












テストレポート
Ryzenはなぜ「ゲーム性能だけあと一歩」なのか? テストとAMD担当者インタビューからその特性と将来性を本気で考える
 |
とはいえ,CPUのマイクロアーキテクチャを従来の「Bulldozer」から「Zen」へと一新したこともあり,RyzenにはBulldozer世代のCPUにない,いろいろなクセがあるようだ。とくに4Gamer,そして4Gamer読者にとって極めて重要なPCゲームを前にすると,競合のCPUに対してベンチマークスコアが及ばないケースが目立つ。ゲーム以外のベンチマークだと全般的に好成績を収めているだけに,ここはとても対照的だと言えるわけだが,なぜRyzenは純粋なゲーム性能だけあと一歩なのだろう? そしてユーザー側では,Ryzenのより高い性能を引き出すために,何かできることはあるのだろうか。
いくつかのテストを行ってみたので,それを通じていろいろ考えてみることにしたい。
●目次
- SMTはゲームに悪影響を及ぼすのか?
- CCXの接続仕様はRyzenの性能をどこまで左右しているのか?
- 2基のCCXが実アプリケーションに与える影響は?
- Ryzenのキャッシュアクセス遅延は大きいのか?
- AMDからリリースされた最新BIOSは性能面でプラスの効果を生むのか?
- メモリクロックとメモリアクセスタイミングでRyzenの性能は変わるのか?
- 専用電源プラン「Ryzen Balanced」の効果はどれだけある?
- AMDはRyzenの現状をどう捉えているのか?
1. SMTはゲームに悪影響を及ぼすのか?
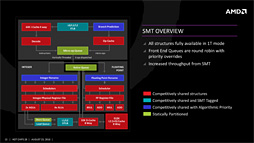
Ryzen 7の発売以降,Ryzenの性能については,ユーザーコミュニティの間でさまざまな説が取り沙汰された。その代表的なものの1つが,AMD製CPUとして初めての実装となる「SMT」(Simultaneous Multi-Threading,サイマルテイニアスマルチスレッディング)に関するものだ。
 |
もちろん,CPUが持つリソースには限りがあり,1基のCPUで2つのスレッドを同時に実装する場合,スレッドあたりの性能はSMTを無効化したときと比べて低下する。そこでWindowsでは,物理的なCPUコアと,SMTの有効化でWindowsから見えるようになったCPUコアを含む,専門用語で言うところの「論理(的な)CPUコア」を区別する仕様になっており,SMTを持つCPUでは,内部リソースの競合が起こりにくいようにスレッドをスケジューリングしているとされる。
言うまでもなく,SMTはIntelが言うところの「Hyper-Threading Technology」(以下,HTT)と完全に同じ技術だ。
豆知識になるが,SMTはもともと1995年にワシントン大学と旧Digital Equipment Corporation(DEC)が共同で開発した技術だった。1997年にIntelが旧DECの半導体部門を買収したところでSMTプロジェクトも引き継ぎ,Xeon,そしてPentium 4においてHTTという名称で市場投入したという歴史がある。
 |
そのような経緯があるので,「AMDのSMT」に目が行きがちとなるのは無理もないところだ。実際,ユーザーコミュニティの間では,「WindowsがRyzenのSMTを正しく認識しておらず,Windowsのスケジューラが『SMTのリソースが競合するような形』でスレッドを割り当ててしまっているのではないか」という疑惑が持ち上がった。
たとえば4つのスレッドがあったとして,物理CPUコアに対して1つのスレッドを割り当てていったほうが効率は高い。しかし,WindowsはRyzenを正しく認識できず,結果として4つのスレッドを2つの物理CPUコア上にある4つの論理CPUコアに割り当ててしまっており,それが性能低下を招いているのではないか? というわけである。
 |
| 「WindowsがRyzenのSMTを正しく認識していないのではないか疑惑」に対し,公式見解を出したのは,AMDで技術面の広報を担当するRobert Hallock(ロバート・ハロック,Head of Global Technical Marketing,AMD)氏だ。画像は2016年のオンラインイベントより |
 |
| Ryzen 7 1800X |
AMDによると,「WindowsがRyzenのSMTを正しく認識していないのではないか」という疑念は,開発者向けWebサイト「TechNet」でMicrosoftが配布している「Coreinfo」ユーティリティの出力が誤っていたために出てきたものだという。バージョン3.31以降のCoreinfoであれば,Ryzenに関する情報を正しくレポートするとされている。
実際はどうか。下に示したのは,「Ryzen 7 1800X」に対してCoreinfoを実行し,その出力データから論理−物理CPUコアマップ(Logical to Physical Processor Map)の部分を抜き出したものだ。左欄のアスタリスク(*)が論理CPU1個を表しており,物理CPU(Physical Processor)ひとつにつき2つの論理CPUがあるということがこれで分かる。
Logical to Physical Processor Map:
**-------------- Physical Processor 0 (Hyperthreaded)
--**------------ Physical Processor 1 (Hyperthreaded)
----**---------- Physical Processor 2 (Hyperthreaded)
------**-------- Physical Processor 3 (Hyperthreaded)
--------**------ Physical Processor 4 (Hyperthreaded)
----------**---- Physical Processor 5 (Hyperthreaded)
------------**-- Physical Processor 6 (Hyperthreaded)
--------------** Physical Processor 7 (Hyperthreaded)
Logical Processor to Socket Map:
**************** Socket 0
Logical Processor to NUMA Node Map:
**************** NUMA Node 0
ただ,実際にSMTを有効化したり無効化したりすると,ゲームのフレームレートが変化する現象は確認できる。ここでは例として「3DMark」(Version 2.3.3663)と「ファイナルファンタジーXIV:蒼天のイシュガルド ベンチマーク」(以下,FFXIVベンチ)を取り上げたい。
 |
テストにあたっては,CPU側の自動クロックアップ機能,具体的にはRyzen 7 1800Xの「Precision Boost」,i7-6900Kの「Enhanced Intel SpeedStep Technology」(以下,EIST)および「Intel Turbo Boost Technology」(以下,Turbo Boost)を有効化している。
また,メインメモリのアクセス設定は双方とも標準で対応できるDDR4-2400で,またメモリアクセスタイミングも15-15-15-35で揃えた。ただし,Ryzen 7 1800Xはデュアルチャネル,一方のi7-6900Kはクアッドチャネルと,メモリコントローラの構成が異なる点は押さえておいてほしい。
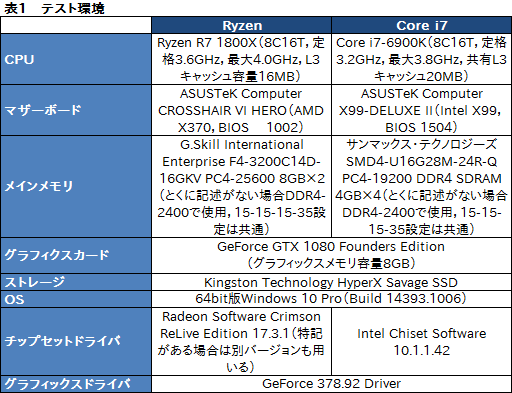 |
なお,本稿は同じ8コア16スレッド対応CPUであるRyzen 7 1800Xとi7-6900Kの振る舞いがどう異なるのかを見るのが目的であって,両製品の優劣を語る意図は一切ない。
また,以後本稿では,“Intel語”であるところのHTTをSMTと呼び分けるのが面倒であるという理由から,HTTもSMTと表記する。もう1つ,スペースの都合から,グラフ中に限り「Ryzen 7」は「R7」と表記するので,こちらもご注意を。
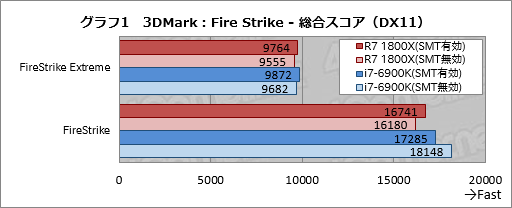
というわけで,まずは3DMarkにおけるSMT有効時と無効時の違いを見ていこう。DirectX 11世代のベンチマークである「Fire Strike」の“無印”と「Fire Strike Extreme」を実行し,総合スコアをまとめたものがグラフ1だ。
SMTに疑惑の目が向けられているRyzen 7 1800Xだが,Fire Strike,Fire Strime ExtremeともにSMT有効時のほうがスコア2〜3%ほど高い結果になった。むしろ,i7-6900KのFire Strikeのみ,SMT有効時よりも無効時のほうがスコアは約5%高くなっているが,なぜここだけ無効時のほうが高いのかについては何とも言えないところである。
 |
一方で,3DMarkから,事実上のGPUベンチマークテスト結果となる「Graphics test」のスコアを抜き出したグラフ2だと,CPU性能の違いでスコアが揺らぐことはまずないので,スコアには誤差程度の違いしか生じていない。
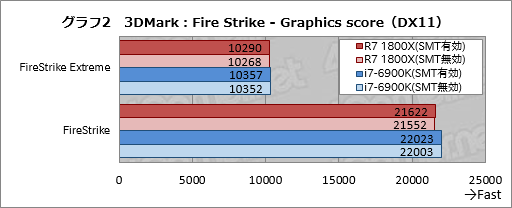 |
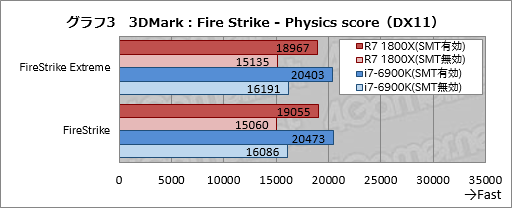
同じ3DMarkでも,CPUベンチマークといえる「Physics test」のスコアを抜き出したグラフ3は,とても興味深い。というのも,Ryzen 7 1800Xとi7-6900Kのいずれも,SMT無効時のスコアが有効時の約79%できれいに揃っているのである。つまり,SMTの効率はRyzen 7 1800Xとi7-6900Kとでほとんど変わらないことになると考えられる。
 |
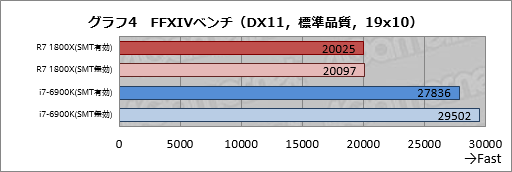
グラフ4は,FFXIVベンチをGPU負荷の低い「標準品質(デスクトップPC)」の解像度1920×1024ドット条件で実行したときのスコアを並べたものだ。
Ryzen 7 1800XだとSMT有効時と無効時で大きなスコア差はなく,誤差レベル。しかしi7-6900KだとSMT有効時よりも無効時のほうがスコアは約6%高い。これは無視できない数字だ。
 |
以上をざっくり見てみると,SMT有効,無効時の違いは,Ryzen 7 1800Xよりむしろi7-6900Kのほうが大きく出てしまったようだ。ただいずれにせよ,FFXIVベンチでSMTの有効化が負の影響をもたらすことがある原因は,実のところ,おおよそ分かっている。
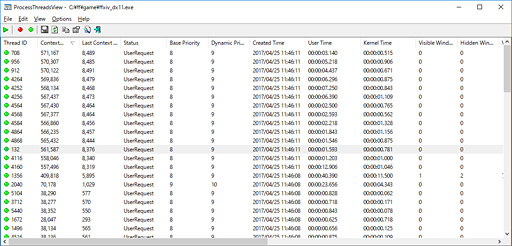
プロセスが生成するスレッドを一覧できるツール「Process
「Context Switches」という欄があるのを確認できるが,簡単に言うと,ここの数字が,そのスレッドがアクティブになった回数を示している。Context Switches欄の数字は動作している最中にどんどん増えていくが,その状態からContext Switches欄でソートすればアクティビティの高いスレッドの数が分かるわけだ。それによるとFFXIVベンチは,「使えるCPUコア」の数から1引いた数だけアクティブなスレッドを生成していると見られる。
 |
ちなみに,下のスクリーンショットはSMTを無効化のうえProcess
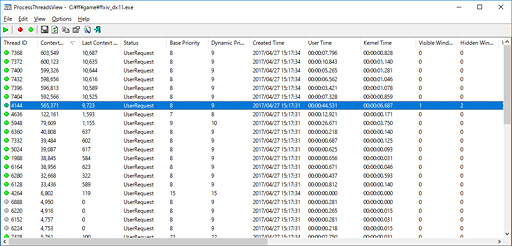 |
以上,FFXIVベンチは,「使えるCPUコア」の数から1引いた数だけアクティブなスレッドを生成していると見られる。だが,SMTで1つのCPUコアに2つのスレッドを割り振ってしまうとリソースの喰い合いが起こり,当然,1スレッドあたりの効率を低下させてしまう。その影響がとくにi7-6900Kで大きく出たというわけである。
このように,論理コア数分のアクティブスレッドを一気に作ってしまうようなタイトルだと,SMT有効時よりも無効時のほうがフレームレートが上がるという現象は起きやすい。そしてそれはRyzenに限った話ではなく,競合製品でも起こり,むしろ今回用意した2製品ではi7-6900Kのほうが影響は大きいということが分かるだろう。
3DMarkにおけるPhysics scoreからして,SMTの効率自体は,Ryzen 7 1800Xとi7-6900Kとで大差ない。また,「Windowsのスケジューラに問題はない」とするAMDの見解も,Physics scoreからして正しいだろう。
→目次に戻る
2. CCXの接続仕様はRyzenの性能をどこまで左右しているのか?
少しおさらいしておくと,Zenマイクロアーキテクチャでは,4基のCPUコア(+コアあたり512KBのL2キャッシュ)と容量8MBのL3キャッシュをひとまとめにしたモジュール「Core Complex」(公式略称「CCX」,以下略称表気)を採用している。
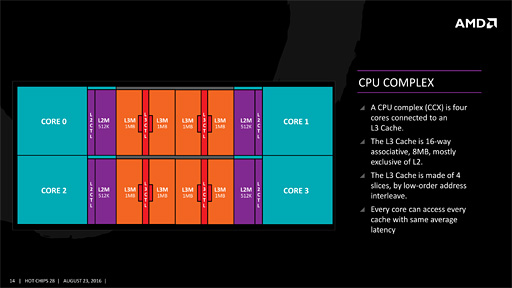 |
 |
この「内部の高速なインタフェース」をAMDは「Infinity Fabric」(インフィニティファブリック)と呼び,将来の同社製品において中核を成す技術と位置づけている。
あくまでもAMDが内部的に使うインタフェースなので,その技術的な詳細はあまり明らかになっていないのだが,データ転送用の「Data Fabric」と,CCXを始めとするモジュールの間の制御情報をやり取りする「Control Fabric」という,2つのデータバスがあることは公表済みだ。
Data Fabricのほうは帯域幅が広くかつ低遅延で,AMDが以前採用していたチップセット間相互接続インタフェースである「HyperTransport」をベースにしたキャッシュデータのコヒーレンシ(coherency,一貫性)維持機能を持つそうだ。
 |
いずれにせよ重要なことは,CCXとそれをつなぐInfinity Fabricの性能が,2基のCCXを1つのダイ上で統合するRyzen 7およびRyzen 5全体の性能を左右する要因となり得ることである。
たとえば,「同じデータを共有する,関連性の高い2つのスレッド」があったとして,それが異なるCCXに割り当てられた場合,Ryzenでは各CCX上のL3キャッシュに同じデータを持たなければならず,かつ両L3キャッシュ上にあるデータのコヒーレンシを維持しなければならない。したがって,当該データを頻繁に更新するようなケースでは,Data Fabricの持つコヒーレンシ維持機能を使ったデータ伝送が多発することになる。
一方,「同じデータを共有する,関連性の高い2つのスレッド」が同一CCX上にある2基の物理CPUコアに割り当てられた場合,データは1基のL3キャッシュ内で共有できるので上記のような問題は発生しない。
ちなみにWindowsは「キャッシュマップ」(Cache Map)という形で,キャッシュの構成を把握している。現在のCPUは,CPUID命令の拡張機能を使ってキャッシュの構成を取得できるようになっており,Windowsは起動時にその機能を使ってキャッシュの情報を得ているのである。
下の例はRyzen 7 1800Xとi7-6900Kのそれぞれに対してCoreinfoを実行し,「Logical Processor to Cache Map」の部分を抜き出したものだ。SMT有効だと論理プロセッサが表示されて分かりにくいため,ここでは両製品ともSMTを無効化して実行している点に注意してほしいが,違いはキャッシュと物理プロセッサの対応を示すアスタリスク(*)を見れば一目瞭然だ。「Level 3」の「Unified Cache」は,Ryzenだと4コア×2に分かれており,i7-6900Kだと全コアに対して1基になっている。
Ryzen 7 1800Xのキャッシュマップ
Logical Processor to Cache Map: *------- Data Cache 0 Level 1 32 KB Assoc 8 LineSize 64 *------- Instruction Cache 0 Level 1 64 KB Assoc 4 LineSize 64 *------- Unified Cache 0 Level 2 512 KB Assoc 8 LineSize 64 ****---- Unified Cache 1 Level 3 8 MB Assoc 16 LineSize 64 -*------ Data Cache 1 Level 1 32 KB Assoc 8 LineSize 64 -*------ Instruction Cache 1 Level 1 64 KB Assoc 4 LineSize 64 -*------ Unified Cache 2 Level 2 512 KB Assoc 8 LineSize 64 --*----- Data Cache 2 Level 1 32 KB Assoc 8 LineSize 64 --*----- Instruction Cache 2 Level 1 64 KB Assoc 4 LineSize 64 --*----- Unified Cache 3 Level 2 512 KB Assoc 8 LineSize 64 ---*---- Data Cache 3 Level 1 32 KB Assoc 8 LineSize 64 ---*---- Instruction Cache 3 Level 1 64 KB Assoc 4 LineSize 64 ---*---- Unified Cache 4 Level 2 512 KB Assoc 8 LineSize 64 ----*--- Data Cache 4 Level 1 32 KB Assoc 8 LineSize 64 ----*--- Instruction Cache 4 Level 1 64 KB Assoc 4 LineSize 64 ----*--- Unified Cache 5 Level 2 512 KB Assoc 8 LineSize 64 ----**** Unified Cache 6 Level 3 8 MB Assoc 16 LineSize 64 -----*-- Data Cache 5 Level 1 32 KB Assoc 8 LineSize 64 -----*-- Instruction Cache 5 Level 1 64 KB Assoc 4 LineSize 64 -----*-- Unified Cache 7 Level 2 512 KB Assoc 8 LineSize 64 ------*- Data Cache 6 Level 1 32 KB Assoc 8 LineSize 64 ------*- Instruction Cache 6 Level 1 64 KB Assoc 4 LineSize 64 ------*- Unified Cache 8 Level 2 512 KB Assoc 8 LineSize 64 -------* Data Cache 7 Level 1 32 KB Assoc 8 LineSize 64 -------* Instruction Cache 7 Level 1 64 KB Assoc 4 LineSize 64 -------* Unified Cache 9 Level 2 512 KB Assoc 8 LineSize 64
i7-6900Kのキャッシュマップ
Logical Processor to Cache Map: *------- Data Cache 0 Level 1 32 KB Assoc 8 LineSize 64 *------- Instruction Cache 0 Level 1 32 KB Assoc 8 LineSize 64 *------- Unified Cache 0 Level 2 256 KB Assoc 8 LineSize 64 ******** Unified Cache 1 Level 3 20 MB Assoc 20 LineSize 64 -*------ Data Cache 1 Level 1 32 KB Assoc 8 LineSize 64 -*------ Instruction Cache 1 Level 1 32 KB Assoc 8 LineSize 64 -*------ Unified Cache 2 Level 2 256 KB Assoc 8 LineSize 64 --*----- Data Cache 2 Level 1 32 KB Assoc 8 LineSize 64 --*----- Instruction Cache 2 Level 1 32 KB Assoc 8 LineSize 64 --*----- Unified Cache 3 Level 2 256 KB Assoc 8 LineSize 64 ---*---- Data Cache 3 Level 1 32 KB Assoc 8 LineSize 64 ---*---- Instruction Cache 3 Level 1 32 KB Assoc 8 LineSize 64 ---*---- Unified Cache 4 Level 2 256 KB Assoc 8 LineSize 64 ----*--- Data Cache 4 Level 1 32 KB Assoc 8 LineSize 64 ----*--- Instruction Cache 4 Level 1 32 KB Assoc 8 LineSize 64 ----*--- Unified Cache 5 Level 2 256 KB Assoc 8 LineSize 64 -----*-- Data Cache 5 Level 1 32 KB Assoc 8 LineSize 64 -----*-- Instruction Cache 5 Level 1 32 KB Assoc 8 LineSize 64 -----*-- Unified Cache 6 Level 2 256 KB Assoc 8 LineSize 64 ------*- Data Cache 6 Level 1 32 KB Assoc 8 LineSize 64 ------*- Instruction Cache 6 Level 1 32 KB Assoc 8 LineSize 64 ------*- Unified Cache 7 Level 2 256 KB Assoc 8 LineSize 64 -------* Data Cache 7 Level 1 32 KB Assoc 8 LineSize 64 -------* Instruction Cache 7 Level 1 32 KB Assoc 8 LineSize 64 -------* Unified Cache 8 Level 2 256 KB Assoc 8 LineSize 64
Windowsがキャッシュグループを把握している以上,先ほど例に挙げたような「関連性の強い2つのスレッド」があった場合,Ryzen 7やRyzen 5では当該2スレッドを片方のCCXに集中して割り当ててくれることを期待できるが,実際にそうであるとまでは断言できない。スレッドのスケジューリングはかなり複雑な動きをするので,調べようとしてもなかなか一筋縄ではいかないのだ。
2.1 RyzenのCCXを視覚化してみる
AMDはInfinity Fabricの技術的詳細を明らかにしていない一方で,少なくともData Fabricについては,「動作クロックが,Ryzen 7およびRyzen 5のメモリクロックと同期する」ことを明らかにしている。CPU側のメモリコントローラがDDR4-2667(実クロック1333MHz)でメインメモリにアクセスするとき,Data Fabricの動作クロックも1333MHzになるとのことだ。
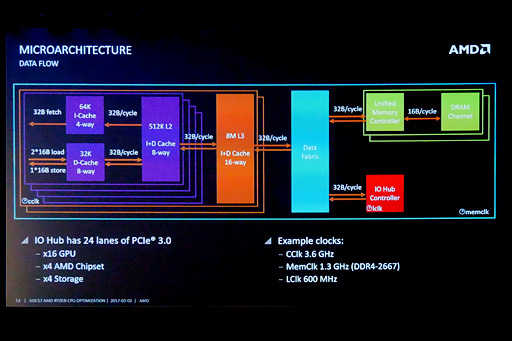 |
先に述べたとおり,「同じデータを共有する,関連性の高い2つのスレッド」が同一CCX上に存在する場合と,異なるCCXに分かれた場合とでは,スレッドの実行効率に違いがあると推測できる。異なるCCXに分かれた場合のスレッドの実行効率は,CCX間をつなぐData Fabricの帯域幅や遅延に左右されるだろう。
ちなみに,これら2基あるCCXの存在はRyzen 7およびRyzen 5において,割と簡単に視覚化できる。あるメモリブロックにデータを書き込むスレッド(以下,Wスレッド)と,そのメモリブロックからデータを読み出すスレッド(以下,Rスレッド)という2つのスレッドを作り,WスレッドとRスレッドを実行するコアの割り当てを変えていき,Rスレッドが1秒あたりに読み出す平均値を出すサンプルプログラムを作って実行してやればいい。
 |
なお,データを書き込むWスレッドと読み出すRスレッドの間でとくに同期は行わず,Wスレッドはひたすらデータをメモリブロックに書き込み続け,Rスレッドはひたすらデータを読み出し続ける。この2つのスレッドが同時に動いているだけだ。
横軸の「RP0」〜「RP7」はRスレッドが動作しているプロセッサコアの番号を,折れ線グラフとして示した「WP0」〜「WP7」が動作しているプロセッサコアの番号をそれぞれ示す。たとえば,横軸の値RP0の位置を縦に見ていくと,WP1〜WP7のときの,Rスレッド1秒あたりの読み出し量(MB/s)が分かるという仕組みだ。
それを踏まえて確認してみると,RP0かつWスレッドがWP1,WP2,WP3のとき,RP0は1700〜1800MB/s程度で読み出しできているのに対し,WスレッドがWP4,WP5,WP6,WP7のときには約1020MB/s前後でしか読み出しできていない。同様にRスレッドがRP1だと,WスレッドがWP4,WP5,WP6,WP7のときには約1020MB/s前後でしか読み出せないという具合に値が変化し,ちょうど真ん中でクロスするようなグラフが得られている。
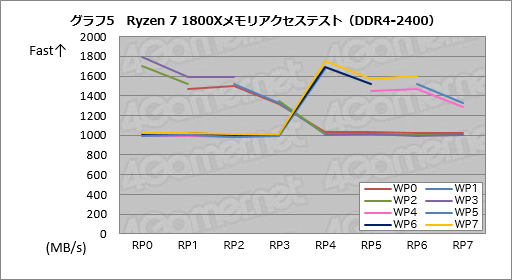 |
こうやって並べてみると,WスレッドとRスレッドが同一CCX内にある場合でもデータをやり取りする速度にコアごとの規則的なバラツキがあるようにも感じられるが,その原因は今のところ分かっていない。ただ,「CCXの境界」がはっきりと見てとれるのは興味深いところだ。
さて,前述のとおり,Data Fabricの動作クロックはメモリクロックと同期しているとのことである。ならばCCXをまたぐデータ転送効率は,メモリクロックを上げれば向上するはずだ。
そこで次に,メモリコントローラのDDR4-2133設定時と,オーバークロック動作となるDDR4-3200設定時でも同じテストを実行してみることにした。,その結果がグラフ6,7である。
DDR4-2133設定時のスコアはグラフ5で示したDDR4-2400設定時とほとんど同じだが,DDR4-3200まで引き上げると,CCXをまたぐデータ転送の効率が1100MB/s超にまで上昇した。DDR4-2400設定時に対してざっくり1割程度は成績がよいという結果だ。
DDR4-2400設定時におけるData Fabricの動作クロックが1.2GHzなのに対して,DDR4-3200設定では1.6GHzと約1.33倍になるので,1割程度のスコア向上が得られるというのは,ほぼ妥当なところではないかと考えている。
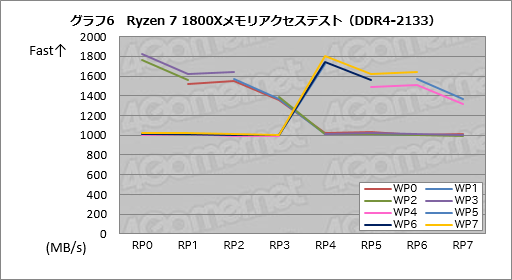 |
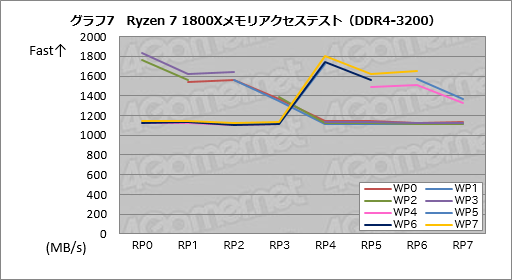 |
同じテストをi7-6900KのDDR4-2400設定で実行した結果がグラフ8で,当然のことながらRyzen 7 1800Xのそれとは異なっている。
なお,どういうわけかRスレッドがP3のときだけ成績がいいという不思議な結果にはなったが,この原因も今のところよく分からない。
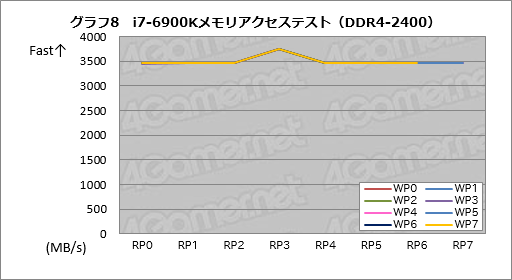 |
→目次に戻る
3. 2基のCCXが実アプリケーションに与える影響は?
では,2基のCCXは実アプリケーションにどのような影響を与えるのだろうか? これを検証するのはとても難しい。というのは,プロセスやプロセスから起動されるスレッドを,どのCPUで実行するかを決めているのはOSのスケジューラだからだ。
ただ,Windowsでは「Affinity Mask」(アフィニティマスク)と呼ばれる値をプロセスに対して設定することで,当該プロセスや「当該プロセスから起動されるスレッドを実行するCPU」を制限できる。
Affinity Maskは,Win32 APIの「SetAffinityMask」から設定できるほか,Windowsのコマンドコマンドプロンプトから実行できる「start」コマンドの「/affnity」スイッチでも設定できるようになっている。
start /affinity 0x00FF (実行ファイル).exe
ここで/affinityに続く16進数「0x00FF」は,それに続く実行ファイル(≒プロセス)が利用できるCPUを指定するAffnity Maskである。この16進数を2進数に直して,オンになっているCPUコアでしか,そのプロセスは実行されない。なお,ここでCPUコアに物理,論理の区別はない。
論理プロセッサ数16基の場合における指定例は次のとおり。アプリケーション実行時に/affinityスイッチを付ければ,アプリケーションのプロセスが生成するスレッドを1基のCCXに偏らせたり,2つのCCXに分散させたりできるようになる。
- 0x00FF:00000000_11111111(P0〜P7で実行)
- 0xF00F:11110000_00001111(P0〜P3,
P12〜P15で実行) - 0x5555:01010101_01010101(P0,
P2, P4, P6, P8, P10, P12, P14で実行) - 0x0055:00000000_01010101(P0,
P2, P4, P6で実行) - 0x5005:01010000_00000101(P0,
P2, P12, P14で実行) - 0x0F:0000_1111(P0〜P3で実行)
- 0xCC:1100_1100(P2,
P3, P6, P7で実行)
問題は,/affinityスイッチをアプリケーションがすんなりと受け入れてくれるかだが,グラフ1〜4で使った3DMarkとFFXIV蒼天のイシュガルド ベンチは受け入れてくれたので,スコアの変化を見ることが可能だった。
そこで,先ほどと同じく,メモリコントローラの設定をDDR4-2400としたうえで,今回はFFXIV蒼天のイシュガルド ベンチのテスト結果から見ていくことにしよう。ここでもグラフィックス設定は標準品質(デスクトップPC),解像度は1920
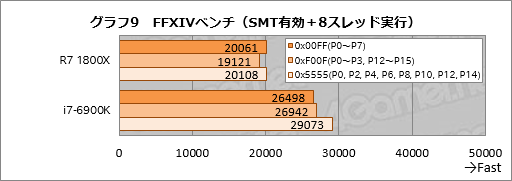
グラフ9はSMTを有効化のうえ,/affinityスイッチを使って割り当てる論理コアを切り換えながら8スレッドでFFXIVベンチを実行したときのスコアだ。
0x00FFは,Ryzen 7 1800Xだと8スレッド全部を片方のCCXに割り当てる格好となる。一方の0xF00Fだと4スレッドずつ2基のCCXへ割り当てるという,Ryzen 7 1800Xにとって苦手なタイプの割り当てだ。さらに0x5555はスレッドを論理CPUコア1つ飛ばしで割り当てるため,結果としてSMT無効時と似た実行形態になる。前述のとおり,FFXIVベンチは使えるCPUコアに対してアクティブスレッドをどかっと立ち上げるので,Ryzen 7 1800X,i7-6900Kとも,0x5555設定時のスコアが最も高い。これは納得だろう。
残る2設定だと,Ryzen 7 1800Xでは0xF00Fのスコアが対0x00FFで約95%と,スコア差が生じている。
一方のi7-6900Kにおいては事実上のSMT無効時となる0x5555が好成績なのはともかくとして,0x00FFより0xF00Fのほうが若干だが好成績を残している。このように,ときおりi7-6900Kでもコア間の対称性を疑わせるような結果が出るが,その理由は正直分からない。
 |
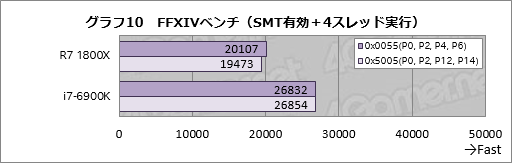
次にグラフ10は,SMT有効かつ論理CPUコア1つ飛ばし,かつ4スレッドで実行したときのスコアである。Ryzen 7 1800Xの場合,0x0055だと1基のCCXに4スレッドを割り当てて実行する設定,0x5005だと2スレッドずつ2基のCCXに分離して実行する設定となるが,ここでもi7-6900Kだと両条件でスコアに大きな違いは生じていないのに対して,Ryzen 7 1800Xだと0x5005設定時のスコアが0x0055設定時に対して約97%に落ちている。
これが2基のCCXにスレッドを分けたときのペナルティということになるだろう。
 |
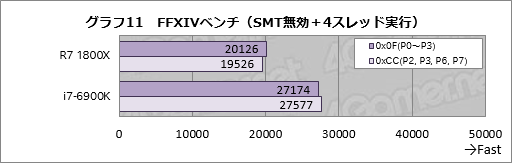
SMTを無効化のうえで4スレッド実行したときの結果がグラフ11だ。
Ryzen 7 1800Xの場合,0x0Fは片方のCCXに4スレッド割り当てる設定,0xCCが2スレッドずつ2基のCCXへ分割する設定だが,スコア傾向はグラフ10に似た形で,0xCC設定時のスコアは0x0F設定時比で約97%となった。
i7-6900Kも0xCCに対して0x0Fのほうが1.5%ほどスコアが高いが,その理由は何とも言えない。ただ,i7-6900Kのアーキテクチャだと8個の物理CPUコアに対する非対称性はなく,またL2キャッシュまで各CPUコアが独立して持つ構成なので,アーキテクチャが原因というわけではないだろう。
 |
以上のテストから,「Ryzenでは2基のCCXにまたがるような形でスレッドが割り当てられた場合,スコア面で不利になる」ことが実アプリケーションで確認できる。続いて,3DMarkのFire Strikeから,純然たるCPU性能のテストになるPhysics testでAffinity Maskを指定し,「実行するCPUコア」を変えるとどうなるのか見ていこう。
グラフ12はSMT有効時のテスト結果,グラフ13は無効時の結果である。SMT有効時において,0x00FFと0xF00Fでは後者が不利になるはずだが,ここではスコア差が非常に小さかった。これは「1基のCPUに2スレッドを割り当ててしまう」ことによるペナルティがCCXをまたぐペナルティよりも大きいためだろう。
SMT有効時と無効時の結果から,3DMarkのPhysics testはスレッドの独立性が高いテストだろうと推測している。つまり,個々のスレッドが独立したデータを使って演算を行うようなテストだ。この種のアプリケーションではCCX間のデータ転送は多発しないので,スレッドがCCXをまたいでいても性能に対する負の影響は小さいはずということである。
 |
 |
さて,前段で確認したとおり,Ryzen 7ではメモリコントローラのアクセスクロック設定を高めることで性能向上を図ることができる。純然たるメモリテストだと,DDR4-2400に対してDDR4-3200だと約1割程度のスコア向上を確認できた。
ここまでのテストは,Ryzen R7 1800Xとi7-6900Kが双方とも標準で対応しているDDR4-2400設定で実行してきたが,DDR4-3200設定とDDR4-2133設定で同じテストを実行してみることにしよう。前項で確認したとおり,Ryzenではメモリクロックを引き上げることでData Fabricのクロックが上がり,CCX間のデータのやり取りの速度が上がるため,スレッドがCCXをまたいだケースにおける性能は向上するはずだ。DDR4-2133とDDR4-3200の結果を比較することで,Data Fabricのクロックを含めたメモリクロックの影響を見ることができるだろう。
テストの順番を元に戻してここは3DMarkのFire Strikeからだが,グラフ14を見ると,1基のCCXに4スレッドを固めることになる0x0F設定において,Ryzen 7 1800XでDDR4-3200設定時のスコアはDDR4-2133時と比べて約1%高い。2基のCCXに2スレッドずつ割く0xCCでも約1%なので,ほとんど変わらないと言っていい。
i7-6900KでもDDR4-3200設定時のスコアはDDR4-2133比で約1%高いので,ここにおいて両者の違いはなさそうだ。前述のとおり,Physics testではデータの独立性が高いと推測できるため,メモリクロック引き上げの効果が主であって,Data Fabricのクロックを引き上げた影響はあまりないのだろう。
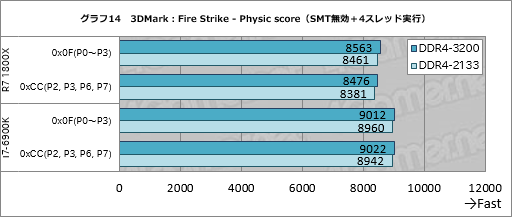 |
次にグラフ15がFFXIVベンチの結果だが,こちらだと,1基のCCXに4スレッドを固めることになる0x0F設定時にRyzen 7 1800XではDDR4-3200のスコアがDDR4-2133比で約14%高い。また,2基のCCXに2スレッドを分離させる0xCC設定だと,DDR4-3200のDDR4-2133に対するアドバンテージは約15%と,両者の間には誤差程度の違いしかなかった。
ただ,i7-6900Kだと,DDR4-3200とDDR4-2133の違いは5〜6%程度に留まるので,ことFFXIVベンチにおいては,メモリクロック設定引き上げの恩恵はCoreよりRyzenのほうが大きいとは言えるだろう。
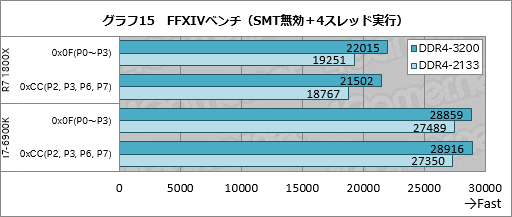 |
というわけで,今回試みたような極端な状況を作ると,Ryzenの抱えるマイクロアーキテクチャレベルの弱点,具体的には「CPUが4コアずつ2基のCCXに分かれている」という弱点が顕在化するものの,それが実際のゲームアプリケーションで極端な違い生むことはあまりなさそうだ,ということが,ここまでのテストからは見える。
メモリテストのような極端な状況で最大1割程度,実アプリケーションでは種類により影響ゼロからせいぜい数%といったところが影響の範囲だろう。
冒頭で,RyzenとCoreプロセッサシリーズとの間で,ゲームおける性能の違いが大きいのはなぜかと疑問を呈したが,少なくともRyzenでCPUコアが4基ずつ2つのCCXに分かれていることがゲームに大きな負の影響を与えていたりはしないということが,テストの結果から言えると思う。
なお,今回のテスト結果からは,「アプリケーションの実装にあたって,Windowsが把握しているキャッシュマップを参照し,関連性の高いスレッドを1基のCCXへ集中させるよう,Affinity Maskを設定すれば効率が上げられる」ことも言える。これは,AMDがGDC 2017のRyzen関連セッションで語っていたものだが,一般ユーザーがstartコマンドでAffnity Maskをいじってもアプリケーション性能の向上にはさして寄与しないはずだ。Affinity Maskが役立つとすれば,SMTが負の影響を与えるようなゲームのAffinity Maskに0x5555を指定して意図的にSMT無効と同じ状況を作り出せる程度だろう。
→目次に戻る
4. Ryzenのキャッシュアクセス遅延は大きいのか?
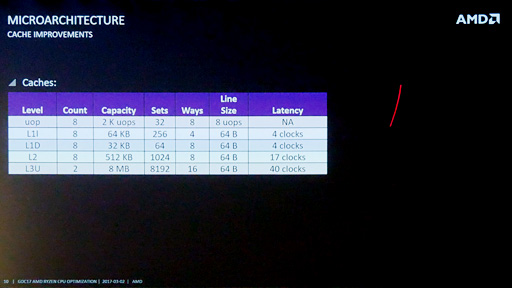
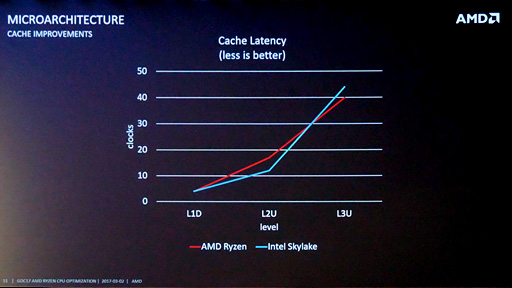
「Sandra 2016 SP1」(Build 2220)を用いてテストしたときには,Ryzen 7 1800Xのキャッシュおよびメモリアクセスに遅延が大きいというテスト結果が出た。しかし,AMDが出している資料だと,キャッシュのアクセス遅延は決して大きくないとされている。
 |
 |
何故このような違いが生じているかだが,原因として考えられるのは,Ryzen 7 1800Xの搭載するL3キャッシュ合計16MBが,ここまで繰り返してきたとおり8MBずつ2基のCCXに分かれており,その間をData Fabricが結んでいるから,というものだ。
Sandra 2016 SP1が/affinityスイッチを受け入れてくれればはっきりするはずなのだが,残念ながら受け入れてくれない。ただ,キャッシュ容量レンジ内の遅延がメモリクロックに引っ張られて変わるのであれば,2基のCCXに分かれていることが遅延として顕れていると推測できるはずである。
通常はメモリクロックを変更してもキャッシュ容量レンジ内のアクセス遅延はほとんど変わらない。だが,Ryzenの場合はメモリクロックに合わせてData Fabricのクロックが変わるため,Data Fabricがキャッシュのアクセス遅延に影響を与えているのであれば,メモリクロックに引っ張られて変化することになる。
そこで今回は,DDR4-3200設定とDDR4-2400設定,DDR4-2133設定のそれぞれでSandra 2016 SP1の「Cache/Memory Latency」を実行してみることにした。
ここではメモリクロックがキャッシュに影響を与えているか否かを見るだけなので,メモリアクセスタイミングは本稿で共通に採用している15-15-15-35固定とし,メモリクロックのみ変えている。その結果がグラフ16で,縦軸の単位はAMDの前出のスライドに合わせてclocksにした。いつものナノ秒(ns)ではない点に注意してほしい。
結果を見ると,少なくとも「4MB Range」までのところで,メモリアクセス設定による違いはないと断言できるレベルだ。しかし「8MB Range」レンジ以上はメモリクロックに引っ張られて大きく変わってしまっており,明らかにおかしい。
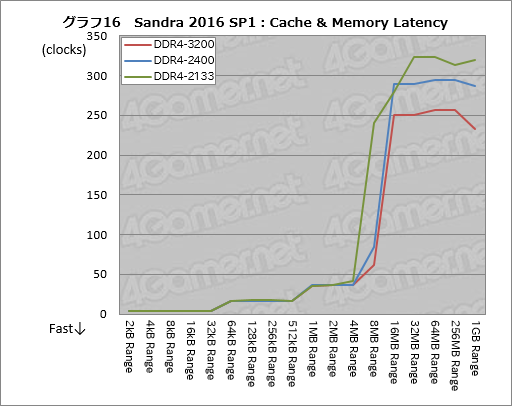 |
L2キャッシュに収まる512kBレンジは17クロックで,これはAMDの出している資料と完全に一致する。また,L1データキャッシュに収まる32kB Range以内は4クロック。こちらもAMDの資料と一致する。信用できないのは8MB Rangeと16MB Rangeで,SandraではRyzenが持つL3キャッシュのアクセス遅延を正しく計測できていないと結論していいだろう。
 |
latency.exeは極めて古典的な方法でアクセス遅延を測定しているようで,そのため単独の計測値にそれほど高い信用は置けないのだが,/affinityスイッチを付けて実行すると,割と安定してCCXあたり8MBあるL3キャッシュの遅延を出力してくれるようになる。
そこで今回は,
start /affinity 0x0001 latency.exe
として実行している。先の説明で分かるかとは思うが,この指定だとlatency.exeはCPUコア0でしか実行されなくなる。その結果が下のスクリーンショットだ。L3キャッシュの容量は8MBで,遅延(latency)は32クロックとレポートしてきている。
AMDの示しているスライドだとL3キャッシュの遅延は40クロックなので,latency.exeの出力の32 cycle(≒32クロック)も決して正しくなはさそうだが,少なくともData Fabricの影響を受けていないのではないかと思う。
最終的にはアクセス遅延を図るツールを自作するほかない気もしているが,今回は時間の都合もあるので,ツールの自作はパスさせていただきたい。
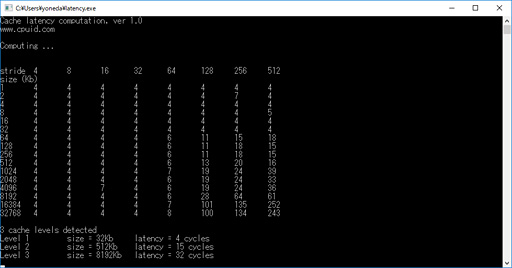 |
以上,Sandra SP1の4MB Rangeと8MB RangeはRyzenのL3キャッシュアクセス遅延を正しく表したものではない。また,CPUコアとは異なるCCX上のキャッシュのデータはData Fabricを通るため,アクセス遅延はどうしても大きくなってしまう。
とはいえ前段でも確認したとおり,アプリケーションを異なるCCXに分割して実行しても,そのペナルティはせいぜい数%程度である。8MB×2基のL3キャッシュがRyzenの性能の足を大きく引っ張っているわけではない,ということもまた言えるのではないかと思う。
→目次に戻る
5. AMDからリリースされた最新BIOSは性能面でプラスの効果を生むのか?
前段でキャッシュのアクセス遅延をテストしたが,メモリアクセス遅延については,北米時間3月30日に動きがあった。公式blogの記事ポストでAMDが,RyzenシリーズのBIOS,より正確に言えば「AGESA」(AMD Generic Encapsulated Software Architecture)のアップデートを告知したのだ。
AGESAというのは「Athlon 64」以降で採用された,AMD製CPUの起動時に実行されるコード「Bootstrap Loader」(ブートストラップローダー)の一種で,AMD製CPUコアやメモリインタフェース,I/Oの初期化などを行っている。AGESAはAMDからマザーボードメーカーに提供され,各マザーボードのUEFIへ組み込まれることになる。
3月下旬に予告のあったRyzen向けAGESAのバージョンは1.0.0.4。このバージョンでは,下に挙げる4点の改良が入っているという。
- DRAM(DDR4-SDRAM)のアクセス遅延を約6ns低減
- FMA3命令でRyzenがハングアップするバグの修正
- S3スリープ後,動作クロックが異常上昇してしまうバグの修正
- 「Ryzen Master Utility」ソフトウェアにおいてHPET(High-Precision Event Timer)を不要化
2.と3.は問題点の修正なので,「直ってよかった」という話だ。性能に影響を及ぼすのは1.と4.である。
4.のHPETというのは現在のPCが持つクロックソース――CPUの動作クロックと直接の関係はなく,システムが時間経過を知るために使う時計のこと――の1つだ。豆知識だが,現在のPCには歴史的経緯から,IBM PC譲りの“化石”と言える「Programmable Interrupt Timer」(以下,PIT)のほか,Pentium時代に登場したHPET,そして最新の「Time Stamp Counter」(以下,TSC)という3つのクロックソースハードウェアがある。
これらのうち,PITは後方互換性のためだけのもので,粒度が粗いため,基本的にOSが使うことはない。HPETはPITの抱える粒度の問題を解決するためチップセット側で装備することになった高精度タイマー,そしてTSCはCPU内部の基準クロックを使ったタイマーである。
「高精度タイマー」と聞くとさも優秀そうだが,今日(こんにち)のPCではPETよりもTSCのほうが粒度は小さい。つまりタイマー精度は高い。なので,Windowsなど最近のOSではHPETもまた標準では使われなくなっている。
 |
そこで,AGESA 1.0.0.4ではHPETを使わずともRyzen Master Utilityを利用できるようにした。Ryzenユーザーの中にはRyzen Master Utilityを使うためにHPETを有効化してしまった人もいるかと思うのだが,HPETの有効化は負の効果のほうが大きいので,無効化しておいたほうがいいだろう。
 |
本稿を執筆している4月下旬時点で,今回テストに用いているASUSTeK Computer(以下,ASUS)製マザーボード「ROG CROSSHAIR VI HERO」向けにはAGESA 1.0.0.4対応BIOS(UEFI)がリリースされていないのだが,今回はASUSの厚意で,AGESA 1.0.0.4を含むテスト版BIOSである「1102」を提供してもらうことができた。
これを使えば,既存の1002版BIOSとの間で,AGESA 1.0.0.4導入効果があるのかを確認することができるはずだ。
なお,今回テストに用いている1102版BIOSはあくまでもテスト版であり,最終的にリリースされる公開版とは,安定性はもちろん,性能も異なる可能性があるとのこと。なのでこのパートで取りあげるテストのスコアはあくまで参考のためのものとなるので,その点は押さえておいてほしい。
さて,メモリアクセス遅延検証には,前段でも使ったSandra 2016 SP1のCache & Memory Latencyを使う。前段で8MB Rangeと16MB Rangeは信用できないと述べたが,メインメモリに対するアクセス遅延計測結果は安定しているので,ほぼ信用できるものと考えられるからだ。ここでは,まず間違いなくテストサイズがキャッシュ容量を外れる,つまりメインメモリの遅延を示している32MB Range以上のデータを使うことにしたい。
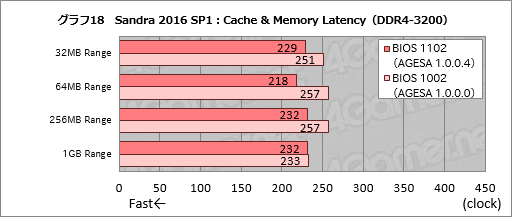
グラフ17はDDR4-2400(15-15-15-35)で1002と1102の両バージョンを比較したもの。グラフ18はメモリアクセス設定をDDR4-3200(15-15-15-35)へ変更したときの結果である。
AMDはAGESA 1.0.0.4により約6nsの改善が得られるとしているので,30クロック前後の改善が見られればAMDの主張どおりということになるが,DDR4-2400設定時を見るグラフ17だと,32MB Rangeで22クロック,64MB Rangeで21クロック,256MB Rangeで15クロック,1GB Rangeで7クロックの改善を見た。テスト版BIOSであることを踏まえても1GB Rangeのスコアは期待外れながら,それ以外では意味のある遅延低減を実現できていると言ってよさそうだ。
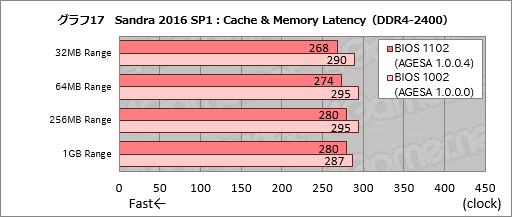 |
DDR4-3200設定時のスコアを見るグラフ18だと,32MB Rangeで22クロック,64MB Rangeで39クロック,256MB Rangeで25クロック,1GB Rangeで1クロックの改善というスコアだ。1GB Rangeの効果はさらに薄まったものの,32〜256MB Rangeで平均するとAMDが主張するとおりの結果が得られたと言えるだろう。
 |
→目次に戻る
6. メモリクロックとメモリアクセスタイミングでRyzenの性能は変わるのか?
前段で新BIOSに含まれるAGESA 1.0.0.4の効果を調べたが,では,メモリアクセスタイミングやメモリクロックの違いは実アプリケーションに対してどのような変化をもたらすだろうか。
本稿ではここまで,i7-6900Kと比較する目的もあり,メモリアクセスタイミングを15-15-15-35設定で統一してきた。だが今回Ryzen R7 1800Xをテストするにあたって4Gamerで独自に用意したG.Skill International製のDDR4メモリモジュール「F4-3200C14D-16GKV」は,DDR4-3200で14-14-14-34設定をサポートする,低遅延設定がウリの製品だ。ここからは,メモリのクロック設定とアクセス遅延設定を切り換えながらテストを行ってみたいと思う。具体的には,メモリクロック設定はDDR4-3200とDDR4-2667,DDR4-2400,メモリアクセス遅延設定は14-14-14-34と15-15-15-35,17-17-17-39,合計9パターンでスコアを取って比較することにしたい。
まずは原稿執筆時点の公式最新版BIOSである1002(AGESA 1.0.0.0)からだ。
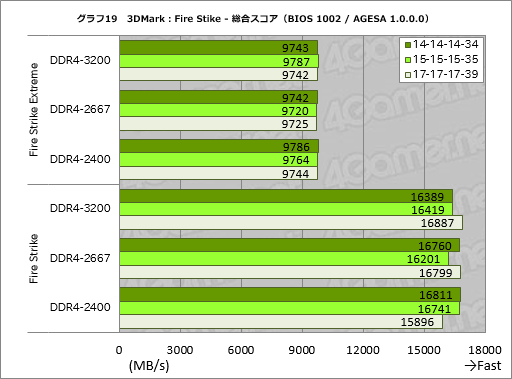
グラフ19は3DMarkのFire Strikeでメモリ設定ごとの総合スコア変化を見たものとなる。グラフィックス描画負荷が高くなり,スコアにおけるCPUの寄与が少なくなるFire Strike Extremeだとほぼ横並びだが,相対的にCPUがスコアを左右しやすくなる“無印”だと,メモリ設定による違いが若干出てきた。
気になるのは,Fire Strike無印のDDR4-3200設定だと17-17-17-39が最もスコアは高く,14-14-14-34が最もスコアが低くなっているところだ。
ちなみに,執筆時点におけるリリース版のBIOSであるバージョン1002は,メモリアクセスタイミングの設定を14-14-14-34にするとやや不安定で,正常に起動しない現象が見られた。メモリモジュールは14-14-14-34設定に対応しており,ASUSのCROSSHAIR VI HERO対応モジュールリストにもF4-3200C14D-16GKVはあるので,BIOSに何らかの問題があり,それが性能面にも影響している可能性はある。
 |
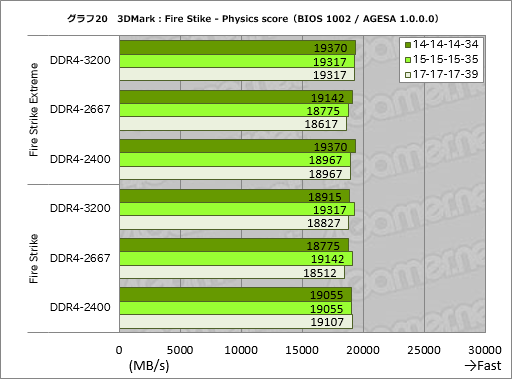
次にグラフ20はグラフ19から事実上のCPUテストであるPhysics testのスコアを抜き出したものとなる。
テストの立ち位置が立ち位置なので,総合スコアよりはかなり分かりやすいスコアになった。ただ,Fire Strike Extremeだといずれのクロック設定でもアクセス遅延設定を詰めるとスコアが上向く傾向を示すのに対し,Fire Strikeのほうは必ずしもそうなっておらず,とくに14-14-14-34設定のスコアが振るわない。どうしてこうなるのかは不明だ。
 |
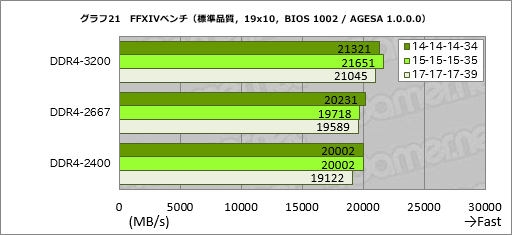
実アプリケーションの例としてFFXIVベンチの結果も見ておこう。グラフ21は標準品質(デスクトップPC)の解像度1920×1080ドット条件におけるスコアをまとめたものだが,こちらはDDR4-3200設定の14-14-14-34設定がスコアを落とす以外は,全体的に妥当なバーの並びとなった。
それぞれのスコア差はわずかとはいえ,最下位のDDR4-2400設定17-17-17-39に対し,最上位のDDR4-3200設定15-15-15-35は約13%高いスコアになっているので,決して無視できないレベルであるとも言えるだろう。
 |
メモリアクセス遅延の低減を確認できたテスト版BIOSである1102(AGESA 1.0.0.4)ではどうだろうか。
まず体感レベルの話をすると,1002のときにあった「14-14-14-34設定を行うとシステムが起動しなくなることがある」問題は,1102版BIOSを導入するとまったく見られなくなった。この点から,おそらくはAGESA 1.0.0.4の効果でDDR4-3200設定時の動作の安定性が増している可能性は高いと考えている。
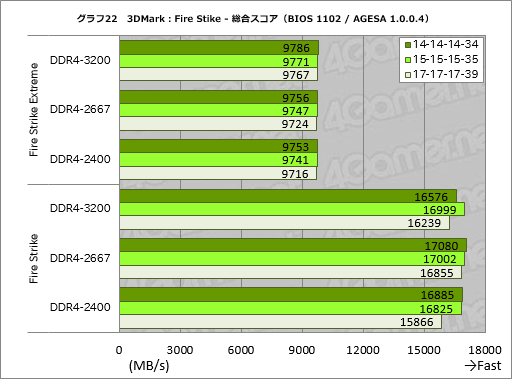
グラフ22はFire Strikeの総合スコアをまとめたものだが,先ほどと同じく,Fire Strike Extreme時のスコアはほぼ横並びだが,よく見るとメモリアクセス遅延設定を反映しているのが見てとれよう。
一方“無印”のほうだとスコアはやや荒れ,DDR4-3200の14-14-14-34設定が振るわない格好となったが,それ以外ではアクセス遅延設定を詰めることでスコアが上がるのを確認できている。
 |
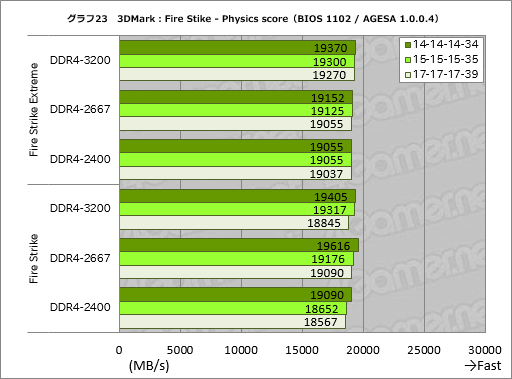
Physics testのスコアを抜き出したものがグラフ23だが,ここではメモリクロックを上げるほど,またアクセスタイミングを詰めるほど好成績を残すというきれいな結果になった。Physics testはCPUのベンチマークなので,メモリ性能の影響が分かりやすく出るのだろう。
 |
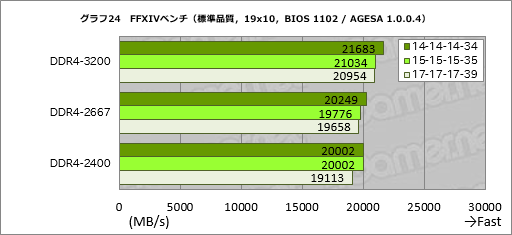
Physics testよりさらににきれいな結果が得られたのが,FFXIVベンチである(グラフ24)最下位であるDDR4-2400の17-17-17-39設定に対して最上位であるDDR4-3200の14-14-14-34設定は約1.13倍のスコアになっており,メモリ設定だけでざっくり1割以上の性能向上が得られた格好だ。
 |
繰り返すが,本稿で使っているBIOS 1102はテスト版なので,純然たる性能評価には向いていない。ただそれでも,「AGESA 1.0.0.0だったBIOS 1002と比べ,BIOS 1102はメモリクロックの最適化や,メモリアクセスタイミングのチューニングが行われ,より素直にメモリ性能が出る傾向にある」とは言ってしまって問題ないはずである。
→目次に戻る
7. 専用電源プラン「Ryzen Balanced」の効果はどれだけある?
お次は,北米時間4月6日に登場し,26日にはチップセットドライバ同梱版も登場した,Ryzen専用の64bit版Windows 10向け電源プラン設定「Ryzen Balanced」についてだ。
AMDはRyzenのリリース直後から,Windows標準の電源プランである「バランス」ではRyzenのポテンシャルを活かすことができないため,「高パフォーマンス」に切り換えるよう呼びかけてきた。高パフォーマンスだと確かにPステートは落ちないが,Ryzenの消費電力はCステートで制御されるため,CPUの消費電力が高くなりすぎることはないというのが,AMDの言い分だ。
混同しやすいので説明しておくと,
- Pステート(P-state):現在のCPUがサポートする,「負荷状況に応じてCPUの動作クロックを動的に変える機能」の設定状態
- Cステート(C-state):現在のCPUがサポートする,「アイドル時にキャッシュへの供給電力を落とすなどといった省電力機能」の省電力設定状態
である。電源プランで高パフォーマンスを選択すると,CPUの動作クロックは「P0」と呼ばれる最高クロックの状態で固定となるが,その状態でもRyzenを始めとする最近のCPUではアイドル時にCステートが変化することでCPUの消費電力を抑えられる仕組みになっている。
とはいえ,Pステートが落ちないとCPUクロックが常に高く保たれるので。やはり消費電力的には不利だ。そこで,RyzenシリーズのCPUの性能を大きく損なってしまうことなしにPステートも制御できる電源プランとしてAMDから登場したのがRyzen Balancedというわけである。
今回のテストにあたっては単体の電源プラン「Ryzen_Balanced_Plan.ppkg」が入った「Ryzen_Balanced_Plan.zip」をダウンロードしたが,現在はチップセットドライバと一緒に導入してしまうのが手っ取り早い。
 |
AMDはゲームについて,「Ryzen Balancedがフレームレートに与えるマイナスの影響は,Windows標準のバランス設定に比べて小さい」と主張している。そこで,ここではFFXIVベンチのほか「Far Cry Primal」も加えて,ゲームの性能と同時に消費電力の変化も調べてみることにした。Far Cry Primalでは,「ノーマル」プリセットの解像度1920
さらにもう1つ,実在のアプリケーションを用いてテストするPC総合ベンチマークソフト「PCMark 8」(Version 2.7.613)も実行して,高パフォーマンスとRyzen Balanced,そしてAMD非推奨のデフォルト設定であるバランス,以上3つの電源プランがどのような違いを生むか調べてみることにしよう。
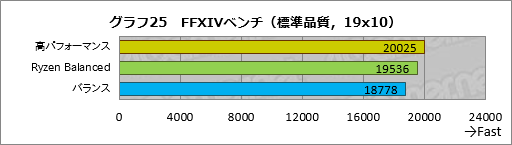
まずはFFXIVベンチからだ。テスト条件は標準品質(デスクトップPC)の1920
ご覧のとおり,スコアはきれいな階段状に並んだ。バランスを基準にすると,Ryzen Balancedは約4%,高パフォーマンスは約6%高いスコアだ。
 |
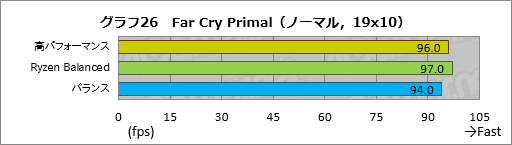
次にFar Cry Primalは「ノーマル」プリセットの解像度1920
Ryzen Balancedが高パフォーマンス設定を上回っているのが意外かもしれないが,違いはわずかに1フレームだけなので,測定誤差の範囲と見ていい。ここは「高パフォーマンス設定とRyzen Balancedが肩を並べている」という解釈が正しいはずだ。
 |
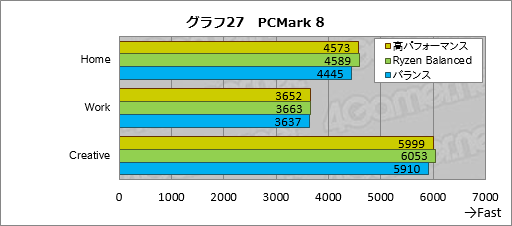
PCMark 8では,「Home」「Work」「Creative」の3ワークロードをいずれも2回ずつ実行し,スコアが高いほうを採用することにした。その結果がグラフ27で,ここではすべてのテストにおいてわずかながらRyzen Balancedが最も高いスコアを示した。
高パフォーマンスとはほぼ横並びと言ってしまってもいいとは思うが,少なくとも,それでも一般アプリケーションを前にしたとき,高パフォーマンスとRyzen Balancedに大差がないとは言えるだろう。
 |
電源プランによって消費電力はどのような制御されるのか。今回は,Ryzen 7 1800Xのレビュー時と同じく,クランプメーターを用いてEPS12Vの電流測定を行っている。
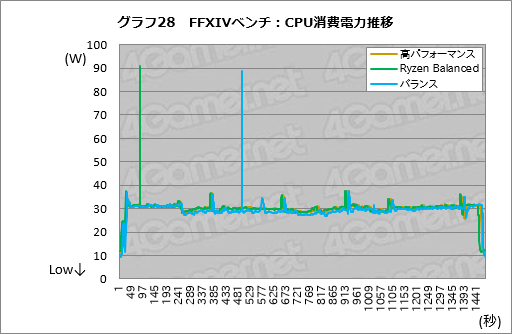
FXIVベンチの冒頭1ターン分,およそ4分弱の消費電力推移を追ってみることにした。標準品質(デスクトップPC)の1920
それ以外だと,ベンチマーク実行中の電力の推移は,バランス設定がほんのわずかながら低く推移するのに対して,Ryzen Balanced設定と高パフォーマンス設定はほぼ同じ消費電力のレベルで推移していることが見て取れるだろう。
 |
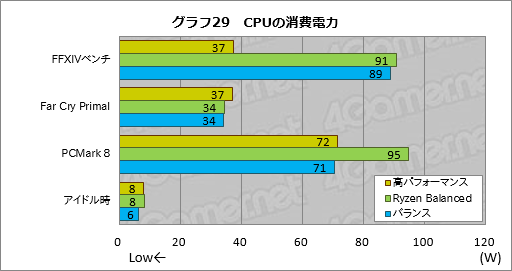
最後に,FFXIVベンチとFar Cry Primal,PCMark 8実行時におけるピークCPU消費電力と,アイドル状態が続いてもディスプレイ出力がオフにならないよう指定した状態で30分間放置した直後(以下,アイドル時)の最小CPU消費電力をグラフ29にまとめた。
前述のとおり,FFXIVベンチだとRyzen Balancedとバランス設定において瞬間的なピークが観測されているため,結果としてのこのグラフだと高パフォーマンス設定を圧倒してしまっている。PCMark 8でもRyzen Balancedが90Wを超えてしまっているが,こちらももしかすると同じ症状が出た可能性があるのかなと考えている。
 |
→目次に戻る
8. AMDはRyzenの現状をどう捉えているのか?
以上,長々とテストの結果を見てきたが,最初に挙げた「PCゲームを前にすると,競合のCPUに対してベンチマークスコアが及ばないのはなぜか」という疑問に対する明確な答えは依然として得られていない。高速なメモリモジュールを組み合わせることでRyzenはざっくり1割程度の性能向上を見込めるが,現時点でエンドユーザーができる性能対策はそれくらいしかないとも言える。
一方で,2基のCCXを持つというRyzen独自の内部構造は,競合のCPUにはないクセをもたらしてはいるものの,それ自体が大きなマイナスにもなっていないことは,今回のテスト結果から判断できる。また,RyzenのL3キャッシュが低速に見えるのはひとえにData Fabricの影響によるもので,CPUコアと同じCCX上のL3キャッシュに対しては十分に低遅延というテスト結果も得られている。
先日4Gamerは,AMDでデスクトップPC向けCPUのマーケティングマネージャーを務めるDon Woligroski(ドン・ウォリグロスキー)氏に話を聞く機会を得ている。氏は開発者ではなく,あくまでもマーケティングの専門家だが,その立場を勘案し,技術的な質問は事前に伝えておいたところ,技術者に聞いた内容も含めて真摯に答えてくれたので,その内容を以下のとおりお伝えしたい。
4Gamer:
まずはSMTについて伺いたいと思います。Ryzen 7発表後,ユーザーコミュニティの間で,WindowsがRyzenの論理CPUを正しく認識しておらず,WindowsがRyzen 7を物理16コアと認識しているために,ゲームのフレームレートが低いのでは? という疑問が取り沙汰されました。この疑問に対して,AMDはblogの中でこれをおおむね否定する見解を発表していますね。
しかし,SMTを無効化するとフレームレートが上がるゲームがあるのは事実です(関連記事)。また我々のテストでは,Ryzenよりむしろ競合のCPUのほうがSMTを有効化することによる負の影響が大きいケースもあったのですが,AMDはSMTにまつわるこうした現象についてどう見ていますか。
 |
確かにSMTを有効化するとフレームレートが低下するゲームタイトルがあります。これはSMTが悪いわけではなく,そのアプリケーションがプロセッサをどう見ているか,によります。
たとえばですが,私達が「RyzenのSMTを有効化するとフレームレートが低下する原因」を調べる中で分かった事実があります。あるゲームタイトルは「IntelのCPUを探す」というコードになっていたのです。
そして当該ゲームタイトルの場合だと,Intel製CPUが見つかれば,論理CPUを理解したうえで仮想スレッドをスケジュールしていました。一方,Ryzenを前にすると(コードがRyzenを把握していないため)論理CPUの数だけ,物理コアがあると判断してしまっていたのです。
もちろん,これを開発者のミスだと言うつもりはまったくありません。「Intel製のCPUとRyzenとで同じ(スレッドの)スケジューリングを行うことはできない」という事実を,AMDとしてもっと開発者に知らせていく努力が必要ということなのだと思います。
4Gamer:
そのRyzenですが,4基のCPUコアをCCXとして束ねており,Ryzen 7の場合は2基のCCXにより8コアCPUとしている点が,とても独特です。Microsoftが配布しているCoreinfoの出力結果を見ると,WindowsはRyzenのL3キャッシュが2つのCCXに分かれていることを把握しているようです。
一方で,「2つに別れたL3キャッシュを効果的に使うように,Windowsがスレッドのスケジューリングを行っているか」は何とも言えません。私が見る限りだと,行っていないように感じられるのですが,WindowsのスケジューラがRyzenの性能を発揮させられない1つの理由になっているということはありませんか。
Don Woligroski氏:
(インタビューにあたってあらかじめAMDから説明があったように)私はエンジニアではありません。AMD社内のミーティングで仕入れた情報しか語ることはできないということをお断りさせてください。
そのうえでお話ししますが,私達に対して寄せられる疑問の中で,現状最も深刻なものは,「シングルスレッド性能でRyzenが競合のCPUへ肉薄しているように見えるにもかかわらず,ゲームをはじめとする実アプリケーションでは競合より劣る場合がある理由を教えてほしい」というものです。
この点に関しては,社内でも多数のテスト行っています。SMTを無効化するとか,1基のCCXにスレッドを集中させてみるとかですね。そして,その結果分かったことは「疑問に対する1つの答えはない」というものでした。
たとえば,2つのCCXを使ったほうがいい場合がある一方,SMTを有効化したほうが性能の上がるタイトルもあります。「1つレバーを引けばRyzenで性能が上がる」わけではないのです。
4Gamer:
スケジューラに関してはいかがですか。
Don Woligroski氏:
Windowsのスケジューラに関して言えば,私達は期待どおりに機能していると考えています。ただ,だからといってMicrosoftに(スケジューラの改善を)働きかけないというわけではなく,働きかけはもちろんやっていきます。
しかし,我々はまず全体的に見て,短期的に何をすれば(Ryzenが)良くなるのかを見ています。その答えとして,まずユーザーの皆様にお知らせしたのが,SMTを有効化し,コアパーキングは使わない(※)というアドバイスでした。
※電源プランで高パフォーマンスを選びましょうというアドバイスのこと。Ryzen Balancedが使えるようになった現在は,必ずしも高パフォーマンスがベターというわけではない。あくまでも「まずユーザーに伝えた」のがこれだという話である。
いま我々が注力しているのは,メモリの安定性と速度の問題です。というのも,RyzenではData Fabricとメモリが密接に連動しているからです。
4Gamer:
注力されている点について,もう少し具体的に説明いただけますか。
 |
はい。まとめると,我々の目標は3つあります。
1つは,Ryzenのプラットフォームをできるだけ早く改善していくということですね。とくにメモリが課題で,DDR4 SDRAMの扱いは競合が先駆けているという事実があります。DDR4 SDRAMを(プラットフォームメモリとして)採用している期間も競合のほうが長いですからね。
ただご存じのとおり,この点でも先月,かなり大きな進展が私達の側にありました(※)。
2つめは開発者との連携です。(4Gamerなどが指摘しているとおり)とくにゲーム性能で課題がありますから,ゲーム開発者に対して積極的に働きかけていきたいですね。
そして最後は,将来的にスケジューラの改善といったことにも着手していくということです。いまお話しした3つの課題へ,迅速かつシンプルに取り組んでいくことにフォーカスしています。
※AGESA 1.0.0.4におけるメモリアクセス遅延低減のこと。
4Gamer:
ゲーム開発者への働きかけという点ですが,公式blogのCommunity Updateで,「Dota 2」と「Ashes of the Singularity」をRyzenへ最適化することで,非常に大きな性能向上を実現できたという話が出てきましたね。これはRyzenを使うゲーマーにとって,とても期待できるニュースだと思いますが,2タイトルでは具体的に何をしたのでしょうか。
Don Woligroski氏:
先程も申し上げたとおり私はエンジニアではありませんし,プログラムもJavaScriptをちょっとかじった程度ですから,エンジニアの人たちが話していたことを聞きかじったことしかお話しできません。
その点はお断りしておきますし,また,その2タイトルの話ではなかったかもしれませんが,エンジニアが言うには,ほんのちょっとしたことらしいのです。「コードの中に変なスイッチがあって,そこが効率を大きく落としているぞ」といった,本当に小さなことが原因だそうです。
いずれにしても,「Ryzenのためにコード全体を変える」などといった,大それた話ではありません。ほんの小さなことがRyzenでフレームレートが上がらない原因になってしまっていることが多いのです。
何しろRyzenはまだ発売されから1か月しか経っていませんから,ゲームもRyzenで実行されることを前提には作られていません。まだまだ(最適化は)これからということですね。
4Gamer:
小さな改善でゲームのフレームレートが10%,20%と上がっていくのであれば,多くのゲーマーはRyzenの今後に期待すると思いますが,今回最適化を実現した2タイトル以外,そのほかのタイトルでも,小さな改善でゲームのフレームレートが改善すると考えてしまっていいものなのでしょうか。
Don Woligroski氏:
その点についてはいくつかお話ししたいことがあります。
まず,ゲーム側に(Ryzen搭載環境でコード実行効率を上げるための)変更を加えることは比較的容易です。ずっと大変なのは,何百万行もあるゲームのコードの中から「問題の部分」を探すことのほうなのです。大切なのは,ゲームの開発者が(最適化に対する)関心を持ってコードを見ることです。ですから,我々AMDとしてもゲームの開発に引き続き関与していきます。
我々が最初に関与したのは,他のタイトルに比べてRyzenで大幅に性能が低下してしまうようなタイトルです。そのなかでもAshes of the Singularityは,マルチスレッドへ最適化されているタイトルで,Ryzenで高い性能が得られるはずなのに,なぜか非常に低いフレームレートしか出ないということで,最初に取り組んだという経緯があります。
4Gamer:
そういうことだったんですね。
Don Woligroski氏:
もう1つは,市場全体としてRyzenに対し,ゲーム性能がとても向上するだろうという期待が市場にあったということです。というか実際の話,決して「遅い」ということはありませんよね?
4Gamer:
ええ。Ryzenにおいて,そこはとても高く評価されるべきポイントだと思います。
 |
多くのゲームで60fps以上がコンスタントに得られる。にも関わらず「ゲームで遅い」という評価を世界的に受けているのはなぜかと言うと,競合のKaby Lakeと比べて得られるフレームレートが低いからだと思うのです。
やはり(Ryzenより)Kaby LakeのほうがIPC(=Instructions Per Clock,クロックあたりに実行できる命令数)は若干高いですから,IPCが制約となるタイトルでは,どうしてもRyzenのほうが遅くなってしまいます。しかし,その(RyzenとKaby Lakeの)ギャップを縮めることは可能だというのが,AMDの見解です。
4Gamer:
Ryzenの今後に楽観的ということだと思いますが,その根拠はいかがでしょう。
Don Woligroski氏:
おっしゃるとおり,Ryzenの今後に関しては楽観的に見ています。
今後,「Ryzenに対して行う(べき最適化)方法というものが,開発者側の間で見えているからです。
また(マルチスレッドに最適化された)DirectX 12やVulkanといったAPIを使ったゲームタイトルも増えてくるでしょう。そして,(Ryzenと組み合わせる)GPUによって,Ryzenの(ゲームにおける)性能を大きく向上させることもできるはずです。
4Gamer:
ゲームをRyzenに最適化する1つの方法はない,ということですよね。ゲームタイトルによって直すべき部分はさまざまにあり,「これを直せばRyzenでパフォーマンスが向上する」と行った答えはない。だからAMDとしては今後も継続してRyzenの最適化を進めていくと。
Don Woligroski氏:
そのとおりです。1つの簡単な方法はありません。今後,開発者と私達とで協力を進め,1年くらいかけて少しずつ,Ryzenでの性能を最適化して上げていくことが必要になるでしょう。
4Gamer:
1つの答えはないというお話ですが,RyzenではInfinity Fabricが性能のカギを握る1つの要素ではないか私達は考えています。ただ,Infinity Fabricの,あまり詳しいスペックが発表されていませんよね。
Don Woligroski氏:
はい,スペックは公開されていません。正直,私も「メモリの半分くらいの速度である」としか聞かされていないんですよ(※)。
※おそらく,「Data Fabricのクロックはメモリクロックの2分の1である」という意味。たとえば,メモリクロック3.2GHz相当のDDR4-3200なら,Data Fabricのクロックは1.6GHzである。そのことをWoligroski氏は「メモリの半分」と表現したのだろう。「Data Fabricの性能がメモリの半分」というわけではないのでご注意を。
4Gamer:
もう1つ,いま私達が困っているのは,RyzenのL3キャッシュに対するアクセス遅延を既存のツールで上手く計測できないことです。Infinity Fabricを通ってしまうので,どうしても,L3キャッシュのアクセス遅延はよかったり悪かったりと,結果にばらつきが出てしまいます。L3キャッシュのアクセス遅延を測るための,よい方法はありませんか。
Don Woligroski氏:
はい,私達もRyzenのL3キャッシュアクセス遅延を測る方法があればと願っています。というか,既存のソフトウェアツールでRyzenのL3キャッシュが持つアクセス遅延を計測できないことに,私達も驚いているというのが現状です。私達もサードパーティのソフトウェアを使ってテストしているのですが,その測定値が,AMD社内で持っている理論値とまったく合っていないんですよ。そこでいまはデベロッパと連携して,この問題を改善しようとしているところです。
いつ(ツールが提供できるか)という時期を,ここで申し上げることはできないのですが,いま開発に取り組んでいますので,お待ちください。
4Gamer:
期待しています。
最後の質問ですが,先日,AGESA 1.0.0.4のアナウンスがあり,BIOS(UEFI)のアップデートでDDR4 SDRAMのアクセス遅延が6nsほど改善するという発表もありました。今回のようなRyzen向けのAGESAのアップデートは今後も入り,Ryzenの性能は改善し続けていくという期待をしていていいのでしょうか。
Don Woligroski氏:
質問へお答えする前にお話ししておくと,私達が最初に行ったのは,(Ryzenの)プラットフォームを安定化し,さらにオーバークロックしやすくするという作業です。Ryzenは発売からまだ1か月ちょっとしか経っていませんから,まず一部のベンダーと協力して,「ユーザーが箱から出したままの状態でさまざまなメモリモジュールに対応し,またマザーボードがDDR4-3200に(できるだけ)対応できるようにする」という目標を立て,そこに向けて作業を行いました。
4Gamer:
はい。
Don Woligroski氏:
さまざまなメモリモジュールをマザーボードメーカーに渡して,メモリクロックを上げたりアクセス遅延設定を下げたりという作業は,とても時間がかかります。AGESA 1.0.0.4では,そうした作業の結果として,DDR4-3200設定における安定化や,アクセス遅延の低減を実現したわけです。
ですがこれはもちろん,「Ryzenでいま以上にメモリアクセス遅延を下げることはできない」ことを意味しません。Ryzenのプラットフォームに何らかの欠陥があるというわけではないのですから,私達は当然,今後も改善を加えていきます。
4Gamer:
つまり,今後もAGESAアップデートによるメモリ周りの強化には期待できると。
Don Woligroski氏:
そうなるよう,今後も我々は改善を続けていきます。当面の目標としては,ユーザーがDDR4-3200のメモリモジュールを買えば,確実に(DDR4-3200設定の安定動作が)実現できるということを目指していきます。そして,1か月という単位を目処に,新しいBIOS(≒AGESA)をリリースしていく計画も立てています。
4Gamer:
おお,それは素晴らしい。今後も定期的に,BIOSや周辺ソフトウェアの改善によって,Ryzenの性能は上がっていくということですね。
Don Woligroski氏:
確実に,どこまで性能が改善しますということを明言することは,もちろんできません(笑)。ですが,我々AMDは今後も努力を続けていきます。このことはお約束します。
以上,テスト結果を踏まえてWoligroski氏に聞いた話をまとめてみたが,氏の発言からは,現時点においてRyzenのボトルネックになっている部分が少し見えたようにも思う。
1つはDDR4 SDRAMメモリコントローラだ。DDR4の扱いでは競合のほうが先行していると,Woligroski氏が認めた点は興味深い。
AGESAのバージョンアップでどこまでメモリコントローラの性能が伸びるのかは何とも言えないが,Zenマイクロアーキテクチャの今後という長いスパンで話をするなら,メモリコントローラの性能向上が大きな課題となっていくだろう。
もう1つは,やはりIPCの違いである。RyzenはBulldozerマイクロアーキテクチャ系の最終形態であるExcavatorに対し54%のIPC向上を果たしたとされる。ただRyzen 7 1800Xのレビュー記事で明らかになっているとおり,競合のCPUには若干及ばないのも事実だ。IPCが“効く”アプリケーションで,競合と同等の性能を発揮するのは難しいと思われる。
 |
- 関連タイトル:
 Ryzen(Zen,Zen+)
Ryzen(Zen,Zen+) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー