












ニュース
「ムーアの法則の終焉」をどう切り抜けるか? NVIDIAのチーフサイエンティストがディープラーニングのイベントで語った
 |
タイトルからも分かるとおり,ゲームとはほぼ何も関係のないイベントだ。だが,本イベントに合わせて来日し,基調講演を行ったNVIDIAのChief ScientistであるBill Dally(ビル・ダリー)氏は,将来のGPUにもつながりそうな興味深い話題を盛り込んでいた。そこで本稿では,基調講演の概要をごく簡単にまとめてみた。
実用段階に入ったディープラーニング
基調講演を担当したDally氏は,NVIDIAの研究開発部門で上級副社長を務めるという,同社を代表する人物だ。かつては,スタンフォード大学で並列コンピューティングに関する先駆的な研究を行い,並列計算の基礎や実装に大きな貢献をしたことでも知られている。
そんな氏による講演は,ディープラーニング分野に留まらず,今後,いかにして演算性能を上げていくかという,NVIDIAにとっての重要課題が取り上げられた。
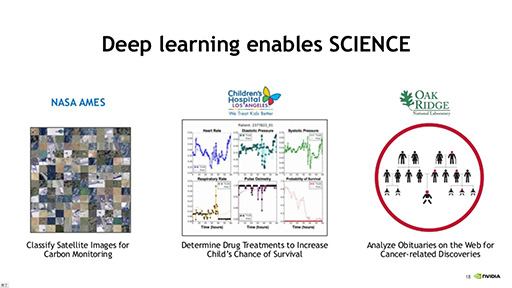
まず,Dally氏が強調したのは,科学の領域においては,すでにディープラーニングが実用に供されていることだ。Dally氏はいくつかの実例を上げて,科学の領域におけるディープラーニングの活用例を紹介していった。
たとえば,NASAのAmes Research Center(エイムズ研究センター)では,衛星からの映像をもとにした大気中における二酸化炭素の監視に,ディープラーニングを応用しているという。
 |
また,欧州のLarge Hadron Collider(大型ハドロン衝突型加速器,LHC)は,1回の実験で解析に何年もかかるほど膨大なデータを得られるそうだが,「ディープラーニングによって,解析すべきデータを高速にフィルタリングすることが可能になっている」と,Dally氏は説明した。
 |
4Gamer読者には知られたとおり,NVIDIAは,ディープラーニングに対して積極的な投資を行い,この用途に向けた新しいGPUを開発している。Pascalアーキテクチャに基づく数値演算アクセラレータ「Tesla P100」と,そのGPUコアである「GP100」がその代表だ(関連記事)。
Dally氏はGP100のイラストを示しながら,「電源部が多くの面積を占めている。また,「HBM2」技術に基づくメモリスタックは,シリコンのサブ基板を介してGPUと接続されている」という具合に,その特徴を説明した。
 |
ディープラーニングが製品やサービスに応用されているのは,研究開発分野だけではない。「人工知能を応用した一般消費者向けの製品が,数多く登場してきている」とDally氏は述べる。
その代表例としてDally氏は,Amazonの音声認識アシスタント「Amazon Echo」を挙げた。日本語対応のサービスが少ないこともあり,日本ではまだ,音声認識技術を応用したサービスが一般的とはいえない状況だ。しかし米国では,Amazon Echoが品薄になるほど好評であると,筆者も耳にしている。「向こう数年で,こうした人工知能搭載デバイスは,数億台というスケールで普及するだろう」とDally氏は語った。
 |
Project Xavierはターゲットによって性能が変わる?
Amazon Echoのような製品に組み込めるデバイスとして,NVIDIAは,組み込み機器向けSoC(System-on-a-Chip)「Tegra X1」と,それを搭載する小型コンピュータ「Jetson TX1」を提供している。
Dally氏は,次世代のTegraを担う製品として開発中の新型SoC「Project Xavier」(プロジェクト・エグゼイビア,開発コードネーム)を取り上げて,「VoltaアーキテクチャのGPUを統合したXavierでは,より高い性能を実現している」とした。
 |
ちなみに,1月4日に行われたNVIDIAのCEOであるJen-Hsun Huang氏によるCES 2017基調講演でも,Xavierの話題が取り上げられている。ただ,CES 2017の講演では,Xavierの性能について,「30TOPS DL※の性能で消費電力30W」と説明していた。ところが,Dally氏が示したスライドでは,これが「20TOPS DLの性能で20W」となっているのだ。
※1秒間に30兆回のディープラーニング処理を実行する性能を意味する。
 |
どちらかが間違い,あるいは古い情報なのかと思う人もいるかもしれないが,筆者は別の推測をしている。Xavierはターゲットとする用途や市場に応じて,異なるスペックを用意しているのではないだろうか。Huang氏が語ったのは,車載情報システム向けのXavierだった。一方,今回のDally氏が語ったのは,Tegra X1の後継としてのXavierではないかという推測だ。
自動運転の制御を最終目標にする車載情報システム向けSoCでは,高い演算性能が必要になるので,30TOPS DL版のXavierを利用する。それに対して,消費電力や熱に対する要求が厳しくなる組み込み用途向けには,20TOPS DL版のXavierを提供するという考えは,それほどおかしなものではないはずだ。
つまりXavierは,ターゲットによって性能を変えられるSoC――単純に動作クロックを変えているだけかもしれないが――というのが,今回のDally氏の公演で分かったことではないだろうか。
ポスト・ムーアの法則時代に,いかにして性能を向上させるのか
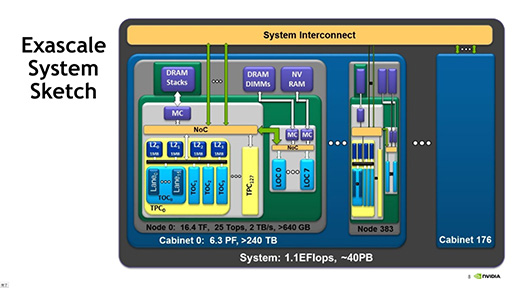
ディープラーニングに取り組むNVIDIAは,GPUの高性能化を今後も続けていく必要がある。とくにDally氏が強調したのは,HPCの分野において「2020年までに,2万Wで1 EFLOPSを達成するHPCを構築しなければならない」という点だった。いわゆる「エクサスケール」(※エクサはテラの100万倍)コンピュータの実現を,NVIDIAも目指しているわけだ。
 |
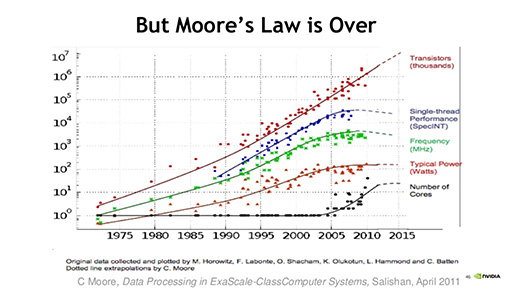
しかし,これまでプロセッサの高性能化を牽引してきた,いわゆる「ムーアの法則」が,すでに成立しなくなっているのが難題である。「ムーアの法則が終焉した状況で,今後,どうやって性能を上げていくのか」と,Dally氏はNVIDIAだけでなく,半導体業界が直面している課題を挙げた。
 |
そんな状況にあって,Dally氏がエクサスケール実現の鍵として取り上げたのが消費電力当たりの性能向上だ。NVIDIAがかねてから強調していることだが,CPUに比べて,GPUは演算あたりに必要とするエネルギー(≒消費電力)が2桁ほど少ないのである。
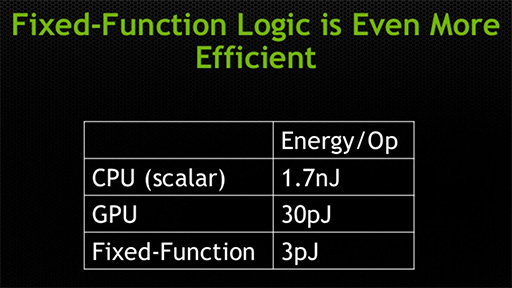 |
「CPUは,分岐予測や再スケジューリングといった演算以外の部分でエネルギーを消費しており,それが大きなオーバーヘッドになっている」というのが,Dally氏の主張だ。GPUは,そうしたオーバーヘッドが少ないので,1演算あたりの消費エネルギーを小さくできるという理屈である。
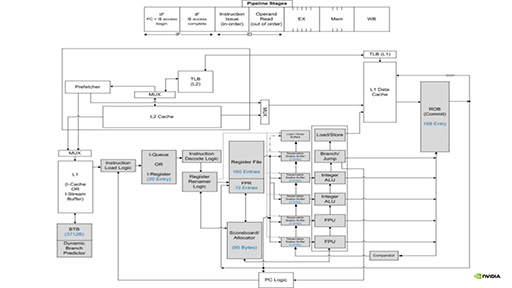 |
エクサスケールを実現するためには,演算あたりの消費エネルギーをさらに削減しなければならないわけだが,その鍵になるのが「データの移動」であるとDally氏は言う。データを移動させるために,現状では多くの電力が消費されているため,それを削減する方法が課題だというのである。
 |
 |
またDally氏は,データの移動を少なくできるように最適化するツールと,プログラミング技法の必要性も訴えた。Dally氏が紹介したのは,スタンフォード大学で研究されている「Legion Programming Model」(関連リンク)というものだ。
Legion Programming Modelは「まだ研究段階のもの」(Dally氏)だそうなので,本稿では説明を割愛するが,要は,データ構造と配置,並列化を最適化することで,高性能化を実現しようというプロジェクトである。すでに,3次元有限要素法の演算を6倍も高速化するなど,相応の実績を挙げているという。
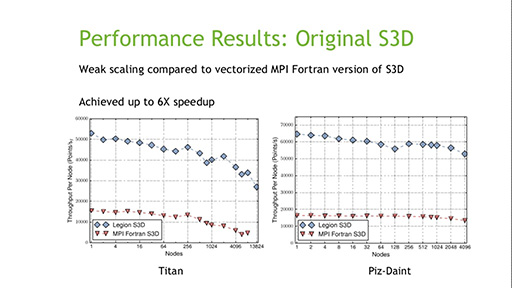 |
簡単にまとめると,ムーアの法則が終わりを迎えつつある状況でエクサスケールのコンピュータを実現するためには,ハードウェアのみならず,ソフトウェアやツールの助けも必要というところだろうか。いずれにしても,ありとあらゆる技術を総動員しないとエクサスケールの実現は難しいのだろう。
 |
NVIDIAによるエクサスケールの実現に向けた取り組みは,将来的にはGPUの高性能化にもつながるだろう。ゲーマーにとっても,決して無関係な話ではないのかもしれない。
- 関連タイトル:
 Tegra
Tegra - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー