




![[SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/001.gif)








ニュース
[SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露
SIGGRAPH 2014で開かれた展示会「Exhibition」(以下,一般展示セクション)のレポート2回めでは,NVIDIAとIntel,AMDの話題をお届けしよう。
まずはNVIDIAブースから。ブース入口に高級電気自動車で名高いTesla Motorsのセダン「Tesla Model S」を置いて,車載用組み込み機器への注力をアピールしていたり,組み込み機器向け開発キット「Jetson TK1」を展示していたりするなど,別種の展示会にでも迷い込んだかのような錯覚を覚えそうになる。とはいえ,ブースの中を進むと,
グラフィックス関連の展示でとくに目を引いたのが,ゲーム開発者向けフレームワーク「GameWorks」(関連記事)に含まれるリアルタイム大局照明技術ライブラリ「GI Works」の最新版を使ったデモである。まずはデモの動画を見てほしい。

GameWorksとは,2013年10月にNVIDIAが発表したゲーム開発者に向けた開発技術支援の枠組みだ。実体としてはライブラリ集のような形態で提供されるようで,ゲーム全体の面倒を見るゲームエンジンよりも小規模な,ミドルウェアに近いものといったほうが分かりやすいかもしれない。
GI WorksはGameWorksに含まれるコンポーネントのひとつで,主に間接照明や大局照明を司るものだ。2013年のGameWorks発表時に,GI Worksの存在も明らかになっていたのだが,詳しい説明は行われなかった。技術的詳細が明らかにされ始めたのは,2014年3月開催のGTC 2014からで,今回のSIGGRAPH 2014では情報がアップデートされたわけだ。
NVIDIAが過去に発表した大局照明技術には,「Sparse Voxel Octree-Global Illumination」(以下,SVO-GI法)と呼ばれるものがある。これはEpic Gamesの「Unreal Engine 4」(以下,UE4)に採用されたことで話題を呼んだ技術だ(関連記事)。ところがその後,これをゲームグラフィックスで採用するには,PlayStation 4(以下,PS4)やXbox One世代でもGPUの処理性能が不足していると判明。現在のUE4では,事実上のお蔵入りとなってしまった。
詳細は2012年8月掲載の解説記事を参照してほしいが,SVO-GI法では,シーンを八分木(Octree)構造に分割した階層型のボクセルデータ※1にするという,処理負荷の大きなプロセスが必要だった。そのうえ,分割後にデータ参照するときにも,各ノード(結節点)をポインタでたどるプロセスが必要というわけで,
※1 3D空間における単位となる立方体のこと。2D平面における画素がピクセル(Pixel)であるのに対して,その立体版とイメージすれば分かりやすい。
それに対して,NVIDIAがGI Worksに採用した「リアルタイム大局照明技術」(Real time Global Illumination)とは,SVO-GI法をベースに軽量化と簡略化を施したものだ。
たとえば,GI Worksでは八分木構造化をあきらめて,3Dテクスチャ(テクスチャ配列)で表される単純な構造に改めた。SVO-GI法は,シーンにおける3Dオブジェクトの密度に応じて正確にボクセル化するものだが,GI Worksでは,使えるメモリ量に応じて決めた適当な固定解像度でボクセル化してしまうのだという。だがこの仕組みでは,広いシーンの場合は対応できなくなりそうだ。そこで導入されたのが,「CLIPMAP」という新しい概念である。
256×256×256テクセルの3Dテクスチャを3セット用意して,シーンをボクセル化するケースで考えてみよう。まず1つめのセットでは,近景のシーンだけをボクセル化する。ここはそれなりに高解像度でのボクセル化が可能だ。
一方,2つめのセットでは,同じ256×256×256テクセルの3Dテクスチャで,1つめよりも遠くまでのシーンをボクセル化する。3Dテクスチャの解像度を変えていないのに広範囲までボクセル化するということは,第1セットよりもボクセル化の解像度が粗くなるわけだ。3つめのセットでは,同じ3Dテクスチャサイズでさらに遠景までをボクセル化する。
CLIPMAPの手法は,言ってみれば「ボクセル化のLOD(Level of Detail)」といったところだろうか。
実際にボクセル化をするときには,
さて,ボクセル化したシーンをレンダリングするときは,SVO-GI法でも使われる「Voxel Cone Tracing」(ボクセルコーントレーシング。以下,VCT)という手法で計算を行う。VCTの詳細はSVO-GI法の解説記事を見てほしいが,ここでも軽く説明しておこう。
簡単に言えば,VCTとは簡易的なレイトレーシングのことだ。通常のレイトレーシングでは,視点から飛ばしたレイ(光線)を,レンダリング対象ピクセルで求める品質に応じた本数のレイに1本ずつ分散させて,描画するシーンを探索しつつライティング結果を集める。これに対してVCTでは,あるまとまった束(たば)のレイを放つ。束になったレイは円錐(Cone)形状になるので,Cone Tracingと呼ばれるわけだ。
SVO-GI法でVCTを利用する場合,八分木化されたシーンのライティング結果を集めるためには,八分木データ構造を順に辿る必要がある。しかし,GI WorksでのVCTならば,階層構造化された3Dテクスチャ(=CLIPMAP)に対するテクスチャサンプリングをLODに配慮して行うだけで済む。これなら普通のテクスチャアクセスと実質的に変わらない。SVO-GI法よりVCTの計算もシンプルになるので,高速に処理できるというわけである。
能書きはともかく,実際の処理速度はどうなるのだろうか。説明員に聞いたところ,サンプルデモの場合,「GeForce GTX 770」でGI処理に要する時間は7.4
メモリ使用量も確認してみたところ,64×64×64テクセルで1ボクセル当たり16byte,3LODに相当するCLIPMAPが12MB程度。256×256×256テクセルで1ボクセル当たり32byte,5LODに相当するCLIPMAPになると,2.5GB程度だという。


GI Worksを用いれば,SVO-GI法よりも計算量,メモリ使用量ともに軽い負荷でリアルタイム大局照明を実現できるとのこと。今後のゲームエンジンで利用されることを期待したい。
開発者向けの難しい話の次は,少し軽めの話題にいこう。Intelも一般展示セクションでは常連となっているのだが,今年の目玉は,「Haswell」こと第4世代Coreプロセッサの統合型グラフィックス機能(以下,統合型GPU)向けに開発が進められている,DirectX 12対応グラフィックスドライバのプロトタイプが公開されたことだ。
そのデモは,5万個の隕石が流れる宇宙空間を描いたもので,デモ画面の右下に,CPU全体の消費電力を水色で,統合型GPUの消費電力を赤色で示したグラフが表示されている。
テストモードは2種類用意されていた。1つめは,シンプルなフレームレート比較テストで,DirectX 11対応ドライバとDirectX 12対応ドライバで,5万個の隕石を描画するときのフレームレートを比較するというものだ。DirectX 11では20fps程度なのに対して,DirectX 12では30fps程度にまで向上していた。約1.5倍の性能向上に当たる。
このデモのポイントは,どちらのモードでもCPU全体の消費電力は変わらないことだと,デモの担当者は述べる。同一の消費電力であるならば,DirectX 12のほうがCPUコア側の負荷を減らせるので,統合型GPUがより多くの電力を使える余地が生まれ,結果としてグラフィックス性能を向上させられるということを示しているというわけだ。
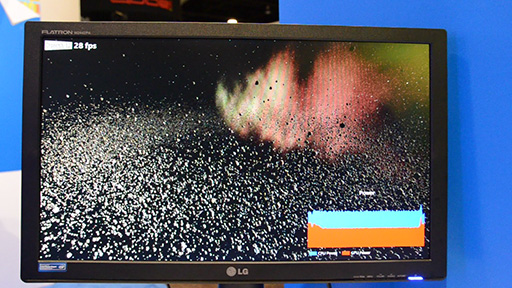
2つめのテストモードは,フレームレートを15fpsに固定した状態で,消費電力の変化を見るというもの。
デモを見てみると,統合型GPUの消費電力は,DirectX 11モードとDirectX 12モードで変化がない。しかし,CPU全体の消費電力はDirectX 12モードのほうが低くなるのが見てとれた。動画も掲載しておくので見てほしい。
つまり,同じGPUであってもDirectX 12のほうがCPU側のオーバーヘッドを押さえて動作できるうえ,統合型GPUに渡すコマンドの作成をマルチスレッドで行いやすくなるために,こうした効果が得られているのだと,担当者氏は説明していた。
Intelの統合型GPUが,絶対的な性能でAMDやNVIDIAのGPUにかなわないことを,Intelもよく理解している。しかし,すべてのPCユーザーが高性能なGPUを必要とするわけでもない。「求める性能水準に対して,DirectX 12ならばこれだけ電力効率がいい」というIntelのアピールは,DirectX 12の新しい価値を見出してくれたともいえなくもない。その意味では,実に「Intelらしいデモ」だったといえる。
NVIDIAが提供するGPGPU向け開発環境「CUDA」は,GPGPUを利用するさまざまな業界で広く受け入れられている。一方,AMDはGPGPU向けの環境として,規格化団体であるKh
AMDは,そうした遅れを挽回するための第一歩として,SIGGRAPH 2014に合わせてOpenCLベースのレイトレーシングエンジン「Fire Render」(仮称)を発表した。本稿で用いている名称は仮称だそうで,正式版では名前が変更になる可能性もあるらしい。
Fire Renderは,GCN世代のRadeonやFi
OptiXに対抗するFire Renderがターゲットユーザーに狙うのは,ゲームグラフィックスのようなリアルタイムレンダリング用途ではなく,映画用のCG制作やそれに関連した照明設計といった用途にレイトレーシングを利用するユーザーだという。
現在は,Autodesk製の3Dツール「Autodesk Maya」(以下,Maya)用のプラグインが提供されている。材質(マテリアル)を表現するためのシェーダー設計には,Fire Render専用のツールを使う必要があるが,それ以外ならMayaの機能を使ってシーンを制作して,レンダリング結果を得られるという。
AMDブースで披露されたデモは,CPUに「Xeon E5-2697 v2」(12C24T,動作クロック2.7GHz)を2基搭載し,「FirePro W8100」を4基搭載したマシンが使用された。原田氏によれば,FirePro W8100×1基でXeon×2基の10倍ほど高速なレンダリングが可能なため,4基のGPUでは40倍ものパフォーマンスが得られるのだという。
数百万ポリゴンのシーンで間接照明を1バウンスに限定すると,約20msでレンダリングが完了するそうだ。単純計算では50fps相当にもなり,とてつもなく速いことが分かる。FireProシリーズ最上位モデルである「FirePro W9100」を使えば,処理性能はさらに25%程度向上するそうだ。
Fire Renderは今後,Solid Angleのレイトレーシングレンダラ「Arnold Renderer」への採用が決定しているとのこと。ちなみに,Arnold Renderは,Electronic Theaterレポートでも触れたSF映画「ゼロ・グラビティ」に採用された実績がある。採用事例の広がりに期待したい。
AMDとしては,Fire Renderを有償化する予定はないそうで,あくまでもAMD製GPUの販売促進用ソリューションに位置づけられている。レイトレーシング向けの実用的なソフトウェアライブラリとして提供するプランもあるとのこと。ゲームグラフィックス用途なら,既存のラスタライズによるレンダリングと局所的なレイトレーシングを組み合わせる次世代技術,「ハイブリッドレンダリング」システムへの応用が期待できるかもしれない。
ところで,Fire RenderはOpenCLで書かれているので,勘の良い人なら,「Op
AMD GPUとNVIDIA GPUのどちらが速いか,最終版が提供されてたら検証してみると面白そうである。
NVIDIAはゲーム開発向けグラフィックスライブラリ「GI Works」の最新デモを披露
![画像ギャラリー No.002のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/002.jpg) |
グラフィックス関連の展示でとくに目を引いたのが,ゲーム開発者向けフレームワーク「GameWorks」(関連記事)に含まれるリアルタイム大局照明技術ライブラリ「GI Works」の最新版を使ったデモである。まずはデモの動画を見てほしい。
![画像ギャラリー No.003のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/003.jpg) |
GI WorksはGameWorksに含まれるコンポーネントのひとつで,主に間接照明や大局照明を司るものだ。2013年のGameWorks発表時に,GI Worksの存在も明らかになっていたのだが,詳しい説明は行われなかった。技術的詳細が明らかにされ始めたのは,2014年3月開催のGTC 2014からで,今回のSIGGRAPH 2014では情報がアップデートされたわけだ。
NVIDIAが過去に発表した大局照明技術には,「Sparse Voxel Octree-Global Illumination」(以下,SVO-GI法)と呼ばれるものがある。これはEpic Gamesの「Unreal Engine 4」(以下,UE4)に採用されたことで話題を呼んだ技術だ(関連記事)。ところがその後,これをゲームグラフィックスで採用するには,PlayStation 4(以下,PS4)やXbox One世代でもGPUの処理性能が不足していると判明。現在のUE4では,事実上のお蔵入りとなってしまった。
詳細は2012年8月掲載の解説記事を参照してほしいが,SVO-GI法では,シーンを八分木(Octree)構造に分割した階層型のボクセルデータ※1にするという,処理負荷の大きなプロセスが必要だった。そのうえ,分割後にデータ参照するときにも,各ノード(結節点)をポインタでたどるプロセスが必要というわけで,
※1 3D空間における単位となる立方体のこと。2D平面における画素がピクセル(Pixel)であるのに対して,その立体版とイメージすれば分かりやすい。
![画像ギャラリー No.005のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/005.jpg) |
それに対して,NVIDIAがGI Worksに採用した「リアルタイム大局照明技術」(Real time Global Illumination)とは,SVO-GI法をベースに軽量化と簡略化を施したものだ。
たとえば,GI Worksでは八分木構造化をあきらめて,3Dテクスチャ(テクスチャ配列)で表される単純な構造に改めた。SVO-GI法は,シーンにおける3Dオブジェクトの密度に応じて正確にボクセル化するものだが,GI Worksでは,使えるメモリ量に応じて決めた適当な固定解像度でボクセル化してしまうのだという。だがこの仕組みでは,広いシーンの場合は対応できなくなりそうだ。そこで導入されたのが,「CLIPMAP」という新しい概念である。
256×256×256テクセルの3Dテクスチャを3セット用意して,シーンをボクセル化するケースで考えてみよう。まず1つめのセットでは,近景のシーンだけをボクセル化する。ここはそれなりに高解像度でのボクセル化が可能だ。
一方,2つめのセットでは,同じ256×256×256テクセルの3Dテクスチャで,1つめよりも遠くまでのシーンをボクセル化する。3Dテクスチャの解像度を変えていないのに広範囲までボクセル化するということは,第1セットよりもボクセル化の解像度が粗くなるわけだ。3つめのセットでは,同じ3Dテクスチャサイズでさらに遠景までをボクセル化する。
CLIPMAPの手法は,言ってみれば「ボクセル化のLOD(Level of Detail)」といったところだろうか。
![画像ギャラリー No.006のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/006.jpg) |
![画像ギャラリー No.017のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/017.jpg) |
![画像ギャラリー No.018のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/018.jpg) |
![画像ギャラリー No.007のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/007.jpg) |
さて,ボクセル化したシーンをレンダリングするときは,SVO-GI法でも使われる「Voxel Cone Tracing」(ボクセルコーントレーシング。以下,VCT)という手法で計算を行う。VCTの詳細はSVO-GI法の解説記事を見てほしいが,ここでも軽く説明しておこう。
簡単に言えば,VCTとは簡易的なレイトレーシングのことだ。通常のレイトレーシングでは,視点から飛ばしたレイ(光線)を,レンダリング対象ピクセルで求める品質に応じた本数のレイに1本ずつ分散させて,描画するシーンを探索しつつライティング結果を集める。これに対してVCTでは,あるまとまった束(たば)のレイを放つ。束になったレイは円錐(Cone)形状になるので,Cone Tracingと呼ばれるわけだ。
SVO-GI法でVCTを利用する場合,八分木化されたシーンのライティング結果を集めるためには,八分木データ構造を順に辿る必要がある。しかし,GI WorksでのVCTならば,階層構造化された3Dテクスチャ(=CLIPMAP)に対するテクスチャサンプリングをLODに配慮して行うだけで済む。これなら普通のテクスチャアクセスと実質的に変わらない。SVO-GI法よりVCTの計算もシンプルになるので,高速に処理できるというわけである。
![画像ギャラリー No.008のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/008.jpg) |
![画像ギャラリー No.012のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/012.jpg) |
![画像ギャラリー No.013のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/013.jpg) |
![画像ギャラリー No.014のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/014.jpg) |
![画像ギャラリー No.015のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/015.jpg) |
![画像ギャラリー No.016のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/016.jpg) |
能書きはともかく,実際の処理速度はどうなるのだろうか。説明員に聞いたところ,サンプルデモの場合,「GeForce GTX 770」でGI処理に要する時間は7.4
メモリ使用量も確認してみたところ,64×64×64テクセルで1ボクセル当たり16byte,3LODに相当するCLIPMAPが12MB程度。256×256×256テクセルで1ボクセル当たり32byte,5LODに相当するCLIPMAPになると,2.5GB程度だという。
GI Worksを用いれば,SVO-GI法よりも計算量,メモリ使用量ともに軽い負荷でリアルタイム大局照明を実現できるとのこと。今後のゲームエンジンで利用されることを期待したい。
Haswell世代の統合型グラフィックス機能向けDirectX 12対応ドライバが公開
![画像ギャラリー No.019のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/019.jpg) |
![画像ギャラリー No.020のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/020.jpg) |
テストモードは2種類用意されていた。1つめは,シンプルなフレームレート比較テストで,DirectX 11対応ドライバとDirectX 12対応ドライバで,5万個の隕石を描画するときのフレームレートを比較するというものだ。DirectX 11では20fps程度なのに対して,DirectX 12では30fps程度にまで向上していた。約1.5倍の性能向上に当たる。
![画像ギャラリー No.021のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/021.jpg) |
![画像ギャラリー No.022のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/022.jpg) |
このデモのポイントは,どちらのモードでもCPU全体の消費電力は変わらないことだと,デモの担当者は述べる。同一の消費電力であるならば,DirectX 12のほうがCPUコア側の負荷を減らせるので,統合型GPUがより多くの電力を使える余地が生まれ,結果としてグラフィックス性能を向上させられるということを示しているというわけだ。
2つめのテストモードは,フレームレートを15fpsに固定した状態で,消費電力の変化を見るというもの。
デモを見てみると,統合型GPUの消費電力は,DirectX 11モードとDirectX 12モードで変化がない。しかし,CPU全体の消費電力はDirectX 12モードのほうが低くなるのが見てとれた。動画も掲載しておくので見てほしい。
つまり,同じGPUであってもDirectX 12のほうがCPU側のオーバーヘッドを押さえて動作できるうえ,統合型GPUに渡すコマンドの作成をマルチスレッドで行いやすくなるために,こうした効果が得られているのだと,担当者氏は説明していた。
Intelの統合型GPUが,絶対的な性能でAMDやNVIDIAのGPUにかなわないことを,Intelもよく理解している。しかし,すべてのPCユーザーが高性能なGPUを必要とするわけでもない。「求める性能水準に対して,DirectX 12ならばこれだけ電力効率がいい」というIntelのアピールは,DirectX 12の新しい価値を見出してくれたともいえなくもない。その意味では,実に「Intelらしいデモ」だったといえる。
AMDは新レイトレーシングエンジン「Fire Render」を発表。NVIDIAの「OptiX」に対抗
![画像ギャラリー No.024のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/024.jpg) |
![画像ギャラリー No.028のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/028.jpg) |
Fire Renderは,GCN世代のRadeonやFi
![画像ギャラリー No.025のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/025.jpg) |
現在は,Autodesk製の3Dツール「Autodesk Maya」(以下,Maya)用のプラグインが提供されている。材質(マテリアル)を表現するためのシェーダー設計には,Fire Render専用のツールを使う必要があるが,それ以外ならMayaの機能を使ってシーンを制作して,レンダリング結果を得られるという。
![画像ギャラリー No.026のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/026.jpg) |
![画像ギャラリー No.027のサムネイル画像 / [SIGGRAPH 2014]NVIDIAがゲーム向けのリアルタイム大局照明,IntelはHaswell用DX12ドライバのデモを一般展示セクションで披露](/games/032/G003263/20140823008/TN/027.jpg) |
AMDブースで披露されたデモは,CPUに「Xeon E5-2697 v2」(12C24T,動作クロック2.7GHz)を2基搭載し,「FirePro W8100」を4基搭載したマシンが使用された。原田氏によれば,FirePro W8100×1基でXeon×2基の10倍ほど高速なレンダリングが可能なため,4基のGPUでは40倍ものパフォーマンスが得られるのだという。
数百万ポリゴンのシーンで間接照明を1バウンスに限定すると,約20msでレンダリングが完了するそうだ。単純計算では50fps相当にもなり,とてつもなく速いことが分かる。FireProシリーズ最上位モデルである「FirePro W9100」を使えば,処理性能はさらに25%程度向上するそうだ。
Fire Renderは今後,Solid Angleのレイトレーシングレンダラ「Arnold Renderer」への採用が決定しているとのこと。ちなみに,Arnold Renderは,Electronic Theaterレポートでも触れたSF映画「ゼロ・グラビティ」に採用された実績がある。採用事例の広がりに期待したい。
AMDとしては,Fire Renderを有償化する予定はないそうで,あくまでもAMD製GPUの販売促進用ソリューションに位置づけられている。レイトレーシング向けの実用的なソフトウェアライブラリとして提供するプランもあるとのこと。ゲームグラフィックス用途なら,既存のラスタライズによるレンダリングと局所的なレイトレーシングを組み合わせる次世代技術,「ハイブリッドレンダリング」システムへの応用が期待できるかもしれない。
ところで,Fire RenderはOpenCLで書かれているので,勘の良い人なら,「Op
AMD GPUとNVIDIA GPUのどちらが速いか,最終版が提供されてたら検証してみると面白そうである。
- 関連タイトル:
 Core i7・i5・i3-4000番台(Haswell)
Core i7・i5・i3-4000番台(Haswell) - 関連タイトル:Radeon Pro,Radeon Instinct

- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー