作させ,ここにGPGPUと推論アクセラレータとしてのTensor Coreまでをグラフィックスに介入させるインターオペラビリティ(interoperability,相互互換性)を実現するにあたって,ドライバ構造を再設計する必要が生じることとなった。
そしてそこで,「これってうち特有のプラットフォームになってるっぽいから,格好いい名前を付けようぜ」ということで,「RTX」という名前になった,くらいの理解でいい。
RTXという意味ありげなキーワードではあるが,そこに深淵な技術的背景が存在していたりはしないのである。
GeForce RTX 20シリーズの発表イベントにおけるHuang氏の発言や氏の示したスライドの中には,独特すぎて難解なキーワードや,そもそも何を指し示しているのか分からない謎なキーワードが散見されたのだが,そのうちの1つが「1 Turing Frame」(テューリングフレーム)である。
1 Turing Frameが登場したのは,速報記事でも紹介したとおり下に示したスライドとなる。
これは「1フレームを描画するにあたって,Turing世代のGPUコアはどんなステップで動くのかを図示したもの」なのだが,まず注意が必要なのは,この図があくまでも事例の1つに過ぎず,必ずしもこの時間配分で処理が進むことを示すものではないということだ。簡単に言えば「適当な図」である。
いちおう図解もしておくと,緑色の「Ray Tracing」というバーは,レイを生成して射出し,衝突判定を行うRT Coreが仕事をしている部分になる。「FP32 Shading」はいわゆる頂点パイプラインにおける頂点シェーダとジオメトリシェーダ,ハルシェーダ,ドメインシェーダといった各種シェーダと,ピクセルパイプラインのピクセルシェーダが仕事をしていることを表している部分だ。
念のため書いておくと,ラスタライズ法においてもレイトレーシング法においても,頂点パイプラインやピクセルパイプラインの仕事内容は変わらない。使う機能ブロックも同じだ。
「INT32 Shading」は整数演算の実動を示す部分で,画像テクスチャやマスクテクスチャを取り扱ったピクセルシェーダ処理などが主に該当する。「DNN Processing」は,Tensor Coreによってアクセラレーションされた推論エンジンでレンダリング結果に対してデノイズ(denoizing,ノイズ低減処理)やアンチエイリアシングといった各種ポストプロセス処理を行うことを示している。この点については後述したい。
GeForce RTX 20シリーズの発表イベントでHuang氏が示した謎キーワードの頂点に君臨すると言っても過言ではないのが,「RTX-OPS」という独特な単位だ。
氏の言い分をそのまま紹介するなら,RTX-OPSは,Turing世代のGPUコアを搭載するGeForce RTXおよびQuadro RTXシリーズが1秒間にこなせる処理量を表した性能値で,GPUコア内にある浮動小数点演算器と整数演算器,RT Core,Tensor Coreの理論性能値をすべてを強引に足し合わせたものとなる。
Turingコア世代同士での性能比較は,今後RTX-OPSを使ってやってほしいというのがNVIDIAの強いメッセージで,その性能値は以下のとおりだ。
困ってしまうのは,(速報記事でも指摘しているとおり)78や60,45といった値の根拠がまったく分からないことである。
Q3のところで出てきた1 Turing Frameのスライドには,いろいろと数値が並んでいるのだが,これらをどう四則演算しても78にはならない。
というわけで,「RTX-OPSってなに?」という質問の答えは「まだ分からない」となる。このあたりは取材を進めたうえであらためて解説してみたい。
どうしてNVIDIAは謎キーワードであるRTX-OPSを“発明”したのか。その理由については長年のGeForceファンならもう気付いているかもしれない。そう,Turing世代のGPUは,これまで長らくNVIDIAが性能指標の目安として用いてきた「CUDA Core数とブーストクロックから導く理論性能値」である「FLOPS」において,Pascal世代のGeForce GTX 10シリーズからそれほど向上していないのである。
逆に言えば「GeForce GTX 10シリーズからの大きな性能向上」はRT CoreとTensor Coreに大きく起因しているので,ここをアピールしないと,GeForce RTXの魅力が半減してしまう。
たとえば実際にGeForce RTX 20シリーズとGeForce RTX 10シリーズでCUDA Coreベースの理論性能値を比較すると,以下のとおりとなった。
確かに性能は向上している。しているが,“GeForce GTX 11”ではなくGeForce RTX 20と,シリーズ名が大きくジャンプアップしたことを考えると,FLOPS値の伸びが控えめなのは否めない。これがQ.5への回答になる。
GeForce GTX 10シリーズが採用する製造プロセス技術はTSMCの16nmなのに対し,GeForce RTX 20シリーズはTSMCの12nm(12nm FFN)なので,見かけ上,微細化は1世代進んでいるが,実のところ12nmは16nmのリファイン版にしか過ぎないため,動作クロックも面積あたりのトランジスタ積載量もそう大しては変わらない。そう考えると,CUDA Core基準の性能向上率はむしろ健闘しているほうだろう。
その点RTX-OPSなら,RT CoreとTensor Coreで得られるスコアを加味したものになるので,RTXベースのアーキテクチャを採用していないGeForce GTX 10シリーズではスコアが伸びず,GeForce RTX 20が圧倒できる。だからこそNVIDIAはRTX-OPSを導入したのだ。
Turingアーキテクチャでは,深層学習の学習データを基に推論を行うためのアクセラレータとしてTensor Coreを搭載している。
「Volta」アーキテクチャ世代のGPUでは,AIの研究開発やAIランタイムのアクセラレーション用途向けにTensor Coreを採用するわけだが(関連記事),NVIDIAは,「グラフィックス処理結果に対して『追加のお化粧や整形』を行うポストエフェクト処理を任せるのに使えるのではないか」と考え,そのままTuring世代のGPUに搭載してきたのである。
そのポストエフェクト処理について,Quadro RTXの発表時にNVIDIAは「DLAA」(Deep Learning Anti-Alising)と紹介していた。
DLAAは,ノイズやエイリアシング(≒ジャギー)が散見されるレイトレーシング結果と,時間を十分にかけて描画したノイズのない描画結果との相関性を学習し,入力映像からノイズやエイリアシングを低減させるポストプロセスだ。
実際にはノイズ低減とエイリアシング低減(≒アンチエイリアシング)とで,その深層学習モデルや学習データそのものも別になるようなのだが,DLAAは,キーワードイメージ的にアンチエイリアシング処理だけでなく,ノイズ低減を行うデノイザの機能も含むような,そうでないような曖昧な言い回しによる紹介となっていた。
そんな曖昧なイメージを払拭する……というか,新造キーワードでむしろさらなる曖昧化を図ったのが,GeForce RTX発表時に出てきた「DLSS」(Deep Learning Super Sampling)である。
「ディープラーニングを活用したスーパーサンプリング」であれば「深層学習による広範囲なポストプロセス」をイメージしやすいので,確かにDLAAよりは一般ユーザーにとって受け止めやすいだろう。
GeForce RTXの発表でHuang氏は,「NGX」という,深層学習ベースの映高品位化学習モデル生成フレームワークについても触れており,「これを使えば,レンダリング結果を,『Tensor Coreを活用したポストエフェクト』で高品位に変換できる」というデモまで披露していた。
「レンダリング結果の高品位化をAIで行うって,ちょっと信用ならなくない!?」という印象を持つ人がいるかもしれないが,最近のテレビ製品,たとえばソニーのBRAVIAや東芝のREGZAなどはすでに深層学習ベースの超解像エンジンを搭載しており,実際に地デジ放送映像などの高画質化に応用していたりする。
その意味でDLSSは,テレビがハードウェアでやっているような高画質化処理を,Tensor Coreを活用してリアルタイムにゲームグラフィックス上で適用するものという解釈でもいいように思う。
ここからはちょっとマニアックな考察へ移ることにしよう。
GeForce RTX 20シリーズはRTX 2080 TiとRTX 2080,RTX 2070というラインナップになっているが,イベントでHuang氏が幾度となく「Turingコア世代では」といった言い回しを使っていたことからも分かるように,GeForce RTX 20シリーズがQuadro RTXと同じアーキテクチャをベースにしたGPUであることは間違いない。
「シリコンダイレベルはどうか」というと,現時点では公開情報がないため,断言は難しい。2080型番の2製品だけがNVLinkの新世代SLIに対応するという状況証拠からすると,GTX 2080 TiとGTX 2080はQuadro RTXシリーズの最上位モデルである「Quadro RTX 8000」と同一のシリコンダイを採用している可能性はありそうだが,Quadro RTX 8000のCUDA Core数は4608基だ。RTX 2080は2944基なので,約64%しか使っていないことになってしまう。
「それほどまでにシリコンダイの歩留まりが悪い」というのも考えにくいので,RTX 2080とRTX 2070は同一のシリコンダイを採用している可能性もあると思う。
GeForce RTX 2070は今回発表になった3製品の中では最もグレードの低い製品だが,歴史的に「十の位が7」はハイクラスGPUだった。これまでNVIDIAはハイクラスGPUのSLIには対応してきた経緯があるので,後者の可能性を取る場合は「なぜ同一のシリコンダイなのにRTX 2070だけSLIを無効化しているのか」という別の疑問が出てくるだろう。その点では「別のシリコンダイで起こしたチップはNVLink非対応で,それをRTX 2070として発表した」と解釈したほうがしっくりくる。
いずれにせよ,RTX 2070搭載グラフィックスカードの499ドル(税別)からという北米市場におけるメーカー想定売価は,スペックからすると破格と言えるほどに安価であり,それはもちろん戦略的な値段設定によるものだろうが,それ以上にダイサイズが小さいことの裏付けにもなり得る。RTX 2080がどうかはさておき,RTX 2080 TiとRTX 2070が別のシリコンダイを採用しているのはまず間違いないと言っていいのではなかろうか。
現在のところ,公式情報はない。
……とだけ書いて終わらせるのもアレなので,考察してみよう。Quadro RTXが発表されたとき,筆者は最上位モデルであるQuadro RTX 8000のCUDA Core数が4608基であることから,
という仮の計算式を作った(関連記事)。GPCは“ミニGPU”的に機能する「Graphics Processing Cluster」のこと,SMはGPCに内包される演算ユニット「Streaming Multiprocessor」のことだ。
注意してほしいのは,この仮の計算式が正しいかどうかまだ分からない点だが,ひとまず正しいことにして話を進めよう。
RTX 2080 Tiはメモリインタフェースが352bit幅なので,384bitのQuadro RTX 8000と比べると32bit分少ない。こういう違いは以前の「GeForce GTX 1080 Ti」と「NVIDIA TITAN X」の間にもあったので,要は32bitメモリコントローラが1基無効になっているという理解でいい。
そのうえでRTX 2080 Tiの基本仕様はQuadro RTX 8000と変わっていない前提に立つと,CUDA Core数が4352基なので,12基のSMを内包したGPCが5基,8基のSMを内包したSMが1基なら,以下のとおり,計算はひとまず合う。
同様にRTX 2080はCUDA Core数が2944基なので,1基あたり12基のSMを内包するGPCが3基,10基のSMを内包するGPCが1基となれば,以下の計算式が成り立つ。
RTX 2070も同様だ。CUDA Core数が2304基なので,1基あたり9基のSMを内包するがGPCが4基構成とすれば以下のとおり計算がぴったりと合う。
RTX 2070が上位2モデルとは異なるシリコンダイだとすれば,GPCあたりのSM数を減らした“GeForce RTX 2060”的な製品を派生させるのは容易だろう。
逆に,RTX 2070とRTX 2080のシリコンダイが同じなのであれば,それこそNVLinkベースのSLIに対応した“GeForce RTX 2070 Ti”的なモデルの存在も妄想できそうだ。
Q.8のところで述べたとおり,RTX 2080 Tiのグラフィックスメモリインタフェースは352bitである。そして,352bitを32bitで割ると11になる。つまり,RTX 2080 Tiに接続されるGDDR6グラフィックスメモリチップは8Gbit品が11枚になるわけだ。
ちなみに,「352bitグラフィックスメモリインタフェース,グラフィックスメモリ容量11GB」という構成はGeForce GTX 1080 Tiと同じなので,別に不思議でも何でもなかったりはする。
RTX 2080 TiのCUDA Core数は4352基で,Quadro RTX 8000(とその下位モデルである「Quadro RTX 6000」)のCUDA Core数は4608基。なのにいずれも,リアルタイムレイトレーシングアクセラレータに相当するRT Coreの性能は「10G Rays/s」(毎秒10億レイ)で揃っている。この点を不思議に思った人は少なくないだろう。
というのも,これまでのNVIDIA製GPUは,さまざまな演算器や実行ユニットを演算ユニットとしてのSMに内包する形で実装してきたからだ。
言い換えると,CUDA採用後のNVIDIA製GPUは,SM数の多寡が性能の高い低いを決定づける仕様になってきたのである。
このルールはVoltaとTuring世代のGPUが搭載するTensor Coreでも継承している。速報記事で紹介したとおり,Huang氏がイベントで示したスライドだと,Turing世代のGPU(=RTX 2080 Ti)が持つシェーダおよび演算性能が14 TFLOPS+14 TIPS,AI推論性能が16bit浮動小数点演算で110 TFLOPSと,Quadro RTX 8000&6000の同14 TFLOPS+14 TIPS,125 TFLOPSより低いわけだが,それはひとえにSM数の違いがもたらしているわけだ。
ではなぜ,CUDA Core数の少ないRTX 2080 Tiで,Quadro RTX 8000&6000と同じ10G Rays/sを実現できているのかだが,少なくとも現時点では,「NVIDIA製GPUとしては極めて例外的に,RT CoreはSMに内包されていない」としか考えられない。
あらためて整理しておくと,Turing世代のGPUが持つレイ投射性能は以下のとおりである。
筆者はQuadro RTXについて触れた連載バックナンバーで,Quadro RTX 8000のGPUクロックが約1.7GHzに達するという推測を行っているが,これが正しければQuadro RTX 8000とRTX 2080 Tiの間ではCUDA Core数どころかGPUコアクロックも異なるということになる。それでレイ投射性能が同じとなれば,RT CoreはSM単位,GPC単位ではなく,GPU単位の実装と考えるのが自然だ。
そしてその場合,RT CoreはGPUの動作パイプライン(≒レンダリングパイプライン)とは完全独立して非同期に並列動作するものと推測できるわけだが,確かにRT Coreのメインの役割である,レイの生成(Generation)や推進(Traverse),衝突判定(Intersection)の仕事は,生成したレイごとにライフタイム(=生成されてからお役御免となるまでの処理時間)があまりにも異なるため,見通しを立てにくい。なので,一定のリズムで工場の生産ラインよろしく結果を出力し続けるSMの動作とは相容れないものがある。
であれば,レジスタ群や作業メモリといったリソースを共有しつつ,動作自体は完全非同期で並列動作するものとして実装したとしても不思議なことではないが,さて……。
このあたりについての詳細な構造についてはNVIDIAの情報開示を待つ必要がある。
Quadro RTXのスペック考察記事でも紹介したとおり,10G Rays/sの性能を持つケースだと,1920
Turing世代のGPUに対して同じ式を適用したときの計算結果は以下のとおりだ。
前述したとおり,レイトレーシング法の活用対象になるであろう影生成や環境光遮蔽陰影,鏡面反射材質における映り込み生成,半透明材質の透過屈折特性,大域照明による間接光再現といった要素の描画には,「再帰的なレイの生成がない」(=投射して当たった先のオブジェクトでさらにレイを投射することになる事態が発生しない)としたケースでも最低1レイずつは必要だ。その意味では,RTX 2070やQuadro RTX 5000でもレイトレーシングのアクセラレーション性能は相応に期待できるのではないかと思う。
ただ,拡散反射系の材質や,大きさを持つ光源を取り扱うようなシェーディングおよびライティングでは広範囲にレイを射出する必要があるため,GPUごとにRT Coreの性能差が出てきて,描画結果や,レイトレーシング法でまかなえるグラフィックス要素に違いが出てくる可能性はある。
Quadro RTX発表時からNVIDIAは「Variable Rate Shading」(ヴァリアブルレートシェーディング)というキーワードを掲げている。直訳すると「可変レートシェーディング」で,以下本稿ではこう呼ぶが,イメージとしては一種のLoD(Level of Detail)だ。
ゲームグラフィックスでよく用いられるLoDは,視点から近い3Dモデルは多ポリゴンでできたモデルで描画し,遠い3Dモデルは少ポリゴンでできたモデルで描画するという,ジオメトリ次元のものになるが,LoDというキーワード自体は専門用語でなく,一般用語である点に注意してほしい。
可変レートシェーディングとは,いわば「適材適所で品質を調整する」LoD処理をライティングとシェーディングにも適用するという意味になる。
可変レートシェーディングの「レート」は「頻度」とか「割合」の意味だが,これは時間方向にも空間方向にも対応できる。
たとえば,空間的な可変レートシェーディングで一般的なのは視線追跡型レンダリング(Foveated Rendering,フォヴィエイティドレンダリング)法としてお馴染みだ。これは眼球が注視している箇所を高品位かつ高解像度で描き,そこから離れるに従って品質や解像度を下げていくLoD的な技法だ。
時間方向的な可変レートシェーディングは,カメラ(=視点)の動いている速度やキャラクターの移動速度(≒1フレームあたりの移動量)で描画品質や解像度をLoD制御することになる。
たとえば視点が大きく動いている場合は,画面全体がモーションブラーでボケてしまう。一方で,あるキャラクターが激しく動いた場合はそのキャラクターがモーションブラーでボケてしまう。「であれば,それらは低品質に描画しても見た目は大して変わらない」として,その部分を低品質化して負荷を下げてしまおうというわけである。
ゲームエンジンレベルでこういう仕組みを導入しているものはすでに存在するが,NVIDIAの可変レートシェーディングは,この仕組みをハードウェアでサポートするというのが新しい。
現在のところ詳細な仕組みは明らかになっていないが,イベント会場で話を聞いたNVIDIAの関係者によると,Turing世代のGPUにおける可変レートシェーディングはやはり,レイトレーシングとペアになった考え方と捉えるのが正解のようである。
つまり,高品位に描く必要がある箇所は1ピクセルあたりのレイ射出量を増やし,そうでない場合は1ピクセルあたりの射出レイ数を減らしたり,あるいはもっと大胆に,それこそ2
「複数のピクセルでライティングとシェーディングの結果を共有する」という考え方は,マルチサンプルアンチエイリアシング(Multi-Sampled Anti-Aliasing,MSAA)処理では昔からありふれた考え方として採用されているため,珍しいことではなかったりする。
時間方向にレイを射出するピクセルを巡回させ(=ジッターさせ),複数フレームかけて全ピクセルでのレイ射出を行うといった,時間方向にレイ処理を分散させて行うLoD制御もあるが,いずれにせよ,このようなライティングやシェーディング,レイ射出を時間的空間的な可変レートで行うのが可変レートシェーディングというわけだ。
その結果はそのままだと汚かったりノイジーだったりするが,その場合は前述したDLSSで品質の引き上げを行うというスタンスになる。
今回のイベントでHuang氏は,GeForce RTX 20シリーズ対応,すなわちDXRないしはRTX対応となるゲームタイトルをいくつか紹介して,そのうえで,近々対応する予定になっているタイトル計21本を挙げていた。
だが,ゲーマーとして知りたいのは,今後,長期にわたってレイトレーシング法がゲームグラフィックスの主流となるのかどうかだろう。
これついて,少なくとも短期的には明るい材料を探しにくい。
表向きには「MicrosoftがDXRを提唱し,そこにNVIDIAがRTXで対応した」ことになっているが,「NVIDIAがRTXの採用をMicrosoftに働きかけ,その結果として,DirectXからRTXを使えるようにする仕組みとしてMicrosoftはDXRを発表した」のが実態である。なので業界的に俯瞰すると,「GPUにレイトレーシングアクセラレータを載せること」を熱烈に推奨しているのは現在のところNVIDIAだけだ。
Huang氏はイベントで,「リアルタイムレイトレーシング対応ゲーム」の動作デモを確かに披露した。だが,少なくとも筆者が確認した限り,イベント会場の来場者が触れる状態で展示されたタイトルは,多くがE3 2018版ビルドそのものか,そうでなくともリアルタイムレイトレーシング対応前のビルドだった点は押さえておいてほしい。
対応を果たしていたタイトルも,影生成と環境光遮蔽陰影への対応に留まるものがほとんど。影生成は「各ピクセルから射出した複数のレイが光源に到達できた割合」に生成でき,環境光遮蔽陰影は「各ピクセルから射出した複数のレイによる局所的な遮蔽率」で生成できるが,これらはいまあるゲーム用グラフィックスエンジンの構造をほとんど弄ることなく,比較的容易に実装できるものだ。
リアルタイムレイトレーシング対応タイトルの1つである「Metro Exodus」は間接光処理にも対応していたが,これはやや実装が高度と言える。
実装の詳細は明らかになっていないものの,実際の映像を見た限り,鏡面反射材質における映り込み生成には対応していないようだったので,ラスタライズ法で得た「直接光によるライティングおよびシェーディング結果」に対して,「各ピクセルから射出した複数レイによる間接光ライティングを行う」か,「もともと非レイトレーシング向け環境用に実装してあった間接光再現用の間接光プローブに対して,レイトレーシングを行う」かした結果のようだ。
いずれにしても,もともと実装されていた「非レイトレーシング向け環境用の間接光再現メカニズム」のアクセラレーションにRT Coreを使うアプローチということになる。
ここまでの対応ならば,ゲーム開発側もそれほど手間はかからない。そのため,対応を進め(てNVIDIAに宣伝してもらおうと考え)るゲーム開発スタジオもある程度は出てくるだろう。
一方,明らかに手間をかけてRT Coreに対応したと思われたのが,イベントでもかなりの時間を割いて紹介された「Battlefield V」である。

Battlefield Vのリアルタイムレイトレーシングは,鏡面反射材質における映り込み生成にも対応しており,BVH(Bounding Volume Hierarchy,バウンディングボリュームハイエラルキー)できちんと定義を行ったうえで,本格的なレイトレーシングを行っていることが推測できた。
BVHの詳細は筆者の連載バックナンバーを参照してほしいが,Battlefield Vでは視点から見えない領域の鏡像も再現できていたため,それこそ「接近する敵の姿を水たまりの映り込みで知る」「壁の向こうにいる敵の位置を,廊下に掛かっている鏡に映る鏡像で目測する」といった,ゲームグラフィックスがゲーム性を拡張するような表現になっていたのが印象的であった。
ただ,ここまで対応してくれるゲームタイトルは,今後もそれほど多くは見込めないと思う。
その理由は,対応ハードがGeForce RTX 20シリーズのみに限られるからだ。
今日(こんにち)の人気ゲームは,PCと据え置き型ゲーム機,そしてスマートフォンやタブレットに向けてマルチプラットフォーム展開となるのがスタンダードとなっている。PCは主要なリリース先プラットフォームの1つではあるが,メインプラットフォームになることはまれだろう。
最近のPlayStation 4およびXbox One向け大作タイトルが,ほぼ間をおかずにPCでも同時発売となっているのは,(MicrosoftによるWindows 10環境整備の影響もあるが)PlayStation 4とXbox OneのアーキテクチャがほとんどPCそのものだからにほかならない。言い換えると,移植コストがほぼゼロに近いからだ。
その観点に立つと,GeForce RTX 20シリーズが持つRT Coreへの対応は,ゲーム開発スタジオにとって,どこまでも「追加の開発工程」となる。なので,Battlefield Vレベルの対応をすべてのゲームに望むのは酷だろう。Metro Exodusレベルの対応が実現できていれば御の字で,大半は影生成と環境光遮蔽陰影への対応止まりになると思われる。
なら,DXRがスタンダードになれるチャンスはないのかと言えば,そんなことはない。AMDがDXRに対応したGPUをNVIDIA対抗として出せれば状況は変わるだろう。NVIDIAとAMDがDXRで並び立てば,少なくともPCと据え置き型ゲーム機はリアルタイムイトレーシングを活用したハイブリッドレンダリングへと一気に流れるはずである。
ただ,このシナリオがすぐ実現する可能性は低い。
GDC 2018の時点,6月のCOMPUTEX TAIPEI 2018においても,AMDはレイトレーシングについて「CPUとGPUのコンビネーションで対応する」というスタンスを変えておらず,DXRの対応については沈黙を守り続けているからだ。
AMDの次世代GPU「Navi」(ナヴィ,開発コードネーム)がDXRに対応することはないと見られている。となると,DXRに対応するGPUが搭載されるとしても,その次の世代だ。どんなに早く見積もっても今から2年はかかるはずである。
つまり,2019年から2020年頃に登場すると噂されている次世代PlayStationと次世代Xboxが仮に次もAMDのカスタムAPUを採用するなら,その時点における据え置き型ゲーム機のレイトレーシングアクセラレーションは望み薄ということになるわけだ。
DirectXがサポートしている以上,中長期な目線で見れば,PCとXboxのゲームグラフィックスはレイトレーシングを採用する方向で動くはずだが,どれくらい早くスタンダードになるかは,むしろ「NVIDIA以外」のGPUメーカーの動きにかかっていると言ってもいい。
まずはAMDの反応に要注目だ。そして意味深な予告映像をSIGGRAPH 2018の会期中に出したIntelの動きもチェックしておきたいところである。
 |
GeForce RTXシリーズのラインナップや現時点で判明しているスペックといった基本的な話は速報記事,「そもそもRT Coreって何?」といった技術的な側面については筆者の連載バックナンバーを参照してもらうとして,今回は,GeForce RTXシリーズについて現時点(※ドイツ時間2018年8月21日時点)で判明している情報から考察した内容を,「想定問答集」的にまとめてみることとしたい。
なお,本稿では「GeForce RTX 2080 Ti」「GeForce RTX 2080」「GeForce RTX 2070」(以下順にRTX 280 Ti,RTX 2080,RTX 2070)のスペック情報を前提として扱うので,適宜,下にまとめた表の内容をチェックしてもらえればと思う。
 |
初級編
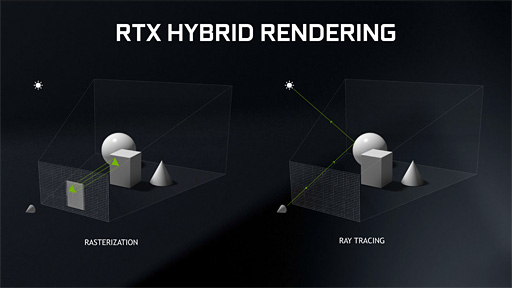
Q.1 ハイブリッドレンダリングってなに?
GeForce RTX 20の発表イベントで,NVIDIAのJensen Huang(ジェンスン・フアン)CEOは「ハイブリッドレンダリング」(Hybrid Rendering)という言葉を多用していた。
 |
ラスタライズ法というのは,「ディスプレイの画面に相当するピクセルで構成された平面にポリゴンを投射して,当該ピクセルを起点に,ライティングやシェーディングを行う」処理系のこと。描画対象となる3Dシーンのうち,画面に入らない領域や視点から見て視界外となる領域――画面より手前の領域や,視点から見て裏側の領域――はレンダリング対象から除外するという,極めて大胆な手抜きを行うことで高速に描画するのが特徴だ。
一方でレイトレーシング法は,視線から画面上の各ピクセルを通る視線の延長線上に描画対象が存在する場合,そこからレイ(Ray,光線)と呼ばれる「情報回収探査船」のようなものを射出して,画面外であろうと視界外であろうと,とにかく当該3Dシーンでレイが到達した先にある光の伝搬情報を回収して描画に反映するというものになっている(※もちろん計算予算は有限なので,レイの発射数はプロセッサの性能に応じて変わる)。
これらラスタライズとレイトレーシング,両方の手法を適材適所で使い分けるのがハイブリッドレンダリングである。
 |
では,いかにして「適材適所の振り分け」を行うかだが,
- 一般的なオブジェクトのライティングとシェーディングはラスタライズ法で
- 影生成や環境光遮蔽陰影(Ambient Occlusion,アンビエントオクルージョン),鏡面反射材質における映り込み(Reflection,リフレクション)生成,半透明材質の透過屈折特性(Refraction,リフラクション),大域照明による間接光再現(Global Illumination,グローバルイルミネーション)といった要素はレイトレーシング法で
といった形が,当面の定番レシピになりそうだ。いまレイトレーシング法に振り分けるとした要素はいずれもラスタライズ法だと一筋縄で描画できないものであり,また(計算量はともかく)レイトレーシング法だと手堅くシンプルで,かつスケーラブルな実装ができるためである。
もちろん,ハイブリッドレンダリングの中でレイトレーシングに任せる要素が多くなればなるほど,レイトレーシング法で射出されるレイの数(≒3Dシーンの中に旅立つ「情報回収探査船」の数)が多くなり,レイの存在時間(=レイの処理時間)も長くなるので,すべての「レイトレーシングに向いた要素」の描画をレイトレーシング法で行うのは,Turingアーキテクチャを採用するGPUには難しいだろう。
ただ,Turingアーキテクチャが登場していなかったGDC 2018の時点だと,「レイトレーシング法で行える要素は(先ほど列挙したレイトレーシング法に振り分けたほうがよいもののうちの)1個が限界では?」という見通しだったりした。それに対し,GeForce RTXのRT Core性能が見えてきたgamescom 2018のタイミングでは,「全部とは言わずとも,複数はいけるのではないか」という明るい未来が見えてきており,これはゲーム業界にとってよい兆候だと言える。
Q.2 RTXってなに?
2018年3月に開催されたGDC 2018の時点でNVIDIAは,同社独自の「RTX Technology」(以下,RTX)について,MicrosoftがレイトレーシングパイプラインをDirectXに統合した「DirectX Raytracing」(以下,DXR)のランタイム(Runtime,プログラムを動作させるために必要な要素)に相当するものと紹介していた。
もちろんこの説明は間違っていないのだが,今回のイベントでは,従来のラスタライズ法によるレンダリングから,レイトレーシング法によるレンダリング,CUDAによるGPGPU処理,そして「Tensor Core」による推論アクセラレーションまでを含む統合ランタイムであることが新たに判明している。
ただ,RTXはGPUドライバにかなり近い層にあるため,レイトレーシングレンダラーの開発者なら「OptiX」,ゲーム開発者はDXRや「Vulkan」を使えばいい。なので,このランタイム構造を強く意識する必要はとくにないはずだ。
 |
上で示したRTXの最上層にMDL(Material Definition Language)があるが,これは物理ベースで材質の反射特性や光源の放射特性などをプロシージャル的に記述できるものだ。
現状,MDLはゲーム用途にあまり関係なく,映画などのプロ映像制作におけるオフラインレンダリング用となっている。ゲームグラフィックスの場合,いくら物理ベースレンダリングが主流になったとはいえ,物理反射特性のメカニクスが非常にシンプルで原始的かつ簡略的なためだ。何より,グラフィックスエンジンがサポートする反射特性パラメータがまちまちで,MDLライブラリで記述された定義を再生できるレベルにはとても到達していない。
いずれ,ゲームグラフィックスレンダリングがリアルタイムレイトレーシング主体になってくればその限りではないものの,「ラスタライズ法が主体で,ワンポイントリリーフ的にレイトレーシング法も用いる」という,今後しばらくゲームグラフィックスにおいて主流となるはずのハイブリッドレンダリングにおいては,これまで同様「MDLはゲームでは無関係」という認識で構わない。
まとめると,NVIDIAは,リアルタイムレイトレーシングに対応するRT Coreを動作させ,ここにGPGPUと推論アクセラレータとしてのTensor Coreまでをグラフィックスに介入させるインターオペラビリティ(interoperability,相互互換性)を実現するにあたって,ドライバ構造を再設計する必要が生じることとなった。
そしてそこで,「これってうち特有のプラットフォームになってるっぽいから,格好いい名前を付けようぜ」ということで,「RTX」という名前になった,くらいの理解でいい。
RTXという意味ありげなキーワードではあるが,そこに深淵な技術的背景が存在していたりはしないのである。
Q.3 Turing Frameってなに?
GeForce RTX 20シリーズの発表イベントにおけるHuang氏の発言や氏の示したスライドの中には,独特すぎて難解なキーワードや,そもそも何を指し示しているのか分からない謎なキーワードが散見されたのだが,そのうちの1つが「1 Turing Frame」(テューリングフレーム)である。
1 Turing Frameが登場したのは,速報記事でも紹介したとおり下に示したスライドとなる。
これは「1フレームを描画するにあたって,Turing世代のGPUコアはどんなステップで動くのかを図示したもの」なのだが,まず注意が必要なのは,この図があくまでも事例の1つに過ぎず,必ずしもこの時間配分で処理が進むことを示すものではないということだ。簡単に言えば「適当な図」である。
 |
いちおう図解もしておくと,緑色の「Ray Tracing」というバーは,レイを生成して射出し,衝突判定を行うRT Coreが仕事をしている部分になる。「FP32 Shading」はいわゆる頂点パイプラインにおける頂点シェーダとジオメトリシェーダ,ハルシェーダ,ドメインシェーダといった各種シェーダと,ピクセルパイプラインのピクセルシェーダが仕事をしていることを表している部分だ。
念のため書いておくと,ラスタライズ法においてもレイトレーシング法においても,頂点パイプラインやピクセルパイプラインの仕事内容は変わらない。使う機能ブロックも同じだ。
「INT32 Shading」は整数演算の実動を示す部分で,画像テクスチャやマスクテクスチャを取り扱ったピクセルシェーダ処理などが主に該当する。「DNN Processing」は,Tensor Coreによってアクセラレーションされた推論エンジンでレンダリング結果に対してデノイズ(denoizing,ノイズ低減処理)やアンチエイリアシングといった各種ポストプロセス処理を行うことを示している。この点については後述したい。
Q.4 RTX-OPSってなに?
GeForce RTX 20シリーズの発表イベントでHuang氏が示した謎キーワードの頂点に君臨すると言っても過言ではないのが,「RTX-OPS」という独特な単位だ。
氏の言い分をそのまま紹介するなら,RTX-OPSは,Turing世代のGPUコアを搭載するGeForce RTXおよびQuadro RTXシリーズが1秒間にこなせる処理量を表した性能値で,GPUコア内にある浮動小数点演算器と整数演算器,RT Core,Tensor Coreの理論性能値をすべてを強引に足し合わせたものとなる。
Turingコア世代同士での性能比較は,今後RTX-OPSを使ってやってほしいというのがNVIDIAの強いメッセージで,その性能値は以下のとおりだ。
- RTX 2080 Ti:78T RTX-OPS(Tは1兆,以下同)
- RTX 2080:60T RTX-OPS
- RTX 2070:45T RTX-OPS
 |
困ってしまうのは,(速報記事でも指摘しているとおり)78や60,45といった値の根拠がまったく分からないことである。
Q3のところで出てきた1 Turing Frameのスライドには,いろいろと数値が並んでいるのだが,これらをどう四則演算しても78にはならない。
 |
というわけで,「RTX-OPSってなに?」という質問の答えは「まだ分からない」となる。このあたりは取材を進めたうえであらためて解説してみたい。
Q.5 GeForce RTXって,CUDA Core数基準で比較すると,Pascal比でどれくらい速いの?
どうしてNVIDIAは謎キーワードであるRTX-OPSを“発明”したのか。その理由については長年のGeForceファンならもう気付いているかもしれない。そう,Turing世代のGPUは,これまで長らくNVIDIAが性能指標の目安として用いてきた「CUDA Core数とブーストクロックから導く理論性能値」である「FLOPS」において,Pascal世代のGeForce GTX 10シリーズからそれほど向上していないのである。
逆に言えば「GeForce GTX 10シリーズからの大きな性能向上」はRT CoreとTensor Coreに大きく起因しているので,ここをアピールしないと,GeForce RTXの魅力が半減してしまう。
たとえば実際にGeForce RTX 20シリーズとGeForce RTX 10シリーズでCUDA Coreベースの理論性能値を比較すると,以下のとおりとなった。
- RTX 2080 Ti:13.45 TFLOPS
- GTX 1080 Ti:11.34 TFLOPS
(スコア差約19%)
- RTX 2080:10.07 TFLOPS
- GTX 1080:8.87 TFLOPS
(スコア差約14%)
- RTX 2070:7.46 TFLOPS
- GTX 1070:6.46 TFLOPS
(スコア差約15%)
確かに性能は向上している。しているが,“GeForce GTX 11”ではなくGeForce RTX 20と,シリーズ名が大きくジャンプアップしたことを考えると,FLOPS値の伸びが控えめなのは否めない。これがQ.5への回答になる。
GeForce GTX 10シリーズが採用する製造プロセス技術はTSMCの16nmなのに対し,GeForce RTX 20シリーズはTSMCの12nm(12nm FFN)なので,見かけ上,微細化は1世代進んでいるが,実のところ12nmは16nmのリファイン版にしか過ぎないため,動作クロックも面積あたりのトランジスタ積載量もそう大しては変わらない。そう考えると,CUDA Core基準の性能向上率はむしろ健闘しているほうだろう。
その点RTX-OPSなら,RT CoreとTensor Coreで得られるスコアを加味したものになるので,RTXベースのアーキテクチャを採用していないGeForce GTX 10シリーズではスコアが伸びず,GeForce RTX 20が圧倒できる。だからこそNVIDIAはRTX-OPSを導入したのだ。
 |
Q.6 Quadro RTXで「DLAA」だったのがGeForce RTXで「DLSS」になっていたのはなぜ?
Turingアーキテクチャでは,深層学習の学習データを基に推論を行うためのアクセラレータとしてTensor Coreを搭載している。
「Volta」アーキテクチャ世代のGPUでは,AIの研究開発やAIランタイムのアクセラレーション用途向けにTensor Coreを採用するわけだが(関連記事),NVIDIAは,「グラフィックス処理結果に対して『追加のお化粧や整形』を行うポストエフェクト処理を任せるのに使えるのではないか」と考え,そのままTuring世代のGPUに搭載してきたのである。
そのポストエフェクト処理について,Quadro RTXの発表時にNVIDIAは「DLAA」(Deep Learning Anti-Alising)と紹介していた。
 |
DLAAは,ノイズやエイリアシング(≒ジャギー)が散見されるレイトレーシング結果と,時間を十分にかけて描画したノイズのない描画結果との相関性を学習し,入力映像からノイズやエイリアシングを低減させるポストプロセスだ。
実際にはノイズ低減とエイリアシング低減(≒アンチエイリアシング)とで,その深層学習モデルや学習データそのものも別になるようなのだが,DLAAは,キーワードイメージ的にアンチエイリアシング処理だけでなく,ノイズ低減を行うデノイザの機能も含むような,そうでないような曖昧な言い回しによる紹介となっていた。
そんな曖昧なイメージを払拭する……というか,新造キーワードでむしろさらなる曖昧化を図ったのが,GeForce RTX発表時に出てきた「DLSS」(Deep Learning Super Sampling)である。
「ディープラーニングを活用したスーパーサンプリング」であれば「深層学習による広範囲なポストプロセス」をイメージしやすいので,確かにDLAAよりは一般ユーザーにとって受け止めやすいだろう。
 |
GeForce RTXの発表でHuang氏は,「NGX」という,深層学習ベースの映高品位化学習モデル生成フレームワークについても触れており,「これを使えば,レンダリング結果を,『Tensor Coreを活用したポストエフェクト』で高品位に変換できる」というデモまで披露していた。
 |
| NGXフレームワークを使えばあなたのゲームグラフィックスに最適なDLSSを適用できますというスライド |
 |
| イベントのプレゼンテーションでは,実際にDLSSを活用した映像再生のデモが披露された |
「レンダリング結果の高品位化をAIで行うって,ちょっと信用ならなくない!?」という印象を持つ人がいるかもしれないが,最近のテレビ製品,たとえばソニーのBRAVIAや東芝のREGZAなどはすでに深層学習ベースの超解像エンジンを搭載しており,実際に地デジ放送映像などの高画質化に応用していたりする。
その意味でDLSSは,テレビがハードウェアでやっているような高画質化処理を,Tensor Coreを活用してリアルタイムにゲームグラフィックス上で適用するものという解釈でもいいように思う。
上級編
ここからはちょっとマニアックな考察へ移ることにしよう。
Q.7 GeForce RTXってQuadro RTXとはどういう関係にあるの?
GeForce RTX 20シリーズはRTX 2080 TiとRTX 2080,RTX 2070というラインナップになっているが,イベントでHuang氏が幾度となく「Turingコア世代では」といった言い回しを使っていたことからも分かるように,GeForce RTX 20シリーズがQuadro RTXと同じアーキテクチャをベースにしたGPUであることは間違いない。
「シリコンダイレベルはどうか」というと,現時点では公開情報がないため,断言は難しい。2080型番の2製品だけがNVLinkの新世代SLIに対応するという状況証拠からすると,GTX 2080 TiとGTX 2080はQuadro RTXシリーズの最上位モデルである「Quadro RTX 8000」と同一のシリコンダイを採用している可能性はありそうだが,Quadro RTX 8000のCUDA Core数は4608基だ。RTX 2080は2944基なので,約64%しか使っていないことになってしまう。
「それほどまでにシリコンダイの歩留まりが悪い」というのも考えにくいので,RTX 2080とRTX 2070は同一のシリコンダイを採用している可能性もあると思う。
 |
 |
| RTX 2080 TiとRTX 2080では,別売りの「GeForce RTX NVLink Bridge」を利用することでNVLinkベースのSLIを利用できる |
 |
| NVIDIAは「GeForce RTXは499ドルから」というアピールを行っている |
いずれにせよ,RTX 2070搭載グラフィックスカードの499ドル(税別)からという北米市場におけるメーカー想定売価は,スペックからすると破格と言えるほどに安価であり,それはもちろん戦略的な値段設定によるものだろうが,それ以上にダイサイズが小さいことの裏付けにもなり得る。RTX 2080がどうかはさておき,RTX 2080 TiとRTX 2070が別のシリコンダイを採用しているのはまず間違いないと言っていいのではなかろうか。
Q.8 GeForce RTX 20ってどういう内部構造なの?
現在のところ,公式情報はない。
……とだけ書いて終わらせるのもアレなので,考察してみよう。Quadro RTXが発表されたとき,筆者は最上位モデルであるQuadro RTX 8000のCUDA Core数が4608基であることから,
- 6(GPC)×12(SM)×64(CUDA Core)=4608 CUDA Core
という仮の計算式を作った(関連記事)。GPCは“ミニGPU”的に機能する「Graphics Processing Cluster」のこと,SMはGPCに内包される演算ユニット「Streaming Multiprocessor」のことだ。
注意してほしいのは,この仮の計算式が正しいかどうかまだ分からない点だが,ひとまず正しいことにして話を進めよう。
RTX 2080 Tiはメモリインタフェースが352bit幅なので,384bitのQuadro RTX 8000と比べると32bit分少ない。こういう違いは以前の「GeForce GTX 1080 Ti」と「NVIDIA TITAN X」の間にもあったので,要は32bitメモリコントローラが1基無効になっているという理解でいい。
そのうえでRTX 2080 Tiの基本仕様はQuadro RTX 8000と変わっていない前提に立つと,CUDA Core数が4352基なので,12基のSMを内包したGPCが5基,8基のSMを内包したSMが1基なら,以下のとおり,計算はひとまず合う。
- 5(GPC)×12(SM)×64(CUDA Core)+1(GPC)×8(SM)×64(CUDA Core)=4352 CUDA Core
同様にRTX 2080はCUDA Core数が2944基なので,1基あたり12基のSMを内包するGPCが3基,10基のSMを内包するGPCが1基となれば,以下の計算式が成り立つ。
- 3(GPC)×12(SM)×64(CUDA Core)+1(GPC)×10(SM)×64(CUDA Core)=2944 CUDA Core
RTX 2070も同様だ。CUDA Core数が2304基なので,1基あたり9基のSMを内包するがGPCが4基構成とすれば以下のとおり計算がぴったりと合う。
- 4(GPC)×9(SM)×64(CUDA Core)=2304 CUDA Core
RTX 2070が上位2モデルとは異なるシリコンダイだとすれば,GPCあたりのSM数を減らした“GeForce RTX 2060”的な製品を派生させるのは容易だろう。
逆に,RTX 2070とRTX 2080のシリコンダイが同じなのであれば,それこそNVLinkベースのSLIに対応した“GeForce RTX 2070 Ti”的なモデルの存在も妄想できそうだ。
Q.9 RTX 2080 Tiのグラフィックスメモリ容量が11GBと中途半端な理由は?
Q.8のところで述べたとおり,RTX 2080 Tiのグラフィックスメモリインタフェースは352bitである。そして,352bitを32bitで割ると11になる。つまり,RTX 2080 Tiに接続されるGDDR6グラフィックスメモリチップは8Gbit品が11枚になるわけだ。
ちなみに,「352bitグラフィックスメモリインタフェース,グラフィックスメモリ容量11GB」という構成はGeForce GTX 1080 Tiと同じなので,別に不思議でも何でもなかったりはする。
Q.10 CUDA Core数が違うRTX 2080 TiとQuadro RTX 8000でなぜRT Coreの性能は同じなの?
RTX 2080 TiのCUDA Core数は4352基で,Quadro RTX 8000(とその下位モデルである「Quadro RTX 6000」)のCUDA Core数は4608基。なのにいずれも,リアルタイムレイトレーシングアクセラレータに相当するRT Coreの性能は「10G Rays/s」(毎秒10億レイ)で揃っている。この点を不思議に思った人は少なくないだろう。
というのも,これまでのNVIDIA製GPUは,さまざまな演算器や実行ユニットを演算ユニットとしてのSMに内包する形で実装してきたからだ。
言い換えると,CUDA採用後のNVIDIA製GPUは,SM数の多寡が性能の高い低いを決定づける仕様になってきたのである。
このルールはVoltaとTuring世代のGPUが搭載するTensor Coreでも継承している。速報記事で紹介したとおり,Huang氏がイベントで示したスライドだと,Turing世代のGPU(=RTX 2080 Ti)が持つシェーダおよび演算性能が14 TFLOPS+14 TIPS,AI推論性能が16bit浮動小数点演算で110 TFLOPSと,Quadro RTX 8000&6000の同14 TFLOPS+14 TIPS,125 TFLOPSより低いわけだが,それはひとえにSM数の違いがもたらしているわけだ。
 |
 |
ではなぜ,CUDA Core数の少ないRTX 2080 Tiで,Quadro RTX 8000&6000と同じ10G Rays/sを実現できているのかだが,少なくとも現時点では,「NVIDIA製GPUとしては極めて例外的に,RT CoreはSMに内包されていない」としか考えられない。
あらためて整理しておくと,Turing世代のGPUが持つレイ投射性能は以下のとおりである。
- Quadro RTX 8000&6000:10G Rays/s
- RTX 2080 Ti:10G Rays/s
- RTX 2080:8G Rays/s
- Quadro RTX 5000:6G Rays/s
- RTX 2070:6G Rays/s
筆者はQuadro RTXについて触れた連載バックナンバーで,Quadro RTX 8000のGPUクロックが約1.7GHzに達するという推測を行っているが,これが正しければQuadro RTX 8000とRTX 2080 Tiの間ではCUDA Core数どころかGPUコアクロックも異なるということになる。それでレイ投射性能が同じとなれば,RT CoreはSM単位,GPC単位ではなく,GPU単位の実装と考えるのが自然だ。
そしてその場合,RT CoreはGPUの動作パイプライン(≒レンダリングパイプライン)とは完全独立して非同期に並列動作するものと推測できるわけだが,確かにRT Coreのメインの役割である,レイの生成(Generation)や推進(Traverse),衝突判定(Intersection)の仕事は,生成したレイごとにライフタイム(=生成されてからお役御免となるまでの処理時間)があまりにも異なるため,見通しを立てにくい。なので,一定のリズムで工場の生産ラインよろしく結果を出力し続けるSMの動作とは相容れないものがある。
であれば,レジスタ群や作業メモリといったリソースを共有しつつ,動作自体は完全非同期で並列動作するものとして実装したとしても不思議なことではないが,さて……。
このあたりについての詳細な構造についてはNVIDIAの情報開示を待つ必要がある。
Q.11 GeForce RTX各モデルのRT Core性能はどれくらい?
Quadro RTXのスペック考察記事でも紹介したとおり,10G Rays/sの性能を持つケースだと,1920
Turing世代のGPUに対して同じ式を適用したときの計算結果は以下のとおりだ。
- Quadro RTX 8000&6000:約80レイ
- RTX 2080 Ti:約80レイ
- RTX 2080:約64レイ
- Quadro RTX 5000:約48レイ
- RTX 2070:約48レイ
前述したとおり,レイトレーシング法の活用対象になるであろう影生成や環境光遮蔽陰影,鏡面反射材質における映り込み生成,半透明材質の透過屈折特性,大域照明による間接光再現といった要素の描画には,「再帰的なレイの生成がない」(=投射して当たった先のオブジェクトでさらにレイを投射することになる事態が発生しない)としたケースでも最低1レイずつは必要だ。その意味では,RTX 2070やQuadro RTX 5000でもレイトレーシングのアクセラレーション性能は相応に期待できるのではないかと思う。
ただ,拡散反射系の材質や,大きさを持つ光源を取り扱うようなシェーディングおよびライティングでは広範囲にレイを射出する必要があるため,GPUごとにRT Coreの性能差が出てきて,描画結果や,レイトレーシング法でまかなえるグラフィックス要素に違いが出てくる可能性はある。
Q.12 Variable Rate Shadingってなに?
 |
ゲームグラフィックスでよく用いられるLoDは,視点から近い3Dモデルは多ポリゴンでできたモデルで描画し,遠い3Dモデルは少ポリゴンでできたモデルで描画するという,ジオメトリ次元のものになるが,LoDというキーワード自体は専門用語でなく,一般用語である点に注意してほしい。
可変レートシェーディングとは,いわば「適材適所で品質を調整する」LoD処理をライティングとシェーディングにも適用するという意味になる。
可変レートシェーディングの「レート」は「頻度」とか「割合」の意味だが,これは時間方向にも空間方向にも対応できる。
たとえば,空間的な可変レートシェーディングで一般的なのは視線追跡型レンダリング(Foveated Rendering,フォヴィエイティドレンダリング)法としてお馴染みだ。これは眼球が注視している箇所を高品位かつ高解像度で描き,そこから離れるに従って品質や解像度を下げていくLoD的な技法だ。
時間方向的な可変レートシェーディングは,カメラ(=視点)の動いている速度やキャラクターの移動速度(≒1フレームあたりの移動量)で描画品質や解像度をLoD制御することになる。
たとえば視点が大きく動いている場合は,画面全体がモーションブラーでボケてしまう。一方で,あるキャラクターが激しく動いた場合はそのキャラクターがモーションブラーでボケてしまう。「であれば,それらは低品質に描画しても見た目は大して変わらない」として,その部分を低品質化して負荷を下げてしまおうというわけである。
ゲームエンジンレベルでこういう仕組みを導入しているものはすでに存在するが,NVIDIAの可変レートシェーディングは,この仕組みをハードウェアでサポートするというのが新しい。
現在のところ詳細な仕組みは明らかになっていないが,イベント会場で話を聞いたNVIDIAの関係者によると,Turing世代のGPUにおける可変レートシェーディングはやはり,レイトレーシングとペアになった考え方と捉えるのが正解のようである。
つまり,高品位に描く必要がある箇所は1ピクセルあたりのレイ射出量を増やし,そうでない場合は1ピクセルあたりの射出レイ数を減らしたり,あるいはもっと大胆に,それこそ2
「複数のピクセルでライティングとシェーディングの結果を共有する」という考え方は,マルチサンプルアンチエイリアシング(Multi-Sampled Anti-Aliasing,MSAA)処理では昔からありふれた考え方として採用されているため,珍しいことではなかったりする。
時間方向にレイを射出するピクセルを巡回させ(=ジッターさせ),複数フレームかけて全ピクセルでのレイ射出を行うといった,時間方向にレイ処理を分散させて行うLoD制御もあるが,いずれにせよ,このようなライティングやシェーディング,レイ射出を時間的空間的な可変レートで行うのが可変レートシェーディングというわけだ。
その結果はそのままだと汚かったりノイジーだったりするが,その場合は前述したDLSSで品質の引き上げを行うというスタンスになる。
そもそも編
Q.13 ゲームにおけるリアルタイムレイトレーシングは標準になるの?
今回のイベントでHuang氏は,GeForce RTX 20シリーズ対応,すなわちDXRないしはRTX対応となるゲームタイトルをいくつか紹介して,そのうえで,近々対応する予定になっているタイトル計21本を挙げていた。
 |
だが,ゲーマーとして知りたいのは,今後,長期にわたってレイトレーシング法がゲームグラフィックスの主流となるのかどうかだろう。
これついて,少なくとも短期的には明るい材料を探しにくい。
 |
Huang氏はイベントで,「リアルタイムレイトレーシング対応ゲーム」の動作デモを確かに披露した。だが,少なくとも筆者が確認した限り,イベント会場の来場者が触れる状態で展示されたタイトルは,多くがE3 2018版ビルドそのものか,そうでなくともリアルタイムレイトレーシング対応前のビルドだった点は押さえておいてほしい。
 |
 |
対応を果たしていたタイトルも,影生成と環境光遮蔽陰影への対応に留まるものがほとんど。影生成は「各ピクセルから射出した複数のレイが光源に到達できた割合」に生成でき,環境光遮蔽陰影は「各ピクセルから射出した複数のレイによる局所的な遮蔽率」で生成できるが,これらはいまあるゲーム用グラフィックスエンジンの構造をほとんど弄ることなく,比較的容易に実装できるものだ。
リアルタイムレイトレーシング対応タイトルの1つである「Metro Exodus」は間接光処理にも対応していたが,これはやや実装が高度と言える。
実装の詳細は明らかになっていないものの,実際の映像を見た限り,鏡面反射材質における映り込み生成には対応していないようだったので,ラスタライズ法で得た「直接光によるライティングおよびシェーディング結果」に対して,「各ピクセルから射出した複数レイによる間接光ライティングを行う」か,「もともと非レイトレーシング向け環境用に実装してあった間接光再現用の間接光プローブに対して,レイトレーシングを行う」かした結果のようだ。
いずれにしても,もともと実装されていた「非レイトレーシング向け環境用の間接光再現メカニズム」のアクセラレーションにRT Coreを使うアプローチということになる。
 |
ここまでの対応ならば,ゲーム開発側もそれほど手間はかからない。そのため,対応を進め(てNVIDIAに宣伝してもらおうと考え)るゲーム開発スタジオもある程度は出てくるだろう。
一方,明らかに手間をかけてRT Coreに対応したと思われたのが,イベントでもかなりの時間を割いて紹介された「Battlefield V」である。
 |
BVHの詳細は筆者の連載バックナンバーを参照してほしいが,Battlefield Vでは視点から見えない領域の鏡像も再現できていたため,それこそ「接近する敵の姿を水たまりの映り込みで知る」「壁の向こうにいる敵の位置を,廊下に掛かっている鏡に映る鏡像で目測する」といった,ゲームグラフィックスがゲーム性を拡張するような表現になっていたのが印象的であった。
 |
ただ,ここまで対応してくれるゲームタイトルは,今後もそれほど多くは見込めないと思う。
その理由は,対応ハードがGeForce RTX 20シリーズのみに限られるからだ。
今日(こんにち)の人気ゲームは,PCと据え置き型ゲーム機,そしてスマートフォンやタブレットに向けてマルチプラットフォーム展開となるのがスタンダードとなっている。PCは主要なリリース先プラットフォームの1つではあるが,メインプラットフォームになることはまれだろう。
最近のPlayStation 4およびXbox One向け大作タイトルが,ほぼ間をおかずにPCでも同時発売となっているのは,(MicrosoftによるWindows 10環境整備の影響もあるが)PlayStation 4とXbox OneのアーキテクチャがほとんどPCそのものだからにほかならない。言い換えると,移植コストがほぼゼロに近いからだ。
その観点に立つと,GeForce RTX 20シリーズが持つRT Coreへの対応は,ゲーム開発スタジオにとって,どこまでも「追加の開発工程」となる。なので,Battlefield Vレベルの対応をすべてのゲームに望むのは酷だろう。Metro Exodusレベルの対応が実現できていれば御の字で,大半は影生成と環境光遮蔽陰影への対応止まりになると思われる。
なら,DXRがスタンダードになれるチャンスはないのかと言えば,そんなことはない。AMDがDXRに対応したGPUをNVIDIA対抗として出せれば状況は変わるだろう。NVIDIAとAMDがDXRで並び立てば,少なくともPCと据え置き型ゲーム機はリアルタイムイトレーシングを活用したハイブリッドレンダリングへと一気に流れるはずである。
ただ,このシナリオがすぐ実現する可能性は低い。
GDC 2018の時点,6月のCOMPUTEX TAIPEI 2018においても,AMDはレイトレーシングについて「CPUとGPUのコンビネーションで対応する」というスタンスを変えておらず,DXRの対応については沈黙を守り続けているからだ。
 |
AMDの次世代GPU「Navi」(ナヴィ,開発コードネーム)がDXRに対応することはないと見られている。となると,DXRに対応するGPUが搭載されるとしても,その次の世代だ。どんなに早く見積もっても今から2年はかかるはずである。
つまり,2019年から2020年頃に登場すると噂されている次世代PlayStationと次世代Xboxが仮に次もAMDのカスタムAPUを採用するなら,その時点における据え置き型ゲーム機のレイトレーシングアクセラレーションは望み薄ということになるわけだ。
DirectXがサポートしている以上,中長期な目線で見れば,PCとXboxのゲームグラフィックスはレイトレーシングを採用する方向で動くはずだが,どれくらい早くスタンダードになるかは,むしろ「NVIDIA以外」のGPUメーカーの動きにかかっていると言ってもいい。
まずはAMDの反応に要注目だ。そして意味深な予告映像をSIGGRAPH 2018の会期中に出したIntelの動きもチェックしておきたいところである。
- 関連タイトル:
 GeForce RTX 20,GeForce GTX 16
GeForce RTX 20,GeForce GTX 16 - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー