










連載
西川善司の3DGE:PCIe Gen.4対応,そしてメモリバス帯域幅1TB/s到達。Vega 7nmは見るべきポイントの多いGPUだ
北米時間2018年11月6日にAMDは7nm世代のCPUとGPUを予告した。そのうち,CPUのほうは次世代のサーバーおよびデータセンター向けCPU「Rome」(ローマ,開発コードネーム)だったわけだが(関連記事),今回はGPUのほう,「Vega 7nm」(ヴェガ7nm)という開発コードネームで知られてきたプロセッサを取り上げたいと思う。
発表イベント「The Next Horizon」でAMDは,Vega 7nmベースの次世代GPUを「Radeon Instinct MI60」「Radeon Instinct MI50」としてGPUサーバー向けに提供することも明らかにしている。少なくとも当面の間,一般ユーザー向けとしての提供はないようだ。
リリース時期は2018年内の予定。具体的な「何月何日」という情報はないが,AMDの公式Webサイトではもうデータシートも上がっている(※Radeon Instinct MI60データシートpdf,Radeon Instinct MI50データシートpdf)くらいなので,準備はほぼできているという理解でいいのではなかろうか。
イベントでVega 7nmのプレゼンテーションを担当したのはAMDでGPUエンジニアリング部門を率いるDavid Wang(デヴィッド・ワン)氏だ。Intelへ電撃移籍したRaja Koduri(ラジャ・コドゥリ)氏の後任として2018年1月にAMD入りした「新・ミスターRadeon」だが,筆者はイベント後に氏へインタビューすることもできたので,今回はその内容から,Vega 7nmのアーキテクチャに迫ってみたい。
Radeon Instinct MI60とRadeon Instinct MI50は,当初から「Radeon Instinct Vega 7nm」として,新しい7nmプロセス技術を用いて開発することが明らかになってきた。
Vega 7nmは「Vega 20」とも呼ばれており,こう書くと,現行の第1世代Vegaである「Vega 10」の後継であることがはっきりすると思う。ではなぜAMDは新しい7nmプロセス技術世代で次世代マクロアーキテクチャ「Navi」(ナヴィ,開発コードネーム)を採用するのではなく,Vegaマクロアーキテクチャに留まったのかと言えば,新世代の製造プロセス技術へ移行するときにはあまり冒険したくないからだ。
製造プロセス技術の微細化を新しいアーキテクチャで進めて何か問題が起きたとき,前者と後者のどちらに原因があるのか分かりにくくなるため,半導体メーカーの間では,ある程度“枯れた”アーキテクチャを使って新しい世代の製造プロセス技術へ移行するというのがトレンドになっている。
新しい世代の製造プロセスを導入するのはコスト的に高くつくので,「失敗するリスクの低い,より安全なアーキテクチャ」を採用し,「そもそも高価なのでコストをある程度吸収できる」エンタープライズ市場向けに展開し,ビジネス上のリスクを減じているというわけである。
まずはRadeon Instinct MI60とRadeon Instinct MI50の基本情報を整理しておこう。
搭載するVega 7nmの総トランジスタ数は132億,ダイサイズは332mm2だ。14nmプロセス技術を用いて製造されるVega 10だと順に125億,486mm2なので,トランジスタ数は約6%増えた一方,ダイサイズは約68%にまで小さくなった計算になる。
有効なシェーダプロセッサ「Stream Processor」の数はRadeon Instinct MI60が4096基,Radeon Instinct MI50が3840基。オンパッケージとなるメモリ「HBM2」(High Bandwidth Memory 2)の容量も順に32GB,16GBと2倍の違いがある。
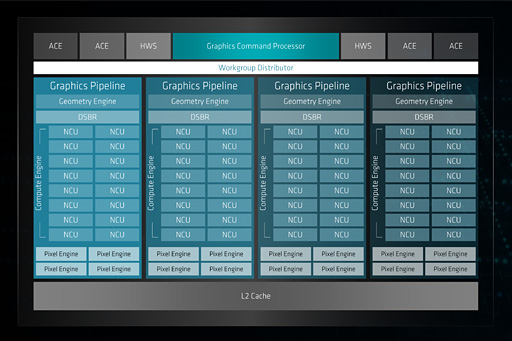
より内部に目を向けてみると分かるが,そのブロック図はVega 7nmとVega 10とで変わらない。64基のシェーダプロセッサを統合する「Compute Unit」は,Vega 10に合わせて「Next-Generation Compute Unit」(以下,NCU)とあらためられたため,図中ではNCU表記になっているが,その数が最大64基なのも変わっていない。
Polaris世代までは「Shader Engine」という名前だったミニGPU的なクラスタ「Compute Engine」が4基なのも同じだ。なので当然のことながら,総シェーダプロセッサ数が4096基(64 Stream Processor × 16 NCU × 4 Compute Engine)なのも同じということになる。
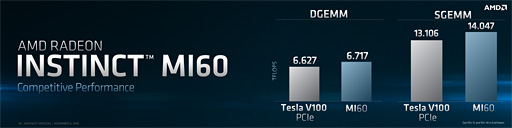
理論性能値は32bit浮動小数点演算(FP32)で14.7 TFLOPSとのことだ。
ちなみに,Stream Processorは1クロックでFP32の積和算を実行できる(=2 FLOPS)仕様なので,Vega 10の理論性能値は,
と求めることができた。この計算式を使って,14.7 TFLOPSという理論性能値から逆算すると,Vega 7nmのブースト最大クロックは1794MHzあたりになるはずだ。Vega 10の1546MHzに対して約16%の高クロック化というのは,製造プロセス技術の微細化によってもたらされるものとしては納得できる数字であるように思う。
Vega 7nmでは,64bit倍精度浮動小数点(FP64)の演算性能も改善している。Vega 10世代におけるFP64演算性能はFP32演算性能の16分の1しかなかったが,これが8倍に達した。(実装形態こそ不明ながら)Vega 7nmではFP32演算性能の半分に相当するFP64演算性能が期待できるわけだ。これはNVIDIAのTeslaシリーズと同じ「FP32とFP64の性能バランス」なので,競合と対抗するための性能強化と言っていいだろう。
さて,そんなVega 7nmを搭載する新世代Radeon InstinctでAMDがとくに力を入れているのは「機械学習ベースのAI開発」用途となっている。
それに向けてAMDは今回,4bit整数演算(INT4)を「Rapid Packed Math」の対象として追加した。Vega 10の発表時にAMDは,Vegaマクロアーキテクチャで16bit浮動小数点演算(FP16)と8bit整数演算(INT8)の「Packed実行」に対応することをアピールしていたが(関連記事),Vega 7nmではさらにINT4もPacked実行の対象に加えたということだ。
機械学習や深層学習の学習フェーズにおける取り扱いデータ精度は,32bit整数や32bit浮動小数点数になることもあるが,多くのケースでは16bit整数や浮動小数点数で十分だとされる。しかも,アプリケーション側で用いる推論処理のフェーズだと,取り扱う学習データにはある種の正規化が入って冗長性も排除されるため,8bit整数や4bit整数で十分となることが多い。実際,最近の携帯電話向けSoC(System-on-a-Chip)が搭載する「AIチップ」的な推論アクセラレータの演算精度はまさにそのくらいだったりするわけだが,そうした技術トレンドに合わせてVega 7nmもINT4に対応してきたというわけである。
ちなみにWang氏は,「実のところ(Vega 7nmは)1bit精度にも対応している。2bit精度にも対応できていたはずだ。公にはしていないが」と述べていた。学習対象や学習モデルによっては,推論時の計算精度が1〜2bitで十分な場合も多く,そうした推論エンジン開発現場からの要望で対応したのだとか。
いずれにせよVega 7nmでは,INT4のPacked実行に対応しており,そのときの理論性能値は118 TOPSとなる。整数演算の理論性能値なのでTFLOPS(テラフロップス)ではなく,TOPS(テラオプス)である点に注意してほしい。
ちなみにこの118 TOPSという数値は,Vega 7nmの32bit浮動小数点演算理論性能値である14.7 TFLOPSに対して8倍となるが,これはビット幅の比率そのままなので納得できるはずだ。
Vega 7nmでは,統合するHBM2のインタフェースが,Vega 10の2048bit幅に対して4096bit幅へと拡大を果たした。これもVega 7nmにおける重要な強化ポイントだ。
Vega 10でパッケージ上にあるメモリスタックは2つだったが,これがVega 7nmで4スタック構成となったことが4096bitバス化の直接的な理由である。
Vega 7nmが搭載するHBM2はピンあたり2Gbps仕様となるので,メモリバス帯域幅は,
と,ついに1TB/sの大台に到達した。これは,Vega 10の484GB/sに対して2倍以上のスペックであり,Tesla V100の900GB/sをも凌ぐ数字だ。
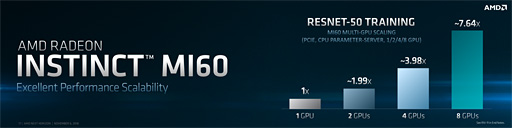
シェーダプロセッサ数がVega 10から変わっていなくとも,グラフィックス描画においてメモリ性能が効いてくる。あまり試す機会はないと思うが,Radeon Instinct MI60とRadeon Instinct MI50はゲームグラフィックス系ベンチマークのスコアも良さそうである。
今回のThe Next HorizonイベントでVega 7nmと同時に発表となった次世代EPYCプロセッサが業界初のPCI Express(以下,PCIe)Gen.4対応CPUとなることはすでにお伝えしているとおりだが,このRome世代のEPYCと組み合わせて使う前提から,Vega 7nmもPCIe Gen.4対応となっている。
もちろんRadeon Instinct MI60とRadeon Instinct MI50はPCIe Gen.3以前の既存環境でも利用できるが,Vega 7nmというGPUの最大ポテンシャルを発揮できるのは(少なくとも現時点では)Romeプラットフォームということになる。このときRomeとVega 7nmとの間は16レーンのリンクでつながるが,帯域幅は双方向(※上り下りそれぞれ)64GB/s。これはPCIe Gen.3 x16比で2倍だ。
またVega 7nmはマルチGPU構成にも対応している。そのときはAMD独自のインターコネクト技術「Infinity Fabric」を利用する仕様になっており,接続にはブリッジアダプターを使うことになった。
AMDはマルチGPU構成のブランド名として使っていた「CrossFire」の名を捨て,最近ではシンプルに「マルチGPU」(mGPU)と呼ぶようになっていたが,今回,Radeon Instinct MI60とRadeon Instinct MI50の発表にあたっては「Infinity Fabric Link」という名称を与えている。
マルチGPU駆動にプロセッサ間専用インタフェースを用いるのはNVIDIAの「NVLink」と同じコンセプトだと言っていい。
従来のマルチGPU(旧CrossFire)やSLI構成では個々のGPUがレンダリングしたピクセルデータを相互に転送するだけの専用インタフェースでつないでいただけだったため,複数搭載するGPU間での協調動作を行ったり,各GPUが管轄するデータを別のGPUと透過的に共有したりすることはできなかった。それに対してInfinity Fabric LinkやNVLinkのような高度なプロセッサ間インターコネクト技術を用いれば,従来なら不可能だったことが可能になる。
言うまでもないことだが,最近のGPUは「グラフィックスを高速に描画する」目的以外に利用されることが増えてきた。そのため,グラフィックス以外の用途を前提とした製品では,高コストになることを覚悟のうえで,より高度な相互連係動作が可能になる技術を採用するようになったというわけだ。
なお,Vega 7nmにおけるInfinity Fabric Linkだと,GPU間のデータ伝送帯域幅は双方向(※上り下りそれぞれ)100GB/sとなる。Infinity Fabric Linkを構成するGPUの数が3基以上になる場合は環状でデータ転送を行うリングバスになるため,離れたGPU同士でデータをやりとりするときには若干の遅延が起こりうる。
Infinity Fabric Linkの接続仕様は,ざっくり言ってしまえばNVLinkと同じだ。なので,相互接続された複数のGPUをアプリケーション側からは,1つの大きなGPUとして活用することも,異なる別個のGPUとして活用することもできる。
また,Vega 7nmのオンパッケージHBM2はアプリケーションから大きな1つのメモリ空間として扱えるが,そのとき,当該メモリ空間の扱いはSVM(Shared Virtual Memory)となる。なので,“自分”のところにない,別のGPUのところにあるデータは,バックグラウンドでInfinity Fabric Link(やNVLink)を使ってコピー(≒転送)しなければならない。
なので結局のところ,マルチGPU環境ではあるのだが,最大性能を得たい場合には個々のGPU内で処理したほうがいいということになるわけだ。
では,この方式のメリットはどこにあるのかだが,「1つのアプリケーションが特別な対応なしにマルチGPU環境で動かせる」というところになる。ゲームグラフィックス用途における実性能は,今までのマルチGPUやSLIとあまり変わらないだろう。プロファイルが不要になるはずなので,これまでマルチGPUやSLIに対応していなかったゲームアプリケーションでも性能向上を実現できる可能性がある。
Vega 7nmは,「Vega 10の設計を継承しつつ製造プロセス技術を微細化したマイナーチェンジ版」という触れ込みだった。実際,GPUコア自体の省電力や高クロック化といったあたりは想像の範疇だったが,それ以外の要素には,事前の予想よりも見るべきものが多いように思う。
PCIe Gen.4やInfinity Fabric Link対応のマルチGPU構成といった新要素,そして4096bit幅となったメモリインタフェースと1TB/sに達したメモリバス帯域幅には「ゲーム系ベンチマークを実行したらどうなるんだろう?」という興味をそそられる。
また,機械学習型AIや深層学習型AIにおける推論アクセラレーションと相性の良いINT4 Packed実行への対応,科学技術演算などで有用な64びt倍精度浮動小数点の演算性能強化といったあたりからは,競合に対するAMDの強い対抗心が感じられる。AMDはGPGPU分野における勢力拡大をまだ諦めていないと断言してしまっていいだろう。
そろそろGPGPU分野はフレームワークベースでの開発が主戦場になってきているため,それら主流のフレームワークに対応できれば,GPGPU市場でのチャンスがあるかもしれない。
……といった具合にVega 7nmは魅力的なGPUと言えるのだが,少なくとも現時点だとゲーマーには縁遠い製品と言わざるを得ない。なので4Gamer読者の関心は,Vega 7nmと同じプロセス技術を用いて製造されるNaviのほうだろう。何しろこのNaviは,次世代PlayStationや次世代Xboxの姿を占うと目されているからだ。
インタビューでWang氏は次世代GPUについての質問には答えてくれなかったが,NVIDIAとMicrosoftが推進するゲーム向けのリアルタイムレイトレーシング技術「DirectX Raytracing」(以下,DXR)については「個人的な見解だが」という前置き付きで語ってくれた。
いわく,「AMDとしては間違いなくDirect Raytracingへの対応は進めていく」が,「当面は,AMDが無償提供しているRadeon ProRenderを中核としたオフラインCG制作環境の高速化の推進に力を入れる」とのことだ。
氏は,「レイトレーシングのゲームに対する活用は,ローエンドからハイエンドまで,すべての製品レンジでレイトレーシングを提供できるようにならないと進まないだろう」とも述べていたので,これを素直に解釈するなら,直近のAMD製GPUにおけるDXRの対応の可能性は低いように思えるが,直近の次世代GPUであるNaviで「上から下まで対応する」というどんでん返しの可能性も否定はできない。果たして……。
 |
発表イベント「The Next Horizon」でAMDは,Vega 7nmベースの次世代GPUを「Radeon Instinct MI60」「Radeon Instinct MI50」としてGPUサーバー向けに提供することも明らかにしている。少なくとも当面の間,一般ユーザー向けとしての提供はないようだ。
 |
 |
リリース時期は2018年内の予定。具体的な「何月何日」という情報はないが,AMDの公式Webサイトではもうデータシートも上がっている(※Radeon Instinct MI60データシートpdf,Radeon Instinct MI50データシートpdf)くらいなので,準備はほぼできているという理解でいいのではなかろうか。
 |
前世代と比べてトランジスタ数は6%増ながらダイサイズは7割以下に
Radeon Instinct MI60とRadeon Instinct MI50は,当初から「Radeon Instinct Vega 7nm」として,新しい7nmプロセス技術を用いて開発することが明らかになってきた。
 |
Vega 7nmは「Vega 20」とも呼ばれており,こう書くと,現行の第1世代Vegaである「Vega 10」の後継であることがはっきりすると思う。ではなぜAMDは新しい7nmプロセス技術世代で次世代マクロアーキテクチャ「Navi」(ナヴィ,開発コードネーム)を採用するのではなく,Vegaマクロアーキテクチャに留まったのかと言えば,新世代の製造プロセス技術へ移行するときにはあまり冒険したくないからだ。
製造プロセス技術の微細化を新しいアーキテクチャで進めて何か問題が起きたとき,前者と後者のどちらに原因があるのか分かりにくくなるため,半導体メーカーの間では,ある程度“枯れた”アーキテクチャを使って新しい世代の製造プロセス技術へ移行するというのがトレンドになっている。
新しい世代の製造プロセスを導入するのはコスト的に高くつくので,「失敗するリスクの低い,より安全なアーキテクチャ」を採用し,「そもそも高価なのでコストをある程度吸収できる」エンタープライズ市場向けに展開し,ビジネス上のリスクを減じているというわけである。
 |
 |
搭載するVega 7nmの総トランジスタ数は132億,ダイサイズは332mm2だ。14nmプロセス技術を用いて製造されるVega 10だと順に125億,486mm2なので,トランジスタ数は約6%増えた一方,ダイサイズは約68%にまで小さくなった計算になる。
 |
有効なシェーダプロセッサ「Stream Processor」の数はRadeon Instinct MI60が4096基,Radeon Instinct MI50が3840基。オンパッケージとなるメモリ「HBM2」(High Bandwidth Memory 2)の容量も順に32GB,16GBと2倍の違いがある。
基本設計はVega 10を踏襲しつつ,高クロック化
 |
Polaris世代までは「Shader Engine」という名前だったミニGPU的なクラスタ「Compute Engine」が4基なのも同じだ。なので当然のことながら,総シェーダプロセッサ数が4096基(64 Stream Processor × 16 NCU × 4 Compute Engine)なのも同じということになる。
 |
理論性能値は32bit浮動小数点演算(FP32)で14.7 TFLOPSとのことだ。
ちなみに,Stream Processorは1クロックでFP32の積和算を実行できる(=2 FLOPS)仕様なので,Vega 10の理論性能値は,
- 4096 Stream Processor × 1546MHz × 2 FLOPS=12.66 TFLOPS
と求めることができた。この計算式を使って,14.7 TFLOPSという理論性能値から逆算すると,Vega 7nmのブースト最大クロックは1794MHzあたりになるはずだ。Vega 10の1546MHzに対して約16%の高クロック化というのは,製造プロセス技術の微細化によってもたらされるものとしては納得できる数字であるように思う。
Vega 7nmでは,64bit倍精度浮動小数点(FP64)の演算性能も改善している。Vega 10世代におけるFP64演算性能はFP32演算性能の16分の1しかなかったが,これが8倍に達した。(実装形態こそ不明ながら)Vega 7nmではFP32演算性能の半分に相当するFP64演算性能が期待できるわけだ。これはNVIDIAのTeslaシリーズと同じ「FP32とFP64の性能バランス」なので,競合と対抗するための性能強化と言っていいだろう。
 |
さて,そんなVega 7nmを搭載する新世代Radeon InstinctでAMDがとくに力を入れているのは「機械学習ベースのAI開発」用途となっている。
それに向けてAMDは今回,4bit整数演算(INT4)を「Rapid Packed Math」の対象として追加した。Vega 10の発表時にAMDは,Vegaマクロアーキテクチャで16bit浮動小数点演算(FP16)と8bit整数演算(INT8)の「Packed実行」に対応することをアピールしていたが(関連記事),Vega 7nmではさらにINT4もPacked実行の対象に加えたということだ。
 |
機械学習や深層学習の学習フェーズにおける取り扱いデータ精度は,32bit整数や32bit浮動小数点数になることもあるが,多くのケースでは16bit整数や浮動小数点数で十分だとされる。しかも,アプリケーション側で用いる推論処理のフェーズだと,取り扱う学習データにはある種の正規化が入って冗長性も排除されるため,8bit整数や4bit整数で十分となることが多い。実際,最近の携帯電話向けSoC(System-on-a-Chip)が搭載する「AIチップ」的な推論アクセラレータの演算精度はまさにそのくらいだったりするわけだが,そうした技術トレンドに合わせてVega 7nmもINT4に対応してきたというわけである。
 |
いずれにせよVega 7nmでは,INT4のPacked実行に対応しており,そのときの理論性能値は118 TOPSとなる。整数演算の理論性能値なのでTFLOPS(テラフロップス)ではなく,TOPS(テラオプス)である点に注意してほしい。
ちなみにこの118 TOPSという数値は,Vega 7nmの32bit浮動小数点演算理論性能値である14.7 TFLOPSに対して8倍となるが,これはビット幅の比率そのままなので納得できるはずだ。
 |
メモリインタフェースはVega 10比で2倍。ついにメモリバス帯域幅は1TB/sの大台へ
Vega 7nmでは,統合するHBM2のインタフェースが,Vega 10の2048bit幅に対して4096bit幅へと拡大を果たした。これもVega 7nmにおける重要な強化ポイントだ。
Vega 10でパッケージ上にあるメモリスタックは2つだったが,これがVega 7nmで4スタック構成となったことが4096bitバス化の直接的な理由である。
Vega 7nmが搭載するHBM2はピンあたり2Gbps仕様となるので,メモリバス帯域幅は,
- 4096 bit × 2Gbps ÷ 8bit=1TB/s
と,ついに1TB/sの大台に到達した。これは,Vega 10の484GB/sに対して2倍以上のスペックであり,Tesla V100の900GB/sをも凌ぐ数字だ。
 |
シェーダプロセッサ数がVega 10から変わっていなくとも,グラフィックス描画においてメモリ性能が効いてくる。あまり試す機会はないと思うが,Radeon Instinct MI60とRadeon Instinct MI50はゲームグラフィックス系ベンチマークのスコアも良さそうである。
業界初となるPCIe Gen.4対応を実現。マルチGPU構成にあたってはInfinity Fabricも採用
今回のThe Next HorizonイベントでVega 7nmと同時に発表となった次世代EPYCプロセッサが業界初のPCI Express(以下,PCIe)Gen.4対応CPUとなることはすでにお伝えしているとおりだが,このRome世代のEPYCと組み合わせて使う前提から,Vega 7nmもPCIe Gen.4対応となっている。
 |
またVega 7nmはマルチGPU構成にも対応している。そのときはAMD独自のインターコネクト技術「Infinity Fabric」を利用する仕様になっており,接続にはブリッジアダプターを使うことになった。
 |
 |
 |
AMDはマルチGPU構成のブランド名として使っていた「CrossFire」の名を捨て,最近ではシンプルに「マルチGPU」(mGPU)と呼ぶようになっていたが,今回,Radeon Instinct MI60とRadeon Instinct MI50の発表にあたっては「Infinity Fabric Link」という名称を与えている。
マルチGPU駆動にプロセッサ間専用インタフェースを用いるのはNVIDIAの「NVLink」と同じコンセプトだと言っていい。
 |
 |
従来のマルチGPU(旧CrossFire)やSLI構成では個々のGPUがレンダリングしたピクセルデータを相互に転送するだけの専用インタフェースでつないでいただけだったため,複数搭載するGPU間での協調動作を行ったり,各GPUが管轄するデータを別のGPUと透過的に共有したりすることはできなかった。それに対してInfinity Fabric LinkやNVLinkのような高度なプロセッサ間インターコネクト技術を用いれば,従来なら不可能だったことが可能になる。
 |
なお,Vega 7nmにおけるInfinity Fabric Linkだと,GPU間のデータ伝送帯域幅は双方向(※上り下りそれぞれ)100GB/sとなる。Infinity Fabric Linkを構成するGPUの数が3基以上になる場合は環状でデータ転送を行うリングバスになるため,離れたGPU同士でデータをやりとりするときには若干の遅延が起こりうる。
Infinity Fabric Linkの接続仕様は,ざっくり言ってしまえばNVLinkと同じだ。なので,相互接続された複数のGPUをアプリケーション側からは,1つの大きなGPUとして活用することも,異なる別個のGPUとして活用することもできる。
また,Vega 7nmのオンパッケージHBM2はアプリケーションから大きな1つのメモリ空間として扱えるが,そのとき,当該メモリ空間の扱いはSVM(Shared Virtual Memory)となる。なので,“自分”のところにない,別のGPUのところにあるデータは,バックグラウンドでInfinity Fabric Link(やNVLink)を使ってコピー(≒転送)しなければならない。
なので結局のところ,マルチGPU環境ではあるのだが,最大性能を得たい場合には個々のGPU内で処理したほうがいいということになるわけだ。
では,この方式のメリットはどこにあるのかだが,「1つのアプリケーションが特別な対応なしにマルチGPU環境で動かせる」というところになる。ゲームグラフィックス用途における実性能は,今までのマルチGPUやSLIとあまり変わらないだろう。プロファイルが不要になるはずなので,これまでマルチGPUやSLIに対応していなかったゲームアプリケーションでも性能向上を実現できる可能性がある。
 |
見るべきポイントの多いVega 7nm。ただし,ゲーマーの関心はその先にある?
 |
 |
また,機械学習型AIや深層学習型AIにおける推論アクセラレーションと相性の良いINT4 Packed実行への対応,科学技術演算などで有用な64びt倍精度浮動小数点の演算性能強化といったあたりからは,競合に対するAMDの強い対抗心が感じられる。AMDはGPGPU分野における勢力拡大をまだ諦めていないと断言してしまっていいだろう。
そろそろGPGPU分野はフレームワークベースでの開発が主戦場になってきているため,それら主流のフレームワークに対応できれば,GPGPU市場でのチャンスがあるかもしれない。
 |
……といった具合にVega 7nmは魅力的なGPUと言えるのだが,少なくとも現時点だとゲーマーには縁遠い製品と言わざるを得ない。なので4Gamer読者の関心は,Vega 7nmと同じプロセス技術を用いて製造されるNaviのほうだろう。何しろこのNaviは,次世代PlayStationや次世代Xboxの姿を占うと目されているからだ。
インタビューでWang氏は次世代GPUについての質問には答えてくれなかったが,NVIDIAとMicrosoftが推進するゲーム向けのリアルタイムレイトレーシング技術「DirectX Raytracing」(以下,DXR)については「個人的な見解だが」という前置き付きで語ってくれた。
いわく,「AMDとしては間違いなくDirect Raytracingへの対応は進めていく」が,「当面は,AMDが無償提供しているRadeon ProRenderを中核としたオフラインCG制作環境の高速化の推進に力を入れる」とのことだ。
氏は,「レイトレーシングのゲームに対する活用は,ローエンドからハイエンドまで,すべての製品レンジでレイトレーシングを提供できるようにならないと進まないだろう」とも述べていたので,これを素直に解釈するなら,直近のAMD製GPUにおけるDXRの対応の可能性は低いように思えるが,直近の次世代GPUであるNaviで「上から下まで対応する」というどんでん返しの可能性も否定はできない。果たして……。
- 関連タイトル:
 Radeon Pro,Radeon Instinct
Radeon Pro,Radeon Instinct
- 関連タイトル:Radeon RX Vega
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー