












連載
西川善司の3DGE:「GeForce GTX 1080」とはどんなGPUか。そのアーキテクチャをひもとく
北米時間2016年5月6日,NVIDIAは,米オースティン市で開催されたLANパーティーイベント「DreamHack Austin」に合わせ,新世代GPU「GeForce GTX 1080」(以下,GTX 1080)と,その下位モデルとなる「GeForce GTX 1070」(以下,GTX 1070)を発表した。
筆者の連載バックナンバー「NVIDIAが『GeForce GTX 1080』の発表会で語ったこと,語らなかったこと」でも指摘したとおり,発表時点でNVIDIAは詳しいアーキテクチャ解説をほとんど行わず,いくつもの「謎」が残ったわけだが,後日,世界中の報道関係者を招待して実施したイベントであらためてGTX 1080というGPUの詳細を語っている。本稿で紹介するのは,この「発表会に遅れて実施となったアーキテクチャ解説イベント」の内容だ。
メインスピーカーは,NVIDIAが抱えるGPUアーキテクトの1人で,上級副社長 GPUエンジニアリング担当のJonah M.Alben(ジョナ・アルベン)氏である。
「グラフィックス用GPU」というのも何だか変な言い回しだが,今回発表となったGTX 1080とGTX 1070は,NVIDIAが「Pascal」(パスカル)と呼ぶGPUアーキテクチャに属するGPUコアのうち,初のグラフィックス処理用となる「GP104」を採用するプロセッサである。
NVIDIAは,2016年4月に開催した自社イベント「GPU Technology Conference 2016」(GTC 2016)において,Pascal世代初のGPUとして「GP100」コアを数値演算用プロセッサ「Tesla P100」と発表しているので(関連記事),Pascal世代GPUとしては2製品めながら,“GeForce用”としてはGP104が初となるのだ。
ここ何世代か,NVIDIAのGPUコア開発コードネーム命名規則だと,頭が「G」で,その後にアーキテクチャ世代の頭文字が続いているが,今回のGP104もその命名規則どおりとなる。
ちなみに「xx4」という数字列からなるGPUコアは,コンシューマ向け(≒大多数のゲーマー向け)として,主に北米市場におけるメーカー想定売価で299
参考までに過去のxx4系を振り返ってみると,第2世代Maxellベースの「GM204」が「GeForce GTX 980」「GeForce GTX 970」(以下順に,GTX 980,GTX 970),Kepler世代の「GK104」だと「GeForce GTX 680」「GeForce GTX 670」といった具合。GTX 1080とGTX 1070も,NVIDIA内の位置づけとしては,このあたりの製品の後継ということになるわけである。
なお下に示した表は,GTX 1080の主なスペックを,GTX 980とGTX 680,そして参考までに第2世代Maxwellベースのトップエンドモデル「GeForce GTX TITAN X」と比較したものである。
GP104の製造で採用する技術は,GP100と同じく,TSMC(Taiwan Semiconductor Manufacturing Company)の16nm FinFET 3Dトランジスタプロセスだ。総トランジスタ数は72億個。第2世代Maxwellのウルトラハイエンドモデル「GeForce GTX TITAN X」(以下,GTX TITAN X)の採用する「GM200」コアだと,TSMCの28nm HP(High Performance)プロセス技術を採用して約80億個,実質的な先代となるGM204コアが52億個だったので,トランジスタ数だけ比較すればGP104の規模はGM200に近い。
一方,GP104のダイサイズは約314mm2。GM200の約600mm2より小さいのは当然として,GM204の398mm2よりも小さいわけで,ここは驚くところだろう。
チップの量産価格はチップ面積と深い関わり合いがあるので,GP104がコスト対スペック比に優れるのは,16nm FinFET技術による恩恵というところが大きい。
製造プロセスルールの微細化は,当然,消費電力低減にも結びついており,GP104のTDP(Thermal Design Power)を180Wとしている。絶対的な比較だと,GM204が165Wだったので,15W上がったことになるが,トランジスタ数が約38%増加しているのに対し,消費電力増加割合は約9%に留まっており,Alben氏も「消費電力1Wあたりの性能は格段に向上した」とアピールしている。
さて,GP104の全体ブロック図は以下のようになる。
GP104の総シェーダプロセッサ数(=総CUDA Core数)は2560基だ。GP100は3584基なので,70%強という規模感になる。さらにGM200は3072基,GM204は2048基という数字を並べると,「思ったよりもシェーダプロセッサの数が多くはなっていない」という印象を持つのではなかろうか。
この「先代比でそれほど増えていないシェーダプロセッサ数」で高い性能を叩き出すためにNVIDIAが採用したのが「高クロック動作」である。
プロセッサの性能を向上させるための最も基本的なアプローチながら,GPUのような大規模かつ複雑なパイプライン構成のプロセッサでの高クロック動作を安定的に実現するのは相当に困難だとされるわけだが,にもかかわらずNVIDIAはGP104で,ベースクロックで1.607GHz,ブーストクロックで1.733GHzを実現した。
発表会の当日,空冷クーラーのまま最大クロック2.114GHzでの動作をデモンストレーションしていたのは記憶に新しい。
Alben氏はこの高クロック動作のための工夫を「職人芸」(Craftmanship)という言葉で形容していたが,具体的にいえば「物理設計の徹底的な最適化」によって実現されたものということだろう。
クロック絡みでは,Alben氏の言う職人芸とは別の話として,「GPU Boost」にも地味ながらアップデートが入っている。
NVIDIAはKepler世代以降,チップの発熱量などに配慮しつつ,GPUのコアクロックを動的に制御するGPU Boostを多くのGeForce GTX GPUで有効化しているが,GTX 1080とGTX 1070ではこれが第3世代の「GPU Boost 3.0」になったのだ。
Maxwell世代以前では,駆動電圧にかかわらず一定比率のクロック引き上げしか行っていなかったが,Pascal世代のGPU Boost 3.0では,電圧ごとに異なる最大クロックでGPUを駆動できるようになったというのが,最大のトピックとなる。
具体的には,低電圧のときに高クロック駆動できるような制御が可能になっており,チップが持つ理論最大動作周波数にかなり迫ることができるようになったという。
なお,GTX 1080の論理性能値となる単精度浮動小数点演算性能は,ブーストクロックである1.733GHzで計算した約8873 GFLOPSが公式の値となっている。
これはCUDA Coreが1クロックあたり1個の積和算(2 FLOPS)を行えることから,以下の計算式で求めたものだ。
同じ計算でGM200は約6144 GFLOPS,
ちなみに先ほど紹介した2.114GHzオーバークロック動作時だと,同じ計算で,
となり,GPU 1基でついに10 TFLOPSを超えてくる。公称性能値ではないものの,とうとう10 TFLOPSの大台を突破できる時代になってきたというのは感慨深い。
GP104は基本的に,CUDA構想を基軸とするアーキテクチャになったTeslaコア世代以降の遺伝子を受け継いだ内部構成を採用している。
複数個のシェーダプロセッサとスケジューラやロード/ストアユニット,超越関数ユニット(以下,SFU),L1キャッシュ,テクスチャユニット,そしてジオメトリエンジン「PolyMoprh Engine」を組み合わせた「Streaming Multiprocessor」(以下,SM)を構成したうえで,さらにこのSMを複数個束ね,そこにラスタライザたる「Raster Engine」を与えて1つのミニGPUコア「Graphics Processing Cluster」(以下,GPC)として構成するという仕様だ。
一方でTeslaコア世代以降,Fermi,Kepler,Maxwellと世代を経るごとに,
ではGP104はどうか。結論から先に述べてしまうと,GP104の内部構成は,GM204と酷似している。
まず,GP104のGPC数は4基で,GM204と同じ。GPCが4基という仕様はGK104もそうだったので,xx4系GPUの共通仕様と言ってもいいだろう。
GPCあたりのSM数は,GM204の4基からGP104で5基構成に変わったので,「同じではないじゃないか」と思うかもしれない。しかし重要なのは,世代単位でがらりと変わってきたSMの内部構成が,GP104とGM204でほぼ同じことだ。そのためGP104は,「GM204をベースに,GPCあたりのSM数を増やしたもの」のようにも見えるのである。
一応詳しく見てみると,SMあたり4基の「Warp Scheduler」があって,Warp Shedulerごとに2基の「Dispatch Unit」があるため,4つのWarpに対して個別の命令実行を2つずつ仕掛けられることが分かる。
「Warp」とはNVIDIA製GPUにおける処理スレッド実行単位の概念である。Warpについての詳細は筆者による「GeForce GTX 480」解説記事を参照してほしいが,簡単に言えば,「1 Warp」とはひとかたまりとなる32スレッドのこと。イメージしやすいピクセルシェーダで言い換えると,ピクセルシェーダプログラムの1命令が,32個のピクセルに対して並列に実行されるイメージだ。
で,先ほど述べたとおり,GP104では32基のシェーダプロセッサに対して2命令実行を振り分けられる構成になっているが,これがGM204とまったく同じ構成なのである。仕様の根幹を成すWarp周りが変わらないため,SMあたりのシェーダプロセッサ総数も128基でもちろん変わらない。
かつて,Kepler世代からMaxwell世代に切り替わったときレジスタファイルの増強があったので,今回も再強化があったのかと思いきや,そこも変わらず。「Warp処理あたりに利用できるレジスタファイルは32bit×16384個」のままである。
なら周辺はどうか……と見てみると,テクスチャ/L1キャッシュが48KB
Alben氏に「倍精度浮動小数点(FP64)の演算性能」と「半精度浮動小数点(FP16)の演算性能」についても確認してみたところ,「単精度浮動小数点(FP32)に対する性能比率はMaxwell世代と同じ」との回答だった。
つまり,GP104では,Maxwell世代と同じく,
ということである。なお,上で示したブロック図に倍精度浮動小数点の演算器(DP)は描かれていないが,GP104には(GM200,GM204と同じく)SMあたり4基のDPがある。
参考までに書いておくと,GPGPU用のGP100における性能比率は以下のとおりだ。
「GP104はグラフィックス用だ。なので,倍精度浮動小数点演算性能は抑え気味という可能性はあるだろう」と思いつつも,同じPascal世代なので,GP100と同じ方向性の性能設計をGP104でも採用すると筆者は思っていたのだが,ここはまったく予想と違っていたことになる。
Alben氏はこの理由について,「ゲームやVRにおいて,倍精度や半精度はそれほど重要ではないため」と説明していたが,倍精度はともかく,半精度はハイダイナミックレンジ(High Dynamic Range,以下 HDR)レンダリング用途のピクセルフォーマットで高頻度で利用されるという現実がある。また,それに関連したデータの取扱単位や演算単位は半精度になっていることも多いので,少々意外な決断だと感じた次第だ。
ということで,ここまでをまとめると,実際のところGP104は,
GPUということになるだろう。
ここであらためて,「同じPascal世代であるはず」のGP100とブロック図を見比べてみると,随分と異なるのが分かる。
詳細はGP100の解説記事を参照してほしいが,GP104とGP100で比較すると,GP104は,SM数あたりのレジスタファイルが半分に,そしてSMあたりのシェーダプロセッサ数が倍になったコアになっているのが分かる。
GP100においてはレジスタファイルの増強しているとも言えるわけだが,これは,Warp処理スレッドの切り換えを高効率に行うことにつながり,ひいてはメモリアクセスの遅さを高効率に隠蔽できることにもつながる。
なおAlben氏に「GP100とGP104とではどちらの開発開始時期が先か」と質問したところ,「GP100が先で,GP104が後だ。なので,機能設計としてはGP104のほうが新しい」という返答が得られた。
つまり,GP104の開発をGP100の後で開始したにもかかわらず,GP104でNVIDIAは「GP100で行ったようなSMの構造改変は,GP104では不要」と判断したということだ。グラフィックス用GPUとしてはMaxwellベースのSM構造でいいとNVIDIAは判断したというわけで,この点も興味深い。
SMあたり1基用意されるジオメトリエンジンのPolyMorph Engineは,Maxwell世代の「PolyMorph Engine 3.0」から,GP104で「PolyMorph Engine 4.0」へとバージョン番号が上がっている。
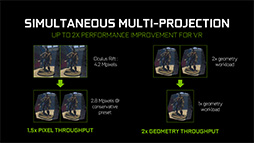
どこが変わったかといえば1点,「Simultaneous Multi-Projection」(サイマルテイニアス・マルチプロジェクション,以下 SMP)と呼ばれる機能の追加である。逆に,SMP以外はPolyMorph Engine 3.0から変わっていない。
Alben氏にも確認したが「ジオメトリシェーダやテッセレーションステージの中間バッファ増強やパイプライン最適化などは行っていない。Maxwell世代からの変更はない」とのことである。
では,SMPとはどんな機能なのか。
具体的な活用ケースについては先行して掲載したレポート記事を参照してもらうとして,本稿ではアーキテクチャ面から「機能がどう実装されたか」を見ていこうと思うが,先の記事における予想が正解で,ラスタライザの機能増強に相当するものであった。
いわばプログラマブルラスタライザの一歩手前的な「コンフィギュアブルラスタライザ」とも言うべきものになる。
頂点シェーダとジオメトリシェーダ,テッセレーションステージなどで構成される頂点パイプラインでは,x,y,zの3D座標からなる頂点単位の仕事,分かりやすく言い変えればポリゴン単位の仕事をしているわけだが,グラフィックスをピクセルとして画面に描画するためには,ポリゴン単位のデータ構造だったものをピクセル単位の仕事に分解してから,ピクセルシェーダを動員するという流れの処理が必要になる。
この「ポリゴン→ピクセル」の分解を行うのがラスタライザ(Rasterizer)だ。
ラスタライザは,「カメラを基準にして,テレビやディスプレイといった描画対象の2D平面に投射(Projection)する」処理を行うものとも言えるのだが,そのとき,投射の仕方をプログラムできるようにしようという,「プログラマブルラスタライザ」のアイデアが,CG業界では結構前から提案されていた。今回GP104が採用したSMPは,このプログラマブルラスタライザの概念を限定的に実用化したものということになる。
従来,GPUのラスタライザは,描画先が1視点,1画面という想定の下で設計されていたわけだが,近年では,描画先を3画面としたマルチディスプレイ環境や,3D立体視,VR(Virtual Reality,仮想現実)といった,多視点描画の機会も増えてきている。
ただ,描画先を1視点,1画面と想定して設計された従来型GPUラスタライザでは,多画面や多視点描画にあたって,「頂点パイプライン→ラスタライザ」のパスを画面数や視点数分だけ回さなければならない。3D立体視やVRを実現するなら,2視点分の描画を行う必要があり,ひいては2回分の描画パイプラインを回さなければならなかった。
同一時間軸にある同一シーンの多画面や多視点描画を頂点パイプラインで複数回処理するのは事実上の反復であり,冗長以外の何ものでもない。そこでラスタライザを強化し,複数視点,複数画面の投射をできるようにしたのが,
GP104のSMPでは,「投射先の2D平面」を16個まで持てるようになっている。
複数持てる投射先の各2D平面では,その位置や角度,傾きなども設定でき,さらには3D立体視やVR用にカメラ基準点を2つ持たせることもできる。つまり,「頂点パイプラインを1回だけ実行したうえでの,多画面,多視点複数投射系」を,
効果だけ見れば,「これまでは異なる投射系へ描画するたびに行っていた,頂点シェーダやジオメトリシェーダ,テッセレーションステージなど頂点単位の演算処理を,1回で済ますことができるようになる」のである。
前述のとおり,GP104でSMPが持てる投射系は最大16個だが,これはいま例に挙げた3D立体視やVR,3画面マルチディスプレイといった事例だけを想定している限り,多すぎるくらいだ。
筆者も当然そこは疑問に思って,「なぜ16個なのか」と聞いてみたのだが,明確な回答は得られなかった。NVIDIAとして,いま挙げた3つの使い道を想定しているのは間違いないようなので,とりあえず実現できるから16個として,あとは開発者のアイデアに期待しているといったところだろうか。

GTX 1080がグラフィックスメモリとしてGDDR5Xを採用したこともホットトピックだ。
GDDR5Xについての詳細は大原雄介氏による解説記事を参照してもらえればと思うのだが,簡単に言えば,データ転送レートがGDDR5の2倍,動作クロック比で8倍となる特徴を持つメモリである。
GP104では1.25GHz駆動のGDDR5Xメモリを採用しているので,そのデータ転送レートは10Gbps。4Gamerの慣例表現に従って表現するなら,10GHz相当の動作クロックということになる。
大原氏の記事にもあるとおり,GDDR5と同じように,GDDR5Xでは異なる2つのアドレスを指定してアクセスすることになるが,GDDR5では16 bytes×2組=32 bytesが最小アクセス単位になるのに対し,GDDR5Xではこれが32 bytes×2組=64 bytesとなる。つまり,「GDDR5Xはメモリへのランダムアクセスするときのアクセス粒度が粗くなる」ということなのだが,Alben氏の説明では,「グラフィックス用途だと,64 bytesが最小アクセス単位となることが大きな問題にはならない」とのことだった。
もともとグラフィックス処理は連続したアドレスへのメモリアクセスが主体であり,ランダムアクセス時において発生しうるデータ伝送の冗長性よりも,連続したアドレスへのメモリアクセス時の高速優位性の恩恵のほうが大きいということなのだろう。
GP104のメモリコントローラは8基あり,1基当たりのメモリバス幅は32bit。すなわち,GP104のメモリバス幅は256bitということになる。なのでメモリバス帯域幅は,以下のとおり求められる。
ちなみに,GDDR5メモリの384bitメモリバスを採用するGM200,GDDR5の256bitメモリバスを採用したGM204のメモリバス帯域幅はそれぞれ以下のとおりだ。
GP104,メモリバス幅こそ256bitのままながら,GDDR5Xを搭載することで,GM204と比べ1.4倍以上のメモリ性能を獲得し,384bitメモリバスを採用するGM200のそれに迫っているということになる。
ただ,話はそれで終わらない。
陰影計算を経たピクセルデータは「Rendering Output Pipeline」(以下,ROP)ユニットによってグラフィックスメモリへ書き出される。そして,このROPユニットがメモリコントローラあたり8基セットになるため,全体としては64基となる仕様はGP104でGM204から変わっていないのだが,グラフィックスメモリへ出力するデータをリアルタイムにロスレス(可逆)圧縮する仕組みのアルゴリズムを,NVIDIAはGP104で改善しているのだ。
NVIDIAは第2世代Maxwellで,「グラフィックスメモリへ出力するデータをリアルタイムにロスレス圧縮する仕組み」を導入した。それによりメモリバスの消費量を25%低減できたとして,たとえばGTX 980の場合,メモリクロックが7GHz相当のところ,「実効メモリクロック9.3GHz相当」だと主張していたのを憶えている人も多いだろう(関連記事)。
要はこの仕組みを,GP104でNVIDIAはさらに改善したというわけである。
第2世代MaxwellでNVIDIAがメモリバス消費低減に向けて採用したのは2分の1圧縮や8分の1圧縮のメソッドだったが,GP104では,新しく2つの新メソッドを追加導入したことで,圧縮を適用できる場面が増えたという。
新しい4分の1圧縮メソッドはグラデーション表現などの色差分が小さいケースで適用される。
また,新しい8分の1圧縮メソッドは,2×2ピクセル粒度での圧縮と,いま述べた新しい4分の1圧縮メソッドを同時に使うケースで用いられるとのことだ。
Alben氏によると,両モードによってロスレス圧縮の効果はさらに高まっており,圧縮効率はGM204の1.2倍相当になるそうだ。
圧縮を適用できる場面が増えると,データによるグラフィックスメモリの占有量が減り,さらにL2キャッシュの利用効率も高まることになる。そのためAlben氏は「GP104のメモリ性能はGM204比で1.7倍に相当する」と主張している。
1.7倍という数字はどこから出てきたかというと,前述した「メモリ帯域幅がGM204の1.4倍」と,「新しい圧縮手法の追加でメモリ利用効率がGM204の1.2倍」という,2つの倍率の掛け合わせである。ただし今回NVIDIAは,第2世代Maxwellのときのような「実効メモリクロック」を示していない。
まぁ,この値は話半分に聞いておくにしても,圧縮を適用できる場面が増えたことだけは間違いないようだ。
2015年10月,AMDが「NVIDIA製GPUは,DirectX 12の優位性を活用できない」という主張を行って話題を集めた(関連記事)。その根拠は「Maxwell世代のGPUでは,グラフィックス描画とGPGPU処理を同時実行できないため」というものだった。
AMDはまた,「DirectX 12では,APIレベルで,グラフィックス描画とGPGPU処理を並列実行させる機能がサポートされているのだが,このAPIを活用しても,Maxwell世代のGPUでは正しく並列実行されず,逐次実行となってしまう」ことも,同時に指摘している。
この問題について,NVIDIAも早くから認識はしていた。というより,NVIDIA側の回答は簡単に言えば「仕様です」というもので,もともとこうした機能はPascal世代からの本格対応が予定されていたのだ。裏を返せば,AMD製GPUは,異なるコンテキストのGPU活用において一日の長があり,AMDはそこを突いたマーケティングキャンペーンを行っていたわけだ。
で,Pascal世代のGP104ではどうなったかというと,グラフィックス描画のスレッドとGPGPUスレッドの発行を並列に仕掛けた場合,その実行スレッドの切り換えを100μs未満で行えるようになった。このような,「実行スレッドの切り換えをスレッド優先順位に従いつつ割り込みを行う仕組み」のことを「プリエンプション」(preemption)という。
さらに,そのスレッド切り換えを,ほとんどCPU並みの細かさで実現できるようにもなっている。グラフィックス描画を例に挙げると,GP104は1ピクセル単位の粒度で別コンテクストの処理へスレッドを切り換えられるようになっている。この機能は,GPUを仮想化したときの性能向上にも大きく貢献できるだろう。
ちなみに,Maxwellコア以前のGPUにおいて,グラフィックス描画スレッドの切り替えを行えるのは描画コマンド単位だった。1ポリゴンを画面いっぱいに描くようなスレッドを実行していた場合,スレッドの切り換えは画面全体のピクセルを描画し終えるまで行えなかったのである。
一方のGPGPUスレッド切り換えにあたって,NVIDIAは2つの粒度を設定している。
DirectX 12のAsynchronous Shader(Asynchronous Compute)APIを使ったときには,GPGPU処理スレッド単位での切り替えが可能だ。あるひとかたまりのデータに対するGPGPUスレッドが発行された場合,当該スレッドの切り換えは,1つのデータに対する処理が終わった段階で行うということである。グラフィックス描画における「1ピクセル単位」と,粒度としては同等という理解でいい。
CUDAアプリケーションにおけるスレッド切り換えの粒度は,さらに細かく,実行命令単位で可能となっている。そう,ほとんどCPUと同じレベルのスレッド切り換えが可能なのである。
これでNVIDIA製GPUも,異なるコンテクストを並列実行するときに抱えていた実行効率の負い目が解消したというわけだ。

GP104では,複数GPUを活用するSLIモードに関する戦略にも若干の変更が見られる。このあたりについても触れておこう。
まず,GP104でもNVIDIA伝統のマルチGPUソリューション「SLI」はサポートされるが,GP104における推奨は2-way SLIとなる。理由は「3-way以上では性能向上率が芳しくないから」(Alben氏)とのことだ。
合わせて,GP104のタイミングでSLIブリッジコネクタは「SLI HB Bridge」にリニューアルととなった。
この新しいSLIブリッジコネクタは,「HB」(High Bandwidth)の略称から想像できるとおり,ピクセルデータの伝送クロックが,従来の400MHzから650MHzへ高められて(帯域幅が向上して)いるのが特徴だ。ただ,従来のブリッジコネクタも,速度性能さえ気にしなければそのままGP104で使えるという。
Pascal世代のGPUが,わざわざ新しいSLIブリッジコネクタを伴って登場したことで,GP100にて新設となったプロセッサ間接続用専用バス「NVLink」をGP104でもサポートしているのではと期待してしまった人もいると思うが,Alben氏に確認したところ「GP104にNVLinkの機能はない」とのことだった。今回の新しいSLIブリッジコネクタは,NVLinkとは無関係という理解でいいようである。
ちなみに,3-wayや4-wayのSLI構成はできないのか? というと,サポート自体はある。NVIDIAによると,3/4-way SLIをアンロックするための特別なキーコード(シリアルコード)を今後,NVIDIAの特設ページで案内して提供していく計画のようだ。
なお,“3/4-way用のSLI HB Bridge”の提供予定はないそうで,GP104での3/4-way SLI動作にあたっては,従来のSLIブリッジを利用する必要がある。
SLIというか,マルチGPU構成に関してはもう1つトピックがある。DirectX 12は,Multi Display Adapter(以下,MDA)とLinked Display Adapter(以下,LDA)という2つのマルチGPU動作モードをサポートしているが,GP104では,このLDAモードに関するサポートが追加されているのだ。
MDAは,同一メーカーのGPUはもちろん,異なるメーカーのGPUが同一システムに搭載されていた場合でも,アプリケーションが個別に駆動できるモードになる。
LDAは,ブリッジコネクタを駆使することで複数のGPUを1基のGPUに見立てて取り扱えるモードなのだが,LDAには「LDA IMPLICIT」(暗黙)モードと「LDA EXPLICIT」(明示)モードの2つがあり,今回追加されたのは後者となる。
ちなみにLDA IMPLICITというのは事実上のSLI(もしくはCrossFire)モードのことで,ドライバ側で“勝手に”複数のGPUを駆使して描画を行うことになる。
これに対してLDA EXPLICITモードだと,アプリケーションからは複数のGPUが1基のGPUに見えるようになり,アプリケーションからこの「1基のGPUに見える複数のGPU」をフルにプログラムできる。LDA IMPLICITの場合,アプリケーションが取り扱えるグラフィックスメモリの最大容量はGPU 1基分になってしまうが,LDA EXPLICITではそれぞれのGPUが持つグラフィックスメモリの合計容量を扱えるのもポイントだ。
もっとも,実体GPUごとに分散してしまったデータを,もう片方側のGPUから直接的にアクセスすることはできず,データのコピーが発生してしまう。そのため,グラフィックス描画でLDA EXPLICITモードを活用するのは難度が高い。おそらくLDA EXPLICITモードは,主にGPGPU(≒DirectCompute)向けと思われる。
NVIDIAは,描画したグラフィックスをディスプレイシステムに表示するための仕組みについて,これまでもさまざまなアイデアを提案してきた経緯があるが,GP104で,また新しいものを提案してきた。それが「Fast Sync」だ。
GP104専用ではなく,従来のNVIDIA製でもサポートされることになるFast Syncだが,これは簡単に言うと,描画パイプラインと表示パイプラインを非同期で実行するディスプレイ同期技術である。
描画された映像を,垂直同期を待って表示にかかるのがVsync有効,待たずに,描画途中であっても,新しく描画が完了した映像の表示に切り替えるのがVsync無効なわけだが(関連記事),新しいFast Syncの表示メカニズムも基本的にはVsync有効と変わらない。
異なるのは,Vsync無効時と同じように,描画パイプラインが垂直同期を無視する点だ。描画パイプラインが垂直同期を無視して描画済みの映像を送ってきても,映像表示メカニズム側(=映像の送出制御側)では,「次に表示予定の映像が描画」が終わっていなければ,新しい映像の表示は次回に持ち越し,現在表示している映像を継続して表示させる。
基本,可変フレームレートでの使用を想定した機能なので,場合によっては,突然フレームレートが向上した結果として,次に表示予定だった映像よりも,さらに新しい映像の描画が完了してしまっている場合もある。その場合は,本来ならば次に表示すべきだった映像は捨てて,最も新しい時間軸上の映像を選択して表示する。この場合,1コマ落ちることになるが,最新映像の表示を優先させたため,遅延は避けられることになる。これがFast Syncの動作アルゴリズムだ。
NVIDIAによれば,NVIDIAコントロールパネルからFast Syncを選択した場合,「比較的フレームレートの高い,可変フレームレートのゲームでの見栄えがよくなる」とのこと。合わせて,GPU主導の表示メカニズムである「G-SYNC」を置き換えるものではないとも説明していた。
GP104では,HDMI 2.0aおよびHDMI 2.0bに対応したことで,最近になって少しずつ増えてきたHDR対応テレビでのHDR表示が可能になっている。
HDMI 2.0aはともかく,HDMI 2.0bは耳慣れないという人もいそうだが,どうやら,4KだけではなくフルHD解像度でもHDR表示を可能にする拡張仕様のことを指しているようである(関連リンク)。
筆者の取材によれば,GP104がサポートするHDRフォーマットは,現状,一般に4K Blu-rayと言われる「Ultra HD Blu-ray」の「HDR10」方式のみとのこと。現状では,「Dolby Vision」「Hybrid Log-Gamma」といったHDR映像フォーマットには対応していないという。
HDR10は,YUV各10bit,YUV=4:2:0フォーマットのHDR形式だが,話を聞いたNVIDIAの担当者は「GP104ではそれ以外にも,YUV各12bit,YUV=4:2:2フォーマットの広色域モードをサポートする」と説明していた。これはおそらくHDRのことではなく,BT.2020で規定される広色域への対応のことを言っているのだと思われる。
NVIDIAは「ゲームのHDR対応は急速に進む」と予測しており,発表会で「Unreal Engine 4」が対応を完了したとの報告を行っていた。おそらく,同エンジンを採用するタイトルは今後,HDR対応のものが多くなるのだろう。
基本,HDR出力にあたっては,HDR対応テレビを用意して,PCとHDMIケーブルで接続することが標準スタイルとなるだろうが,PC業界ではDisplayPortを用いたHDR出力のための準備も着々と進んでいる。
2016年5月17日現在,DisplayPortを持つディスプレイ製品はバージョン1.2までの対応となっているが,仕様上はバージョン1.4が存在している(関連記事)。つまり,DisplayPort 1.4は,規格こそ存在しているものの,対応製品はほとんど存在しないペーパースペックだったのだが,GP104ではそのDisplayPort 1.4にいち早く対応を果たした。まさかこんなに早くから対応してくるとは思わなかったというのが正直な感想で,筆者としても素直に驚いている次第だ。
一方のDisplayPort 1.4では,HDMI 2.0a&bと同様にHDR対応を果たすだけでなく,1本のケーブルで「8K」こと7680
また,GP104ではビデオプロセッサも進化しており,映像デコーダと映像エンコーダはいずれもH.265(HEVC)に対応した。つまり,デコーダとエンコーダはどちらもHDRの4K/60Hzをサポートすることになる。
ちなみに,GP104のビデオプロセッサがH.265とHDRをサポートしたことから,NVIDIAは,「SHIELD」コンソールからPCゲームをリモートでプレイできる機能「GameStream」にも拡張を入れ,GameStreamにおいてもHDR映像を楽しめるようにもしている。名称は「GameStream HDR」だ。
以上,GP104は,「アーキテクチャ一新のPascalコア」という前振りとは裏腹に,意外にもグラフィックスのコアアーキテクチャ部分は第2世代Maxwellに近い,というのが,技術面での見どころになるだろう。「歩留まりや開発期間の短縮のため,コアアーキテクチャの刷新はあえて避け,プロセス微細化と物理設計の最適化による高クロック動作を優先させる」というのが,ひょっとするとGP104の開発コンセプトだったのかもしれない。
コストが高く付くHBM(High Bandwidth Memory)を避け,GDDR5Xを選択したのも,想定ユーザーがPCゲーマーというのを考えればよい判断だったと思う。
なら,GP104はただの“第3世代Maxwell”か……と言えば,そんなことはない。
同時複数投射機能のSMP機能や,ピクセル単位・命令単位のプリエンプション対応は,エンドユーザーこそ地味なものと感じるかもしれないが,業界に与えるインパクトは結構大きい。
SMP機能は当面,3D立体視やVR向けの描画,マルチディスプレイ環境向けに使われるだろうが,応用次第で面白いことができそうである。
たとえば現在は,影生成を行うためのシャドウマップ生成において,視点と光源との位置関係によって1テクセルがカバーする面積に不均衡が起きることの対策として,「シャドウマップを視点からの遠近で複数枚分けて生成する」といったことを行っているが,SMP機能をうまく活用すれば,シングルパスで非線形かつ疎密なシャドウマップ生成を行える可能性がある。
なおAlben氏に聞くところによると,このSMP機能はGP104特有のもので,
そして,ピクセル単位・命令単位のプリエンプションは,まるで「AMDにいつまでも好き放題言わせない」ための新機能といった感じで,NVIDIAの気合を感じる。
……というわけで,GP100,GP104と,Pascalコア世代のGPUが揃いつつあるわけだが,今後はどうなっていくのだろうか。
過去の歴史に従えば,ミドルクラスの“GeForce GTX 1060”“GeForce GTX 1050”といったあたりが出てくるはずだ。GPUコアでいうと,“GP106”で,GPC数2基,CUDA Core数1280基といったあたりが“GeForce GTX 1060”の順当なスペックとなるだろうか。
もちろん,Pascal世代のウルトラハイエンドGPU,具体的にはTITAN系列の後継がどうなるのかも気になるところだ。
順当にいけば,GP100ベースということになるのだろうが,NVIDIAは「GP100は,当面の間,GPGPU用途を想定する」という立場を崩していないので,すぐ登場することはなさそうである。上で述べたとおり,GP100がSMP機能を持っていないというのも,“GeForce化”にあたってのハードルになるだろう。
HBM2採用予定となっているAMDの次次世代GPU「Vega」(開発コードネーム)の出方を待ってカウンターとしてGP100の後継製品を当てるとか,そういうことを考えているのかもしれない。
ちなみに,CES 2016で公開された,自動運転技術開発プラットフォームの「Drive PX 2」の背面側に実装されていた「名称不詳のPascal世代GPUコア」は,GP100でもGP104でもない「まだ秘密のやつ(笑)」(Alben氏)とのことだ。
Pascal世代は始まったばかり。今後もラインナップは続々と登場するだろう。
なお,4Gamerでは,本稿と同時に,GTX 1080のレビュー記事を掲載している。興味のある人はそちらもチェックしてほしい。
 |
 |
メインスピーカーは,NVIDIAが抱えるGPUアーキテクトの1人で,上級副社長 GPUエンジニアリング担当のJonah M.Alben(ジョナ・アルベン)氏である。
GTX 1080こと「GP104」のアーキテクチャ概要
 |
NVIDIAは,2016年4月に開催した自社イベント「GPU Technology Conference 2016」(GTC 2016)において,Pascal世代初のGPUとして「GP100」コアを数値演算用プロセッサ「Tesla P100」と発表しているので(関連記事),Pascal世代GPUとしては2製品めながら,“GeForce用”としてはGP104が初となるのだ。
ここ何世代か,NVIDIAのGPUコア開発コードネーム命名規則だと,頭が「G」で,その後にアーキテクチャ世代の頭文字が続いているが,今回のGP104もその命名規則どおりとなる。
 |
参考までに過去のxx4系を振り返ってみると,第2世代Maxellベースの「GM204」が「GeForce GTX 980」「GeForce GTX 970」(以下順に,GTX 980,GTX 970),Kepler世代の「GK104」だと「GeForce GTX 680」「GeForce GTX 670」といった具合。GTX 1080とGTX 1070も,NVIDIA内の位置づけとしては,このあたりの製品の後継ということになるわけである。
なお下に示した表は,GTX 1080の主なスペックを,GTX 980とGTX 680,そして参考までに第2世代Maxwellベースのトップエンドモデル「GeForce GTX TITAN X」と比較したものである。
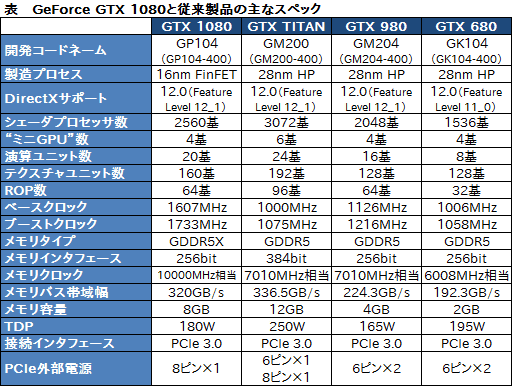 |
GP104の製造で採用する技術は,GP100と同じく,TSMC(Taiwan Semiconductor Manufacturing Company)の16nm FinFET 3Dトランジスタプロセスだ。総トランジスタ数は72億個。第2世代Maxwellのウルトラハイエンドモデル「GeForce GTX TITAN X」(以下,GTX TITAN X)の採用する「GM200」コアだと,TSMCの28nm HP(High Performance)プロセス技術を採用して約80億個,実質的な先代となるGM204コアが52億個だったので,トランジスタ数だけ比較すればGP104の規模はGM200に近い。
一方,GP104のダイサイズは約314mm2。GM200の約600mm2より小さいのは当然として,GM204の398mm2よりも小さいわけで,ここは驚くところだろう。
チップの量産価格はチップ面積と深い関わり合いがあるので,GP104がコスト対スペック比に優れるのは,16nm FinFET技術による恩恵というところが大きい。
 |
 |
製造プロセスルールの微細化は,当然,消費電力低減にも結びついており,GP104のTDP(Thermal Design Power)を180Wとしている。絶対的な比較だと,GM204が165Wだったので,15W上がったことになるが,トランジスタ数が約38%増加しているのに対し,消費電力増加割合は約9%に留まっており,Alben氏も「消費電力1Wあたりの性能は格段に向上した」とアピールしている。
さて,GP104の全体ブロック図は以下のようになる。
 |
GP104の総シェーダプロセッサ数(=総CUDA Core数)は2560基だ。GP100は3584基なので,70%強という規模感になる。さらにGM200は3072基,GM204は2048基という数字を並べると,「思ったよりもシェーダプロセッサの数が多くはなっていない」という印象を持つのではなかろうか。
 |
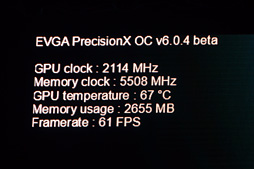
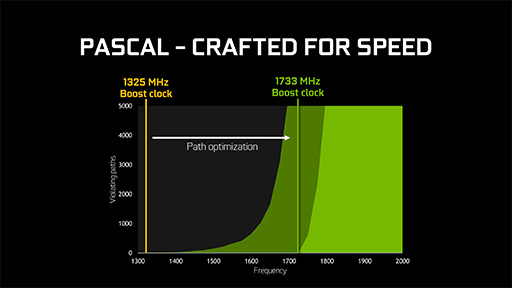
プロセッサの性能を向上させるための最も基本的なアプローチながら,GPUのような大規模かつ複雑なパイプライン構成のプロセッサでの高クロック動作を安定的に実現するのは相当に困難だとされるわけだが,にもかかわらずNVIDIAはGP104で,ベースクロックで1.607GHz,ブーストクロックで1.733GHzを実現した。
発表会の当日,空冷クーラーのまま最大クロック2.114GHzでの動作をデモンストレーションしていたのは記憶に新しい。
 |
 |
Alben氏はこの高クロック動作のための工夫を「職人芸」(Craftmanship)という言葉で形容していたが,具体的にいえば「物理設計の徹底的な最適化」によって実現されたものということだろう。
 |
クロック絡みでは,Alben氏の言う職人芸とは別の話として,「GPU Boost」にも地味ながらアップデートが入っている。
NVIDIAはKepler世代以降,チップの発熱量などに配慮しつつ,GPUのコアクロックを動的に制御するGPU Boostを多くのGeForce GTX GPUで有効化しているが,GTX 1080とGTX 1070ではこれが第3世代の「GPU Boost 3.0」になったのだ。
Maxwell世代以前では,駆動電圧にかかわらず一定比率のクロック引き上げしか行っていなかったが,Pascal世代のGPU Boost 3.0では,電圧ごとに異なる最大クロックでGPUを駆動できるようになったというのが,最大のトピックとなる。
具体的には,低電圧のときに高クロック駆動できるような制御が可能になっており,チップが持つ理論最大動作周波数にかなり迫ることができるようになったという。
 |
 |
なお,GTX 1080の論理性能値となる単精度浮動小数点演算性能は,ブーストクロックである1.733GHzで計算した約8873 GFLOPSが公式の値となっている。
これはCUDA Coreが1クロックあたり1個の積和算(2 FLOPS)を行えることから,以下の計算式で求めたものだ。
- 2560(CUDA Core)×1.733GHz×2 FLOPS=8872.96 GFLOPS
 |
ちなみに先ほど紹介した2.114GHzオーバークロック動作時だと,同じ計算で,
- 2560(CUDA Core)×2.114GHz×2 FLOPS=10823.68 GFLOPS
となり,GPU 1基でついに10 TFLOPSを超えてくる。公称性能値ではないものの,とうとう10 TFLOPSの大台を突破できる時代になってきたというのは感慨深い。
GP100よりはGM204に近い,GP104の内部構成
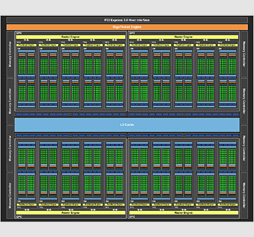
GP104は基本的に,CUDA構想を基軸とするアーキテクチャになったTeslaコア世代以降の遺伝子を受け継いだ内部構成を採用している。
複数個のシェーダプロセッサとスケジューラやロード/ストアユニット,超越関数ユニット(以下,SFU),L1キャッシュ,テクスチャユニット,そしてジオメトリエンジン「PolyMoprh Engine」を組み合わせた「Streaming Multiprocessor」(以下,SM)を構成したうえで,さらにこのSMを複数個束ね,そこにラスタライザたる「Raster Engine」を与えて1つのミニGPUコア「Graphics Processing Cluster」(以下,GPC)として構成するという仕様だ。
一方でTeslaコア世代以降,Fermi,Kepler,Maxwellと世代を経るごとに,
ではGP104はどうか。結論から先に述べてしまうと,GP104の内部構成は,GM204と酷似している。
まず,GP104のGPC数は4基で,GM204と同じ。GPCが4基という仕様はGK104もそうだったので,xx4系GPUの共通仕様と言ってもいいだろう。
GPCあたりのSM数は,GM204の4基からGP104で5基構成に変わったので,「同じではないじゃないか」と思うかもしれない。しかし重要なのは,世代単位でがらりと変わってきたSMの内部構成が,GP104とGM204でほぼ同じことだ。そのためGP104は,「GM204をベースに,GPCあたりのSM数を増やしたもの」のようにも見えるのである。
 |
 |
 |
「Warp」とはNVIDIA製GPUにおける処理スレッド実行単位の概念である。Warpについての詳細は筆者による「GeForce GTX 480」解説記事を参照してほしいが,簡単に言えば,「1 Warp」とはひとかたまりとなる32スレッドのこと。イメージしやすいピクセルシェーダで言い換えると,ピクセルシェーダプログラムの1命令が,32個のピクセルに対して並列に実行されるイメージだ。
で,先ほど述べたとおり,GP104では32基のシェーダプロセッサに対して2命令実行を振り分けられる構成になっているが,これがGM204とまったく同じ構成なのである。仕様の根幹を成すWarp周りが変わらないため,SMあたりのシェーダプロセッサ総数も128基でもちろん変わらない。
かつて,Kepler世代からMaxwell世代に切り替わったときレジスタファイルの増強があったので,今回も再強化があったのかと思いきや,そこも変わらず。「Warp処理あたりに利用できるレジスタファイルは32bit×16384個」のままである。
なら周辺はどうか……と見てみると,テクスチャ/L1キャッシュが48KB
Alben氏に「倍精度浮動小数点(FP64)の演算性能」と「半精度浮動小数点(FP16)の演算性能」についても確認してみたところ,「単精度浮動小数点(FP32)に対する性能比率はMaxwell世代と同じ」との回答だった。
つまり,GP104では,Maxwell世代と同じく,
- 単精度浮動小数点(FP32)演算性能:倍精度浮動小数点(FP64)演算性能=32:1
- 単精度浮動小数点(FP32)演算性能:半精度浮動小数点(FP16)演算性能=1:1
ということである。なお,上で示したブロック図に倍精度浮動小数点の演算器(DP)は描かれていないが,GP104には(GM200,GM204と同じく)SMあたり4基のDPがある。
参考までに書いておくと,GPGPU用のGP100における性能比率は以下のとおりだ。
- 単精度浮動小数点(FP32)演算性能:倍精度浮動小数点(FP64)演算性能=2:1
- 単精度浮動小数点(FP32)演算性能:半精度浮動小数点(FP16)演算性能=1:2
「GP104はグラフィックス用だ。なので,倍精度浮動小数点演算性能は抑え気味という可能性はあるだろう」と思いつつも,同じPascal世代なので,GP100と同じ方向性の性能設計をGP104でも採用すると筆者は思っていたのだが,ここはまったく予想と違っていたことになる。
Alben氏はこの理由について,「ゲームやVRにおいて,倍精度や半精度はそれほど重要ではないため」と説明していたが,倍精度はともかく,半精度はハイダイナミックレンジ(High Dynamic Range,以下 HDR)レンダリング用途のピクセルフォーマットで高頻度で利用されるという現実がある。また,それに関連したデータの取扱単位や演算単位は半精度になっていることも多いので,少々意外な決断だと感じた次第だ。
ということで,ここまでをまとめると,実際のところGP104は,
- 基本設計のベースはMaxwell世代と同じだが,
- GPCあたりのSMを増強し,
- プロセス微細化と物理設計の最適化による高クロック駆動を実現した
GPUということになるだろう。
 |
詳細はGP100の解説記事を参照してほしいが,GP104とGP100で比較すると,GP104は,SM数あたりのレジスタファイルが半分に,そしてSMあたりのシェーダプロセッサ数が倍になったコアになっているのが分かる。
GP100においてはレジスタファイルの増強しているとも言えるわけだが,これは,Warp処理スレッドの切り換えを高効率に行うことにつながり,ひいてはメモリアクセスの遅さを高効率に隠蔽できることにもつながる。
なおAlben氏に「GP100とGP104とではどちらの開発開始時期が先か」と質問したところ,「GP100が先で,GP104が後だ。なので,機能設計としてはGP104のほうが新しい」という返答が得られた。
つまり,GP104の開発をGP100の後で開始したにもかかわらず,GP104でNVIDIAは「GP100で行ったようなSMの構造改変は,GP104では不要」と判断したということだ。グラフィックス用GPUとしてはMaxwellベースのSM構造でいいとNVIDIAは判断したというわけで,この点も興味深い。
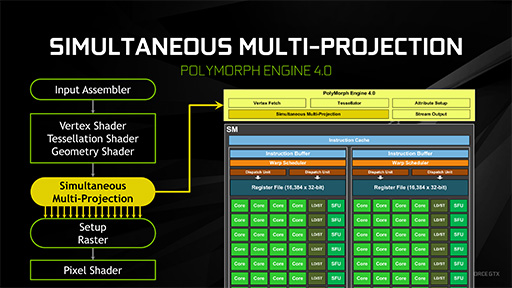
ジオメトリエンジンの改良が入ったGP104
SMあたり1基用意されるジオメトリエンジンのPolyMorph Engineは,Maxwell世代の「PolyMorph Engine 3.0」から,GP104で「PolyMorph Engine 4.0」へとバージョン番号が上がっている。
 |
Alben氏にも確認したが「ジオメトリシェーダやテッセレーションステージの中間バッファ増強やパイプライン最適化などは行っていない。Maxwell世代からの変更はない」とのことである。
では,SMPとはどんな機能なのか。
具体的な活用ケースについては先行して掲載したレポート記事を参照してもらうとして,本稿ではアーキテクチャ面から「機能がどう実装されたか」を見ていこうと思うが,先の記事における予想が正解で,ラスタライザの機能増強に相当するものであった。
いわばプログラマブルラスタライザの一歩手前的な「コンフィギュアブルラスタライザ」とも言うべきものになる。
 |
頂点シェーダとジオメトリシェーダ,テッセレーションステージなどで構成される頂点パイプラインでは,x,y,zの3D座標からなる頂点単位の仕事,分かりやすく言い変えればポリゴン単位の仕事をしているわけだが,グラフィックスをピクセルとして画面に描画するためには,ポリゴン単位のデータ構造だったものをピクセル単位の仕事に分解してから,ピクセルシェーダを動員するという流れの処理が必要になる。
この「ポリゴン→ピクセル」の分解を行うのがラスタライザ(Rasterizer)だ。
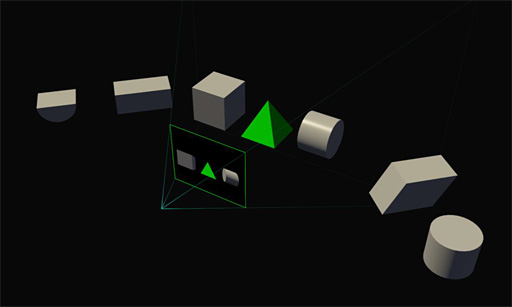
ラスタライザは,「カメラを基準にして,テレビやディスプレイといった描画対象の2D平面に投射(Projection)する」処理を行うものとも言えるのだが,そのとき,投射の仕方をプログラムできるようにしようという,「プログラマブルラスタライザ」のアイデアが,CG業界では結構前から提案されていた。今回GP104が採用したSMPは,このプログラマブルラスタライザの概念を限定的に実用化したものということになる。
従来,GPUのラスタライザは,描画先が1視点,1画面という想定の下で設計されていたわけだが,近年では,描画先を3画面としたマルチディスプレイ環境や,3D立体視,VR(Virtual Reality,仮想現実)といった,多視点描画の機会も増えてきている。
 |
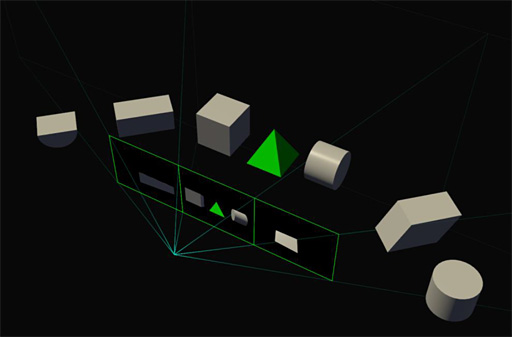
ただ,描画先を1視点,1画面と想定して設計された従来型GPUラスタライザでは,多画面や多視点描画にあたって,「頂点パイプライン→ラスタライザ」のパスを画面数や視点数分だけ回さなければならない。3D立体視やVRを実現するなら,2視点分の描画を行う必要があり,ひいては2回分の描画パイプラインを回さなければならなかった。
 |
 |
 |
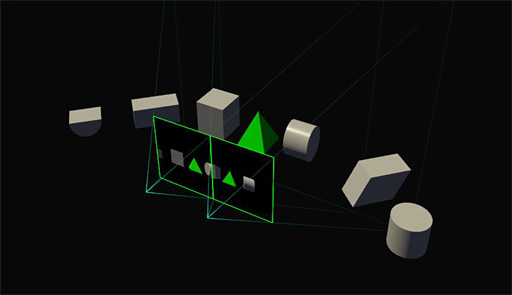
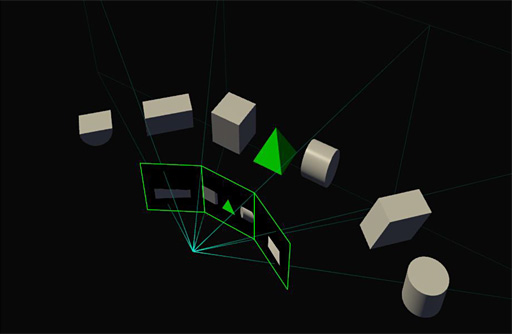
同一時間軸にある同一シーンの多画面や多視点描画を頂点パイプラインで複数回処理するのは事実上の反復であり,冗長以外の何ものでもない。そこでラスタライザを強化し,複数視点,複数画面の投射をできるようにしたのが,
GP104のSMPでは,「投射先の2D平面」を16個まで持てるようになっている。
複数持てる投射先の各2D平面では,その位置や角度,傾きなども設定でき,さらには3D立体視やVR用にカメラ基準点を2つ持たせることもできる。つまり,「頂点パイプラインを1回だけ実行したうえでの,多画面,多視点複数投射系」を,
効果だけ見れば,「これまでは異なる投射系へ描画するたびに行っていた,頂点シェーダやジオメトリシェーダ,テッセレーションステージなど頂点単位の演算処理を,1回で済ますことができるようになる」のである。
 |
 |
前述のとおり,GP104でSMPが持てる投射系は最大16個だが,これはいま例に挙げた3D立体視やVR,3画面マルチディスプレイといった事例だけを想定している限り,多すぎるくらいだ。
筆者も当然そこは疑問に思って,「なぜ16個なのか」と聞いてみたのだが,明確な回答は得られなかった。NVIDIAとして,いま挙げた3つの使い道を想定しているのは間違いないようなので,とりあえず実現できるから16個として,あとは開発者のアイデアに期待しているといったところだろうか。
GDDR5Xだけに留まらない,GP104のメモリ拡張
 |
GDDR5Xについての詳細は大原雄介氏による解説記事を参照してもらえればと思うのだが,簡単に言えば,データ転送レートがGDDR5の2倍,動作クロック比で8倍となる特徴を持つメモリである。
GP104では1.25GHz駆動のGDDR5Xメモリを採用しているので,そのデータ転送レートは10Gbps。4Gamerの慣例表現に従って表現するなら,10GHz相当の動作クロックということになる。
 |
もともとグラフィックス処理は連続したアドレスへのメモリアクセスが主体であり,ランダムアクセス時において発生しうるデータ伝送の冗長性よりも,連続したアドレスへのメモリアクセス時の高速優位性の恩恵のほうが大きいということなのだろう。
GP104のメモリコントローラは8基あり,1基当たりのメモリバス幅は32bit。すなわち,GP104のメモリバス幅は256bitということになる。なのでメモリバス帯域幅は,以下のとおり求められる。
- 256bit×10GHz÷8bit≒320GB/s
ちなみに,GDDR5メモリの384bitメモリバスを採用するGM200,GDDR5の256bitメモリバスを採用したGM204のメモリバス帯域幅はそれぞれ以下のとおりだ。
- 【GM200】384bit×7GHz÷8bit≒336GB/s
- 【GM204】256bit×7GHz÷8bit≒224GB/s
GP104,メモリバス幅こそ256bitのままながら,GDDR5Xを搭載することで,GM204と比べ1.4倍以上のメモリ性能を獲得し,384bitメモリバスを採用するGM200のそれに迫っているということになる。
ただ,話はそれで終わらない。
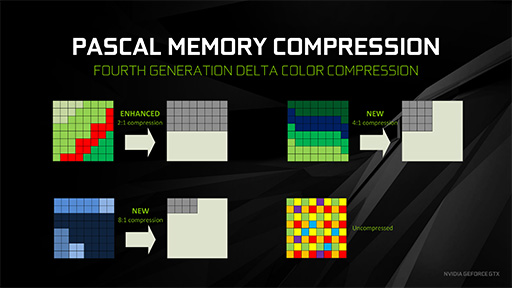
陰影計算を経たピクセルデータは「Rendering Output Pipeline」(以下,ROP)ユニットによってグラフィックスメモリへ書き出される。そして,このROPユニットがメモリコントローラあたり8基セットになるため,全体としては64基となる仕様はGP104でGM204から変わっていないのだが,グラフィックスメモリへ出力するデータをリアルタイムにロスレス(可逆)圧縮する仕組みのアルゴリズムを,NVIDIAはGP104で改善しているのだ。
NVIDIAは第2世代Maxwellで,「グラフィックスメモリへ出力するデータをリアルタイムにロスレス圧縮する仕組み」を導入した。それによりメモリバスの消費量を25%低減できたとして,たとえばGTX 980の場合,メモリクロックが7GHz相当のところ,「実効メモリクロック9.3GHz相当」だと主張していたのを憶えている人も多いだろう(関連記事)。
要はこの仕組みを,GP104でNVIDIAはさらに改善したというわけである。
 |
新しい4分の1圧縮メソッドはグラデーション表現などの色差分が小さいケースで適用される。
また,新しい8分の1圧縮メソッドは,2×2ピクセル粒度での圧縮と,いま述べた新しい4分の1圧縮メソッドを同時に使うケースで用いられるとのことだ。
 |
 |
 |
Alben氏によると,両モードによってロスレス圧縮の効果はさらに高まっており,圧縮効率はGM204の1.2倍相当になるそうだ。
 |
圧縮を適用できる場面が増えると,データによるグラフィックスメモリの占有量が減り,さらにL2キャッシュの利用効率も高まることになる。そのためAlben氏は「GP104のメモリ性能はGM204比で1.7倍に相当する」と主張している。
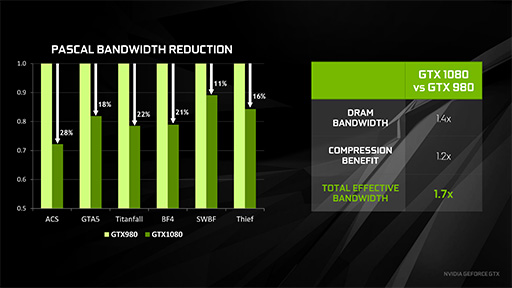 |
1.7倍という数字はどこから出てきたかというと,前述した「メモリ帯域幅がGM204の1.4倍」と,「新しい圧縮手法の追加でメモリ利用効率がGM204の1.2倍」という,2つの倍率の掛け合わせである。ただし今回NVIDIAは,第2世代Maxwellのときのような「実効メモリクロック」を示していない。
まぁ,この値は話半分に聞いておくにしても,圧縮を適用できる場面が増えたことだけは間違いないようだ。
粒度がより細かくなったGP104のプリエンプションは「Asynchronous Compute問題」を解消
 |
AMDはまた,「DirectX 12では,APIレベルで,グラフィックス描画とGPGPU処理を並列実行させる機能がサポートされているのだが,このAPIを活用しても,Maxwell世代のGPUでは正しく並列実行されず,逐次実行となってしまう」ことも,同時に指摘している。
この問題について,NVIDIAも早くから認識はしていた。というより,NVIDIA側の回答は簡単に言えば「仕様です」というもので,もともとこうした機能はPascal世代からの本格対応が予定されていたのだ。裏を返せば,AMD製GPUは,異なるコンテキストのGPU活用において一日の長があり,AMDはそこを突いたマーケティングキャンペーンを行っていたわけだ。
で,Pascal世代のGP104ではどうなったかというと,グラフィックス描画のスレッドとGPGPUスレッドの発行を並列に仕掛けた場合,その実行スレッドの切り換えを100μs未満で行えるようになった。このような,「実行スレッドの切り換えをスレッド優先順位に従いつつ割り込みを行う仕組み」のことを「プリエンプション」(preemption)という。
さらに,そのスレッド切り換えを,ほとんどCPU並みの細かさで実現できるようにもなっている。グラフィックス描画を例に挙げると,GP104は1ピクセル単位の粒度で別コンテクストの処理へスレッドを切り換えられるようになっている。この機能は,GPUを仮想化したときの性能向上にも大きく貢献できるだろう。
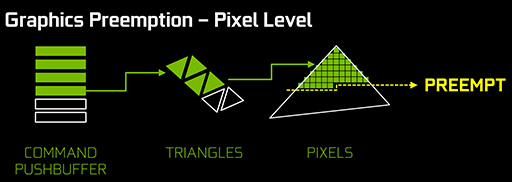 |
ちなみに,Maxwellコア以前のGPUにおいて,グラフィックス描画スレッドの切り替えを行えるのは描画コマンド単位だった。1ポリゴンを画面いっぱいに描くようなスレッドを実行していた場合,スレッドの切り換えは画面全体のピクセルを描画し終えるまで行えなかったのである。
一方のGPGPUスレッド切り換えにあたって,NVIDIAは2つの粒度を設定している。
DirectX 12のAsynchronous Shader(Asynchronous Compute)APIを使ったときには,GPGPU処理スレッド単位での切り替えが可能だ。あるひとかたまりのデータに対するGPGPUスレッドが発行された場合,当該スレッドの切り換えは,1つのデータに対する処理が終わった段階で行うということである。グラフィックス描画における「1ピクセル単位」と,粒度としては同等という理解でいい。
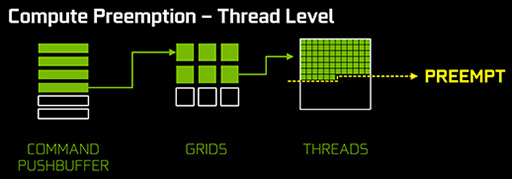 |
CUDAアプリケーションにおけるスレッド切り換えの粒度は,さらに細かく,実行命令単位で可能となっている。そう,ほとんどCPUと同じレベルのスレッド切り換えが可能なのである。
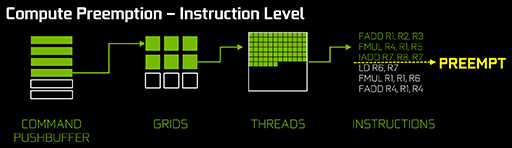 |
これでNVIDIA製GPUも,異なるコンテクストを並列実行するときに抱えていた実行効率の負い目が解消したというわけだ。
SLIブリッジコネクタは高クロック仕様に。マルチGPU周りにも改善が
GP104では,複数GPUを活用するSLIモードに関する戦略にも若干の変更が見られる。このあたりについても触れておこう。
 |
合わせて,GP104のタイミングでSLIブリッジコネクタは「SLI HB Bridge」にリニューアルととなった。
この新しいSLIブリッジコネクタは,「HB」(High Bandwidth)の略称から想像できるとおり,ピクセルデータの伝送クロックが,従来の400MHzから650MHzへ高められて(帯域幅が向上して)いるのが特徴だ。ただ,従来のブリッジコネクタも,速度性能さえ気にしなければそのままGP104で使えるという。
 |
 |
 |
Pascal世代のGPUが,わざわざ新しいSLIブリッジコネクタを伴って登場したことで,GP100にて新設となったプロセッサ間接続用専用バス「NVLink」をGP104でもサポートしているのではと期待してしまった人もいると思うが,Alben氏に確認したところ「GP104にNVLinkの機能はない」とのことだった。今回の新しいSLIブリッジコネクタは,NVLinkとは無関係という理解でいいようである。
ちなみに,3-wayや4-wayのSLI構成はできないのか? というと,サポート自体はある。NVIDIAによると,3/4-way SLIをアンロックするための特別なキーコード(シリアルコード)を今後,NVIDIAの特設ページで案内して提供していく計画のようだ。
なお,“3/4-way用のSLI HB Bridge”の提供予定はないそうで,GP104での3/4-way SLI動作にあたっては,従来のSLIブリッジを利用する必要がある。
SLIというか,マルチGPU構成に関してはもう1つトピックがある。DirectX 12は,Multi Display Adapter(以下,MDA)とLinked Display Adapter(以下,LDA)という2つのマルチGPU動作モードをサポートしているが,GP104では,このLDAモードに関するサポートが追加されているのだ。
MDAは,同一メーカーのGPUはもちろん,異なるメーカーのGPUが同一システムに搭載されていた場合でも,アプリケーションが個別に駆動できるモードになる。
LDAは,ブリッジコネクタを駆使することで複数のGPUを1基のGPUに見立てて取り扱えるモードなのだが,LDAには「LDA IMPLICIT」(暗黙)モードと「LDA EXPLICIT」(明示)モードの2つがあり,今回追加されたのは後者となる。
ちなみにLDA IMPLICITというのは事実上のSLI(もしくはCrossFire)モードのことで,ドライバ側で“勝手に”複数のGPUを駆使して描画を行うことになる。
これに対してLDA EXPLICITモードだと,アプリケーションからは複数のGPUが1基のGPUに見えるようになり,アプリケーションからこの「1基のGPUに見える複数のGPU」をフルにプログラムできる。LDA IMPLICITの場合,アプリケーションが取り扱えるグラフィックスメモリの最大容量はGPU 1基分になってしまうが,LDA EXPLICITではそれぞれのGPUが持つグラフィックスメモリの合計容量を扱えるのもポイントだ。
もっとも,実体GPUごとに分散してしまったデータを,もう片方側のGPUから直接的にアクセスすることはできず,データのコピーが発生してしまう。そのため,グラフィックス描画でLDA EXPLICITモードを活用するのは難度が高い。おそらくLDA EXPLICITモードは,主にGPGPU(≒DirectCompute)向けと思われる。
 |
新しいVsyncモード「Fast Sync」
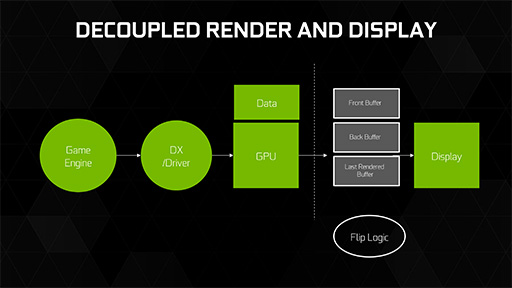
NVIDIAは,描画したグラフィックスをディスプレイシステムに表示するための仕組みについて,これまでもさまざまなアイデアを提案してきた経緯があるが,GP104で,また新しいものを提案してきた。それが「Fast Sync」だ。
GP104専用ではなく,従来のNVIDIA製でもサポートされることになるFast Syncだが,これは簡単に言うと,描画パイプラインと表示パイプラインを非同期で実行するディスプレイ同期技術である。
描画された映像を,垂直同期を待って表示にかかるのがVsync有効,待たずに,描画途中であっても,新しく描画が完了した映像の表示に切り替えるのがVsync無効なわけだが(関連記事),新しいFast Syncの表示メカニズムも基本的にはVsync有効と変わらない。
異なるのは,Vsync無効時と同じように,描画パイプラインが垂直同期を無視する点だ。描画パイプラインが垂直同期を無視して描画済みの映像を送ってきても,映像表示メカニズム側(=映像の送出制御側)では,「次に表示予定の映像が描画」が終わっていなければ,新しい映像の表示は次回に持ち越し,現在表示している映像を継続して表示させる。
 |
 |
 |
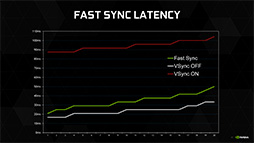
NVIDIAによれば,NVIDIAコントロールパネルからFast Syncを選択した場合,「比較的フレームレートの高い,可変フレームレートのゲームでの見栄えがよくなる」とのこと。合わせて,GPU主導の表示メカニズムである「G-SYNC」を置き換えるものではないとも説明していた。
HDRに完全対応するDisplayPort&HDMI出力
 |
HDMI 2.0aはともかく,HDMI 2.0bは耳慣れないという人もいそうだが,どうやら,4KだけではなくフルHD解像度でもHDR表示を可能にする拡張仕様のことを指しているようである(関連リンク)。
筆者の取材によれば,GP104がサポートするHDRフォーマットは,現状,一般に4K Blu-rayと言われる「Ultra HD Blu-ray」の「HDR10」方式のみとのこと。現状では,「Dolby Vision」「Hybrid Log-Gamma」といったHDR映像フォーマットには対応していないという。
HDR10は,YUV各10bit,YUV=4:2:0フォーマットのHDR形式だが,話を聞いたNVIDIAの担当者は「GP104ではそれ以外にも,YUV各12bit,YUV=4:2:2フォーマットの広色域モードをサポートする」と説明していた。これはおそらくHDRのことではなく,BT.2020で規定される広色域への対応のことを言っているのだと思われる。
 |
NVIDIAは「ゲームのHDR対応は急速に進む」と予測しており,発表会で「Unreal Engine 4」が対応を完了したとの報告を行っていた。おそらく,同エンジンを採用するタイトルは今後,HDR対応のものが多くなるのだろう。
 |
基本,HDR出力にあたっては,HDR対応テレビを用意して,PCとHDMIケーブルで接続することが標準スタイルとなるだろうが,PC業界ではDisplayPortを用いたHDR出力のための準備も着々と進んでいる。
2016年5月17日現在,DisplayPortを持つディスプレイ製品はバージョン1.2までの対応となっているが,仕様上はバージョン1.4が存在している(関連記事)。つまり,DisplayPort 1.4は,規格こそ存在しているものの,対応製品はほとんど存在しないペーパースペックだったのだが,GP104ではそのDisplayPort 1.4にいち早く対応を果たした。まさかこんなに早くから対応してくるとは思わなかったというのが正直な感想で,筆者としても素直に驚いている次第だ。
一方のDisplayPort 1.4では,HDMI 2.0a&bと同様にHDR対応を果たすだけでなく,1本のケーブルで「8K」こと7680
また,GP104ではビデオプロセッサも進化しており,映像デコーダと映像エンコーダはいずれもH.265(HEVC)に対応した。つまり,デコーダとエンコーダはどちらもHDRの4K/60Hzをサポートすることになる。
 |
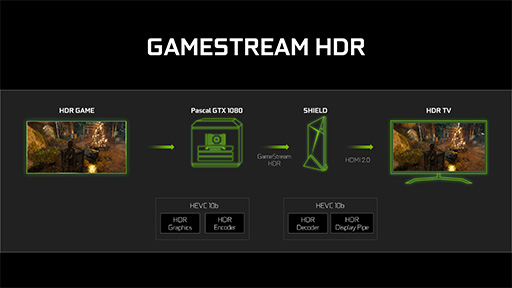
ちなみに,GP104のビデオプロセッサがH.265とHDRをサポートしたことから,NVIDIAは,「SHIELD」コンソールからPCゲームをリモートでプレイできる機能「GameStream」にも拡張を入れ,GameStreamにおいてもHDR映像を楽しめるようにもしている。名称は「GameStream HDR」だ。
 |
ついに本格立ち上げとなったPascal
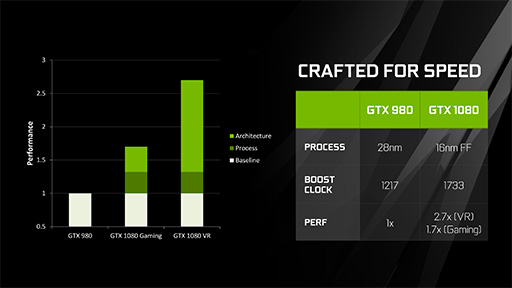
以上,GP104は,「アーキテクチャ一新のPascalコア」という前振りとは裏腹に,意外にもグラフィックスのコアアーキテクチャ部分は第2世代Maxwellに近い,というのが,技術面での見どころになるだろう。「歩留まりや開発期間の短縮のため,コアアーキテクチャの刷新はあえて避け,プロセス微細化と物理設計の最適化による高クロック動作を優先させる」というのが,ひょっとするとGP104の開発コンセプトだったのかもしれない。
コストが高く付くHBM(High Bandwidth Memory)を避け,GDDR5Xを選択したのも,想定ユーザーがPCゲーマーというのを考えればよい判断だったと思う。
 |
なら,GP104はただの“第3世代Maxwell”か……と言えば,そんなことはない。
同時複数投射機能のSMP機能や,ピクセル単位・命令単位のプリエンプション対応は,エンドユーザーこそ地味なものと感じるかもしれないが,業界に与えるインパクトは結構大きい。
SMP機能は当面,3D立体視やVR向けの描画,マルチディスプレイ環境向けに使われるだろうが,応用次第で面白いことができそうである。
たとえば現在は,影生成を行うためのシャドウマップ生成において,視点と光源との位置関係によって1テクセルがカバーする面積に不均衡が起きることの対策として,「シャドウマップを視点からの遠近で複数枚分けて生成する」といったことを行っているが,SMP機能をうまく活用すれば,シングルパスで非線形かつ疎密なシャドウマップ生成を行える可能性がある。
なおAlben氏に聞くところによると,このSMP機能はGP104特有のもので,
そして,ピクセル単位・命令単位のプリエンプションは,まるで「AMDにいつまでも好き放題言わせない」ための新機能といった感じで,NVIDIAの気合を感じる。
……というわけで,GP100,GP104と,Pascalコア世代のGPUが揃いつつあるわけだが,今後はどうなっていくのだろうか。
過去の歴史に従えば,ミドルクラスの“GeForce GTX 1060”“GeForce GTX 1050”といったあたりが出てくるはずだ。GPUコアでいうと,“GP106”で,GPC数2基,CUDA Core数1280基といったあたりが“GeForce GTX 1060”の順当なスペックとなるだろうか。
もちろん,Pascal世代のウルトラハイエンドGPU,具体的にはTITAN系列の後継がどうなるのかも気になるところだ。
順当にいけば,GP100ベースということになるのだろうが,NVIDIAは「GP100は,当面の間,GPGPU用途を想定する」という立場を崩していないので,すぐ登場することはなさそうである。上で述べたとおり,GP100がSMP機能を持っていないというのも,“GeForce化”にあたってのハードルになるだろう。
HBM2採用予定となっているAMDの次次世代GPU「Vega」(開発コードネーム)の出方を待ってカウンターとしてGP100の後継製品を当てるとか,そういうことを考えているのかもしれない。
 |
Pascal世代は始まったばかり。今後もラインナップは続々と登場するだろう。
なお,4Gamerでは,本稿と同時に,GTX 1080のレビュー記事を掲載している。興味のある人はそちらもチェックしてほしい。
- 関連タイトル:
 GeForce GTX 10
GeForce GTX 10 - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー