











ニュース
Arm,ミドルクラスおよびエントリー市場向けの新GPU IPコア「Mali-G52」「Mali-G31」を発表
 |
- GPU IPコア「Mali-G52」「Mali-G31」
- ディスプレイプロセッサ「Mali-D51」
- ビデオプロセッサ「Mali-V52」
これらのうち,ゲーマーにとって重要なのは,GPU IPコアの2製品である。Mali-G31は,Armの既存GPU IPコアでも採用されている「Bifrost」(バイフロストまたはビフロスト)アーキテクチャを採用したローエンド向けGPUとのことだが,メインストリーム(ミドルクラス)向けに位置付けられるMali-G52は,新しい第2世代Bifrostアーキテクチャを採用するという点がポイントだ。
そこで本稿では,Mali-G52とMali-G31について少し詳しく紹介したい。
ハイエンドからエントリーまでBifrostアーキテクチャで統一
ArmがMali Multimedia Suiteを発表した背景には,メインストリーム市場向けスマートフォンに求められる要求が,次第に高くなってきていて,従来のプレミアム(ハイエンド)市場向けスマートフォンに近づいてきたということがある。
 |
 |
 |
 |
Armは以前から,「Utgard」(ウトガルド)や「Midgard」(ミッドガルド)というSIMDベースのアーキテクチャに基づくGPUを提供していた。それに対して,現行世代のBifrostは,スカラISA(命令セット)ベースのGPUとなる。UtgardやMidgardは事実上終息しており,GPU IPとしての提供は「リクエストがあれば行う」(Arm担当者)そうだが,推奨はしていないそうだ。
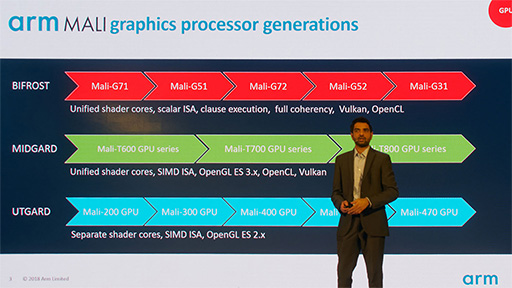 |
市場セグメント別に,ArmのGPUラインナップを見てみると,ハイエンド市場向けの最新モデルには,COMPUTEX 2017で発表となったBifrostアーキテクチャ世代の「Mali-G72」があり,今回発表のMali-G52は,Bifrost世代のメインストリーム市場向けGPU IPコアとなる「Mali-G51」の後継に位置付けられている。
また,市場セグメント別で一番下に当たるUltra Efficient(エントリー)市場向けは,これまでUtgardベースのGPUを提供し続けていたが,ようやくBifrostベースのMali-G31に置き換えられることになった。
 |
処理スレッド数の倍増で性能を向上
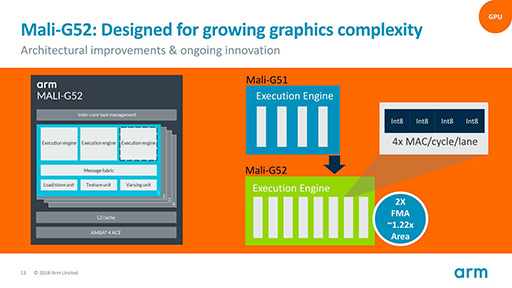
そのMali-G51と比べて,Mali-G52は,エリアサイズ比の処理性能※は30%,消費電力あたりの性能は15%改善したとする。
※半導体ダイに占めるGPUコアの面積が同等の場合,処理性能はどれだけ違うかの比較
 |
Armは,Mali-G52における性能向上を,どのようにして実現したかも説明した。
その1つが,演算ユニット「Execution Engine」1基あたりの処理スレッド数を倍増したこと。この結果として,Execution Engine 1基あたりのエリアサイズは22%増となったが,性能は2倍となったので,エリア効率でいえば64%ほど改善した計算になる。
もちろん,実際はここまで単純に効率が上がるわけではない。それでも30%ほどは改善できたというわけだ。
 |
 |
Mali-G52で面白いのは,この性能向上を,あまりリソースを増やすことなく実現したことにある。
Execution Engine自体はスレッド数(※Armのスライドでは,Laneと表記)が倍増するので,面積は単純に倍増してしまう。詳しい説明はなかったが,Texture Unitも“Dual”と書かれているので,倍増しているのだろう。ただ,それ以外のところは,数を2倍にするのではなく,動作速度を2倍にすることで辻褄を合わせた格好だ。
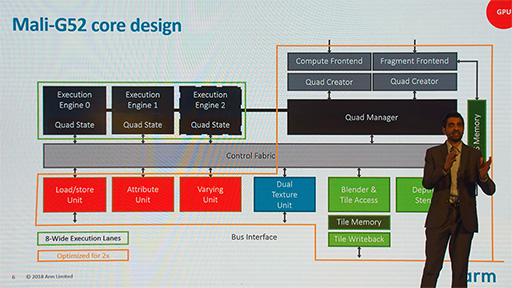 |
なぜArmは,このような構造を採用したのか。メインストリーム市場向けGPUは,ハイエンド市場向けに比べて部品の価格に対する要求が厳しいので,ダイサイズをぎりぎりまで抑えたかったのだと,Armは説明していた。つまり倍速化によって多少消費電力が増えても,ダイ面積を抑えるほうがトータルコストの削減につながると判断したようだ。
価格に厳しいメインストリーム市場向けにAI処理をGPUで実現可能に
処理スレッド数の倍増と同じ理由で,Mali-G52に追加されたのが,Int 8(8bit整数演算)のサポートである。ハイエンド市場向けSoC(System-on-a-Chip)の場合,HiSilicon Technologies製SoC「Kirin 970」におけるAI処理機構「Neural-network Processing Unit」のように,AI処理専用コプロセッサを追加するのは,それほど難しくない(関連記事)。SoCの価格が上がっても,端末メーカーに許容されやすいからだ。
ところがメインストリーム市場向けSoCの場合,AIコプロセッサを追加するほどの費用を受け入れられない場合が多く,そのためGPUにAI処理機能を持たせる必要があると,Armは判断しているということだった。
そういった事情を踏まえて,どういう実装になったのかというと,Execution Engineにおける各スレッドの処理で,FP32(単精度浮動小数点演算)やInt 32
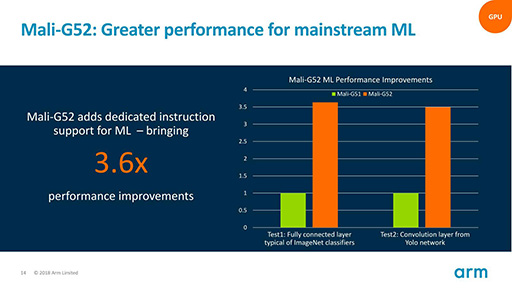 |
ちなみに,このInt 8での処理は,Armが提供するソフトウェアフレームワーク「Arm NN」(関連リンク)で,そのままサポートしているという話だ。このArm NNは,2018年2月に同社が発表した機械学習向けプロセッサ「Arm ML」(関連リンク)もサポートしているそうで,アプリケーションからは,どちらのプロセッサでも同じように扱えることになる。
話を戻そう。Execution Engineの処理スレッド数倍増とInt 8でのSIMD演算のサポートが,第2世代Bifrostアーキテクチャの特徴だ。ただ,SoCに統合するGPU IPコアの構成が同じであれば,メインストリーム市場向けSoCのグラフィックス性能が,現在のハイエンド市場向けSoCを上回ってしまう可能性も出てくる。
それを考慮してか,Mali-G52は,最大4コアまでに制限されているそうだ。ハイエンド市場向けのMali-G71やMali-G72は最大32コアまでサポートしているので,最大構成だと,
32(コア)×3(Execution Engine)×4(スレッド)=384スレッド
を同時に処理できる。3サイクル(=3クロック)で1ピクセルの処理が可能なので,128ピクセル/クロックの処理が可能なわけだ。
これに対してMali-G52は,
4(コア)×3(Execution Engine)×8(スレッド)=96スレッド
で,最大でも32ピクセル/クロックに留まる。
もっともMali-G51は最大3コアまでの構成なので,
3(コア)×3(Execution Engine)×4(スレッド)=36スレッド
で12ピクセル/クロックとなるので,Mali-G52は,大幅に性能が向上したわけだ。
余談になるが,Mali-G51は,ターゲットとする製造プロセスが,TSMCの28nmプロセス「28HPM」あたりだった。それに対してMali-G52では,TSMCの16nmプロセス「16FF+」「16FFC」や,12nmプロセス
そのため,実際にはMali-G51を搭載するSoCよりも,Mali-G52を搭載するSoCのほうが,省電力化や高速化を実現できる。実際,ArmのWebサイトにある情報では,Mali-G51をクロック650MHzで動作させた場合のピクセルスループットが3.9Gピクセル/secとなっている(関連リンク)のに対して,Mali-G52は850MHz動作で6.8Gピクセル/secと,74%も向上しているのがその一例と言えよう(関連リンク)。
ただ,理論上のピクセル/クロックにおける性能差に対して,スループットの性能差が低い理由や,Armが挙げたエリアサイズ比での性能差が30%と控えめな数字となっている理由は,今のところ分からない。
エントリー市場向け端末にVulkanをもたらすMali-G31
さて,Mali-G52と同時に発表となったMali-G31であるが,こちらは第1世代のBifrostアーキテクチャを採用しているという。Execution Engineは最大2つで,
 |
 |
 |
Mali-G31ではAI処理など考慮していないし,性能も前世代と比べて,それほど向上するわけではない。しかし,その代わりに「Arm Frame Buffer Compression」(AFBC)という機能を,GPUコア内に搭載したのが特徴であるという。従来のエントリー市場向けGPU IPコアでは,これをGPUに内蔵できず,外側に置いていたのだそうだ。
Mali-G31のターゲットプロセスは,前世代から引き続いて28HPMで,スループットは1.3Gピクセル/secとなっている。前世代のエントリー市場向けGPU IPコアである「Mali-470」の場合,28HPMでスループットは650Mピクセル/sec程度となっていたので,3倍ほど高速化されている計算だ。リッチなグラフィックスのゲームをするのは無理だろうが,カジュアルゲーム程度であれば快適に動作しそうである。
- 関連タイトル:
 Mali,Immortalis
Mali,Immortalis
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー