










これを読めば,ストレージの高速化技術がゲームにとってどれだけ重要で,そのためにどのような工夫が盛り込まれているかが分かるはずだ。
 |
●目次
コンソールのほうが一足先に取り組み始めたローディング速度改善
 |
ゲームファンにとって最も身近で不愉快なことは,ローディングで待たされることだろう。どんなに素晴らしいゲームでも,ローディング待ちほど無駄な時間はない。
待ち時間を劇的に削減する試みは,すでに,現世代の家庭用ゲーム機(以下,コンソール)でも行われてきた。
前提として,現行コンソールの技術動向を押さえておきたい。
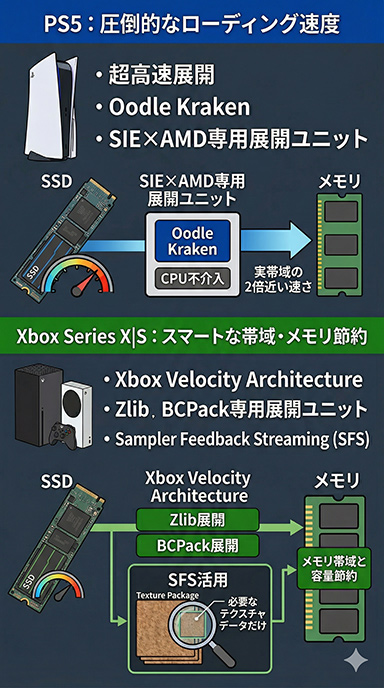
PlayStation 5は,Sony Interactive EntertainmentがAMDと共同開発した専用展開ユニットにより,データ圧縮技術「Oodle Kraken」による圧縮データを,CPUを使わずに超高速で展開できる。これにより,SSDの実効帯域幅の約2倍に達する読み出し速度を実現しているわけだ。
それに加えて,「BC7」などの圧縮済みテクスチャを,見た目の品質を維持しつつOodle Krakenで効率よく二重圧縮するためのツール「Oodle Texture」もゲーム開発ではよく利用されている。この話は後半で再び触れる。
Xbox Series X|S(以下,XSX)にも,「Xbox Velocity Architecture」と呼ばれるMicrosoftとAMDが共同開発した専用展開ユニットが搭載されている。
PS5との違いは,汎用データ向けの「Zlib」と,テクスチャ向けの「BCPack」という2系統の展開ユニットを備える点だ。さらに,テクスチャストリーミング技術「Sampler Feedback Streaming」(SFS)により,必要なテクスチャだけをSSDから読み出せる。
PS5とXSXの圧縮率と実効性能はほぼ互角だが,SSD自体のストレージ帯域幅は,PS5が約2倍速い。大ざっぱにいえば,PS5はローディング速度の圧倒的な高速化を,XSXはSFS前提でのメモリ効率を重視した設計なのだ。
こうしたコンソール側の発想を,PCで実装したものがDirectStorageである。
 |
DirectStorageの現在
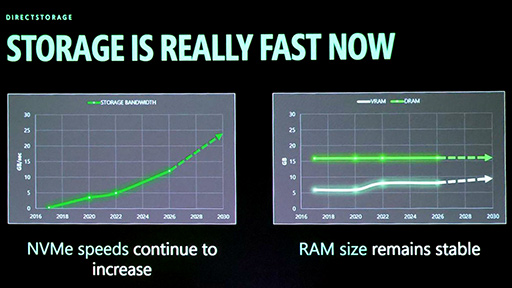
DirectStorageパートの講演を担当したDanny Chen氏は,まず初めに,ストレージの伝送帯域幅が大幅に向上し続けている一方で,メインメモリの量はほとんど増えていないことを示した。
 |
こうした状況を踏まえたうえでChen氏は,「DirectStorageの今日までの歩み」と題したスライドで,5つの項目を挙げた。
- DirectStorageは,2020年からこれらのトレンドに賭けてきた
- XboxとPCにまたがるサポートを推進し,一貫したストーリーを築いた
- Batched SubmissionとBypassIOによって,パイプラインのレイテンシを削減した
- XboxではZlib,PCではGDeflateを用いて,CPU負荷をオフロードする道筋を構築した
- EnqueueRequestsを通じてI/Oスケジューリングを強化し,開発者の効率化を改善した
DirectStorage APIは,XSXで採用された低レイテンシなストレージAPIを,PCにも展開したものだ。XSXとPCの双方で一貫して使えるAPIとして設計されている。
そもそも2020年時点のWindowsでは,標準のファイルシステムにおけるOS側のオーバーヘッドが大きすぎて,NVMe SSDが持つ数GB/sの帯域を活かしきれなかった。コンソールと同等の高速ストレージアクセスをPCで実現するには,根本的な改善が必要だったのだ。
そこでDirectStorageは,NVMe SSDへのアクセスリクエストをキューに積み,非同期で一括処理する新しいI/Oシステムとして構築された。
DirectStorageに,OSをバイパスしてストレージにアクセスする機能を実装するにあたっては,XSXで先行していたストレージアクセスAPIセットをそのままDirectStorageに組み込んだ。
開発者は,XSX向けに書いたストレージアクセスのプログラムコードを,最小限の変更でPC版でも動かせるわけだ。
DirectStorageが,PCとXSX共通の開発キット「Game Development Kit」(GDK)に組み込まれていることも,移植のしやすさを支えている。
DirectStorageのうち,筆頭にあげるべき機能が「BypassIO」だ。
これは,Windows 11で導入された機能で,OS側のファイルシステムをバイパスして,直接ストレージデバイスからメインメモリへ流し込む高速ホットラインと呼べるものだ。
BypassIOと並ぶDirectStorageの基本機能が,「Batched Submission」である。
Windowsの標準ファイル入出力API(ReadFileなど)は,ファイルをひとつ読み込むたびにAPIコールが必要だ。しかも,ファイル入出力の実処理は,カーネルモード(※OSの特権モード)で行うため,アプリ側のユーザーモードとの切り替えやセキュリティチェックが毎回発生する。
ファイル入出力が膨大なゲームでは,このオーバーヘッドが深刻な負荷となっていた。
Batched Submissionは,複数ファイルの読み出し要求をキューに積み,1回のAPIコールでまとめて処理する仕組みだ。APIコール回数が減るだけでなく,モード切り替えやセキュリティチェックの回数も激減するため,負荷軽減の効果は大きい。
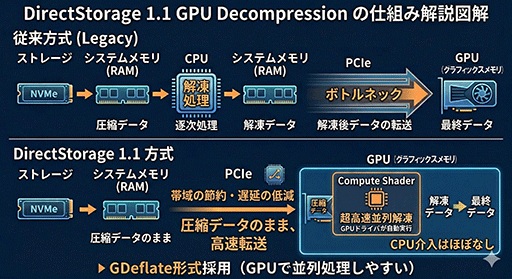
DirectStorage 1.1で実装された「GPU Decompression」も,看板機能のひとつだ。圧縮されたままのデータを,ストレージデバイスから直接グラフィックスメモリに読み出し,GPU上のCompute Shaderで高速に展開する仕組みである。
Compute Shaderベースのデータ展開用プログラムは,GPUドライバが必要に応じてGPU側で自動実行するため,開発者は,DirectStorage経由で,データの読み出しを要求するだけでいい。
PC向けの圧縮方式には,NVIDIA主導で開発されたライセンスフリーの「GDeflate」が採用されている。XSXが「Zlib」を採用しているのと異なるが,これはハードウェアの違いによるものだ。
XSXは,Zlib専用の展開プロセッサを搭載している。一方,PCにはそうしたハードウェアがない。しかもZlibはGPUによる並列処理での展開に向かず,PCで使うとCPU依存になってしまう。
DirectStorageは,CPU介入を極力排除することがコンセプトである。そこでMicrosoftは,NVIDIAやAMD,Intelといった各GPUベンダーと協議のうえ,Compute Shaderでの並列展開に適したGDeflateを選んだというわけだ。
従来型のプロセスは,以下のとおり。
- CPUがストレージから圧縮データをメインメモリに読み出す
- CPUで圧縮データを展開する
- 展開済みデータをDMAがグラフィックスメモリへ転送する
DirectStorageでは,これが次のように変わる。
- DirectStorageが命じて,DMAがストレージから圧縮データをメインメモリ側の汎用バッファに読み出す
- DMAが圧縮データをGPU側の汎用バッファへ転送する
- GPUがCompute Shaderで圧縮データを展開する
- GPU内のDMAが,展開済みデータをグラフィックスメモリの適切なアドレスへ配置する
ポイントは,全工程からCPUの介入をほぼ排除できる点だ。加えて,圧縮データのままGPU側へ送るため,PCI Express(以下,PCIe)インタフェースの帯域(=トラフィック)も削減できる。
 |
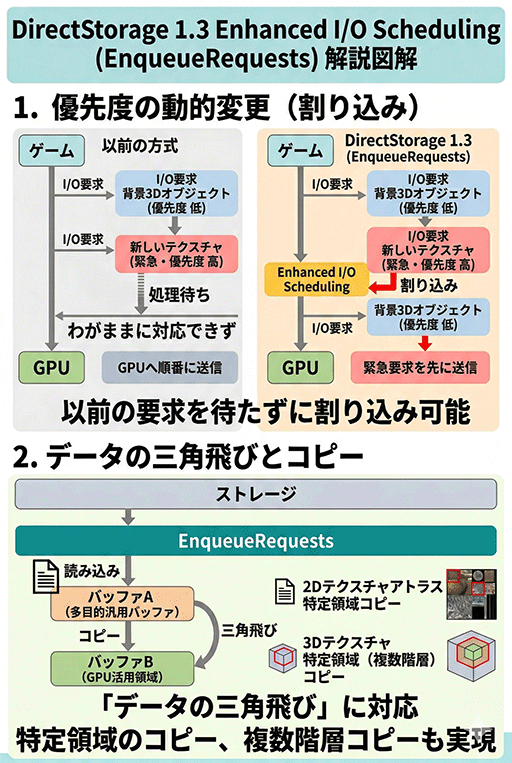
DirectStorage 1.3では,ゲーム実行中のリアルタイムな状況変化に対応するための「Enhanced I/O Scheduling」(Enqueue Requests)が新設された。
分かりやすい使用例は,読み出し優先度の動的な変更だ。たとえば,背景3Dオブジェクトの読み出しをすでに要求していたところに,ゲーム展開の都合でテクスチャの読み出しが緊急で必要になった場合,後者を優先させることが可能になる。
さらにEnqueue Requestsは,「バッファAにデータを読み込んだあと,続けてバッファBへコピーする」といった多段転送にも対応する。2Dのテクスチャアトラスの特定領域や,3Dテクスチャの複数階層にまたがるコピーも扱える。
なお,この例でいうバッファAは,汎用の一時バッファで,バッファBはGPUが実際に使用するために確保された領域であることが多い。
 |
次世代DirectStorageへの道〜OS側が抱える課題の解決
続いてChen氏は,DirectStorageの今後の進化の方向性を示すスライドを提示した。
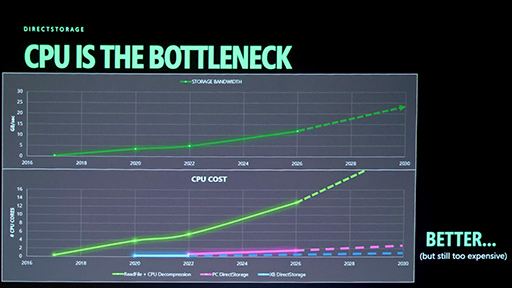 |
スライド上段のグラフは,NVMe SSDの帯域向上の推移,下段はCPU負荷の推移を示している。
注目すべきは下段側だ。緑の線は,PCにおける通常のファイル読み出し時のCPU負荷で,急激な右肩上がりを描いている。ここには読み出し処理そのものだけでなく,圧縮データをCPUで展開する負荷も含まれている。SSDの帯域幅が増えれば,単位時間に読み込まれる圧縮データ量も増えるため,CPU側の展開負荷もそれに比例して増大するわけだ。
一方,PC版DirectStorage使用時のCPU負荷は,ピンクの線で示しており,緑よりは大幅に低い。しかし,XSX版DirectStorageの青い線が地を這うように推移しているのと比べると,まだ明確な差がある。
Chen氏がこのスライドで訴えたかったのは,まさにこの点だ。PC版DirectStorageは,XSX版と比べてCPUへの依存度がまだ大きく,改善の余地が残っている,という指摘である。
続いてのスライドでは,DirectStorage 1.3で実装済みの機能と,次世代DirectStorageで搭載予定の機能が整理されている。ここまで解説してきた機能にはチェックマークが付いており,チェックのない右側の項目が今後の課題だ。
搭載予定の機能を,順に見ていこう。
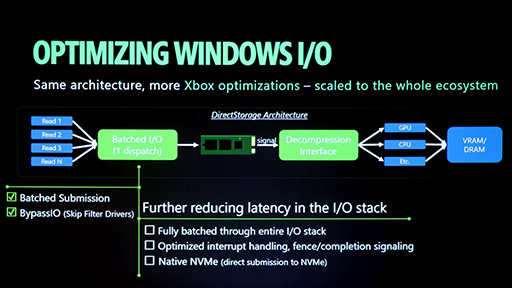 |
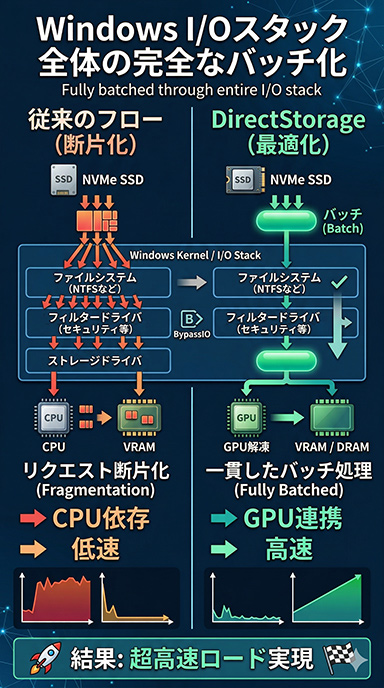
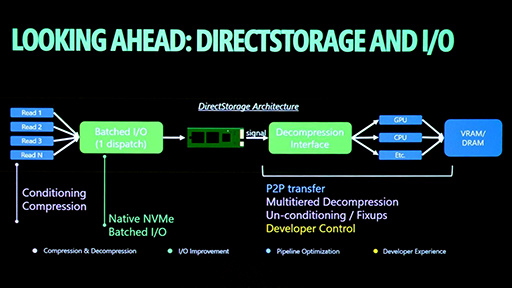
最初の機能は「Fully batched through entire I/O stack」,すなわちI/Oスタック全体を通じた完全なバッチ処理の実現だ。
先述のBatched Submissionにより,複数ファイルへのアクセス要求をまとめて発行すること自体はできている。しかし実際には,アクセス要求群がWindowsのカーネルに送られる過程で,NTFSなどファイルシステムを経由するうちに断片化されてしまい,ストレージドライバに届く頃には,個別のアクセス要求に戻ってしまうことが多い。
そこで次世代DirectStorageでは,OS側のI/Oスタックの最下層まで,バッチを崩すことなく一貫して処理する仕組みを実現するという。
 |
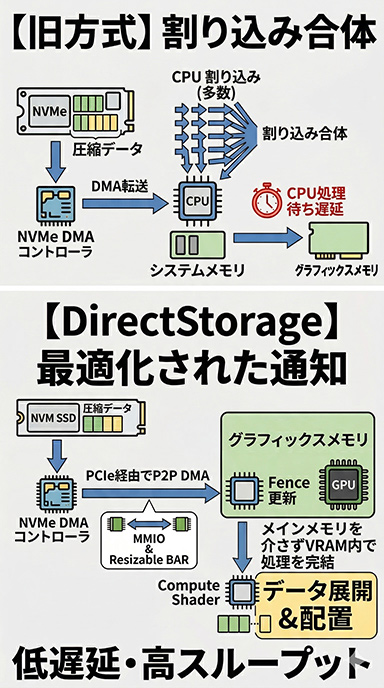
2つめの機能「Optimized interrupt handling, fence/completion signaling」は,割り込み処理の最適化だ。やや低レイヤの話になるので,背景から説明したい。
NVMe SSDからのデータ伝送自体は,DMAが担うが,読み出しが完了するたびにCPUへ割り込み(Interrupt)が発生する。
今では割り込みの発生頻度を抑えるために,「割り込み合体」(Interrupt Coalescing)が使われている。一定数の読み出しが完了するまで割り込みを保留するか,割り込みの間隔を広げるといった仕組みだ。
一般的なアプリケーションならこれで十分だが,ゲームでは事情が異なる。読み出したデータを,可能な限り低遅延でグラフィックスメモリへ届けたいからだ。
現状,NVMe SSDからのデータは,いったんCPU管理下の汎用バッファに読み出される。そこからグラフィックスメモリへ転送するには,CPUがデータの到着に気づく必要があるため,割り込み合体で通知を遅らせてしまうと,かえって転送の遅延につながる。
つまり,CPUが汎用バッファへの読み出し完了を検知したタイミングでしか,グラフィックスメモリへの転送は始まらないのだ。
そこで次世代DirectStorageでは,NVMe SSDからGPU管理下のグラフィックスメモリへ直接データを読み出す仕組みによって,この問題を解決する。CPU側の汎用バッファを経由しないため,CPUの介在そのものが不要という理屈だ。
それでは,NVMe SSD側のDMAコントローラは,どうやってPCIeインタフェースを介してGPU側のメモリへデータを届けるのか。ここで使われるのが,Memory Mapped I/O(MMIO)と「Resizable BAR」(ReBAR)だ。
ReBARは,PCゲーマーや自作PCファンならUEFI設定で見かけたことがあるだろう。AMD用語では「Smart Access Memory」(SAM)と呼ばれている。
MMIOは,CPUのメモリアドレス空間にI/Oデバイスを割り当てる技術で,16bit CPU時代から存在する。特定のメモリアドレスへの読み書きが,そのまま周辺機器への入出力として機能する仕組みだ。
MMIOを応用して,CPUのアドレス空間上にGPU管理下のグラフィックスメモリを割り当てる(マッピングする)と,NVMe SSD側のDMAがメインメモリの汎用バッファに書き込んだつもりのデータが,実際にはPCIeインタフェースを経由してグラフィックスメモリへ送られることになる。
 |
ReBARが関係してくるのは,グラフィックスメモリ側の汎用バッファのサイズだ。UEFIでReBARを有効化していない場合,MMIOで割り当てられるバッファは,最大256MBに制限される。有効化すれば,搭載グラフィックスメモリの容量に応じた適切なサイズを確保可能だ。
汎用バッファへの読み出しが完了すると,GPUに通知が届き,データを実際の使用先アドレスへ転送する工程に移る。ここでの通知は,CPU側のような割り込み信号ではなく,特定のメモリアドレスを監視するフェンス(Fence)の仕組みが使われる。
ただ,汎用バッファから最終的な使用先アドレスへのデータ転送に,GPU側のDMAは使わない。SSDから読み出されたデータは,圧縮されたままだからだ。先述のとおり,この展開処理はCompute Shaderが担う。つまり,展開と同時にデータが適切なアドレスへ書き出される流れになる。
この仕組みが実現すれば,PCでもXSXに近い低遅延のストレージアクセスが可能となるだろう。
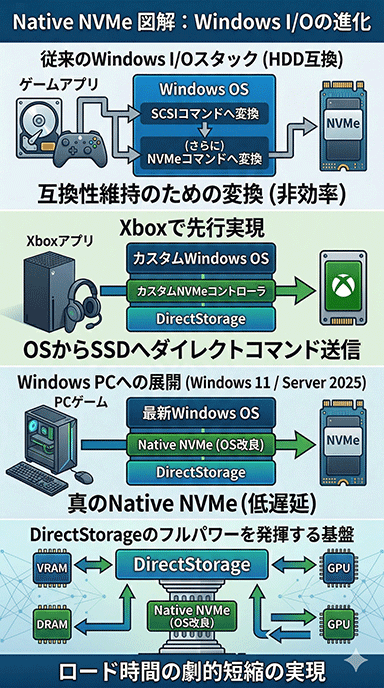
3つめの「Native NVMe」(direct submission to NVMe)は,XSXのストレージ性能にPCが追いつくための重要な改善項目だ。
Windowsのストレージシステムは,歴史的にHDDを前提に構築されてきた。NVMe SSDが登場したときも,互換性維持のために,OSからのストレージアクセス要求をいったんSCSIコマンドに変換して,さらにそれをNVMeコマンドに変換してからSSDに送るという,二重変換の設計を採用しているのだ。
SCSIデバイスを使っていないのに,デバイスマネージャに「SCSI〜」の項目が表示されるのは,この仕組みが残っているためだ。
この二重変換を,Microsoftが初めて排除したのがXSXである。XSXのカスタムWindowsでは,カスタムNVMeコントローラへ直接コマンドを発行する「Native NVMe」が実現された。
ちなみに,前世代のXbox Oneでは,主要ストレージがSATA接続のHDDだったため,SCSIコマンド変換がそのまま使われていた。
NVMeが普及して10年が経つ2026年現在,PC側のWindowsでも,ようやくNative NVMeへの刷新が行われようとしている。それも,次期Windowsまで待つ必要はなく,Windows 11の年次アップデートで提供される見込みだ。
その根拠となるのが,Chen氏が示した次のスライドである。
 |
スライドで引用されているのは,2025年12月に公開されたMicrosoftの公式ブログ記事で,Windows Server 2025がNative NVMeに対応する方針を報じたものだ。
Windows Server 2025は,クライアント向けWindows 11とカーネルを共有しているので,遠からずゲーミングPCでも,XSX同等のネイティブNVMeアクセスが実現するはずだ。
つまりNative NVMe対応は,DirectStorageの機能追加ではなく,Windows OS自体の改良である点は押さえておきたい。
 |
最新のDirectStorage 1.4が採用した「Zstd」とは?
2026年3月には,DirectStorage 1.4のプレビュー版が公開された。Chen氏が示した次のスライドでは,ストレージ上のデータ圧縮に関する解決済みの課題と残課題が整理されている。
 |
先述のとおり,DirectStorage 1.3の時点で,標準圧縮技術としてXSXにはZlib,PCにはGDeflateが採用済みだ。
DirectStorage 1.4で新たに解決する課題は,次の3項目となる。
- Compression Ratio&Performance(圧縮率と性能)
- Unencumbered availability on HW/SW platforms(ハード/ソフトを問わない自由な利用)
- Existing adoption and tools(既存の普及状況とツール群)
この3要件に対するDirectStorage 1.4の解答が,「Zstandard」(Zstd)である(関連記事)。
 |
Zstdは,Meta(旧Facebook)のYann Collet氏が開発したオープンソースの可逆(ロスレス)圧縮技術で,2016年の発表以来,採用が広がっている。リアルタイムストリーミングにも対応できる展開速度の速さと,他方式に引けを取らない圧縮率の高さが評価されているためだ。
業界標準規格として正式採用されたわけではないが,そのアルゴリズムは,インターネット関連技術の標準化団体「IETF」(Internet Engineering Task Force)から,「RFC 8878」として公開されている。
Zstdとほかの圧縮技術を,性能やCPU/GPUでの扱いやすさで表にまとめてみた(筆者調べ)。
| 圧縮アルゴリズム | 圧縮率 | CPU展開 | GPU展開 | ライセンス,特徴 |
|---|---|---|---|---|
| Zstd | 高い | 非常に速い | △〜◯:本来はCPU向けで,GPUはシェーダで処理。ハード対応で速くできる | オープンライセンス。圧縮率,速度,汎用性のバランスに優れた業界標準技術 |
| Oodle Kraken | 極めて高い | 最速 | ◯:CPU向けだがGPUデコーダで高速展開可能 | UE以外はEpic Gamesのライセンスが必要。PS5の標準技術で,専用ハードで超高速に展開できる |
| GDeflate | 中程度 |
標準的 | ◎:GPUによる超並列処理専用設計で,相性が完璧 | オープン(NVIDIA主導)。圧縮率よりGPU展開スループット重視 |
| Zlib | 中程度 | 遅い | ×:データ構造がGPU並列処理に不適で,GPUのメリットなし | オープン。レガシー標準でXSX標準技術。専用ハードで超高速展開 |
ZstdをDirectStorage 1.4で採用した理由について,Chen氏は,「他方式に劣らない圧縮率の高さに加え,すでに多くの業界で採用が進んでいること,そしてオープンスタンダードであることが決め手だった」と述べている。
筆者の推測だが,Microsoftにとって,PS5も採用した高圧縮率でGPU展開スループットの高いOodle Krakenは,魅力的だったはずだ。しかしOodle Krakenは有償ライセンスの技術である。XSX専用であれば,Epic Gamesとの包括契約で対応できても,PCゲーム開発まで含めた標準技術としては採用しにくい。
XSXとPCで透過的に使えるプラットフォームを目指すMicrosoftにとって,Oodle Krakenに匹敵する圧縮率を持ちながらオープンソースであるZstdは,最適な選択だったのだろう。
ただし,上の表で1点気になるのは,ZstdのGPU展開スループットが,GDeflateを下回る点だ。Chen氏もこれを認めたうえで,「将来的には改善される見通しだ」と,楽観的な見通しを示していた。
Zstd展開用のCompute Shaderプログラムは,まずMicrosoftが全GPU共通のものを提供するが,DirectStorage 1.4では各GPUベンダーが,ドライバレベルで独自実装に置き換えられるようにしているのだ。
つまり,PS5やXSXが専用展開プロセッサを搭載したように,将来的にはGPUベンダーが,Zstd展開用のハードウェアをGPUに実装してくることを期待しているのではないだろうか。
 |
Zstd支援ライブラリ「GACL」
Zstdの採用にあたってMicrosoftは,ゲーム用途向けのライブラリ/ツール「Game Asset Conditioning Library」(GACL)を新しく開発した。
これは,先述したOodle Textureに対抗する技術で,テクスチャデータをZstdで効率よく圧縮するためのコンバータ/エンコーダ機能を備えている。
 |
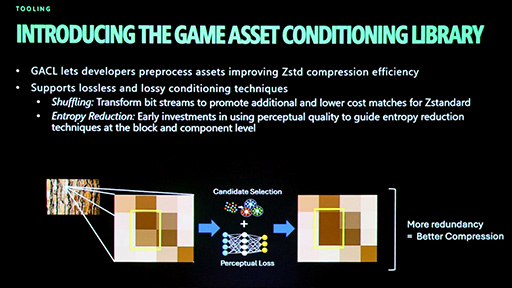
GACLの機能のひとつが,ロスレスコンバータ「Shuffling」だ。「BCx」などの業界標準形式で圧縮済みのテクスチャデータを,Zstdでさらに二重圧縮する前に,Zstdの圧縮アルゴリズムが効きやすいようにデータ列を並べ替えるものだ。
GPU向け圧縮テクスチャであるBCx形式は,一般的な画像データとは異なり,複数テクセルのグループを,圧縮を適用する1ブロックとして扱う。次のスライドは,最も基本的なBC1形式のデータ配列と,GACLでShufflingを施した結果を示している。
 |
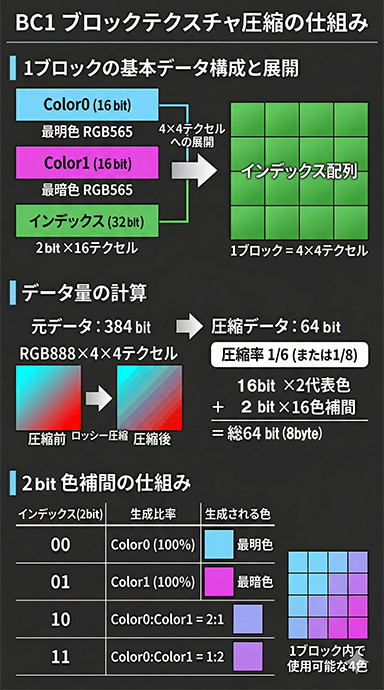
図中の水色(Color0)とマゼンタ(Color1),その下の緑(インデックス)で構成される一組がBC1の1ブロックにあたり,4×4テクセル分のデータに相当する。図では,これが縦横4×4の計16ブロック並んでいるので,全体で256テクセル(16×16テクセル)分を表すわけだ。
Color0は,ブロック内で最も明るい色,Color1は,最も暗い色を示す。Color0とColor1は,本来ならRGB各8bitの24bitフルカラーで表現するところを,R 5bit,G 6bit,B 5bitの16bitカラーに削減するのだ。この時点で情報の欠損が生じるため,BC1はロッシー(非可逆)圧縮である。
インデックスは,4×4テクセル=16テクセルの各テクセルに2bitずつ,計32bit分を割り当てるフォーマットで,後述する色補間のルックアップに使われる。
非圧縮の場合,4×4=16テクセルには,24bit×16テクセルで384bitが必要だ。BC1ではこれを,16bit×代表色2色+2bit色補間×16テクセルのインデックス=計64bitに収める。圧縮率は6分の1(※α要素込みなら8分の1)となる計算だ。
2bit色補間は,00/01/10/11の4つのビットパターンを用いて,以下のように演算する(1bitアルファの特例は省略)。
- 00:Color0(最明色)そのもの
- 01:Color1(最暗色)そのもの
- 10:最明色と最暗色を2:1で混ぜた中間色
- 11:最明色と最暗色を1:2で混ぜた中間色
BC1は圧縮率を優先する方式のため,色精度は24bitから,実質16bit相当まで低下する。
 |
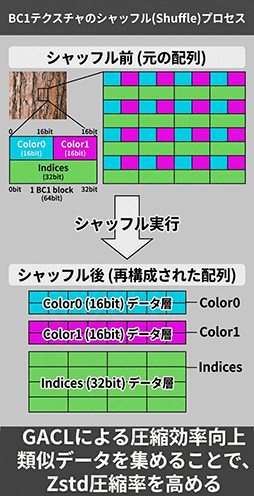 |
同系列のデータを集めると,値の類似性や反復性が高まりやすいので,圧縮が効きやすくなる。とくにテクスチャのような素材では,Color0やColor1のような局所色情報は,近い値や反復パターンが出やすいため,Zstdとの相性がいい。
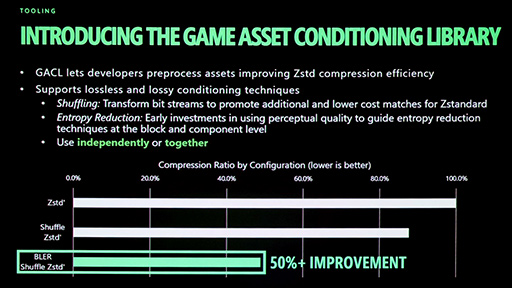
Chen氏によれば,Shufflingの有無だけで,Zstdの圧縮率が10%ほど向上するとのことだ。
Shufflingで圧縮したデータは,Zstdで展開しただけでは,元のBCx形式には戻らない。そのため,ゲーム実行時にストレージからZstd圧縮データをGPUで展開するときは,同時に元のBCx配列への復元する逆Shufflingも行う必要がある。展開と逆Shufflingを順に処理するのではなく,展開データの書き出しを逆Shufflingに配慮するイメージだ。
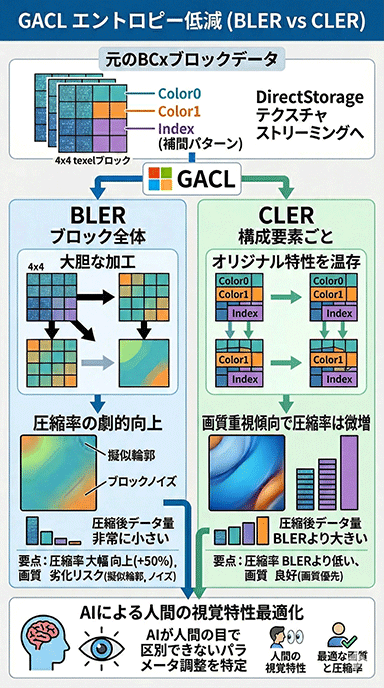
さらなる圧縮率の向上を求める開発者に向けては,GACLの「Entropy Reduction」(エントロピー低減)を活用するよう,Chen氏は推奨していた。
ここでいうエントロピーとは,データのランダム性(バラツキ)と捉えてもらえばよい。Entropy Reductionは,圧縮前のデータのバラツキを平滑化して,Zstdの圧縮効率を高める処理だ。
実写画像系テクスチャの場合,隣接する4×4テクセルのブロック同士が,ほぼ同じパターンになることが多い。そこでEntropy Reductionは,圧縮済みテクスチャのブロックデータ(Color0,Color1,インデックス)自体を,Zstd圧縮が効きやすいように書き換えてしまうのだ。
Entropy Reductionには2つのモードがある。ひとつが「Block Level Entropy Reduction」(BLER)で,ブロック単位での書き換えを行う。隣接ブロックを単純にコピーするのではなく,GACLがブロックごとに加工を施す仕組みだ。
BLERの効果は非常に大きく,Shufflingと組み合わせてZstdで圧縮すると,BCx圧縮済みテクスチャのデータ量が,さらに50%前後まで小さくなるという。
 |
 |
ただ,BLERは素材によってはやりすぎる傾向があり,擬似輪郭やブロックノイズが露呈する場合がある。そこで用意されているのが,画質を優先するモード「Component Level Entropy Reduction」(CLER,構成要素ごとのエントロピー削減)だ。
CLERはブロック単位での大胆な加工は行わず,Color0,Color1,インデックスといった構成要素をなるべく温存しながらデータを書き換える。当然,ランダム性はある程度残るため,BLERほどの圧縮率向上は得られないが,画質の劣化を抑えられる。
では,Entropy Reductionはどのようなアルゴリズムで書き換えを行っているのか。先ほどのスライドにヒントが描かれていたが,シンプルな数理処理ではなく,AIを用いるのだ。
詳細は割愛するが,AIの挙動としては,人間の視覚では気づかないギリギリのパラメータを探る。
 |
最後に,過去のDirectStorageで搭載していたZlibやGDeflateがどうなるかにも触れておきたい。
当然,過去の資産との互換性もあるのでサポートは続くはずだ。XSXはZlib専用のハードウェア展開ブロックを搭載しているので,今後も重要な選択肢となる。PCでも,GPU展開スループットに優れ,ノウハウの蓄積もあるGDeflateは,当面活用が続くだろう。
 |