








連載
西川善司の3DGE:新世代GPU「Turing」のリアルタイムレイトレーシングは「本物」なのか? その正体に迫る
既報のとおり,北米時間2018年8月13日,NVIDIAは,カナダ・バンクーバーで行われているコンピュータグラフィックスとインタラクティブ技術の学会であるSIG
本稿執筆時点で,Turingのアーキテクチャ面に関する詳細は明らかになっていない。つまり,NVIDIAのイベントで明らかになった以上の情報はないわけだが,それでも「Turing世代で何ができるようになるのか」はやはり気になるところだ。
今回は,現時点における公開情報を基に,Turingコアの特徴をできる限り噛み砕いて説明してみたい。
説明に入る前に,今回発表となったQuadro RTXシリーズのラインナップをおさらいしておこう。NVIDIAは今のところ,以下のとおり3種類の製品を用意している。
現地でのイベント終了後に行われた質疑応答で明らかになった情報として,
ダイサイズは754mm2で,総トランジスタ数は約186億個。Volta世代の「GV100」コアだとダイサイズが815mm2,トランジスタ数が約211億個なので,サイズは約93%,トランジスタ数は約88%にまで小さくなったと言える。
ただ,GeForce 10シリーズやQuadro Pシリーズが採用する「Pascal」世代で最も大きな「GP102」コアだとダイサイズは471mm2,トランジスタ数は約118億個だったので,それと比べると相当に巨大なのも確かだ。
次に演算ユニットの規模だが,TuringのCUDA Core数は4608基。GV100の5376基と比べると約86%という計算になる。ただこれもGP102の3840基と比べると1.2倍という規模だ。ダイサイズやトランジスタ数の違いからすると,TuringのCUDA Core数は明らかに控えめで,ここにこそ最大の特徴があるわけだが,それは後述することにしてCUDA Core周りの話を続けよう。
NVIDIAのGPUは,CPUで言うところの「コア」に相当するクラスタ(cluster,固まり)を「Graphics Processor Cluster」(以下,GPC),GPC内にある演算コアクラスタを「Streaming Multiprocessor」(以下,SM)と呼んでいる。最近のNVIDIA製GPUのアーキテクチャだと,SMあたりのCUDA Core(≒シェーダコア)数は64基だ。
NVIDIAはGPUの詳細構成を明らかにしていないが,ただ,質疑応答時にNVIDIAの担当者は,「TuringコアはGV100と似ている」「GV100のアーキテクチャをベースにして開発した」と述べていた。GV100だとGPC数は6基,GPCあたりのSM数は14基だったが,これに当てはめると,TuringはGPC数が6基,GPCあたりのSM数12基で,
という,それっぽい計算式を作ることができる。
Turingコアでは,L2キャッシュ容量が最大6MBになるが,それ以上に,グラフィックスメモリとしてGDDR6 DRAM(関連記事,以下 GDDR6)を採用しているのがトピックだ。
メモリインタフェースは384bit,メモリの実効転送レートは14Gbps(動作クロック14GHz相当)なので,単純計算すると,
でメモリバス帯域幅は672GB/sとなる。
先述のスペック一覧でも触れたが,Quadro RTXシリーズのグラフィックスメモリ容量は最上位モデルであるQuadro RTX 8000で48GBに達する。上から2番めのQuadro RTX 6000でも24GBだ。この2製品では,おそらく384bitメモリインタフェースを採用してくるだろう。
グラフィックスメモリ容量が16GBとなる最下位モデルのQuadro RTX 5000だけはCUDA Core数も控えめになっているので,メモリインタフェースが256bitに抑えられていても不思議ではないと筆者は考えている。
Quadro RTXシリーズの話になったので少し続けると,イベントでNVIDIAは,
従来のGeForceやQuadroにおけるSLIは,レンダリングパイプラインの最下流にあたる「ピクセルデータの共有」目的で使われていた。一方,NVLinkでは,2基のGPUを専用バスで接続することにより,仮想的に1基の巨大なGPUとして協調動作できるようになる。そのため,NVLink時のグラフィックスメモリ容量は,2基のGPU分を合計した数字になるのだ。これは地味ながらも大きな拡張ポイントである。
NVLinkを用いたGPUとGPU間のデータ転送帯域幅は100GB/sとのことだ。
以上のデータを基に,Turingの性能面を考察してみよう。
Turingコアの理論性能値は,「16 TFLOPS
Turingコア,というかQuadro RTXシリーズの動作クロックは公表されていないが,最大で16 TFLOPSという数値から逆算すると,
という,これまたそれっぽい数字を求めることができる。
そして16 TIPSのほうだが,この値は,Turingコアにおける整数演算能力の性能(Integer Per Second)を表したものだ。Turingコアでは,整数の積和算を単精度浮動小数点演算と同時に行えるというのが大きなアピールポイントの1つなのだが,要するに「16 TFLOPS
ちなみにSMあたりの整数演算コア数はCUDA Coreと同じ。なのでこなせる演算量もCUDA Coreと同じ「16T」ということになる。
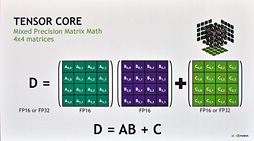
というわけで,先ほど出てきた「ダイサイズの割にCUDA Core数が少ない理由」のほうに話を移していくが,Turingコアでは,Volta世代で初搭載となった「Tensor Core」(テンサーコア)を引き続き搭載している。
Tensor Coreとは何か,という話はGV100を解説した連載バックナンバーを参照してほしいと思うが,ものすごく簡単に言うと,最大で4
ただそれだけに,グラフィックス用途に向けたQuadro RTXがTensor Coreを搭載するのはやや不思議に思えるかもしれない。この部分は後述しよう。
先ほどの「Turing世代のGPUコアにおける基本アーキテクチャはGV100と同じ」という解釈で話を続けるなら,GV100ではSMあたり8基のTensor Coreを搭載していたため,Turingでは最大576基(=6
となって,NVIDIAが発表した公称値である125 Tensor FLOPSとほぼ一致する。
ちなみに,Turingコアでは,16bit浮動小数点演算(FP16)比でスループットが8bit整数演算(INT8)だと2倍,4bit整数演算(INT4)では4倍に達することから,8bit整数演算で250 TOPS,4bit整数演算で500 TOPSという性能値をNVIDIAが掲げている。
TOPSというのはいま述べたTensor FLOPSの略語と同系列の略語だ。
Turingコアにおける最大の目玉は,なんと言ってもレイトレーシングユニット「RT Core」(Ray Tracing Core)だろう。
そもそもレイトレーシングとは何か。
レイトレーシングでは,まず,カメラのある視点の位置から画面上のピクセルに向かって,描画範囲(画角や視野角,視錐台※)に対応する角度で放射状にレイ(ray,視線もしくは光線)を伸ばしていく。そして,「何らかの3Dオブジェクトを構成するポリゴン」にそのレイが衝突した場合は,衝突したポリゴンの材質パラメータを読んで,その材質に適した処理を行う。仮に材質が鏡のように反射する性質を持っていたなら,その反射方向にもさらにレイを飛ばして,何かに衝突しないかを調べる。
レイの投射元は,材質の情報に基づいて処理をする。いま紹介した鏡のような材質の例で言えば,レイが反射した先にもレイを飛ばした結果として別の何かに衝突したら,その材質の情報を基に,映り込み(Reflection)表現を行うことになる。
※視点とスクリーンの四隅を結んだ線を延長してできる四角錐の空間のこと。
さて,「視点からピクセルに向かって投げられたレイがポリゴン面に衝突した」ところまでちょっと話を戻して,衝突した点から光源に向かってレイを飛ばしてみよう。もし,この飛ばしたレイが光源まで到達できたのであれば,「レイの投射元である衝突点に,光源の放つ光が当たっている」と判断できる。
一方,衝突点から放ったレイが,別の3Dオブシェクトを構成するポリゴンに衝突した場合,衝突点は光源から見て遮蔽されていて,「影になる」と判断できるわけだ。レイトレーシングというのは,こうした処理を繰り返して描画を行う描画方法のことを言う。
……と,ここまで説明すると,RT Coreの役割もおぼろげながら見えてくるのではないだろうか。そう,RT Coreとは,このレイを投射する専用ハードウェアなのだ。
イベントでNVIDIAは,RT Coreの性能を10G Rays/s(毎秒100億レイ)とアピールしていたが,要するにこれは,1秒あたり100億個のレイを投射できるということである。
フルHD解像度の場合,総ピクセル数は1920×1080=207万3600ピクセルとなる。そこで,100億レイを207万3600ピクセルで割れば,1秒あたりに投射できるレイの数が約4822本であることを求められる。
PC用3Dゲームの映像がおおむね毎秒60コマ(60fps)で動くとすると,1フレームあたりに1ピクセルが投射できるレイの本数は約80本ということになる。
2018年3月に行われたGDC 2018で,Microsoftが発表したレイトレーシングパイプライン「DirectX Raytracing」(以下,DXR)を用いた技術デモがいくつか登場したが(関連記事),複数個のGV100を用いたケースであっても,60fpsの1フレーム,1ピクセルあたりのレイ数は5〜6本程度。Pascal世代のGeForceを用いた場合はこれが1本となり,反射だけを描画する実装になっていた。
つまり,これまでのNVIDIA製GPUではハイエンドモデルを使っても1桁本数のレイを投射処理するのがやっとだったのだ。それがいきなり60fpsの1フレーム,1ピクセルあたり約80本も投射できるようになると言えば,トンデモない性能向上なのが理解してもらえると思う。
これだけの性能向上を実現できたカギは,繰り返しになるが,「レイが3D空間を突き進む処理」や「レイとポリゴンとの衝突判定処理」を専用ハードウェアとしてのRT Coreで行うところにある。
これまで,GPUによるレイトレーシングは,レイトレーシングに必要な演算をGPGPU――NVIDIA製GPUの場合はCUDA――で行っていた。GPUは,大量のデータに対して1つの演算を適用することは得意である一方,処理対象のデータごとに場合分け(条件分岐)しながら並列に処理していくのがとても苦手だ。もちろん不可能ではないが,すべての処理に要する時間は,一番時間のかかった分岐処理の実行時間に左右されるので,トータルの処理時間が長くなってしまう。
この問題を,「専用ハードウェアを搭載する」というやり方で,NVIDIAは解決したというわけなのだ。
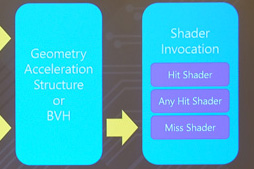
もちろん,広大な3D空間に無数のレイを飛ばすのはとてつもなく時間がかかる。そこでNVIDIAは,この処理を高速化するために「Bounding Volume Hierarchy」(バウンディングボリューム階層構造,以下 BVH)という概念を取り入れた(関連記事)。
BVHは,3Dシーンを階層構造で記述する概念である。たとえば,ある3Dシーン内に巨大な船があると仮定しよう。そのとき,この船全体を覆うような箱(Bounding Volume)を定義しておくと,レイが船に衝突したか否かの判定を,シンプルな箱との衝突判定で代用できる。
GDC 2018で,Remedy EntertainmentがゲームエンジンのDXR対応を説明するときに使ったスライドがあるので(関連記事),下に再掲しつつ,BVHの使い方をもう少し具体的に説明してみよう。
DXRの場合,シーンのデータ構造は階層構造になっている。いま挙げたスライドの例では,まず(黄色い線で描かれた)3Dオブジェクトと,その3Dオブジェクトを囲んだ赤い箱,そして赤い箱を複数集めてひとまとめにして囲んだ青い箱という3つの階層を確認できる。
レイは最初,青い箱との衝突判定を行い,衝突していれば階層を下って,次にどの赤い箱と衝突しているかを判定する。青い箱に衝突していないなら,赤い箱との衝突判定は不要なので,処理を省いていいわけだ。
赤い箱のどれかに衝突していると判断できれば,その箱に囲まれた3Dオブジェクトを読み出して,実際にどのポリゴンに当たっているかの判定を行う。こうした階層的な判定によって,レイの直進と衝突判定を効率よく行っていくのである。
ここまで読み進んだところで,「RT Coreがレイの投射と直進,レイとポリゴンの衝突判定しかしないとすれば,ライティング計算とか,材質ごとの陰影の計算とか,テクスチャを用いた多様な処理とかは誰が担当するの?」と疑問を持つかもしれない。
その答えはズバリ,「これまでのGPUと同じ」。つまり,プログラマブルシェーダで処理を行う。シェーダプログラムの部分は,従来の3Dグラフィックスとほとんど変わらないプログラムで処理できるので,「TuringはレイトレーシングGPUだ」と言っても,従来の3Dグラフィックスパイプラインはそのまま活用できるのである。
これまでのGPUアーキテクチャはそのままに,レイを飛ばす専用ハードウェアを追加することでレイトレーシング対応を果たしたのがTuringコアなのだと言うこともできるだろう。
ここからは,TuringのRT Coreにまつわる細かい特徴や仕様について,質疑応答で判明した情報と合わせて紹介してみたい。
そもそも論として,RT Coreでレイを投射したり直進させたり,衝突判定行ったりするのをどのようにプログラムすればいいのだろうか。
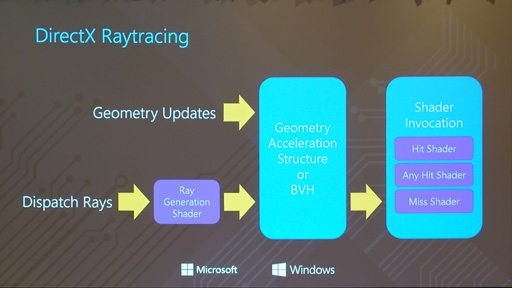
その方法は2つある。1つはシンプルにDXRを活用する方法だ。DXRでは,レイを生成するプログラマブルシェーダ「Ray Generation Shader」が定義されているので,これを活用すればいい。前段で紹介したとおり,DXRにおける3Dシーンの構造データは,BVHで定義できるようになっているからだ。
2つめは,NVIDIAのDXR対応ランタイムモジュール「RTX Technology」(以下,RTX)を活用する方法である。
DXRは,NVIDIA製GPU以外にも対応する構造なので,多少なりとも抽象化レイヤーが存在していたりと,RT Coreが持つすべての機能を活用できるような構造にはなっていない(かもしれない)。それに対してRTXはNVIDIA製ミドルウェア的な立ち位置にあるので,比較的薄い抽象化レイヤー越しにRT Coreを利用できるという性能面での優位性を持つ。
ゲームや汎用ゲームエンジンなどは,NVIDIA製以外のGPUでも動作する必要があるため,DXRベースで開発されるだろう。しかし,3Dグラフィックス開発ソフトやレンダラーなどは,RTXベースで開発することもあるのではなかろうか。
なおNVIDIAは質疑応答で,「現在のところ,NVIDIA以外のAPIとしてはDXRしかないが,いずれVulkanも対応するのではないか」という見通しを述べていたので,Vulkanが似たような仕組みを実装する可能性はある。ただし,OpenGLについての言及はなかった。
ところで,今回のイベントで公開されたリアルタイムレイトレーシングのデモ映像では,機械学習ベースのレイトレーシング用デノイザ(denoiser,ノイズ低減機能)や,深層学習ベースのアンチエイリアシング機能「DLAA」(Deep Learning Anti Aliasing)など,「レンダリングしたレイトレーシング映像の見栄えを良くするためのポストエフェクト」が適用済みだった。
こうしたAI系ポストエフェクトをTuringコアで実行した場合の性能について質問してみたところ,「現状,処理の所要時間は数ms」という回答が返ってきた。適用対象となるピクセル数によって処理時間は変わってくるそうだ。一方,シーンの複雑性には依存しないとのことである。
パフォーマンスのイメージとしては「複数フレームにわたるピクセルの相関性に配慮してアンチエイリアシングを行う『TAA』(テンポラルアンチエイリアシング)よりは(処理負荷が)重い」という補足も得られているので,記しておきたい。
デノイザのほうは正直なところ,フレームレートが重要になるゲームグラフィックス用途だと,NVIDIAの「GameWorks Raytracing」に組み込まれている,バイラテラルフィルタ(Bilateral Filter,エッジを保持しつつ画像を滑らかにするフィルタ)ベースの「Denoiser」のほうが,安定して性能が得られそうな気がしている。
ただ,発表イベントを見た人なら憶えているかもしれないが,Huang氏はこの点について「64サンプルで処理すれば,機械学習型デノイザ(によるポストエフェクト)でも,時間をたっぶりかけたレイトレーシング映像とほとんど変わらない(効果が得られる)」と述べていた。
「ゲームグラフィックスで実用レベルになるか」はひとまず置いておいて,NVIDIAはAI系ポストエフェクトをなるべく高速に処理できるようにしたいと考えているようだ。
先ほど後述するとしたが,グラフィックス用途向けのQuadro RTXで推論処理アクセラレータに相当するTensor Coreを採用しているのは,ひとえにこのAI系ポストエフェクト高速化のためなのである。
ちなみに,今回のQuadro RTXシリーズが下手をするとホストコンピュータ側のメインメモリ容量より大きくなるかもしれないほどのグラフィックスメモリを積んでいる背景にも,レイトレーシングがある。
従来のリアルタイムレンダリング手法で主流のラスタライズ法では,視点から見えないポリゴン,いわゆる隠面ポリゴンはレンダリング時に除外してしまう。当然,画面外の3Dオブジェクトやポリゴンも破棄する。
ところがレイトレーシングでは,画面外(視界外)のオブジェクトが画面内(視界内)の光景に影を落としたり,間接光をもたらしたりするのが当たり前だ。たとえば床面がツルツルのタイルなら,視界外にある光景が床に映り込んだりするしれない。すなわち,視界外にも広がる広範囲の3Dシーン構造をグラフィックスメモリ上に置いておかなければ,正しいレンダリングを行うときに不都合が起きたり,処理性能面で問題を引き起こしたりしかねないのだ。

レイトレーシング時代のGPUは,今までのよりも多めのグラフィックスメモリを搭載してくるのが当たり前になるかもしれない。
Huang氏はTuringコアを「史上初のレイトレーシングGPU」と位置づけている。最終製品の市場投入までこぎつけたGPUとしてはまったくそのとおりなのだが,実のところ「史上初のレイトレーシングGPU」には先駆者がある。「PowerVR Wizard」のImagination Technologies(以下,Imagination)だ。
PowerVRシリーズで知られるImaginationは,既存のGPU IPコアにレイトレーシングエンジンを組み込んだ製品としてのPowerVR Wizardを2014年に開発し,製品発表している(関連記事)。動作デモも行われているので,「動作するレイトレーシングGPU」を出したのは,Imaginationがおそらく世界初と言ってしまっていいだろう。
ただImaginationは,最大の顧客であったAppleとの関係が切れたことで業績が悪化し(関連記事),結局,PowerVR Wizard搭載製品を市場に出すことのないまま開発中止してしまった。
下に示したのは,PowerVR Wizardシリーズとして最初で最後の製品となった「PowerVR GR6500」のブロック図で,そこには「PowerVR Ray Tracing Unit」(以下,RTU)という機能ブロックがあるのだが,これはまさにTuringコアにおけるRT Coreと同じ用途,すなわちレイの投射と推進,衝突判定を行うものだった。
ImaginationはRTUに関する特許を保有していると思うのだが,RT Coreとの間で特許的な問題が解決しているのかどうかはちょっと気になるところだ。
ちなみに,2015年時点におけるPowerVR GR6500のレイ処理性能は,300M Rays/s(毎秒3億レイ)。つまり,日の目を見なかった“史上初のレイトレーシングGPU”に対し,10G Ray/sのスペックで今回発表になった「史上初のレイトレーシングGPU」は約33倍の性能を持つわけである。
もちろんPowerVRシリーズは組み込み機器向けの製品なので,Turingコアと直接比較することに意味はない。ただ,それでも比較したくなるほど,Turingの登場はいろいろと感慨深いものがある。
 |
本稿執筆時点で,Turingのアーキテクチャ面に関する詳細は明らかになっていない。つまり,NVIDIAのイベントで明らかになった以上の情報はないわけだが,それでも「Turing世代で何ができるようになるのか」はやはり気になるところだ。
今回は,現時点における公開情報を基に,Turingコアの特徴をできる限り噛み砕いて説明してみたい。
Voltaと同じ12nm FFNプロセス技術に基づき製造されるTuring。基本アーキテクチャも同じか?
説明に入る前に,今回発表となったQuadro RTXシリーズのラインナップをおさらいしておこう。NVIDIAは今のところ,以下のとおり3種類の製品を用意している。
- Quadro RTX 8000:4608 CUDA Cores,576 Tensor Cores(10G Rays/s),グラフィックスメモリ容量48GB(GDDR6),1万ドル(税別)
- Quadro RTX 6000:4608 CUDA Cores,576 Tensor Cores(10G Rays/s),グラフィックスメモリ容量24GB(GDDR6),6300ドル(税別)
- Quadro RTX 5000:3072 CUDA Cores,384 Tensor Cores(6G Rays/s),グラフィックスメモリ容量16GB(GDDR6),2300ドル(税別)
 |
ダイサイズは754mm2で,総トランジスタ数は約186億個。Volta世代の「GV100」コアだとダイサイズが815mm2,トランジスタ数が約211億個なので,サイズは約93%,トランジスタ数は約88%にまで小さくなったと言える。
ただ,GeForce 10シリーズやQuadro Pシリーズが採用する「Pascal」世代で最も大きな「GP102」コアだとダイサイズは471mm2,トランジスタ数は約118億個だったので,それと比べると相当に巨大なのも確かだ。
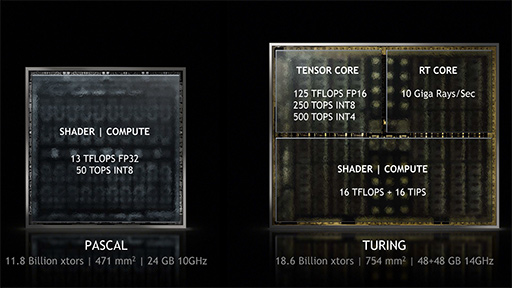 |
次に演算ユニットの規模だが,TuringのCUDA Core数は4608基。GV100の5376基と比べると約86%という計算になる。ただこれもGP102の3840基と比べると1.2倍という規模だ。ダイサイズやトランジスタ数の違いからすると,TuringのCUDA Core数は明らかに控えめで,ここにこそ最大の特徴があるわけだが,それは後述することにしてCUDA Core周りの話を続けよう。
NVIDIAのGPUは,CPUで言うところの「コア」に相当するクラスタ(cluster,固まり)を「Graphics Processor Cluster」(以下,GPC),GPC内にある演算コアクラスタを「Streaming Multiprocessor」(以下,SM)と呼んでいる。最近のNVIDIA製GPUのアーキテクチャだと,SMあたりのCUDA Core(≒シェーダコア)数は64基だ。
NVIDIAはGPUの詳細構成を明らかにしていないが,ただ,質疑応答時にNVIDIAの担当者は,「TuringコアはGV100と似ている」「GV100のアーキテクチャをベースにして開発した」と述べていた。GV100だとGPC数は6基,GPCあたりのSM数は14基だったが,これに当てはめると,TuringはGPC数が6基,GPCあたりのSM数12基で,
- 6(GPC)
×12(SM) ×64(CUDA Core)=4608 CUDA Core
という,それっぽい計算式を作ることができる。
 |
Turingコアでは,L2キャッシュ容量が最大6MBになるが,それ以上に,グラフィックスメモリとしてGDDR6 DRAM(関連記事,以下 GDDR6)を採用しているのがトピックだ。
メモリインタフェースは384bit,メモリの実効転送レートは14Gbps(動作クロック14GHz相当)なので,単純計算すると,
- 384(bit)
×14(Gbps)÷8(bit)=672GB/s
でメモリバス帯域幅は672GB/sとなる。
先述のスペック一覧でも触れたが,Quadro RTXシリーズのグラフィックスメモリ容量は最上位モデルであるQuadro RTX 8000で48GBに達する。上から2番めのQuadro RTX 6000でも24GBだ。この2製品では,おそらく384bitメモリインタフェースを採用してくるだろう。
グラフィックスメモリ容量が16GBとなる最下位モデルのQuadro RTX 5000だけはCUDA Core数も控えめになっているので,メモリインタフェースが256bitに抑えられていても不思議ではないと筆者は考えている。
 |
従来のGeForceやQuadroにおけるSLIは,レンダリングパイプラインの最下流にあたる「ピクセルデータの共有」目的で使われていた。一方,NVLinkでは,2基のGPUを専用バスで接続することにより,仮想的に1基の巨大なGPUとして協調動作できるようになる。そのため,NVLink時のグラフィックスメモリ容量は,2基のGPU分を合計した数字になるのだ。これは地味ながらも大きな拡張ポイントである。
NVLinkを用いたGPUとGPU間のデータ転送帯域幅は100GB/sとのことだ。
数字データからTuringのスペックを予想する
以上のデータを基に,Turingの性能面を考察してみよう。
 |
Turingコア,というかQuadro RTXシリーズの動作クロックは公表されていないが,最大で16 TFLOPSという数値から逆算すると,
- 16T(FLOPS)÷4608(CUDA Core)÷2(1クロックあたりの積和算数)=1.736GHz
という,これまたそれっぽい数字を求めることができる。
そして16 TIPSのほうだが,この値は,Turingコアにおける整数演算能力の性能(Integer Per Second)を表したものだ。Turingコアでは,整数の積和算を単精度浮動小数点演算と同時に行えるというのが大きなアピールポイントの1つなのだが,要するに「16 TFLOPS
ちなみにSMあたりの整数演算コア数はCUDA Coreと同じ。なのでこなせる演算量もCUDA Coreと同じ「16T」ということになる。
というわけで,先ほど出てきた「ダイサイズの割にCUDA Core数が少ない理由」のほうに話を移していくが,Turingコアでは,Volta世代で初搭載となった「Tensor Core」(テンサーコア)を引き続き搭載している。
 |
ただそれだけに,グラフィックス用途に向けたQuadro RTXがTensor Coreを搭載するのはやや不思議に思えるかもしれない。この部分は後述しよう。
先ほどの「Turing世代のGPUコアにおける基本アーキテクチャはGV100と同じ」という解釈で話を続けるなら,GV100ではSMあたり8基のTensor Coreを搭載していたため,Turingでは最大576基(=6
- 576(Tensor Core)
×1.736(GHz) ×(16(要素) ×4回 ×2(FLOPS)) =127991G Tensor FLOPS
となって,NVIDIAが発表した公称値である125 Tensor FLOPSとほぼ一致する。
ちなみに,Turingコアでは,16bit浮動小数点演算(FP16)比でスループットが8bit整数演算(INT8)だと2倍,4bit整数演算(INT4)では4倍に達することから,8bit整数演算で250 TOPS,4bit整数演算で500 TOPSという性能値をNVIDIAが掲げている。
TOPSというのはいま述べたTensor FLOPSの略語と同系列の略語だ。
Turingコアのレイトレーシング性能はどの程度なのか
 |
そもそもレイトレーシングとは何か。
レイトレーシングでは,まず,カメラのある視点の位置から画面上のピクセルに向かって,描画範囲(画角や視野角,視錐台※)に対応する角度で放射状にレイ(ray,視線もしくは光線)を伸ばしていく。そして,「何らかの3Dオブジェクトを構成するポリゴン」にそのレイが衝突した場合は,衝突したポリゴンの材質パラメータを読んで,その材質に適した処理を行う。仮に材質が鏡のように反射する性質を持っていたなら,その反射方向にもさらにレイを飛ばして,何かに衝突しないかを調べる。
レイの投射元は,材質の情報に基づいて処理をする。いま紹介した鏡のような材質の例で言えば,レイが反射した先にもレイを飛ばした結果として別の何かに衝突したら,その材質の情報を基に,映り込み(Reflection)表現を行うことになる。
※視点とスクリーンの四隅を結んだ線を延長してできる四角錐の空間のこと。
さて,「視点からピクセルに向かって投げられたレイがポリゴン面に衝突した」ところまでちょっと話を戻して,衝突した点から光源に向かってレイを飛ばしてみよう。もし,この飛ばしたレイが光源まで到達できたのであれば,「レイの投射元である衝突点に,光源の放つ光が当たっている」と判断できる。
一方,衝突点から放ったレイが,別の3Dオブシェクトを構成するポリゴンに衝突した場合,衝突点は光源から見て遮蔽されていて,「影になる」と判断できるわけだ。レイトレーシングというのは,こうした処理を繰り返して描画を行う描画方法のことを言う。
……と,ここまで説明すると,RT Coreの役割もおぼろげながら見えてくるのではないだろうか。そう,RT Coreとは,このレイを投射する専用ハードウェアなのだ。
イベントでNVIDIAは,RT Coreの性能を10G Rays/s(毎秒100億レイ)とアピールしていたが,要するにこれは,1秒あたり100億個のレイを投射できるということである。
フルHD解像度の場合,総ピクセル数は1920×1080=207万3600ピクセルとなる。そこで,100億レイを207万3600ピクセルで割れば,1秒あたりに投射できるレイの数が約4822本であることを求められる。
PC用3Dゲームの映像がおおむね毎秒60コマ(60fps)で動くとすると,1フレームあたりに1ピクセルが投射できるレイの本数は約80本ということになる。
2018年3月に行われたGDC 2018で,Microsoftが発表したレイトレーシングパイプライン「DirectX Raytracing」(以下,DXR)を用いた技術デモがいくつか登場したが(関連記事),複数個のGV100を用いたケースであっても,60fpsの1フレーム,1ピクセルあたりのレイ数は5〜6本程度。Pascal世代のGeForceを用いた場合はこれが1本となり,反射だけを描画する実装になっていた。
つまり,これまでのNVIDIA製GPUではハイエンドモデルを使っても1桁本数のレイを投射処理するのがやっとだったのだ。それがいきなり60fpsの1フレーム,1ピクセルあたり約80本も投射できるようになると言えば,トンデモない性能向上なのが理解してもらえると思う。
これだけの性能向上を実現できたカギは,繰り返しになるが,「レイが3D空間を突き進む処理」や「レイとポリゴンとの衝突判定処理」を専用ハードウェアとしてのRT Coreで行うところにある。
 |
この問題を,「専用ハードウェアを搭載する」というやり方で,NVIDIAは解決したというわけなのだ。
もちろん,広大な3D空間に無数のレイを飛ばすのはとてつもなく時間がかかる。そこでNVIDIAは,この処理を高速化するために「Bounding Volume Hierarchy」(バウンディングボリューム階層構造,以下 BVH)という概念を取り入れた(関連記事)。
BVHは,3Dシーンを階層構造で記述する概念である。たとえば,ある3Dシーン内に巨大な船があると仮定しよう。そのとき,この船全体を覆うような箱(Bounding Volume)を定義しておくと,レイが船に衝突したか否かの判定を,シンプルな箱との衝突判定で代用できる。
 |
GDC 2018で,Remedy EntertainmentがゲームエンジンのDXR対応を説明するときに使ったスライドがあるので(関連記事),下に再掲しつつ,BVHの使い方をもう少し具体的に説明してみよう。
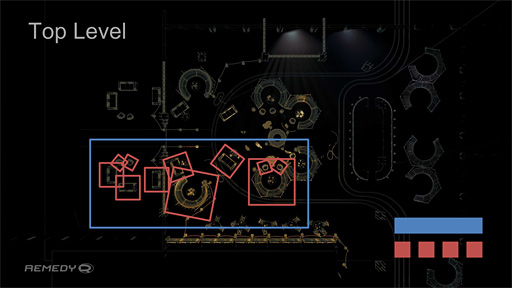 |
DXRの場合,シーンのデータ構造は階層構造になっている。いま挙げたスライドの例では,まず(黄色い線で描かれた)3Dオブジェクトと,その3Dオブジェクトを囲んだ赤い箱,そして赤い箱を複数集めてひとまとめにして囲んだ青い箱という3つの階層を確認できる。
レイは最初,青い箱との衝突判定を行い,衝突していれば階層を下って,次にどの赤い箱と衝突しているかを判定する。青い箱に衝突していないなら,赤い箱との衝突判定は不要なので,処理を省いていいわけだ。
赤い箱のどれかに衝突していると判断できれば,その箱に囲まれた3Dオブジェクトを読み出して,実際にどのポリゴンに当たっているかの判定を行う。こうした階層的な判定によって,レイの直進と衝突判定を効率よく行っていくのである。
 |
その答えはズバリ,「これまでのGPUと同じ」。つまり,プログラマブルシェーダで処理を行う。シェーダプログラムの部分は,従来の3Dグラフィックスとほとんど変わらないプログラムで処理できるので,「TuringはレイトレーシングGPUだ」と言っても,従来の3Dグラフィックスパイプラインはそのまま活用できるのである。
これまでのGPUアーキテクチャはそのままに,レイを飛ばす専用ハードウェアを追加することでレイトレーシング対応を果たしたのがTuringコアなのだと言うこともできるだろう。
レイトレーシング映像にデノイザを組み合わせるTuring
ここからは,TuringのRT Coreにまつわる細かい特徴や仕様について,質疑応答で判明した情報と合わせて紹介してみたい。
そもそも論として,RT Coreでレイを投射したり直進させたり,衝突判定行ったりするのをどのようにプログラムすればいいのだろうか。
その方法は2つある。1つはシンプルにDXRを活用する方法だ。DXRでは,レイを生成するプログラマブルシェーダ「Ray Generation Shader」が定義されているので,これを活用すればいい。前段で紹介したとおり,DXRにおける3Dシーンの構造データは,BVHで定義できるようになっているからだ。
2つめは,NVIDIAのDXR対応ランタイムモジュール「RTX Technology」(以下,RTX)を活用する方法である。
DXRは,NVIDIA製GPU以外にも対応する構造なので,多少なりとも抽象化レイヤーが存在していたりと,RT Coreが持つすべての機能を活用できるような構造にはなっていない(かもしれない)。それに対してRTXはNVIDIA製ミドルウェア的な立ち位置にあるので,比較的薄い抽象化レイヤー越しにRT Coreを利用できるという性能面での優位性を持つ。
ゲームや汎用ゲームエンジンなどは,NVIDIA製以外のGPUでも動作する必要があるため,DXRベースで開発されるだろう。しかし,3Dグラフィックス開発ソフトやレンダラーなどは,RTXベースで開発することもあるのではなかろうか。
 |
なおNVIDIAは質疑応答で,「現在のところ,NVIDIA以外のAPIとしてはDXRしかないが,いずれVulkanも対応するのではないか」という見通しを述べていたので,Vulkanが似たような仕組みを実装する可能性はある。ただし,OpenGLについての言及はなかった。
ところで,今回のイベントで公開されたリアルタイムレイトレーシングのデモ映像では,機械学習ベースのレイトレーシング用デノイザ(denoiser,ノイズ低減機能)や,深層学習ベースのアンチエイリアシング機能「DLAA」(Deep Learning Anti Aliasing)など,「レンダリングしたレイトレーシング映像の見栄えを良くするためのポストエフェクト」が適用済みだった。
こうしたAI系ポストエフェクトをTuringコアで実行した場合の性能について質問してみたところ,「現状,処理の所要時間は数ms」という回答が返ってきた。適用対象となるピクセル数によって処理時間は変わってくるそうだ。一方,シーンの複雑性には依存しないとのことである。
パフォーマンスのイメージとしては「複数フレームにわたるピクセルの相関性に配慮してアンチエイリアシングを行う『TAA』(テンポラルアンチエイリアシング)よりは(処理負荷が)重い」という補足も得られているので,記しておきたい。
デノイザのほうは正直なところ,フレームレートが重要になるゲームグラフィックス用途だと,NVIDIAの「GameWorks Raytracing」に組み込まれている,バイラテラルフィルタ(Bilateral Filter,エッジを保持しつつ画像を滑らかにするフィルタ)ベースの「Denoiser」のほうが,安定して性能が得られそうな気がしている。
ただ,発表イベントを見た人なら憶えているかもしれないが,Huang氏はこの点について「64サンプルで処理すれば,機械学習型デノイザ(によるポストエフェクト)でも,時間をたっぶりかけたレイトレーシング映像とほとんど変わらない(効果が得られる)」と述べていた。
「ゲームグラフィックスで実用レベルになるか」はひとまず置いておいて,NVIDIAはAI系ポストエフェクトをなるべく高速に処理できるようにしたいと考えているようだ。
 |
先ほど後述するとしたが,グラフィックス用途向けのQuadro RTXで推論処理アクセラレータに相当するTensor Coreを採用しているのは,ひとえにこのAI系ポストエフェクト高速化のためなのである。
 |
 |
ちなみに,今回のQuadro RTXシリーズが下手をするとホストコンピュータ側のメインメモリ容量より大きくなるかもしれないほどのグラフィックスメモリを積んでいる背景にも,レイトレーシングがある。
従来のリアルタイムレンダリング手法で主流のラスタライズ法では,視点から見えないポリゴン,いわゆる隠面ポリゴンはレンダリング時に除外してしまう。当然,画面外の3Dオブジェクトやポリゴンも破棄する。
ところがレイトレーシングでは,画面外(視界外)のオブジェクトが画面内(視界内)の光景に影を落としたり,間接光をもたらしたりするのが当たり前だ。たとえば床面がツルツルのタイルなら,視界外にある光景が床に映り込んだりするしれない。すなわち,視界外にも広がる広範囲の3Dシーン構造をグラフィックスメモリ上に置いておかなければ,正しいレンダリングを行うときに不都合が起きたり,処理性能面で問題を引き起こしたりしかねないのだ。
レイトレーシング時代のGPUは,今までのよりも多めのグラフィックスメモリを搭載してくるのが当たり前になるかもしれない。
“史上初のレイトレ向けGPU”比で約33倍の性能を持つ「史上初のレイトレ向けGPU」
Huang氏はTuringコアを「史上初のレイトレーシングGPU」と位置づけている。最終製品の市場投入までこぎつけたGPUとしてはまったくそのとおりなのだが,実のところ「史上初のレイトレーシングGPU」には先駆者がある。「PowerVR Wizard」のImagination Technologies(以下,Imagination)だ。
PowerVRシリーズで知られるImaginationは,既存のGPU IPコアにレイトレーシングエンジンを組み込んだ製品としてのPowerVR Wizardを2014年に開発し,製品発表している(関連記事)。動作デモも行われているので,「動作するレイトレーシングGPU」を出したのは,Imaginationがおそらく世界初と言ってしまっていいだろう。
ただImaginationは,最大の顧客であったAppleとの関係が切れたことで業績が悪化し(関連記事),結局,PowerVR Wizard搭載製品を市場に出すことのないまま開発中止してしまった。
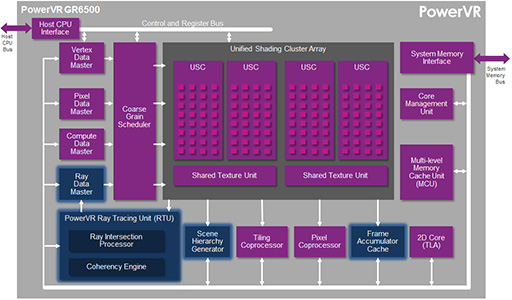
下に示したのは,PowerVR Wizardシリーズとして最初で最後の製品となった「PowerVR GR6500」のブロック図で,そこには「PowerVR Ray Tracing Unit」(以下,RTU)という機能ブロックがあるのだが,これはまさにTuringコアにおけるRT Coreと同じ用途,すなわちレイの投射と推進,衝突判定を行うものだった。
ImaginationはRTUに関する特許を保有していると思うのだが,RT Coreとの間で特許的な問題が解決しているのかどうかはちょっと気になるところだ。
 |
ちなみに,2015年時点におけるPowerVR GR6500のレイ処理性能は,300M Rays/s(毎秒3億レイ)。つまり,日の目を見なかった“史上初のレイトレーシングGPU”に対し,10G Ray/sのスペックで今回発表になった「史上初のレイトレーシングGPU」は約33倍の性能を持つわけである。
もちろんPowerVRシリーズは組み込み機器向けの製品なので,Turingコアと直接比較することに意味はない。ただ,それでも比較したくなるほど,Turingの登場はいろいろと感慨深いものがある。
- 関連タイトル:
 NVIDIA RTX,Quadro,Tesla
NVIDIA RTX,Quadro,Tesla
- この記事のURL:
キーワード
- 連載
- HARDWARE:NVIDIA RTX,Quadro,Tesla
- HARDWARE
- GPU
- NVIDIA
- イベント
- 西川善司の3Dゲームエクスタシー
- ライター:西川善司
- SIGGRAPH 2018
Copyright(C)2010 NVIDIA Corporation
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー