








イベント
空中に描かれた「触れる絵」やリアルな立体映像など,日本の研究者による展示をまとめたSIGGRAPH 2015のEmerging Technologiesレポート後編
 |
なお,仮想現実(以下,VR)やインタラクティブ技術の展示を紹介した前編を未見の人は,そちらも参照してほしい。
Fairy Lights in Femtoseconds
筑波大学,宇都宮大学,名古屋工業大学,東京大学
 |

Fairy Lightsでは,無数の光るドット(輝点)を空中に出現させて,この輝点で立体物や図形を描き出す仕組みになっている。
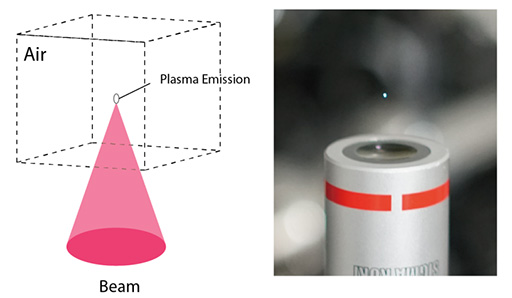
では,何もない空中にどうやって輝点を作り出すのか。用いるのはレーザーだ。レーザーは位相の揃った光を収束させたもので,遠くまで伝達しても発散しない特性を持つ光としてお馴染みだろう。
まず,虫眼鏡で日光を収束させて,紙を焦がす実験をイメージしてほしい。それと同じように,レーザーを収束光学系に通してある一点に収束させると崩壊する「レーザーブレイクダウン」(Laser Breakdown)と呼ばれる現象が起こる。レーザーのエネルギーが収束されたところにある空気分子は,たちまち電離(※イオン化,プラズマ化とも)してしまう。レーザーの照射を止めれば,空気分子は再び平常に戻って再結合するが,再結合の瞬間に光を放つ。
つまり,レーザーの照射方向とレーザーブレークダウンが発生する距離を設定できれば,任意の空間上に輝点を発生させられるはずだ。この輝点を複数空間に出現させられれば,何もない空間に「点描画」を浮かび上がらせることができるだろう。これがFairy Lightsの基本概念になる。
 |
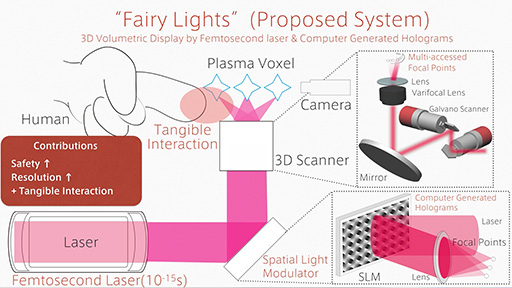
任意の空間に点を描くには,X・Y・Zでの座標指定が必要だ。X・Y座標の指定には,2組のガルバノミラー(Galvanometer Mirror)を使う。ガルバノミラーとは,電気制御で高速に首振り動作ができる小さな鏡のこと。このガルバノミラーの1つをレーザーのX軸座標指定に,もう1つめをY軸座標指定に使えば,レーザーをガルバノミラーで反射させて,任意のX・Y座標に導くことができる。
残るZ座標の指定には,電気制御で任意の焦点距離を作り出せるバリフォーカルレンズを用いる。つまり,X・Y座標指定には鏡の反射,Z座標指定は光学レンズによる焦点距離の調整により実現しているわけだ。
 |
 |
 |
 |
さて,ブースで披露されていたFairy Lightsでは,波長1045nmの269フェムト秒レーザーを使っていたそうだ。パルスレーザーのピークエネルギー強度は50マイクロジュールで,展示機で使われたフェムト秒レーザー発振器では,50マイクロジュールのレーザーパルスを毎秒20万回(=200kHz)発振できる性能を持つという。
50マイクロジュールのピークに合わせてレーザーブレイクダウンを起こさせるので,1回の発振ごとにX・Y・Zの座標を変化させるならば,毎秒20万個の輝点を作り出すことができる計算になる。つまり,毎秒20万個の画素が表現できるわけだ。そして,20万個の輝点を用いて毎秒20コマのアニメーションを表現しようとした場合,1コマあたりに使える画素数は1万個(20万輝点÷20)ということになる。
Fairy Lightsの展示システムでは,「Spatial Light Modulator」(空間光変調器,以下 SLM)を使って,単位時間あたりに表示可能な輝点の数を増やす仕組みも盛り込まれていた。SLMとは,光の位相や軌道を変えられる機能を持つ,液晶パネルのような構造の光学デバイスだ。
今回の展示システムで表現可能な3D点描画は,体積にして1×1×1cm程度と,かなり小さいものでしかない。これは,ガルバノミラーとバリフォーカルレンズの可動範囲によって決定されており,投影用の対物レンズを拡大光学系に替えれば,表示の体積を大きくすることはできるという。
では,なぜ今回はそうしなかったかというと,「表示した3D点描画を実際に手で触れるようにしたかったから」と落合氏は答えた。
 |
 |
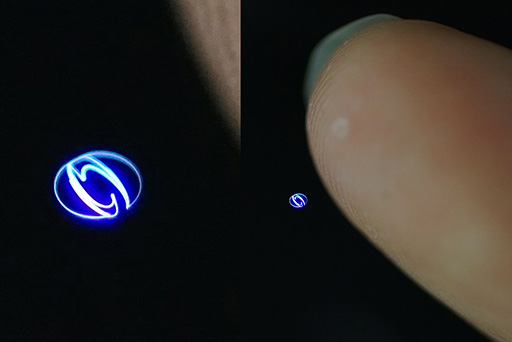
指で3D点描画に触れると,表示は別のパターンに切り替わった。空中に浮かんだ映像に触れるだけで絵が変わるというのは,いったいどんな技術を使っているのかと不思議に思うかもしれないが,実は意外とシンプルな仕組みである。3D点描画の輝点に指で触れた瞬間,絵を構成している複数の輝点が指で拡散されて強く発光するので,その発光を普通のWebカメラでとらえて,これをトリガーにグラフィックパターンを切り換えているのだそうだ。
 |
それにしても,空気分子がプラズマ化して発光しているようなところに,指を突っ込んでも大丈夫なのだろうか。ちょっと心配になって,ブースの説明員氏に聞いてみたところ,「およそ2秒間までだったら大丈夫です」と明るく答えられてしまった。説明員氏がいうには,ナノ秒レーザーだとちょっと危険だが,フェムト秒レーザーによるレーザーブレイクダウンは,超々一瞬なので,皮膚が焼けるとしても数百μm焦げる程度であるらしい(笑)。実際に筆者も触ってみたが,痛くも痒くもなかった。
 |
さて,このFairy Lightsの仕組み・原理自体は,日本の企業であるBurton(関連リンク)が開発した「Aerial 3D Display」に近い。Aerial 3D Displayは,2010年5月に日本科学未来館で開催された「予感研究所展」で展示されたので,見たことがある人もいるかもしれない。今回のFairy Lightsは,Aerial 3D Displayに独自の改良や工夫を加えたもの,といえようか。
たとえば,Aerial 3D Displayではナノ秒レーザーを採用していたが,Fairy Lightsではフェムト秒レーザーとなっているし,SLMを光学システムに組み合わせた要素も,Fairy Lights独自の工夫だ。それにより,点描画を構成する1秒あたりの輝点数も,Aerial 3D Displayでは1000点程度だったのが,Fairy Lightsでは20万点にまで増えている。スペック的には大きな違いといえよう。
Pixie Dust Technologiesという会社を起業をした落合氏は,今後も独自アイデアで実現した科学の不思議な魅力を見せてくれそうだ。
MidAir Touch Display&Haptoclone
東京大学,慶應大学
東京大学と慶應大学の研究グループは,Fairy Lightsとは異なるアプローチの空中結像ディスプレイ「MidAir Touch Display」を披露していた。
MidAir Touch Displayの映像は,Fairy Lightsのような点描ではなく,液晶ディスプレイに表示されるような映像を,空中に浮かび上がらせているのだ。
 |
先に種明かしをしてしまうと,MidAir Touch Displayは,液晶パネルの映像を特殊な光学デバイスを用いて空中に浮かび上がらせている。Fairy Lightsでは,実体を持つ輝点を空中に出現させていたが,MidAir Touch Displayは,虚像を空中に投影しているのである。
虚像を空中に投影する仕組みは,日本の企業であるアスカネット(関連リンク)が開発した,「Aerial Imaging Plate」(以下,AI plate)という特殊な光学デバイスを活用することで,実現されたものだ。AI plateを使った空中結像ディスプレイは,4Gamerでも一度紹介したことがあるので,名前を覚えている人もいるかもしれない。ちょっと横道にそれるが,AI plateの仕組みをなるべく簡単に説明しておこう。
このAI plateは,2枚の平板光学素子を貼り合わせた構造をしている。そして平面光学素子は,両面が鏡となった厚さ数μmのガラス板を大量に並べて,上と下で直交するように貼り合わせた構造をしているという。
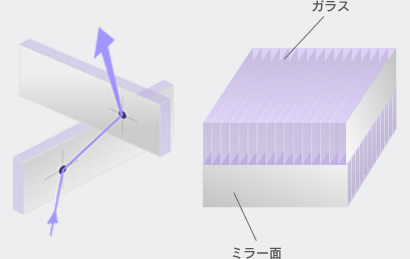 |
普通の鏡は,光を入れると入射角度と同じ角度で反射する。一方,光を当てると明るく反射して見える道路標識や看板などで使われている「再帰性反射材」は,入射した光が同じ方向と角度で戻るように反射する特性を持つ。しかし,AI plateはこれらと異なり,入射した光がAI plateの裏側に向かって,同じ角度で突き抜けるように進むのだ。
こうした光学特性により,AI plateの近くに物を置いたり,あるいは液晶パネルを配置したりすると,線対称の位置にその虚像を表示できるのである。
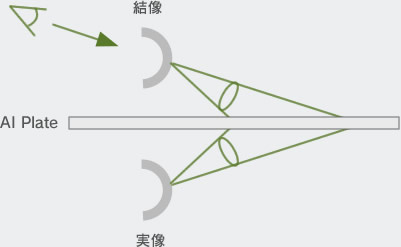 |
空中結像する映像は,AI plateを挟んで液晶パネルと線対称の位置に出現するので,この位置から大きくずれてしまうと見えなくなってしまう。実体の映像が浮いているわけではなく,あくまで特殊な光学デバイスによって虚像を見せているので,これは仕方ない。しかし,既存の液晶パネルとAI plateを組み合わせるだけで,空中に映像を浮かべられるというのは,シンプルでシステムを構成しやすいメリットがある。
また,AI plateは,それほど高価なものではないそうなので,映像の空中結像を比較的容易に実現する手段として,幅広い応用が期待されているそうだ。MidAir Touch Displayは,そんなAI plateのユニークかつ効果的な応用事例といえるだろう。
話を本題に戻そう。MidAir Touch Displayの映像は,液晶パネルの映像をAI plateによって空中に結像した虚像なのだが,この映像に触れるというところが大きな特徴だ。筆者も触ってみたのだが,空中に浮かんだ虚像であるにもかかわらず,触ると画面に触れたような感触があり,画面上に表示されているアイコンをドラッグすることもできた。
 |
なんとも不思議な空中触覚を実現しているのは,超音波のビームであるという。
MidAir Touch Displayの内側上面には,超音波ビーム発生ユニットを横18×縦14基のマトリックス状に並べた「超音波収束装置」が備え付けられている。虚像に触れる指の動きは,赤外線センサーを使ったモーションコントローラの「Leap Motion Controller」を内部に設置して読み取っており,指が触れた座標を識別して,そこに超音波のビームを飛ばし,力場を発生させているわけだ。
この超音波収束装置によって発生できる力場の強さは,1cm2あたり10g程度で,力場を発生させる座標の誤差は1mm以下と,かなり正確にビームを照射できる。
指が空中にあるにもかかわらず,宙に浮いたアイコンをドラッグ操作すると,その指を連続的に押し上げるような感触を感じるのだから面白い。「触れる虚像」というのはなんとも不思議なものである。
MidAir Touch Display公式動画 from ACM SIGGRAPH on Vimeo.
このMidAir Touch Display技術を応用したもう1つの展示が,「Haptoclone」だ(関連リンク)。Haptocloneとは,触覚(Hapto)を複製(Clone)するという意味とのこと。
 |
MidAir Touch Displayでは,液晶パネルを映像の表示装置に使っていたわけだが,Haptocloneは映像ではなく,人間の手や紙風船といった実体物を使う点が大きな違いだ。とはいっても,原理的にはMidAir Touch Displayと同じようなもので,AI plateを使って虚像を作っている点は変わらない。ただ,Haptocloneでは,2人の体験者を横に並べたシステムになっているため,AI plateを2枚使用した構成になっている。
下に掲載した図にあるとおり,左のA側においた手や物体は,2枚のAI plateを経由して右のC側に虚像として出現する仕組みだ。
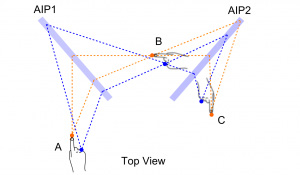 |
AI plateの前,ちょうど虚像が出現する場所の上下左右には,MidAir Touch Displayでも使われた超音波収束装置が取り付けられている。Haptocloneで,4方向に超音波収束装置を配置しているのは,上下左右から立体的な力場を出現させるためだ。
 |
さて,このシステムで,片方の装置Aに紙風船を置くと,もう一方の装置Bには,紙風船の虚像が出現する。それと同時に装置A側では,Haptoclone内部に仕込まれた第2世代のKinectセンサー(以下,Kinect)が紙風船を検知して,それが装置内の空間をどのように遮蔽しているかをHaptocloneのシステム――披露はされなかったが,おそらく普通のPCだろう――に伝えることで,Haptocloneは空間内に置かれた物体の形状を立体的に把握できるのだ。
 |

 |
さらに,ここから虚像を見ている側の体験者が手を強く動かしてみると,その動きもKinectで取得されて,実体の紙風船が置かれている側の超音波収束装置を駆動させ,実体の紙風船を動かすことができる。
つまり,実体側の体験者と虚像側の体験者は,Haptocloneを介して紙風船の弾き合えるのだ。超音波収束装置の力場がそれほど強くないので,虚像を見ている側から,実体物をしっかりとつかむようなことはできないのだが,握手の真似事程度は可能とのこと。
 |
担当者によれば,この技術を発展させて,うまく活用すれば,遠く離れた人同士が触れあったりすることのできる,存在感(Existence)を伝送する「Telexistence」(テレイグジスタンス,遠隔臨場感とも)の実現を可能にできるかもしれないとのことだった。今後の発展に期待したい。
An Automultiscopic Projector Array for Interactive Digital Humans
南カリフォルニア大学,長野光希氏ほか
SIGGRAPH 2013で南カリフォルニア大学の長野光希氏らによる研究グループは,顔の表示に最適化した立体視ディスプレイ「An Autostereoscopic Projector Array Optimized for 3D Facial Display」を発表したことがある。その研究グループがSIGGRAPH 2015で,さらに完成度を高めてインタラクティブ性も取り入れた,改良型の立体視ディスプレイ「An Automultiscopic Projector Array for Interactive Digital Humans」(以下,Automultiscopic Projector Array)を展示していた。
このプロジェクトは,映画監督のスティーブン・スピルバーグ氏などからの提案で始まったプロジェクトだという。究極の目標は,「対話できる立体映像によるデジタル人間の開発」とのこと。今回展示されたシステムは,さすがにその域までは達していないが,イリノイ州にあるHolocaust Museum&Education Center(ホロコースト博物館)の展示物とすることを目指して開発されているそうだ。
知っている人も多いとは思うが,ここでいうホロコーストとは,第2次世界大戦時にナチス・ドイツの支配地域で行われた,ユダヤ人に対する大量殺戮のこと。終戦後70年が経った今日(こんにち)では,当時迫害を受けていた生存者達も,80歳以上の高齢となっている。そこで,過酷な時代の記憶や体験談を後世へと伝えるために,デジタルアーカイブしていこうというのが,この研究が始まる動機となっているそうだ。
しかも,デジタルアーカイブ化するにあたり,インタビュー音声を録音して残すだけでなく,その語り手達の姿や表情,身振りまで記録してしまおうというのが,大きな特徴となっている。
今回のプロジェクトでは,ホロコースト生存者のPinchas Gutter氏が協力しており,計30時間に及ぶインタビューが実施された。インタビューの様子は,パナソニック製ビデオカメラ「X900MK」30台を,Gutter氏の正面180度を取り囲むように設置して,フルHD解像度の60fpsで撮影されたという。180度を30台で割ると6度になるので,つまり,Gutter氏を6度の視差で30台同時に撮影したことになる。
 |
この視差6度,30台の視点による映像を,コンピュータで約10倍の細かさとなる0.625度単位の視差を持った216視点の映像へと変換。そのうえで,Gutter氏の話に応じて,エピソード単位のファイルに分割して保存したそうだ。ビデオクリップの総数は約2000にも及んだそうである。
プロジェクトはその後,インタラクション技術開発部門と映像技術開発部門の2チームに分かれて,開発が進めているという。
まず,インタラクション技術開発部門は,南カリフォルニア大学で機械学習分野を研究する研究室が担当。この研究室が持つ自然言語エンジンを使い,出された質問に対して,その答えとなるビデオクリップを2000ファイルの中からを検索して,再生するという仕組みを構築した。たとえば,博物館の来場者が「ホロコースト時代に一番つらかったことはなんですか?」と質問すると,この答えに該当するか,あるいは答えに近い内容が話されているビデオクリップを2000ファイルの中から検索するのだ。
音声入力をテキストデータへ変換する仕組みには,Googleが提供しているスピーチ・テキスト変換システム「Google Speech API」を利用しているとのこと。
さらに,キーワードそのものによる検索だけではなく,投げかけられた質問の意味を解釈して,回答に当る情報を返す,機械学習型AIの開発も進められている。2011年にアメリカのクイズ番組に出場し,人間のクイズチャンピオン二人に勝利したIBMの機械学習型AI「Watson」(関連リンク)のような技術を,このプロジェクトでも応用しているとのことだった。
一方,映像技術開発部門を担当したのが,長野氏らの研究グループだ。 前述したように,演算により生成された0.625度単位のビデオ映像を使って,Gutter氏の姿を立体映像として再現するのだが,その原理は,SIGGRAPH 2013で展示されたものとほぼ同じであった。ただし,立体映像の品質は各段に向上しているという。
0.625度単位で216視点分の映像を投影するために,216基のLED光源プロジェクタを円弧状に並べて表示システムは構成されている。使用されたLED光源プロジェクタは,SIGGRAPH 2013で使ったものよりも各段にスペックアップしたVivitek製の「QUMI V3」で,解像度は1280×800ドットであるという。
QUMI V3が選ばれた理由は,プロジェクタの厚みが薄いためだそうだ。0.625度単位の視差を実現するために,216基のプロジェクタを円弧状に並べるには,厚みが薄いほどいい。そうした理由で216基のQUMI V3が用意されたわけだが,それでもこれを円弧状に並べると,円弧の半径は3.4mにもなるそうだ。
 |
216視点から投影されたプロジェクタの映像は,高さ2mのLuiminit製特殊スクリーンに映し出される。この特殊スクリーンは,垂直方向には60度という広い角度で映像を拡散するが,水平方向にはわずか1度しか拡散しないという特性を持つそうだ。
 |
 |
水平方向に1度ずれると,線対称の位置にあったプロジェクタの映像はその視点から見えなくなる。この「水平方向1度しか見えない」特性が,視差マスク型裸眼立体視ディスプレイにおける視差マスクの役割を果たしているのだ。これにより,任意の視点から見たGutter氏の映像が,約1度の視差分解能を持った立体映像に見えるのである。
 |
さて,ここまでの説明を聞いて,「事前生成した映像が視差0.625度なのに,スクリーンの水平拡散角が1度と,少し大きいのはなぜだ?」と疑問を持った人はいるだろうか。これは,裸眼立体像が離散的な見映えになるのを軽減させているためだ。スクリーン面で映像をやや大きめに拡散させることにより,隣り合った0.625度視差の映像同士を少しオーバーラップさせているのである。
 |
 |
 |
さて,この216台のプロジェクタに映像を出力しているシステムは,Radeon HD 7870カード2枚を搭載したPCを6台使用しているという。PC 1台で12画面を出力するので計72画面分,これにMatrox製のマルチディスプレイアダプタ「TripleHead-to-Go DisplayPort Edition」を組み合わせることで,1画面分の出力を3台のプロジェクタで分割出力させるように工夫しているのだ。
Radeon HD 7870からは,1画面あたり3840×800ドットで映像を出力し,これをTripleHead-to-Go DisplayPort Editionで1280×800ドット×3に分割する。そうすると,12×6×3で216台分の表示が可能という理屈だ。

SIGGRAPH 2013での展示は,静止した頭部だけのデモだったが,今回のデモは全身を表示しているだけでなく,表情の変化や身振り手振りまで再現できているので,技術の進化には目を見張る思いだった。生きたGutter氏が,目の前でこちらに語りかけてきているようにしか見えない。

ただ,注意深く映像を観察していると,顔を大きく動かしたときには,首筋にブレが生じたり,身振り手振りの指先がくっついて見えたりするような瞬間もあった。長野氏に聞いてみると,これは視差6度の録画映像から,視差0.625度の映像を演算で合成するときに生じるエラー(ノイズ)であるとのこと。30台のカメラで前面180度を撮影はしているとはいえ,どのカメラからも撮影されていない遮蔽部分が生じることは避けられない。こうした遮蔽部分は,映像を演算で合成したときに穴になってしまうので,隣接する周囲のピクセル色から類推して,穴を埋めていくことになる。このときの類推に誤差があると,それが時間方向のブレとして露呈してしまうそうだ。
筆者から見れば,こうしたブレも,SF映画に出てくるホログラムっぽい味わいがあっていいと思うのだが,長野氏は笑って,「直せと上司からいわれていますので」と答えていた。アップデートされた映像を体験してみたいものだ。
Deformation Lamps
NTTコミュニケーション科学基礎研究所
ETのNTTコミュニケーション科学基礎研究所のブースでは,ちょっと変わった映像が展示されていた。人物の表情がうねうねといった感じで変化したり,水面を進む船が波をかき分けたりするように見えるのだが,これが何なのか,すぐには思いつかない。
 |
プロジェクタが置いてあるので,「何かのプロジェクションマッピングかな」としばらくデモを見続けていたところ,説明員が映像の前に白い紙を突きだした。すると,紙にはカラー映像が映っておらず,代わりに波紋のような薄い陰影模様が動いている映像が映っていた。紙を外すと,元の動く映像に戻るのだが,どう見ても,カラー映像が動いているようにしか見えない。これはいったいどういう仕組みなのだろうか。

「Deformation Lamps」と呼ばれるこの研究プロジェクトのリーダーを務めるNTTコミュニケーション科学基礎研究所上席特別研究員,西田眞也氏に種明かしをしてもらったところ,この現象は,人間の視覚メカニズムを逆手にとった錯覚なのだという。
人間の視覚メカニズムや心理物理学(※精神物理学とも)を長年研究してきた西田氏によれば,人間の視覚は,色と輝度を別々に知覚しており,白黒映像に相当する「輝度分布」を優先的に知覚して,色差信号に当たる「色分布」は,脳内で合成することで知覚していることが分かっているのだという。つまり,輝度と色がずれた視覚情報が目に飛び込んできても,脳が適当に都合よく知覚してしまうのだ。
この知覚現象を逆手にとって,静止している絵や立体物といったオブジェクトに対して,任意の動きを付けた白黒映像を生成して投影すると,そのオブジェクトが動いているように錯覚させられるのではないか。そう考えて制作されたのが,Deformation Lampsなのだ。ちなみに,日本語では「変幻灯」(関連リンク)と呼ばれているそうだ。
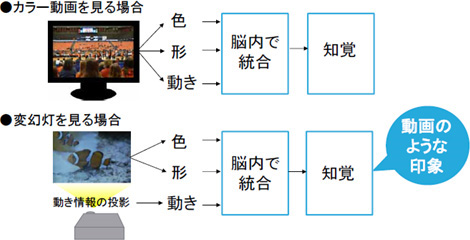 |
 |
オブジェクトに任意の動きを付けるには,まず,初期状態となる対象物の白黒映像を,カメラで撮影しておく。この白黒映像に対して,付けたい動きに応じた変形を施す。しかし,「変形させた動き付き白黒映像」をオブジェクトにそのまま投影しても,初期状態のオブジェクトが持つ輝度分布を消し去らないと,動いているようには見えない。
そこで,投影したい動き付き白黒映像に対して,初期状態の輝度分布で差分の映像を作りだし,それをプロジェクタで対象オブジェクトに投影する。これを1コマごとに実行すれば,対象オブジェクトが動いているかのように見えるのである。
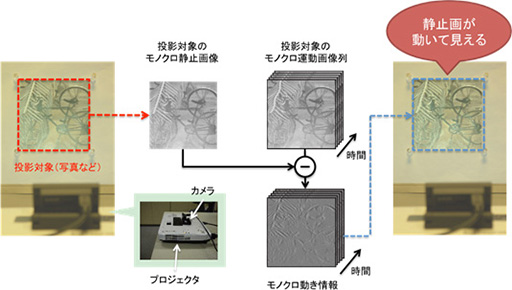 |

錯覚を利用した映像なので,あまり大きな動きを与えると,色と輝度が分離していることが知覚されてしまうため,動かせる量には限度があるそうだ。西田氏によれば「回転角度にして0.2〜0.3度くらいがひとつの目安となる」とのこと。また,この錯覚効果は,近くで見たときと遠くから見たときでも見え方が異なるそうで,厳密にはケースバイケースであるそうだ。
ちなみに,今回展示されていたデモでは,絵本の船が動くデモや,バッハの顔が表情を変えるデモは,比較的大きな動きを付けている事例とのことだった。
この技術のポイントは,原理自体がシンプルで,動かしたい対象物を一切加工しないで済むところにある。普段は止まっているオブジェクトが突然動き出したように見せられれば,かなり人目を惹くし,驚きを与えられるだろう。デジタルサイネージ分野やアート,そしてエンターテインメント分野への応用など,多方面への展開が期待できそうに思う。既存のプロジェクションマッピング技術に応用することで,その表現幅を拡張することにもつながるに違いない。
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー