












企画記事
キーワードで押さえる新世代CPU「Core i7」のポイント
 |
そのゲームにおけるパフォーマンスはレビュー記事,そして基礎ポテンシャルはテストレポートを参照してほしいが,そもそも,Nehalemマイクロアーキテクチャ,そしてCore i7とは何なのだろうか。まだ正式発表されているわけではないため,いくつか不明な部分は残っているが,現時点で明らかになっているキーワードを軸に,Core i7の概要紹介を試みてみたいと思う。
→Core i7レビュー記事
→Core i7基礎テストレポート記事
Nehalemの“一形態”となるCore i7
「Core」「Uncore」それぞれに大きな特徴が
Nehalemマイクロアーキテクチャが持つ最大の特徴は,プロセッサをモジュール化している点にある。一つのプロセッサは,
- 「Core」:「Hyper-Threading」テクノロジーに対応したCPUコアとL1,L2キャッシュ部分
- 「Uncore」:CPUの足回りを支える,「Core」以外の要素
 |
つまり,Nehalem世代のCPUは,「Core」と「Uncore」の組み合わせによって特徴づけられるわけだ。そして,Nehalemマイクロアーキテクチャを採用し,ハイエンドデスクトップPC向けと位置づけられ,開発コードネーム「Bloomfield」(ブルームフィールド)と呼ばれてきたCore i7は,
- 「Core」部:四つのCPUコアを統合した,いわゆるネイティブクアッドコアCPUである
- 「Uncore」部:L3キャッシュとトリプルチャネルDDR3メモリコントローラ,「QPI」を統合している
この2点で特徴づけられるプロセッサといえる。
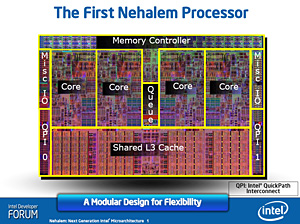 |
| Nehalem世代の第1弾プロセッサ,つまりCore i7のCPUダイイメージ。L3キャッシュとメモリコントローラを統合し,さらにチップセット間インタフェースとしてPoint-to-Pointのものを採用したネイティブクアッドコアCPUというのは,AMDのPhenom(やQuad-Core Opteron)と非常によく似ている |
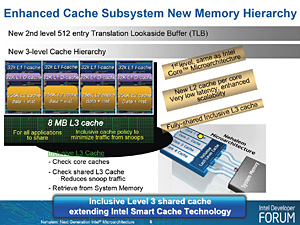 |
| Core i7のキャッシュ構成。L1キャッシュの仕様はCore 2ファミリーと同じ。一方,L2キャッシュはレイテンシの低減が図られたとされる |
1コア当たりのL1キャッシュ容量は命令32kB,データ32kB。L2キャッシュは命令&データ共通で,同256kB。L2キャッシュ容量はCore 2 Quadの上位モデルで2コア当たり6MB(4コアで合計12MB)だったので,ずいぶんと少なくなったが,代わりに高速化が図られたとされている。
「Uncore」部に用意されるL3キャッシュ容量は8MB。これは四つのCPUコアで共有される仕様だ。また,メモリコントローラは,従来のIntelプラットフォームだとノースブリッジに統合されていたので,Core i7で初めてCPUへ統合されたことになる。また,DDR2のサポートを廃したことと,DDR3-1066のトリプルチャネル(3ch)アクセスを実現している点もトピックといえるだろう。
「QPI」は「QuickPath Interconnect」の略で,これはCPUとチップセット間を結ぶPoint-to-Pointの接続インタフェースだ。詳細は後述するが,従来のFSB(Front Side Bus)を置き換えるものである。
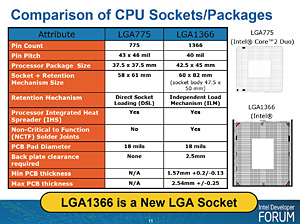 |
ところで,メモリコントローラがCore i7側に移ったことで,メモリコントローラを統合し,「Memory Controller Hub」(MCH)と呼ばれてきた従来のノースブリッジは利用できなくなったため,Core i7用には新たに,QPIをサポートした「Intel X58 Express」(以下,X58)チップセットが用意されている。
開発コードネーム「Tylersburg」(タイラースバーグ)もしくは「Tylersburg-DT」などと呼ばれてきたX58チップセットには,MCHに変わる呼称として,「I/O Hub」(IOH)という呼称が与えられている。
X58 IOHはグラフィックス機能を統合していないため,外部グラフィックスカードの利用を前提としたPCI Express 2.0インタフェースが用意されており,最大36レーンをサポート。マザーボードベンダーは,PCI Express 2.0 x16 ×2やPCI Express 2.0 x8 ×4などといった構成を選択できる。
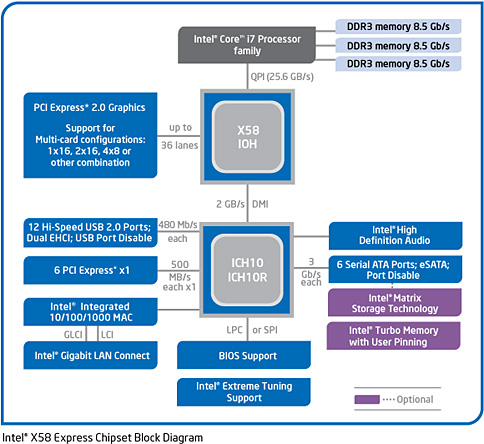 |
なお,IOHという名称から誤解してしまいそうだが,X58にサウスブリッジ機能は統合されておらず,サウスブリッジとしてはIntel 4シリーズと同じICH10(もしくはICH10R)が組み合わされる。X58とICH10/ICH10R間のインタフェースは,これまた従来どおりのDMIで,帯域幅はPCI Express 4レーン分,つまり実効帯域幅で2GB/sだ。
最後に,発表当初のラインナップだが,下記の3製品になる見込みだ。最上位モデルの「Extreme Edition」のみ,いわゆる倍率ロックフリー機能(※厳密には異なる。詳細はレビュー記事を参照してほしい)と,より高い性能のQPIリンクを持つが,基本的な仕様は共通である。
●発表時点におけるCore i7のラインナップ
- Core i7 965 Extreme Edition/3.20GHz(QPI 6.4GT/s,1000個ロット時価格999ドル)
- Core i7 940/2.93GHz(QPI 4.8GT/s,同562ドル)
- Core i7 920/2.66GHz(QPI 4.8GT/s,同284ドル)
新世代CPUのキーワードを
もう少し細かく掘り下げてみる
以上が概要となる。もう少し知りたい読者のため,ここからは,上で紹介したキーワードのうち,とくに重要なポイントを掘り下げてみることにしよう。
■トリプルチャネルDDR3メモリコントローラ
 |
ただ,単なる後追いではない。Core i7が統合したのは,トリプルチャネル(3ch)の,DDR3専用メモリコントローラ。発表時点では,DDR3-1066がサポートされる予定なので,対応するPC3-8500 DDR3 SDRAMモジュール×3で,3chの合計帯域幅は約25.6GB/sに達する。Core 2ファミリー対応のチップセット最上位品となる「Intel X48 Express」だと,Intel独自のオーバークロックメモリ規格「XMP」(eXtreme Memory Profile)準拠でDDR3-1600のデュアルチャネルをサポートするが,この帯域幅は25.6GB/sなので,Core i7は,規定の動作クロックで,前世代のプラットフォームでオーバークロックメモリモジュールを利用したときと同等のメモリバス帯域幅を獲得した計算になる。
■QPI
Core i7で初めて採用されたCPU−IOH間接続インタフェース,QPI。Core 2ファミリーまでのIntel製CPUでは,一つのCPU−チップセット間バスをメモリとI/Oで共用するFSBを採用していたため,高負荷時にこのバスがボトルネックとなる可能性があったが,メモリがノースブリッジから移動したことで,メモリとI/Oのインタフェースがそれぞれ独立するという,ボトルネックの生じにくい設計へと生まれ変わったことになる。
これも,「AMDがAthlon 64で取り入れた設計の後追い」と言ってしまえばそれまでだが,Athlon 64以降のAMD製CPUが,I/O負荷の高い状況下で優れたパフォーマンスを発揮するのは知られている事実であり,少なくとも間違った進化の方向性ではない。
 |
Core i7から伸びるQPIリンクは,片方向20bit(双方向40bit)幅。片方向ごとにプロトコル用に2bit,CRCエラーチェック用に2bitずつ確保されるため,データ転送用に利用できるのは片方向16bitだ。つまり,
16bit(2bytes)×6.4GT/s=12.8GB/s
ということになり,双方向25.6GB/sという帯域幅を持つ計算になる。
ちなみに,AMDが提唱する「HyperTransport」だと,第3世代の「HyperTransport 3.0」で,最高クロックの2.6GHz動作時に双方向最大41.6GB/s。「Phenom X4 9950 Black Edition/2.6GHz」だと,HyperTransportクロックは2GHzなので,32GB/sとなる。
なお,Core i7の説明ということで,ここまでは「CPU−IOH間接続インタフェース」と説明してきたが,NehalemマイクロアーキテクチャにおけるQPIは実際のところ,マルチCPU構成時にCPU間接続にも用いられる。その意味ではHyperTransportと同じだ。I/Oインタフェースは,あくまでPCI Expressで提供されるので,この点は誤解しないよう気をつけておきたい。
■Loop Stream Detector
DDR3メモリコントローラとQPIはCore i7の大きな特徴だが,いずれも「Uncore」部分の特徴である。では,「Core」部分はどうかというと,実のところ,IntelはNehalemマイクロアーキテクチャにおける実行エンジンの詳細について多くを語っていない。そんななか,数少ないアピールポイントの一つとして挙げられているのが,「Loop Stream Detector」(以下,LSD)という技術である。
Nehalemマイクロアーキテクチャは4命令同時実行が可能なスーパースケーラだが,これはCore 2ファミリーの「Coreマイクロアーキテクチャ」と同じ。5命令,6命令……と増やせばクロック当たりの性能を引き上げられそうだが,そうしなかったのはおそらく電力効率周りの事情だろう。
x86命令は非常に複雑で,命令の解釈(デコード)に手間がかかる。そのため,Coreマイクロアーキテクチャ以上にデコード性能を上げようとすると,相当な規模の回路を投入する必要があり,消費電力が上がってしまうわけだ。しかし,世界的な消費電力低減という流れのなかにあって,消費電力当たりの性能を,従来製品以下にするわけにはいかない。そうなると,デコード性能を飛躍的に向上させられないから,実行部を拡張してもムダ。同時実行可能な命令数が据え置かれた理由は,そんなところだと思われる。
ただ,何もかも同じでは,クロック当たりの性能も変わらなくなってしまう。そこで加えられた改良のうち,プログラムに数多く含まれるループ(※同じ手続きの繰り返し)部分の効率を上げてやろうというのが,LSDのポイントだ。「命令を解析してループを検出したら,CPU内部に命令を“溜めて”おき,ループの実行は,その溜めておいた命令で行おう」という仕組みである。
 |
 |
従来のLSDでは,x86命令をメモリから取り込んだ後のステージでループの命令並びを保持していた。したがって,検出されたループであっても,命令の解釈(デコード)を行うステージを通過する必要があった。
一方,NehalemマイクロアーキテクチャのLSDでは,デコードが終了したあと,μOPs(縮小命令)の形でループの命令を蓄積する。LSDが有効なループではデコーダもバイパスされるため,効率はより高いということになる。
また,CoreマイクロアーキテクチャのLSDで溜められる命令の数は最大18だったが,Nehalemマイクロアーキテクチャではこれが28へとサイズが増えている。
正確にいえば,28μOps。x86命令は1〜4μOpsに展開されるので,場合によっては少なくなるが,たいていの場合,x86命令とμOpsは1対1で対応するとIntelは述べており,だとすると,従来では対応出来なかった,より大きなループでも,NehalemマイクロアーキテクチャならLSDの効果を期待できるわけだ。
■Hyper-Threading
一つのCPUコアを2コアに見せかける「Hyper-Threading」テクノロジー。Pentium 4時代の中期において大きくアピールされた機能がNehalemマイクロアーキテクチャで復活する。
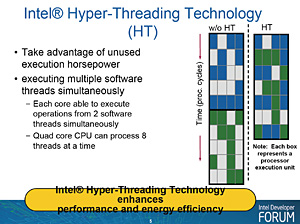 |
それを踏まえ,「どうせ空きが出来るのなら,その空きで別のスレッドを実行さえてしまおう」というのがHyper-Threadingの基本的な発想だ。異なるスレッドなら,命令の並び順に依存関係がないから,効率的に同時実行が可能というわけである。
Core i7は四つのCPUコアを持つため,Hyper-Threadingを有効化すると,OSからは8コアのCPUとして扱える。Hyper-Threadingが有効化されたシステムでは,異なるスレッドが,実行中のもう一方のスレッドとは異なるデータを扱う可能性があるため,より大きなメモリバス帯域幅を必要とするが,Pentium 4時代と比べて帯域幅は格段に広がっているため,Hyper-Threadingの効率はより高められているとIntelはアピールする。
Hyper-Threadingが実際にどの程度の効果があるかを定量的に計るのは難しい。アプリケーションによるとしか言いようがないのが正直なところだ。一般論としては,「マルチスレッド化されているアプリケーションであれば,ある程度の効果は期待できる」といえる。
しかし,OSは空いているCPUにスレッドやプロセスを割り当てるが,そのとき,物理的なCPUコアかそうでないかを区別しないため,「Hyper-Theadingによって特定のスレッド/プロセスが処理されているCPUを『空いている』と判断して,別のスレッド/プロセスを割り当ててしまう」可能性があり,この場合は1コアの負荷がボトルネックとなり,システム全体のパフォーマンスが低下してしまう。
まあもっともこの現象は,OSの負荷が低い場合に生じやすいため,そもそも「OSの負荷が低い=たいした作業をしていない」となるデスクトップPCではまず問題にならないだろうが。
■Intel Turbo Boost Technology
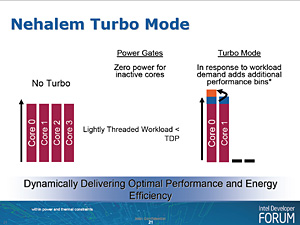 |
本機能を改良し,より多くの局面で動作倍率の自動引き上げを実現できるようにしたのが,「Intel Turbo Boost Technology」(以下,Turbo Boost)である。
本機能については,宮崎真一氏がCore i7のレビュー記事内で詳しく説明しているので,そちらを参照してもらえればと思う。
なお,“発動条件”は,TDPと各コアに流れる電流,各コアの温度のいずれもが閾値以下に収まっていることとされている。
■そのほか〜C6ステート&SSE4.2
 |
C6ステートは,Penryn世代のノートPC用Core 2 Duoで初採用となった動作モードで,CPUコアの消費電力をほぼゼロにできる機能だ。Penryn世代では,「消費電力をほぼゼロにする」条件がやや厳しめで,二つのCPUコアがいずれもC6ステートへ移行している必要があったのだが,Nehalemマイクロアーキテクチャでは,CPUコアそれぞれが,ほかのコアとの依存関係なしに,単独でC6ステートへ移行し,消費電力を最小限にまで下げられるようになった。
また,Nehalemマイクロアーキテクチャでは,7個のSSE命令が「SSE4.2」として新設されている点も触れておく必要があろう。もっとも,追加されたのはXMLパーサーを加速するものなど,(該当する環境では効果的であるものの)ゲームのパフォーマンス向上に寄与しそうなものは見あたらない。新命令は,使用されなければ意味がないことを踏まえるに,当面の間,SSE4.2がゲーマーにとって大きなインパクトをもたらすことはないだろう。
というわけで,後半が長くなってしまったが,以上,NehalemマイクロアーキテクチャとCore i7プロセッサの特徴をまとめてみた。レビュー記事やテストレポート記事を読み進めるに当たって,参考にしてもらえれば幸いだ。
- 関連タイトル:
 Core i7(LGA1366,クアッドコア)
Core i7(LGA1366,クアッドコア) - この記事のURL:
(C)Intel Corporation
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー