











ニュース
次世代GPU「Volta」からAIまで,新製品&新サービスラッシュだったJensen Huang氏のGTC 2017基調講演レポート
 |
なぜNVIDIAは,GPUのロードマップをGTCで明らかにするのか。そこには理由があると筆者は考える。
GTCというイベントは,GPGPUに重きを置いたものになっており,少し前まではスーパーコンピュータ用途のGPUコンピューティングやHigh Performance Computing(HPC)分野の研究者やエンジニアを,そして近年では,コンピュータビジョンやAIによる機械学習分野の人々を主なターゲットにしているからだ。
こうした分野の顧客は,「高価な最新GPUでも,かなりの数を大量発注する」傾向があるのだが,一方でその莫大な導入予算を確保するには,相応に長期的な導入計画を立てる必要がある。そのため,「いつ頃,どの程度のGPUがいくらくらいで出てくるのか」の情報が,とても重要なのだ。
 |
余談になるが,GTCの会期中,NVIDIA関係者は驚くほどGeForce――というよりもグラフィックス全般――に関連した質問や取材を嫌がる。それだけGTCというイベントは,PCグラフィックスやゲーム用途に向けた内容ではないということを示しているとも言えよう。
とはいっても,GPU技術の進化の方向性を知るために,GTCが重要な位置付けにあることに変わりはないというわけで,本稿ではGTC 2017におけるHuang氏の基調講演の詳報をレポートしたい。
「ムーアの法則を維持しているのはNVIDIAのGPUだけ」
 |
知っている人も多いかと思うが,ムーアの法則とは,Intel創業者の1人であるGordon E.Moore(ゴードン・ムーア)氏が,1965年に論文の中で提唱した「プロセッサの集積率は12か月で2倍になる」という経験則である(※その後,18か月に延びた)。「プロセッサの性能は18か月で2倍になる。1年なら1.5倍」と間違って語られたり,最近では公式(?)に18か月が24か月に延びていたりもするのだが,いずれにせよここで重要なのは,集積率も,誤用である性能向上率においても,汎用プロセッサの代表格であるCPUにおいて,「24か月で2倍」は達成できなくなっているということだ。
 |
Huang氏はこのことを指摘したうえで,これまでCPUが実現していた「1年で1.5倍」の性能向上を達成できているのは,2007年に登場したCUDAベースのGPU,すなわちNVIDIAのGPUだけであると強調した。Huang氏の見通しによると,2025年のGPUは2007年のGPUと比べて,1000倍の性能に到達できるそうだ。
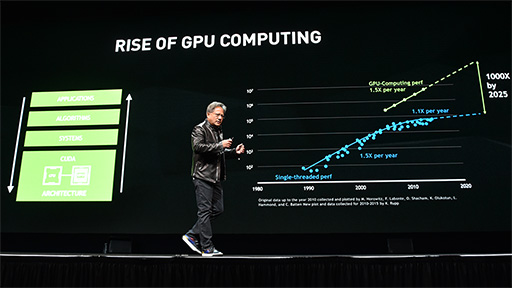 |
ここまでが,毎年恒例のオープニングトークで,この後,Huang氏は,まさに怒濤の新製品&新技術の発表ラッシュを繰り広げるのであった。
 |
複数同時参加型VRシステム「Project Holodeck」はUnreal Engine 4ベース
話の流れからして,GPGPU関連の発表があるのかと思いきや,最初にアナウンスされたのは意外なことに,多人数同時参加型VR会議システム「Project Holodeck」だった(関連リンク)。
 |
多人数同時参加型のVRによるコミュニケーションと聞くと,東京ジョイポリスで稼動中の6人同時参加型VRアトラクション「ZERO LATENCY VR」を連想する人もいるかもしれない。しかしHolodeckは,ゲームやエンターテインメント,あるいは「Second Life」やFacebookが開発中の「Facebook Spaces」といったVR SNSでもない。あくまでも会議のためのシステムだ。
しかも,「SkypeやLINEのビデオチャットをVR化しました」といった,単純なものではない。リッチな3Dモデルや物理シミュレーションまでサポートするとのことなので,「参加者全員でVR空間のものに触れて,リアルタイムに反応が返ってくるVRプレゼンテーションツール」のようなものを目指しているようだ。
基調講演でのデモでは,Koenigsegg(ケーニグセグ)製スーパーカー「Regera」(レゲーラ)の3DモデルをVR参加者が囲んで,好きな角度から眺めたり,ドアを開けたりする様子が披露された。建築物のモデルなら,参加者がVR空間内でモデルの中を歩き回って子細を検討するなんてこともできるだろう。
 |
Project Holodeckは,Unreal Engine 4ベースで開発を進めており,2017年9月にβ版の公開を予定しているとのことだ。
レイトレーシングの中間映像をAIで美しくする「Iray with Deep Learning」
 |
レイトレーシングでは,ピクセルに対して光がどのように当たるかを計算していくが,間接光の場合,何回の反射まで求める(トレースする)かで,最終的な映像の品質が変わってくる。よって,最終的な映像は時間をかけてでもきっちりレンダリングすことになるわけだが,アーティストやデザイナーが3Dモデルのデザインを修正したり,あるいは光源をどこに置くとシーンがどう見えるか確認したりといったプロセスでは,品質が多少落ちても,素早く結果が得られたほうがいい。
しかしここにジレンマがある。レイトレーシングにおいて処理時間を優先し,反射回数を減らして計算を早期に適当に打ち切ってしまうと,得られる計算結果は誤差が大きくなり,映像としてはノイジーに見えてしまう。また,目標の解像度で計算せず,歯抜きでピクセルを飛ばしながら計算するようなことをやれば,計算量が減る代わりに解像感は落ちてしまうのだ。いずれの場合においても,見栄えの評価に使うのは難しくなってしまう。
 |
基調講演で披露したデモは,3000シーンに及ぶレイトレーシングの1万5000の描画結果に対して,「ノイジーな中間映像」と,「時間をかけて計算した最終映像」との相関性を学習させた機械学習用AIを使って,映像を修正するというものだった。AIが修正した映像をそのまま完成品にすることはないが,制作過程における調整や確認用としては十分な品質である,というのがNVIDIAの言い分だ。
 機械学習用AIによる映像修正処理を行う前の映像 |
 映像修正を適用した映像。見栄えは大きく異なる |
これは筆者からの補足解説になるが,実は,こうした機械学習用AIを使った映像生成技術はすでに実用化が始まっている。今回発表された「Iray with Deep Learning」とまったく同じアプローチの技術をディズニーはすでに導入しており,また,テレビ製品業界だと,ソニーや東芝が最新のテレビ製品で採用している「フルHD映像から4K化する超解像処理エンジン」は,機械学習用AIの学習結果から推論(Inference)処理するタイプのものになっている(関連リンク)。
今後,このタイプのAIの実用化はどんどんと加速するはずで,そのAIの学習処理のためにGPUの高性能化が今まで以上に期待されることになるわけである。
Huang氏は,Iray with Deep Learningはあくまでも事例の1つだとし,そのほかにも「これまでは考えもしなかったような分野で応用が始まっている」と述べていた。
 |
 |
また,企業向け基幹業務アプリケーションでは最大手であるSAPが,NVIDIA製GPUベースの機械学習用AIを採用したこともHuang氏は発表している。さまざまなビッグデータをAIで分析するSAPのサービスに,NVIDIAのGPUを利用しているのだそうだ。
 |
 |
Tesla V100の搭載製品を続々発表
 |
たとえば,最近劇的に精度が向上したと評判になっている機械学習用AIベース機械翻訳である「Google翻訳」は,現時点で105 EFLOPS(ExaFLOPS,100京FLOPS)の演算性能の上に成り立っているという。
 |
 |
Tesla V100のスペックや性能といった詳細については,筆者による解説記事で解説済みなのでそちらを参照してもらうとして,ここでは基調講演での話を続けよう。
 |
これは,「FINAL FANTASY XV」(以下,FFXV)の前日譚となるCG映画「KINGSGLAIVE FINAL FANTASY XV」のオフラインCG用アセットを使い,リアルタイムでレンダリングするというもの。披露された映像は,映画の主人公ニックス・ウリックが佇むだけというシンプルなものだったが,わずか10日程度の制作期間で実現したものだという。CG映画とゲームグラフィックスの間にあるリアリティの差が,さらに縮まってきたというメッセージと言えよう。
 |
 |
ところで,GV100の解説記事でも触れたように,Tesla V100にはビデオ出力インタフェースなしのバージョンと,ありのバージョンが存在する。このデモ映像は,おそらくビデオ出力ありのTesla V100で動作していたものだろう。GV100そのものを搭載したものかどうかはともかく,近い将来,Volta世代のGeForceが登場することには期待が持てそうだ。
GV100搭載スパコンやワークステーションを矢継ぎ早に発表
FFXVの次に,Huang氏がGV100の性能を誇示するデモとして紹介したのは,地球がある天の川銀河とアンドロメダ銀河の50億年後をシミュレートする科学技術計算である。
両銀河を構成する恒星系を800万個選び,それらの重力がお互いにどう影響を与えるのかを計算するというもので,200万光年以上離れた2つの銀河の軌道が50億年後にどうなるかを計算するという,気の遠くなる規模のシミュレーションを,Tesla V100の処理能力ならば,インタラクティブなスピードで実行できるというアピールである。
講演後に筆者が関係者を取材したところ,このデモに登場する全恒星系の位置と重力の計算は,64bitの倍精度浮動小数点演算で行っているとのことだ。
 |
 |
Huang氏は,機械学習用AIを応用した画像変換技術「Deep Learning for Style Transfer」も紹介した。Webアプリとして人気を博している画像合成システム「Ostagram」(関連リンク)も,同種の技術を使った研究成果の1つだが,今回の基調講演でHuang氏が紹介したのは,NVIDIAの研究チームが開発している,「実写の風景写真2枚から特徴を抽出して,互いを合成する」技術だ。
 |
このデモは,2枚の異なる画像を合成するという,比較的難度の高いテーマだったが,フォトレタッチソフトなどでよく使われる不要部分の削除や顔の美化,風景に人物を合成するといった用途には,今後,こうしたAI技術の成果が導入されていくのかもしれない。
 |
 |
 |
1つめは,Tesla V100を8基搭載したスーパーコンピュータ「DGX-1 with Tesla V100」(以下,DGX-1V)だ。2017年第3四半期の発売を予定しており,価格は14万9000ドル(約1693万円)とのこと。PascalベースのDGX-1は,発表時点での価格が12万9000ドルだったので,2万ドルの値上げとなる。
ちなみに,基調講演の行われた北米時間2017年5月10日以降にDGX-1を購入した顧客に対して,搭載GPUをTesla V100に無償アップグレードするキャンペーンを展開するとHuang氏は述べていた。値上げ分をなかったことにしてDGX-1Vを購入できるので,かなりお得なキャンペーンだろう。
 |
 |
 |
DGX Stationは,CPUに「Xeon E5-2698 v4」(20C40T,定格2.2GHz,最大3.6GHz,共有L3キャッシュ容量50MB)を採用。メインメモリ容量は256GBで,プリインストールOSはLinux系のUbuntuとなっている。4基搭載するTesla V100のうち,最下段に装着したカードにはDisplayPort出力が3ポートあり,ここから映像を出力できるという。
価格は6万9000ドル(約783万円)で,発売時期はDGX-1Vと同じ2017年第3四半期予定とのことだ。
 |
 |
さらに,DGX-1のクラウドサーバー版である「HGX-1」を,Tesla V100にアップグレードした「HGX-1 With Tesla V100」(以下,HGX-1V)も,Huang氏により発表された。価格は未定だが,発売時期はこちらも2017年第3四半期を予定しているとのことだ。
 |
Tesla V100搭載製品の最後に,チラ見せ的に発表されたのが,PCI Ex
 |
 |
ちなみに,DGX-1VやHGX-1Vが搭載するTesla V100は,システムとの接続にNVLinkインタフェース(関連記事)を使うモジュール基板のものだ。一方でTesla V100カードは,シングルスロットサイズのPCIe拡張カードとなっていたのが興味深い。というのも,前出のDGX Stationが搭載するものは,2スロットサイズでカード長も長いタイプだったからだ。
NVIDIAのTesla V100製品情報ページにも,2スロット仕様でTDP 300WのPCIe拡張カード型しか載っていないので,シングルスロット版Tesla V100カードの詳細は,よく分からないというのが正直なところ。
いずれにせよ,シングルスロット版はデータセンターなどのGPUサーバー向けの製品のようで,単品売りは行わず,システムビルダーに対して出荷するということらしい。あるいは,特殊な冷却システムを有するシステムで運用することを想定しているのかもしれない。
 |
機械学習用AIを仮想マシンで提供するクラウドサービスも2017年7月にスタート
Tesla V100搭載製品のラッシュが一段落したのに続いて取り上げられたのは,クラウドサービスの話題だ。
Huang氏はまず,「サービス利用者からの問い合わせに対して毎秒30万件の推測結果を返すAIサービス」を構築する場合,Intel製CPUでは,1ノードあたりCPUを2基使う500ノードのシステムが必要という試算を示す。そのうえで,Tesla V100なら,1ノードあたりのGPUが1基だとして,同等性能のシステムを33ノードで構築できるため,消費電力と構築コスト,物理的な設置スペースのすべてで,大幅な節約が可能になるとアピールしていた。
余談だが,Huang氏が示したスライドでは,1ノードあたりのコストを3000ドルと試算していた。そこから考えると,(単品売りはないにしても)シングルスロット版Tesla V100カードの単価は,3000ドル未満となりそうだ。
 |
NVIDIA自体も,機械学習用AIのクラウドサービスを展開する。その名もずばり「NVIDIA GPU Cloud」(以下,GPU Cloud)サービスだ。といっても,具体的に特定のAIサービスを提供するものではなく,機械学習用AIの開発が行える仮想マシンを提供するサービスになるとのこと。
 |
Huang氏は,GPU Cloudの仮想マシンが3ステップのセットアップで使えるようになる様子をデモで紹介した。
1つめのステップは,DGX-1やDGX Stationといった仮想マシンの選択で,2つめのステップは取り扱うデータの選択となる。3つめのステップは,機械学習用AIフレームワークの選択で,サービス稼動初期は「Pytorch」と「Caffe2」の2種類から選べるとのこと。
当面はWebベースのサービスとして展開していくようで,βテストは2017年7月に開始の予定とのこと。料金体系などは未定となっている。
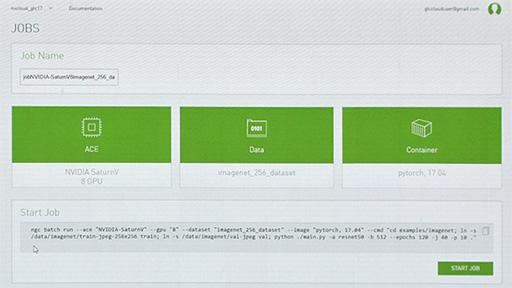 |
Voltaの技術を自動運転技術にも展開
 |
Xavierの存在自体は,2016年9月に行われた「GTC Europe 2016」で発表済みであり,とくに新しい発表というわけではない。あくまでも自動運転分野における直近のロードマップを示したという程度だ。
Xavierは,NVIDIAが独自開発した64bit ARMベースCPUコア「Denver」の改良型に,Volta世代GPUコアの組み込み機器向けを組み合わせたものになる予定である。それに加えて筆者の取材によれば,Xavierが統合するVolta世代GPUコアにも,「Tensor Core」(テンサーコア)が搭載されるらしい。
ただ,その仕様はGV100のTensor Coreとは異なり,浮動小数点演算をサポートしない「8bit整数」(int 8)ベースになるとのこと。演算性能の30TOPS(Trillion OPS,1秒あたり30兆回の演算)は,CES 2017におけるXavierの説明と変わっていない。
と,ここまでは今までに発表済みの情報が中心で,新しい情報はないのかなと思っていたが,Huang氏は最後に筆者も驚いた新情報を明らかにした。XavierにはTensor Coreに加えて,機械学習用AI向けの専用アクセラレータチップ「Deep Learning Accelerator」(以下,Xavier DLA)を搭載できるというのだ。
 |
Xavier DLAの目標性能は,10TOPS程度になる見込みとのこと。筆者の取材によると,先述したXavierの性能が30TOPSになるというのは,GPU側のTensor Coreで20TOPS分,Xavier DLAで10TOPS分で,合計で30TOPSになるという理屈というわけだ。
2016年9月の発表時点だと,Xavierの演算性能は20TOPSとされていたのが,
Xavier DLAでさらに驚かされたのは,Huang氏が,Xavier DLAのアーキテクチャと仕様をオープンソース化していくと述べたことだ。いわく,仕様の策定には,NVIDIA以外の企業や研究機関も参加可能とのこと。仕様が決まったら情報を公開するので,NVIDIA以外のグループが,好きに改良なり拡張なりを加えてもかまわないという。もちろん,Xavier DLAの使用や改良に対して,ライセンス料の支払いも求めないそうだ。
はっきり明言されたわけではないが,Xavier DLAのベースとなる仕様は,
Xavier DLAプロジェクトへの早期参加募集は2017年7月に開始予定とのこと。情報の一般公開は2017年9月を予定しているという。
 |
ただ,講演後に行われた質疑応答では,トヨタに関する質問は,ほぼ一貫して「然るべき時に答える」と言った具合で,実質的に「ノーコメント」に近いものであったことを付け加えておきたい。
加速した仮想空間でロボットAIを学習させるUE4ベースのシステム「Isaac」
Huang氏が基調講演の最後に取り上げたのは,AIとロボットに関連した技術だ。
Huang氏によると「ロボットと自動運転はとてもよく似た技術だが,決定的に違う部分があり,その部分にこそ,難度の高い問題が潜んでいる。それは衝突だ。自動車の自動運転は,いかに衝突を避けるかの技術であり,ある意味,明解なテーマだ。一方でロボット技術(Robotics)は,どのようにして現実世界に触れていくかが求められるものであり,難度が高い」という。
研究開発の難しさを示す事例としてHuang氏は,南カリフォルニア大学のComputational Learning & Motor Control Lab(計算器学習とモーター制御研究室)で行われた「ホッケーロボットの人工知能開発プロジェクト」の動画を紹介した。
この実験では,教育対象のホッケーロボットがゴールを目がけてパックを打つのだが,打つたびにスタッフが飛んでいったパックを拾いに行って,ロボットの足元にセットし直す必要があるため,その繰り返しが参加者の笑いを誘った。

自動運転技術の開発もそうだが,反復動作の基礎学習を現実世界で行うと,やり直しのたびに時間を浪費するので,手間がかかりすぎるという問題がある。それならば,「物理的な挙動が現実世界とほぼ同じバーチャル世界で,基礎学習をやらせればいい。時間も加速させたうえで!」(Huang氏)というアイデアが出てくるのは自然なことだ。
そして,そのためにNVIDIAが開発したのが,ロボットAI学習用の仮想シミュレーションシステム「Isaac」である。
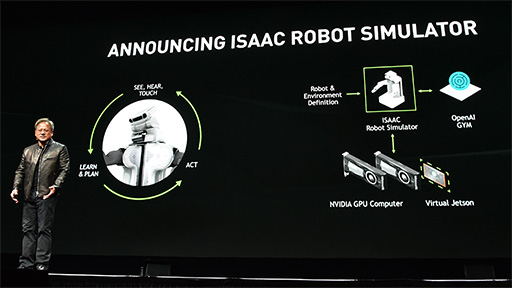 |
Isaacは,Unreal Engine 4(以下,UE4)ベースで開発されたシステムで,AI部分にはオープンソースのアルゴリズム学習型AI「OpenAI Gym」(関連リンク)を利用するシステムとのことだ。
Isaacには,ロボットのAIを動かすために,NVIDIAの組み込み機器向け開発キットであるJetsonシリーズ(関連記事)の仮想マシンも含まれており,Jetsonで動作するように開発したロボットのAIを,仮想マシン上で実行して学習を行わせることが可能となっている。
「ホッケーロボットの開発で言えば,パックをロボットの足元に戻す作業を自動化できる。学習実験を同時に複数回行うこともできる。時間を加速させたっていい」と,Huang氏はその利点を説明する。
 |
 |
実のところNVIDIAは,Isaacよりも前に,UE4を使った自動運転の基礎学習実験を行っていた。そうした経験が,Isaacのようなツールを生み出すもとになっているのだろう。
新世代GPUとしてのVoltaが脚光を浴びるも,GeForceへの採用はもう少し先?
例年以上に盛りだくさんの内容だったHuang氏の基調講演だが,主役はやはり,Volta世代のGPUであるGV100と,その応用製品だった。多くのハードウェアやソフトウェア,サービスが発表されたが,そのほとんどがGV100をベースにしたり,GV100でデモを披露したりしているといった具合で,「2017年下半期はVolta一色で行くぞ」というNVIDIAのメッセージが感じられたように思う。
そのなかで驚かされたのは,冒頭でも触れた「定例行事」としてのロードマップ開陳がなかったことだ。強いて言えばXavier DLAプロジェクトが,将来製品のロードマップと言えなくもないが,その程度である。
2017年から2018年以降にかけて,半導体の製造プロセスは次世代の10nm,さらには次々世代の7nmへと進化していくことが見えている。それにも関わらず,科学者の名前を付けた将来GPUのコードネームがまったく語られなかったのはなぜか。考えを巡らせてみるのも面白いだろう。
「Voltaの登場が,当初の予定よりも遅れている」という話をGTC 2017の会場で耳にしたこともあったので,そのあたりが影響しているのかもしれない。
 |
UE4の開発元であるEpic Gamesは,
とくにUE4は近年,ゲーム以外での利用に力を入れており,その方針が,NVIDIAのGPGPU重視方針とうまくマッチングしているのかもしれない。
さて,ゲーマーにとって気になるのは,Volta世代のGPUを搭載したGeForceが登場するのかなのだが,今のところ,筆者の耳には,そうした情報は届いていない。2017年5月末に始まる「COMPUTEX TAIPEI 2017」に,NVIDIAはGPGPU関連のスタッフを中心に派遣すると聞き及んでいる。となると,Volta世代のGeForceが登場するのは,もう少し先の話ということになりそうだ。
- 関連タイトル:
 Volta(開発コードネーム)
Volta(開発コードネーム) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー