











イベント
次世代DirectXは推論アクセラレータとレイトレーシングの深淵へ向かう。2026年から先のDirectX最新事情
 |
タイトルからすると,Direct
そこで本稿では,セッション前半のDirectX本体に関する最新情報を取り上げよう。セッション後半に行われた新版DirectStorageについては,別途解説する予定だ。
●目次
10周年めのDirectX 12とバージョン管理の変化
 |
まずHargreaves氏は,2025年にDirectX 12が10周年を迎えたことに触れた。とはいえ,2015年の登場以来,DirectX 12に何も変化がなかったわけではない。
 |
DirectX 12は,機能レベルの違いにより,バージョン番号の小数点以下が変化する。
ベースとなる機能レベル12.0は,2015年に登場したが,当時すでに一部の高スペックGPUは,12.1に当たる機能を備えていた。
その5年後となる2020年には,機能レベル12.2が登場している。
DirectX 11以前の場合,DirectXのバージョン更新は,新しいWindowsの登場にほぼ同期していたが,その頃にはWindowsもDirectXも,大規模な更新が緩やかになってきた。
そんな理由もあって,機能レベル12.3はひとまず欠番となり,12.2の先は,更新サイクルを必要に応じて不定期に行うものとしたのだ。
新しいバージョン管理ルールとなったDirectX 12は,「DirectX 12 Agility SDK」という名称に改められている。
なお,MicrosoftはDirectX 11について,既存アプリケーションとの互換性維持や非ゲーム用途などのためにDirectX 12と併存させる方針を打ち出している。ただ,DirectX 12 Agility SDKに,DirectX 11の更新は含まれない。
DirectX 11のサポートは続けられるが,機能の更新は終了したと考えていいかもしれない。つまり,今後のDirectX 11でレイトレーシング対応が実現することはないのだ。
2026年3月時点でのDirectX 12の最新版は,DirectX 12 Agility SDKのVersion 1.619である。
ちなみに,1.6の「1」がメジャーバージョン番号で,「6」がブランチ識別子,19がアップデートの番号だ。たとえば,2026年内にリリースされるゲームに同梱されるDirectX 12 Agility SDKは,「1.6xx」となり,最新の実験的な新機能は「1.7xx」でプレビューリリースが行われるだろう。
 |
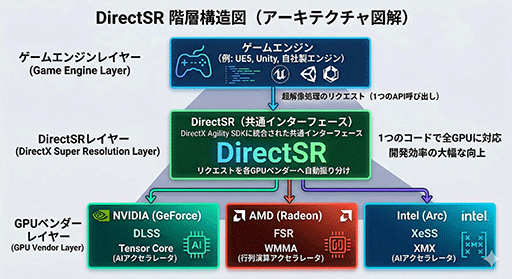
ところで,すっかり忘れてしまった人も多そうな,超解像処理系をDirectXシステムで抽象化して,DLSS/FSR/XeSSに半自動で対応できる「Direct Super Resolution」(DirectSR)はどうなったのか。
実際には,2024年リリースのDirectX 12 Agility SDK 1.714.0 preview版から提供が始まっているものの,積極採用されたという話はあまり聞こえてこない。「Unreal Engine」などのメジャーゲームエンジンでは,DirectSRに頼らず,独自にDirectSR相当の機能を搭載しているからだ。
 |
シェーダプログラムから推論アクセラレータを直接駆動
長らく,DirectXが手をつけてこなかった分野に,ようやく手が入った。それは,推論アクセラレータをシェーダプログラムから直接制御するための拡張だ。
この拡張は3つのアプローチで実現される予定であり,順を追って解説しよう。
2018年に,NVIDIAがGPUコア内部に推論アクセラレータ(※実体としては行列演算器)の「Tensor Core」を組み込んでから,すでに8年が経過している。
その間に,AMDやIntelも,推論アクセラレータをGPUに内蔵する動きに追従した。今ではモバイル系GPUにも,この動きは波及している。
だが,現行GPUのほぼすべてが推論アクセラレータを搭載したにもかかわらず,これをシェーダプログラム側から透過的に活用するための環境や言語の整備が行われていなかった。
たとえば,身近な例であるNVIDIAの「DLSS」を見ると,その動作メカニズムは次のとおりだ。なお,下記は現在のゲームグラフィックスで採用事例が多い「Deferred Rendering」系のパイプラインを前提としている。
- ジオメトリ描画(G-Bufferなどの描画)
- ライティングとシェーディングの実行
- ゲーム側の描画プロセスはいったん終了。ここまでの低解像度レンダリング結果や深度バッファ,モーションベクトルを,NVIDIA NGX API(NVIDIA Neural Graphics Acceleration)へ渡してDLSS(推論処理)を実行
問題は,2と3でパイプラインが分断されることだ。
なぜなら,GPUに推論アクセラレータが搭載されて8年も経っているのに,HLSLに代表されるシェーダプログラム言語から,推論アクセラレータ部分を実行する手段が整備されていなかったからだ。
そのため,NVIDIA GPU内の推論アクセラレータであるTensor Coreを活用するには,NVIDIA NGX API経由で呼び出すしかなく,そのためにレンダリングパイプラインをいったん分断するしかなかったわけだ。
 |
しかし2026年2月に,DirectX 12 Agility SDK Ver 1.619.0で正式提供された「Shader Model 6.9」(プログラマブルシェーダ Version 6.9)から「Cooperative Vector」が使えるようになったことで,事情は大きく変わることになる。
Cooperative Vectorは,任意のサイズのベクトルと行列の乗算命令などを,シェーダプログラムに直接記述できるようにする拡張機能だ。
具体的にいえば,ピクセルの色を決定づける目的のピクセルシェーダプログラムや,GPGPU寄りの処理を担うコンピュートシェーダプログラムに,小規模なニューラルネットワークを実行するコードを直接記述できるようになった。
もちろん,先述のようにパイプラインを分断する必要もなくなるわけだ。
 |
Cooperativeというキーワードに引っかかりを覚えた読者の直感は正しい。「誰が,何と協調するのか」という点が気になったはずだ。
従来,GPUで動作するシェーダプログラム,たとえばピクセルシェーダプログラムであれば,1スレッドで1ピクセルを独立して処理するイメージで動作していた。そのため,「ピクセルスレッド」と呼ばれることもあった。
しかしAIの処理系は,複数のスレッド間でデータを共有しつつ,行列演算を行う(≒推論アクセラレータを駆動する)必要がある。この複数スレッド間のデータ共有によってAIワークロードを実行する点から,名称にCooperativeと付いているのだ。
ただCooperative Vectorは,習得難度は高いとされ,DirectXのβテストでも評判はあまりよくなかったという。
というのも,Cooperative Vectorを使いこなすには,ハードウェアのアーキテクチャを深く理解している必要があったからだ。いわば,Cプログラム中に,インラインアセンブラを埋め込むようなイメージである。
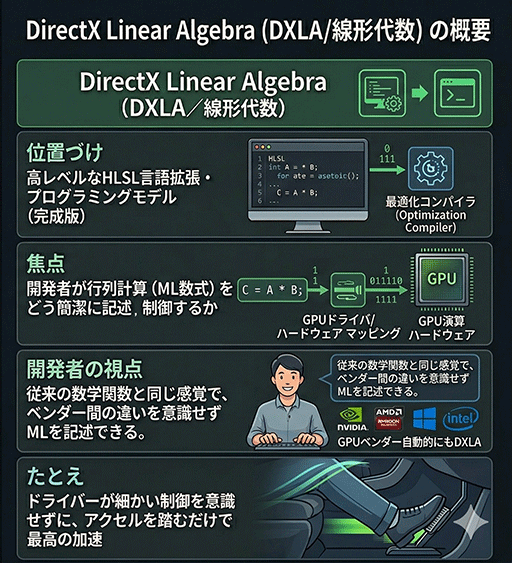
これは難度が高いとして,Cooperative Vectorのサポートを継続しつつ,新たに「DirectX Linear Algebra」(DirectX線形代数)を追加することになった。
DirectX Linear Algebraにて,シェーダプログラムから,高級言語で推論アクセラレータを制御できるようになる。2026年春に評価版がリリースされる予定で,DirectX 12 Agility SDKへの統合は,その後になる見込みだ。
 |
DirectX Linear Algebraでは,GPU内部のスレッド構造とどう協調させるかという部分を,プログラマが意識する必要はない。
たとえば,HLSL上で行列Aと行列Bを乗算するような数学的な行列演算命令を記述するだけで,あとはDirectXと各社のGPUドライバが,対象GPUのアーキテクチャにおけるスレッド間協調に適合したコードを,自動生成する仕組みだ。
Cooperative Vectorと比べれば,一般的な高級言語でプログラミングする感覚で扱える。
 |
 |
Cooperative VectorやDirectX Linear Algebraよりも,さらに抽象度を上げた手法である。
先述した2つのアプローチは,どちらかといえば推論アクセラレータの活用を,局所的なシェーダプログラムへ組み込むものだった。
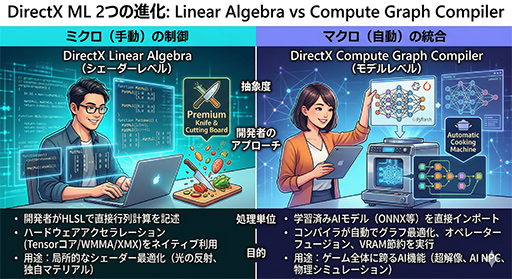
それに対して,3つめのアプローチであるDirectX Compute Graph Compilerは,どちらかといえばゲームエンジンに訓練済みの機械学習モデルAIをまるごと直接組み込むための取り組みだ。
「PyTorch」や「ONNX」などのAIフレームワークで作成された機械学習モデルAIを,ゲームのグラフィックスパイプライン上でネイティブ,かつ最高速で実行するためのコンパイラ技術,と言い換えてもいい。
これまでは,こうしたAI処理を実現しようとすると,AI処理がグラフィックス描画のリソースを奪ってしまうことがあり,また,それぞれの処理の最適な並列化や同期が困難だった。DirectX Compute Graph Compilerは,機械学習モデルAIの計算構造全体を分析して,1回分のGPU実行パスへと自動的に統合する役割を持つ。
 |
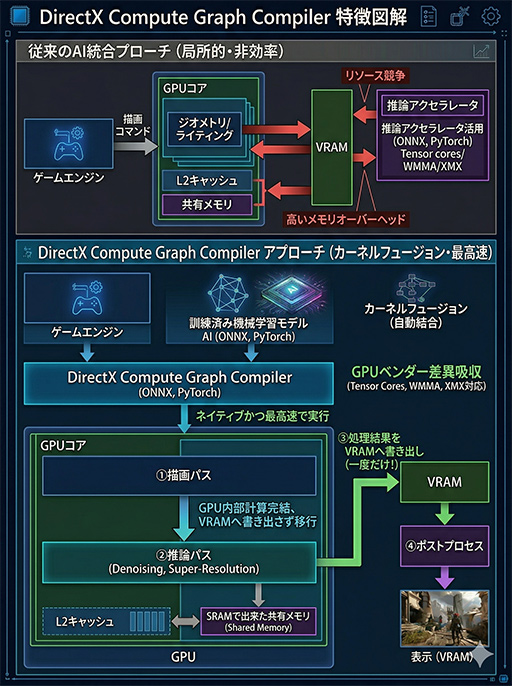
実行時には,機械学習モデルAIの処理においても,グラフィックスメモリへのアクセスを最小限に抑えて,GPU内のL2キャッシュやSRAMで構成される共有メモリ(Shared Memory)内で計算を完結させる。この動作こそがポイントだ。
ここからは筆者の所感になるが,説明を聞く限り,ソニーとAMDの共同プロジェクト「Project Amethyst」や,次世代Xbox「Project Helix」に搭載予定の新SoC(System-on-a-Chip)のコンセプトに非常に近い印象を受ける。
さらに,この機能がDirectXでサポートされるということは,GPUベンダーによるアーキテクチャの差異を吸収することを意味する。
つまり,DirectX Compute Graph Compilerを使うと,別フレームワークで開発した機械学習モデルを,NVIDIAのTensor Core,AMDの「WMMA」,Intelの「XMX」といった任意の推論アクセラレータで実行できるだけでなく,その処理をグラフィックス描画パイプラインと融合させることも可能だ。
具体的な動作の流れは,以下のようになる。
- 【描画パス】ジオメトリの描画,ライティング演算
- 【推論パス】Compute Graph Compilerが生成したAI処理を実行。Tensor Core,WMMA,XMXなどを用いてノイズ除去や超解像を処理
- 1〜2の処理結果がグラフィックスメモリへ書き出される
- 【ポストプロセス】最終的なポストエフェクトやUIを合成して表示
注目すべき点は,1と2の処理をグラフィックスメモリへ一切書き出さずに実行できることだ。
 |
DirectX RaytracingはNVIDIA案を標準仕様として採用
初めてハードウェアレイトレーシング機能を搭載したGPUは,NVIDIAが2018年に発表したGeForce RTX 20シリーズ(Turing世代)だ。
そして2018年末には,Turing世代のGPU仕様をDirectXに取り込んだ形の「DirectX Raytracing 1.0」が登場した。
2020年には,シェーダプログラムの中に直接レイトレーシングコードを組み込むインラインレイトレーシングに対応した「DirectX Raytracing 1.1」が登場。これら一連の新機能を搭載したDirectXは,「DirectX 12 Ultimate」と呼ばれている。
ここからは,DirectX 12 Agility SDK Version 1.619.0で実装された「DirectX Raytracing 1.2」の機能と,その先の展望についてまとめよう。
なお,レイトレーシングの基本については説明を省くので,こちらの記事を参照してほしい。
関連記事
 |
OMMは,NVIDIAのGeForce RTX 40シリーズ(Ada世代)で導入されたレイトレーシング向け拡張機能を,DirectX Raytracingの標準機能として取り込んだものだ。
なお,OMMについての詳細は,GeForce RTX 40シリーズの解説記事を参照してほしい。
関連記事



西川善司の3DGE:GeForce RTX 40完全解説。シェーダの大増量にレイトレーシングの大幅機能強化など見どころのすべてを明らかに
10月12日に第1弾製品の「GeForce RTX 4090」が発売となる「GeForce RTX 40」シリーズは,長いGeForceの歴史でも珍しいほど,多きの新機能や新要素を詰め込んだGPUだ。その見どころを大ボリュームの記事で徹底的にお伝えしよう。
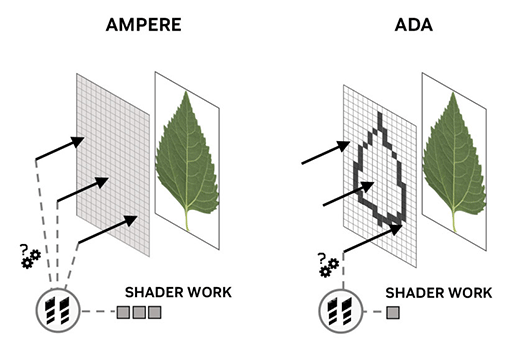
実務的な観点に絞って説明すると,レイトレーシングとは,3Dシーンへ飛ばしたレイが,3Dシーン内のどのポリゴンと衝突したかを調べる処理系だ。
レイと3Dシーン内の全ポリゴンを総当たりで計算していては無駄が多すぎる。そこで判定効率を高めるために,「BVH」といったデータ構造を用いるのが定石だ。
衝突したと判定されたポリゴンに,「葉」のような透明部分を含むテクスチャマップが適用されていた場合,レイが葉の実体に衝突したかどうかを見極めなければならない。
葉の輪郭外にあるテクスチャマップの透明領域に衝突した場合は,衝突していなかったと判定を改める必要がある。
従来であれば,こうした衝突判定は,プログラマブルシェーダがテクスチャユニットを介してテクスチャを読み出す必要があり,レイトレーシングのパイプラインが中断されることもあった。
この精査判定をプログラマブルシェーダに委ねる前に,明らかにテクスチャ実体に衝突している場合や,明らかに透明部分をすり抜けている場合であれば,レイトレーシングのパイプライン内で判定できるようにする仕組みがOMMだ。
簡潔にまとめると,各ポリゴンに適用されるテクスチャの不透明・透明要素の大まかな分布情報をBVHに内包できるよう拡張したもの,といったところか。
 |
もうひとつのSERについては,NVIDIAカスタム版UE5「NvRTX」の解説記事を参照してほしい。ここでは,ごく簡単に説明しておく。
SERとは,複雑度の近いピクセルやレイのスレッド同士を,GPU内部で動的に並べ替えてグループ化し,ライティングやシェーディングの並列演算が完了するタイミングを最適化する機能だ。レイトレーシングはもちろん,パストレーシングで最大の威力を発揮する。
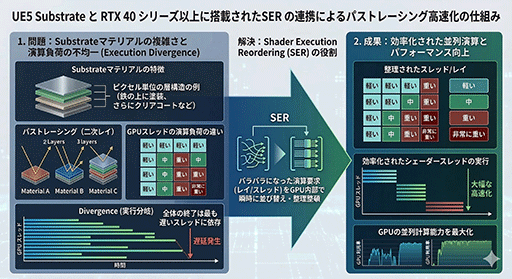 |
DirectX Raytracing 1.2では,GeForce RTX 40シリーズで実装されたSERを,標準機能として取りこんだ。今後AMDやIntelがリリースする新GPUも,DirectX標準のOMMとSERに対応するだろう。
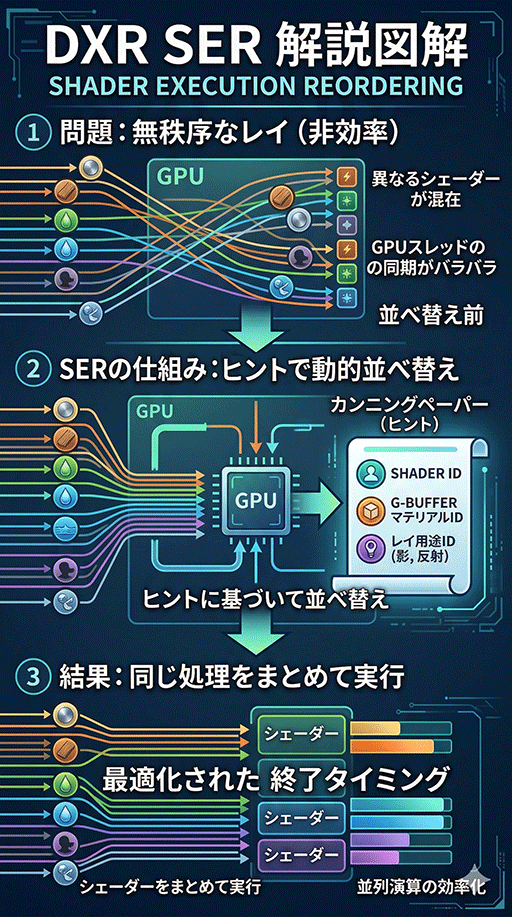
では,SERシステムは何を手がかりに,各スレッドが同種の材質を扱いそうだとか,同種の複雑度になりそうだと判断し,同じスレッドにまとめて実行するのだろうか。
結論から言うと,これはAIが介入する仕組みではない。開発者側(ゲームエンジンやグラフィックスエンジン)からの事前ヒントを頼りに,同じSERグループに振り分けるのだ。
たとえばSERシステムでは,レイがポリゴンと衝突したときに,「HitObject」という構造体オブジェクトが生成され,そこに次にどの材質のシェーダプログラムを実行すべきかを示す「Shader ID」が記録される。これを手がかりに,SERは同じShader IDを持つスレッド同士をグループ化するわけだ。
ただ,この手法は,比較的高度なやり方で,よりシンプルな手法もある。
たとえば,レイの発射元ピクセルのG-Bufferに含まれるマテリアルIDを手がかりとしたり,どの3Dモデルのどのポリゴンに当たったかといった3D空間情報をもとにしたりといった方法で,同じSERグループへ振り分けられるだろう。
同じポリゴンに衝突したレイスレッドは,同程度の処理負荷がある可能性が高いためだ。
また,「影生成用レイ」や「反射レイ」といったように,レイの用途ごとに固有IDをあらかじめ割り当てておき,そのIDごとにSERグループへ分ける方法もある。
 |
このように見ていくと,SERという機能は,比較的泥臭い仕組みであることが分かって面白い。
DirectX Raytracingは1.3を飛ばして2.0へ
Hargreaves氏は,続いて,DirectX Raytracingの新機能について説明した。いずれも「DirectX Raytracing 2.0」で実装予定である。
ちなみに,プログラマブルシェーダバージョンは6.10,「Shader Model 6.10」となる見込みだ。つまり,DirectX Raytracing 1.3は欠番となる
発表となった内容は以下のとおり。なお,より深い情報を求める人は,新DirectX Raytracingの仕様をまとめた公式Webページを確認してほしい。
●DirectX Raytracing 2.0で実装予定の機能
- Clustered Geometry
- Compressed Position Encoding
- TriangleObjectPositions()
- Partitioned top level acceleration structures
- Indirect acceleration structure operations
結論から言うと,これらのほとんどは,Blackwell世代のGeForce RTX 50シリーズに搭載された一連の拡張レイトレーシング機能そのものだ。NVIDIA案が再び,次世代DirectX Raytracingに採用されたと理解していい。
競合であるAMDのGPUは,そもそもRadeon系GPUへのレイトレーシング対応がNVIDIAより2年遅れたので,もともと勝負に挑んでいない雰囲気ではあった。
新機能のひとつめ,「Clustered Geometry」から見ていきたい。NVIDIAのGeForce RTXシリーズに,同名の機能は存在しないが,これはBlackwell世代で導入された「Mega Geometry」機能のことだ。
関連記事

西川善司の3DGE:GeForce RTX 50完全解説前編 Blackwell世代の構造とレイトレーシングにおける革新
Blackwell世代のGPU「GeForce RTX 50」シリーズは,製造プロセスこそ前世代と変わらないが,内部はゲームの性能にも関わるさまざまな改良が施されていた。NVIDIAが明らかにした詳細情報をもとに,前後編でGeForce RTX 50シリーズの全貌に迫ってみよう。
Clustered GeometryにおけるBVHは,3Dモデル単位ではなく,部位ごとの塊(Cluster)単位で定義される。これが,「ひとかたまりのジオメトリ」(Clustered Geometry)という名称の意味に通じる。
特徴的なのは,Clustered Geometryでは無段階LODを実現するために,全LODレベルの「ポリゴン数の少ない粗い部位モデル」を,すべて内包する構造になっている点だ。これは,テクスチャマップがデータ構造上,低解像度のMip Mapテクスチャを全階層分内包しているのとよく似ている。
テクスチャマップと同様に,階層構造のデータはサイズが大きくなりがちなため,圧縮が必要になる。
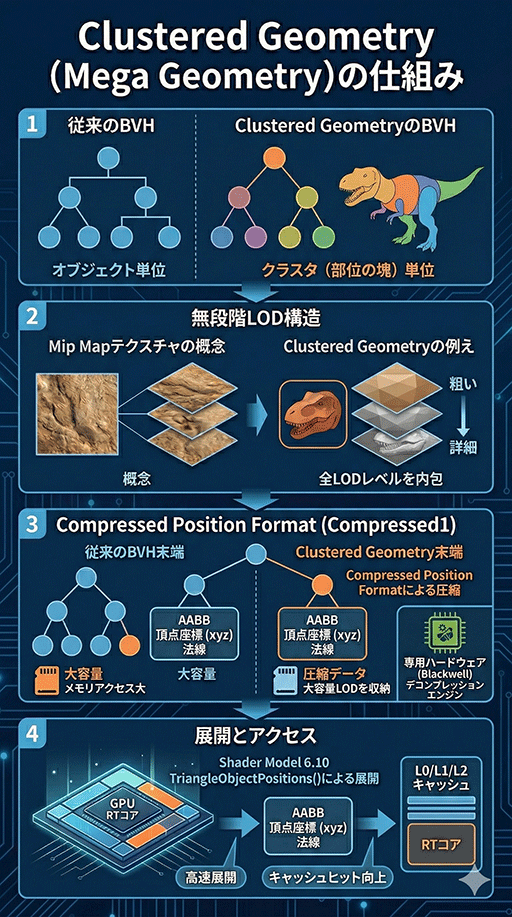 |
新機能の2つめは,Clustered Geometry機能を支えるサブシステム「Compressed Position Encoding」である。具体的には,レイトレーシングに用いる3DシーンのBVH構造体における末端部分のデータを圧縮する機能だ。
BVHでは,3Dモデルを覆うAABB(Axis-Aligned Bounding Box)の最小座標(xyz)と最大座標(xyz)が無圧縮で格納されており,その先には下階層にある直方体ノードへのポインタ情報や,末端ノードであることを示すフラグなどが格納されている。
ポリゴンの頂点座標(xyz)や法線,テクスチャアドレスなどのデータは,末端ノードに格納される仕様だ。
従来のBVHでは,この末端ノードのデータ群も無圧縮で格納されていたが,Clustered Geometryでは,全LODレベルの部位モデルのデータ群が階層構造として格納されるため,データ量が大きくなる。
そこで,末端ノードのデータ領域をハードウェアで圧縮する仕組みが導入された。
データの種別に応じて,ロスレス(可逆圧縮)またはロッシー(不可逆圧縮)から適切な圧縮方式が選ばれる。
圧縮によって小さくなったデータは,GPU側のラストレベルキャッシュに残りやすく,メモリアクセスの隠蔽に役立つのも利点だ。
展開処理は,専用のハードウェアで実行するため,極めて短時間で展開できる。
そして,この圧縮データから任意のポリゴンの頂点データや付随データを取り出すための仕組みが,「TriangleObjectPositions()」だ。
なお,筆者の調査によれば,この関数は,Shader Model 6.10で新設されるHLSLの組み込み関数になる見込みだ。
4つめの新機能「Partitioned top level acceleration structures」もBVHに関連するものだ。こちらも,Blackwell世代のGPUで,Mega Geometryに関連して追加された機能である。
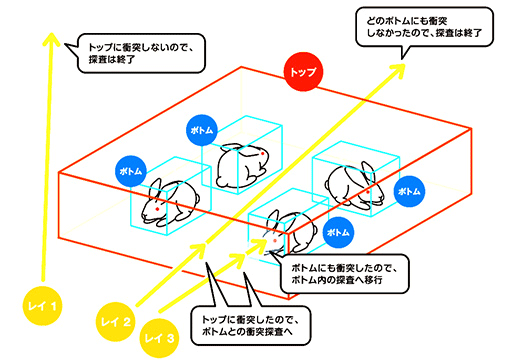 |
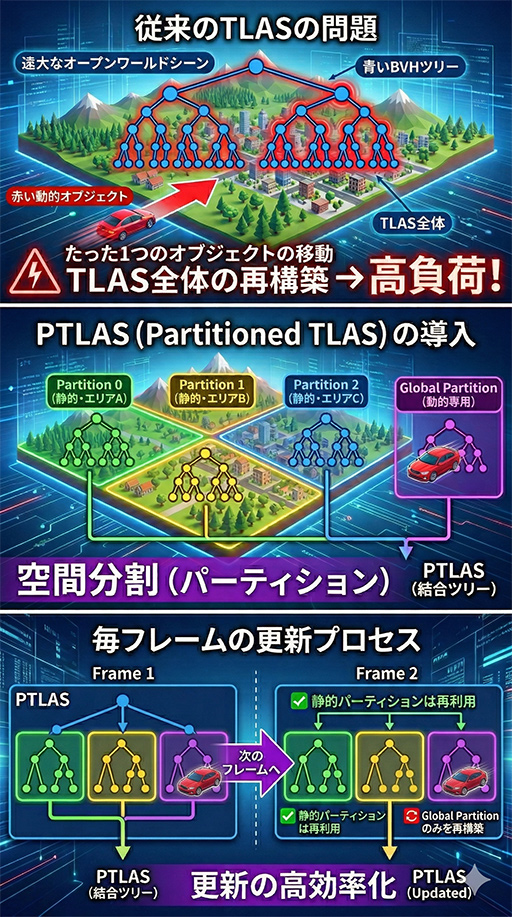
上の図におけるTLASとは,シーン全体のオブジェクトの配置を管理する構造体だ。従来は,たった1つの3Dオブジェクト(BLAS)が動くだけでも,TLAS全体の再構築や更新が必要だった。
オープンワールド型のゲームでは,扱う3Dシーンが非常に広大になりがちで,TLASも大規模なものになる。そのため,TLAS全体の更新が頻発すると,大きな負荷が生じていた。
そこでTLASを,複数のパーティションに分けて管理する「Partitioned TLAS」(PTLAS)とすることで,TLAS全体ではなく,変化のあったパーティション単位での更新,または「Global Partition」のみの更新へと処理を細分化して,負荷の低減を図っている。
 |
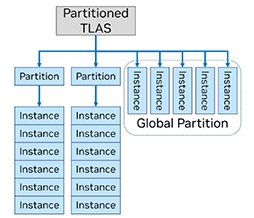 |
Blackwell世代GPUで追加されたGlobal Partitionも,DirectX Raytracing 2.0では正式仕様として導入される。
Global Partitionとは,各PTLAS管理下の3Dオブジェクトのうち,消えたり動いたりする動的オブジェクトを,動かない静的な3Dオブジェクトと区別して管理するための専用領域のようなものだ。
この仕組みにより,フレームごとにGlobal Partitionだけを作り直せばいいので,静的オブジェクトが存在する広範なBVHツリーには一切手を加える必要がない。つまり,フレームごとのBVH更新を効率化できるわけだ。
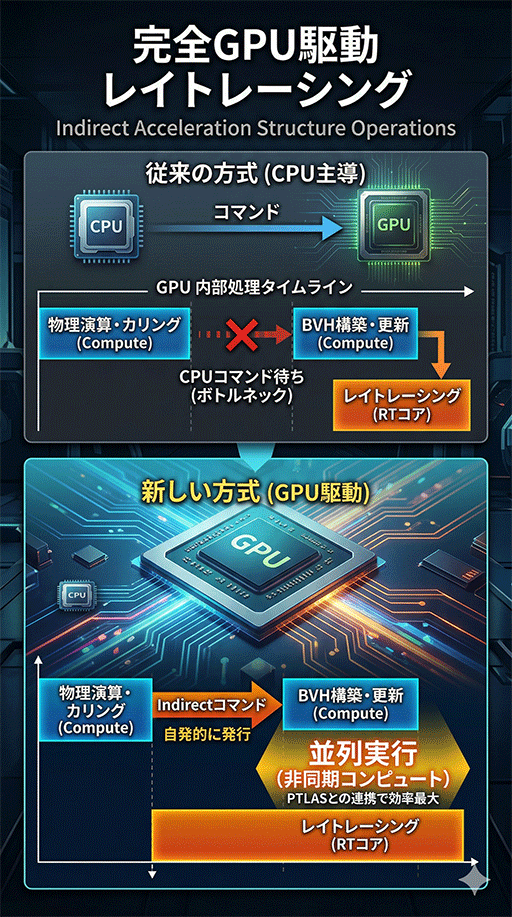
5つめの新機能「Indirect acceleration structure operations」も,レイトレーシングおよびパストレーシング世代のゲームグラフィックスにおいては,欠かせない重要な機能となるはずだ。
これをシンプルに言えば,BVH(TLASやBLAS)の更新を,CPUの手を借りずにGPU側で行う仕組みだ。
より具体的には,GPUベンダーがドライバに実装したCompute Shader製のBVHビルダーで,ほかのGPUスレッドと非同期かつ並列に,BVHの再構築をGPUが行えるようにする仕組みだ。
現在のゲームグラフィックスにおいては,CPUの介入を可能な限り排除して,GPUが自らコマンドを発行するGPUドリブンな動作へ移行しようとする動きが強まっている。
古くは,PlayStation 3時代から実用化されてきた,パーティクル制御をGPU内部で実行する「GPUパーティクル」などがその典型だ。
GPU自身が実行を制御する仕組みを象徴するDirectXのコマンドが,「Execute Indirect」だ。
現在のDirectX Raytracingのパイプラインでは,BVH(TLASやBLAS)を構築,更新するコマンド(BuildRaytracingAccelerationStructureなど)は,必ずCPU側から発行する必要があった。
そのため,Compute Shaderで実行した物理シミュレーションや,頂点シェーダで処理したアニメーション結果を,レイトレーシング側のBVH構造体に反映させるためには,CPUからの指示待ちというボトルネックが生じてしまう。
それがIndirect acceleration structure operationsに対応すると,たとえば,ある3Dオブジェクト群に対するジオメトリ処理が完了したことをトリガに,BVH更新をGPUが自発的に発行できるようになる。
CPUからの指示を待たずに処理を進められるため,GPU側では,たとえば別のPTLASに対するレイトレーシングを並列に実行できるようになるだろう。
 |
ところで,GPU主導で行われるBVH更新処理がどのように実行されるのか,気になる人もいるだろう。
GPUによるBVHの再構築は,GPUベンダーがグラフィックスドライバに組み込んだCompute Shader製のBVHビルダーで処理する。Compute Shader製のBVHビルダーが,新しい頂点座標をもとにAABBを再計算して,グラフィックスメモリ上にBVHデータ構造を構築する。
そしてその間にも,GPUは別スレッドを並列に動作させられることは言うまでもない。
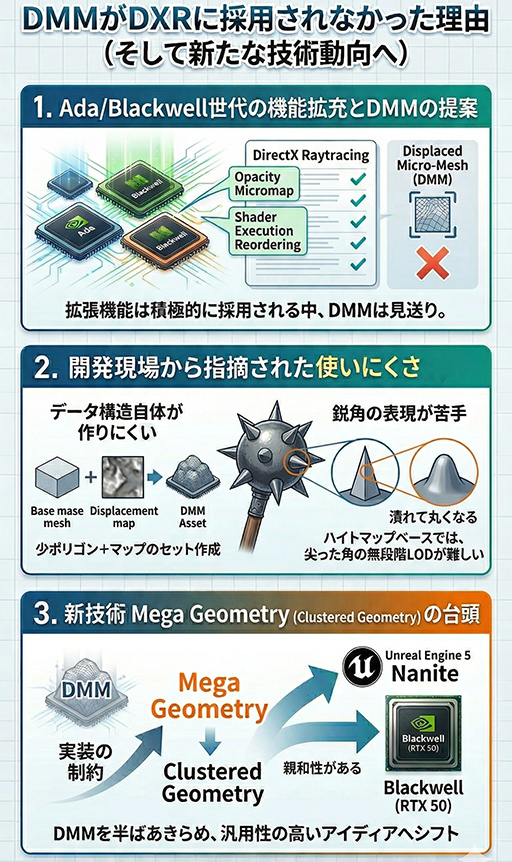
DirectX Raytracing 2.0に採用されなかったDis
Ada世代やBlackwell世代のGPUで導入されたレイトレーシング関連の拡張機能が,積極的にDirectX Raytracing 2.0に標準採用されていることは理解してもらえたと思うが,実は,採用が見送られた機能もある。
Ada世代で提唱された「Displaced Micro-Mesh」(DMM)だ。DMMは,レイトレーシングで扱うジオメトリ構造に,ディスプレースメントマップの概念を持ち込むものだった。
 |
このDMMの仕組みは,無段階で連続的なLODシステムの実現を目指すものだったが,開発現場から「使いにくい」との指摘を受けたため,事実上フェードアウトする可能性が高い。
使いにくいといわれた点を筆者が調べたところ,たとえば少ポリゴンモデルとディスプレースメントマップをセットで扱うDMMデータ構造を作りにくいのに加えて,ハイトマップベースでは,尖った角のように鋭角的なものの表現において,無段階LODへ対応しにくいといった汎用性の低さなどが指摘されている。
DMMには未来がなくなったものの,連続的LODの概念をレイトレーシングやパストレーシングの世界に持ち込む汎用性の高いアイデアとして,Clustered Geometry(Mega Geometry)がすでに採用済みである。
DMMをほぼ断念したからこそ,NVIDIAは,UE5のNaniteと親和性の高い「Mega Geometry」をBlackwellで新たに提案してきたのだ。
 |
こうして見ていくと,ここで挙げた新機能はいずれも地味ながら,レイトレーシングやパストレーシングがゲームグラフィックス描画の主流となるためには,欠かせないチューニングだといえよう。
MicrosoftのDirectXに関する取り組みから,ゲームグラフィックスの世界が,本格的にオールレイトレーシング,オールパストレーシングへと移行していく動きを見せ始めているのがよく分かった。
- 関連タイトル:
 DirectX
DirectX
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー