











連載
西川善司連載 / GeForce GTX 400アーキテクチャ徹底解説(後)

Fermi(フェルミ)アーキテクチャを採用し,開発コードネーム「GF100」とも呼ばれていた,「GeForce GTX 400」シリーズ。とうとう北米時間2010年3月26日に正式発表を迎える新GPUのアーキテクチャを掘り下げる記事,後編をお届けしたい。
前編では,GeForce GTX 400の概要や,「CUDA Core」と呼ばれるシェーダコアを見てきた。その流れを受けつつ,今回は,よりディープな世界,メモリ&キャッシュシステム周りや,DirectX 11の花形フィーチャーであるテッセレーション周りを取り上げていこう。

下に示したのは,前編でも紹介した,GF100(≒GeForce GTX 480)の全体ブロックダイアグラムと,それを構成する「Graphics Processing Cluster」(以下,GPC),GPCを構成する「Streaming Multi-Processor」(以下,SM)の,それぞれブロックダイアグラムになる。順に,全体からミクロへと,視点を移していくイメージだ。
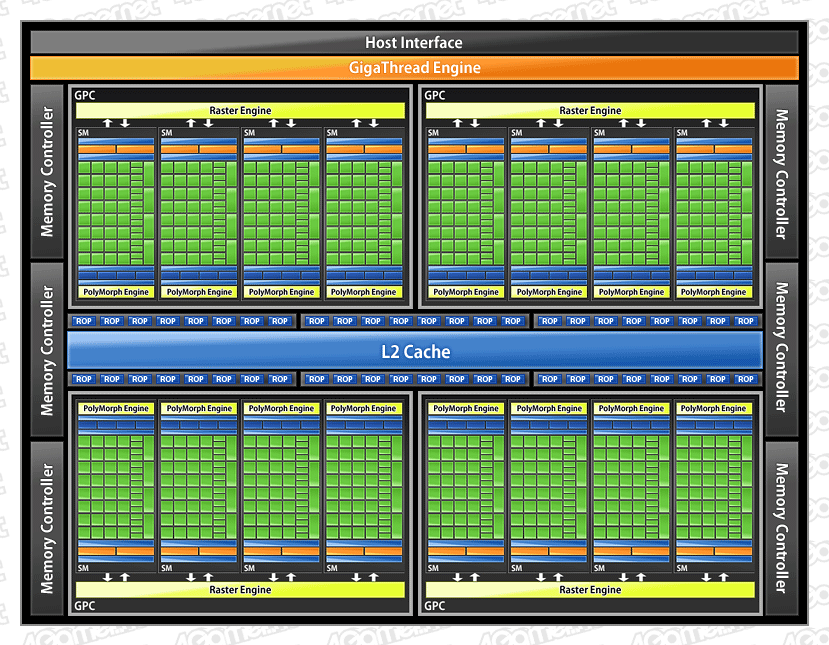
GF100の全体ブロックダイアグラム。GF100では,4基のGPCを内包する
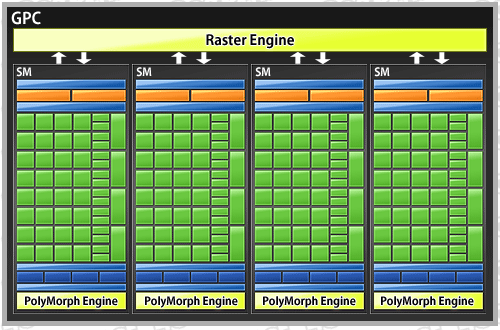
GPC 1基を取り出したブロックダイアグラム。1GPU当たり,4基のSMと「Raster Engine」で構成される

そしてこれがSM 1基のブロックダイアグラム
メモリアクセスを担当する「Load/Store Unit」(ロード/ストアユニット,以下日本語表記)は,SMごとに16基実装され,これらはSM内のCUDA Core 32基から共用される構造になっている。1基のロード/ストアユニットは,1クロックで1スレッド分のソースアドレスとデスティネーション(宛先)アドレスを計算可能だ。
そして,SM内には4基のテクスチャユニット(※上に示した図だと「Tex」)を実装。各テクスチャユニットは,1クロックあたり一つのテクスチャアドレス計算と,4テクセル分のフェッチ(読み出し)を行える。
専用テクスチャキャッシュの容量は,先代の「GT200」(≒「GeForce GTX 280」)と同じ,12KB。ただし,テクスチャユニット数は,GT200が計80基搭載していたのに対して,GF100では,SMあたり4基の計64基と,その数を減らしている。
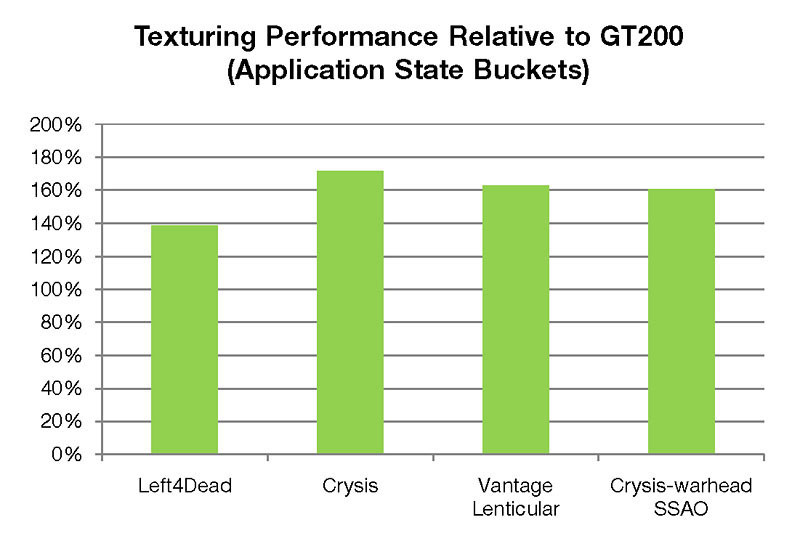
NVIDIAのホワイトペーパーから,“テクスチャヘビー”な3Dゲームアプリケーション実行時におけるGF100の性能を,GT200との対比で示したグラフ
しかし,GF100において注目しておきたいのは,テクスチャユニットが,SM内へと移設されていること。「G80」(≒「GeForce 8800 GTX」)以降,GeForceではSMクロックがコアクロックよりも高く設定されるようになっているが,この移設によって,テクスチャユニットの動作クロックが引き上げられ,スループットが向上したことにより,「全テクスチャユニットのトータルピーク性能は,GT200と同等だ」とNVIDIAは述べている。
「GT200を上回る」という発言を避けていたのは印象的だったが,とはいえ,L1テクスチャキャッシュの動作クロックがCUDA Coreと同等に高速化したこと,そして後述するL2キャッシュ容量がGT200の3倍へと増量したことは効いてくるので,高負荷時(=テクスチャアクセス集中時)のパフォーマンス低下は,GT200よりも小さくなるとのこと。
要するに,「実質的な実効テクスチャ性能はGT200比で改善している」というのが,NVIDIAの主張である。
なお,テクスチャユニットの機能自体はDirectX 11フィーチャーの実装に伴って強化されている。具体的には,従来の「S3TC」(DXTC)などに加えて,新しいテクスチャ圧縮メソッドである「BC6H」「BC7」などへの対応がホットトピックだ。
BC6Hは,HDR(High Dynamic Range)テクスチャ圧縮メソッドとして,BC7は高品位LDR(Low Dynamic Range)テクスチャ圧縮メソッドとして,それぞれDirectX 11から新規にサポートされたフォーマット。これら,新しいテクスチャ圧縮メソッドについては,筆者の過去記事「DirectX 11でデータ並列コンピューティングをサポートする演算シェーダとは」が詳しいので,合わせて参照してほしいと思う。

Four-offset Gather4の概念。テクスチャアドレスとして与えられたs,tに対して−64〜+63のオフセットを与えつつ,4テクセル読み出せる機能だ
このほか,GF100のテクスチャユニットは,DirectX 11におけるもう一つのテクスチャ関連新要素「Four-offset Gather4」(4オフセットGather4)への対応が,ハードウェア的に施されている。
4オフセットGather4というのは,DirectX 9世代のGPUであるATI Radeon X1000シリーズがサポートしていた「Fetch4」機能を一般化して,DirectX 11の標準仕様として取り込んだもの。Fetch4は,Zバッファから4テクセル分のZ値(深度値)を同時に読み出す機能で,NVIDIAオリジナルの深度バッファ(Depth Buffer)参照機能,俗称「NVIDIA SHADOW」に向けた対抗機能という位置づけだった。
これに対して,Four-offset Gather4は,Fetch4の概念を一般化して拡張し,テクスチャ内の4か所から,任意の要素 α/R/G/B を,オフセット値 s,t=−64〜+63 を与えつつ読み出せるものになった。要するに,基準テクスチャ座標から128×128テクセル範囲にある,任意の4テクセルを同時にサンプリングできるようになったのだ。
これは,デプスシャドウ(Depth Shadow)系影生成の高効率実行はもちろんのこと,最近流行となっているSSAO(Screen Space Ambient Occlusion,ピクセルのレンダリングにあたって,当該ピクセルがどれだけ周囲から遮蔽されているかを調査すること)のような,深度値の広範囲かつ多段なアクセスを駆使した,複雑なポストプロセッシング処理を高効率で実行させるのにも役立つ。 NVIDIAによれば,そうしたポストプロセスシェーダを動作させたときの実行性能は,GF100で,GT200の2倍へと引き上げられているという。

GF100で,キャッシュシステムに大きく手が入ったのも,GT200からの改良点といえる。
下に示したのは,GF100におけるメモリ階層構造だけを抜き出したものだ。
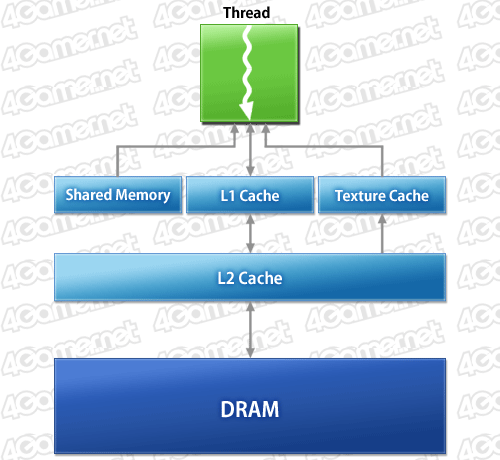
GFのメモリ階層(Memory Hierarchy)概念図
SMあたり容量12KBの専用テクスチャキャッシュが用意されることは先ほど述べたとおりだが,GF100ではこれに加え,用途別に構成を変更できる,容量64KBのオンチップメモリ(configurable on-chip memory)も用意されている。
これは,SM内のロード/ストアユニットが読み書きするデータのL1キャッシュ(=汎用データキャッシュ)として使ったり,スレッド内同期通信を行うためのスレッド間共有メモリ「Shared Memory」として利用したりできる高速なメモリ領域。FermiアーキテクチャではL1キャッシュ16KB+共有メモリ48KB,あるいはL1キャッシュ48KB+共有メモリ16KBという2通りの使い方ができる。
3DグラフィックスプロセッサとしてのGF100では,L1キャッシュ16KB+共有メモリ48KBの構成が設定され,キャッシュメモリとしての用途以外に,溢れレジスタやスタックポインタの待避場所としても利用される。簡単にいうと,GF100では,GT200と比べて,より大容量の高速メモリを利用できるようになった,といったところか。
そして,先ほど簡単に「GT200比3倍」と述べたように,L2キャッシュ容量が,GT200の256KBから768KBへと大幅に増加しているのも,GF100におけるトピックの一つだ。そう,CUDA Coreの数は2倍なのに,L2キャッシュ容量は3倍になったのである。
NVIDIAによれば,この強化は,「今世代のGPU用途で,より多くのランダムメモリアクセスが想定されるため」。一般的な3Dグラフィックス用途だと,メインになるのはテクスチャアクセスやレンダリング結果の書き出し,Zバッファへのアクセスで,メモリアドレス的見地からすると,メモリアクセスは局所性が高いという特徴がある。
これに対し,新要素としてDirectComputeが実装されたDirectX 11世代では,従来以上にGPUをGPGPU(General Purpose GPU,汎用GPU)的に活用する動きが盛んになることが予測される。業務用や科学技術計算用アプリケーションだけでなく,ゲーム用途の物理シミュレーション,レイトレーシング,あるいは各種映像処理などの汎用アプリケーションにおいても,GPGPUが波及する可能性が高いのだ。CPUプログラムに近い,より複雑なロジックをGPUに実装する機会が増えると予想されるから,ランダムで広範囲なメモリアクセスに堪え得るキャッシュデザインが必要になった,ということなのだろう。
この流れは今後も進み,近い将来,GPUのラストレベルキャッシュも,CPUと同様,MB(メガバイト)の世界へ突入するものと思われる。
また,L2キャッシュに関しては,容量の3倍増以外にも,大きな変更点がある。それは,統合型データキャッシュになったことだ。
GT200で,容量256KBのL2キャッシュは,8基用意されたメモリコントローラに32KBずつ実装されての合計256KBで,しかも,キャッシュするのはテクスチャデータのみ。実際,その名称も「Tex L2」(テクスチャ用L2キャッシュ)となっていた。
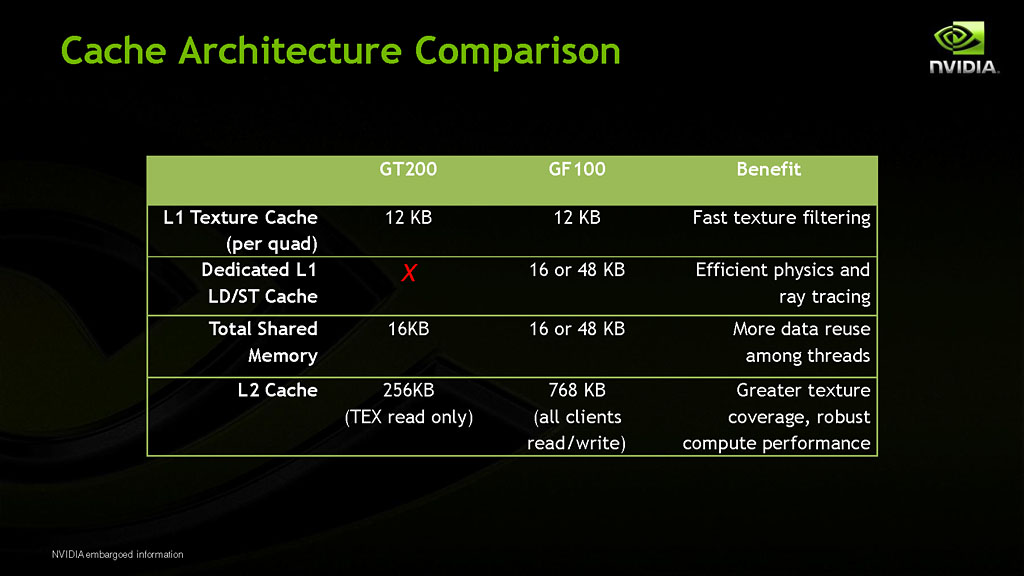
GT200とGF100のキャッシュ周辺アーキテクチャを比較した表
これに対して,「Unified L2 Cache」(統合型L2キャッシュ)と呼ばれるGF100のL2キャッシュは,全メモリコントローラから共有され,その用途はテクスチャデータに限定されない。各CUDA Coreからのメモリアクセスはもちろんのこと,ROPユニットからのメモリアクセスなど,あらゆる種類のメモリ読み書きをキャッシュ可能だ。
GT200のように,L2キャッシュを各メモリコントローラに直結させ,“メモリコントローラ専用L2キャッシュ”として用いるキャッシュシステムの場合,当該メモリアクセスがすべてのメモリコントローラに対して均一に発生すれば高い効果を望めるが,ランダムアクセスが発生した結果,あるメモリコントローラにメモリアクセスが集中すると,キャッシュメモリ利用量の不均衡が生じてしまうと,NVIDIAは主張する。「あるメモリコントローラのL2キャッシュは満杯なのに,別のメモリコントローラに直結した別のL2キャッシュはスカスカの空きだらけ」といった状況が起こり得るというのだ。
来るべきGPGPU全盛時代では,ますますメモリアクセスパターンが予測できなくなるので,GF100のような,適応力の高い統合型L2キャッシュシステムが必要になってきたと,NVIDIAは説明している。
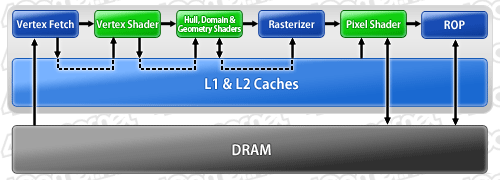
GF100では,GPU内部におけるランダムなデータ入出力の,かなりの割合をL1&L2キャッシュでまかなえる,CPU的なアーキテクチャとなった
また,前編でも簡単に触れたが,L2キャッシュがライトバックに対応したというのも,GT200からの大きな進化ポイントといえるだろう。
GF100では,CUDA Core側からのメモリの書き出しがあったとき,そのアドレスがキャッシュメモリでキャッシングされている場合は,まずその書き出しをL2キャッシュメモリ上に対して行い,システムが折を見てグラフィックスメモリ側に書き戻す振る舞いをしてくれるのだ。
なので,ある一定のパターンで同一アドレスへの読み書きが集中する場合は読み出しも書き込みもL2キャッシュ効果による高速化が見込めるという。

GF100で,ROPユニットは8基ずつグループにまとめられ,1グループが「ROPパーティション」となっている。GF100のROPパーティションは,メモリコントローラ数と同じく6基用意されるので,総数は48ROPということになる。
GT200だと,ROPユニット4基がROPパーティションを構成するイメージで,それが八つ用意されて32ROP相当だったので,GF100ではGT200比1.5倍となった計算だ。
GF100のROPユニットは,1基で,32bit整数ピクセルを1クロック,16bit浮動小数点(64bit)ピクセルを2クロック,32bit浮動小数点ピクセルを4クロックで出力できる能力を持つ。また,GPGPU用途では重要となるアトミック(Atomic)命令の場合,同一アドレスへの処理ならGT200に対して約20倍も高速化され,隣接したアドレスへの処理でも約7.5倍の高速化を実現したとNVIDIAは説明している。これはもちろん,前述したキャッシュシステム改良の恩恵があってこそ実現できたものだ。
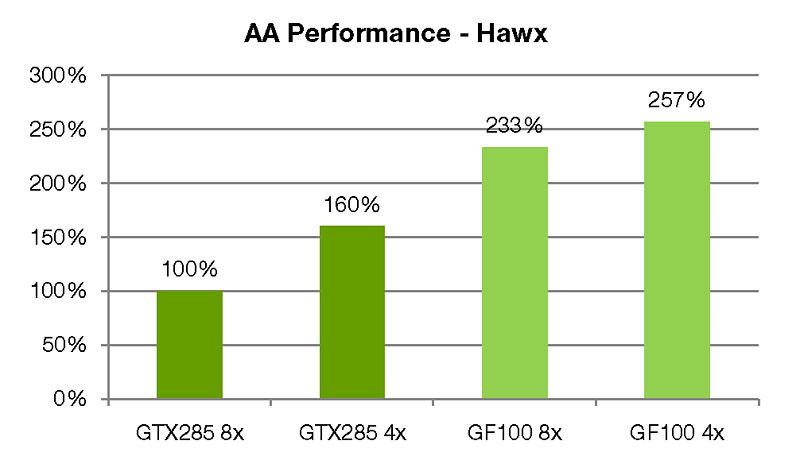
NVIDIAのホワイトペーパーから,Tom Clancy's H.A.W.Xを題材に,GF100の8x AA適用時の性能をアピールするグラフ。「8x MSAAを適用しても,4x MSAA比で1割弱しかパフォーマンスは落ちないので,積極的に8x MSAAを使うべき」というメッセージも,このグラフには込められている
(C)2008 Ubisoft Entertainment. All Rights Reserved. H.A.W.X, Ubisoft, Ubi.com, the Ubisoft logo, and the Soldier icon are trademarks of Ubisoft Entertainment in the U.S. and/or other countries.
また,ROPユニットは,8xサンプリング以上のMSAA(Multi-Sampling Anti-Aliasing)を高速化するのに特化した改善が行われている。
例えば8x MSAAだと,ピクセルシェーダからの1ピクセル分の出力値(カラー値)と,8倍解像度のZ値(深度値)を取り扱うが,GF100では,このカラー値と深度値の圧縮処理を高効率化することに成功したという。これによって,バス帯域幅消費を削減でき,さらに前述の統合型L2キャッシュシステムの恩恵も重なって,GT200から,8x MSAAのパフォーマンスが,劇的に向上。Ubisoft Entertainmentの「Tom Clancy's H.A.W.X」で,8x MSAA適用時における「GeForce GTX 285」の平均フレームレートを100%としたパフォーマンス比較を行うと,GF100は8x MSAA適用時に233%のスコアを示すとのことだ。
これまでとくに公表されていなかったが,NVIDIAは古くから,MSAAに最適化したピクセル値圧縮を採用してきたという。「あるピクセルに対応する四つのサブピクセルが同一色の場合には,四つバラバラのサブピクセル値をフレームバッファに書き出すのではなく,ひとかたまりの圧縮データとしてカラー値を書き出す」という工夫だ(※一般的な「ランレングス圧縮」に相当する)。

G80で導入されたCSAAは,GF100で拡張された
GT200までは,この圧縮を適用できるサブピクセル数に上限があったのだが,GF100でこの上限は「ほぼ」撤廃されたとのこと。NVIDIAが,「ほぼ」という言い方をしたのは,「アルゴリズム的にはいくつでも対応できるが,費用対効果の面で,MSAAのサンプル数上限が16x程度までとされているためだろう。
実際,16xを超えたアンチエイリアシングについては,NVIDIA独自のCSAA(Coverage Sasmpling Anti-Aliasing)に,新しく「32x CSAA」モードを追加していたりする。
CSAAについては,GeForce 8800 GTXのアーキテクチャを紹介したときに解説したが,要するに「サブピクセルのカラーやZ値を圧縮することでメモリやメモリバス帯域幅利用量を節約し,その分で通常のMSAAよりも多くのサンプリングを行うことで,アンチエイリアシング品質を向上させよう」というもの。一言でまとめるなら,「圧縮処理付きMSAA」といったところだ。
例えば16x CSAAだと,16か所あるサブピクセル解像度のZ値から“エッジ内外率”となる「Coverage Sample」を求めるが,サブピクセル解像度の色情報は4個しか持たない。さらに,それを圧縮して管理することにより,「多少のGPU負荷と引き替えに,ボトルネックとなり得るメモリ消費量を削減することで,より高いサンプル数とパフォーマンスを発揮させよう」というわけである。
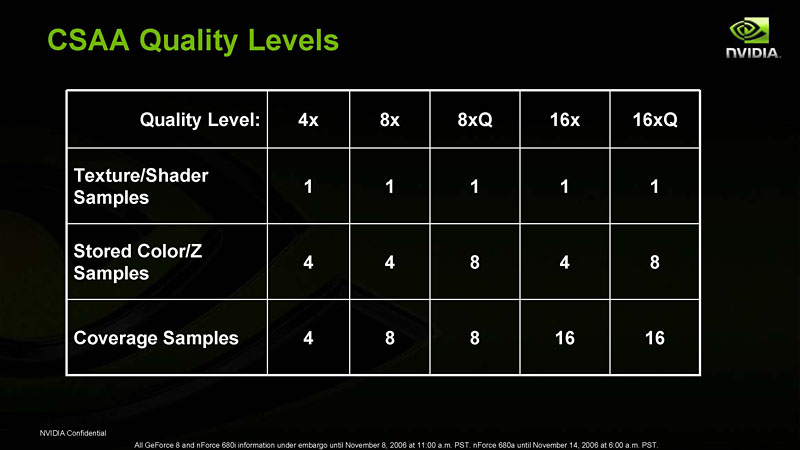
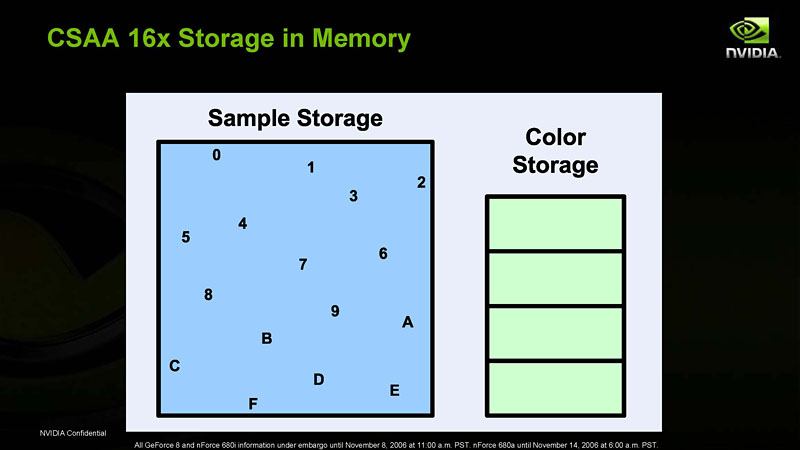
G80(≒GeForce 8800 GTX)では4x CSAA〜16xQ CSAAがサポートされていた。ちなみに「Q」は,より高品質に振った意で,16xQ CSAAだと,サブピクセル解像度の色情報を8個持つ

言ってしまえば,CSAAは“改良版MSAA”。ピクセルシェーダからの出力は1個しか利用せず,エッジ内外率はサブピクセル解像度の個数分のZ値から判断するところまでは同じだが,サブピクセル解像度の色情報を保持する個数が異なる。ちなみに,この表を見ても分かるように,4x CSAAと4x MSAAの品質および負荷は変わらず。8x MSAAと8x CSAAも同じだ。CSAAの“旨み”が出てくるのは8xQ CSAA以上
前述したように,GF100では,ROPシステムが8x MSAAに特化した構造を装備した。これにより,8x MSAAを高速に処理できるようになったので,8個分のサブピクセル色情報サンプルと,24個のCoverage Sampleを元手にアンチエイリアシングを行う32x CSAAが新設されたというわけだ。

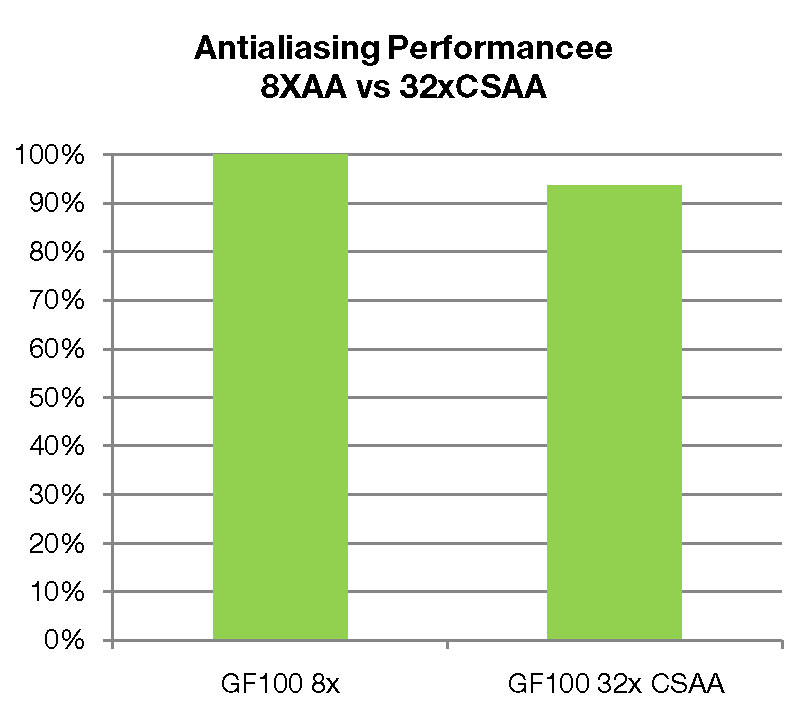
32x CSAAの概要(左)。32x CSAAで配慮されるCoverage Sample数が24なのは,「8個のサブピクセル色情報をサンプリングするとき,同時に,対応するZ値もサンプリングする」(NVIDIA)ため。右はGF100における8x MSAAと32x CSAAのパフォーマンス比較。32x CSAAを適用しても,パフォーマンスはわずか7%しか低下しないという
テクスチャの透明テクセルと不透明テクセルの境界に対してアンチエイリアシングを適用するTAA(Transparency Anti-Aliasing,トランスペアレンシー・アンチエイリアシング),そして,DirectX 10.0以降に新設されたACAA(Alpha Coverage Anti-Aliasing,アルファカバレージ・アンチエイリアシング,別名「Alpha to Coverage」)の処理においても,32x CSAAは大きな効果を発揮する。
金網や生い茂る雑草の表現などでは,テクスチャを貼り付けた素ポリゴンを表示する,いわゆるビルボード的な実装手法が主流だが,こうしたテクスチャは,“その向こう”を見透かせる透明テクセルを含んでいる。そして,「深度値の段差をエッジとして認識して,そこに対してアンチエイリアシング処理を行う」という通常の手法では,こうしたテクスチャ境界のジャギーは低減できない。
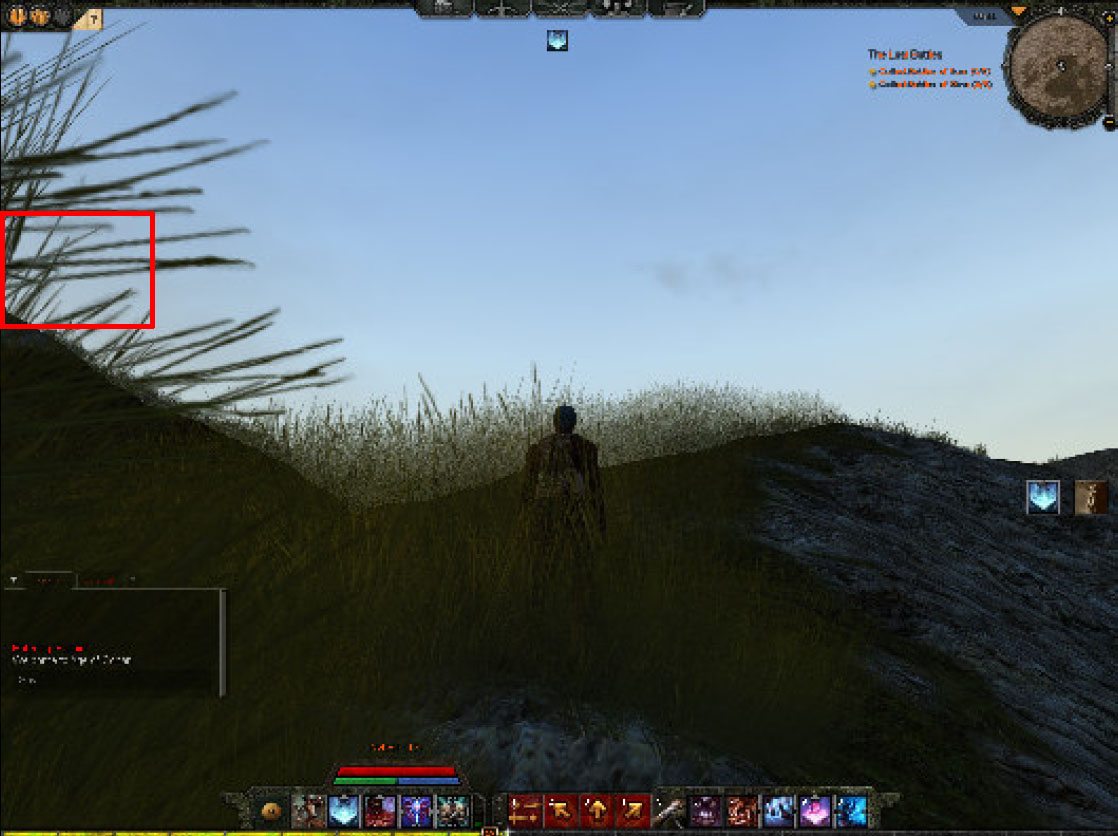
「Age of Conan: Hyborian Adventures」より,GT200とGF100のTAA品質を,赤い枠で囲った雑草表現で比較しようというスクリーンショット。拡大してみると……(下に続く)
この問題を解決すべく登場したのがACAAで,本手法なら,透明テクセルと不透明テクセルの境界に対してアンチエイリアシング処理を適用できる。ただACAAは,描画ピクセル単位ではなく,テクセル単位でのアンチエイリアシングとなる。そのため,金網や雑草が視点の近くに来ると,テクスチャそのものが大写しとなる関係で,4xあるいは8x程度だと,まだジャギーの低減が不十分となるケースが多かった。
その点,32x CSAAなら,ACAAに応用することで,エッジ内外判定のサンプル数がGT200以前と比較して劇的に多くなるため,大写しになるテクスチャに対するアンチエイリアシング品質が相当に向上するというのが,NVIDIAの主張だ。


(続き)左は,GT200で16x CSAA(8カラー+16 Coverage Sample)を適用したところ。右が,GF100で32x CSAA(8カラー+32 Coverage Sample)適用時のもので,これだけの違いが出ている
(c)2007 Conan Properties International LLC . CONAN, CONAN THE BARBARIAN and related logos, characters, names, and distinctive likenesses thereof are trademarks of Conan Properties International LLC unless otherwise noted. All Rights Reserved. Funcom Authorized User.

DirectX 9世代のアプリケーションである「Left 4 Dead 2」で,赤枠で囲んだ部分を使ってTAAの品質を比較したスクリーンショット。拡大してみると……(下に続く)
さらにGF100では,ACAAのAPIが用意されていないDirectX 9世代のゲームアプリケーションでも,32x CSAAを活用した“ACAAオーバーライド”機能を持たせているという。DirectX 9において,半透明合成にはアルファテストを実行するが(※DirectX 10以降でアルファテストはなくなった),GF100では,このアルファテストを,自動的に32x CSAA付きACAAに変換する仕組みを有しているとのことだ。
これは,オンラインゲームなど,以前から長く遊ばれているDirectX 9世代のタイトルのユーザーから,新たなグラフィックス表示品質手段として歓迎されるかもしれない。


(続き)GT200では,サンプル数が少ないため,柵の消失が見て取れる(左)。対し,GF100は柵の形が破綻していない(右)
(C)2009 Valve Corporation. All rights reserved. Valve, the Valve logo, Left 4 Dead, the Left 4 Dead logo, Source, the Source logo, Half-Life, Counter-Strike, Portal and Team Fortress are trademarks or registered trademarks of Valve Corporation in the United States and/or other countries.

最後は,「GF100で,DirectX 11の目玉であるテッセレーションステージがどのように実装されているか」を解説してみたい。
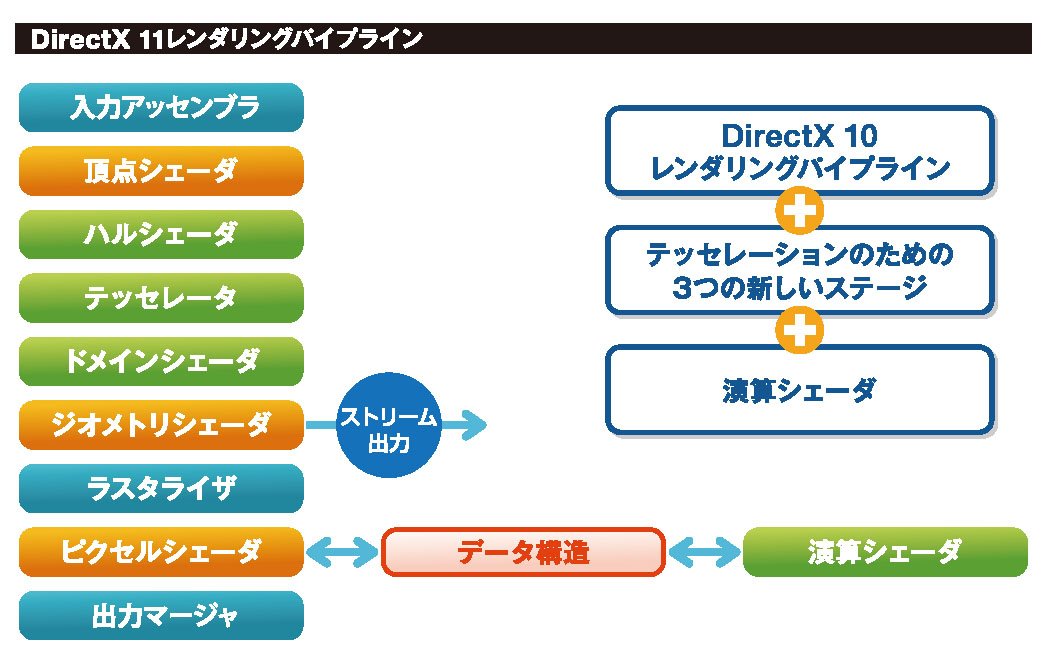
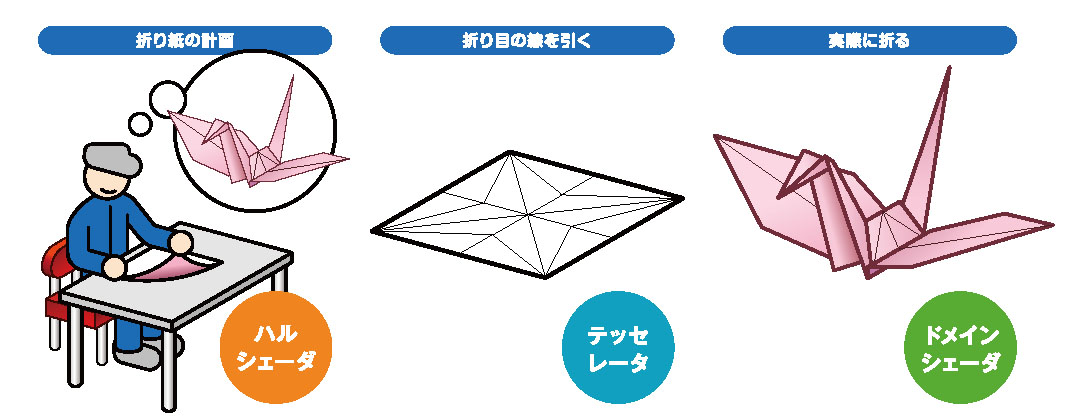
上はDirectX 11のレンダリングパイプライン。下は,テッセレーションステージに新設された3機能の役割を折り紙にたとえたイメージだ
出典:『ゲーム制作者になるための3Dグラフィックス技術』(西川善司著/インプレスジャパン刊)
まず「そもそもテッセレーションステージとは何なのか」について簡単に触れておこう。
DirectX 10.0では,ジオメトリシェーダ(Geometry Shader)という,頂点を増減させる新しいプログラマブルシェーダが頂点パイプラインに新設されたのを憶えている人は多いだろうが,DirectX 11で新設されたテッセレーション(Tessellation)ステージは,これまた頂点パイプラインに追加された新機能,というか,新しいシェーダステージになる。
テッセレーション“シェーダ”でなく「ステージ」なのは,複数の機能による集合体であるためだ。具体的には,「ハルシェーダ」(Hull Shader)と「ドメインシェーダ」(Domain Shader)の二つで,これに加えて,固定機能シェーダユニットとしての「テッセレータ」(Tessellator)も追加されている。
ステージの流れは,ざっくり下記のとおりだ。
- ハルシェーダが,「ポリゴンをどう分割するのか」を定義し,
- ハルシェーダが立てた“ポリゴン分割計画”に従って,テッセレータが実際にポリゴンを分割処理し,
- 分割されたポリゴン群に対して,ドメインシェーダが,「実際の3D空間上でどの位置に変位するのか」の意味づけを行う


NVIDIA製デモ「Realistic Water Terrain」より。水面の波と地形の凹凸がテッセレーションステージで表現されている。上が適用レベル最低,下が最高で,見栄えはこんなに変わる。LoD(Level of Detail)システムを,GPU側から面倒見る時代がついに到来する?!
ちなみに,三つの新しい新シェーダステージ中,,3Dモデルにユニークなディテールを付加するディスプレイスメントマッピング(Displacement Mapping)の実作業を担当するのはドメインシェーダになる。
下に示した図は,NVIDIAが示しているテッセレーション処理の例。左上が,基本形状となる低ポリゴンモデルだ。アニメーションは,この低ポリゴンベースで行われる。
次に右上と左下はいずれも,左上のモデルに対して,テッセレーションステージを経て多ポリゴン化したモデル。右上は,左上との対応関係を分かりやすくすべく,ワイヤーフレームを可視化したものである。
そして右下が,多ポリゴンに変換された3Dモデルに対し,ディテール情報を付加するディスプレイスメントマッピングを適用した結果だ。

テッセレーション処理(&ディスプレイスメントマッピング)の例
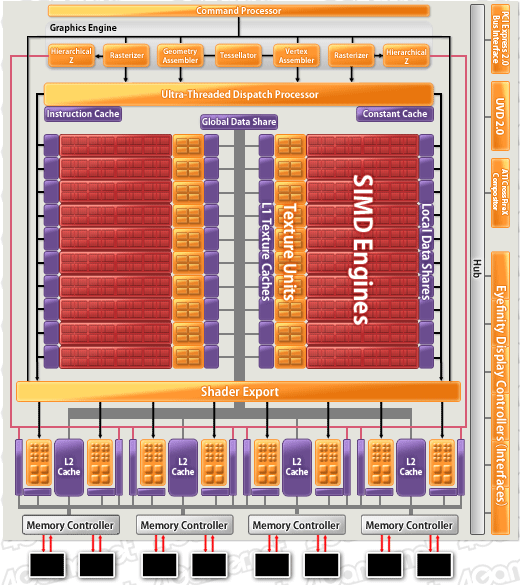
(参考)「ATI Radeon HD 5870」のブロックダイアグラム。テッセレータはシェーダコアの外,「Graphics Engine」部に設けられている
AMDは,DirectX 11対応GPUシリーズであるATI Radeon HD 5000シリーズで「テッセレーション工程は,それほど高負荷なものではないため,単一の専用ロジックで十分に処理できる」というスタンスを取っており,「ATI Radeon HD 4800シリーズを拡張しつつ,テッセレータユニットをシェーダコアの外に設ける」という形でテッセレーションに対応している。
DirectX 11におけるテッセレーションステージの原型は,旧ATI Technologiesが設計したXbox 360用GPU「Xenos」やATI Radeon HD 2000で搭載されていた独自テッセレータにあると言われているが,実際,このころから,ATI Radeonのテッセレータはシェーダコアの外に設けられてきた。それは,最新世代でも変わっていないわけだ。
これに対してNVIDIAは,「今後,テッセレーションステージは,劇的かつ積極的に活用される」という予測を立てており,テッセレータにかかる負荷を大きなものと想定。GF100の開発に当たって,ジオメトリエンジンそのものの見直しを図った(※G80以降,3DグラフィックスよりGPGPUに重心を置いてGPUを開発してきた近年のNVIDIAにしては,意外な判断にも思える)。
「DirectX 10.xのジオメトリシェーダが現在もそうであるように,テッセレーションステージは,3Dゲームグラフィックス表現において,今後しばらくはワンポイントリリーフ的な存在になる」と見るか,「3Dゲームエンジンの根幹からテッセレーションステージが用いられる」と見るか。AMDとNVIDIAによる,未来予想のこの違いが,DirectX 11世代におけるテッセレーションステージの実装方法の違いになって現れた,ということもできそうだ。
GF100の全体ブロックダイアグラムを再掲
テッセレーションステージが3Dゲームグラフィックスエンジンの根幹に使われるようになると,(当たり前だが)テッセレーションが頻繁に行われ,ひいては,GPU内部で行う頂点処理量が爆発的に増加していく。
そこで,NVIDIAはテッセレータの実装をAMDとは変えてきたわけだが,実のところ,変化はテッセレータだけに留まらない。テッセレータを含むエンジン部そのものの実装方針も見直し,SM単位で「PolyMorph Engine」(ポリモーフエンジン)として実装する設計へと,大きく舵を切ったのだ。順当ならGPC単位で1基ずつでもよさそうなところを,SMごとに1基ずつ――GF100全体では,16基のPolyMorph Engineを持つことになる。
ポリゴン(Polygon)を変形(Morph)させるポテンシャルがあることからその名が与えられたPolyMorph Engineは,頂点単位の仕事を生成してSMに向けて発行し,結果をSMから受け取る。そして,頂点単位の仕事がすべて終わったら,その結果を今度は,前編で解説した「Raster Engine」に受け渡し,最後はRaster Engineがピクセル単位の仕事生成を行う。“頂点次元”のタスク生成を行うのがPolyMorph Engine,“ピクセル次元”のタスクを生成してピクセルシェーダへ渡すのがRaster Engineというわけである。
さて,16基あるPolyMorph Engineには,それぞれ「Vertex Fetch」「Tessellator」「Viewport Transform」「Attribute Setup」「Stream Output」,計5ユニットが実装されている。
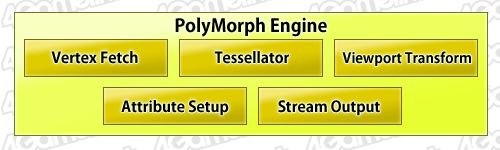
PolyMorph Engineを構成する5ユニット
Vertex Fetch(バーテックスフェッチ)ユニットは,頂点バッファから頂点情報を読み出し,その頂点情報をSMへと送り,SM内CUDA Coreを頂点シェーダやハルシェーダとして起用させる。
頂点シェーダでオブジェクト座標系からワールド座標系に変換し,ハルシェーダでLoDに配慮したテッセレーション計画を計算したら,これらの情報がPolyMorph Engineに戻ってくることになる。
GF100のSMブロックダイアグラムを再掲
次にTessellatorユニットが,ハルシェーダで算出されたパラメータを基に,ポリゴン分割を実施する。同時に,分割したポリゴンとテクスチャ座標の対応付けも行って,結果をSMへと送るのだが,そこでSMは,この結果を基にして,CUDA Coreをドメインシェーダとして起用し,分割されたポリゴンに3D情報を加味する計算を行う(※このとき,凹凸変位情報を記載したテクスチャを読み出し,分割したポリゴンの各頂点を粘土のように隆起させたり,沈降させたりするディスプレイスメントマッピング処理も行える)。
この結果は,再びPolyMorph Engineへと戻される。以上で,一連の頂点次元処理が完了だ。
そこで,今度は,実際にピクセルをレンダリングする前段階処理として,カメラ(=視点)基準の座標系に変換したり透視投影変換したりする処理を,Viewport Transform(ビューポートトランスフォーム)ユニットで行う。
さらに,後段でピクセルシェーダを動作させるために必要な情報,例えば,平面方程式に必要な法線ベクトルをはじめとする頂点付随情報などを,Attribute Setup(アトリビュートセットアップ)ユニットで算出する。
Stream Output(ストリームアウトプット)ユニットは,ここまでの処理結果をRaster Engineに回さず,途中出力するために利用される。
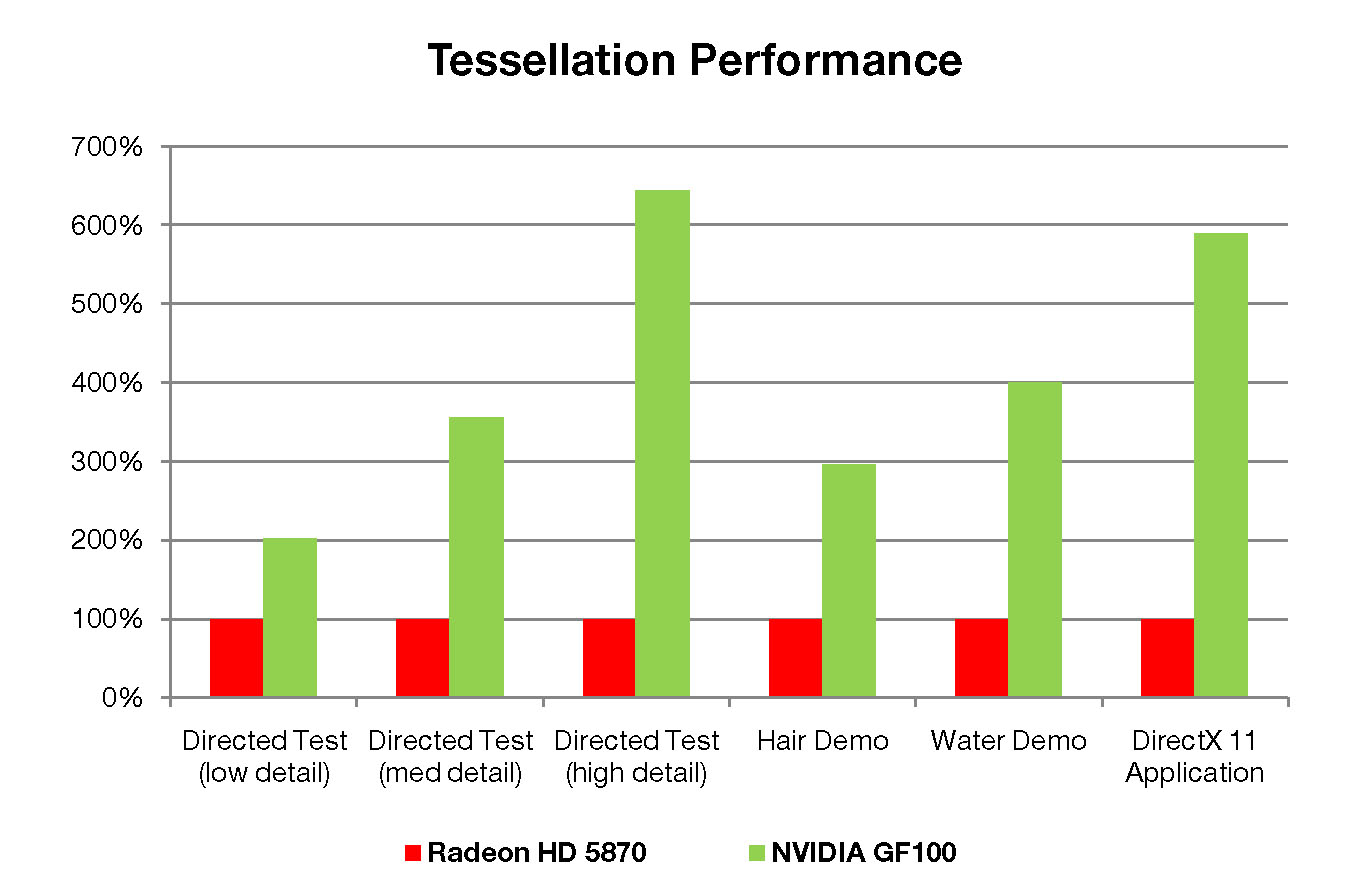
NVIDIAのホワイトペーパーより,ATI Radeon HD 5870とGF100のテッセレーション性能を比較したグラフ
従来のGPUだと,「頂点パイプラインにおいて,シェーダユニットを用いないで行われる基本処理」は,ほぼ例外なくシングルパイプラインで実行されてきた。しかし,GF100ではジオメトリエンジンが16基もあるので,この部分が16並列処理されることになったのだ。
これら16基のPolyMorph Engineの効果もあって,テッセレーションの実行性能差は,ATI Radeon HD 5870比で最大6倍以上に達しているという。

CUDA Coreの大幅な増強と,メモリ&キャッシュシステムのリファインは,G80の後継として,GT200で行われたGPGPU性能強化に通じるものがある。ただ,GF100がそれだけに留まらず,ジオメトリエンジンの並列化にまで取り組んできたことは大変興味深い。
また,GPUメーカーは,アーキテクチャのメジャーバージョンアップ時,DirectXの新機能対応へ慎重になることが多いのだが,今回NVIDIAが,新世代のシェーダステージにおいて要となるテッセレータを,並列化したジオメトリエンジンに組み込んできたあたり,久々に,NVIDIAが3Dグラフィックスレンダリングに本気を出してきた印象を抱かせてくれる。
今後,テッセレーションステージが3Dゲームタイトルや主要3Dベンチマークソフトで積極的に用いられるようなことがあれば,GF100が持つ贅沢なジオメトリエンジン仕様は高い評価を得ることになるだろう。
ただし,AMDが予想するように,テッセレーションが,DirectX 10.xにおけるジオメトリシェーダ程度にしか使われないで終わってしまうと,かなりオーバーキルなフィーチャーとなってしまい,「NVIDIAの本気」はまったく評価されず,報われず仕舞いになるという可能性もある。
NVIDIAとしては,このゴージャスなアーキテクチャをムダにしないため,今後,自社と関係の深いゲームスタジオに対し,テッセレーションステージの積極的な活用をアピールしていくことが責務であり,急務となるだろう。
AMDに対してずいぶんと出遅れた感はあるものの,NVIDIAからも対応GPUが登場することによって,Direct3Dに関する二強の足並みが久しぶりに揃うわけで,ユーザー側としては,ゲームやアプリケーションの技術レベル底上げや,ゲームエンジンの世代交代を期待したくなるところだ。
北米時間26日に明らかになるGF100の最終スペックとパフォーマンス,そして,2010年の3Dグラフィックスシーンの盛り上がりに期待したい。
- 関連タイトル:
 GeForce GTX 400
GeForce GTX 400 - この記事のURL:
Copyright(C)2010 NVIDIA Corporation
